Beyond Text and Tables: Vision-Language Model Integration in ComProScanner for Extracting Materials Data from Scientific Figures with High Accuracy
Pith reviewed 2026-06-30 17:46 UTC · model grok-4.3
The pith
Integrating a vision-language model lets ComProScanner extract composition-property data from scientific figures at 0.97 accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
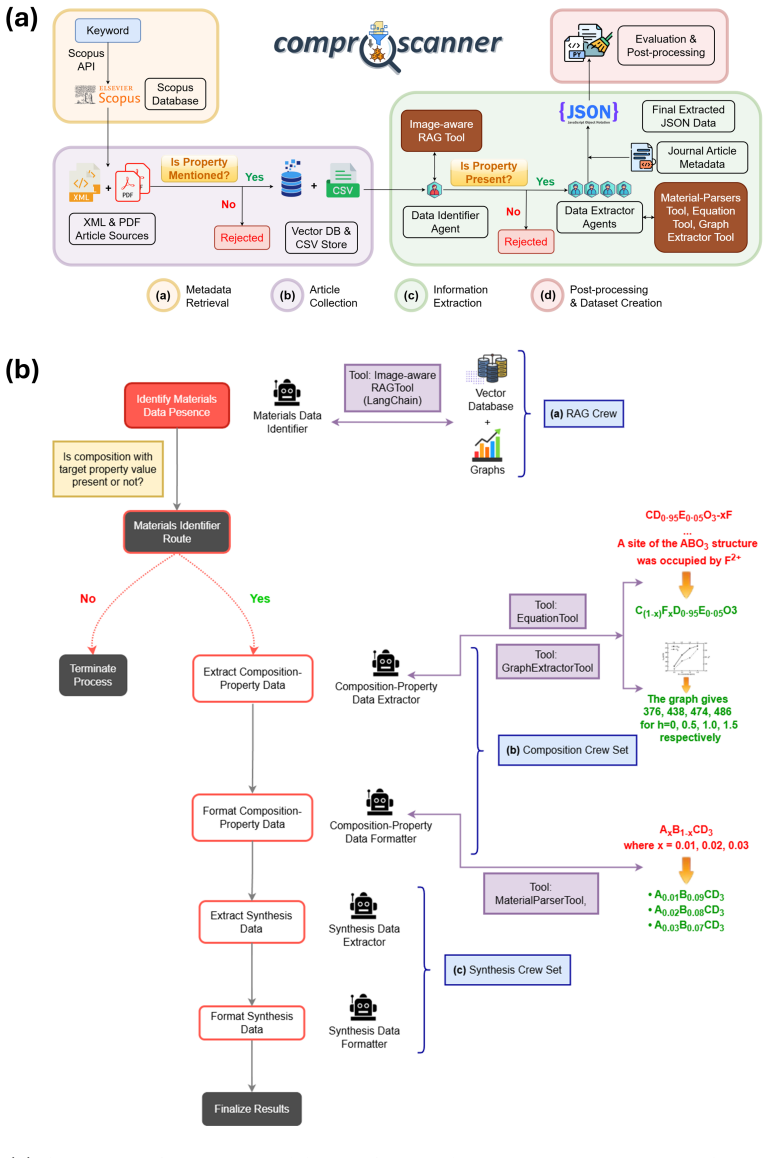
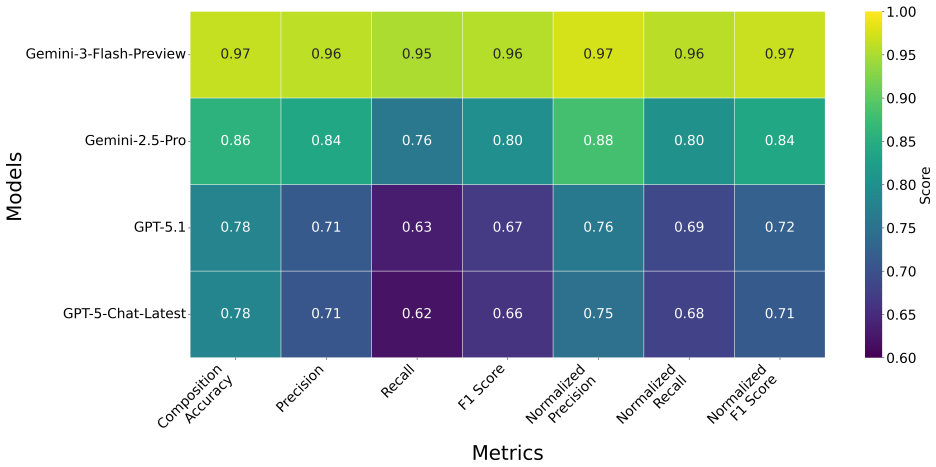
VLM-integrated ComProScanner recovers composition-property pairs from scientific charts and plots via the GraphExtractorTool, reaching 0.97 composition accuracy and 0.97 normalized F1 score with Gemini-3-Flash-Preview on the d33 test corpus of 50 piezoelectric ceramic articles and establishing the first materials-specific fully automated multimodal literature-mining platform.
What carries the argument
The GraphExtractorTool agent, which applies caption-keyword figure filtering then passes selected charts to a configurable VLM to recover composition-property pairs.
Load-bearing premise
The 50-article d33 test corpus is representative of the broader literature and VLM outputs require no human post-correction for the accuracy to hold in production use.
What would settle it
Running the pipeline on a larger and more diverse collection of articles from multiple publishers and finding substantially lower accuracy or requiring frequent manual fixes would falsify the performance claim.
Figures
read the original abstract
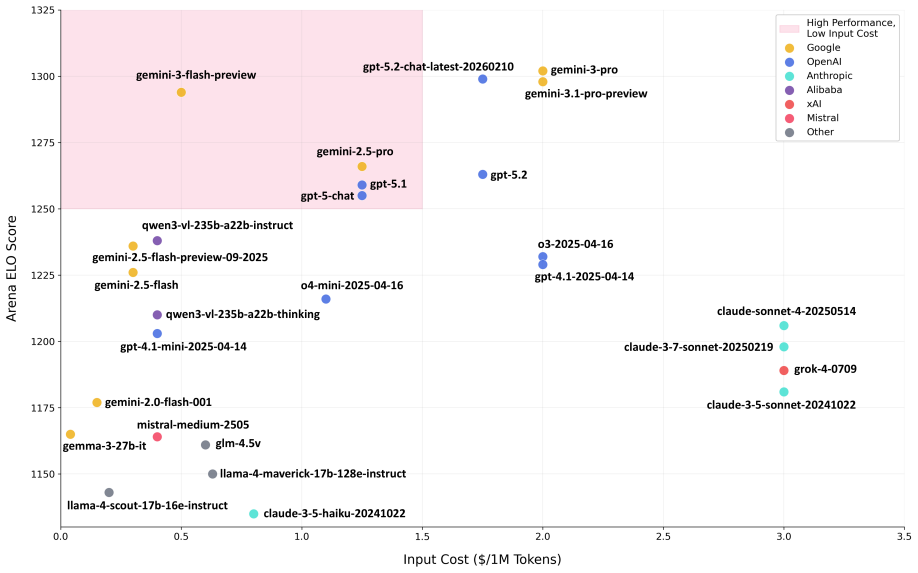
Automated extraction of materials composition-property data from scientific literature has advanced considerably with the development of large language model-based pipelines; however, existing frameworks remain limited to textual and tabular content, overlooking the substantial proportion of quantitative property data reported exclusively in scientific figures. Here, we extend ComProScanner, a fully end-to-end multi-agent framework for automated composition-property database construction, with a native vision-language model (VLM) based figure extraction capability. The extension introduces a FigureExtractor utility for caption-keyword-based figure filtering across