StemBind: When MLLMs Get Lost Between Rules and Instances in Abstract Visual Reasoning
Pith reviewed 2026-06-28 23:14 UTC · model grok-4.3
The pith
MLLMs name the rule in abstract visual puzzles yet still pick the wrong answer more than half the time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
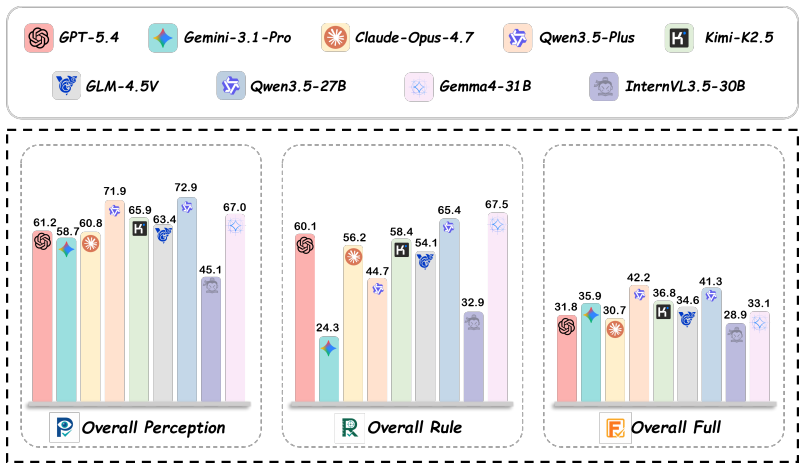
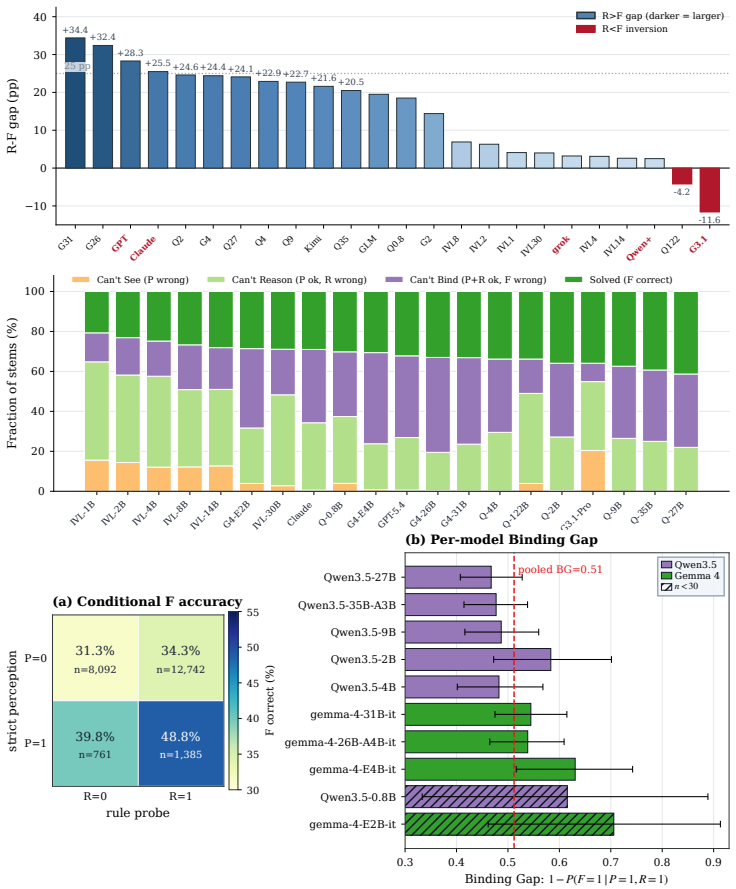
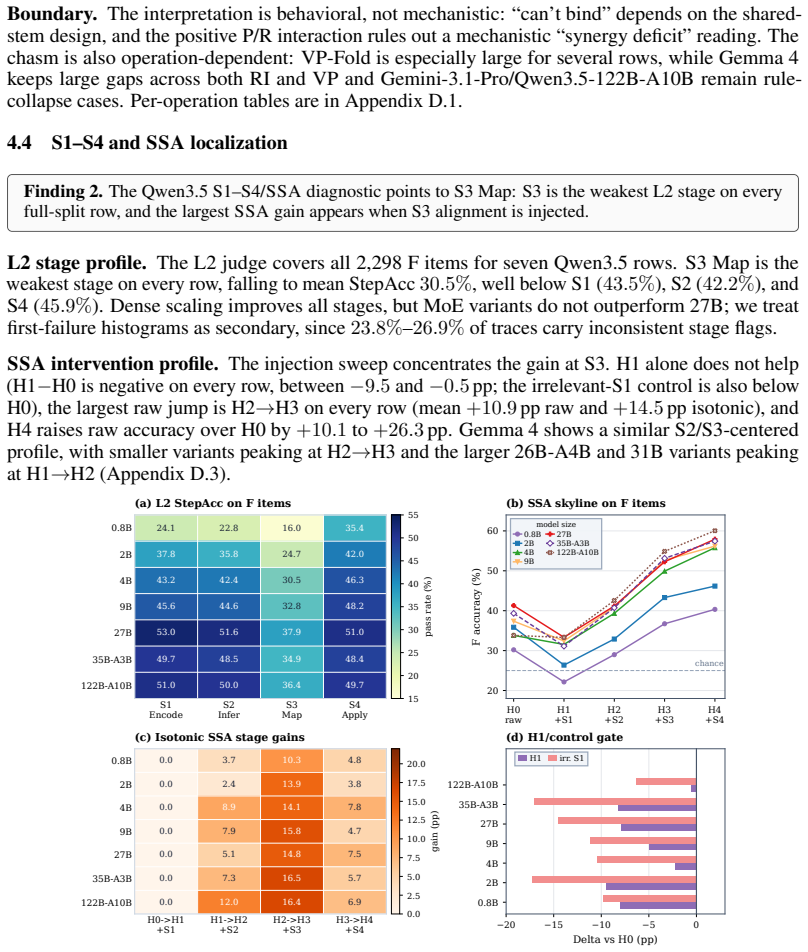
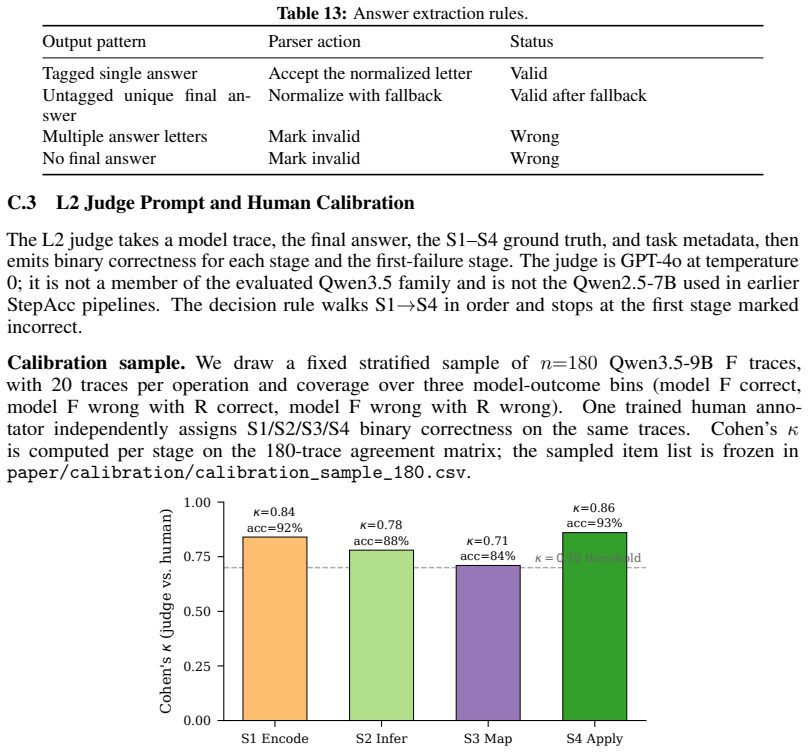
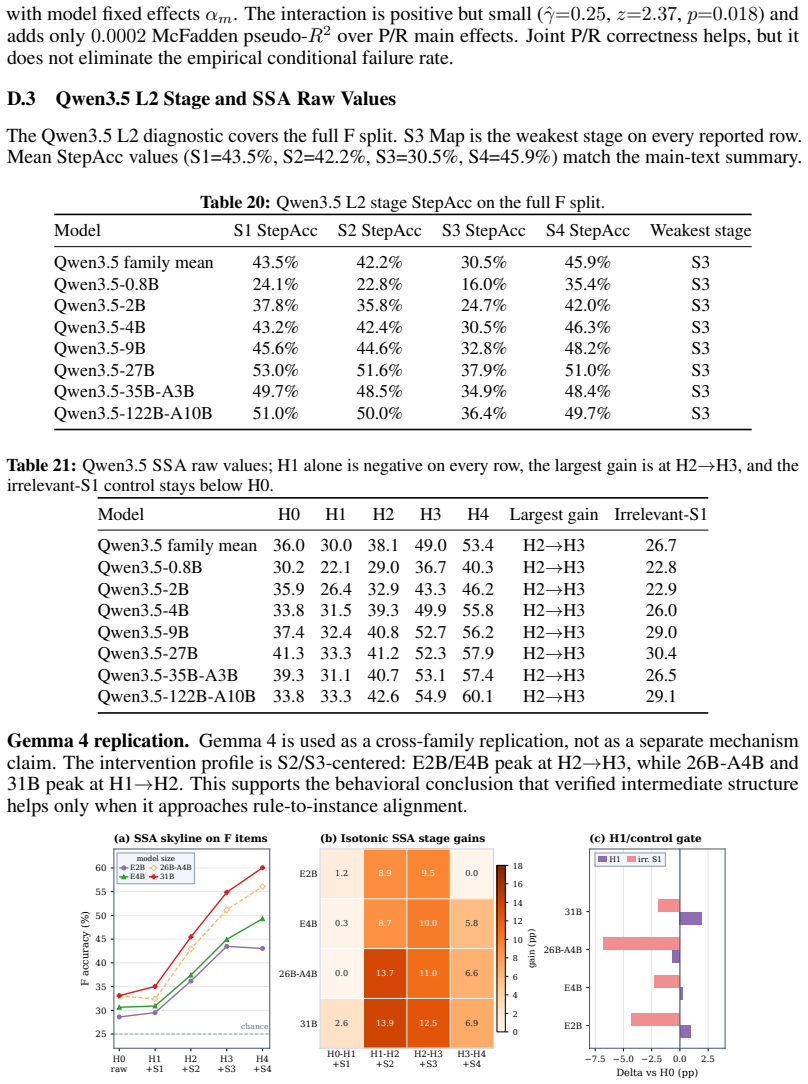
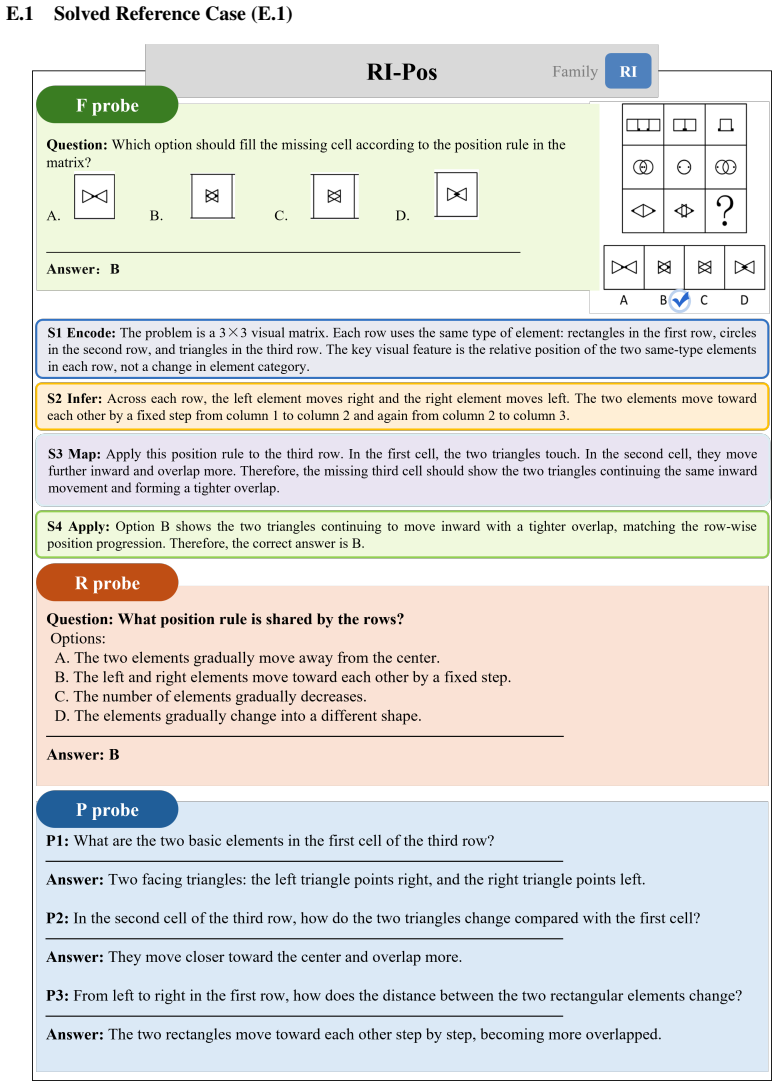
