How to Compare the Security of Code Written by Humans to LLM-generated Code
Pith reviewed 2026-06-28 21:34 UTC · model grok-4.3
The pith
The paper proposes an automated framework for reproducible, species-fair comparisons of code security across human-only, LLM-only, and hybrid conditions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that an automated framework which logs prompts, timing, and experimental settings, then applies multi-dimensional static and dynamic quality analysis, makes it possible to conduct reproducible comparisons of security properties in code from human-only, LLM-only, and hybrid conditions, supported by an open-source implementation and a feasibility study that provides a blueprint for species-fair experiments.
What carries the argument
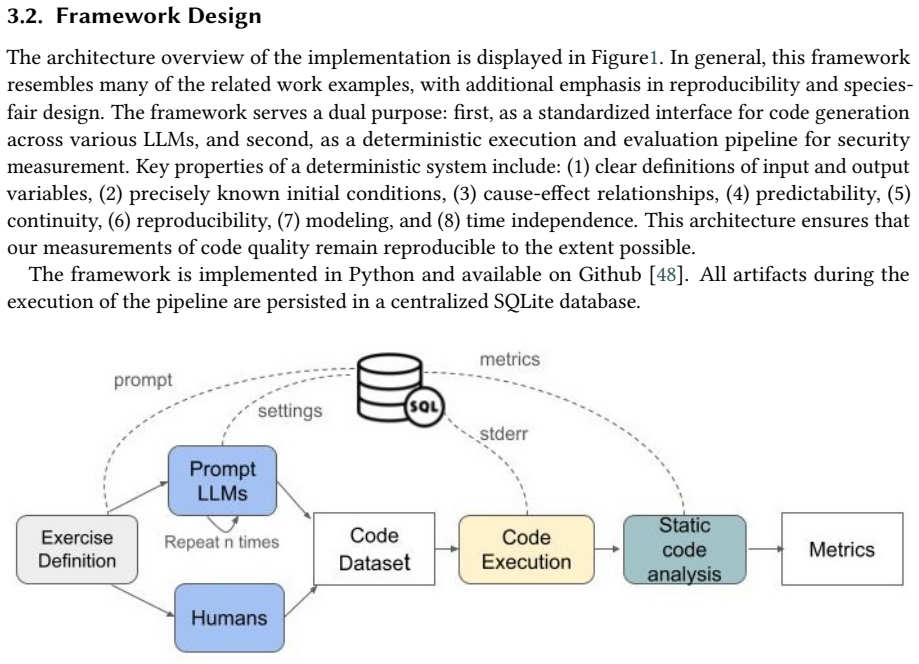
The automated framework for species-fair comparisons, which records prompts, timing, and settings while measuring security through multi-dimensional static and dynamic quality analysis.
Load-bearing premise
Multi-dimensional static and dynamic analysis supplies valid, unbiased, and comparable measures of security properties across human-written, LLM-generated, and hybrid code without systematic blind spots.
What would settle it
An experiment that shows the chosen analysis methods systematically miss certain vulnerability classes in one production condition but detect them in the others would falsify the framework's suitability for cross-condition comparisons.
Figures


read the original abstract
Large language models (LLMs) are rapidly transforming how software is created and maintained. Comparing LLM-generated code against human-written standards is essential to determine whether these new tools uphold or erode the security baselines established by professional developers. Yet, we lack a standardized method for empirically comparing the security of code produced through human-LLM collaboration against LLM-only, or traditional human-only methods. To facilitate this, we propose an automated framework for conducting comparative studies across human-only, LLM-only, and hybrid conditions. Our approach automates the logging of prompts, timing, and experimental settings, measuring outcomes through multi-dimensional static and dynamic quality analysis. We provide an open-source implementation of this framework to ensure that future researchers can conduct reproducible, species-fair experiments. Importantly, we validate the framework via a feasibility study, providing an experimental blueprint for ``species-fair'' comparisons between human and AI subjects. By sharing lessons learned, we establish a foundation for empirical research on human and LLM-generated code for software security.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an automated framework for empirically comparing the security of human-only, LLM-only, and hybrid code. It automates logging of prompts, timing, and settings; applies multi-dimensional static and dynamic quality analysis; releases an open-source implementation for reproducibility; and validates the approach via a high-level feasibility study that serves as an experimental blueprint for 'species-fair' comparisons.
