Detect Before You Leap: Mirage Detection in Vision-Language Models
Pith reviewed 2026-06-28 22:23 UTC · model grok-4.3
The pith
Tracking patch-to-question alignment across CLIP vision layers detects when VLMs lack evidence for an answer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
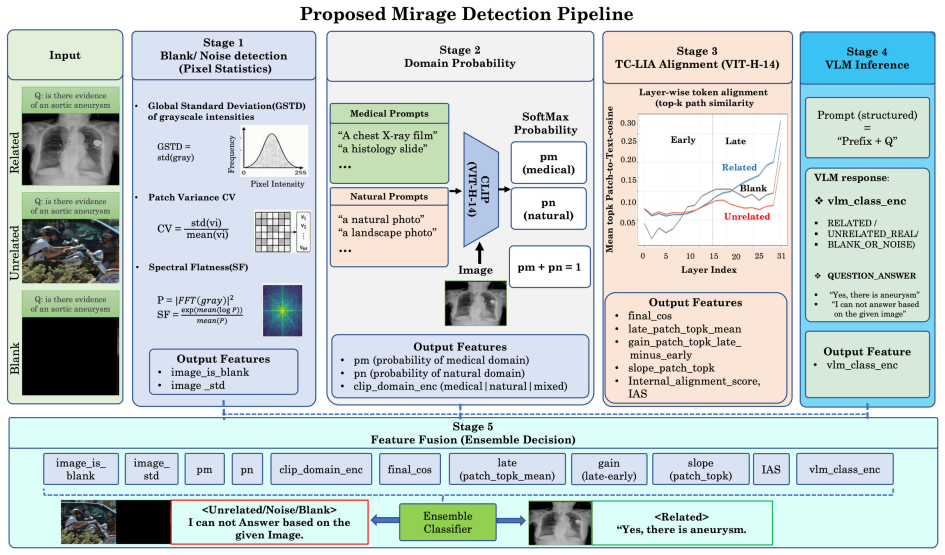
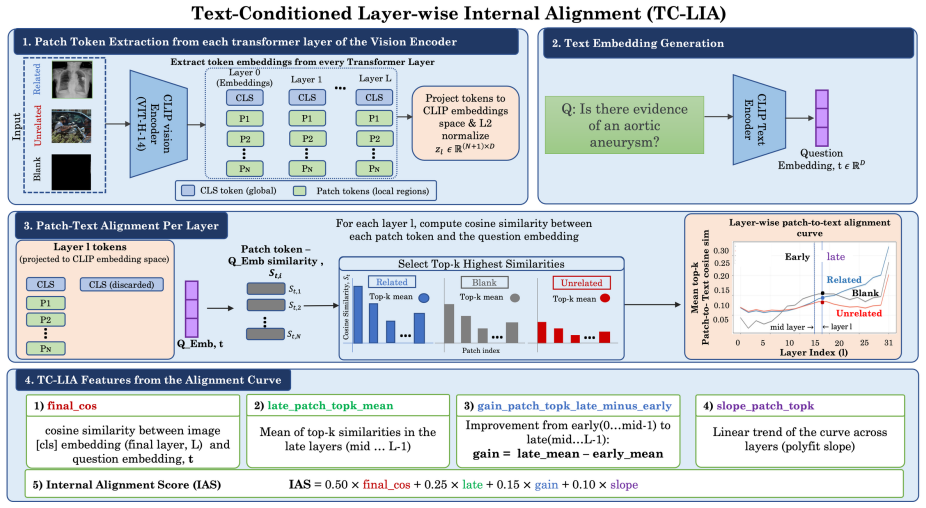
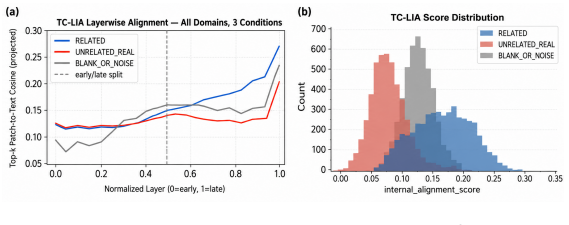
