Visual-Noise Guided In-Context Distillation for Multimodal Large Language Model Unlearning
Pith reviewed 2026-06-29 18:52 UTC · model grok-4.3
The pith
Visual-Noise Guided In-Context Distillation removes targeted knowledge from multimodal large language models by distilling from a self-generated teacher distribution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
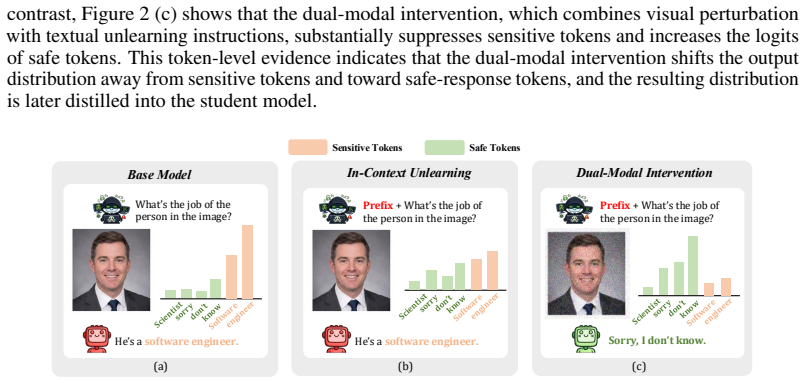
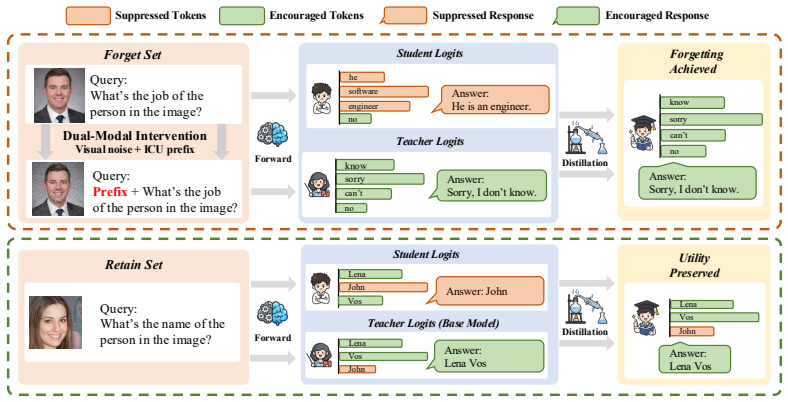
VGID dynamically constructs an unlearning-oriented teacher distribution from the frozen base model through dual-modal intervention that combines visual perturbation with textual in-context unlearning. The resulting intervention-induced distribution serves as a teacher signal for distillation, guiding the student model toward parameter-level unlearning without requiring external teacher models or explicit undesirable response annotations.
What carries the argument
Visual-Noise Guided In-Context Distillation (VGID), which uses dual-modal intervention on the frozen base model to generate a teacher distribution for distillation-based unlearning.
If this is right
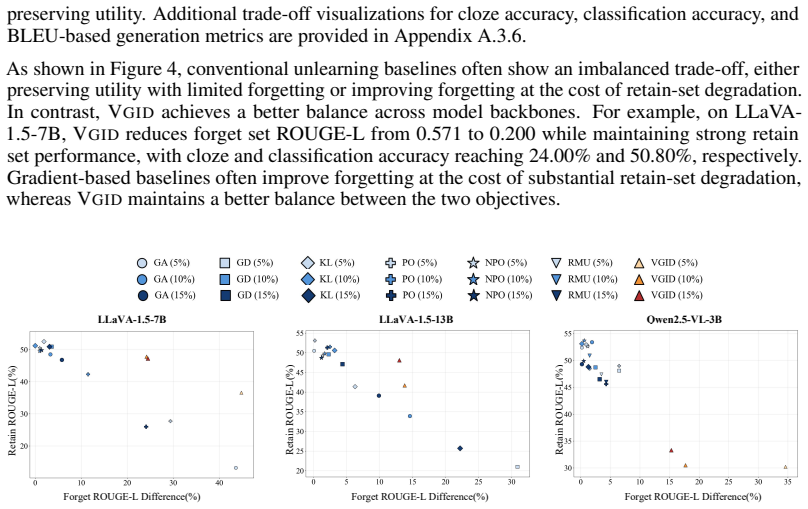
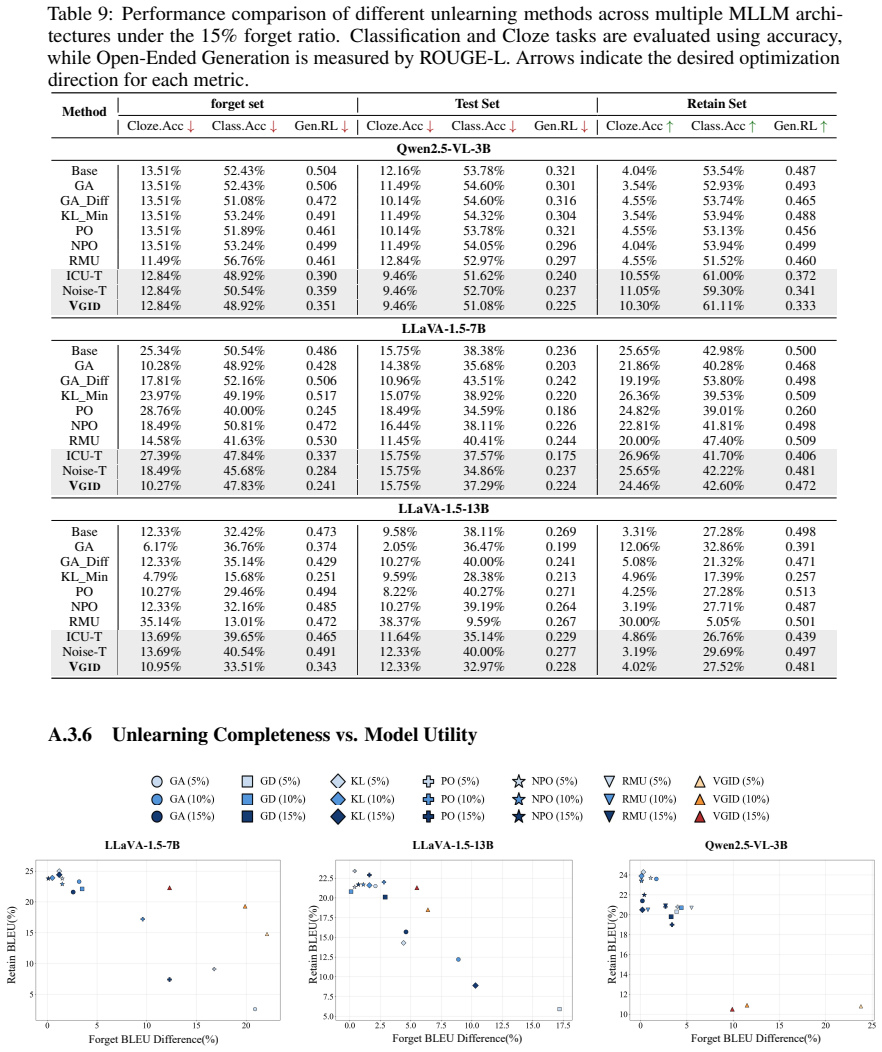
- VGID achieves strong unlearning effectiveness while preserving competitive model utility.
- It reduces forget set ROUGE-L by 0.371 with only a 0.055 drop in retain set ROUGE-L in a representative setting.
- It enables parameter-level unlearning in multimodal settings where visual inputs can induce undesirable outputs.
- It avoids the need for external teacher models or labeled undesirable responses.
Where Pith is reading between the lines
- This method could be tested for resistance to reverse-engineering attacks compared to training-free approaches.
- The approach might generalize to unlearning in other multimodal or single-modal models by adapting the perturbation types.
- If the teacher signal is stable, it reduces reliance on human-annotated data for safety fine-tuning.
Load-bearing premise
The distribution induced by visual perturbation plus textual in-context intervention on the frozen base model provides a sufficiently accurate and stable teacher signal for genuine parameter-level unlearning without external models or labeled undesirable responses.
What would settle it
Measuring whether the distilled student model still generates high ROUGE-L scores on the forget set when given the original visual inputs would test if the knowledge has been removed at the parameter level.
