V-LynX: Token Interface Alignment for Video+X LLMs
Pith reviewed 2026-06-28 18:58 UTC · model grok-4.3
The pith
Video LLMs build an internal continuous manifold that lets new modalities align to video priors using unpaired data alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
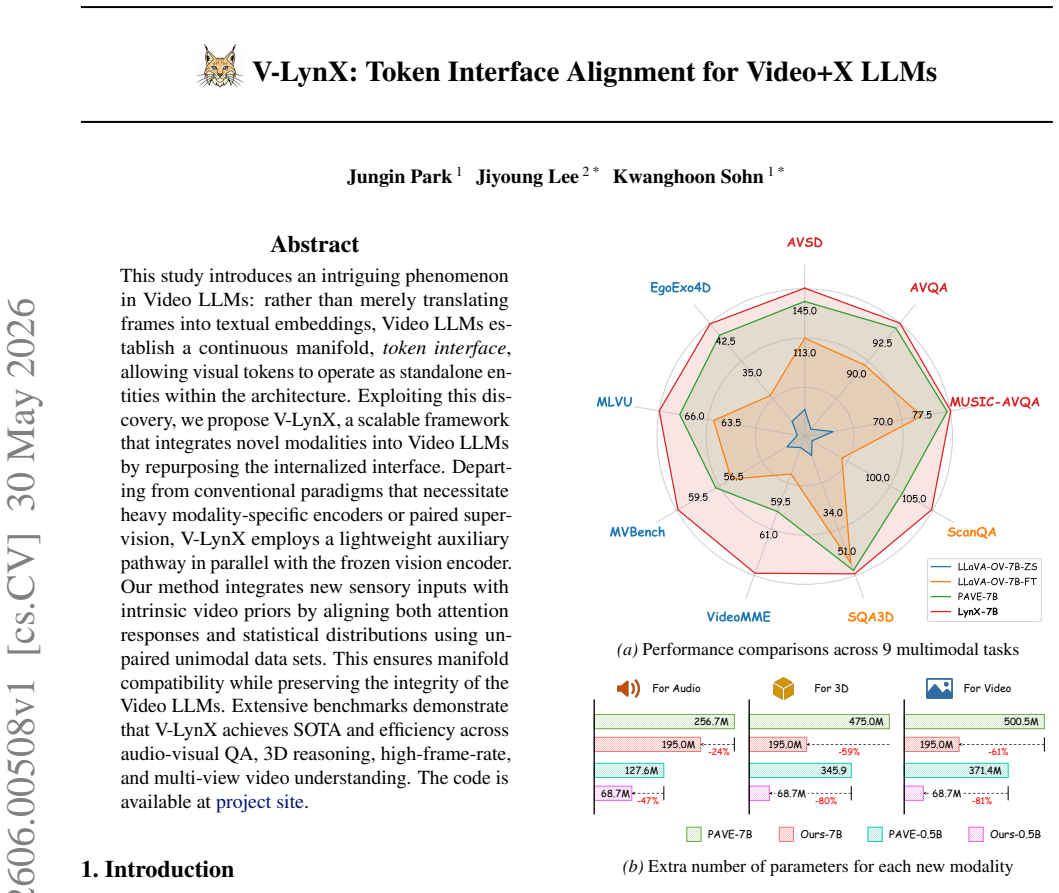
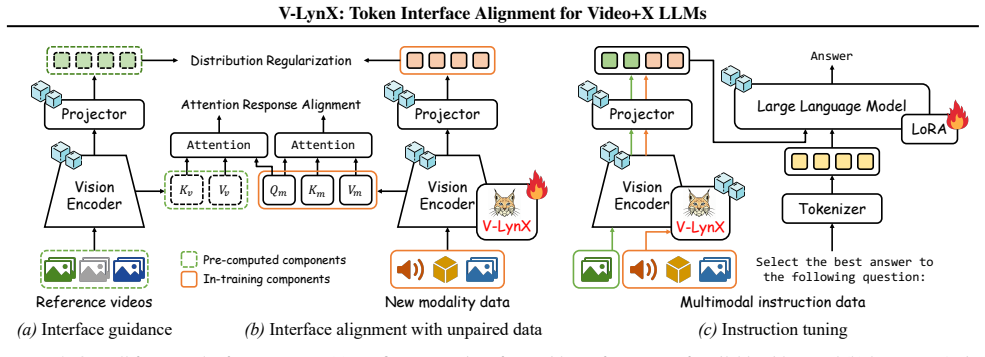
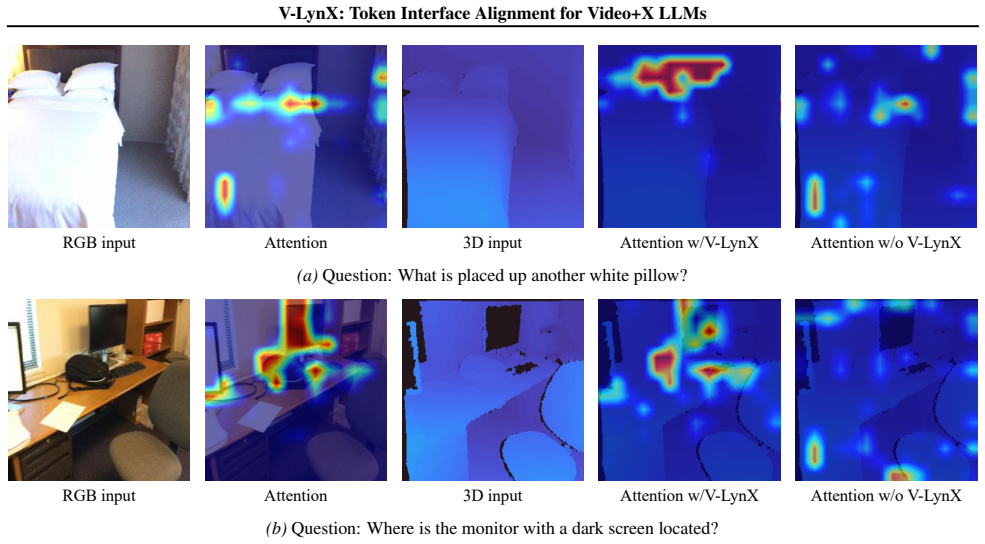
Video LLMs establish a continuous manifold token interface allowing visual tokens to operate as standalone entities within the architecture. V-LynX integrates new sensory inputs with intrinsic video priors by aligning both attention responses and statistical distributions using unpaired unimodal data sets through a lightweight auxiliary pathway in parallel with the frozen vision encoder, ensuring manifold compatibility while preserving the integrity of the Video LLMs.
