Agreement Metrics for LLM-as-Judge Evaluation: What to Report and Why
Pith reviewed 2026-06-29 21:42 UTC · model grok-4.3
The pith
For binary LLM judge labels, Pearson's r, Spearman's ρ, Kendall's τ_b, phi, and Matthews correlation all reduce to the same number.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
On non-degenerate binary data, Pearson's r, Spearman's ρ, Kendall's τ_b, the phi coefficient φ, and the Matthews Correlation Coefficient are all equivalent, so reporting several of them supplies no independent evidence; Cohen's κ differs by normalizing against chance agreement and the gap between κ and φ tracks divergence in positive-label rates between judge and human.
What carries the argument
Mathematical reductions showing equivalence of correlation and association coefficients on 2x2 binary contingency tables.
If this is right
- Reporting multiple rank correlations on binary judgments creates an illusion of corroborating evidence rather than independent confirmation.
- The numerical gap between Cohen's κ and φ directly quantifies how far the judge's positive-label rate has drifted from the human's.
- The three common abstention-handling procedures are not interchangeable preprocessing steps; each answers a different evaluation question and restores or breaks the binary equivalences.
- The same equivalences hold, up to negligible finite-sample correction, for multi-judge ensembles evaluated with Fleiss' κ or Krippendorff's α.
Where Pith is reading between the lines
- Papers that have already reported several of the listed metrics on binary data can be re-read with the understanding that only one independent number was actually obtained.
- Adopting the checklist would make future LLM-judge evaluations easier to compare across studies.
- The same reduction logic could be checked on ordinal or continuous judgment scales to see whether additional metrics become redundant there as well.
Load-bearing premise
The data consists of non-degenerate binary labels without ties or abstentions that would invalidate the reductions.
What would settle it
A binary dataset on which the computed Pearson's r and phi coefficient take different numerical values would falsify the claimed reduction.
Figures
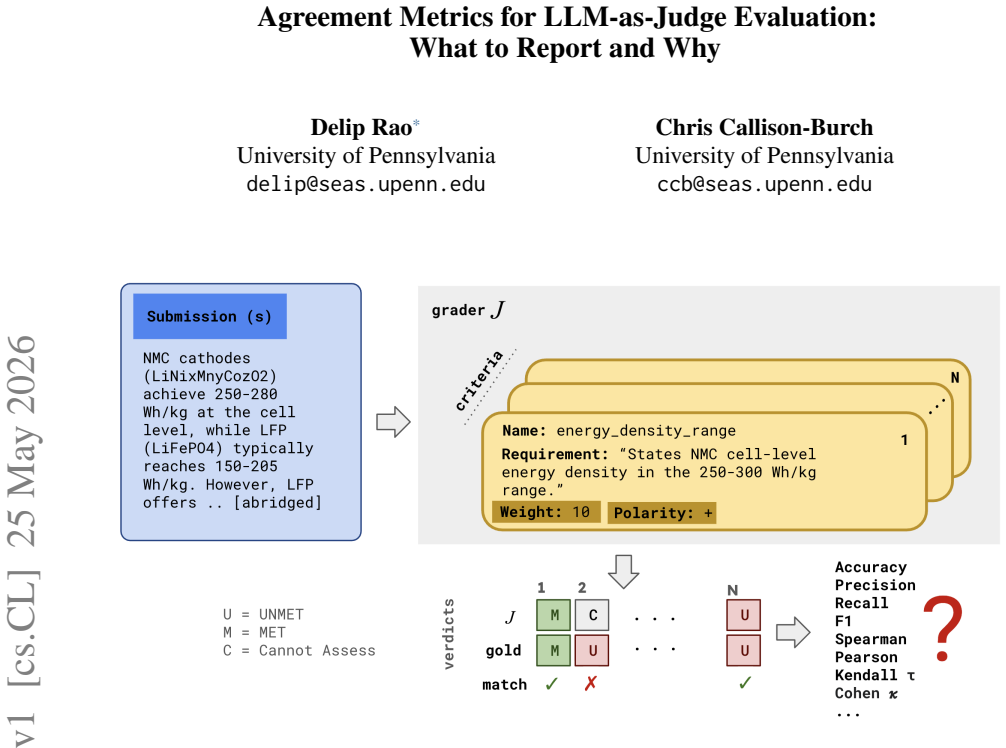
read the original abstract
Validating an LLM judge against human annotations usually means reporting several agreement statistics: accuracy, precision, recall, $F_1$, Cohen's $\kappa$, and one or more rank correlations. A survey of 24 recent LLM-as-judge papers finds metric choice entangled with the judgment scale, tie handling, invalid outputs, and abstention handling, and those choices rarely stated. For binary criteria -- the common case in rubric-based evaluation, where each criterion is graded MET or UNMET -- most of the reported numbers are redundant: Pearson's $r$, Spearman's $\rho$, Kendall's $\tau_b$, the phi coefficient $\phi$, and the Matthews Correlation Coefficient all reduce to a single number on non-degenerate binary data, so reporting several of them only creates an illusion of corroborating evidence. Cohen's $\kappa$ is the one agreement coefficient that adds information: it shares $\phi$'s numerator but normalizes differently, and the gap between them measures how far the judge's positive-label rate has drifted from the human's. We then trace what changes when a judge may abstain with a CANNOT_ASSESS verdict: the three common ways of handling abstentions are not interchangeable preprocessing choices but answer different questions, and they break the binary equivalences. The same equivalences reappear, up to a negligible finite-sample correction, for multi-judge ensembles scored with Fleiss' $\kappa$ or Krippendorff's $\alpha$. We close with a reporting checklist that names the judgment scale, the abstention and tie handling mode, coverage, the confusion matrix, and the aggregation level alongside any scalar agreement coefficient.