Significance. If the analysis components can be shown to yield comparable security metrics without origin-dependent bias, the work would supply a much-needed standardized, reproducible methodology and tooling for security studies involving LLM-generated code. The open-source release is a concrete strength that directly supports the reproducibility goal stated in the abstract.
major comments (2)
- [feasibility study description (abstract and validation section)] The central claim that the framework supports valid cross-condition security comparisons rests on the untested assumption that the chosen static and dynamic analyzers produce unbiased metrics across human-written and LLM-generated code. The manuscript provides no controlled differential-bias evaluation (e.g., matched vulnerability pairs or false-positive/negative rate comparison) in the feasibility study description.
- [feasibility study (abstract)] The feasibility study is presented only at a high level with no quantitative results, error analysis, or evidence that the multi-dimensional analysis methods actually support the intended comparisons. This absence leaves the soundness of the validation step unassessable.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments on our manuscript. We address each major comment below and indicate how we will revise the paper accordingly.
read point-by-point responses
-
Referee: [feasibility study description (abstract and validation section)] The central claim that the framework supports valid cross-condition security comparisons rests on the untested assumption that the chosen static and dynamic analyzers produce unbiased metrics across human-written and LLM-generated code. The manuscript provides no controlled differential-bias evaluation (e.g., matched vulnerability pairs or false-positive/negative rate comparison) in the feasibility study description.
Authors: We agree that the manuscript does not include a controlled evaluation of potential bias in the analyzers across code origins. The feasibility study is designed as an experimental blueprint to illustrate how the framework can be used for species-fair comparisons, rather than to empirically validate the neutrality of the specific analysis tools. We will revise the validation section to explicitly state this limitation and discuss the assumption that the analyzers are origin-agnostic, including suggestions for future bias assessments. revision: yes
-
Referee: [feasibility study (abstract)] The feasibility study is presented only at a high level with no quantitative results, error analysis, or evidence that the multi-dimensional analysis methods actually support the intended comparisons. This absence leaves the soundness of the validation step unassessable.
Authors: The feasibility study is intentionally high-level, as the paper's main contribution is the framework and its open-source implementation, with the study providing a template for future work. No quantitative results are presented because a full empirical study is beyond the scope of this methodological paper. We will update the abstract and validation section to better clarify the purpose of the feasibility study as a blueprint and to outline the multi-dimensional analysis methods more explicitly. revision: partial
Circularity Check
Methodological proposal contains no derivations, equations, or self-referential predictions
full rationale