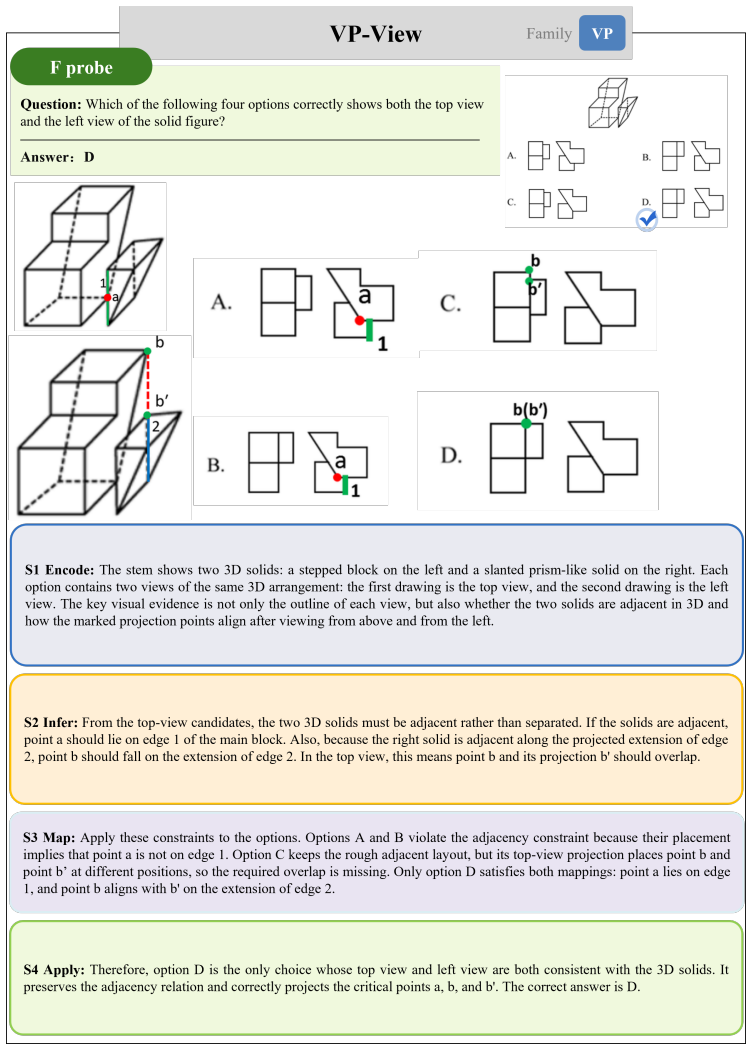
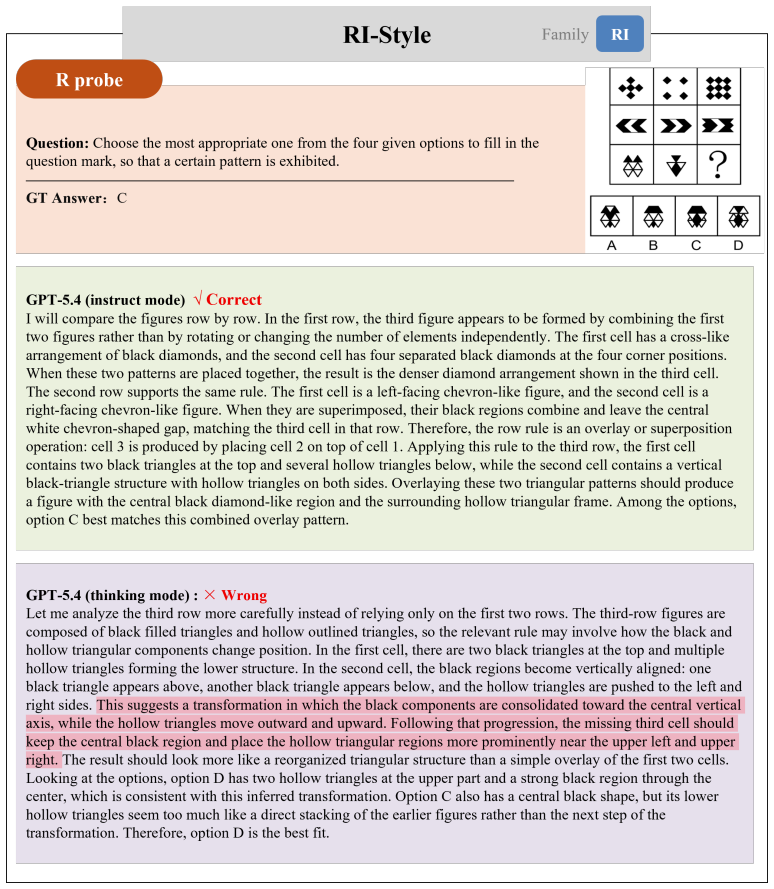
On abstract visual reasoning tasks, multimodal large language models can correctly perceive the image and state the governing rule yet still select the wrong completion because they fail to map the rule onto the specific instances present. StemBind isolates this by running aligned Perception, Rule, and Full questions on identical stems and annotating errors with Sternberg's four stages; it finds that rule accuracy exceeds full accuracy on 22 of 24 models