{α}Depth: Learning Single-Pass Soft Boundary Decomposition for Stereo Conversion
Pith reviewed 2026-06-28 22:35 UTC · model grok-4.3
The pith
αDepth decomposes soft boundaries via layered color and depth estimates plus circular alpha representation for accurate stereo conversion without manual guidance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
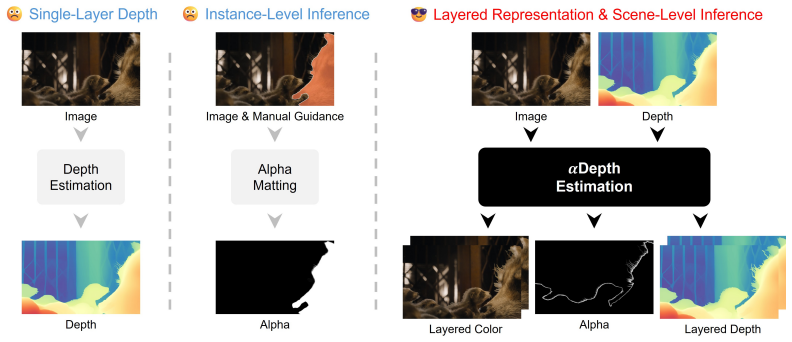
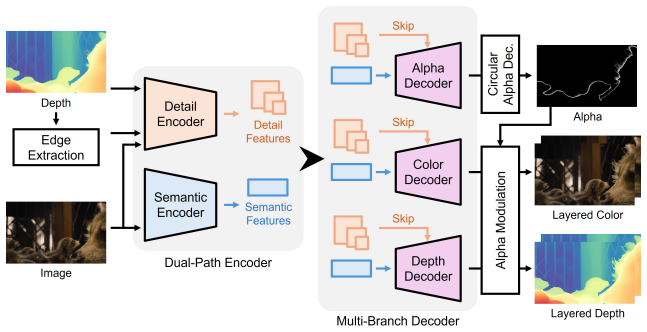
αDepth is a layered representation that resolves mixed color and depth ambiguity by estimating layered color and depth values at soft boundaries and employs Circular Alpha Representation (CAR) to shift from global target extraction to local boundary decomposition, enabling efficient scene-level inference without manual guidance.
What carries the argument
Circular Alpha Representation (CAR), a local boundary decomposition method that replaces global target extraction to support multi-target scene inference.
If this is right
- Eliminates background bleeding at soft boundaries in stereo output.
- Removes structural distortions at soft boundaries.
- Supports single-pass processing in complex multi-target scenes.
- Removes the need for user intervention required by prior matting methods.
Where Pith is reading between the lines
- The local decomposition approach could extend to temporal consistency checks in video stereo conversion.
- Layered boundary handling may improve related tasks such as instance-aware image synthesis.
- Replacing global matting with boundary-focused representations might apply to other vision problems involving transparency.
Load-bearing premise
That estimating layered color and depth values combined with CAR enables accurate scene-level inference without manual guidance even in complex multi-target scenes.
What would settle it
Stereo conversion results on a test set of complex multi-object scenes that still exhibit background bleeding or structural distortions at soft boundaries.
Figures














read the original abstract
Accurately modeling soft boundaries, e.g., hair and defocus blur, is a fundamental challenge in stereo conversion due to the ambiguous blending of foreground and background. Existing depth models primarily predict single-layer depth, leading to ambiguity in depth correspondence at soft boundaries. While matting techniques can capture opacity for layered modeling, they often struggle in complex scenes with multiple targets and usually require user intervention. This paper introduces {\alpha}Depth, a layered representation that decomposes soft boundaries for high-fidelity stereo conversion. Specifically, we first resolve mixed color and depth ambiguity by estimating layered color and depth values at soft boundaries. Considering complex multi-target scenes, we design a Circular Alpha Representation (CAR) that shifts the paradigm from global target extraction to local boundary decomposition. Unlike prior matting methods restricted to a single foreground/background, CAR enables efficient scene-level inference without manual guidance. Extensive evaluations demonstrate that {\alpha}Depth achieves state-of-the-art performance in stereo conversion, eliminating background bleeding and structural distortions at soft boundaries.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces αDepth, a layered representation for stereo conversion that resolves mixed color and depth ambiguity at soft boundaries via layered estimation and proposes Circular Alpha Representation (CAR) to shift from global extraction to local boundary decomposition, enabling guidance-free scene-level inference in multi-target scenes and claiming SOTA performance with elimination of bleeding and distortions.
