Isolating LLM Lexical Bias: A Curation-Free Triangulated Metric for Preference-Stage Learning
Pith reviewed 2026-06-28 22:02 UTC · model grok-4.3
The pith
A new triangulated metric isolates lexical biases introduced specifically during the preference-learning stage of LLM training by comparing human, base-model, and instruct-model outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Triangulated Preference Shift score isolates shifts induced specifically by preference learning without manual curation by triangulating between human gold standards, base models, and instruct variants. The metric provides an initial automated method to quantify behavioral shifts attributable to preference tuning across six model families and can test whether those shifts move models toward what could be interpreted as a language of prestige.
What carries the argument
Triangulated Preference Shift score, which measures lexical distribution differences across human text, base-model outputs, and instruct-model outputs on the same prompts to attribute changes to the preference stage.
If this is right
- The score can be applied to outputs from six model families to detect preference-induced lexical changes.
- It can test whether preference learning shifts models toward language patterns associated with prestige.
- Results can be anchored against existing literature on lexical misalignment from preference stages.
- The approach supplies an automated check that may help guide model alignment and trustworthy AI development.
Where Pith is reading between the lines
- If the triangulation reliably separates stages, the same comparison could be used to evaluate how different preference datasets or reward models alter lexical output.
- Repeated application of the score at intermediate training checkpoints might locate the precise point at which specific word biases are introduced.
- Developers could run the metric on candidate preference data before full training to anticipate and reduce unwanted lexical shifts.
Load-bearing premise
Lexical differences observed when the same prompts are given to humans, base models, and instruct models arise primarily from the preference-learning stage rather than from other training differences, prompt distributions, or sampling choices.
What would settle it
Finding nearly identical lexical distributions between base models and their corresponding instruct models on matched prompts, or large human-instruct differences that already appear in the base models before any preference training occurs.
Figures

read the original abstract
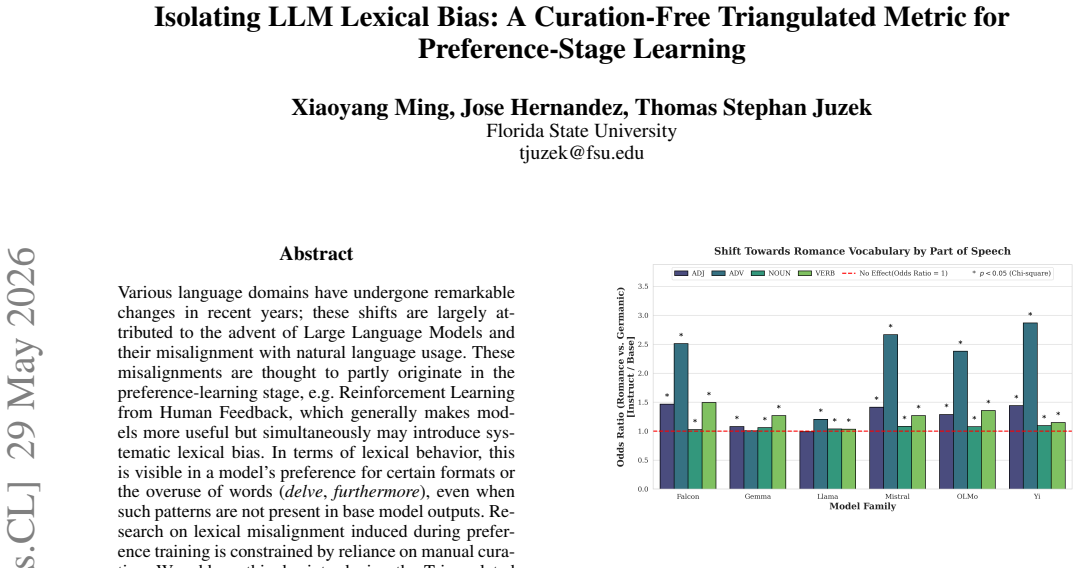
Various language domains have undergone remarkable changes in recent years; these shifts are largely attributed to the advent of Large Language Models and their misalignment with natural language usage. These misalignments are thought to partly originate in the preference-learning stage, e.g. Reinforcement Learning from Human Feedback, which generally makes models more useful but simultaneously may introduce systematic lexical bias. In terms of lexical behavior, this is visible in a model's preference for certain formats or the overuse of words (delve, furthermore), even when such patterns are not present in base model outputs. Research on lexical misalignment induced during preference training is constrained by reliance on manual curation. We address this, by introducing the Triangulated Preference Shift score, a metric that triangulates between human gold standards, base models, and instruct variants to isolate shifts induced specifically by preference learning, without manual curation. We provide data across six model families, anchor the results in the literature, and illustrate the general approach's utility by analyzing whether preference learning shifts models toward what could be interpreted as a "language of prestige". The metric provides an initial automated method to quantify behavioral shifts attributable to preference tuning, and thus, may help inform model alignment and development of trustworthy AI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Triangulated Preference Shift score, a curation-free metric that triangulates lexical statistics across human gold-standard text, base-model outputs, and instruct-model outputs on identical prompts. The goal is to isolate lexical shifts attributable specifically to the preference-learning stage (e.g., RLHF) across six model families, while also examining whether these shifts align with a hypothesized "language of prestige."