and that even correct perception plus correct rule still yields an incorrect full answer 51.2 percent of the time, with process diagnostics localizing the main failure to stage S3 rule-to-instance mapping.
What carries the argument
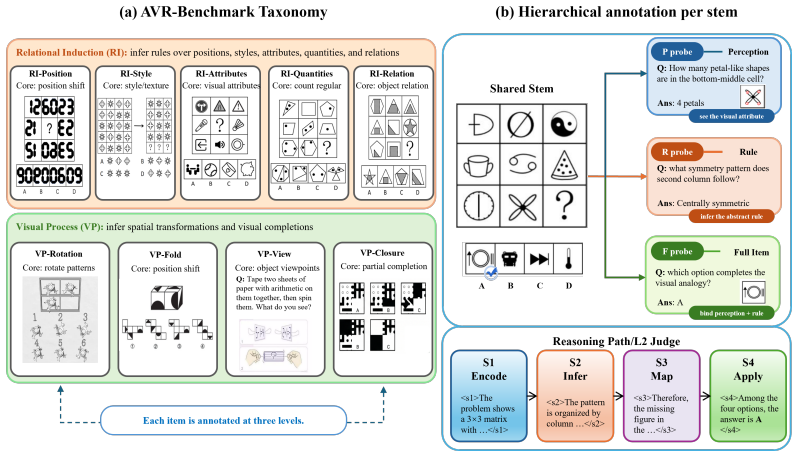
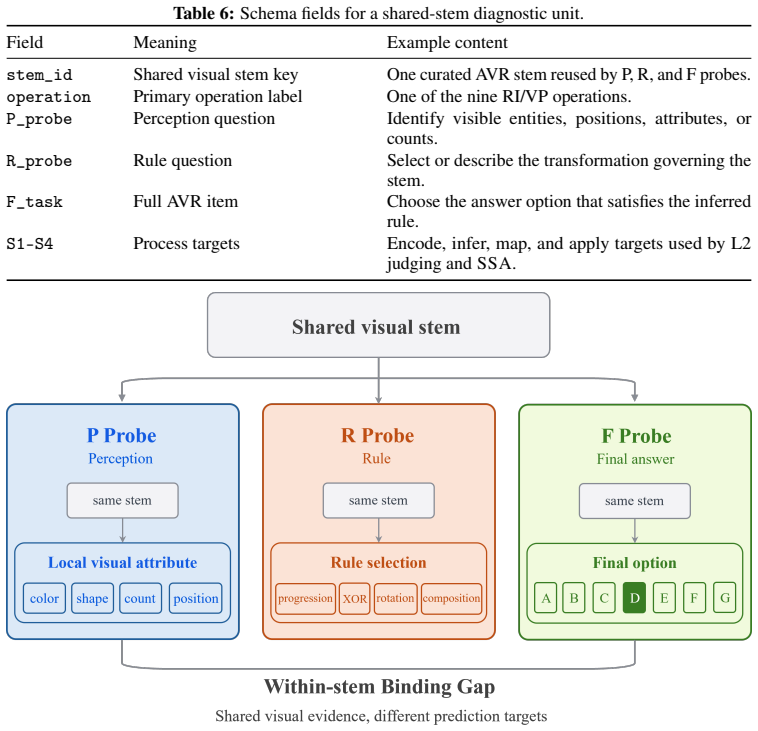
StemBind shared-stem diagnostic benchmark that runs three aligned questions (Perception, Rule, Full) on each visual stem and tags every item with Sternberg's four reasoning stages to attribute final-answer errors to one sub-step.
