MyoSem: Aligning Electromyography to Natural-Language Action Semantics for Hand Action Understanding
Pith reviewed 2026-06-28 22:39 UTC · model grok-4.3
The pith
MyoSem maps EMG signals to a shared semantic space from action descriptions for bidirectional retrieval between muscle signals and text.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
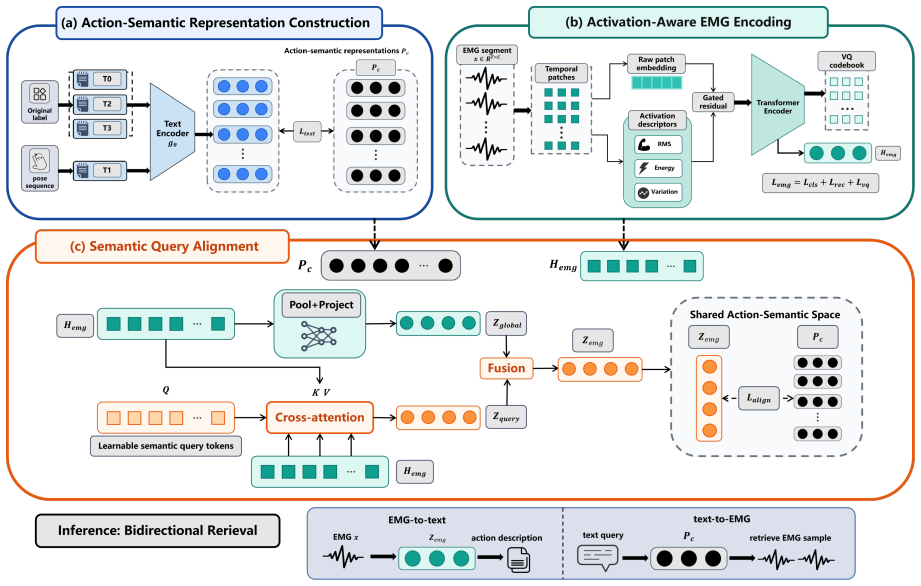
MyoSem performs well on EMG-text bidirectional retrieval, generally outperforms most baselines, and shows favorable generalization to unseen users, held-out action classes, and amputee-user transfer scenarios by combining multi-view action-semantic construction, activation-aware EMG encoding, and semantic query alignment to map low-level EMG signals into a shared semantic space.
What carries the argument
EMG-action semantic alignment framework that maps signals into a shared space built from multi-view action descriptions using construction, activation-aware encoding, and query alignment.
If this is right
- EMG recordings can be queried using natural-language action descriptions instead of fixed class labels.
- The same model supports retrieval in both directions without separate training.
- Performance holds for users and action classes not seen in training.
- Transfer is possible from non-amputee to amputee EMG data.
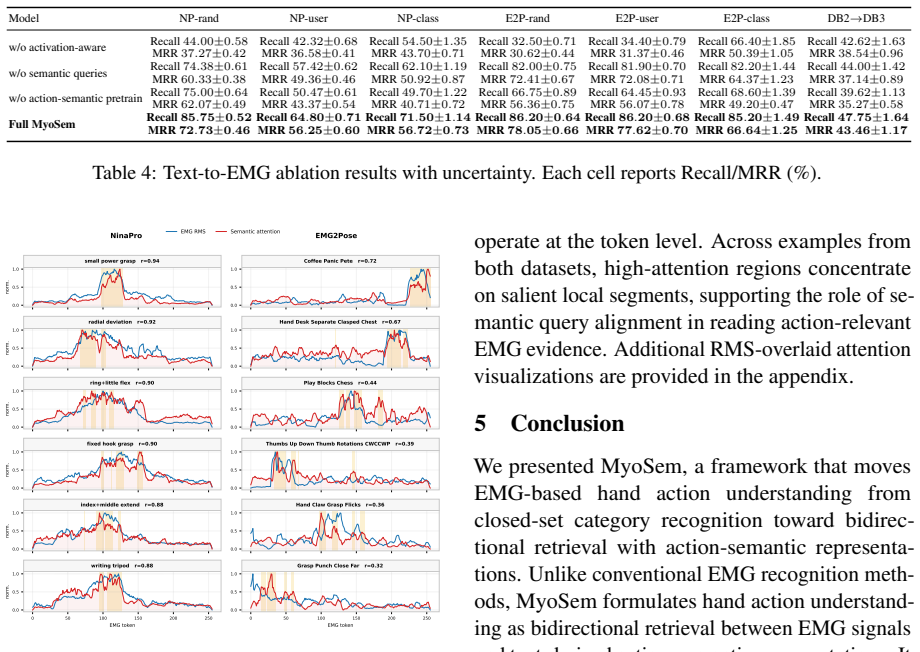
- Each component of the alignment contributes measurably as shown by ablations.