Significance. If the central claims hold, the work would offer a meaningful advance for stereo conversion by addressing soft-boundary artifacts without manual intervention, with potential impact on applications requiring accurate layered depth in complex scenes.
major comments (2)
- [Abstract] Abstract: the claim that CAR 'enables efficient scene-level inference without manual guidance' in complex multi-target scenes rests on the untested premise that independent local decompositions compose without residual ambiguity or bleeding; no derivation or bound on composition error is supplied.
- [Abstract] Abstract: assertions of 'state-of-the-art performance' and 'eliminating background bleeding and structural distortions' are unsupported by any quantitative results, baselines, error metrics, or evaluation details.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment point-by-point below and indicate planned revisions to the abstract.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that CAR 'enables efficient scene-level inference without manual guidance' in complex multi-target scenes rests on the untested premise that independent local decompositions compose without residual ambiguity or bleeding; no derivation or bound on composition error is supplied.
Authors: CAR is explicitly formulated for local boundary decomposition so that each soft boundary can be processed independently; the full manuscript shows through multi-target scene experiments that these local results compose into coherent scene-level layered representations without guidance. We agree, however, that the manuscript supplies no formal derivation or composition-error bound. We will revise the abstract to frame the claim as empirically validated rather than theoretically guaranteed. revision: partial
-
Referee: [Abstract] Abstract: assertions of 'state-of-the-art performance' and 'eliminating background bleeding and structural distortions' are unsupported by any quantitative results, baselines, error metrics, or evaluation details.
Authors: The abstract summarizes results that are quantified in the manuscript (comparisons to prior depth and matting baselines, PSNR/SSIM and perceptual metrics on stereo conversion, and visual ablation of bleeding/distortion). To address the concern that the abstract itself lacks supporting detail, we will revise it to reference the key quantitative findings and evaluation protocol. revision: yes
Circularity Check
No circularity detectable; derivation chain not shown
full rationale
The provided abstract and context contain no equations, derivations, parameter fits, or self-citations. CAR is introduced descriptively as a shift to local decomposition, but no mathematical steps are exhibited that could reduce a claimed prediction or uniqueness result to its own inputs by construction. Per the hard rules, absence of quotable reductions means score 0 and empty steps list.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Circular Alpha Representation (CAR)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Recammaster: Camera-controlled generative rendering from a single video
Jianhong Bai, Menghan Xia, Xiao Fu, Xintao Wang, Lianrui Mu, Jinwen Cao, Zuozhu Liu, Haoji Hu, Xiang Bai, Pengfei Wan, et al. Recammaster: Camera-controlled generative rendering from a single video. InICCV, 2025
2025
-
[2]
Depth pro: Sharp monocular metric depth in less than a second
Alexey Bochkovskiy, Amaël Delaunoy, Hugo Germain, Marcel Santos, Yichao Zhou, Stephan Richter, and Vladlen Koltun. Depth pro: Sharp monocular metric depth in less than a second. InICLR, 2025
2025
-
[3]
Video depth anything: Consistent depth estimation for super-long videos
Sili Chen, Hengkai Guo, Shengnan Zhu, Feihu Zhang, Zilong Huang, Jiashi Feng, and Bingyi Kang. Video depth anything: Consistent depth estimation for super-long videos. InCVPR, pages 22831–22840, 2025
2025
-
[4]
Peng Dai, Feitong Tan, Qiangeng Xu, David Futschik, Ruofei Du, Sean Fanello, Xiaojuan Qi, and Yinda Zhang. Svg: 3d stereoscopic video generation via denoising frame matrix.arXiv preprint arXiv:2407.00367, 2024
-
[5]
Boosting robustness of image matting with context assembling and strong data augmentation