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper surveys 24 recent LLM-as-judge papers and demonstrates that, for the common case of binary MET/UNMET rubric criteria on non-degenerate data, Pearson's r, Spearman's ρ, Kendall's τ_b, the phi coefficient φ, and the Matthews Correlation Coefficient are algebraically equivalent (up to finite-sample conventions) and thus redundant when reported together. Cohen's κ is shown to supply distinct information via its different normalization of the same numerator. The paper further analyzes how CANNOT_ASSESS abstentions alter the question being answered depending on the handling method, shows that the binary equivalences largely reappear for multi-judge Fleiss' κ and Krippendorff's α, and concludes with a reporting checklist that includes judgment scale, abstention/tie handling, coverage, confusion matrix, and aggregation level.
Significance. If the equivalences hold as stated, the work is significant for improving reporting standards in LLM evaluation research. By grounding the claim in both algebraic identities and an external survey of current practice, it directly addresses the proliferation of redundant metrics that create an illusion of corroboration. Credit is due for the concrete survey of 24 papers and for isolating the marginal-drift interpretation of the κ–φ gap as a falsifiable, actionable distinction rather than an ad-hoc adjustment.
minor comments (2)
- The abstract states that the equivalences hold 'up to a negligible finite-sample correction' for multi-judge ensembles; a brief explicit statement of the size of that correction (or a reference to the exact formula) would aid readers who wish to verify the claim numerically.
- Section describing the survey (implied by the abstract's count of 24 papers) would benefit from a short table or appendix listing the papers and the exact metric combinations each reported, to make the entanglement claim fully auditable.
Simulated Author's Rebuttal
We thank the referee for the careful reading of the manuscript and the positive recommendation to accept. The provided summary correctly reflects the paper's scope, methods, and conclusions.
Circularity Check
No significant circularity identified
full rationale
The central claim consists of algebraic identities showing that Pearson r, Spearman ρ, Kendall τ_b, φ, and MCC coincide on non-degenerate binary labels; these are standard mathematical reductions independent of any fitted parameters or self-referential definitions in the paper. The survey of 24 external papers supplies grounding for prevalence rather than serving as a load-bearing premise. Cohen’s κ is correctly isolated as the sole coefficient with distinct normalization. No step matches any enumerated circularity pattern; the derivation is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard algebraic identities hold for correlation coefficients when restricted to non-degenerate binary data.
Forward citations
Cited by 1 Pith paper
-
How Humans, Bots, and Agents Communicate About Vulnerabilities in Pull Requests
The authors present a registered report outlining their planned large-scale empirical study of vulnerability communication in pull requests by different account types.
