ProjQ: Project-and-Quantize for Adapter-Aware LLM Compression
Pith reviewed 2026-06-28 19:09 UTC · model grok-4.3
The pith
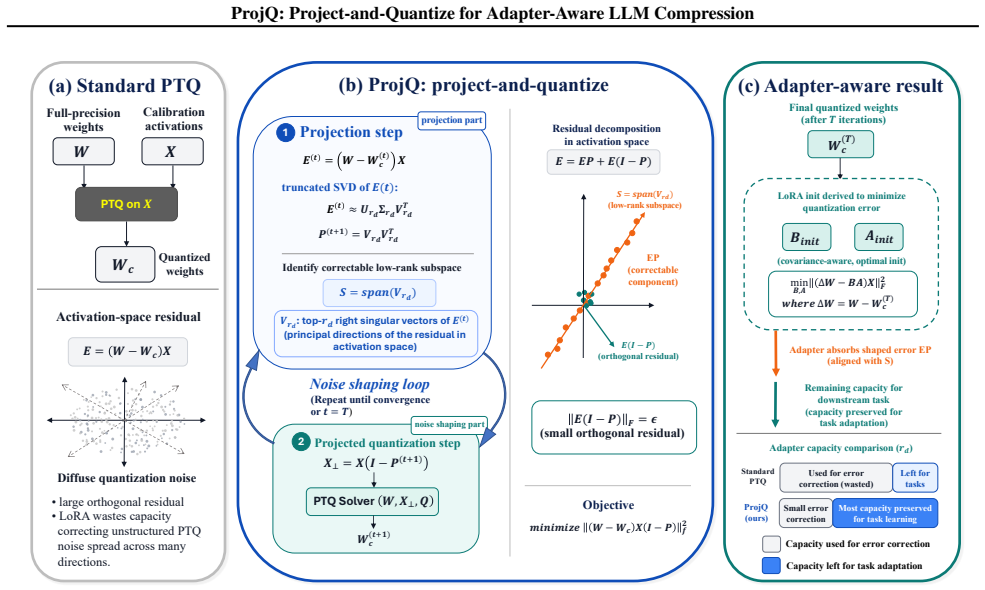
By projecting quantization noise onto the low-rank manifold, ProjQ allows LoRA to correct more error than standard post-training quantization permits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ProjQ constrains quantization noise to the low-rank manifold via orthogonal subspace projection and derives an efficient alternating algorithm that shapes the noise into low-rank structure. This offloads dominant error components to the subsequent adapter while minimizing the residual error in the orthogonal uncorrectable subspace, preserving strictly greater model plasticity for downstream tasks compared to standard PTQ.
What carries the argument
orthogonal subspace projection that moves dominant quantization noise components onto the low-rank manifold for adapter correction
If this is right
- Up to 2 times lower evaluation loss during quantization error compensation.
- 3-bit quantized models reach the language-modeling performance of standard 4-bit baselines.
- Consistent gains on LLaMA-2, Qwen2.5, and Qwen3 for both compensation accuracy and task fine-tuning.
- Adapter capacity is used more for task improvement rather than noise cleanup.
Where Pith is reading between the lines
- The same projection idea could be tested with other low-rank adapters to see whether the plasticity gain is specific to LoRA.
- If the noise-shaping step works at even lower bit widths, it might enable viable 2-bit models on the same hardware.
- Measuring the rank of the residual error after projection on new model families would test how general the low-rank assumption holds.
Load-bearing premise
Quantization noise from standard PTQ is spread out enough that LoRA cannot correct it, yet an orthogonal projection can relocate the main components onto the low-rank manifold without creating new uncorrectable residuals.
What would settle it
A side-by-side run of ProjQ and standard PTQ followed by identical LoRA fine-tuning on the same downstream tasks, checking whether the measured plasticity gap vanishes or reverses.