Significance. If the triangulation successfully isolates preference-stage effects, the metric would supply an automated, reproducible tool for quantifying and tracking lexical bias introduced during alignment, complementing existing manual-curation approaches and supporting more trustworthy model development.
major comments (2)
- [Method / Triangulated Preference Shift score definition] The central claim that the metric isolates shifts induced specifically by preference learning rests on the assumption that base-to-instruct differences are driven primarily by the preference stage. However, the method description does not report controls that hold SFT data, tokenizer, or sampling temperature fixed across the base/instruct pairs; any measured shift therefore conflates the target stage with earlier pipeline differences.
- [Method / Triangulated Preference Shift score definition] The triangulation subtracts base-model statistics from instruct-model statistics and further anchors against human text, but without the above controls the subtraction step cannot be shown to remove only preference-induced components rather than SFT-induced token-distribution changes.
minor comments (2)
- [Abstract] The abstract states results are "anchored in the literature," but the manuscript should explicitly cite the specific prior lexical-bias studies being used for anchoring.
- [Method] Notation for the three-way comparison (human, base, instruct) should be introduced with a compact equation or table to improve readability.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying a key assumption in the Triangulated Preference Shift score. We respond to each major comment below and will revise the manuscript to increase transparency around methodological limitations.
read point-by-point responses
-
Referee: [Method / Triangulated Preference Shift score definition] The central claim that the metric isolates shifts induced specifically by preference learning rests on the assumption that base-to-instruct differences are driven primarily by the preference stage. However, the method description does not report controls that hold SFT data, tokenizer, or sampling temperature fixed across the base/instruct pairs; any measured shift therefore conflates the target stage with earlier pipeline differences.
Authors: We agree that the publicly released base/instruct pairs used in the study do not hold SFT corpora, tokenizers, or decoding parameters fixed, and the original method section did not explicitly flag this. The triangulation subtracts base-model lexical statistics from instruct-model statistics (anchored to human text) precisely to surface differences attributable to whatever stages separate the two models; in the families examined, preference tuning is the dominant post-base stage. Nevertheless, the referee is correct that earlier differences could contribute. In revision we will add a dedicated “Assumptions and Limitations” subsection that states this caveat, describes the model pairs examined, and explains why the metric remains useful as a curation-free indicator even if it does not isolate preference effects with perfect purity. revision: yes
-
Referee: [Method / Triangulated Preference Shift score definition] The triangulation subtracts base-model statistics from instruct-model statistics and further anchors against human text, but without the above controls the subtraction step cannot be shown to remove only preference-induced components rather than SFT-induced token-distribution changes.