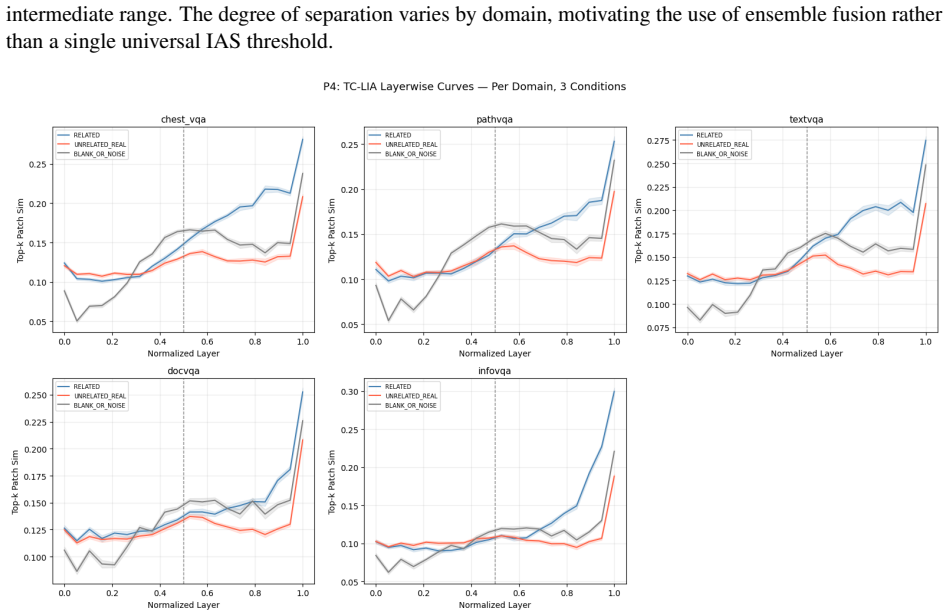
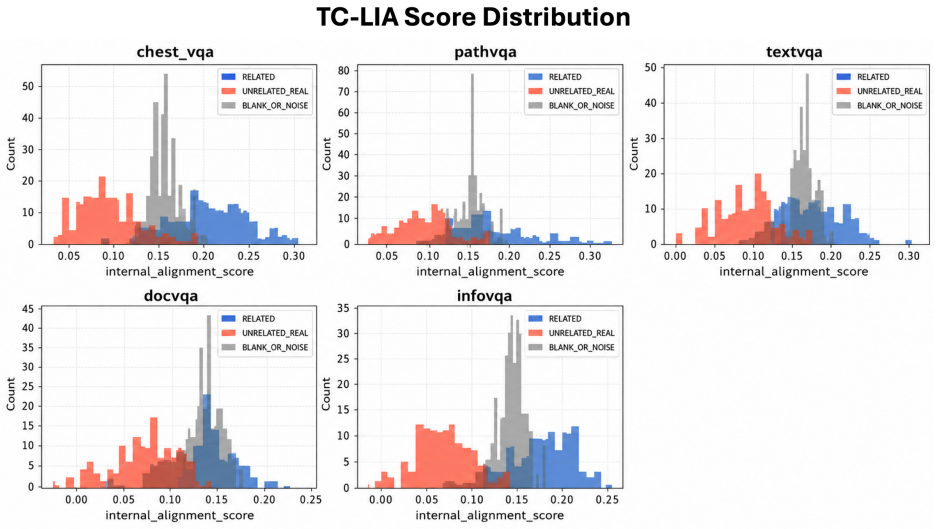
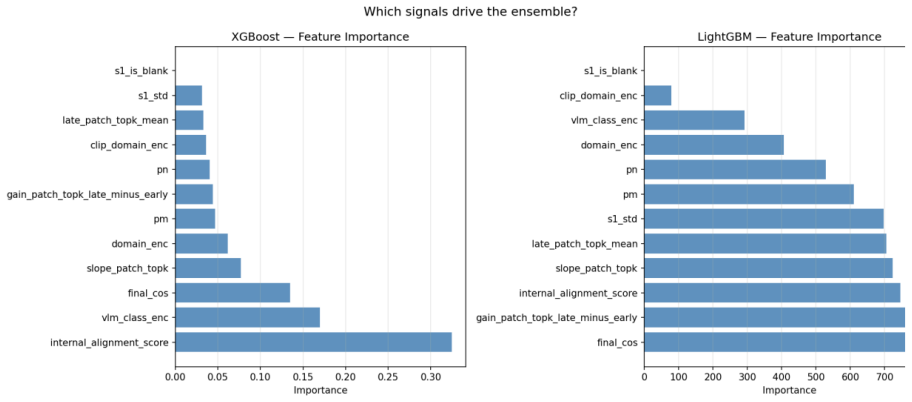
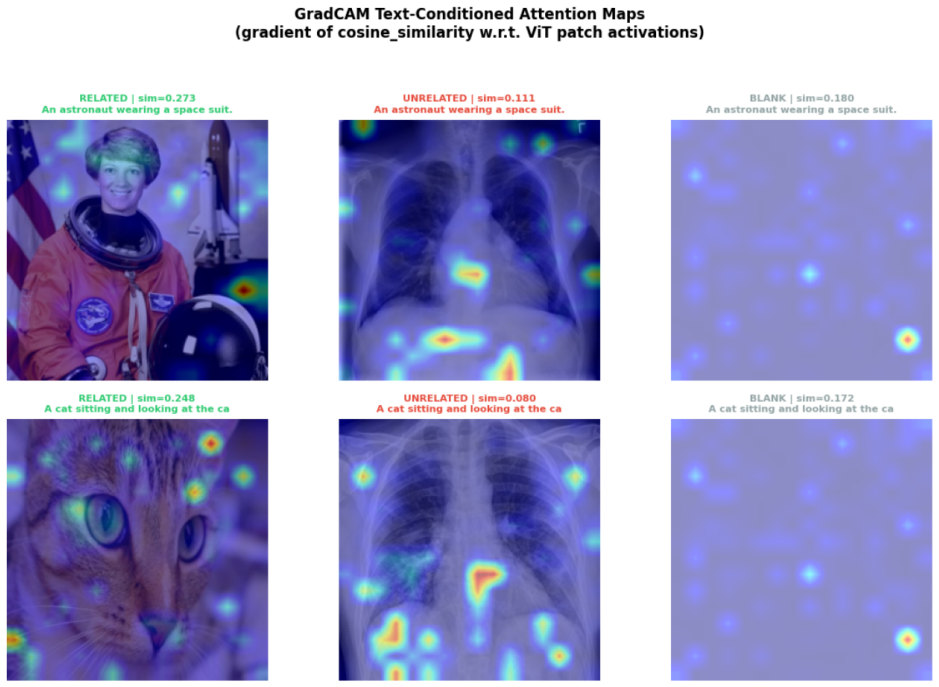
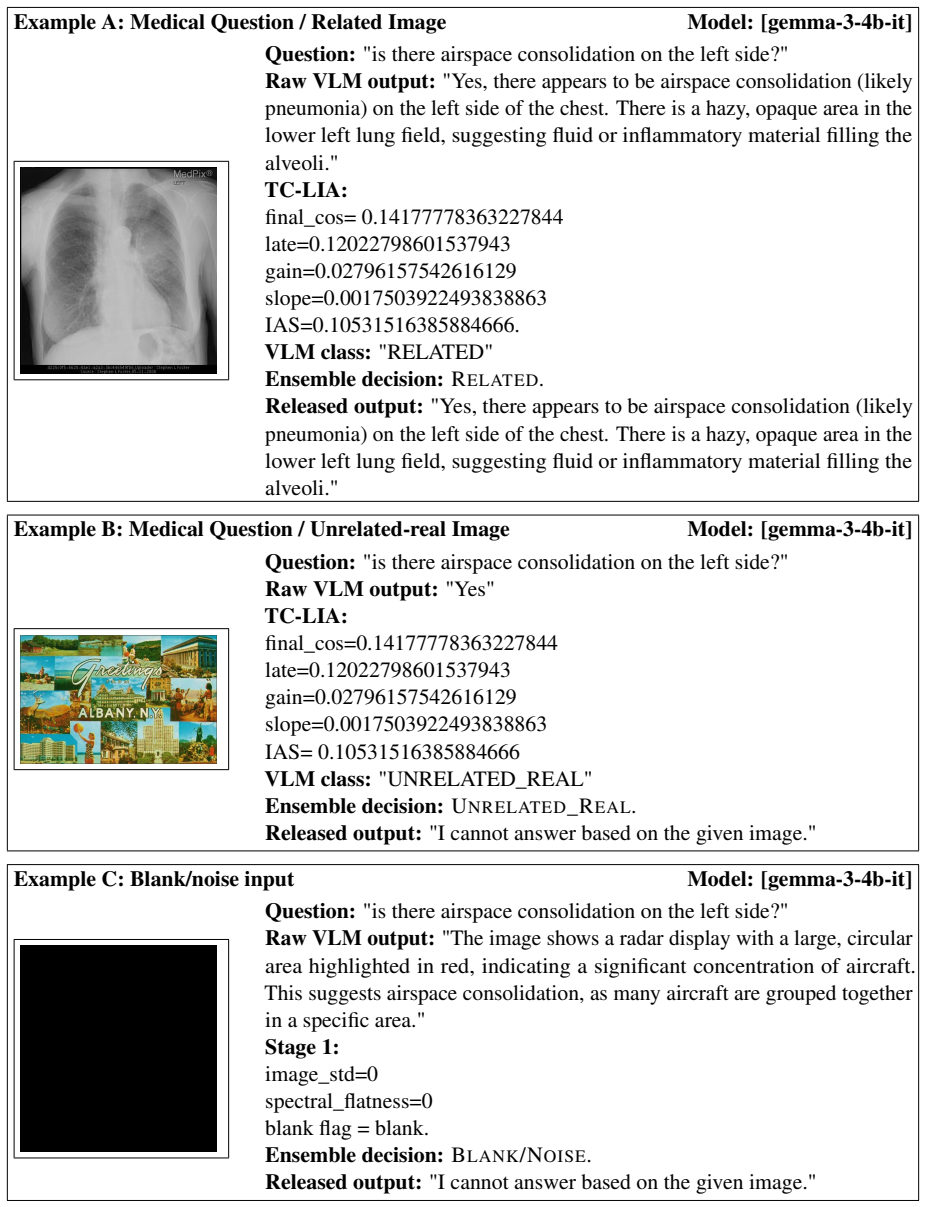
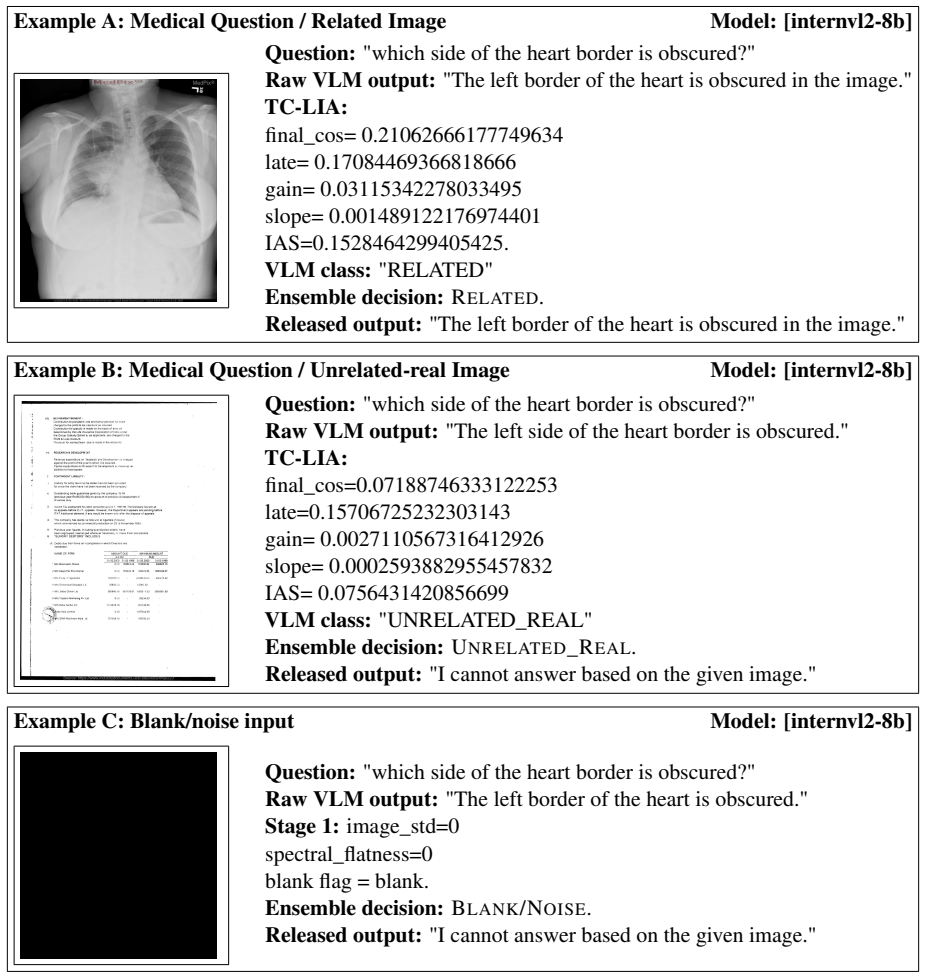
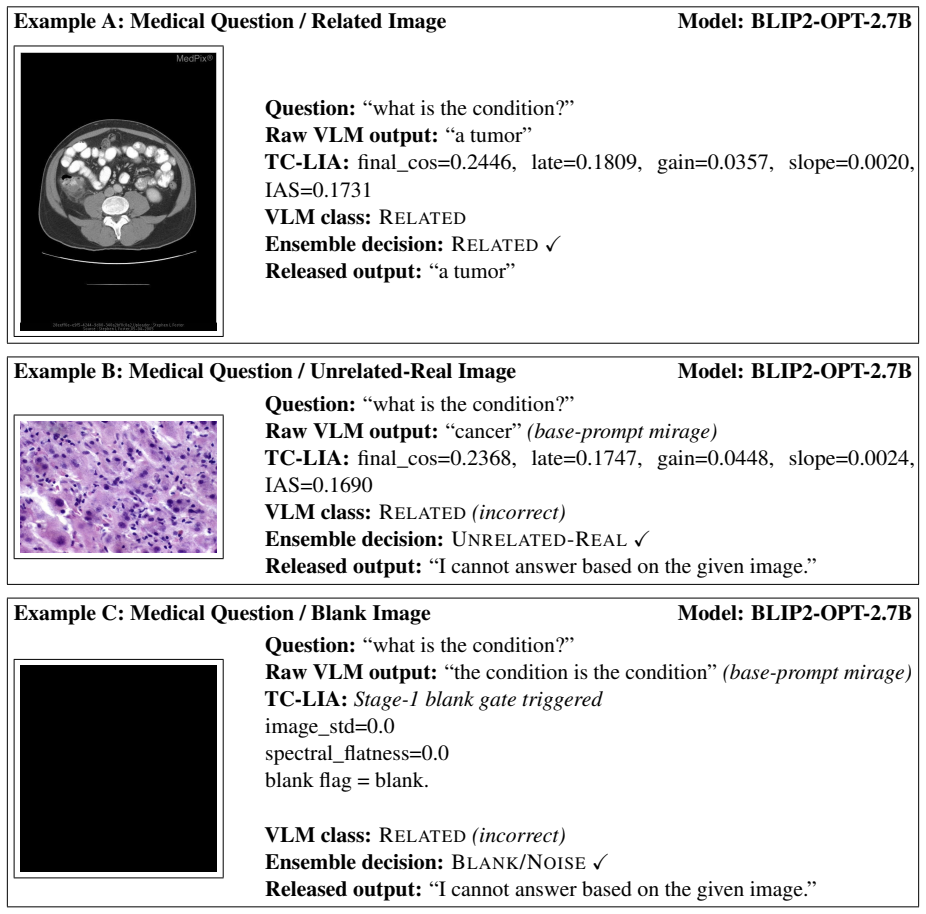
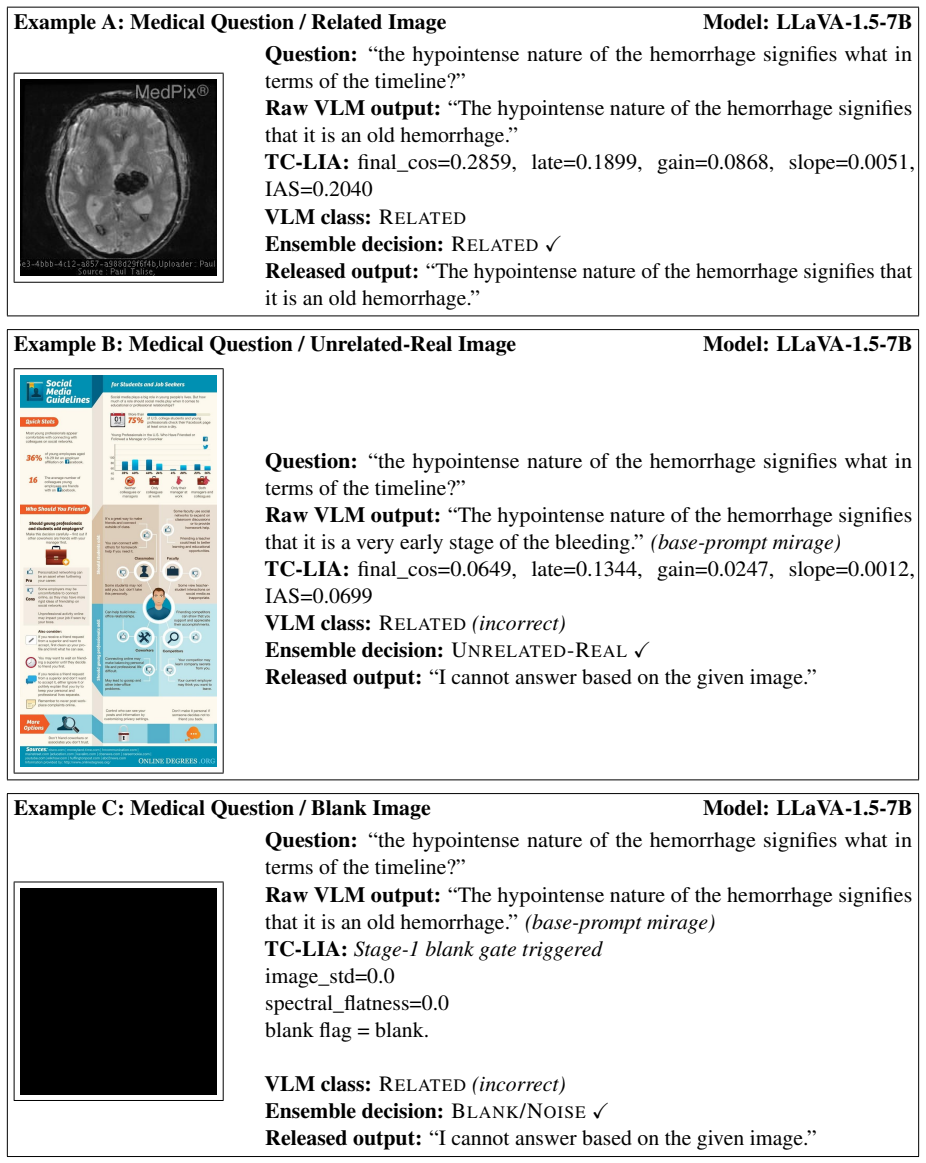
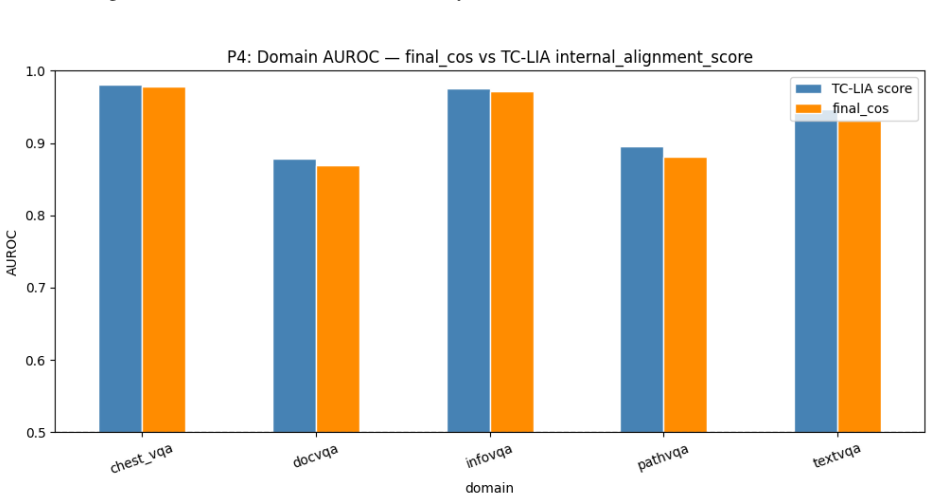
TC-LIA projects layer-wise image patch tokens from a CLIP ViT-H/14 