Reference graph
Works this paper leans on
-
[1]
Anna Bavaresco, Raffaella Bernardi, Leonardo Bertolazzi, Desmond Elliott, Raquel Fern\'andez, Albert Gatt, Esam Ghaleb, Mario Giulianelli, Michael Hanna, Alexander Koller, Andre Martins, Philipp Mondorf, Vera Neplenbroek, Sandro Pezzelle, Barbara Plank, David Schlangen, Alessandro Suglia, Aditya K Surikuchi, Ece Takmaz, and Alberto Testoni. 2025. https://...
-
[2]
Chi-Min Chan, Weize Chen, Yusheng Su, Jianxuan Yu, Wei Xue, Shanghang Zhang, Jie Fu, and Zhiyuan Liu. 2023. https://arxiv.org/abs/2308.07201 ChatEval : Towards better LLM -based evaluators through multi-agent debate . arXiv preprint
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Yew Ken Chia, Pengfei Hong, Lidong Bing, and Soujanya Poria. 2023. https://doi.org/10.48550/arXiv.2306.04757 INSTRUCTEVAL : Towards holistic evaluation of instruction-tuned large language models . arXiv preprint. ArXiv:2306.04757
-
[4]
C. K. Chow. 1970. https://doi.org/10.1109/TIT.1970.1054406 On optimum recognition error and reject tradeoff . IEEE Transactions on Information Theory, 16(1):41--46
-
[5]
Jacob Cohen. 1960. https://doi.org/10.1177/001316446002000104 A coefficient of agreement for nominal scales . Educational and Psychological Measurement, 20(1):37--46
-
[6]
Anthony J. Conger. 1980. https://doi.org/10.1037/0033-2909.88.2.322 Integration and generalization of kappas for multiple raters . Psychological Bulletin, 88(2):322--328
-
[7]
Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators
Yann Dubois, Bal \'a zs Galambosi, Percy Liang, and Tatsunori B. Hashimoto. 2024. https://arxiv.org/abs/2404.04475 Length-controlled AlpacaEval : A simple way to debias automatic evaluators . arXiv preprint
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Ran El-Yaniv and Yair Wiener. 2010. https://jmlr.org/papers/v11/el-yaniv10a.html On the foundations of noise-free selective classification . Journal of Machine Learning Research, 11:1605--1641
2010
-
[9]
Shahul Es, Jithin James, Luis Espinosa-Anke, and Steven Schockaert. 2023. https://doi.org/10.48550/arXiv.2309.15217 RAGAS : Automated evaluation of retrieval augmented generation . arXiv preprint. ArXiv:2309.15217
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2309.15217 2023
-
[10]
Alvan R. Feinstein and Domenic V. Cicchetti. 1990. https://doi.org/10.1016/0895-4356(90)90158-L High agreement but low kappa: I . the problems of two paradoxes . Journal of Clinical Epidemiology, 43(6):543--549
-
[11]
C. A. Field and A. H. Welsh. 2007. https://doi.org/10.1111/j.1467-9868.2007.00593.x Bootstrapping clustered data . Journal of the Royal Statistical Society Series B: Statistical Methodology, 69(3):369--390
-
[12]
Joseph L. Fleiss. 1971. https://doi.org/10.1037/h0031619 Measuring nominal scale agreement among many raters . Psychological Bulletin, 76(5):378--382
-
[13]
Joseph L. Fleiss, Jacob Cohen, and B. S. Everitt. 1969. https://doi.org/10.1037/h0028106 Large sample standard errors of kappa and weighted kappa . Psychological Bulletin, 72(5):323--327
-
[14]
Ariel Gera, Odellia Boni, Yotam Perlitz, Roy Bar-Haim, Lilach Eden, and Asaf Yehudai. 2024. https://doi.org/10.48550/arXiv.2412.09569 JuStRank : Benchmarking LLM judges for system ranking . arXiv preprint. ArXiv:2412.09569; to appear ACL 2025
-
[15]
J. Gorodkin. 2004. https://doi.org/10.1016/j.compbiolchem.2004.09.006 Comparing two k-category assignments by a k-category correlation coefficient . Computational Biology and Chemistry, 28(5-6):367--374
-
[16]
Helia Hashemi, Jason Eisner, Corby Rosset, Benjamin Van Durme, and Chris Kedzie. 2024. https://doi.org/10.18653/v1/2024.acl-long.745 Llm-rubric: A multidimensional, calibrated approach to automated evaluation of natural language texts . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), page...