Yutong Dai, Brian Price, He Zhang, and Chunhua Shen. Boosting robustness of image matting with context assembling and strong data augmentation. InCVPR, pages 11707–11716, 2022
2022
-
[6]
Simoncelli
Keyan Ding, Kede Ma, Shiqi Wang, and Eero P. Simoncelli. Image quality assessment: Unifying structure and texture similarity.IEEE TPAMI, 44(5):2567–2581, 2022
2022
-
[7]
Cat3d: Create anything in 3d with multi-view diffusion models
Ruiqi Gao, Aleksander Holynski, Philipp Henzler, Arthur Brussee, Ricardo Martin-Brualla, Pratul Srini- vasan, Jonathan T Barron, and Ben Poole. Cat3d: Create anything in 3d with multi-view diffusion models. InNeurIPS, 2024
2024
-
[8]
Generative video matting
Yongtao Ge, Kangyang Xie, Guangkai Xu, Li Ke, Mingyu Liu, Longtao Huang, Hui Xue, Hao Chen, and Chunhua Shen. Generative video matting. InSIGGRAPH, pages 1–10, 2025
2025
-
[9]
Michal Geyer, Omer Tov, Linyi Jin, Richard Tucker, Inbar Mosseri, Tali Dekel, and Noah Snavely. Eye2eye: A simple approach for monocular-to-stereo video synthesis.arXiv preprint arXiv:2505.00135, 2025
-
[10]
Repurposing diffusion-based image generators for monocular depth estimation
Bingxin Ke, Anton Obukhov, Shengyu Huang, Nando Metzger, Rodrigo Caye Daudt, and Konrad Schindler. Repurposing diffusion-based image generators for monocular depth estimation. InCVPR, pages 9492–9502, 2024
2024
-
[11]
Modnet: Real-time trimap-free portrait matting via objective decomposition
Zhanghan Ke, Jiayu Sun, Kaican Li, Qiong Yan, and Rynson WH Lau. Modnet: Real-time trimap-free portrait matting via objective decomposition. InAAAI, volume 36, pages 1140–1147, 2022
2022
-
[12]
Zim: Zero-shot image matting for anything
Beomyoung Kim, Chanyong Shin, Joonhyun Jeong, Hyungsik Jung, Se-Yun Lee, Sewhan Chun, Dong- Hyun Hwang, and Joonsang Yu. Zim: Zero-shot image matting for anything. InICCV, pages 23828–23838, 2025
2025
-
[13]
Matting anything
Jiachen Li, Jitesh Jain, and Humphrey Shi. Matting anything. InCVPR, pages 1775–1785, 2024
2024
-
[14]
PhD thesis, University of Sydney, 2020
Jizhizi Li.End-to-end Animal Matting. PhD thesis, University of Sydney, 2020
2020
-
[15]
Privacy-preserving portrait matting
Jizhizi Li, Sihan Ma, Jing Zhang, and Dacheng Tao. Privacy-preserving portrait matting. InACMMM, pages 3501–3509, 2021
2021
-
[16]
Deep automatic natural image matting
Jizhizi Li, Jing Zhang, and Dacheng Tao. Deep automatic natural image matting. InIJCAI. International Joint Conferences on Artificial Intelligence Organization, 2021
2021
-
[17]
Megadepth: Learning single-view depth prediction from internet photos
Zhengqi Li and Noah Snavely. Megadepth: Learning single-view depth prediction from internet photos. In CVPR, pages 2041–2050, 2018
2041
-
[18]
Depth Anything 3: Recovering the Visual Space from Any Views
Haotong Lin, Sili Chen, Junhao Liew, Donny Y Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Robust high-resolution video matting with temporal guidance
Shanchuan Lin, Linjie Yang, Imran Saleemi, and Soumyadip Sengupta. Robust high-resolution video matting with temporal guidance. InWACV, pages 238–247, 2022
2022
-
[20]
Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision
Lu Ling, Yichen Sheng, Zhi Tu, Wentian Zhao, Cheng Xin, Kun Wan, Lantao Yu, Qianyu Guo, Zixun Yu, Yawen Lu, et al. Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision. InCVPR, pages 22160–22169, 2024
2024
-
[21]
What is the fractional laplacian? a comparative review with new results.Journal of Computational Physics, 404:109009, 2020
Anna Lischke, Guofei Pang, Mamikon Gulian, Fangying Song, Christian Glusa, Xiaoning Zheng, Zhiping Mao, Wei Cai, Mark M Meerschaert, Mark Ainsworth, et al. What is the fractional laplacian? a comparative review with new results.Journal of Computational Physics, 404:109009, 2020. 10
2020
-
[22]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InICLR, 2019
2019
-
[23]
Stereo conversion with disparity- aware warping, compositing and inpainting
Lukas Mehl, Andrés Bruhn, Markus Gross, and Christopher Schroers. Stereo conversion with disparity- aware warping, compositing and inpainting. InWACV, pages 4260–4269, 2024
2024
-
[24]
Elastic3d: Controllable stereo video conversion with guided latent decoding