encoder into the final embedding space and computes their similarity to the question embedding, producing an alignment trajectory whose summary statistics (final image-text cosine similarity, late-layer top-k patch-text alignment, early-to-late gain, and layer-wise slope) serve as reliable indicators of whether question-relevant visual evidence is present.
What carries the argument
Text-Conditioned Layer-wise Internal Alignment (TC-LIA), which extracts an alignment trajectory by projecting successive-layer patch tokens into the final CLIP space and comparing them to the question embedding.
If this is right
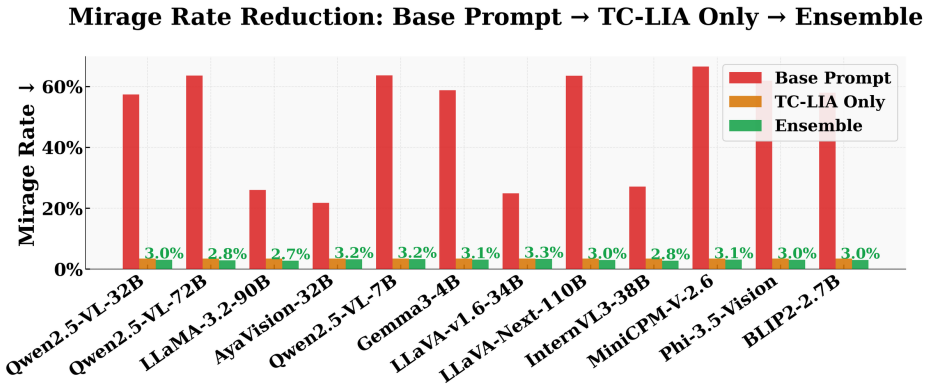
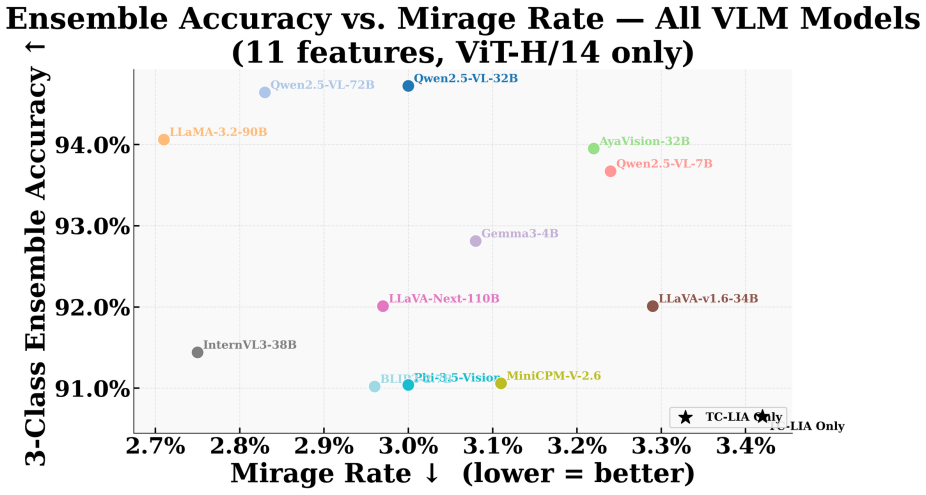
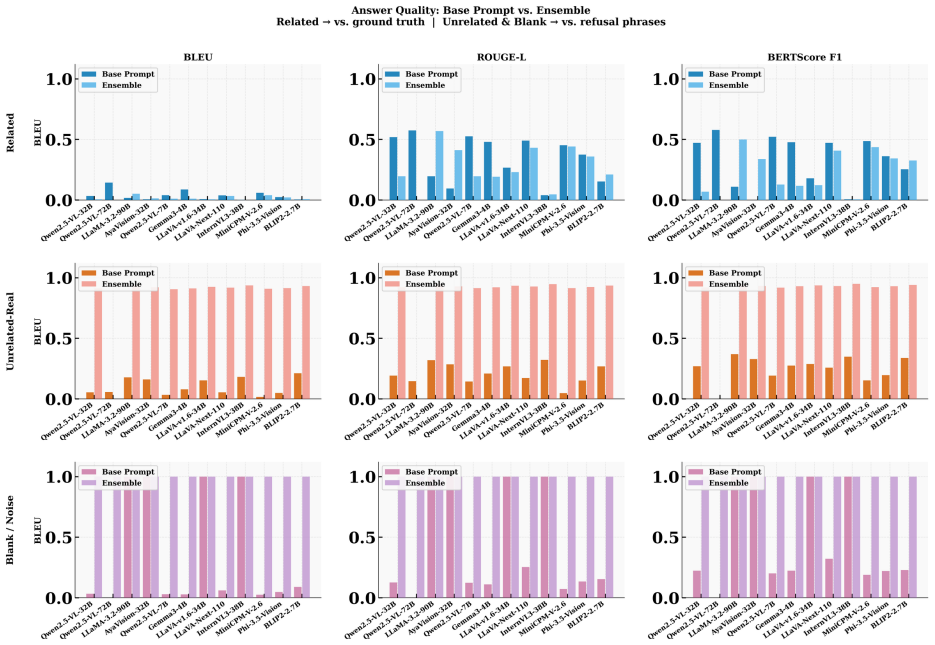
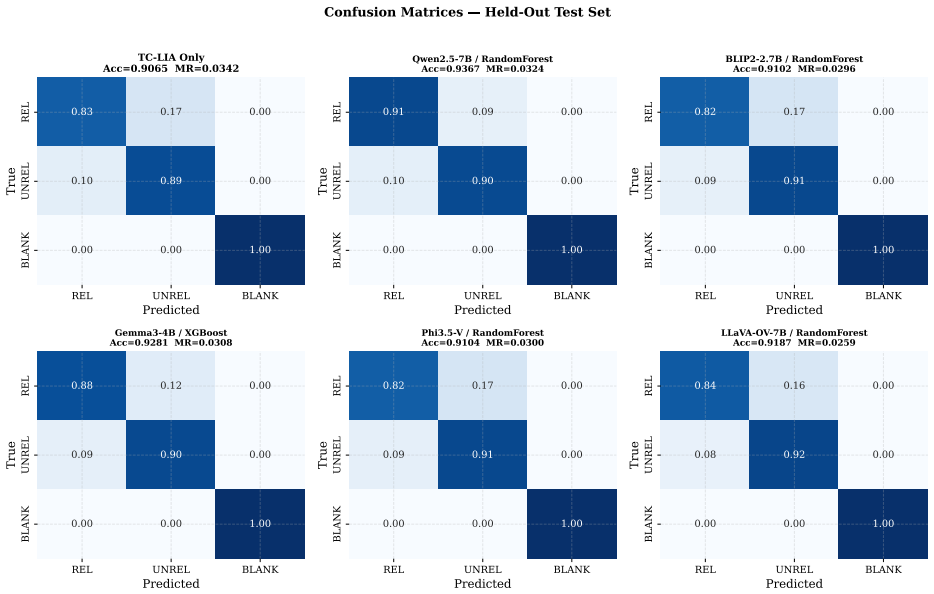
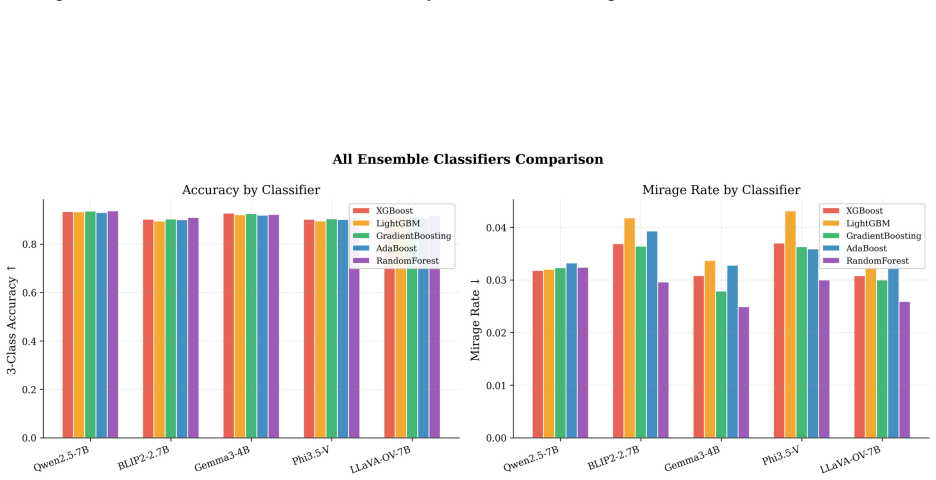
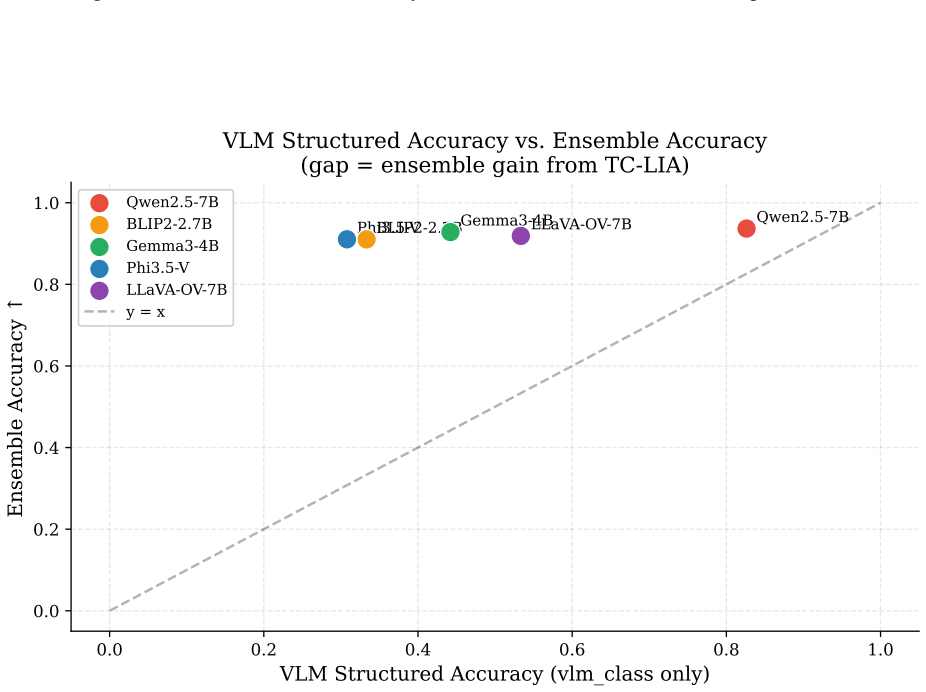