all supported publishers, and a GraphExtractorTool agent that passes extracted figures to a configurable VLM to recover composition-property pairs from scientific charts and plots. Four VLMs are selected for evaluation on the basis of the LMArena Diagram leaderboard with an input cost criterion of less than \$1.50 per million tokens. Benchmarking on 50 piezoelectric ceramic articles from the established $d_{33}$ test corpus demonstrates that Gemini-3-Flash-Preview achieves the highest performance with a composition accuracy of 0.97 and a normalised F1 score of 0.97, whilst remaining the most cost-effective model among the four evaluated. We additionally introduce a range-based value error threshold parameter into the evaluation framework, providing a more physically meaningful assessment of numeric property values extracted from figures than exact value matching. These contributions establish VLM-integrated ComProScanner as the first materials-specific, fully automated, multimodal literature mining platform capable of extracting structured composition-property data from text, tables, and figures within a single unified pipeline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper extends ComProScanner, an end-to-end multi-agent framework for materials composition-property database construction, by adding native VLM-based figure extraction. It introduces a FigureExtractor utility for caption-keyword-based figure filtering and a GraphExtractorTool agent that routes figures to configurable VLMs (selected from the LMArena Diagram leaderboard under a cost constraint) to recover composition-property pairs from charts. Benchmarking on the established d33 test corpus of 50 piezoelectric ceramic articles reports that Gemini-3-Flash-Preview attains the highest performance (composition accuracy 0.97, normalised F1 0.97) while remaining cost-effective; a range-based value error threshold is added to the evaluation framework for more physically meaningful numeric assessment. The work positions the resulting system as the first materials-specific fully automated multimodal platform handling text, tables, and figures in one pipeline.