Figures
read the original abstract
Post-Training Quantization (PTQ) and Low-Rank Adaptation (LoRA) constitute the standard pipeline for efficient Large Language Model (LLM) deployment. However, applying them sequentially poses a problem: PTQ often leaves behind random noise that is spread out (across the model's weights) in a way LoRA can't easily fix, meaning that LoRA ends up wasting its limited capacity trying to fix uncorrectable noise instead of improving task performance. In this paper, we propose \textbf{ProjQ}, a novel framework for constraining quantization noise to the low-rank manifold via orthogonal subspace projection. We derive an efficient alternating algorithm that shapes the quantization noise into a low-rank structure, effectively offloading dominant error components to the subsequent adapter while minimizing the residual error in the orthogonal "uncorrectable" subspace. Our theoretical analysis demonstrates that ProjQ preserves strictly greater model plasticity for downstream tasks compared to standard PTQ. Extensive experiments on LLaMA-2, Qwen2.5 and Qwen3 confirm that ProjQ consistently outperforms existing methods in both quantization error compensation and downstream task fine-tuning, achieving up to $2\times$ lower evaluation loss for compensation and matching the performance of standard 4-bit baselines on language modeling tasks with only 3 bits. The code is available on https://github.com/yy9301/ProjQ .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ProjQ, a PTQ method that uses orthogonal subspace projection to constrain quantization noise to the low-rank manifold compatible with subsequent LoRA adapters. It introduces an efficient alternating algorithm to shape the noise, claims a theoretical result that this yields strictly greater downstream model plasticity than standard PTQ, and reports experiments on LLaMA-2, Qwen2.5 and Qwen3 showing up to 2× lower compensation loss and matching 4-bit baselines at 3 bits. Code is released.
Significance. If the plasticity theorem holds and the alternating procedure is stable, the method could meaningfully improve the PTQ+LoRA pipeline by reducing wasted adapter capacity on uncorrectable noise. The explicit code release is a clear strength for reproducibility.
major comments (2)
- [Theoretical analysis (abstract and §3–4)] Theoretical analysis (abstract and §3–4): the claim that ProjQ 'preserves strictly greater model plasticity' is asserted without the error model, the precise definition of plasticity (e.g., bound on fine-tuning loss or effective rank in the orthogonal complement), or the inequality derivation. It is therefore impossible to confirm that the result follows from the projection construction rather than from the unstated assumption that the projection step is lossless w.r.t. the uncorrectable subspace.
- [§4 (alternating algorithm)] §4 (alternating algorithm): the description of how the orthogonal projection and quantization steps are alternated does not include a convergence argument or a bound showing that the residual norm in the orthogonal complement is strictly smaller than under standard PTQ; without this, the 'strictly greater plasticity' claim remains unverified.
minor comments (2)
- [Abstract] The abstract states 'up to 2× lower evaluation loss' but does not specify the exact metric or baseline; a table or equation reference would clarify the comparison.
- [§2–3] Notation for the low-rank manifold and the orthogonal complement is introduced without an explicit definition or diagram; a short notation table or figure would improve readability.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments highlight important gaps in the presentation of the theoretical results, which we will address through targeted revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: Theoretical analysis (abstract and §3–4): the claim that ProjQ 'preserves strictly greater model plasticity' is asserted without the error model, the precise definition of plasticity (e.g., bound on fine-tuning loss or effective rank in the orthogonal complement), or the inequality derivation. It is therefore impossible to confirm that the result follows from the projection construction rather than from the unstated assumption that the projection step is lossless w.r.t. the uncorrectable subspace.
Authors: We agree that the current presentation of the theoretical analysis is incomplete. In the revised manuscript we will explicitly introduce the quantization error model, define model plasticity as the achievable reduction in downstream fine-tuning loss within the orthogonal complement, and provide the full step-by-step derivation of the strict inequality. The derivation will show that the improvement follows directly from the orthogonal projection step without invoking any lossless assumption on the uncorrectable subspace. revision: yes
-
Referee: §4 (alternating algorithm): the description of how the orthogonal projection and quantization steps are alternated does not include a convergence argument or a bound showing that the residual norm in the orthogonal complement is strictly smaller than under standard PTQ; without this, the 'strictly greater plasticity' claim remains unverified.
Authors: We acknowledge that a convergence argument and a comparative residual-norm bound are necessary to substantiate the claim. The revised version will include a convergence proof for the alternating procedure (under standard Lipschitz assumptions on the quantization operator) together with an explicit bound establishing that the residual norm in the orthogonal complement is strictly smaller than the corresponding quantity under standard PTQ. revision: yes
Circularity Check
No circularity: theoretical claim stated without equations reducing to input by construction
full rationale
The provided abstract and description assert a theoretical analysis showing strictly greater plasticity but supply no equations, error bounds, or derivations. No self-citations, fitted parameters renamed as predictions, ansatzes smuggled via citation, or self-definitional steps are quoted. The central claim is presented as independently derived from the ProjQ construction; absent any exhibited reduction (e.g., Eq. X = Eq. Y by construction), the derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption PTQ leaves behind random noise spread across weights in a way that LoRA cannot easily fix.