Where Pith is reading between the lines
- Language could serve as a more flexible interface for prosthetic control or wearable devices.
- The semantic space might accept inputs from additional sensing modalities beyond EMG.
- Real-time systems could use the alignment to translate ongoing muscle activity into descriptive feedback.
Load-bearing premise
EMG signals contain enough information about action semantics to be mapped into the shared space while preserving details needed for accurate retrieval and generalization.
What would settle it
Bidirectional retrieval accuracy on EMG2Pose or NinaPro datasets dropping to chance levels or below non-alignment baselines when tested on held-out users or classes.
Figures


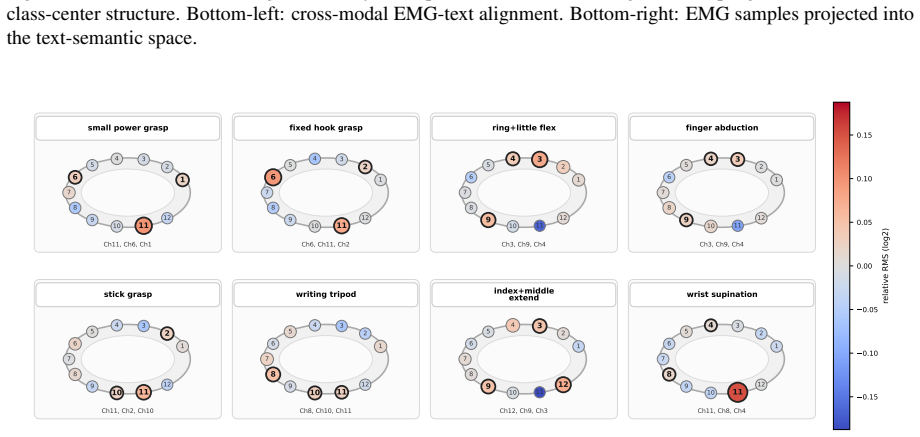
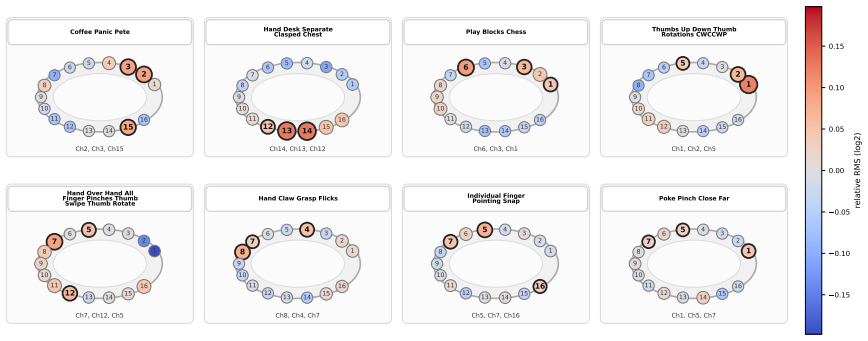
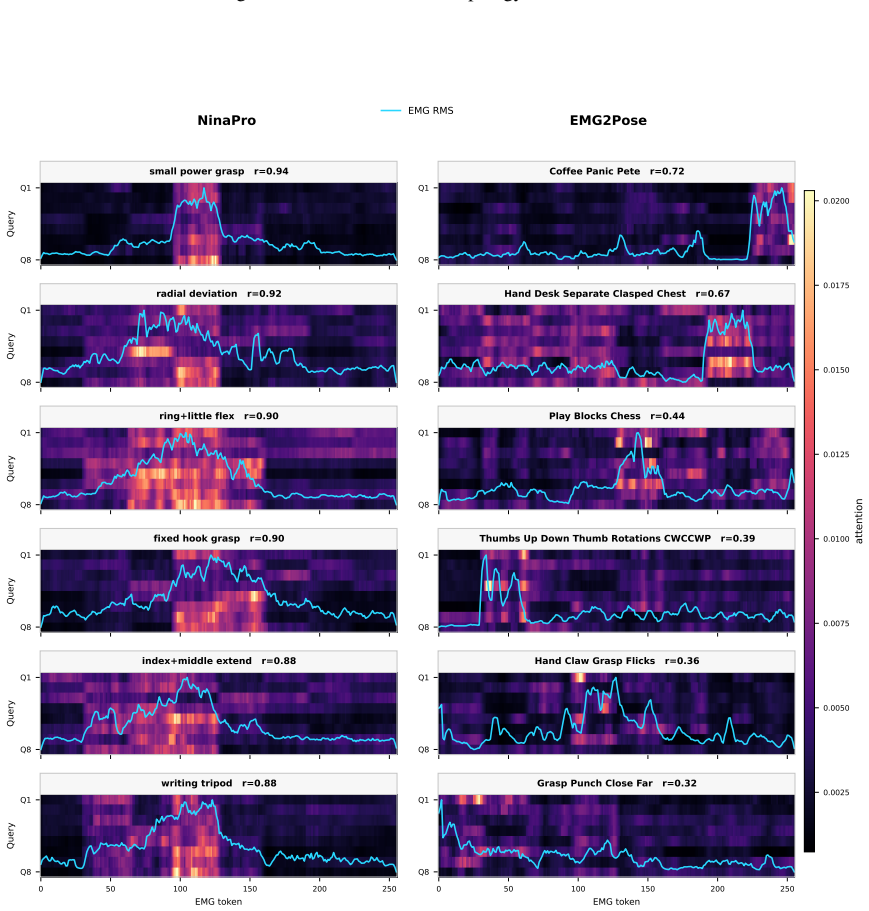
read the original abstract
Electromyography (EMG) directly reflects muscle activation and is a key sensing modality for gesture recognition, prosthetic control, and wearable interaction. Existing EMG methods, however, commonly formulate hand action understanding as classification over fixed labels, making it difficult to support querying, retrieval, and generalization based on action descriptions. We present MyoSem, an EMG--action semantic alignment framework that maps low-level EMG signals into a shared semantic space constructed from multi-view action descriptions. MyoSem combines multi-view action-semantic construction, activation-aware EMG encoding, and semantic query alignment, enabling bidirectional retrieval between EMG signals and text descriptions. We systematically evaluate MyoSem on EMG2Pose and NinaPro-series datasets. Results show that MyoSem performs well on EMG--text bidirectional retrieval, generally outperforms most baselines, and shows favorable generalization to unseen users, held-out action classes, and amputee-user transfer scenarios. Ablations and visualizations further validate the effectiveness of each module. Overall, MyoSem advances EMG-based hand action understanding from fixed-label recognition toward queryable bidirectional semantic retrieval, providing a new modeling paradigm for language-mediated EMG action understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MyoSem, a framework for aligning