Significance. If the reported accuracy generalises, the contribution would be significant for materials informatics by closing the gap between text/table extraction pipelines and the substantial fraction of quantitative data that appears only in figures, thereby enabling more complete automated database population from the literature. The range-based threshold is a constructive methodological addition that aligns evaluation with physical tolerances rather than exact matching.
major comments (3)
- [Abstract / benchmarking description] Abstract and benchmarking description: the headline performance figures (Gemini-3-Flash-Preview: composition accuracy 0.97, normalised F1 0.97) rest on evaluation over a fixed 50-article d33 corpus, yet the manuscript supplies no quantitative evidence on corpus representativeness with respect to figure styles, caption conventions, data density, or publisher variability across the wider materials literature; this directly underpins the generalisability claim.
- [Abstract / evaluation framework] Abstract and evaluation framework: no error analysis, failure-mode breakdown, or ablation on the range-based value error threshold (including how its value was selected or its sensitivity to prompt/VLM choice) is reported, leaving the central numeric performance claim without the supporting diagnostics needed to interpret the 0.97 scores.
- [Abstract] Abstract: the assertion that VLM-integrated ComProScanner is 'the first materials-specific, fully automated, multimodal literature mining platform' requires an explicit comparison table or discussion against prior multimodal extraction systems to substantiate the novelty claim; absent that, the positioning is unsupported.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract / benchmarking description] Abstract and benchmarking description: the headline performance figures (Gemini-3-Flash-Preview: composition accuracy 0.97, normalised F1 0.97) rest on evaluation over a fixed 50-article d33 corpus, yet the manuscript supplies no quantitative evidence on corpus representativeness with respect to figure styles, caption conventions, data density, or publisher variability across the wider materials literature; this directly underpins the generalisability claim.