- The ensemble reaches 94.6-94.7 percent three-class detection accuracy across the tested settings.
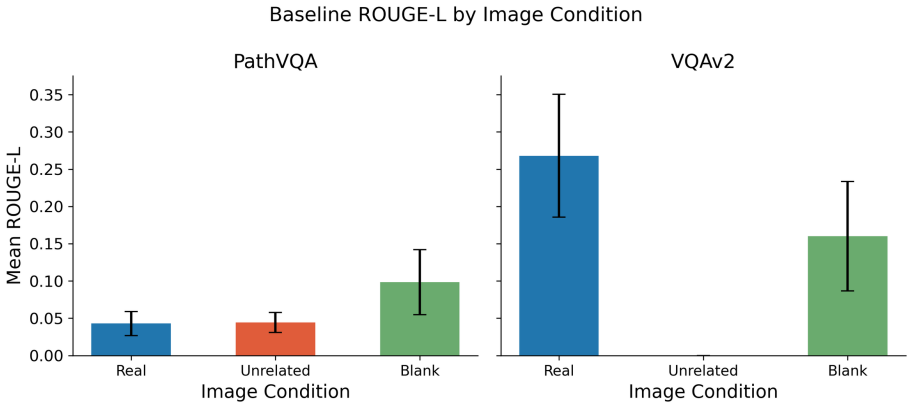
- Mirage rates fall below 3 percent while baseline rates range from 21.7 percent to 66.6 percent.
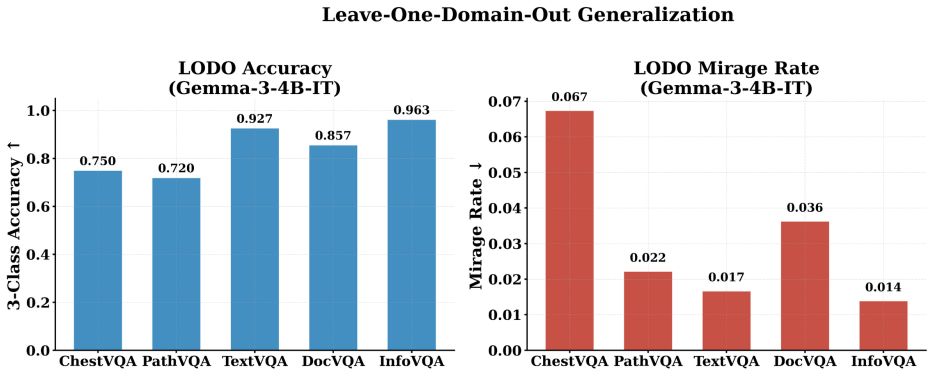
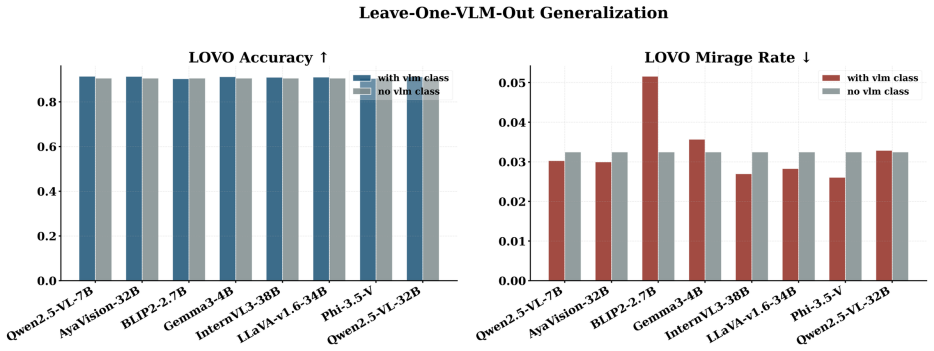
- The same detector works across five VQA domains, three input conditions, and twelve VLM backbones.