If this is right
- Rule accuracy exceeds full-item accuracy on 22 of 24 models, so most failures occur after the rule has been identified.
- Even when perception and rule answers are both correct on the same stem, the full answer is still wrong 51.2 percent of the time.
- Stage-wise diagnostics and stimulus augmentation both point to S3 rule-to-instance mapping as the dominant bottleneck.
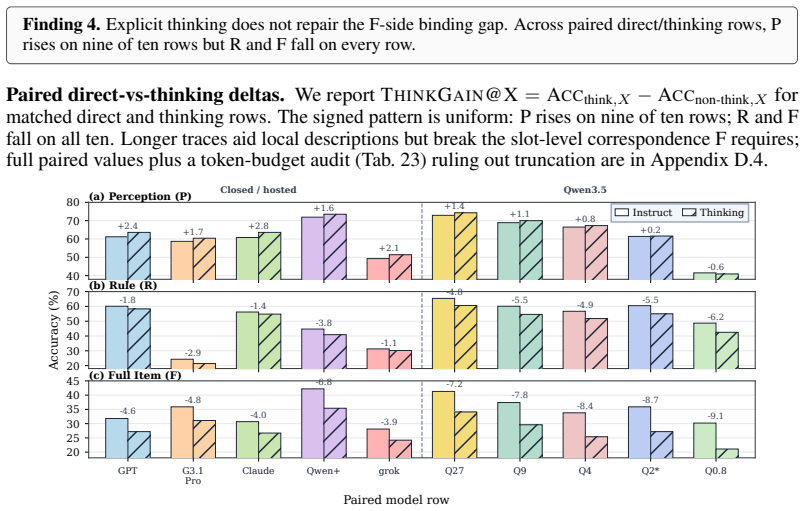
- Neither larger model size nor explicit thinking mode reliably narrows the binding gap and thinking can lower both rule and full accuracy.
Where Pith is reading between the lines
- Training regimes that explicitly supervise the mapping between extracted rules and visual instances could be tested on the same stems to measure gap reduction.
- The same binding failure may limit performance on other tasks that require applying an abstract relation to a new visual scene.
- Extending the benchmark to include explicit mapping supervision examples would allow direct measurement of whether the S3 step is trainable.
Load-bearing premise
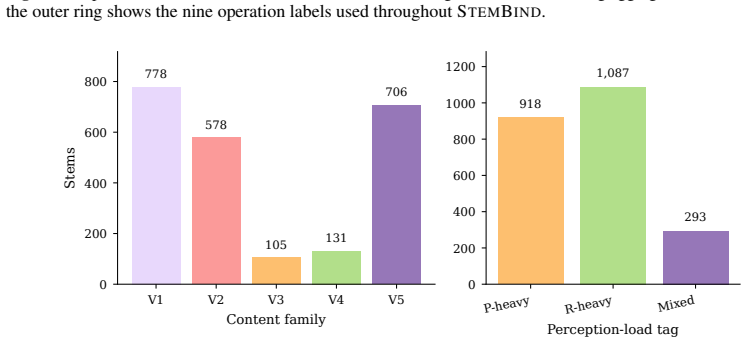
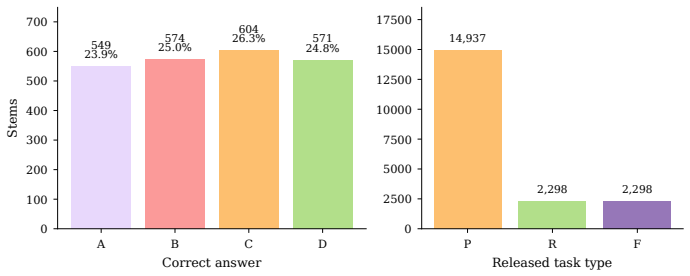
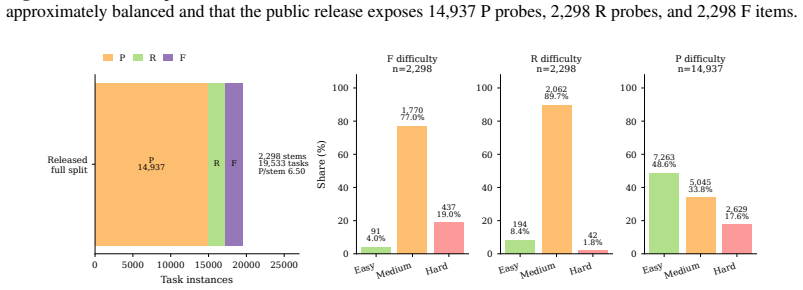
The 2,298 stems are knowledge-light and the three aligned questions allow unambiguous attribution of final-answer errors to a single sub-step on identical visual evidence.
What would settle it
A controlled test in which a model or prompt explicitly trained on rule-to-instance mapping reduces the 51.2 percent full-answer error rate on the same StemBind stems while perception and rule accuracies remain high.