Authors: The d33 corpus is an established benchmark for piezoelectric materials extraction used in prior literature. The original manuscript does not supply quantitative representativeness metrics across the broader materials domain. In revision we will add a dedicated paragraph in the evaluation section that characterises the corpus (figure types, publishers, data density) from available metadata and explicitly qualifies the generalisability scope to similar ceramic systems, thereby making the limitation transparent. revision: partial
-
Referee: [Abstract / evaluation framework] Abstract and evaluation framework: no error analysis, failure-mode breakdown, or ablation on the range-based value error threshold (including how its value was selected or its sensitivity to prompt/VLM choice) is reported, leaving the central numeric performance claim without the supporting diagnostics needed to interpret the 0.97 scores.
Authors: We agree that these diagnostics are needed for proper interpretation. The threshold was selected to reflect typical experimental uncertainty ranges reported for d33 measurements. The revised manuscript will add an error-analysis subsection containing failure-mode examples, an ablation over threshold values, and sensitivity results across the evaluated VLMs and prompt variants. revision: yes
-
Referee: [Abstract] Abstract: the assertion that VLM-integrated ComProScanner is 'the first materials-specific, fully automated, multimodal literature mining platform' requires an explicit comparison table or discussion against prior multimodal extraction systems to substantiate the novelty claim; absent that, the positioning is unsupported.
Authors: To substantiate the claim we will insert a comparison table and accompanying discussion in the related-work section. The table will enumerate prior multimodal extraction systems (both general-domain and materials-specific), contrasting automation level, handling of text/table/figure modalities, and end-to-end integration. This will clarify the distinctive position of the multi-agent VLM-extended pipeline. revision: yes
Circularity Check
No circularity; empirical benchmarking on external corpus
full rationale
The paper reports VLM performance metrics (composition accuracy 0.97, normalised F1 0.97) obtained by running Gemini-3-Flash-Preview and three other models on the fixed, pre-existing d33 test corpus of 50 piezoelectric articles. No derivation, equation, or prediction is claimed that reduces by construction to fitted parameters, self-defined quantities, or a self-citation chain. The evaluation framework (range-based error threshold) is introduced as an external assessment tool rather than an internal tautology. This is a standard empirical result against an independent benchmark corpus and therefore receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
free parameters (1)
- range-based value error threshold
axioms (1)
- domain assumption Selected VLMs can recover composition-property pairs from scientific charts at the reported accuracy without systematic bias
Reference graph
Works this paper leans on
-
[1]
Data-driven materials research enabled by natural language processing and information extraction,
E. A. Olivetti, J. M. Cole, E. Kim, O. Kononova, G. Ceder, T. Y.-J. Han, and A. M. Hiszpanski, “Data-driven materials research enabled by natural language processing and information extraction,” Applied Physics Reviews, vol. 7, no. 4, 2020
2020
-
[2]
From text to insight: large language models for chemical data extraction,
M. Schilling-Wilhelmi, M. Ríos-García, S. Shabih, M. V. Gil, S. Miret, C. T. Koch, J. A. Márquez, and K. M. Jablonka, “From text to insight: large language models for chemical data extraction,”Chemical Society Reviews, vol. 54, no. 3, pp. 1125–1150, 2025
2025
-
[3]
Commentary: The materials project: A materials genome approach to accelerating materials innovation,
