Closed-Loop Neural Activation Control in Vision-Language-Action Models
Pith reviewed 2026-06-28 22:22 UTC · model grok-4.3
The pith
Closed-loop feedback replaces fixed coefficients to stabilize steering of temporal concepts in VLA models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Steering along motion-aligned residual directions while a separate feedback controller dynamically adjusts intervention magnitude produces more stable regulation of temporal concepts than static coefficients, without changing the underlying VLA policy.
What carries the argument
CTRL-STEER framework, which decouples representation via motion-aligned residual directions from regulation via an online feedback controller that varies steering strength.
If this is right
- Regulation of speed and smoothness becomes stable across task duration rather than oscillating.
- The steering-task success trade-off improves relative to any fixed-coefficient method.
- The same base model can be used for both unsteered and adaptively steered behavior without retraining.
- Both PID and reinforcement-learning controllers can be substituted inside the same residual-direction framework.
Where Pith is reading between the lines
- The separation of direction choice from magnitude control may generalize to other forms of test-time intervention in sequence models.
- Real-time robotic deployment could benefit from the reduced oscillation when safety depends on smooth motion.
- Different sensor feedback signals could be routed to the controller without altering the residual directions.
- The method leaves open the possibility of learning the residual directions themselves from interaction data.
Load-bearing premise
Temporal concepts can be separated from the base representation by choosing motion-aligned residual directions while a feedback loop alone handles the time-varying strength of the intervention.
What would settle it
A direct comparison on the same OpenVLA policy and LIBERO tasks in which the closed-loop controller produces equal or greater oscillation and lower task success than the best fixed-coefficient baseline.
Figures
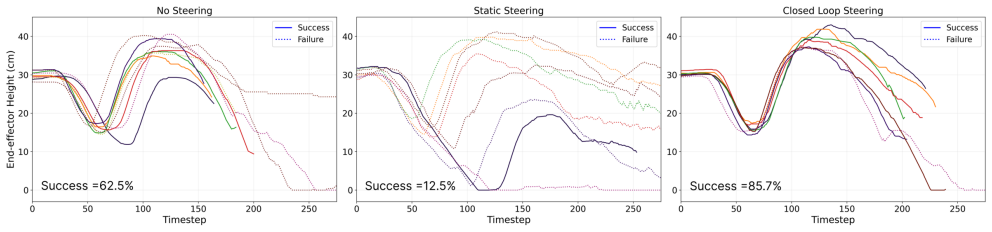
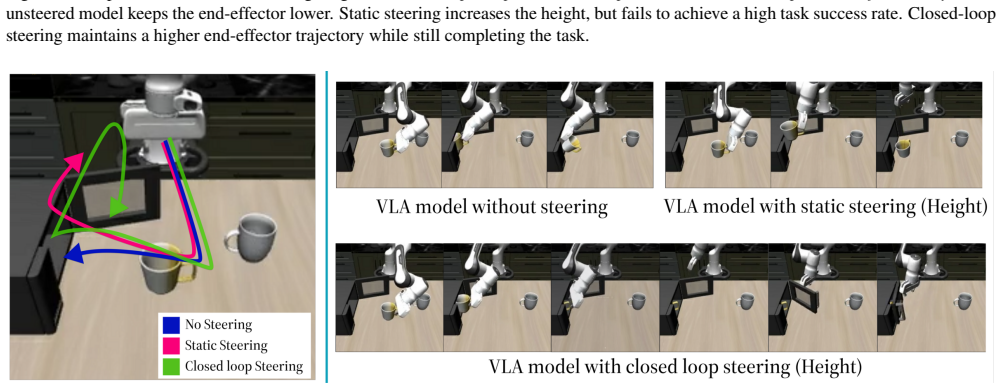
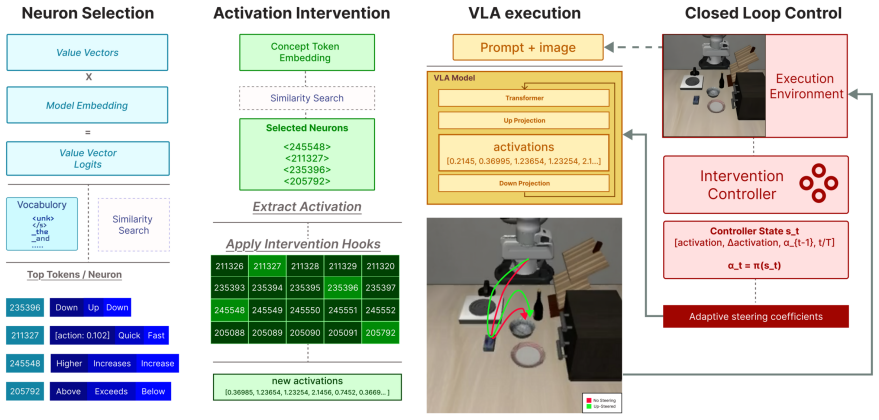

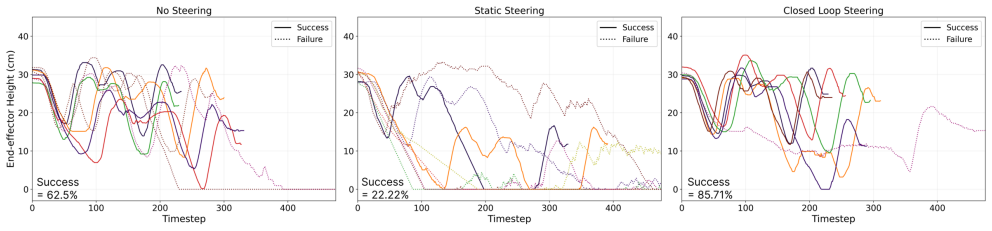
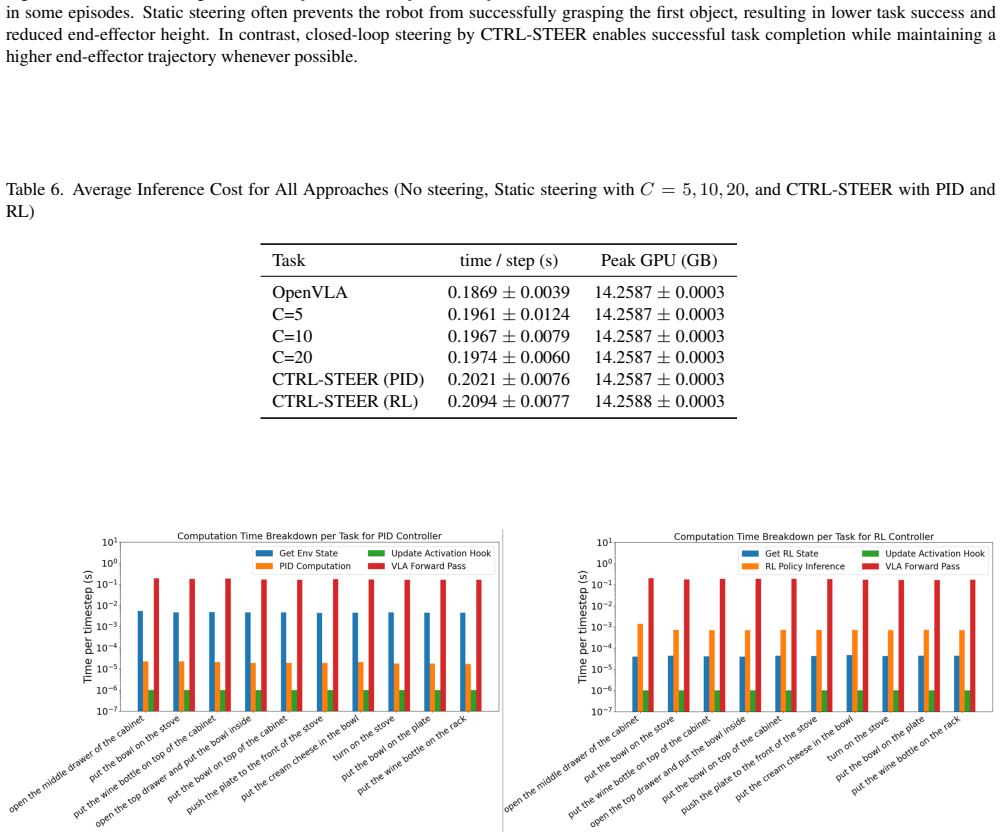
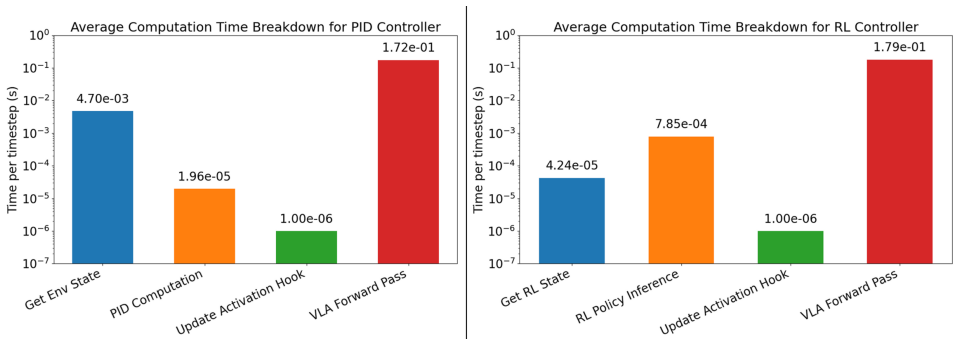
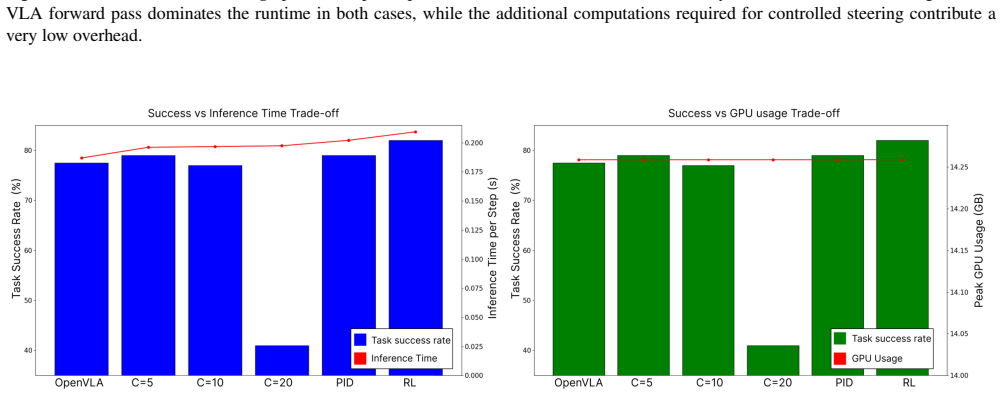
read the original abstract
Vision-Language-Action (VLA) models can be steered at test time by intervening on semantically meaningful internal directions, but existing methods use a fixed steering coefficient, effectively operating in open loop. This is poorly suited to embodied control, where task state and concept error evolve over time, often causing overcorrection, oscillation, and reduced task success, especially for temporal behaviors such as speed and smoothness. We propose CTRL-STEER, a closed-loop framework that replaces static intervention strength with adaptive, time-varying control signals. The key idea is to decouple representation from regulation: rather than assuming temporal concepts are directly controlled by individual neurons, we steer along motion-aligned residual directions while a feedback controller adjusts intervention magnitude online. We instantiate this framework with both PID and reinforcement learning based controllers. Experiments with a fine-tuned OpenVLA policy on four LIBERO task suites show that CTRL-STEER achieves more stable concept regulation and a better steering-task success trade-off than fixed-coefficient baselines, without modifying or retraining the base model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CTRL-STEER, a closed-loop framework for steering Vision-Language-Action (VLA) models at test time. It replaces fixed steering coefficients with adaptive control signals from PID or RL controllers, decoupling representation via motion-aligned residual directions from regulation. Experiments on four LIBERO task suites using a fine-tuned OpenVLA policy are reported to demonstrate more stable concept regulation and a superior steering-task success trade-off compared to fixed-coefficient baselines, without retraining the base model.