Reference graph
Works this paper leans on
-
[2]
Piqa: Reasoning about physical commonsense in natural language
Bisk, Y., Zellers, R., Gao, J., Choi, Y., et al. Piqa: Reasoning about physical commonsense in natural language. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pp.\ 7432--7439, 2020
2020
-
[3]
Chee, J., Cai, Y., Kuleshov, V., and De Sa, C. M. Quip: 2-bit quantization of large language models with guarantees. Advances in Neural Information Processing Systems, 36: 0 4396--4429, 2023
2023
-
[6]
Qlora: Efficient finetuning of quantized llms
Dettmers, T., Pagnoni, A., Holtzman, A., and Zettlemoyer, L. Qlora: Efficient finetuning of quantized llms. Advances in neural information processing systems, 36: 0 10088--10115, 2023
2023
-
[9]
J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al
Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al. Lora: Low-rank adaptation of large language models. ICLR, 1 0 (2): 0 3, 2022
2022
-
[11]
Awq: Activation-aware weight quantization for on-device llm compression and acceleration
Lin, J., Tang, J., Tang, H., Yang, S., Chen, W.-M., Wang, W.-C., Xiao, G., Dang, X., Gan, C., and Han, S. Awq: Activation-aware weight quantization for on-device llm compression and acceleration. Proceedings of machine learning and systems, 6: 0 87--100, 2024
2024
-
[13]
A., MacIntyre, R., Bies, A., Ferguson, M., Katz, K., and Schasberger, B
Marcus, M., Kim, G., Marcinkiewicz, M. A., MacIntyre, R., Bies, A., Ferguson, M., Katz, K., and Schasberger, B. The penn treebank: Annotating predicate argument structure. In Human Language Technology: Proceedings of a Workshop held at Plainsboro, New Jersey, March 8-11, 1994, 1994
1994
-
[15]
A corpus and cloze evaluation for deeper understanding of commonsense stories
Mostafazadeh, N., Chambers, N., He, X., Parikh, D., Batra, D., Vanderwende, L., Kohli, P., and Allen, J. A corpus and cloze evaluation for deeper understanding of commonsense stories. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp.\ 839--849, 2016
2016
-
[16]
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., and Liu, P. J. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21 0 (140): 0 1--67, 2020
2020
-
[17]
J., and Pilanci, M
Saha, R., Sagan, N., Srivastava, V., Goldsmith, A. J., and Pilanci, M. Compressing large language models using low rank and low precision decomposition. Advances in Neural Information Processing Systems, 37: 0 88981--89018, 2024
2024
-
[18]
Commonsenseqa: A question answering challenge targeting commonsense knowledge
Talmor, A., Herzig, J., Lourie, N., and Berant, J. Commonsenseqa: A question answering challenge targeting commonsense knowledge. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp.\ 4149--4158, 2019
2019
-
[20]
Svd-llm: Truncation-aware singular value decomposition for large language model compression
Wang, X., Zheng, Y., Wan, Z., and Zhang, M. Svd-llm: Truncation-aware singular value decomposition for large language model compression. ICLR, 2025
2025
-
[21]
Qa-lora: Quantization-aware low-rank adaptation of large language models
Xu, Y., Xie, L., Gu, X., Chen, X., Chang, H., Zhang, H., Chen, Z., Zhang, X., and Tian, Q. Qa-lora: Quantization-aware low-rank adaptation of large language models. ICLR, 2024
2024
-
[22]
Lowra: Accurate and efficient lora fine-tuning of llms under 2 bits
Zhou, Z., Zhang, Q., Kumbong, H., and Olukotun, K. Lowra: Accurate and efficient lora fine-tuning of llms under 2 bits. ICML, 2025
2025
-
[23]
Large language models in 6g from standard to on-device networks
Zou, H., Zhao, Q., Lasaulce, S., Zhang, C., Tian, Y., Bariah, L., Bader, F., and Debbah, M. Large language models in 6g from standard to on-device networks. Nature Reviews Electrical Engineering, pp.\ 1--12, 2026
2026
-
[24]
Nature Reviews Electrical Engineering , pages=
Large language models in 6G from standard to on-device networks , author=. Nature Reviews Electrical Engineering , pages=. 2026 , publisher=
2026
-
[25]
Proceedings of machine learning and systems , volume=
Awq: Activation-aware weight quantization for on-device llm compression and acceleration , author=. Proceedings of machine learning and systems , volume=
-
[26]
ICLR , year=
Svd-llm: Truncation-aware singular value decomposition for large language model compression , author=. ICLR , year=
-
[27]
arXiv preprint arXiv:2410.21271 , year=
EoRA: Fine-tuning-free Compensation for Compressed LLM with Eigenspace Low-Rank Approximation , author=. arXiv preprint arXiv:2410.21271 , year=
-
[28]
ICML , year=