A. Jain, S. P. Ong, G. Hautier, W. Chen, W. D. Richards, S. Dacek, S. Cholia, D. Gunter, D. Skinner, G. Ceder,et al., “Commentary: The materials project: A materials genome approach to accelerating materials innovation,”APL materials, vol. 1, no. 1, 2013
2013
-
[4]
The joint automated repository for various integrated simulations (jarvis) for data-driven materials design,
K. Choudhary, K. F. Garrity, A. C. Reid, B. DeCost, A. J. Biacchi, A. R. Hight Walker, Z. Trautt, J. Hattrick-Simpers, A. G. Kusne, A. Centrone,et al., “The joint automated repository for various integrated simulations (jarvis) for data-driven materials design,”npj computational materials, vol. 6, no. 1, p. 173, 2020
2020
-
[5]
Materials design and discovery with high-throughputdensityfunctionaltheory: theopenquantummaterialsdatabase(oqmd),
J. E. Saal, S. Kirklin, M. Aykol, B. Meredig, and C. Wolverton, “Materials design and discovery with high-throughputdensityfunctionaltheory: theopenquantummaterialsdatabase(oqmd),”Jom, vol.65, no. 11, pp. 1501–1509, 2013
2013
-
[6]
Chemdataextractor: a toolkit for automated extraction of chemical information from the scientific literature,
M. C. Swain and J. M. Cole, “Chemdataextractor: a toolkit for automated extraction of chemical information from the scientific literature,”Journal of chemical information and modeling, vol. 56, no. 10, pp. 1894–1904, 2016
1904
-
[7]
Chemdataextractor 2.0: Autopop- ulated ontologies for materials science,
J. Mavracic, C. J. Court, T. Isazawa, S. R. Elliott, and J. M. Cole, “Chemdataextractor 2.0: Autopop- ulated ontologies for materials science,”Journal of Chemical Information and Modeling, vol. 61, no. 9, pp. 4280–4289, 2021
2021
-
[8]
Batterybert: A pretrained language model for battery database enhance- ment,
S. Huang and J. M. Cole, “Batterybert: A pretrained language model for battery database enhance- ment,”Journal of chemical information and modeling, vol. 62, no. 24, pp. 6365–6377, 2022
2022
-
[9]
Text-mined dataset of inorganic materials synthesis recipes,
O. Kononova, H. Huo, T. He, Z. Rong, T. Botari, W. Sun, V. Tshitoyan, and G. Ceder, “Text-mined dataset of inorganic materials synthesis recipes,”Scientific data, vol. 6, no. 1, p. 203, 2019
2019
-
[10]
A database of battery materials auto-generated using chemdataextractor,
S. Huang and J. M. Cole, “A database of battery materials auto-generated using chemdataextractor,” Scientific Data, vol. 7, no. 1, p. 260, 2020
2020
-
[11]
Quantifying the advantage of domain-specific pre-training on named entity recognition tasks in materials science,
A. Trewartha, N. Walker, H. Huo, S. Lee, K. Cruse, J. Dagdelen, A. Dunn, K. A. Persson, G. Ceder, and A. Jain, “Quantifying the advantage of domain-specific pre-training on named entity recognition tasks in materials science,”Patterns, vol. 3, no. 4, 2022
2022
-
[12]
Structured information extraction from scientific text with large language models,
J. Dagdelen, A. Dunn, S. Lee, N. Walker, A. S. Rosen, G. Ceder, K. A. Persson, and A. Jain, “Structured information extraction from scientific text with large language models,”Nature communications, vol. 15, no. 1, p. 1418, 2024
2024
-
[13]
Extracting accurate materials data from research papers with conver- sational language models and prompt engineering,
M. P. Polak and D. Morgan, “Extracting accurate materials data from research papers with conver- sational language models and prompt engineering,”Nature Communications, vol. 15, no. 1, p. 1569, 2024
2024
-
[14]
Reflections from the 2024 large language model (llm) hackathon for applications in materials science and chemistry,
Y. Zimmermann, A. Bazgir, Z. Afzal, F. Agbere, Q. Ai, N. Alampara, A. Al-Feghali, M. Ansari, D. Antypov, A. Aswad, J. Bai, V. Baibakova, D. D. Biswajeet, E. Bitzek, J. D. Bocarsly, A. Borisova, A. M. Bran, L. C. Brinson, M. M. Calderon, A. Canalicchio, V. Chen, Y. Chiang, D. Circi, B. Charmes, V. Chaudhary, Z. Chen, M.-H. Chiu, J. Clymo, K. Dabhadkar, N. ...