Significance. If the reported empirical improvements hold, this work could be significant for embodied AI applications by enabling more reliable test-time intervention in VLA models, particularly for temporal behaviors like speed and smoothness, addressing limitations of open-loop steering methods.
major comments (1)
- [Abstract] Abstract: The central claim that CTRL-STEER 'achieves more stable concept regulation and a better steering-task success trade-off than fixed-coefficient baselines' on four LIBERO suites is presented without any quantitative results, metrics, error bars, or experimental details. This absence prevents verification of the empirical findings that form the core of the paper's contribution.
minor comments (1)
- [Abstract] The description of the framework would benefit from a brief mention of how the motion-aligned residual directions are identified or computed.
Simulated Author's Rebuttal
We thank the referee for their review and constructive comment on the abstract. We address the point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that CTRL-STEER 'achieves more stable concept regulation and a better steering-task success trade-off than fixed-coefficient baselines' on four LIBERO suites is presented without any quantitative results, metrics, error bars, or experimental details. This absence prevents verification of the empirical findings that form the core of the paper's contribution.
Authors: We agree that the abstract would be strengthened by including key quantitative results. The full paper reports detailed experiments on four LIBERO suites with a fine-tuned OpenVLA policy, including task success rates, stability metrics, and comparisons to fixed-coefficient baselines. In the revised manuscript we will update the abstract to incorporate specific metrics (e.g., success rate improvements and regulation stability measures) with error bars to make the central claim verifiable at a glance. revision: yes
Circularity Check
No significant circularity; empirical framework with independent experimental validation
full rationale
The paper describes CTRL-STEER as a test-time closed-loop steering method using motion-aligned residuals and feedback controllers (PID or RL), evaluated empirically on four LIBERO suites with a fine-tuned OpenVLA policy. No equations, parameter-fitting procedures, or derivation steps are presented that would reduce the claimed performance gains to a self-definition, fitted-input prediction, or self-citation chain. The central claim rests on direct experimental comparisons of regulation stability and steering-success trade-offs against fixed-coefficient baselines, which are falsifiable by the reported protocol and do not rely on internal redefinitions or prior author results as load-bearing premises.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Analysis and design of feedback systems princeton, 2008
KJ ˚Astr¨om and RM Murray. Analysis and design of feedback systems princeton, 2008. 3
2008
-
[2]
Pid controllers: theory, design, and tuning
Karl J Astrom. Pid controllers: theory, design, and tuning. The international society of measurement and control, 1995. 2
1995
-
[3]
Princeton uni- versity press, 2021
Karl Johan ˚Astr¨om and Richard Murray.Feedback systems: an introduction for scientists and engineers. Princeton uni- versity press, 2021. 3
2021
-
[4]
A Careful Examination of Large Behavior Models for Multitask Dexterous Manipulation
Jose Barreiros, Andrew Beaulieu, Aditya Bhat, Rick Cory, Eric Cousineau, Hongkai Dai, Ching-Hsin Fang, Kunimatsu Hashimoto, Muhammad Zubair Irshad, Masha Itkina, et al. A careful examination of large behavior models for multitask dexterous manipulation.arXiv preprint arXiv:2507.05331,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al.π 0: A vision-language- action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Towards monosemanticity: Decomposing language mod- els with dictionary learning.Transformer Circuits Thread,
Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Conerly, Nick Turner, Cem Anil, Carson Denison, Amanda Askell, Robert Lasenby, Yi- fan Wu, Shauna Kravec, Nicholas Schiefer, Tim Maxwell, Nicholas Joseph, Zac Hatfield-Dodds, Alex Tamkin, Ka- rina Nguyen, Brayden McLean, Josiah E Burke, Tristan Hume, Shan Carter, Tom Henighan, an...