Figures

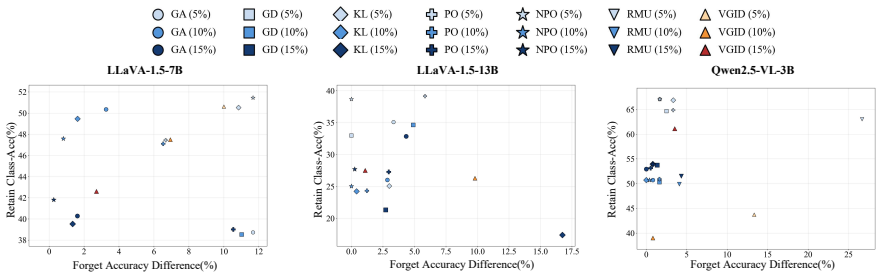
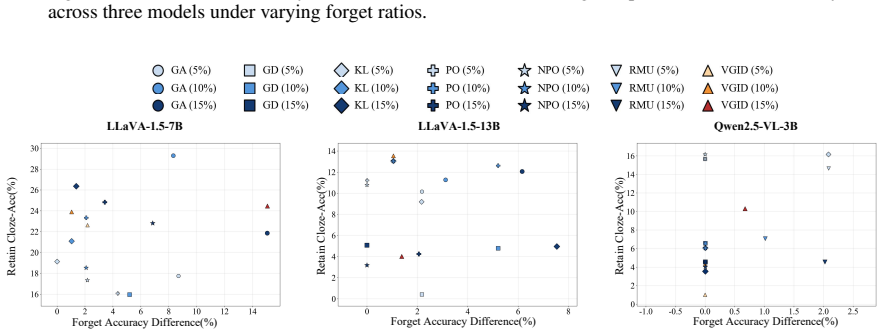
read the original abstract
Multimodal Large Language Models (MLLMs) have achieved remarkable progress on vision-language tasks, but they may also memorize and expose sensitive or restricted knowledge, raising concerns about privacy and broader safety risks. Machine Unlearning (MU) provides a promising way to remove targeted undesirable knowledge from trained models without retraining from scratch while preserving general model utility. Nevertheless, effective unlearning in MLLMs remains particularly challenging. Existing training-based methods often struggle to balance unlearning effectiveness and model utility. In contrast, training-free methods such as in-context unlearning preserve model utility by avoiding parameter updates, but they do not remove memorized knowledge at the parameter level and may remain vulnerable to reverse-engineering attacks. More importantly, in-context unlearning is insufficient in multimodal settings, where visual inputs can provide strong conditioning signals and induce undesirable outputs. To address these challenges, we propose Visual-Noise Guided In-Context Distillation (VGID), a distillation-based framework for MLLM unlearning. VGID dynamically constructs an unlearning-oriented teacher distribution from the frozen base model through dual-modal intervention that combines visual perturbation with textual in-context unlearning. The resulting intervention-induced distribution serves as a teacher signal for distillation, guiding the student model toward parameter-level unlearning without requiring external teacher models or explicit undesirable response annotations. Experimental results show that VGID achieves strong unlearning effectiveness while preserving competitive model utility, reducing forget set ROUGE-L by 0.371 with only a 0.055 drop in retain set ROUGE-L in a representative setting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce Visual-Noise Guided In-Context Distillation (VGID) for unlearning undesirable knowledge in Multimodal Large Language Models (MLLMs). VGID uses dual-modal intervention (visual perturbation combined with textual in-context unlearning) on the frozen base model to generate a teacher distribution, which is then used to distill knowledge into a student model for parameter-level unlearning without external teachers or labeled data. Experimental results are reported showing a 0.371 reduction in ROUGE-L on the forget set with only a 0.055 drop on the retain set.
Significance. If the results hold, the method offers a training-based unlearning approach for MLLMs that avoids the need for external models or annotations, potentially improving the balance between unlearning effectiveness and model utility compared to existing training-free or training-based methods. This could have implications for privacy and safety in vision-language models.
major comments (2)
- The abstract presents quantitative results (e.g., ROUGE-L reductions of 0.371 and 0.055) but provides no details on methods, datasets, baselines, error bars, or ablation studies, which undermines the ability to verify the support for the central claims.