The paper proposes an automated framework for comparative security studies across human, LLM, and hybrid code conditions. It describes logging, multi-dimensional static/dynamic analysis, open-source implementation, and a high-level feasibility study. No equations, parameter fitting, predictions, or derivation chains appear in the provided text. The framework is presented as a new methodological contribution rather than derived from prior results. The assumption that analyzers produce comparable metrics is a design choice, not a reduction to self-inputs. No self-citation load-bearing steps or uniqueness claims are present.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multi-dimensional static and dynamic quality analysis accurately and comparably measures security across human and LLM code conditions
Reference graph
Works this paper leans on
-
[1]
L. C. Ramírez, X. Limón, A. J. Sánchez-García, J. C. Pérez-Arriaga, State of the Art of the Security of Code Generated by LLMs: A Systematic Literature Review, in: 2024 12th International Conference in Software Engineering Research and Innovation (CONISOFT 2024), 2024, pp. 331–339. doi:10. 1109/CONISOFT63288.2024.00050
arXiv 2024
-
[2]
C. Firestone, Performance vs. competence in human–machine comparisons, Proceedings of the National Academy of Sciences 117 (2020) 26562–26571. doi:10.1073/pnas.1905334117
-
[3]
M. Tahaei, K. Vaniea, A Survey on Developer-Centred Security, in: 2019 IEEE European Symposium on Security and Privacy Workshops (EuroS&PW), 2019, pp. 129–138. URL: https://ieeexplore.ieee. org/document/8802434. doi:10.1109/EuroSPW.2019.00021
-
[4]
Y. Acar, S. Fahl, M. L. Mazurek, You are Not Your Developer, Either: A Research Agenda for Usable Security and Privacy Research Beyond End Users, in: 2016 IEEE Cybersecurity Develop- ment (SecDev), IEEE, Boston, MA, USA, 2016, pp. 3–8. URL: http://ieeexplore.ieee.org/document/ 7839782/. doi:10.1109/SecDev.2016.013
-
[5]
S.-C. Dai, J. Xu, G. Tao, Rethinking the Evaluation of Secure Code Generation, 2025. doi:10.48550/ arXiv.2503.15554, arXiv:2503.15554 [cs]
arXiv 2025
-
[6]
Y. Shin, L. Williams, An empirical model to predict security vulnerabilities using code complexity metrics, in: Proceedings of the Second ACM-IEEE international symposium on Empirical software engineering and measurement, ESEM ’08, Association for Computing Machinery, New York, NY, USA, 2008, pp. 315–317. URL: https://dl.acm.org/doi/10.1145/1414004.141406...
-
[7]
V. J. Manès, H. Han, C. Han, S. K. Cha, M. Egele, E. J. Schwartz, M. Woo, The Art, Science, and Engineering of Fuzzing: A Survey, IEEE Transactions on Software Engineering 47 (2021) 2312–2331. URL: https://ieeexplore.ieee.org/abstract/document/8863940. doi:10.1109/TSE.2019.2946563
-
[8]
Pistoia, S
M. Pistoia, S. Chandra, S. J. Fink, E. Yahav, A survey of static analysis methods for identifying security vulnerabilities in software systems, IBM systems journal 46 (2007) 265–288
2007
-
[9]
H. Choi, D. Kang, J.-Y. Choi, Static Analysis for Software Reliability and Security, in: K. Daimi, H. R. Arabnia, L. Deligiannidis, M.-S. Hwang, F. G. Tinetti (Eds.), Advances in Security, Networks, and Internet of Things, Springer International Publishing, Cham, 2021, pp. 463–470
2021
-
[10]
Gosain, G
A. Gosain, G. Sharma, Static analysis: A survey of techniques and tools, in: Intelligent Computing and Applications: Proceedings of the International Conference on ICA, 22-24 December 2014, Springer, 2015, pp. 581–591
2014
-
[11]
Y. Shin, L. Williams, An empirical model to predict security vulnerabilities using code complexity metrics, in: Proceedings of the Second ACM-IEEE international symposium on Empirical software engineering and measurement, 2008, pp. 315–317
2008
-
[12]
Moshtari, A
S. Moshtari, A. Sami, M. Azimi, Using complexity metrics to improve software security, Computer Fraud & Security 2013 (2013) 8–17
2013
-
[13]
M. J. Tehrani, S. Hashemi, Assessing vulnerability in smart contracts: The role of code complexity metrics in security analysis, arXiv preprint arXiv:2411.17343 (2024)
arXiv 2024
-
[14]