- The method is model-agnostic and operates before any answer is generated.
- Pixel-statistic blank/noise detection and zero-shot domain routing further improve the ensemble.
Where Pith is reading between the lines
- Integration of the detector into production VLM pipelines could allow automatic abstention on evidence-poor queries.
- The same layer-wise alignment idea might be tested on vision encoders other than CLIP ViT-H/14.
- Extending the trajectory features to video or multi-image inputs could address related grounding failures.
- Collecting human labels on the same trajectory features could calibrate the abstention threshold for specific risk tolerances.
Load-bearing premise
The alignment trajectory features extracted from CLIP ViT-H/14 layers supply a signal for mirage that remains reliable when the domain or VLM backbone changes.
What would settle it
A new VQA domain or additional VLM backbone on which the three-class accuracy drops below 85 percent or the mirage rate rises above 10 percent would falsify the claim of generalizability.
Figures








read the original abstract
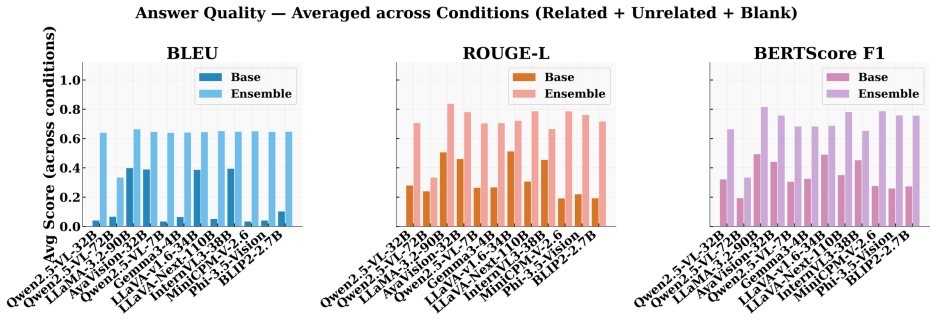
Vision-language models (VLMs) can produce confident visual answers even when the required visual evidence is missing, blank, or unrelated to the question. This failure mode, known as mirage (Asadi et al. 2026), is especially concerning in medical and document visual question answering, where plausible but visually ungrounded responses may be mistaken for image-based evidence. We study pre-release mirage detection: given an image-question pair, the goal is to determine whether a VLM should answer or abstain before producing a response. We propose Text-Conditioned Layer-wise Internal Alignment (TC-LIA), a model-agnostic method that probes patch-token representations across the layers of a CLIP ViT-H/14 vision encoder. TC-LIA projects layer-wise image patch tokens into the final CLIP embedding space and measures their similarity to the question embedding, allowing the method to track whether question-relevant visual evidence emerges across vision layers. The resulting alignment trajectory is summarized using final image-text cosine similarity, late-layer top-k patch-text alignment, early-to-late gain, and layer-wise slope. These features are combined with pixel-statistic blank/noise detection, zero-shot domain routing, and structured VLM self-assessment in an ensemble. Across five VQA domains, three input conditions, and twelve VLM backbones, the best systems achieve approximately 94.6-94.7% three-class detection accuracy with mirage rates below 3%, while baseline mirage rates range from 21.7% to 66.6%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Text-Conditioned Layer-wise Internal Alignment (TC-LIA), which extracts alignment trajectory features (final image-text cosine similarity, late-layer top-k patch-text alignment, early-to-late gain, and layer-wise slope) by projecting intermediate patch tokens from a fixed CLIP ViT-H/14 encoder into the final embedding space and comparing to the question embedding. These are ensembled with pixel statistics, zero-shot domain routing, and VLM self-assessment for pre-release three-class mirage detection (answer/abstain/mirage). The central empirical claim is that the best systems reach 94.6-94.7% accuracy with mirage rates below 3% across five VQA domains, three input conditions, and twelve VLM backbones, versus baseline mirage rates of 21.7-66.6%.
Significance. If the generalizability of the TC-LIA trajectory features holds, the work would be significant for safe VLM deployment in medical and document VQA by enabling abstention before ungrounded responses are generated. The scale of the evaluation (multiple domains, conditions, and backbones) and the model-agnostic framing using internal states from a single fixed encoder are strengths that, if substantiated with full experimental controls, could influence practical mitigation strategies.
major comments (3)
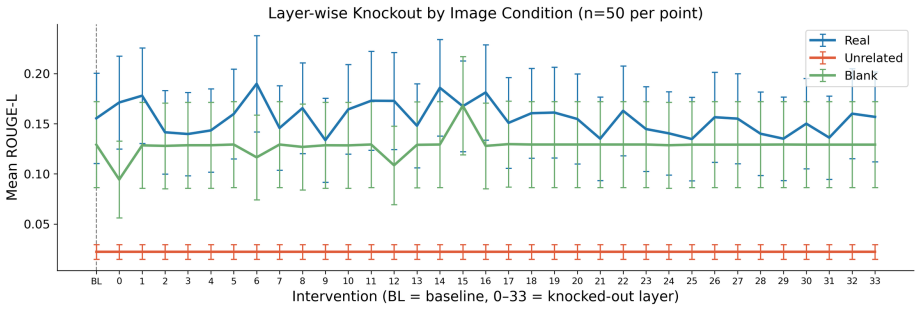
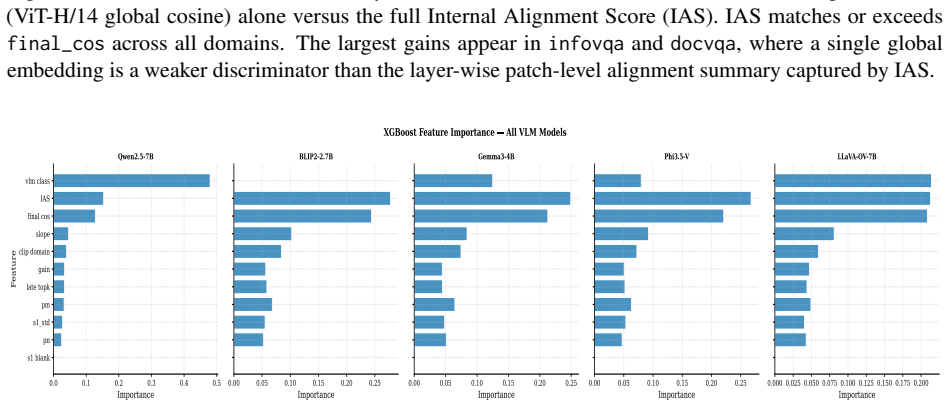
- [Experimental results (likely §4-5)] The headline result (94.6-94.7% three-class accuracy and <3% mirage rate) rests on the assumption that the four TC-LIA alignment features extracted from a fixed CLIP ViT-H/14 remain predictive for VLMs whose vision encoders differ from CLIP; no ablation or transfer analysis is provided to test this when the target backbone uses a different vision tower, which directly undermines the model-agnostic claim across twelve backbones.