EMG signals with natural-language action semantics via multi-view action-semantic construction, activation-aware EMG encoding, and semantic query alignment. This enables bidirectional EMG-text retrieval. The work evaluates the approach on the EMG2Pose and NinaPro-series datasets and claims strong performance on retrieval tasks along with favorable generalization to unseen users, held-out action classes, and amputee-user transfer scenarios.
Significance. If the quantitative results and ablations hold, the shift from fixed-label EMG classification to queryable bidirectional semantic retrieval would be a meaningful advance for prosthetic control and wearable interaction. The multi-view semantic space construction and activation-aware encoder represent a concrete modeling contribution that could support language-mediated EMG applications.
major comments (2)
- [Abstract, §4] Abstract and §4 (Evaluation): The central claims of outperforming baselines and favorable generalization (including amputee transfer) are stated without any numerical metrics, baseline names, error bars, or statistical details. This prevents verification that the data support the claims of bidirectional retrieval accuracy and cross-domain robustness.
- [Abstract, §5] Abstract and §5 (Ablations/Transfer Experiments): The amputee-user transfer result rests on the untested assumption that the learned semantic alignment is invariant to domain shift (altered muscle recruitment and signal characteristics). No description is given of explicit regularization, domain-adversarial training, or controlled comparisons that would isolate semantic robustness from dataset-specific overlap or small sample effects.
minor comments (1)
- [Abstract] The abstract would benefit from a single sentence summarizing the key quantitative result (e.g., retrieval mAP or accuracy) to allow readers to gauge the strength of the claims immediately.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Evaluation): The central claims of outperforming baselines and favorable generalization (including amputee transfer) are stated without any numerical metrics, baseline names, error bars, or statistical details. This prevents verification that the data support the claims of bidirectional retrieval accuracy and cross-domain robustness.