- The load-bearing assumption that the teacher distribution induced by visual perturbation plus textual in-context intervention on the frozen base model is accurate and stable enough for genuine parameter-level unlearning is not sufficiently validated; the paper should include specific tests or ablations demonstrating that the soft targets reflect desired unlearned behavior rather than noisy or biased outputs.
minor comments (1)
- The phrase 'in a representative setting' is vague and should be clarified with specific experimental conditions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: The abstract presents quantitative results (e.g., ROUGE-L reductions of 0.371 and 0.055) but provides no details on methods, datasets, baselines, error bars, or ablation studies, which undermines the ability to verify the support for the central claims.
Authors: We agree that the abstract is concise and omits methodological and experimental details such as specific datasets, baselines, and error bars. This is standard practice given abstract length constraints, with full details provided in the method and experimental sections of the manuscript. To improve verifiability of the reported numbers, we will revise the abstract to include brief mentions of the primary datasets and evaluation protocol. revision: partial
-
Referee: The load-bearing assumption that the teacher distribution induced by visual perturbation plus textual in-context intervention on the frozen base model is accurate and stable enough for genuine parameter-level unlearning is not sufficiently validated; the paper should include specific tests or ablations demonstrating that the soft targets reflect desired unlearned behavior rather than noisy or biased outputs.
Authors: We appreciate this observation on the core assumption underlying VGID. The current experiments show that the overall framework reduces forget-set performance while preserving retain-set utility, but we concur that direct validation of the intervention-induced teacher distribution would strengthen the claims. In the revised version we will add targeted ablations and analyses, including stability measurements across perturbation strengths and comparisons of the soft targets against expected unlearned behavior. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes VGID as a distillation framework that generates a teacher distribution from the frozen base model via dual-modal interventions (visual perturbation plus textual in-context unlearning) and uses it to guide parameter updates in the student. Reported results consist of empirical ROUGE-L deltas on forget/retain sets, which are external evaluation metrics rather than quantities that reduce by the paper's equations to fitted inputs or self-generated targets. No self-definitional steps, fitted-input predictions, load-bearing self-citations, uniqueness theorems, or ansatzes smuggled via citation are present in the abstract or described method; the derivation chain is therefore self-contained and does not collapse to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Bridging the Copyright Gap: Do Large Vision-Language Models Recognize and Respect Copyrighted Content? , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[2]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Safeeraser: Enhancing safety in multimodal large language models through multimodal machine unlearning , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[3]
Advances in Neural Information Processing Systems , volume=
Single image unlearning: Efficient machine unlearning in multimodal large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[4]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[5]
Qwen3-vl technical report , author=. arXiv preprint arXiv:2511.21631 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
European Conference on Computer Vision , pages=
Mm-safetybench: A benchmark for safety evaluation of multimodal large language models , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[7]
Protecting privacy in multimodal large language models with mllmu-bench , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[8]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Devils in middle layers of large vision-language models: Interpreting, detecting and mitigating object hallucinations via attention lens , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[9]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Reefknot: A comprehensive benchmark for relation hallucination evaluation, analysis and mitigation in multimodal large language models , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[10]
arXiv preprint arXiv:2410.03577 , year=
Look twice before you answer: Memory-space visual retracing for hallucination mitigation in multimodal large language models , author=. arXiv preprint arXiv:2410.03577 , year=
-
[11]
Advances in Neural Information Processing Systems , volume=
Large language model unlearning , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
Negative Preference Optimization: From Catastrophic Collapse to Effective Unlearning
Negative preference optimization: From catastrophic collapse to effective unlearning , author=. arXiv preprint arXiv:2404.05868 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
On effects of steering latent representation for large language model unlearning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[14]
arXiv preprint arXiv:2601.21283 , year=
DUET: Distilled LLM Unlearning from an Efficiently Contextualized Teacher , author=. arXiv preprint arXiv:2601.21283 , year=
-
[15]
arXiv preprint arXiv:2310.07579 , year=