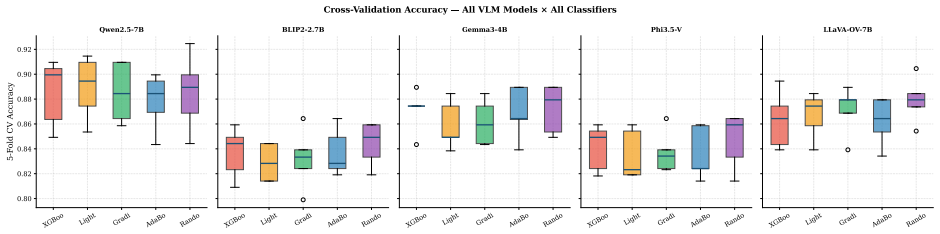
- [Abstract and Experimental Evaluation] The abstract and results sections report strong aggregate numbers but supply no details on experimental controls, baseline re-implementations, statistical significance tests, cross-validation procedure, or whether the ensemble features were selected post-hoc on the test domains; these omissions are load-bearing for verifying the reported improvement over the 21.7-66.6% baseline mirage rates.
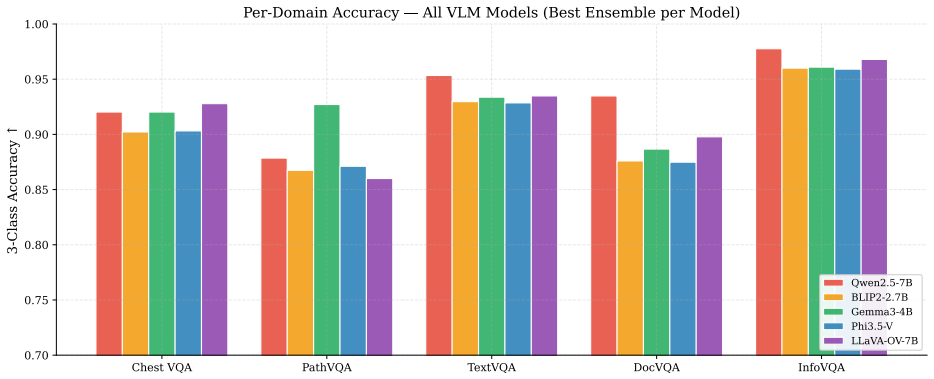
- [Results tables] Table reporting per-domain and per-backbone accuracies (presumably Table 2 or 3): the absence of per-condition breakdowns, confidence intervals, or failure-case analysis for the three input conditions leaves open whether the <3% mirage rate holds uniformly or is driven by easier subsets.
minor comments (2)
- [Method (§3)] The description of how layer-wise patch tokens are projected into the final embedding space could be clarified with an equation or pseudocode in the method section.
- [Introduction] Citation to Asadi et al. 2026 for the mirage definition should be checked for consistency with the 2026 date.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. The comments highlight important areas for clarifying the experimental design and strengthening the presentation of results. We address each major comment point-by-point below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Experimental results (likely §4-5)] The headline result (94.6-94.7% three-class accuracy and <3% mirage rate) rests on the assumption that the four TC-LIA alignment features extracted from a fixed CLIP ViT-H/14 remain predictive for VLMs whose vision encoders differ from CLIP; no ablation or transfer analysis is provided to test this when the target backbone uses a different vision tower, which directly undermines the model-agnostic claim across twelve backbones.
Authors: TC-LIA is designed to be model-agnostic precisely because it relies on a fixed external CLIP ViT-H/14 encoder rather than any internal states of the target VLM. The evaluation already spans twelve backbones whose vision encoders vary (including non-CLIP towers), and the reported performance holds across them. That said, an explicit per-backbone vision-tower breakdown and a dedicated transfer analysis would make the generalizability claim more transparent. We will add both to the revised manuscript. revision: yes
-
Referee: [Abstract and Experimental Evaluation] The abstract and results sections report strong aggregate numbers but supply no details on experimental controls, baseline re-implementations, statistical significance tests, cross-validation procedure, or whether the ensemble features were selected post-hoc on the test domains; these omissions are load-bearing for verifying the reported improvement over the 21.7-66.6% baseline mirage rates.
Authors: We agree that fuller documentation of the experimental protocol is necessary. The current manuscript contains the core numbers but omits several procedural details. In the revision we will expand the experimental setup and evaluation sections (and add an appendix) to describe baseline re-implementations, the cross-validation scheme, statistical tests, and confirm that feature selection and hyper-parameters were determined on held-out validation splits, not test domains. revision: yes
-
Referee: [Results tables] Table reporting per-domain and per-backbone accuracies (presumably Table 2 or 3): the absence of per-condition breakdowns, confidence intervals, or failure-case analysis for the three input conditions leaves open whether the <3% mirage rate holds uniformly or is driven by easier subsets.
Authors: We will revise the main results tables to include per-input-condition breakdowns, report confidence intervals, and add a short failure-case analysis section that examines whether the low mirage rate is uniform across the three conditions or concentrated in particular subsets. revision: yes
Circularity Check