Charoenwet, P
W. Charoenwet, P. Thongtanunam, V.-T. Pham, C. Treude, Toward effective secure code reviews: an empirical study of security-related coding weaknesses, Empirical Software Engineering 29 (2024)
2024
-
[15]
doi:10.1007/s10664-024-10496-y
URL: https://doi.org/10.1007/s10664-024-10496-y. doi:10.1007/s10664-024-10496-y
-
[16]
Edmundson, B
A. Edmundson, B. Holtkamp, E. Rivera, M. Finifter, A. Mettler, D. Wagner, An Empirical Study on the Effectiveness of Security Code Review, in: J. Jürjens, B. Livshits, R. Scandariato (Eds.), Engineering Secure Software and Systems, Springer, Berlin, Heidelberg, 2013, pp. 197–212. doi:10. 1007/978-3-642-36563-8_14
2013
-
[17]
Y. Acar, M. Backes, S. Fahl, S. Garfinkel, D. Kim, M. L. Mazurek, C. Stransky, Comparing the Usability of Cryptographic APIs, in: 2017 IEEE Symposium on Security and Privacy (SP), 2017, pp. 154–171. URL: https://ieeexplore.ieee.org/abstract/document/7958576. doi:10.1109/SP.2017.52, iSSN: 2375-1207
-
[18]
Perry, M
N. Perry, M. Srivastava, D. Kumar, D. Boneh, Do users write more insecure code with ai assistants?, in: Proceedings of the 2023 ACM SIGSAC conference on computer and communications security, 2023, pp. 2785–2799
2023
- [19]
-
[20]
R. Balebako, A. Marsh, J. Lin, J. Hong, L. Faith Cranor, The Privacy and Security Behaviors of Smartphone App Developers, in: Proceedings 2014 Workshop on Usable Security, Internet Society, San Diego, CA, 2014. doi:10.14722/usec.2014.23006
-
[21]
L. Braz, A. Bacchelli, Software security during modern code review: the developer’s perspective, in: Proceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/FSE 2022, Association for Computing Machinery, New York, NY, USA, 2022, pp. 810–821. URL: https://dl.acm.org/doi/10.11...
-
[22]
M. Gutfleisch, J. H. Klemmer, N. Busch, Y. Acar, M. A. Sasse, S. Fahl, How Does Usable Security (Not) End Up in Software Products? Results From a Qualitative Interview Study, in: 2022 IEEE Symposium on Security and Privacy (SP), 2022, pp. 893–910. URL: https://ieeexplore.ieee.org/ document/9833756. doi:10.1109/SP46214.2022.9833756, iSSN: 2375-1207
-
[23]
H. Assal, S. Chiasson, ’Think secure from the beginning’: A Survey with Software Developers, in: Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, CHI ’19, Association for Computing Machinery, New York, NY, USA, 2019, pp. 1–13. URL: https: //dl.acm.org/doi/10.1145/3290605.3300519. doi:10.1145/3290605.3300519
-
[24]
M. Meli, M. R. McNiece, B. Reaves, How Bad Can It Git? Characterizing Secret Leakage in Public GitHub Repositories, in: Proceedings 2019 Network and Distributed System Security Symposium, Internet Society, San Diego, CA, 2019
2019
-
[25]
F. Fischer, K. Böttinger, H. Xiao, C. Stransky, Y. Acar, M. Backes, S. Fahl, Stack Overflow Con- sidered Harmful? The Impact of Copy&Paste on Android Application Security, in: 2017 IEEE Symposium on Security and Privacy (SP), 2017, pp. 121–136. URL: https://ieeexplore.ieee.org/ abstract/document/7958574. doi:10.1109/SP.2017.31, iSSN: 2375-1207
-
[26]
Stransky, Y
C. Stransky, Y. Acar, D. C. Nguyen, D. Wermke, D. Kim, E. M. Redmiles, M. Backes, S. Garfinkel, M. L. Mazurek, S. Fahl, Lessons Learned from Using an Online Platform to Conduct Large- Scale, Online Controlled Security Experiments with Software Developers, 2017. URL: https: //www.usenix.org/conference/cset17/workshop-program/presentation/stransky
2017
-
[27]
A. Alami, M. Zahedi, N. Ernst, Are You a Real Software Engineer? Best Practices in Online Recruitment for Software Engineering Studies, in: Proceedings of the 1st IEEE/ACM International Workshop on Methodological Issues with Empirical Studies in Software Engineering, WSESE ’24, Association for Computing Machinery, New York, NY, USA, 2024, pp. 52–57. URL: ...