Authors: The subtraction step is intended to cancel components shared by base and instruct outputs; the human anchor then contextualizes whether the residual shift moves toward or away from natural language. We acknowledge that, absent fixed controls, any SFT-induced distributional change unique to the instruct checkpoint will remain in the residual. The revised manuscript will (a) restate the triangulation formula with explicit notation for the stages being compared and (b) add a short paragraph discussing the practical difficulty of obtaining perfectly matched base/instruct pairs while still providing a reproducible, curation-free signal across six families. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper proposes the Triangulated Preference Shift score as a new metric constructed via direct comparison of human gold standards, base-model outputs, and instruct-model outputs on the same prompts. This is presented as an independent definitional contribution for isolating preference-stage effects without curation. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text that would reduce the claimed isolation to an input by construction. The central claim retains independent content as a proposed automated measurement approach, even though its interpretive validity rests on external assumptions about training stages.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
AI --- 2024 Stack Overflow Developer Survey , year =
2024
-
[2]
2024 , month = may, howpublished =
Coffey, Lauren , title =. 2024 , month = may, howpublished =
2024
-
[3]
2025 , month = jul, howpublished =
O'Brien, Matt and Sanders, Linley , title =. 2025 , month = jul, howpublished =
2025
-
[4]
2025 , month = jun, howpublished =
Sidoti, Olivia and McClain, Colleen , title =. 2025 , month = jun, howpublished =
2025
- [5]
-
[6]
arXiv preprint arXiv:2404.01268 , year =
Liang, Weixin and Zhang, Yaohui and Wu, Zhengxuan and Lepp, Haley and Ji, Wenlong and Zhao, Xuandong and Cao, Hancheng and Liu, Sheng and He, Siyu and Huang, Zhi and others , title =. arXiv preprint arXiv:2404.01268 , year =
-
[7]
Advances in Neural Information Processing Systems , year =
Ouyang, Long and Wu, Jeffrey and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and others , title =. Advances in Neural Information Processing Systems , year =
-
[8]
Advances in Neural Information Processing Systems , year =
Rafailov, Rafael and Sharma, Archit and Mitchell, Eric and Manning, Christopher D and Ermon, Stefano and Finn, Chelsea , title =. Advances in Neural Information Processing Systems , year =
-
[9]
and Kolossa, Dorothea , title =
Irrgang, Verena and Solopova, Veronika and Zeiler, Steffen and Nickel, Robert M. and Kolossa, Dorothea , title =. Proceedings of the 20th Conference on Natural Language Processing (KONVENS 2024) , address =. 2024 , month = sep, pages =
2024
-
[10]
Achiam, Josh and Adler, Steven and Agarwal, Sandhini and Ahmad, Lama and Akkaya, Ilge and others , journal =
-
[11]
Measuring Massive Multitask Language Understanding (
Hendrycks, Dan and Burns, Collin and Basart, Steven and Zou, Andy and Mazeika, Mantas and Song, Dawn and Steinhardt, Jacob , journal =. Measuring Massive Multitask Language Understanding (
-
[12]
medRxiv , year =
Matsui, Kentaro , title =. medRxiv , year =
-
[13]
arXiv preprint arXiv:2404.15799 , year =
Liu, Jialin and Bu, Yi , title =. arXiv preprint arXiv:2404.15799 , year =
-
[14]
arXiv preprint arXiv:2403.16887 , year =
Gray, Andrew , title =. arXiv preprint arXiv:2403.16887 , year =
-
[15]
Geng, Mingmeng and Trotta, Roberto , journal =. Is
-
[16]
arXiv preprint arXiv:2506.05339 , year =
Flattery, Fluff, and Fog: Diagnosing and Mitigating Idiosyncratic Biases in Preference Models , author =. arXiv preprint arXiv:2506.05339 , year =
-
[17]
arXiv preprint arXiv:2508.01930 , year =
Word Overuse and Alignment in Large Language Models: The Influence of Learning from Human Feedback , author =. arXiv preprint arXiv:2508.01930 , year =
-
[18]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Deep Reinforcement Learning from Human Preferences , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[19]
arXiv preprint arXiv:2109.01652 , year =
Finetuned Language Models are Zero-Shot Learners , author =. arXiv preprint arXiv:2109.01652 , year =
-
[20]