Nando Metzger, Prune Truong, Goutam Bhat, Konrad Schindler, and Federico Tombari. Elastic3d: Controllable stereo video conversion with guided latent decoding. InCVPR, 2026
2026
-
[25]
Softmax splatting for video frame interpolation
Simon Niklaus and Feng Liu. Softmax splatting for video frame interpolation. InCVPR, pages 5437–5446, 2020
2020
-
[26]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Matteformer: Transformer- based image matting via prior-tokens
GyuTae Park, SungJoon Son, JaeYoung Yoo, SeHo Kim, and Nojun Kwak. Matteformer: Transformer- based image matting via prior-tokens. InCVPR, pages 11696–11706, 2022
2022
-
[28]
UniDepthV2: Universal Monocular Metric Depth Estimation Made Simpler
Luigi Piccinelli, Christos Sakaridis, Yung-Hsu Yang, Mattia Segu, Siyuan Li, Wim Abbeloos, and Luc Van Gool. Unidepthv2: Universal monocular metric depth estimation made simpler.arXiv preprint arXiv:2502.20110, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Unidepth: Universal monocular metric depth estimation
Luigi Piccinelli, Yung-Hsu Yang, Christos Sakaridis, Mattia Segu, Siyuan Li, Luc Van Gool, and Fisher Yu. Unidepth: Universal monocular metric depth estimation. InCVPR, pages 10106–10116, 2024
2024
-
[30]
Attention-guided hierarchical structure aggregation for image matting
Yu Qiao, Yuhao Liu, Xin Yang, Dongsheng Zhou, Mingliang Xu, Qiang Zhang, and Xiaopeng Wei. Attention-guided hierarchical structure aggregation for image matting. InCVPR, June 2020
2020
-
[31]
Vision transformers for dense prediction
René Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. Vision transformers for dense prediction. InICCV, pages 12179–12188, 2021
2021
-
[32]
Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer.PAMI, 44(3):1623–1637, 2020
René Ranftl, Katrin Lasinger, David Hafner, Konrad Schindler, and Vladlen Koltun. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer.PAMI, 44(3):1623–1637, 2020
2020
-
[33]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InCVPR, pages 10684–10695, 2022
2022
-
[34]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InInternational Conference on Medical image computing and computer-assisted intervention, pages 234–241. Springer, 2015
2015
-
[35]
Guibao Shen, Yihua Du, Wenhang Ge, Jing He, Chirui Chang, Donghao Zhou, Zhen Yang, Luozhou Wang, Xin Tao, and Ying-Cong Chen. Stereopilot: Learning unified and efficient stereo conversion via generative priors.arXiv preprint arXiv:2512.16915, 2025
-
[36]
Nina Shvetsova, Goutam Bhat, Prune Truong, Hilde Kuehne, and Federico Tombari. M2svid: End-to-end inpainting and refinement for monocular-to-stereo video conversion.arXiv preprint arXiv:2505.16565, 2025
-
[37]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Thomas Unterthiner, Sjoerd Van Steenkiste, Karol Kurach, Raphael Marinier, Marcin Michalski, and Sylvain Gelly. Towards accurate generative models of video: A new metric & challenges.arXiv preprint arXiv:1812.01717, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[38]
Stereodiffusion: Training-free stereo image generation using latent diffusion models
Lezhong Wang, Jeppe Revall Frisvad, Mark Bo Jensen, and Siavash Arjomand Bigdeli. Stereodiffusion: Training-free stereo image generation using latent diffusion models. InCVPR, pages 7416–7425, 2024
2024
-
[39]
Moge: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision
Ruicheng Wang, Sicheng Xu, Cassie Dai, Jianfeng Xiang, Yu Deng, Xin Tong, and Jiaolong Yang. Moge: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision. InCVPR, pages 5261–5271, 2025
2025
-
[40]
Moge-2: Accurate monocular geometry with metric scale and sharp details
Ruicheng Wang, Sicheng Xu, Yue Dong, Yu Deng, Jianfeng Xiang, Zelong Lv, Guangzhong Sun, Xin Tong, and Jiaolong Yang. Moge-2: Accurate monocular geometry with metric scale and sharp details. In NIPS, 2025
2025
-
[41]
Deep3d: Fully automatic 2d-to-3d video conversion with deep convolutional neural networks
Junyuan Xie, Ross Girshick, and Ali Farhadi. Deep3d: Fully automatic 2d-to-3d video conversion with deep convolutional neural networks. InEuropean conference on computer vision, pages 842–857. Springer, 2016. 11
2016
-
[42]