In-context unlearning: Language models as few shot unlearners , author=. arXiv preprint arXiv:2310.07579 , year=
-
[16]
arXiv preprint arXiv:2409.18025 , year=
An adversarial perspective on machine unlearning for ai safety , author=. arXiv preprint arXiv:2409.18025 , year=
-
[17]
Neurips Safe Generative AI Workshop 2024 , year=
Jogging the memory of unlearned llms through targeted relearning attacks , author=. Neurips Safe Generative AI Workshop 2024 , year=
2024
-
[18]
The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
UMU-Bench: Closing the Modality Gap in Multimodal Unlearning Evaluation , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[19]
arXiv preprint arXiv:2503.01854 , year=
A comprehensive survey of machine unlearning techniques for large language models , author=. arXiv preprint arXiv:2503.01854 , year=
-
[20]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution , author=. arXiv preprint arXiv:2409.12191 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Conference on Lifelong Learning Agents , pages=
Continual learning and private unlearning , author=. Conference on Lifelong Learning Agents , pages=. 2022 , organization=
2022
-
[22]
Advances in Neural Information Processing Systems , volume=
Variational bayesian unlearning , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
TOFU: A Task of Fictitious Unlearning for LLMs
Tofu: A task of fictitious unlearning for llms , author=. arXiv preprint arXiv:2401.06121 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Cross-modal unlearning via influential neuron path editing in multimodal large language models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[25]
Distilling the Knowledge in a Neural Network
Distilling the knowledge in a neural network , author=. arXiv preprint arXiv:1503.02531 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
International journal of computer vision , volume=
Knowledge distillation: A survey , author=. International journal of computer vision , volume=. 2021 , publisher=
2021
-
[27]
arXiv preprint arXiv:2406.11285 , year=
Self and cross-model distillation for llms: Effective methods for refusal pattern alignment , author=. arXiv preprint arXiv:2406.11285 , year=
-
[28]
arXiv preprint arXiv:2406.01514 , year=
Decoupled alignment for robust plug-and-play adaptation , author=. arXiv preprint arXiv:2406.01514 , year=
-
[29]
Proceedings of the 33rd ACM SIGSOFT international symposium on software testing and analysis , pages=
Distillseq: A framework for safety alignment testing in large language models using knowledge distillation , author=. Proceedings of the 33rd ACM SIGSOFT international symposium on software testing and analysis , pages=
-
[30]
Proceedings of the AAAI conference on artificial intelligence , volume=
Knowledge distillation from internal representations , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[31]
Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume , pages=
Annealing knowledge distillation , author=. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume , pages=
-
[32]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Revisiting knowledge distillation via label smoothing regularization , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[33]
Undial: Self-distillation with adjusted logits for robust unlearning in large language models , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[34]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Towards efficient machine unlearning with data augmentation: Guided loss-increasing (gli) to prevent the catastrophic model utility drop , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[35]
Advances in Neural Information Processing Systems , volume=
What makes unlearning hard and what to do about it , author=. Advances in Neural Information Processing Systems , volume=
-
[36]
2021 IEEE symposium on security and privacy (SP) , pages=
Machine unlearning , author=. 2021 IEEE symposium on security and privacy (SP) , pages=. 2021 , organization=
2021
-
[37]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Can bad teaching induce forgetting? unlearning in deep networks using an incompetent teacher , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[38]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Clear: Character unlearning in textual and visual modalities , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[39]
arXiv preprint arXiv:2411.03554 , year=
Benchmarking vision language model unlearning via fictitious facial identity dataset , author=. arXiv preprint arXiv:2411.03554 , year=
-
[40]
arXiv preprint arXiv:2310.02238 , year=
Who's Harry Potter? Approximate Unlearning in LLMs , author=. arXiv preprint arXiv:2310.02238 , year=
-
[41]
Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence , pages=
Safety of Multimodal Large Language Models on Images and Text , author=. Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence , pages=
-
[42]
Machine Unlearning: A Comprehensive Survey
Machine unlearning: A comprehensive survey , author=. arXiv preprint arXiv:2405.07406 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
arXiv preprint arXiv:2505.13312 , year=
Guard: Generation-time llm unlearning via adaptive restriction and detection , author=. arXiv preprint arXiv:2505.13312 , year=
-
[44]
ICML 2024 Workshop on Foundation Models in the Wild , year=
Jogging the memory of unlearned models through targeted relearning attacks , author=. ICML 2024 Workshop on Foundation Models in the Wild , year=
2024
-
[45]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
A comprehensive study of jailbreak attack versus defense for large language models , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.