arXiv preprint arXiv:2307.09288 , year =
Llama 2: Open Foundation and Fine-Tuned Chat Models , author =. arXiv preprint arXiv:2307.09288 , year =
-
[21]
ACL 2025 Student Research Workshop , year =
Testing English News Articles for Lexical Homogenization Due to Widespread Use of Large Language Models , author =. ACL 2025 Student Research Workshop , year =
2025
-
[22]
arXiv preprint arXiv:2409.01754 , year =
Empirical Evidence of Large Language Model's Influence on Human Spoken Communication , author =. arXiv preprint arXiv:2409.01754 , year =
-
[23]
, journal =
Anderson, Bryce and Galpin, Riley and Juzek, Tom S. , journal =. Model Misalignment and Language Change: Traces of
-
[24]
Gibney, Elizabeth , title =. Nature , year =. doi:10.1038/d41586-025-00229-6 , note =
-
[25]
arXiv preprint arXiv:2110.14168 , year =
Training Verifiers to Solve Math Word Problems , author =. arXiv preprint arXiv:2110.14168 , year =
-
[26]
arXiv preprint arXiv:2409.11704 , year =
Zhang, Xuanchang and Xiong, Wei and Chen, Lichang and Zhou, Tianyi and Huang, Heng and Zhang, Tong , title =. arXiv preprint arXiv:2409.11704 , year =
-
[27]
Nature , year =
Shumailov, Ilia and Shumaylov, Zakhar and Zhao, Yiren and Gal, Yarin and Papernot, Nicolas and Anderson, Ross , title =. Nature , year =
- [28]
-
[29]
arXiv preprint arXiv:2311.16822 , year =
Briesch, Martin and Sobania, Dominik and Rothlauf, Franz , title =. arXiv preprint arXiv:2311.16822 , year =
-
[30]
Texto Livre , year =
da Silva, Antonio Marcio and Rottava, Lucia , title =. Texto Livre , year =
-
[31]
Lengua y Sociedad , year =
Kotz, Gabriela and Salcedo-Lagos, Pedro and Fuentes, Karina , title =. Lengua y Sociedad , year =
-
[32]
2025 , howpublished =
Jin, Houji and Ashrafi, Negin and Abdollahi, Armin and others , title =. 2025 , howpublished =
2025
-
[33]
PLOS ONE , year =
Zaitsu, Wataru and Jin, Mingzhe , title =. PLOS ONE , year =
-
[34]
International Journal of Speech Technology , year =
Schaaff, Kristina and Schlippe, Tim and Mindner, Lorenz , title =. International Journal of Speech Technology , year =
-
[35]
Linguistic Characteristics of
Ter. Linguistic Characteristics of. 2025 , howpublished =
2025
-
[36]
Gehrmann, Sebastian and Strobelt, Hendrik and Rush, Alexander , booktitle =
-
[37]
On the Possibilities of
Chakraborty, Souradip and others , journal =. On the Possibilities of
-
[38]
and Finn, Chelsea , booktitle =
Mitchell, Eric and Lee, Yoonho and Khazatsky, Alexander and Manning, Christopher D. and Finn, Chelsea , booktitle =
-
[39]
Proceedings of ICLR , year =
On the Reliability of Watermarks for Large Language Models , author =. Proceedings of ICLR , year =
-
[40]
Huang, Yifei and others , booktitle =
-
[41]
arXiv preprint arXiv:2303.11156 , year =
Sadasivan, Vinu Sankar and others , title =. arXiv preprint arXiv:2303.11156 , year =
-
[42]
International Journal for Educational Integrity , year =
Weber-Wulff, Debora and others , title =. International Journal for Educational Integrity , year =
-
[43]
Language (Technology) is Power: A Critical Survey of ``Bias'' in
Blodgett, Su Lin and Barocas, Solon and Daum. Language (Technology) is Power: A Critical Survey of ``Bias'' in. arXiv preprint arXiv:2005.14050 , year =
arXiv 2005
-
[44]
and Gebru, Timnit and McMillan-Major, Angelina and Shmitchell, Shmargaret , title =
Bender, Emily M. and Gebru, Timnit and McMillan-Major, Angelina and Shmitchell, Shmargaret , title =. Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency , year =
2021
-
[45]
Proceedings of the ACM Collective Intelligence Conference , year =
Kotek, Hadas and Dockum, Rikker and Sun, David , title =. Proceedings of the ACM Collective Intelligence Conference , year =
-
[46]
and Lester, Jenna C
Omiye, Jesutofunmi A. and Lester, Jenna C. and Spichak, Simon and Rotemberg, Veronica and Daneshjou, Roxana , title =. NPJ Digital Medicine , year =
-
[47]
arXiv preprint arXiv:2310.13548 , year =
Towards Understanding Sycophancy in Language Models , author =. arXiv preprint arXiv:2310.13548 , year =
-
[48]
Proceedings of ICLR , year =
Simple Synthetic Data Reduces Sycophancy in Large Language Models , author =. Proceedings of ICLR , year =
-
[49]
Poushter, Jacob and Smerkovich, Maria and Fagan, Moira and Prozorovsky, Andrew , title =
-
[50]
, title =