-
[17]
Dongfu Jiang, Yishan Li, Ge Zhang, Wenhao Huang, Bill Yuchen Lin, and Wenhu Chen. 2023. https://doi.org/10.48550/arXiv.2310.00752 TIGERScore : Towards building explainable metric for all text generation tasks . arXiv preprint. ArXiv:2310.00752; published in TMLR 2024
-
[18]
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, Scott Johnston, Sheer El-Showk, Andy Jones, Nelson Elhage, Tristan Hume, Anna Chen, Yuntao Bai, Sam Bowman, Stanislav Fort, and 17 others. 2022. https://doi.org/10.48550/arXiv.2207.05221 Language model...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2207.05221 2022
-
[19]
Amita Kamath, Robin Jia, and Percy Liang. 2020. https://doi.org/10.18653/v1/2020.acl-main.503 Selective question answering under domain shift . In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 5684--5696, Online. Association for Computational Linguistics
-
[20]
M. G. Kendall. 1945. https://doi.org/10.1093/biomet/33.3.239 The treatment of ties in ranking problems . Biometrika, 33(3):239--251
-
[21]
Seungone Kim, Jamin Shin, Yejin Cho, Joel Jang, Shayne Longpre, Hwaran Lee, Sangdoo Yun, Seongjin Shin, Sungdong Kim, James Thorne, and Minjoon Seo. 2023. https://doi.org/10.48550/arXiv.2310.08491 Prometheus: Inducing fine-grained evaluation capability in language models . arXiv preprint. ArXiv:2310.08491
-
[22]
Seungone Kim, Juyoung Suk, Shayne Longpre, Bill Yuchen Lin, Jamin Shin, Sean Welleck, Graham Neubig, Moontae Lee, Kyungjae Lee, and Minjoon Seo. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.248 Prometheus 2: An open source language model specialized in evaluating other language models . In Proceedings of the 2024 Conference on Empirical Methods in Na...
-
[23]
Klaus Krippendorff. 2004. Content Analysis: An Introduction to Its Methodology, 2nd edition. SAGE Publications, Thousand Oaks, CA
2004
-
[24]
Chungpa Lee, Thomas Zeng, Jongwon Jeong, Jy yong Sohn, and Kangwook Lee. 2026. https://arxiv.org/abs/2511.21140 How to correctly report llm-as-a-judge evaluations . Preprint, arXiv:2511.21140
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
Yukyung Lee, JoongHoon Kim, Jaehee Kim, Hyowon Cho, Jaewook Kang, Pilsung Kang, and Najoung Kim. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.796 Checkeval: A reliable llm-as-a-judge framework for evaluating text generation using checklists . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 15782--15809
-
[26]
Junlong Li, Shichao Sun, Weizhe Yuan, Run-Ze Fan, Hai Zhao, and Pengfei Liu. 2023. https://doi.org/10.48550/arXiv.2310.05470 Generative judge for evaluating alignment . arXiv preprint. ArXiv:2310.05470
-
[27]
Yen-Ting Lin and Yun-Nung Chen. 2023. https://doi.org/10.48550/arXiv.2305.13711 LLM-Eval : Unified multi-dimensional automatic evaluation for open-domain conversations with large language models . arXiv preprint. ArXiv:2305.13711
-
[28]
Roderick J. A. Little and Donald B. Rubin. 2019. Statistical Analysis with Missing Data, 3rd edition. John Wiley & Sons, Hoboken, NJ
2019
-
[29]
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023. https://arxiv.org/abs/2303.16634 G-Eval : NLG evaluation using GPT-4 with better human alignment . arXiv preprint
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
B. W. Matthews. 1975. https://doi.org/10.1016/0005-2795(75)90109-9 Comparison of the predicted and observed secondary structure of T4 phage lysozyme . Biochimica et Biophysica Acta (BBA) - Protein Structure, 405(2):442--451
-
[31]
Barbara Plank. 2022. https://doi.org/10.18653/v1/2022.emnlp-main.731 The "problem" of human label variation: On ground truth in data, modeling and evaluation . In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 10671--10682, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics
-
[32]
Delip Rao and Chris Callison-Burch. 2026. https://arxiv.org/abs/2603.00077 Autorubric: Unifying rubric-based llm evaluation . Preprint, arXiv:2603.00077
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
Jon Saad-Falcon, Omar Khattab, Christopher Potts, and Matei Zaharia. 2023. https://doi.org/10.48550/arXiv.2311.09476 ARES : An automated evaluation framework for retrieval-augmented generation systems . arXiv preprint. ArXiv:2311.09476
-
[34]
Hwanjun Song, Hang Su, Igor Shalyminov, Jason Cai, and Saab Mansour. 2024. https://doi.org/10.18653/v1/2024.acl-long.51 FineSurE : Fine-grained summarization evaluation using LLMs . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 906--922, Bangkok, Thailand. Association for Computat...