Pixel-perfect depth with semantics-prompted diffusion transformers
Gangwei Xu, Haotong Lin, Hongcheng Luo, Xianqi Wang, Jingfeng Yao, Lianghui Zhu, Yuechuan Pu, Cheng Chi, Haiyang Sun, Bing Wang, Guang Chen, Hangjun Ye, Sida Peng, and Xin Yang. Pixel-perfect depth with semantics-prompted diffusion transformers. InNIPS, 2025
2025
-
[43]
Deep image matting
Ning Xu, Brian Price, Scott Cohen, and Thomas Huang. Deep image matting. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2970–2979, 2017
2017
-
[44]
Depth anything: Unleashing the power of large-scale unlabeled data
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything: Unleashing the power of large-scale unlabeled data. InCVPR, pages 10371–10381, 2024
2024
-
[45]
Depth anything v2
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything v2. InNeurIPS, 2024
2024
-
[46]
Matanyone 2: Scaling video matting via a learned quality evaluator
Peiqing Yang, Shangchen Zhou, Kai Hao, and Qingyi Tao. Matanyone 2: Scaling video matting via a learned quality evaluator. InCVPR, 2026
2026
-
[47]
Matanyone: Stable video matting with consistent memory propagation
Peiqing Yang, Shangchen Zhou, Jixin Zhao, Qingyi Tao, and Chen Change Loy. Matanyone: Stable video matting with consistent memory propagation. InCVPR, pages 7299–7308, 2025
2025
-
[48]
Vitmatte: Boosting image matting with pre-trained plain vision transformers.Information Fusion, 103:102091, 2024
Jingfeng Yao, Xinggang Wang, Shusheng Yang, and Baoyuan Wang. Vitmatte: Boosting image matting with pre-trained plain vision transformers.Information Fusion, 103:102091, 2024
2024
-
[49]
Wei Yin, Xinlong Wang, Chunhua Shen, Yifan Liu, Zhi Tian, Songcen Xu, Changming Sun, and Dou Renyin. Diversedepth: Affine-invariant depth prediction using diverse data.arXiv preprint arXiv:2002.00569, 2020
-
[50]
Mono2stereo: A benchmark and empirical study for stereo conversion
Songsong Yu, Yuxin Chen, Zhongang Qi, Zeke Xie, Yifan Wang, Lijun Wang, Ying Shan, and Huchuan Lu. Mono2stereo: A benchmark and empirical study for stereo conversion. InCVPR, pages 21847–21856, 2025
2025
-
[51]
ViewCrafter: Taming Video Diffusion Models for High-fidelity Novel View Synthesis
Wangbo Yu, Jinbo Xing, Li Yuan, Wenbo Hu, Xiaoyu Li, Zhipeng Huang, Xiangjun Gao, Tien-Tsin Wong, Ying Shan, and Yonghong Tian. Viewcrafter: Taming video diffusion models for high-fidelity novel view synthesis.arXiv preprint arXiv:2409.02048, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InCVPR, pages 586–595, 2018
2018
-
[53]
Betterdepth: Plug-and-play diffusion refiner for zero-shot monocular depth estimation
Xiang Zhang, Bingxin Ke, Hayko Riemenschneider, Nando Metzger, Anton Obukhov, Markus Gross, Konrad Schindler, and Christopher Schroers. Betterdepth: Plug-and-play diffusion refiner for zero-shot monocular depth estimation. InNeurIPS, 2024
2024
-
[54]
High-fidelity novel view synthesis via splatting-guided diffusion
Xiang Zhang, Yang Zhang, Lukas Mehl, Markus Gross, and Christopher Schroers. High-fidelity novel view synthesis via splatting-guided diffusion. InSIGGRAPH, SIGGRAPH Conference Papers ’25, New York, NY , USA, 2025. Association for Computing Machinery
2025
-
[55]
Guardians of the hair: Rescuing soft boundaries in depth, stereo, and novel views
Xiang Zhang, Yang Zhang, Lukas Mehl, Markus Gross, and Christopher Schroers. Guardians of the hair: Rescuing soft boundaries in depth, stereo, and novel views. InCVPR, 2026
2026
-
[56]
Sijie Zhao, Wenbo Hu, Xiaodong Cun, Yong Zhang, Xiaoyu Li, Zhe Kong, Xiangjun Gao, Muyao Niu, and Ying Shan. Stereocrafter: Diffusion-based generation of long and high-fidelity stereoscopic 3d from monocular videos.arXiv preprint arXiv:2409.07447, 2024
-
[57]
Stereo magnification: learning view synthesis using multiplane images.ACM Trans
Tinghui Zhou, Richard Tucker, John Flynn, Graham Fyffe, and Noah Snavely. Stereo magnification: learning view synthesis using multiplane images.ACM Trans. Graph., 37(4), July 2018. 12 Appendix We provide more technical details, experimental results, ablation studies, and qualitative visualizations to support the contributions of ourαDepth approach. Detail...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.