2024
-
[15]
Automatic identification of relevant quantities and unit conversion for materials science literature,
L. Foppiano, G. Lambard, T. Amagasa, and M. Ishii, “Automatic identification of relevant quantities and unit conversion for materials science literature,”Science and Technology of Advanced Materials: Methods, vol. 4, no. 1, p. 2356506, 2024
2024
-
[16]
Retrieval augmented generation for building datasets from scientific literature,
P. R. Maharana, A. Verma, and K. Joshi, “Retrieval augmented generation for building datasets from scientific literature,”Journal of Physics: Materials, vol. 8, no. 3, p. 035006, 2025
2025
-
[17]
Agent-based learning of materials datasets from the scientific literature,
M. Ansari and S. M. Moosavi, “Agent-based learning of materials datasets from the scientific literature,” Digital Discovery, vol. 3, no. 12, pp. 2607–2617, 2024
2024
-
[18]
Llm-based ai agents for automated extraction of material properties and structural features,
S. Ghosh and A. Tewari, “Llm-based ai agents for automated extraction of material properties and structural features,”Computational Materials Science, vol. 265, p. 114521, Feb. 2026
2026
-
[19]
From knowledge to action: Outcomes of the 2025 large language model (llm) hackathon for applications in materials science and chemistry,
A. Roy, K. Shen, A. MacBride, A. Oladipupo, M. Taskeen, W. Treyde, R. A. E. A. Abakar, A. D. Abbas, E. Abdelfatah, A. A. Abdullahi, S. S. Abyah, C. R. Adjmi, F. Agbere, S. Aggarwal, M. Ahmed, T. Ahmed, M. Ajlouni, M. Akke, H. AlAdwan, A. S. Alazani, Z. A. Alharbi, W. A. Aljulyhi, M. A. AlKubaish, F. A. Almahri, S. A. Almohri, D. O. Alobo, M. Alouni, A. S....
2025
-
[20]
Comproscanner: a multi-agent based framework for composition-property structured data extraction from scientific literature,
A. Roy, E. Grisan, J. Buckeridge, and C. Gattinoni, “Comproscanner: a multi-agent based framework for composition-property structured data extraction from scientific literature,”Digital Discovery, vol. 5, no. 4, pp. 1794–1808, 2026
2026
-
[21]
Plot2spectra: an auto- matic spectra extraction tool,
W. Jiang, K. Li, T. Spreadbury, E. Schwenker, O. Cossairt, and M. K. Chan, “Plot2spectra: an auto- matic spectra extraction tool,”Digital Discovery, vol. 1, no. 5, pp. 719–731, 2022
2022
-
[22]
Matgd: materials graph digitizer,
J. Lee, W. Lee, and J. Kim, “Matgd: materials graph digitizer,”ACS Applied Materials & Interfaces, vol. 16, no. 1, pp. 723–730, 2023
2023
-
[23]
Lineex: Data extraction from scientific line charts,
S. V. P, M. Yusuf Hassan, and M. Singh, “Lineex: Data extraction from scientific line charts,” in2023 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pp. 6202–6210, 2023
2023
-
[24]
Chartocr: Data extraction from charts images via a deep hybrid framework,
J. Luo, Z. Li, J. Wang, and C.-Y. Lin, “Chartocr: Data extraction from charts images via a deep hybrid framework,” in2021 IEEE Winter Conference on Applications of Computer Vision (WACV), pp. 1916–1924, 2021
1916
-
[25]
DePlot: One-shot visual language reasoning by plot-to-table translation,
F. Liu, J. Eisenschlos, F. Piccinno, S. Krichene, C. Pang, K. Lee, M. Joshi, W. Chen, N. Collier, and Y. Altun, “DePlot: One-shot visual language reasoning by plot-to-table translation,” inFindings of the Association for Computational Linguistics: ACL 2023(A. Rogers, J. Boyd-Graber, and N. Okazaki, eds.), (Toronto, Canada), pp. 10381–10399, Association fo...