-
[7]
https://transformer-circuits.pub/2023/monosemantic- features/index.html. 3
2023
-
[8]
Jiahang Cao, Yize Huang, Hanzhong Guo, Rui Zhang, Mu Nan, Weijian Mai, Jiaxu Wang, Hao Cheng, Jingkai Sun, Gang Han, et al. Compose your policies! im- proving diffusion-based or flow-based robot policies via test-time distribution-level composition.arXiv preprint arXiv:2510.01068, 2025. 1
-
[9]
Diffusion policy: Visuomotor policy learning via action dif- fusion.The International Journal of Robotics Research, 44 (10-11):1684–1704, 2025
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action dif- fusion.The International Journal of Robotics Research, 44 (10-11):1684–1704, 2025. 1
2025
-
[10]
Sparse autoencoders find highly interpretable features in language models.arXiv e-prints, pages arXiv–2309, 2023
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. Sparse autoencoders find highly interpretable features in language models.arXiv e-prints, pages arXiv–2309, 2023. 2, 3, 4
2023
-
[11]
Transformer feed-forward layers are key-value memories
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. Transformer feed-forward layers are key-value memories. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 5484–5495, 2021. 1, 2, 3, 4
2021
-
[12]
Transformer feed-forward layers build predictions by pro- moting concepts in the vocabulary space
Mor Geva, Avi Caciularu, Kevin Wang, and Yoav Goldberg. Transformer feed-forward layers build predictions by pro- moting concepts in the vocabulary space. InProceedings of the 2022 conference on empirical methods in natural lan- guage processing, pages 30–45, 2022. 3
2022
-
[13]
Mechanistic interpretability for steering vision-language-action models
Bear H ¨aon, Kaylene Caswell Stocking, Ian Chuang, and Claire Tomlin. Mechanistic interpretability for steering vision-language-action models. InConference on Robot Learning, pages 2743–2762. PMLR, 2025. 2, 3, 4, 5, 7, 8, 9, 12, 13, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25
2025
-
[14]
Vima: Robot manipulation with multimodal prompts
Yunfan Jiang, Agrim Gupta, Zichen Zhang, Guanzhi Wang, Yongqiang Dou, Yanjun Chen, Li Fei-Fei, Anima Anandku- mar, Yuke Zhu, and Linxi Fan. Vima: Robot manipulation with multimodal prompts. 2023. 1
2023
-
[15]
Prismatic vlms: Investigating the design space of visually-conditioned language models
Siddharth Karamcheti, Suraj Nair, Ashwin Balakrishna, Percy Liang, Thomas Kollar, and Dorsa Sadigh. Prismatic vlms: Investigating the design space of visually-conditioned language models. InForty-first International Conference on Machine Learning, 2024. 6
2024
-
[16]
Vision-language-action models for robotics: A review towards real-world applications.IEEE Access, 2025
Kento Kawaharazuka, Jihoon Oh, Jun Yamada, Ingmar Pos- ner, and Yuke Zhu. Vision-language-action models for robotics: A review towards real-world applications.IEEE Access, 2025. 1
2025
-
[17]
Controlling vision–language–action poli- cies through sparse latent directions
Momin Ahmad Khan, Novak Boskov, Fatima M Anwar, and Manzoor A Khan. Controlling vision–language–action poli- cies through sparse latent directions. InMechanistic Inter- pretability Workshop at NeurIPS 2025. 2
2025
-
[18]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ash- win Balakrishna, Sudeep Dasari, Siddharth Karamcheti, Soroush Nasiriany, Mohan Kumar Srirama, Lawrence Yun- liang Chen, Kirsty Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024. 1, 2, 6, 7, 8, 9, 12, 18, 19, 20, 21, 22, 23, 24, 25 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
A review of robot learning for manipulation: Challenges, rep- resentations, and algorithms.Journal of Machine Learning Research, 22(30):1–82, 2021
Oliver Kroemer, Scott Niekum, and George Konidaris. A review of robot learning for manipulation: Challenges, rep- resentations, and algorithms.Journal of Machine Learning Research, 22(30):1–82, 2021. 2
2021
-
[21]
Evaluating Real-World Robot Manipulation Policies in Simulation