LowRA: Accurate and Efficient LoRA Fine-Tuning of LLMs under 2 Bits , author=. ICML , year=
-
[29]
ICLR , year=
QA-LoRA: Quantization-aware low-rank adaptation of large language models , author=. ICLR , year=
-
[30]
Advances in Neural Information Processing Systems , volume=
Quip: 2-bit quantization of large language models with guarantees , author=. Advances in Neural Information Processing Systems , volume=
-
[31]
Omniquant: Omnidirectionally calibrated quantization for large language models , author=. arXiv preprint arXiv:2308.13137 , year=
-
[32]
arXiv preprint arXiv:2303.08302 , year=
A comprehensive study on post-training quantization for large language models , author=. arXiv preprint arXiv:2303.08302 , year=
-
[33]
A Survey of Large Language Models
A survey of large language models , author=. arXiv preprint arXiv:2303.18223 , volume=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
ACM Computing Surveys , volume=
Towards efficient generative large language model serving: A survey from algorithms to systems , author=. ACM Computing Surveys , volume=. 2025 , publisher=
2025
-
[35]
arXiv preprint arXiv:2411.06084 , year=
Optimizing Large Language Models through Quantization: A Comparative Analysis of PTQ and QAT Techniques , author=. arXiv preprint arXiv:2411.06084 , year=
-
[36]
Applied Intelligence , volume=
A comprehensive review of model compression techniques in machine learning , author=. Applied Intelligence , volume=. 2024 , publisher=
2024
-
[37]
Advances in neural information processing systems , volume=
Post training 4-bit quantization of convolutional networks for rapid-deployment , author=. Advances in neural information processing systems , volume=
-
[38]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Quantization and training of neural networks for efficient integer-arithmetic-only inference , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[39]
European conference on computer vision , pages=
Post-training piecewise linear quantization for deep neural networks , author=. European conference on computer vision , pages=. 2020 , organization=
2020
-
[40]
International conference on machine learning , pages=
Accurate post training quantization with small calibration sets , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[41]
Advances in Neural Information Processing Systems , volume=
Optimal brain compression: A framework for accurate post-training quantization and pruning , author=. Advances in Neural Information Processing Systems , volume=
-
[42]
Advances in neural information processing systems , volume=
Qlora: Efficient finetuning of quantized llms , author=. Advances in neural information processing systems , volume=
-
[43]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Gptq: Accurate post-training quantization for generative pre-trained transformers , author=. arXiv preprint arXiv:2210.17323 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
arXiv preprint arXiv:2501.18475 , year=
Cloq: Enhancing fine-tuning of quantized llms via calibrated lora initialization , author=. arXiv preprint arXiv:2501.18475 , year=
-
[45]
arXiv preprint arXiv:2505.03802 , year=
Efficient fine-tuning of quantized models via adaptive rank and bitwidth , author=. arXiv preprint arXiv:2505.03802 , year=
-
[46]
On-the-Fly Adaptation to Quantization: Configuration-Aware LoRA for Efficient Fine-Tuning of Quantized LLMs , author=. arXiv preprint arXiv:2509.25214 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
RILQ: Rank-Insensitive LoRA-based Quantization Error Compensation for Boosting 2-bit Large Language Model Accuracy , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[48]
arXiv preprint arXiv:2505.21895 , year=
Compressing Sine-Activated Low-Rank Adapters through Post-Training Quantization , author=. arXiv preprint arXiv:2505.21895 , year=
-
[49]
5-VL , author=
Efficient Fine-Tuning of Multimodal Language Models for Medical AI via LoRA and 4-bit Quantization on Qwen2. 5-VL , author=. 2025 7th International Conference on Data-driven Optimization of Complex Systems (DOCS) , pages=. 2025 , organization=
2025
-
[50]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Controlled low-rank adaptation with subspace regularization for continued training on large language models , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[51]
2025 62nd ACM/IEEE Design Automation Conference (DAC) , pages=