Figures






read the original abstract
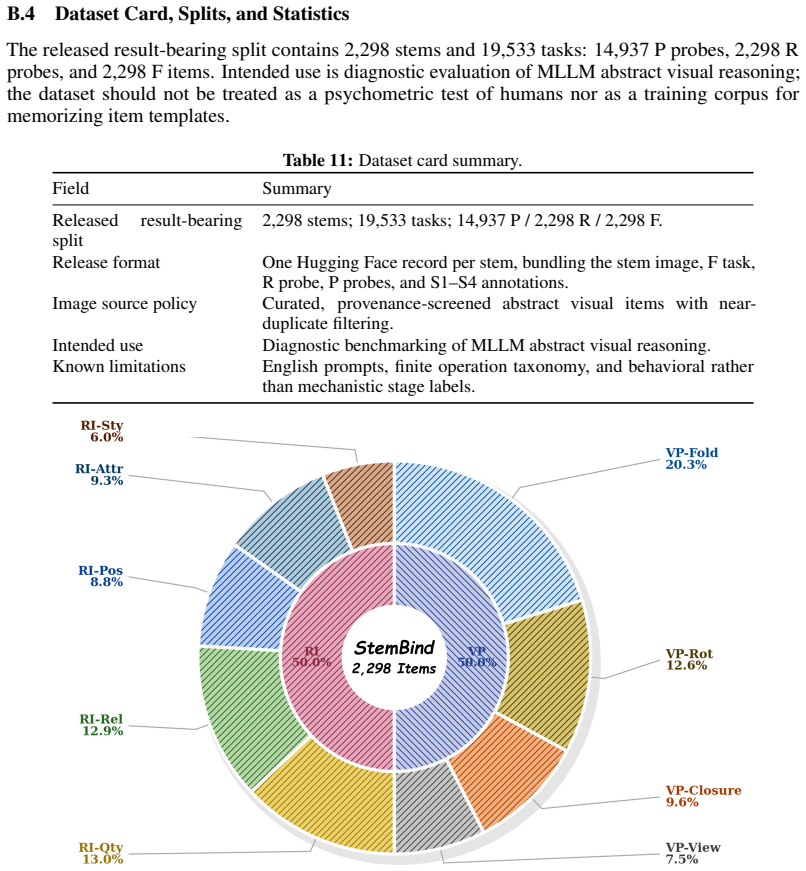
Multimodal large language models (MLLMs) often know the rule but pick the wrong answer: on abstract visual reasoning (AVR) tasks, a model can describe what it sees and name the underlying pattern, yet still fail to choose the matching candidate. Existing AVR benchmarks cannot detect this because they collapse perception, rule induction, and answer selection into a single right-or-wrong signal. We introduce StemBind, a shared-stem diagnostic benchmark that probes the same visual stem with three aligned questions: Perception (what is in the image), Rule (what pattern governs it), and Full (which option completes it), so a final-answer error can be attributed to a specific sub-step on the same evidence. StemBind contains 2,298 curated knowledge-light stems across nine auditable visual operations, totaling 19,533 P/R/F tasks, with each full item annotated by Sternberg's four reasoning stages (S1 Encode, S2 Infer, S3 Map, S4 Apply). Evaluating 24 frontier MLLM configurations yields four findings. (i) The R-F chasm: rule accuracy exceeds full-item accuracy on 22 of 24 models, so most failures happen after the rule is identified. (ii) A persistent binding gap: even when P and R are both correct on the same stem, models still answer F incorrectly 51.2% of the time. (iii) The bottleneck is S3: process diagnostics and Stage-wise Stimulus Augmentation localize the dominant failure to rule-to-instance mapping. (iv) Scaling and thinking do not help: neither larger models nor explicit thinking mode reliably closes the gap, and thinking even lowers rule and full-item accuracy. StemBind reframes AVR evaluation from final-answer ranking to locating where abstract visual reasoning breaks down, identifying rule-to-instance binding as a concrete next target for vision-grounded reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces StemBind, a shared-stem diagnostic benchmark containing 2,298 knowledge-light AVR stems across nine visual operations (19,533 P/R/F tasks total). Each stem is probed with three aligned questions—Perception, Rule, and Full—plus Sternberg stage annotations, allowing final-answer errors to be attributed to specific sub-steps. Evaluation of 24 MLLM configurations reports an R-F chasm (rule accuracy > full accuracy on 22/24 models), a 51.2% binding gap (F incorrect despite correct P and R on the same stem), localization of the dominant failure to S3 (rule-to-instance mapping) via process diagnostics and Stage-wise Stimulus Augmentation, and that neither scale nor explicit thinking reliably closes the gap.
Significance. If the localization holds, StemBind supplies a reproducible, stage-annotated benchmark that shifts AVR evaluation from end-to-end accuracy to concrete bottleneck identification, with the 2,298-stem scale and auditable operations constituting a clear methodological contribution. The empirical measurement of the binding gap on external models (zero free parameters or self-referential definitions) is a strength that could guide targeted improvements in vision-grounded rule application.
major comments (2)
- [§4] §4 (Evaluation) and the binding-gap definition: the central claim that the 51.2% gap localizes failure to S3 assumes that a correct R response on an independent forward pass supplies the same rule representation the model attempts to bind under the F prompt. The manuscript provides no stability check (e.g., rule verbalization consistency or controlled re-prompting on identical stems) to rule out inconsistent retrieval, which directly undermines attribution of F errors to mapping rather than S2/S3 inconsistency.
- [§3.2] §3.2 (Stage-wise Stimulus Augmentation) and process diagnostics: the claim that diagnostics isolate S3 as the bottleneck rests on the premise that P+R correct implies S1 and S2 success on the identical visual evidence; because the three questions are posed separately, the paper must demonstrate that the extracted rule is the one active during F, yet no such verification (e.g., cross-prompt rule equivalence metrics) is reported.
minor comments (2)
- [§3.1] Table 1 or §3.1: the nine visual operations are listed but lack a compact summary table of stem counts per operation and example images; this would improve auditability without altering the central results.
- [Abstract] Abstract and §5: the phrase "knowledge-light" is used repeatedly; a short operational definition or inter-annotator agreement statistic for this property would clarify the claim.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments regarding the attribution of the binding gap to S3. These points correctly identify the need for explicit verification that the rule representation remains consistent across the independent R and F prompts. We address each comment below and will incorporate the suggested checks in the revised manuscript.
read point-by-point responses
-
Referee: [§4] §4 (Evaluation) and the binding-gap definition: the central claim that the 51.2% gap localizes failure to S3 assumes that a correct R response on an independent forward pass supplies the same rule representation the model attempts to bind under the F prompt. The manuscript provides no stability check (e.g., rule verbalization consistency or controlled re-prompting on identical stems) to rule out inconsistent retrieval, which directly undermines attribution of F errors to mapping rather than S2/S3 inconsistency.
Authors: We agree that the absence of an explicit stability analysis leaves open the possibility of retrieval inconsistency between the R and F passes. Our current design conditions the binding gap strictly on stems where both P and R are answered correctly and uses identical visual stems with aligned prompt structures, but this does not fully rule out variability in the internal rule representation. In the revision we will add a stability check: for a subset of stems we will re-prompt the rule question multiple times (with temperature 0 where supported) and report the rate at which the verbalized rule remains semantically equivalent. This analysis will be placed in §4 and will directly support or qualify the S3 localization. revision: yes
-
Referee: [§3.2] §3.2 (Stage-wise Stimulus Augmentation) and process diagnostics: the claim that diagnostics isolate S3 as the bottleneck rests on the premise that P+R correct implies S1 and S2 success on the identical visual evidence; because the three questions are posed separately, the paper must demonstrate that the extracted rule is the one active during F, yet no such verification (e.g., cross-prompt rule equivalence metrics) is reported.