Xuanlin Li, Kyle Hsu, Jiayuan Gu, Karl Pertsch, Oier Mees, Homer Rich Walke, Chuyuan Fu, Ishikaa Lunawat, Isabel Sieh, Sean Kirmani, et al. Evaluating real-world robot manipulation policies in simulation.arXiv preprint arXiv:2405.05941, 2024. 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Libero: Benchmarking knowl- edge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowl- edge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023. 7
2023
-
[23]
Locating and editing factual associations in gpt.Ad- vances in neural information processing systems, 35:17359– 17372, 2022
Kevin Meng, David Bau, Alex Andonian, and Yonatan Be- linkov. Locating and editing factual associations in gpt.Ad- vances in neural information processing systems, 35:17359– 17372, 2022. 3
2022
-
[24]
Feature visualization.Distill, 2(11):e7, 2017
Chris Olah, Alexander Mordvintsev, and Ludwig Schubert. Feature visualization.Distill, 2(11):e7, 2017. 2
2017
-
[25]
Towards scalable robot learning without physical robots
Younghyo Park. Towards scalable robot learning without physical robots. Master’s thesis, Massachusetts Institute of Technology, 2025. 1
2025
-
[26]
Scott Reed, Konrad Zolna, Emilio Parisotto, Sergio Gomez Colmenarejo, Alexander Novikov, Gabriel Barth-Maron, Mai Gimenez, Yury Sulsky, Jackie Kay, Jost Tobias Sprin- genberg, et al. A generalist agent.arXiv preprint arXiv:2205.06175, 2022. 1
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[27]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Rad- ford, and Oleg Klimov. Proximal policy optimization algo- rithms.arXiv preprint arXiv:1707.06347, 2017. 2
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[28]
GigaBrain Team, Angen Ye, Boyuan Wang, Chaojun Ni, Guan Huang, Guosheng Zhao, Haoyun Li, Jie Li, Jia- gang Zhu, Lv Feng, et al. Gigabrain-0: A world model- powered vision-language-action model.arXiv preprint arXiv:2510.19430, 2025. 1
-
[29]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023. 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Steering Your Diffusion Policy with Latent Space Reinforcement Learning
Andrew Wagenmaker, Mitsuhiko Nakamoto, Yunchu Zhang, Seohong Park, Waleed Yagoub, Anusha Nagabandi, Ab- hishek Gupta, and Sergey Levine. Steering your diffu- sion policy with latent space reinforcement learning.arXiv preprint arXiv:2506.15799, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Bridgedata v2: A dataset for robot learning at scale
Homer Rich Walke, Kevin Black, Tony Z Zhao, Quan Vuong, Chongyi Zheng, Philippe Hansen-Estruch, An- dre Wang He, Vivek Myers, Moo Jin Kim, Max Du, et al. Bridgedata v2: A dataset for robot learning at scale. InCon- ference on Robot Learning, pages 1723–1736. PMLR, 2023. 1, 7
2023
-
[32]
arXiv preprint arXiv:2412.13630 , year=
Xiu Yuan, Tongzhou Mu, Stone Tao, Yunhao Fang, Mengke Zhang, and Hao Su. Policy decorator: Model-agnostic online refinement for large policy model.arXiv preprint arXiv:2412.13630, 2024. 1
-
[33]
Up-vla: A unified understanding and prediction model for embodied agent
Jianke Zhang, Yanjiang Guo, Yucheng Hu, Xiaoyu Chen, Xi- ang Zhu, and Jianyu Chen. Up-vla: A unified understanding and prediction model for embodied agent. InInternational Conference on Machine Learning (ICML), 2025. 1
2025
-
[34]
X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment Vision-Language-Action Model
Jinliang Zheng, Jianxiong Li, Zhihao Wang, Dongxiu Liu, Xirui Kang, Yuchun Feng, Yinan Zheng, Jiayin Zou, Yilun Chen, Jia Zeng, et al. X-vla: Soft-prompted transformer as scalable cross-embodiment vision-language-action model. arXiv preprint arXiv:2510.10274, 2025. 7, 8
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Unified latent steering and residual refine- ment for online improvement of diffusion policy models
Zhengbang Zhu, Ziyan Li, Xiu Yuan, Hanbo Zhang, Yux- iao Liu, Chongjie Zhang, Yong Yu, Weinan Zhang, and Minghuan Liu. Unified latent steering and residual refine- ment for online improvement of diffusion policy models
-
[36]
Rt-2: Vision-language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023. 1, 2
2023
-
[37]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, et al. Representation engineering: A top-down approach to ai transparency.arXiv preprint arXiv:2310.01405, 2023. 3 11 A. RL Training without PID Initialization In this section, we provide detailed results across all...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.