Zajonc, Robert B. , title =. Journal of Personality and Social Psychology, Monograph Supplement , year =
-
[51]
Journal of Verbal Learning and Verbal Behavior , volume =
Frequency and the Conference of Referential Validity , author =. Journal of Verbal Learning and Verbal Behavior , volume =
-
[52]
arXiv preprint arXiv:2311.16867 , year=
The Falcon Series of Open Language Models , author=. arXiv preprint arXiv:2311.16867 , year=
-
[53]
arXiv preprint arXiv:2503.19786 , year=
Gemma 3 Technical Report , author=. arXiv preprint arXiv:2503.19786 , year=
-
[54]
arXiv preprint arXiv:2407.21783 , year=
The Llama 3 Herd of Models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[55]
and Sablayrolles, Alexandre and Mensch, Arthur and others , journal=
Jiang, Albert Q. and Sablayrolles, Alexandre and Mensch, Arthur and others , journal=. Mistral
- [56]
-
[57]
Yi: Open Foundation Models by 01
Young, Alex and Chen, Bei and Li, Chao and others , journal=. Yi: Open Foundation Models by 01
-
[58]
2024 , howpublished =
Open. 2024 , howpublished =
2024
-
[59]
Krichevsky, R. E. and Trofimov, V. K. , title =. IEEE Transactions on Information Theory , year =
-
[60]
Wiktionary: The Free Dictionary , year =
-
[61]
Comparing LLM-generated and human-authored news text using formal syntactic theory , author =. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month = jul, year =. doi:10.18653/v1/2025.acl-long.443 , note =
-
[62]
Artificial Intelligence Review , volume =
Contrasting Linguistic Patterns in Human and LLM-Generated News Text , author =. Artificial Intelligence Review , volume =. 2024 , doi =
2024
-
[63]
2024 , note =
Do LLMs write like humans? Variation in grammatical and rhetorical styles , author =. 2024 , note =
2024
-
[64]
spaCy: Industrial-Strength Natural Language Processing in Python , author =. Zenodo , year =. doi:10.5281/zenodo.1212303 , url =
-
[65]
Proceedings of the Twelfth Language Resources and Evaluation Conference , year =
Universal Dependencies v2: An Evergrowing Multilingual Treebank Collection , author =. Proceedings of the Twelfth Language Resources and Evaluation Conference , year =
-
[66]
CoNLL 2017 Shared Task: Multilingual Parsing from Raw Text to Universal Dependencies , author =. Proceedings of the CoNLL 2017 Shared Task: Multilingual Parsing from Raw Text to Universal Dependencies , year =. doi:10.18653/v1/K17-3001 , url =
-
[67]
2023 , howpublished =
Verbosity Bias in Preference Labeling by Large Language Models , author =. 2023 , howpublished =
2023
-
[68]
Verbalized Sampling: How to Mitigate Mode Collapse and Unlock
Zhang, Xuanchang and Xiong, Wei and Chen, Lichang and Zhou, Tianyi and Huang, Heng and Zhang, Tong , journal =. Verbalized Sampling: How to Mitigate Mode Collapse and Unlock. 2025 , url =
2025
-
[69]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , year =
What Comes Next? Evaluating Uncertainty in Neural Text Generators Against Human Production Variability , author =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , year =. doi:10.18653/v1/2023.emnlp-main.887 , url =
-
[70]
Proceedings of the 24th Conference on Computational Natural Language Learning , year =
Cloze Distillation: Improving Neural Language Models with Human Next-Word Prediction , author =. Proceedings of the 24th Conference on Computational Natural Language Learning , year =. doi:10.18653/v1/2020.conll-1.49 , url =
-
[71]
2001 , publisher=
English Words: History and Structure , author=. 2001 , publisher=
2001
-
[72]
Language and Speech , volume=
The formality of the Latinate lexicon in English , author=. Language and Speech , volume=. 1981 , publisher=
1981
-
[73]
Can Grammarly and ChatGPT accelerate language change? AI-powered technologies and their impact on the English language: wordiness vs. conciseness , author=. arXiv preprint arXiv:2502.04324 , year=
-
[74]
TIME , year =
Perrigo, Billy , title =. TIME , year =
-
[75]
arXiv preprint arXiv:2603.18161 , year=
How LLMs Distort Our Written Language , author=. arXiv preprint arXiv:2603.18161 , year=
-
[76]
and Harman, Mark and Syme, Don and Noppen, Joost and Yannakoudakis, Helen and Nauck, Detlef , journal=
Twist, Lukas and Zhang, Jie M. and Harman, Mark and Syme, Don and Noppen, Joost and Yannakoudakis, Helen and Nauck, Detlef , journal=. A Study of
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.