Authors: The referee is correct that separate prompting requires additional evidence that the rule extracted under the R prompt is the same representation engaged during the F prompt. The Stage-wise Stimulus Augmentation experiments provide indirect support by showing that targeted interventions at S3 improve performance while earlier-stage interventions do not, but they do not include a direct equivalence metric. We will add, in the revised §3.2, a cross-prompt rule equivalence analysis: for stems where F is answered correctly we will extract the rule from the F response (via a follow-up probe) and compute semantic similarity to the R response; we will also report the rate at which the model can restate the same rule after completing F. These metrics will be used to strengthen the claim that the dominant failure occurs at the mapping stage. revision: yes
Circularity Check
No circularity: direct empirical measurements on external models via new benchmark
full rationale
The paper constructs StemBind (2,298 stems, 19,533 tasks) and reports accuracy statistics (e.g., 51.2% F-error rate conditional on P+R correct) from evaluations of 24 external MLLM configurations. No equations, fitted parameters, or derivations appear; all claims are direct counts on held-out model outputs. No self-citations are load-bearing for the central attribution, and the benchmark is presented as an independent diagnostic tool rather than a self-referential definition. This matches the default expectation of a non-circular empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Don’t just assume; look and answer: Overcoming priors for visual question answering
Aishwarya Agrawal, Dhruv Batra, Devi Parikh, and Aniruddha Kembhavi. Don’t just assume; look and answer: Overcoming priors for visual question answering. InCVPR, 2018
2018
-
[2]
Introducing claude opus 4.7, 2026
Anthropic. Introducing claude opus 4.7, 2026. URL https://www.anthropic.com/news/ claude-opus-4-7
2026
-
[3]
Measuring abstract reasoning in neural networks
David Barrett, Felix Hill, Adam Santoro, Ari Morcos, and Timothy Lillicrap. Measuring abstract reasoning in neural networks. InICML, 2018
2018
-
[4]
Huanqia Cai, Yijun Yang, and Winston Hu. Mm-iq: Benchmarking human-like abstraction and reasoning in multimodal models.arXiv preprint arXiv:2502.00698, 2025
-
[5]
Zikui Cai, Andrew Wang, Anirudh Satheesh, Ankit Nakhawa, Hyunwoo Jae, Keenan Powell, Minghui Liu, Neel Jay, Sungbin Oh, Xiyao Wang, et al. Morse-500: A programmatically con- trollable video benchmark to stress-test multimodal reasoning.arXiv preprint arXiv:2506.05523, 2025
-
[6]
M3CoT: A novel benchmark for multi-domain multi-step multi-modal chain-of-thought
Qiguang Chen, Libo Qin, Jin Zhang, Zhi Chen, Xiao Xu, and Wanxiang Che. M3CoT: A novel benchmark for multi-domain multi-step multi-modal chain-of-thought. InACL, 2024
2024
-
[7]
OMIBench: Benchmarking Olympiad-Level Multi-Image Reasoning in Large Vision-Language Model
Qiguang Chen, Chengyu Luan, Jiajun Wu, Qiming Yu, Yi Yang, Yizhuo Li, Jingqi Tong, Xiachong Feng, Libo Qin, and Wanxiang Che. Omibench: Benchmarking olympiad-level multi-image reasoning in large vision-language model.arXiv preprint arXiv:2604.20806, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Shuhang Chen, Yunqiu Xu, Junjie Xie, Aojun Lu, Tao Feng, Zeying Huang, Ning Zhang, Yi Sun, Yi Yang, and Hangjie Yuan. Cogflow: Bridging perception and reasoning through knowledge internalization for visual mathematical problem solving.arXiv preprint arXiv:2601.01874, 2026
-
[9]
Ao Cheng, Xingming Li, Xuanyu Ji, Xixiang He, Qiyao Sun, Chunping Qiu, Runke Huang, and Qingyong Hu. Enc-bench: A benchmark for evaluating multimodal large language models in electronic navigational chart understanding.arXiv preprint arXiv:2603.22763, 2026
-
[10]
Fan, Y ., He, X., Yang, D., Zheng, K., Kuo, C.-C., Zheng, Y ., Narayanaraju, S
Zihui Cheng, Qiguang Chen, Xiao Xu, Jiaqi Wang, Weiyun Wang, Hao Fei, Yidong Wang, Alex Jinpeng Wang, Zhi Chen, Wanxiang Che, et al. Visual thoughts: A unified perspective of understanding multimodal chain-of-thought.arXiv preprint arXiv:2505.15510, 2025
-
[11]
Ziming Cheng, Binrui Xu, Lisheng Gong, Zuhe Song, Tianshuo Zhou, Shiqi Zhong, Siyu Ren, Mingxiang Chen, Xiangchao Meng, Yuxin Zhang, et al. Evaluating mllms with multimodal multi-image reasoning benchmark.arXiv preprint arXiv:2506.04280, 2025
-
[12]
Puzzlevqa: Diagnosing multimodal reasoning challenges of language models with abstract visual patterns
Yew Ken Chia, Vernon Toh, Deepanway Ghosal, Lidong Bing, and Soujanya Poria. Puzzlevqa: Diagnosing multimodal reasoning challenges of language models with abstract visual patterns. InFindings of ACL, 2024
2024
-
[13]
On the Measure of Intelligence
François Chollet. On the measure of intelligence.arXiv preprint arXiv:1911.01547, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[14]
Smith, Wei-Chiu Ma, and Ranjay Krishna
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A. Smith, Wei-Chiu Ma, and Ranjay Krishna. BLINK: multimodal large language models can see but not perceive. InECCV, 2024
2024
-
[15]
Wichmann
Robert Geirhos, Jörn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Felix A. Wichmann. Shortcut learning in deep neural networks.Nature Machine Intelligence, 2020
2020
-
[16]
Gemini 3.1 pro model card, 2026
Google DeepMind. Gemini 3.1 pro model card, 2026. URL https://deepmind.google/ models/model-cards/gemini-3-1-pro/
2026
-
[17]
Gemma 4 model card, 2026
Google DeepMind. Gemma 4 model card, 2026. URL https://ai.google.dev/gemma/ docs/core/model_card_4. 10
2026
-
[18]
Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, et al. Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems. InACL, 2024
2024
-
[19]
Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, et al. Glm-4.5v and glm-4.1v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning.arXiv preprint arXiv:2507.01006, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Stratified rule-aware network for abstract visual reasoning