-
[28]
W. Wang, D. Hidellaarachchi, J. Grundy, H. Khalajzadeh, H. O. Obie, A. Madugalla, End- Users vs Software Practitioners: Recruitment Challenges and Strategies in Software Engineer- ing Research, in: 2024 IEEE Symposium on Visual Languages and Human-Centric Comput- ing (VL/HCC), 2024, pp. 400–411. URL: https://ieeexplore.ieee.org/abstract/document/10714544....
-
[29]
H. Kaur, S. Klivan, D. Votipka, Y. Acar, S. Fahl, Where to Recruit for Security Development Studies: Comparing Six Software Developer Samples, 2022, pp. 4041–4058. URL: https://www.usenix.org/ conference/usenixsecurity22/presentation/kaur
2022
-
[30]
Tahaei, K
M. Tahaei, K. Vaniea, Lessons Learned From Recruiting Participants With Programming Skills for Empirical Privacy and Security Studies: RoPES - ICSE 2022, 2022. URL: https://ropes-workshops. github.io/ropes22/
2022
-
[31]
Serafini, M
R. Serafini, M. Gutfleisch, S. A. Horstmann, A. Naiakshina, On the Recruitment of Company Developers for Security Studies: Results from a Qualitative Interview Study, 2023, pp. 321–340. URL: https://www.usenix.org/conference/soups2023/presentation/serafini
2023
-
[32]
Sandoval, H
G. Sandoval, H. Pearce, T. Nys, R. Karri, S. Garg, B. Dolan-Gavitt, Lost at C: A User Study on the Security Implications of Large Language Model Code Assistants, 2023, pp. 2205–2222. URL: https://www.usenix.org/conference/usenixsecurity23/presentation/sandoval
2023
-
[33]
V. Belozerov, P. J. Barclay, A. Sami, Secure Coding with AI, From Creation to Inspection, arXiv preprint arXiv:2504.20814 (2025)
arXiv 2025
-
[34]
G. Marvin, N. Hellen, D. Jjingo, J. Nakatumba-Nabende, Prompt Engineering in Large Language Models, in: I. J. Jacob, S. Piramuthu, P. Falkowski-Gilski (Eds.), Data Intelligence and Cognitive Informatics, Springer Nature, Singapore, 2024, pp. 387–402. doi:10.1007/978-981-99-7962-2_ 30
-
[35]
M. Bruni, F. Gabrielli, M. Ghafari, M. Kropp, Benchmarking Prompt Engineering Techniques for Secure Code Generation with GPT Models, in: 2025 IEEE/ACM Second International Conference on AI Foundation Models and Software Engineering (Forge), 2025, pp. 93–103. URL: https://ieeexplore. ieee.org/abstract/document/11052790. doi:10.1109/Forge66646.2025.00018
-
[36]
J. He, M. Vechev, Large Language Models for Code: Security Hardening and Adversarial Testing, in: Proceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security, CCS ’23, Association for Computing Machinery, New York, NY, USA, 2023, pp. 1865–1879. URL: https://dl.acm.org/doi/10.1145/3576915.3623175. doi:10.1145/3576915.3623175
-
[37]
J. He, M. Vero, G. Krasnopolska, M. Vechev, Instruction tuning for secure code generation, in: Proceedings of the 41st International Conference on Machine Learning, volume 235 ofICML’24, JMLR.org, Vienna, Austria, 2024, pp. 18043–18062
2024
-
[38]
CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis
E. Nijkamp, B. Pang, H. Hayashi, L. Tu, H. Wang, Y. Zhou, S. Savarese, C. Xiong, CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis, 2023. URL: http: //arxiv.org/abs/2203.13474. doi:10.48550/arXiv.2203.13474, arXiv:2203.13474 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2203.13474 2023