Authors: We agree that the abstract summarizes results qualitatively. Section 4 of the manuscript contains the full quantitative results with metrics, baseline names, error bars, and comparisons. To address the concern, we will revise the abstract to include key numerical highlights (e.g., retrieval accuracies and generalization metrics) while respecting length constraints. revision: yes
-
Referee: [Abstract, §5] Abstract and §5 (Ablations/Transfer Experiments): The amputee-user transfer result rests on the untested assumption that the learned semantic alignment is invariant to domain shift (altered muscle recruitment and signal characteristics). No description is given of explicit regularization, domain-adversarial training, or controlled comparisons that would isolate semantic robustness from dataset-specific overlap or small sample effects.
Authors: The amputee transfer results are empirical demonstrations on available data. The framework uses semantic alignment for robustness rather than explicit domain-adversarial methods. We will expand Section 5 to discuss the assumptions, potential dataset overlap effects, and limitations of the transfer experiments. revision: partial
Circularity Check
No circularity: framework is a standard learned alignment without self-referential derivations
full rationale
The paper presents MyoSem as an EMG-text alignment framework using multi-view semantic construction, activation-aware encoding, and query alignment. The abstract and description contain no equations, no fitted parameters renamed as predictions, and no self-citation chains that bear the central claims. Generalization results (including amputee transfer) are presented as empirical outcomes on specific datasets rather than derived by construction from the model definition itself. The derivation chain is therefore self-contained against external benchmarks and does not reduce to its inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption EMG signals directly reflect muscle activation
- domain assumption Multi-view action descriptions can be used to construct a usable shared semantic space
Reference graph
Works this paper leans on
-
[1]
Biao Jiang, Xin Chen, Wen Liu, Jingyi Yu, Gang Yu, and Tao Chen
A new strategy for multifunction myoelectric control.IEEE Transactions on Biomedical Engineer- ing, 40(1):82–94. Biao Jiang, Xin Chen, Wen Liu, Jingyi Yu, Gang Yu, and Tao Chen. 2023. MotionGPT: Human motion as a foreign language. InAdvances in Neural Information Processing Systems. Wei-Bang Jiang, Li-Ming Zhao, and Bao-Liang Lu
2023
-
[2]
LaBraM: Large brain model for learning generic representations with tremendous EEG data in BCI.Preprint, arXiv:2405.18765. Jiarui Jin, Haoyu Wang, Hongyan Li, Jun Li, Jiahui Pan, and Shenda Hong. 2025. Reading your heart: Learn- ing ECG words and sentences via pre-training ECG language model. InThe Thirteenth International Conference on Learning Represent...
-
[3]
emg2pose: A large and diverse benchmark for surface electromyographic hand pose estimation. Preprint, arXiv:2412.02725. NeurIPS 2024 Datasets and Benchmarks Track. Mike Schuster and Kuldip K. Paliwal. 1997. Bidirec- tional recurrent neural networks.IEEE Transactions on Signal Processing, 45(11):2673–2681. Ziwei Shan, Yaoyu He, Chengfeng Zhao, Jiashen Du, ...
-
[4]
Chinese clip: Contrastive vision-language pretraining in chinese,
A novel SE-CNN attention architecture for sEMG-based hand gesture recognition.Computer Modeling in Engineering & Sciences, 134(1):157– 177. Hua Yan, Heng Tan, Yi Ding, Pengfei Zhou, Vinod Namboodiri, and Yu Yang. 2025. Large language model-guided semantic alignment for human activity recognition.Proceedings of the ACM on Interac- tive, Mobile, Wearable an...
-
[5]
InAdvances in Neural Informa- tion Processing Systems
BIOT: Biosignal transformer for cross-data learning in the wild. InAdvances in Neural Informa- tion Processing Systems. Jehan Yang, Maxwell Soh, Vivianna Lieu, Dou- glas J. Weber, and Zackory Erickson. 2024. EMG- Bench: Benchmarking out-of-distribution generaliza- tion and adaptation for electromyography.Preprint, arXiv:2410.23625. Lin Yuan, Zhen He, Qian...