Sheng Hu, Yuqing Ma, Xianglong Liu, Yanlu Wei, and Shihao Bai. Stratified rule-aware network for abstract visual reasoning. InAAAI, 2021
2021
-
[21]
Smith, and Ranjay Krishna
Yushi Hu, Weijia Shi, Xingyu Fu, Dan Roth, Mari Ostendorf, Luke Zettlemoyer, Noah A. Smith, and Ranjay Krishna. Visual sketchpad: Sketching as a visual chain of thought for multimodal language models. InNeurIPS, 2024
2024
-
[22]
Human Cognitive Benchmarks Reveal Foundational Visual Gaps in MLLMs
Jen-Tse Huang, Dasen Dai, Jen-Yuan Huang, Youliang Yuan, Xiaoyuan Liu, Wenxuan Wang, Wenxiang Jiao, Pinjia He, Zhaopeng Tu, and Haodong Duan. Human cognitive benchmarks reveal foundational visual gaps in mllms.arXiv preprint arXiv:2502.16435, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Mantis: Interleaved multi-image instruction tuning.Transactions on Machine Learning Research, 2024
Dongfu Jiang, Xuan He, Huaye Zeng, Cong Wei, Max Ku, Qian Liu, and Wenhu Chen. Mantis: Interleaved multi-image instruction tuning.Transactions on Machine Learning Research, 2024
2024
-
[24]
Mme-cot: Benchmarking chain-of-thought in large multimodal models for reasoning quality, robustness, and efficiency
Dongzhi Jiang, Renrui Zhang, Ziyu Guo, Yanwei Li, Yu Qi, Xinyan Chen, Liuhui Wang, Jianhan Jin, Claire Guo, Shen Yan, et al. Mme-cot: Benchmarking chain-of-thought in large multimodal models for reasoning quality, robustness, and efficiency. InICML, 2025
2025
-
[25]
Beyond perception: Evaluating abstract visual reasoning through multi-stage task
Yanbei Jiang, Yihao Ding, Chao Lei, Jiayang Ao, Jey Han Lau, and Krista A Ehinger. Beyond perception: Evaluating abstract visual reasoning through multi-stage task. InFindings of ACL, 2025
2025
-
[26]
MARVEL: multidimensional abstraction and reasoning through visual evaluation and learning
Yifan Jiang, Jiarui Zhang, Kexuan Sun, Zhivar Sourati, Kian Ahrabian, Kaixin Ma, Filip Ilievski, and Jay Pujara. MARVEL: multidimensional abstraction and reasoning through visual evaluation and learning. InNeurIPS, 2024
2024
-
[27]
Remi: A dataset for reasoning with multiple images
Mehran Kazemi, Nishanth Dikkala, Ankit Anand, Petar Devic, Ishita Dasgupta, Fangyu Liu, Bahare Fatemi, Pranjal Awasthi, Sreenivas Gollapudi, Dee Guo, and Ahmed Qureshi. Remi: A dataset for reasoning with multiple images. InNeurIPS, 2024
2024
-
[28]
Vriq: Benchmarking and analyzing visual-reasoning iq of vlms.arXiv preprint arXiv:2602.05382, 2026
Tina Khezresmaeilzadeh, Jike Zhong, and Konstantinos Psounis. Vriq: Benchmarking and analyzing visual-reasoning iq of vlms.arXiv preprint arXiv:2602.05382, 2026
-
[29]
Mibench: Evaluating multimodal large language models over multiple images
Haowei Liu, Xi Zhang, Haiyang Xu, Yaya Shi, Chaoya Jiang, Ming Yan, Ji Zhang, Fei Huang, Chunfeng Yuan, Bing Li, et al. Mibench: Evaluating multimodal large language models over multiple images. InEMNLP, 2024
2024
-
[30]
Learn to explain: Multimodal reasoning via thought chains for science question answering
Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering. InNeurIPS, 2022
2022
-
[31]
Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts. InICLR, 2024
2024
-
[32]
Kevin S. McGrew. Chc theory and the human cognitive abilities project: Standing on the shoulders of the giants of psychometric intelligence research.Intelligence, 37(1):1–10, 2009. doi: https://doi.org/10.1016/j.intell.2008.08.004
-
[33]
MMIU: multimodal multi-image understanding for evaluating large vision-language models
Fanqing Meng, Jin Wang, Chuanhao Li, Quanfeng Lu, Hao Tian, Tianshuo Yang, Jiaqi Liao, Xizhou Zhu, Jifeng Dai, Yu Qiao, Ping Luo, Kaipeng Zhang, and Wenqi Shao. MMIU: multimodal multi-image understanding for evaluating large vision-language models. InICLR, 2025. 11
2025
-
[34]
Arseny Moskvichev, Victor Vikram Odouard, and Melanie Mitchell. The conceptarc bench- mark: Evaluating understanding and generalization in the arc domain.arXiv preprint arXiv:2305.07141, 2023
-
[35]
Patel, Yuke Zhu, and Anima Anandkumar
Weili Nie, Zhiding Yu, Lei Mao, Ankit B. Patel, Yuke Zhu, and Anima Anandkumar. Bongard- logo: A new benchmark for human-level concept learning and reasoning. InNeurIPS, 2020
2020
-
[36]
OpenAI. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Gpt-5.4 thinking system card, 2026
OpenAI. Gpt-5.4 thinking system card, 2026. URL https://openai.com/index/ gpt-5-4-thinking-system-card/. Accessed: 2026-05-06
2026
-
[38]
Cambridge university press, 2009
Judea Pearl.Causality. Cambridge university press, 2009
2009
-
[39]
Tan-Hanh Pham, Phu-Vinh Nguyen, Dang The Hung, Bui Trong Duong, Vu Nguyen Thanh, Chris Ngo, Tri Quang Truong, and Truong-Son Hy. Iqbench: How" smart”are vision-language models? a study with human iq tests.arXiv preprint arXiv:2505.12000, 2025
-
[40]
Qwen3.5: Towards native multimodal agents, 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, 2026. URL https://qwen.ai/ blog?id=qwen3.5
2026
-
[41]
Donald B. Rubin. Estimating causal effects of treatments in randomized and nonrandomized studies.Journal of Educational Psychology, 1974
1974
-
[42]
The cattell-horn-carroll model of intelligence
W Joel Schneider and Kevin S McGrew. The cattell-horn-carroll model of intelligence. 2012
2012
-
[43]
Wei Song, Yadong Li, Jianhua Xu, Guowei Wu, Lingfeng Ming, Kexin Yi, Weihua Luo, Houyi Li, Yi Du, Fangda Guo, et al. M3gia: A cognition inspired multilingual and multimodal general intelligence ability benchmark.arXiv preprint arXiv:2406.05343, 2024
-
[44]
Yueqi Song, Tianyue Ou, Yibo Kong, Zecheng Li, Graham Neubig, and Xiang Yue. Visualpuz- zles: Decoupling multimodal reasoning evaluation from domain knowledge.arXiv preprint arXiv:2504.10342, 2025
-
[45]
Intelligence, information processing, and analogical reasoning: The componential analysis of human abilities, 1977