-
[39]
A. S. Molison, M. Moraes, G. Melo, F. Santos, W. K. G. Assuncao, Is LLM-Generated Code More Maintainable & Reliable than Human-Written Code?, 2025. doi:10.48550/arXiv.2508.00700, arXiv:2508.00700 [cs]
-
[40]
D. Cotroneo, C. Improta, P. Liguori, Human-Written vs. AI-Generated Code: A Large-Scale Study of Defects, Vulnerabilities, and Complexity, in: 2025 IEEE 36th International Symposium on Software Reliability Engineering (ISSRE), 2025, pp. 252–263. doi: 10.1109/ISSRE66568.2025.00035, iSSN: 2332-6549
-
[41]
S. A. Licorish, A. Bajpai, C. Arora, F. Wang, K. Tantithamthavorn, Comparing Human and LLM Gen- erated Code: The Jury is Still Out!, 2025. doi:10.48550/arXiv.2501.16857, arXiv:2501.16857 [cs]
-
[42]
M. Astekin, M. Hort, L. Moonen, An Exploratory Study on How Non-Determinism in Large Language Models Affects Log Parsing, in: Proceedings of the ACM/IEEE 2nd International Workshop on Interpretability, Robustness, and Benchmarking in Neural Software Engineering, InteNSE ’24, Association for Computing Machinery, New York, NY, USA, 2024, pp. 13–18. doi:10. ...
arXiv 2024
-
[43]
A. Y. Cui, P. Yu, Do Language Models Have Bayesian Brains? Distinguishing Stochastic and Deterministic Decision Patterns within Large Language Models, 2025. doi: 10.48550/arXiv. 2506.10268, arXiv:2506.10268 [cs]
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[44]
S. Sawadogo, A. Sabane, R. Kafando, A. K. Kabore, T. F. Bissyande, Revisiting the Non-Determinism of Code Generation by the GPT-3.5 Large Language Model, in: 2025 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER), 2025, pp. 36–44. doi: 10.1109/ SANER64311.2025.00012, iSSN: 2640-7574
arXiv 2025
-
[45]
Ortloff, C
A.-M. Ortloff, C. Tiefenau, M. Smith, SoK: I Have the (Developer) Power! Sample Size Estimation for Fisher’s Exact, Chi-Squared, McNemar’s, Wilcoxon Rank-Sum, Wilcoxon Signed-Rank and t-tests in Developer-Centered Usable Security, 2023, pp. 341–359. URL: https://www.usenix.org/ conference/soups2023/presentation/ortloff
2023
-
[46]
S. Beckers, Large language models as nondeterministic causal models, arXiv preprint arXiv:2509.22297 (2025)
Pith/arXiv arXiv 2025
-
[47]
Y. Song, G. Wang, S. Li, B. Y. Lin, The good, the bad, and the greedy: Evaluation of llms should not ignore non-determinism, in: Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 2025, pp. 4195–4206
2025
-
[48]
Ouyang, J
S. Ouyang, J. M. Zhang, M. Harman, M. Wang, An empirical study of the non-determinism of chatgpt in code generation, ACM Transactions on Software Engineering and Methodology 34 (2025) 1–28
2025
-
[49]
URL: https://github.com/jaegli/LLMEvaluationTool/
Egli, Jasmine, LLMEvaluationTool/LLMgenerateCodeEvaluationTool at main·jaegli/LLMEvalua- tionTool, 2026. URL: https://github.com/jaegli/LLMEvaluationTool/
2026
-
[50]
Gonzalez, Ruff: a game changer or Python linters., 2024
S. Gonzalez, Ruff: a game changer or Python linters., 2024. URL: https://xantygc.medium.com/ ruff-a-game-changer-for-python-linters-12b1ec8c5f12
2024
-
[51]
Walsh, Podman in Action: Secure, rootless containers for Kubernetes, microservices, and more, Simon and Schuster, 2023