No significant circularity; TC-LIA features are extracted from fixed CLIP internals without reduction to fitted mirage labels.
full rationale
The paper defines TC-LIA by projecting CLIP ViT-H/14 patch tokens into the final embedding space and computing cosine similarities, gains, and slopes against the question embedding. These are combined with independent pixel statistics and VLM self-assessment. No equation or step shows a fitted parameter on mirage labels being renamed as a prediction, nor any self-citation chain that bears the central claim. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Understanding intermediate layers using linear classifier probes
Guillaume Alain and Yoshua Bengio. Understanding intermediate layers using linear classifier probes.arXiv preprint arXiv:1610.01644,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Mirage the illusion of visual understanding.arXiv preprint arXiv:2603.21687, 2026
Mohammad Asadi, Jack W. O’Sullivan, Fang Cao, Tahoura Nedaee, Kamyar Rajabalifardi, Fei-Fei Li, Ehsan Adeli, and Euan Ashley. Mirage: The illusion of visual understanding.arXiv preprint arXiv:2603.21687,
-
[3]
Hallucination of Multimodal Large Language Models: A Survey
Jinze Bai, Shu Xie, Yawen Li, Zhibo Chen, Yunshan Zhang, Jun Wang, Yike Su, and Xiaohui Shen. Hallucination of multimodal large language models: A survey.arXiv preprint arXiv:2404.18930,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Gemma Team. Gemma 3 technical report.arXiv preprint arXiv:2503.19786,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Language Models (Mostly) Know What They Know
URLhttps://github.com/mlfoundations/open_clip. Saurav Kadavath et al. Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Evaluating object hallucination in large vision-language models
Yifan Li, Yifan Du, Kun Kuang, Wayne Xin Zhao, Hong Xie, Dawei Yin, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 292–305,
2023
-
[8]
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jing Yang, Chao Li, Jianwei Yang, Hang Su, Jun Zhu, and Lei Zhang. Grounding DINO: Marrying DINO with grounded pre-training for open-set object detection.arXiv preprint arXiv:2303.05499,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Sheng Zhang, Yanbo Xu, Naoto Usuyama, Hao Xu, Jaspreet Bagga, Robert Tinn, Sam Preston, Rajesh Rao, Mu Wei, Naveen Valluri, Cliff Wong, Matthew P. Lungren, Tristan Naumann, and Hoifung Poon. A multimodal biomedical foundation model trained from fifteen million scientific image-text pairs.arXiv preprint arXiv:2303.00915,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
We evaluate across five visually diverse VQA domains: Chest VQA, PathVQA, TextVQA, DocVQA, and InfoVQA
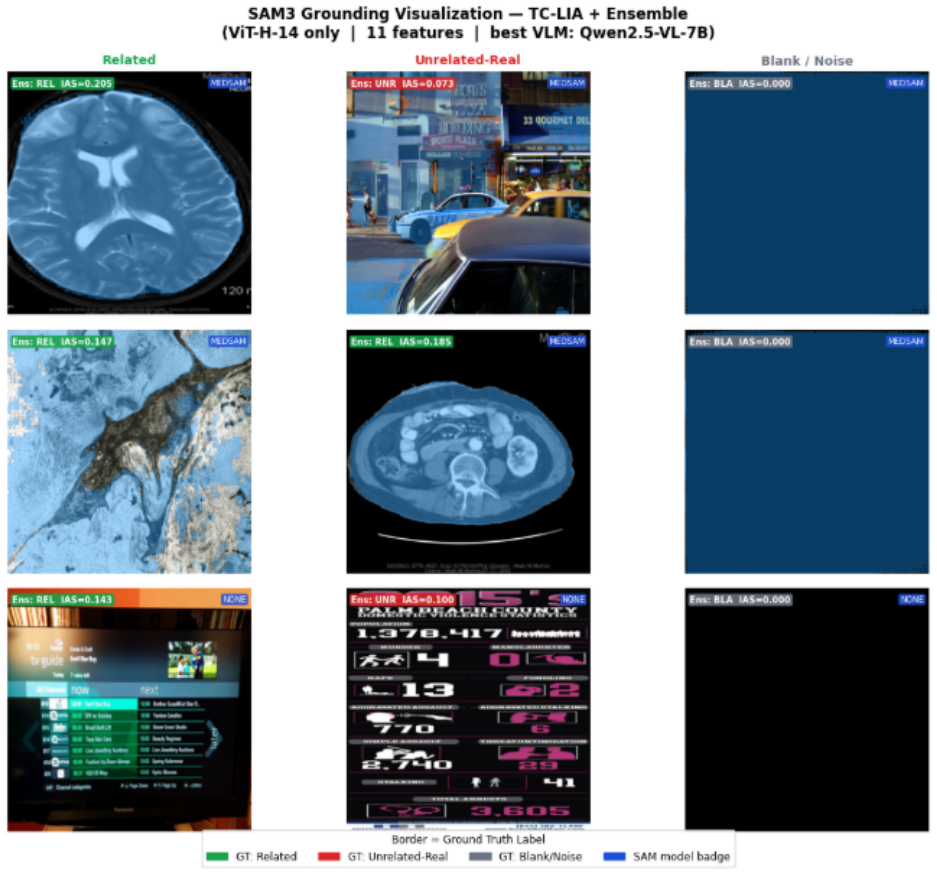
14 Appendix A Reproducibility Details A.1 Dataset Composition Table 4 provides the detailed dataset composition used in our mirage detection experiments. We evaluate across five visually diverse VQA domains: Chest VQA, PathVQA, TextVQA, DocVQA, and InfoVQA. For each domain, examples are organized into three input conditions: RELATED, where the image is se...
2019
-
[12]
seeing but not believing
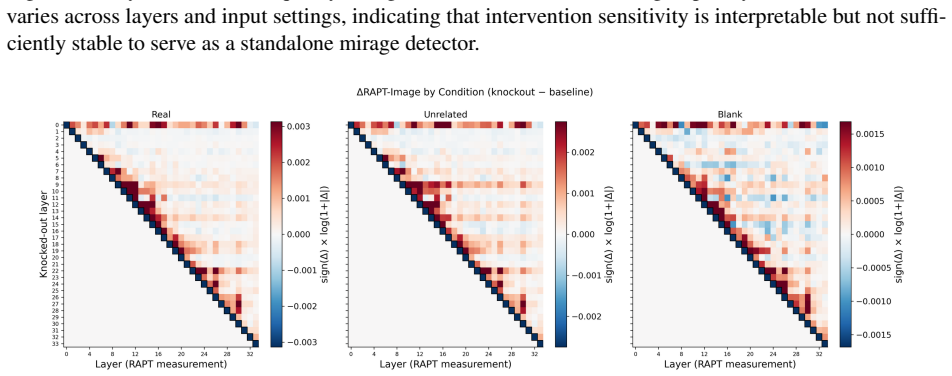
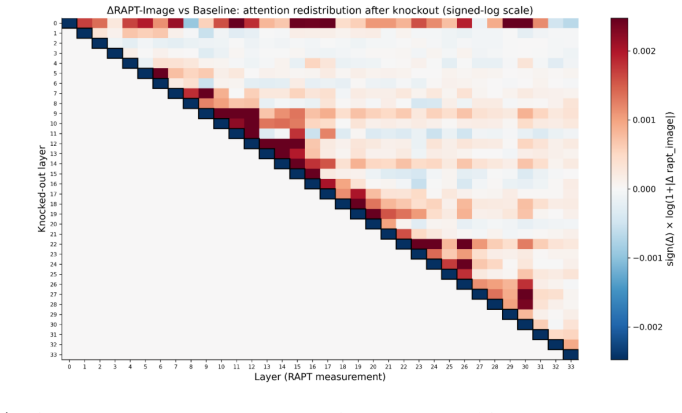
The result shows that the overall mirage risk can be reduced by separately controlling blank/noise failures throughg B and semantic mismatch failures throughg N, which matches the staged design of the proposed detector. E Negative and Developmental Experiments In this section, we describe orthogonal approaches to TC-LIA that were attempted before TC-LIA. ...
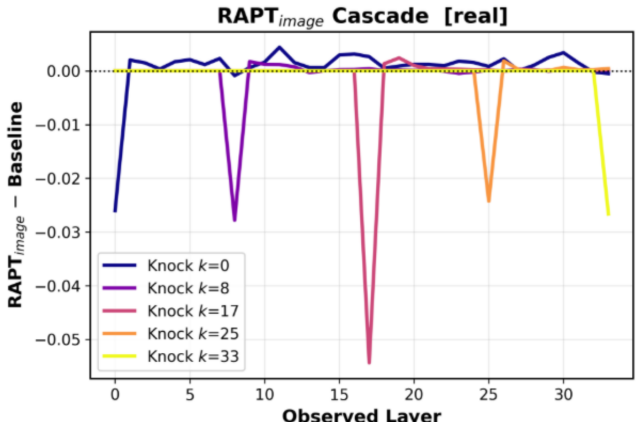
2026
-
[13]
Seeing but not believing
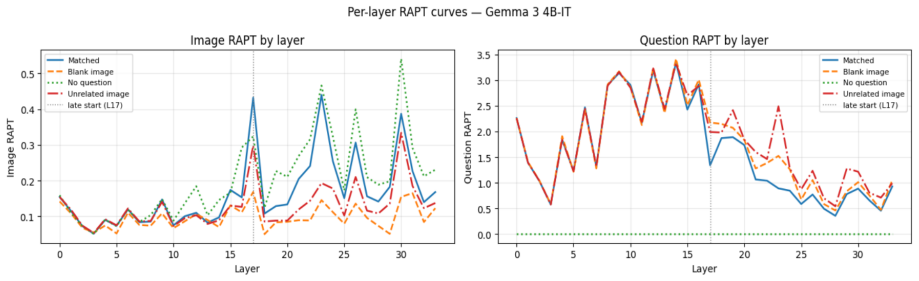
In the image RAPT panel, theunrelated imagecondition (red) tracks closely with thematchedcondition (blue) across all layers, confirming that the decoder allocates similar image attention regardless of whether the image is semantically relevant. Theblank imagecondition (orange) shows suppressed but non-zero image RAPT, whileno question(green) produces spur...
1929
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.