RJ Sternberg. Intelligence, information processing, and analogical reasoning: The componential analysis of human abilities, 1977
1977
-
[46]
Thinking with Images for Multimodal Reasoning: Foundations, Methods, and Future Frontiers
Zhaochen Su, Peng Xia, Hangyu Guo, Zhenhua Liu, Yan Ma, Xiaoye Qu, Jiaqi Liu, Yanshu Li, Kaide Zeng, Zhengyuan Yang, et al. Thinking with images for multimodal reasoning: Foundations, methods, and future frontiers.arXiv preprint arXiv:2506.23918, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Mm-math: Advancing multimodal math evaluation with process evaluation and fine-grained classification
Kai Sun, Yushi Bai, Ji Qi, Lei Hou, and Juanzi Li. Mm-math: Advancing multimodal math evaluation with process evaluation and fine-grained classification. InFindings of EMNLP, 2024
2024
-
[48]
Kimi K2.5: Visual Agentic Intelligence
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. Kimi k2.5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[49]
Lê Khac, Ankit Singh, Sofian Chaybouti, and Sanath Narayan
Brigitta Malagurski Törtei, Yasser Dahou, Ngoc Dung Huynh, Wamiq Reyaz Para, Phúc H. Lê Khac, Ankit Singh, Sofian Chaybouti, and Sanath Narayan. Visres bench: On evaluating the visual reasoning capabilities of vlms.arXiv preprint arXiv:2512.21194, 2025
-
[50]
Huang, Zekun Li, Qin Liu, Xiaogeng Liu, Mingyu Derek Ma, Nan Xu, Wenxuan Zhou, Kai Zhang, et al
Fei Wang, Xingyu Fu, James Y . Huang, Zekun Li, Qin Liu, Xiaogeng Liu, Mingyu Derek Ma, Nan Xu, Wenxuan Zhou, Kai Zhang, et al. Muirbench: A comprehensive benchmark for robust multi-image understanding. InICLR, 2025
2025
-
[51]
Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models
Lei Wang, Wanyu Xu, Yihuai Lan, Zhiqiang Hu, Yunshi Lan, Roy Ka-Wei Lee, and Ee-Peng Lim. Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models. InACL, 2023
2023
-
[52]
Spatialviz-bench: A cognitively-grounded benchmark for diagnosing spatial visualization in mllms
Siting Wang, Minnan Pei, Luoyang Sun, Cheng Deng, Yuchen Li, Kun Shao, Zheng Tian, Haifeng Zhang, and Jun Wang. Spatialviz-bench: A cognitively-grounded benchmark for diagnosing spatial visualization in mllms. InICLR, 2025. 12
2025
-
[53]
Weiyun Wang, Zhangwei Gao, Lianjie Chen, Zhe Chen, Jinguo Zhu, Xiangyu Zhao, Yangzhou Liu, Yue Cao, Shenglong Ye, Xizhou Zhu, et al. Visualprm: An effective process reward model for multimodal reasoning.arXiv preprint arXiv:2503.10291, 2025
-
[54]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Mementos: A comprehensive benchmark for multimodal large language model reasoning over image sequences
Xiyao Wang, Yuhang Zhou, Xiaoyu Liu, Hongjin Lu, Yuancheng Xu, Feihong He, Jaehong Yoon, Taixi Lu, Fuxiao Liu, Gedas Bertasius, et al. Mementos: A comprehensive benchmark for multimodal large language model reasoning over image sequences. InACL, 2024
2024
-
[56]
Slow perception: Let’s perceive geometric figures step-by-step.arXiv preprint arXiv:2412.20631, 2024
Haoran Wei, Youyang Yin, Yumeng Li, Jia Wang, Liang Zhao, Jianjian Sun, Zheng Ge, Xiangyu Zhang, and Daxin Jiang. Slow perception: Let’s perceive geometric figures step-by-step.arXiv preprint arXiv:2412.20631, 2024
-
[57]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. NeurIPS, 2022
2022
-
[58]
Weiye Xu, Jiahao Wang, Weiyun Wang, Zhe Chen, Wengang Zhou, Aijun Yang, Lewei Lu, Houqiang Li, Xiaohua Wang, Xizhou Zhu, et al. Visulogic: A benchmark for evaluating visual reasoning in multi-modal large language models.arXiv preprint arXiv:2504.15279, 2025
-
[59]
Mc-bench: A benchmark for multi-context visual grounding in the era of mllms
Yunqiu Xu, Linchao Zhu, and Yi Yang. Mc-bench: A benchmark for multi-context visual grounding in the era of mllms. InICCV, 2025
2025
-
[60]
Hao Yan, Xingchen Liu, Hao Wang, Zhenbiao Cao, Handong Zheng, Liang Yin, Xinxing Su, Zihao Chen, Jihao Wu, Minghui Liao, et al. Visuriddles: Fine-grained perception is a primary bottleneck for multimodal large language models in abstract visual reasoning.arXiv preprint arXiv:2506.02537, 2025
-
[61]
LENS: Multi-level Evaluation of Multimodal Reasoning with Large Language Models
Ruilin Yao, Bo Zhang, Jirui Huang, Xinwei Long, Yifang Zhang, Tianyu Zou, Yufei Wu, Shichao Su, Yifan Xu, Wenxi Zeng, et al. Lens: Multi-level evaluation of multimodal reasoning with large language models.arXiv preprint arXiv:2505.15616, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. InCVPR, 2024
2024
-
[63]
Raven: A dataset for relational and analogical visual reasoning
Chi Zhang, Feng Gao, Baoxiong Jia, Yixin Zhu, and Song-Chun Zhu. Raven: A dataset for relational and analogical visual reasoning. InCVPR, 2019
2019
-
[64]
Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems? InECCV, 2024
Renrui Zhang, Dongzhi Jiang, Yichi Zhang, Haokun Lin, Ziyu Guo, Pengshuo Qiu, Aojun Zhou, Pan Lu, Kai-Wei Chang, Yu Qiao, et al. Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems? InECCV, 2024
2024
-
[65]
AdaptMMBench: Benchmarking Adaptive Multimodal Reasoning for Mode Selection and Reasoning Process
Xintong Zhang, Xiaowen Zhang, Jongrong Wu, Zhi Gao, Shilin Yan, Zhenxin Diao, Kunpeng Gao, Xuanyan Chen, Yuwei Wu, Yunde Jia, and Qing Li. Adaptmmbench: Benchmarking adaptive multimodal reasoning for mode selection and reasoning process.arXiv preprint arXiv:2602.02676, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[66]
Bingchen Zhao, Yongshuo Zong, Letian Zhang, and Timothy Hospedales. Benchmarking multi-image understanding in vision and language models: Perception, knowledge, reasoning, and multi-hop reasoning.arXiv preprint arXiv:2406.12742, 2024
-
[67]
synergy deficit
Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc Le, et al. Least-to-most prompting enables complex reasoning in large language models. InICLR, 2023. 13 Appendix for STEMBIND When MLLMs Get Lost Between Rules and Instances in Abstract Visual Reasoning A Benchmark Specificatio...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.