DuQTTA: Dual Quantized Tensor-Train Adaptation with Decoupling Magnitude-Direction for Efficient Fine-Tuning of LLMs , author=. 2025 62nd ACM/IEEE Design Automation Conference (DAC) , pages=. 2025 , organization=
2025
-
[52]
IEEE transactions on pattern analysis and machine intelligence , volume=
Robust recovery of subspace structures by low-rank representation , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2012 , publisher=
2012
-
[53]
arXiv preprint arXiv:2311.12023 , year=
Lq-lora: Low-rank plus quantized matrix decomposition for efficient language model finetuning , author=. arXiv preprint arXiv:2311.12023 , year=
-
[54]
, author=
Lora: Low-rank adaptation of large language models. , author=. ICLR , volume=
-
[55]
Expert Systems with Applications , volume=
Imbalanced complemented subspace representation with adaptive weight learning , author=. Expert Systems with Applications , volume=. 2024 , publisher=
2024
-
[56]
OPT: Open Pre-trained Transformer Language Models
Opt: Open pre-trained transformer language models , author=. arXiv preprint arXiv:2205.01068 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[57]
LLaMA: Open and Efficient Foundation Language Models
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[58]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[59]
Qwen technical report , author=. arXiv preprint arXiv:2309.16609 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[60]
Journal of machine learning research , volume=
Exploring the limits of transfer learning with a unified text-to-text transformer , author=. Journal of machine learning research , volume=
-
[61]
Proceedings of the AAAI conference on artificial intelligence , volume=
Piqa: Reasoning about physical commonsense in natural language , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[62]
Pointer Sentinel Mixture Models
Pointer sentinel mixture models , author=. arXiv preprint arXiv:1609.07843 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[63]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Think you have solved question answering? try arc, the ai2 reasoning challenge , author=. arXiv preprint arXiv:1803.05457 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[64]
BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions
Boolq: Exploring the surprising difficulty of natural yes/no questions , author=. arXiv preprint arXiv:1905.10044 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[65]
Human Language Technology: Proceedings of a Workshop held at Plainsboro, New Jersey, March 8-11, 1994 , year=
The penn treebank: Annotating predicate argument structure , author=. Human Language Technology: Proceedings of a Workshop held at Plainsboro, New Jersey, March 8-11, 1994 , year=
1994
-
[66]
Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
A corpus and cloze evaluation for deeper understanding of commonsense stories , author=. Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
2016
-
[67]
GitHub repository , howpublished =
ModelCloud.ai , title =. GitHub repository , howpublished =
-
[68]
arXiv e-prints , pages=
The llama 3 herd of models , author=. arXiv e-prints , pages=
-
[69]
arXiv preprint arXiv:2310.08659 , year=
Loftq: Lora-fine-tuning-aware quantization for large language models , author=. arXiv preprint arXiv:2310.08659 , year=
-
[70]
tinybenchmarks: Evaluating LLMs with fewer examples
tinyBenchmarks: evaluating LLMs with fewer examples , author=. arXiv preprint arXiv:2402.14992 , year=
-
[71]
2023 , publisher=
Stanford alpaca: An instruction-following llama model , author=. 2023 , publisher=
2023
-
[72]
Commonsense\_170k Dataset , author =
-
[73]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[74]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language understanding , author=. arXiv preprint arXiv:2009.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[75]
Advances in neural information processing systems , volume=
Pytorch: An imperative style, high-performance deep learning library , author=. Advances in neural information processing systems , volume=
-
[76]
LoRDQ: activation-aware Low-Rank Decomposition and Quantization for Large Language Model Compression , author=
-
[77]
Commonsenseqa: A question answering challenge targeting commonsense knowledge , author=. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , pages=
2019
-
[78]
Advances in Neural Information Processing Systems , volume=
Compressing large language models using low rank and low precision decomposition , author=. Advances in Neural Information Processing Systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.