2023
-
[26]
MatCha: Enhancing visual language pretraining with math reasoning and chart derendering,
F. Liu, F. Piccinno, S. Krichene, C. Pang, K. Lee, M. Joshi, Y. Altun, N. Collier, and J. Eisenschlos, “MatCha: Enhancing visual language pretraining with math reasoning and chart derendering,” inPro- ceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 12756–12770, 2023
2023
-
[27]
Image and data mining in reticular chemistry powered by gpt-4v,
Z. Zheng, Z. He, O. Khattab, N. Rampal, M. A. Zaharia, C. Borgs, J. T. Chayes, and O. M. Yaghi, “Image and data mining in reticular chemistry powered by gpt-4v,”Digital discovery, vol. 3, no. 3, pp. 491–501, 2024
2024
-
[28]
Leveraging vision capabilities of multimodal llms for automated data extraction from plots,
M. P. Polak and D. Morgan, “Leveraging vision capabilities of multimodal llms for automated data extraction from plots,” 2025
2025
-
[29]
Probing the limitations of multimodal language models for chemistry and materials research,
N. Alampara, M. Schilling-Wilhelmi, M. Ríos-García, I. Mandal, P. Khetarpal, H. S. Grover, N. A. Krishnan, and K. M. Jablonka, “Probing the limitations of multimodal language models for chemistry and materials research,”Nature computational science, vol. 5, no. 10, pp. 952–961, 2025
2025
-
[30]
Agent-based multimodal information extraction for nanomaterials,
R. Odobesku, K. Romanova, S. Mirzaeva, O. Zagorulko, R. Sim, R. Khakimullin, J. Razlivina, A. Dmitrenko, and V. Vinogradov, “Agent-based multimodal information extraction for nanomaterials,” npj Computational Materials, vol. 11, no. 1, p. 194, 2025. 9
2025
-
[31]
Chatbot arena: An open platform for evaluating llms by human preference,
W. L. Chiang, L. Zheng, Y. Sheng, A. N. Angelopoulos, T. Li, D. Li, H. Zhang, B. Zhu, M. Jordan, J. E. Gonzalez, and I. Stoica, “Chatbot arena: An open platform for evaluating llms by human preference,” 2024
2024
-
[32]
A new era of intelligence with gemini 3
S. Pichai, D. Hassabis, and K. Kavukcuoglu, “A new era of intelligence with gemini 3.”https://blog. google/products-and-platforms/products/gemini/gemini-3/, 2025. Accessed: 2026-05-18
2025
-
[33]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities,
G. Comanici, E. Bieber, M. Schaekermann, I. Pasupat, N. Sachdeva, I. Dhillon, M. Blistein, O. Ram, D. Zhang, E. Rosen, L. Marris, S. Petulla, C. Gaffney, A. Aharoni, N. Lintz, T. C. Pais, H. Jacobsson, I. Szpektor, N.-J. Jiang, K. Haridasan, A. Omran, N. Saunshi, D. Bahri, G. Mishra, E. Chu, T. Boyd, B. Hekman, A. Parisi, C. Zhang, K. Kawintiranon, T. Bed...
2025
-
[34]
Openai gpt-5 system card,
A. Singh, A. Fry, A. Perelman, A. Tart, A. Ganesh, A. El-Kishky, A. McLaughlin, A. Low, A. Ostrow, A. Ananthram, A. Nathan, A. Luo, A. Helyar, A. Madry, A. Efremov, A. Spyra, A. Baker-Whitcomb, A. Beutel, A. Karpenko, A. Makelov, A. Neitz, A. Wei, A. Barr, A. Kirchmeyer, A. Ivanov, A. Chris- takis, A. Gillespie, A. Tam, A. Bennett, A. Wan, A. Huang, A. M....
2026
-
[35]
GPT-5.1: A Smarter, More Conversational ChatGPT
OpenAI, “GPT-5.1: A Smarter, More Conversational ChatGPT.”https://openai.com/index/ gpt-5-1/, 2026. Accessed: 2026-05-18. 18
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.