-
[35]
Pat Verga, Sebastian Hofstatter, Sophia Althammer, Yixuan Su, Aleksandra Piktus, Arkady Arkhangorodsky, Minjie Xu, Naomi White, and Patrick Lewis. 2024. https://arxiv.org/abs/2404.18796 Replacing judges with juries: Evaluating LLM generations with a panel of diverse models . arXiv preprint
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Peiyi Wang, Lei Li, Liang Chen, Zefan Cai, Dawei Zhu, Binghuai Lin, Yunbo Cao, Qi Liu, Tianyu Liu, and Zhifang Sui. 2023 a . https://arxiv.org/abs/2305.17926 Large language models are not fair evaluators . arXiv preprint
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Yidong Wang, Zhuohao Yu, Zhengran Zeng, Linyi Yang, Cunxiang Wang, Hao Chen, Chaoya Jiang, Rui Xie, Jindong Wang, Xing Xie, Wei Ye, Shikun Zhang, and Yue Zhang. 2023 b . https://doi.org/10.48550/arXiv.2306.05087 PandaLM : An automatic evaluation benchmark for LLM instruction tuning optimization . arXiv preprint. ArXiv:2306.05087
-
[38]
Matthijs J. Warrens. 2008. https://doi.org/10.1007/s11336-008-9070-3 On association coefficients for 2x2 tables and properties that do not depend on the marginal distributions . Psychometrika, 73(4):777--789
-
[39]
Meng-Chen Wu, Md Mosharaf Hossain, Tess Wood, Shayan Ali Akbar, Si-Chi Chin, and Erwin Cornejo. 2025. https://doi.org/10.18653/v1/2025.findings-naacl.411 SEEval : Advancing LLM text evaluation efficiency and accuracy through self-explanation prompting . In Findings of the Association for Computational Linguistics: NAACL 2025, pages 7372--7383, Albuquerque...
-
[40]
Ji Xin, Raphael Tang, Yaoliang Yu, and Jimmy Lin. 2021. https://doi.org/10.18653/v1/2021.acl-long.84 The art of abstention: Selective prediction and error regularization for natural language processing . In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Languag...
-
[41]
Wenda Xu, Danqing Wang, Liangming Pan, Zhenqiao Song, Markus Freitag, William Yang Wang, and Lei Li. 2023. https://doi.org/10.48550/arXiv.2305.14282 INSTRUCTSCORE : Explainable text generation evaluation with fine-grained feedback . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Association for Computational Lin...
-
[42]
Seonghyeon Ye, Doyoung Kim, Sungdong Kim, Hyeonbin Hwang, Seungone Kim, Yongrae Jo, James Thorne, Juho Kim, and Minjoon Seo. 2024. Flask: Fine-grained language model evaluation based on alignment skill sets. In Proceedings of the Twelfth International Conference on Learning Representations
2024
-
[43]
Zhiyuan Zeng, Jiatong Yu, Tianyu Gao, Yu Meng, Tanya Goyal, and Danqi Chen. 2023. https://doi.org/10.48550/arXiv.2310.07641 Evaluating large language models at evaluating instruction following . arXiv preprint. ArXiv:2310.07641
-
[44]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. https://arxiv.org/abs/2306.05685 Judging LLM -as-a-judge with MT-Bench and Chatbot Arena . In Advances in Neural Information Processing Systems (Datasets and Benchmarks Tr...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[45]
Lianghui Zhu, Xinggang Wang, and Xinlong Wang. 2023. https://doi.org/10.48550/arXiv.2310.17631 JudgeLM : Fine-tuned large language models are scalable judges . arXiv preprint. ArXiv:2310.17631
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.