-
[6]
Ali Heydari, Girish Narayanswamy, Maxwell A
SensorLM: Learning the language of wearable sensors.Preprint, arXiv:2506.09108. Wentao Zhu, Xiaoxuan Ma, Zhaoyang Liu, Libin Liu, Wayne Wu, and Yizhou Wang. 2023. MotionBERT: A unified perspective on learning human motion rep- resentations. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision, pages 15085–15099. A Experimental Detai...
-
[7]
finger adduction 0.12 EMG -> Text GT: screwdriver gr
-
[8]
screwdriver gr... 0.36
-
[9]
grasp 0.18
index ext. grasp 0.18
-
[10]
0.18 EMG -> Text GT: index pointing
open bottle... 0.18 EMG -> Text GT: index pointing
-
[11]
index+middle e... 0.05
-
[12]
thumb up 0.04 EMG -> Text GT: thumb up
-
[13]
index pointing 0.07 Text -> EMG Query: index pointing
-
[14]
index pointing Text -> EMG Query: wrist flex
-
[15]
Text -> EMG Query: sphere power
wrist flex. Text -> EMG Query: sphere power
-
[16]
medium wrap Text -> EMG Query: lateral grasp
-
[17]
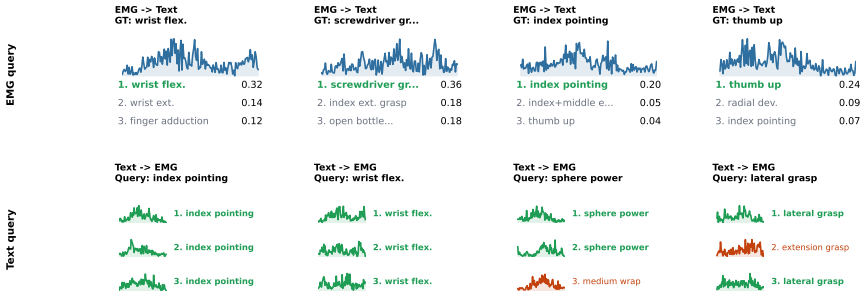
The top row shows EMG-to-text retrieval, and the bottom row shows text-to-EMG retrieval
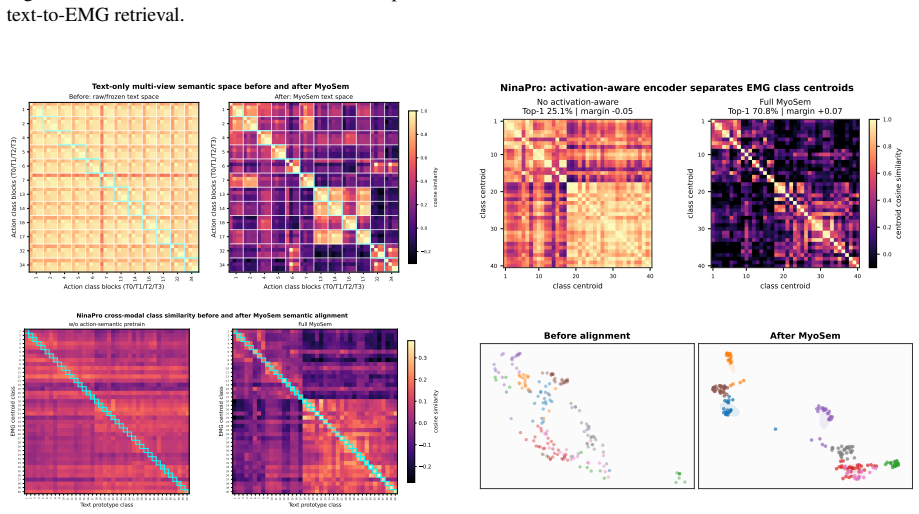
lateral grasp EMG queryText query Figure 5: Bidirectional retrieval cases. The top row shows EMG-to-text retrieval, and the bottom row shows text-to-EMG retrieval. 1 2 4 5 6 7 13 14 16 17 32 34 Action class blocks (T0/T1/T2/T3) 1 2 4 5 6 7 13 14 16 17 32 34 Action class blocks (T0/T1/T2/T3) Before: raw/frozen text space 1 2 4 5 6 7 13 14 16 17 32 34 Actio...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.