D. Walsh, Podman in Action: Secure, rootless containers for Kubernetes, microservices, and more, Simon and Schuster, 2023
2023
-
[52]
URL: https://adventofcode.com/2024/
AoC, Advent of Code 2024, 2025. URL: https://adventofcode.com/2024/
2024
-
[53]
Börstler, K
J. Börstler, K. E. Bennin, S. Hooshangi, J. Jeuring, H. Keuning, C. Kleiner, B. MacKellar, R. Duran, H. Störrle, D. Toll, Developers talking about code quality, Empirical Software Engineering 28 (2023) 128
2023
-
[54]
URL: https://platform.openai.com/docs/models
OpenAI, Models, 2025. URL: https://platform.openai.com/docs/models
2025
-
[55]
M. A. Alvarado Gonzalez, M. B. Hernandez, M. A. Peñaloza Perez, B. Lopez Orozco, J. Tadeo Cruz Soto, S. Malagon, Do Repetitions Matter? Strengthening Reliability in LLM Evaluations, arXiv e-prints (2025) arXiv: 2509.24086
arXiv 2025
-
[56]
Kohno, Y
T. Kohno, Y. Acar, W. Loh, Ethical Frameworks and Computer Security Trolley Problems: Founda- tions for Conversations, in: Usenix Security, 2023, pp. 5145–5162. URL: https://www.usenix.org/ conference/usenixsecurity23/presentation/kohno
2023
-
[57]
Verdier, The Fastest Way to Boost your Code Quality: Use Ruff Linter, 2023
E. Verdier, The Fastest Way to Boost your Code Quality: Use Ruff Linter, 2023. URL: https: //data-ai.theodo.com/en/technical-blog/boost-code-quality-ruff-linter
2023
-
[58]
BRTNÍK, Analysis and Extension of the Ruff Linter (????)
T. BRTNÍK, Analysis and Extension of the Ruff Linter (????)
-
[59]
B. T. Kristinsson, Implementing Python code quality checks in the CMSSW Continuous Integration infrastructure, Technical Report, 2024
2024
-
[60]
URL: https://openai.com/de-DE/codex/
OpenAI, Codex, 2025. URL: https://openai.com/de-DE/codex/
2025
-
[61]
Akamine, D
A. Akamine, D. Hayashi, A. Tomizawa, Y. Nagasaki, C. Akamine, T. Fukawa, I. Hirosawa, O. Saigo, M. Hayashi, M. Nanaoya, Effects of temperature settings on information quality of ChatGPT- 3.5 responses: A prospective, single-blind, observational cohort study, medRxiv (2024) 2024.06. 11.24308759
2024
-
[62]
URL: https://platform.openai.com/docs/api-reference/audio/ createTranslation#audio_createtranslation-temperature
OpenAI, createTranslation, ????. URL: https://platform.openai.com/docs/api-reference/audio/ createTranslation#audio_createtranslation-temperature
-
[63]
URL: https://platform.openai.com/docs/api-reference/chat/ create#chat_create-frequency_penalty
OpenAI, Create chat completion, ????. URL: https://platform.openai.com/docs/api-reference/chat/ create#chat_create-frequency_penalty
-
[64]
URL: https://www.w3resource.com/python-exercises/ cybersecurity/
w3resource, w3resource, 2024. URL: https://www.w3resource.com/python-exercises/ cybersecurity/
2024
-
[65]
URL: https://adventofcode.com/2025/
AoC, Advent of Code 2025, 2025. URL: https://adventofcode.com/2025/. A. Appendix: Framework and Metrics Execution and static analysis are coordinated by the analyse_outputs routine, which launches each script in its own container, executes it and performs static checks. With a minimal monitoring system, the analyse_outputs orchestration routine verifies r...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.