What carries the argument
The continuous manifold token interface, which serves as an internalized alignment point enabling visual tokens to function independently and accept new modality inputs.
If this is right
- New modalities integrate without modality-specific encoders or paired supervision.
- The Video LLM backbone stays frozen during alignment.
- Alignment relies solely on unpaired unimodal datasets for both attention and distribution matching.
- The method reaches state-of-the-art results on audio-visual QA, 3D reasoning, high-frame-rate video, and multi-view understanding.
- A single lightweight auxiliary pathway suffices to maintain manifold compatibility across added inputs.
Where Pith is reading between the lines
- The same manifold-matching approach could apply to non-video multimodal LLMs if they develop comparable internal interfaces.
- Unpaired alignment might lower data collection costs for future multimodal extensions beyond the tested tasks.
- Incremental addition of further modalities could be tested by repeating the alignment process on the updated interface.
- Failure modes on edge cases like very low-frame-rate inputs would reveal limits of the manifold's continuity assumption.
Load-bearing premise
The internalized token interface forms a continuous manifold that remains compatible when new modalities are aligned to it via attention and distribution matching on unpaired data.
What would settle it
A direct test would check whether new-modality tokens aligned only through attention and distribution matching on unpaired data produce outputs that remain compatible with the original video manifold or instead cause measurable degradation on pure video tasks.
Figures

read the original abstract
This study introduces an intriguing phenomenon in Video LLMs: rather than merely translating frames into textual embeddings, Video LLMs establish a continuous manifold, token interface, allowing visual tokens to operate as standalone entities within the architecture. Exploiting this discovery, we propose V-LynX, a scalable framework that integrates novel modalities into Video LLMs by repurposing the internalized interface. Departing from conventional paradigms that necessitate heavy modality-specific encoders or paired supervision, V-LynX employs a lightweight auxiliary pathway in parallel with the frozen vision encoder. Our method integrates new sensory inputs with intrinsic video priors by aligning both attention responses and statistical distributions using unpaired unimodal data sets. This ensures manifold compatibility while preserving the integrity of the Video LLMs. Extensive benchmarks demonstrate that V-LynX achieves SOTA and efficiency across audio-visual QA, 3D reasoning, high-frame-rate, and multi-view video understanding. The code is available at https://github.com/park-jungin/lynx.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Video LLMs establish a continuous manifold token interface allowing visual tokens to operate as standalone entities. It introduces V-LynX, a framework that integrates new modalities (e.g., audio, 3D) into frozen Video LLMs via a lightweight auxiliary pathway. Alignment is performed by matching attention responses and statistical distributions on unpaired unimodal datasets, without modality-specific encoders or paired supervision. The method is reported to preserve the original model's integrity while achieving SOTA results on audio-visual QA, 3D reasoning, high-frame-rate video, and multi-view understanding tasks.
Significance. If the manifold claim and unpaired alignment procedure hold without degrading base Video LLM performance, the work could enable more scalable multimodal extensions by reducing reliance on paired data and heavy encoders. Code release supports reproducibility, which strengthens the contribution if experiments are verifiable.
major comments (2)
- [Abstract] Abstract: The central claim that Video LLMs establish a 'continuous manifold, token interface' is presented as a discovery but lacks any supporting derivation, equation, or empirical verification (e.g., no manifold dimensionality analysis, continuity metric, or ablation showing standalone token operation). This assumption is load-bearing for the entire V-LynX alignment procedure.
- [Abstract] Abstract: The assertion that alignment of attention responses and statistical distributions on unpaired data 'ensures manifold compatibility while preserving integrity' is stated without controls, error bars, or comparison to paired-supervision baselines, making it impossible to assess whether the method actually avoids degradation or requires hidden paired data.
minor comments (2)
- [Abstract] Abstract: 'Extensive benchmarks' and 'SOTA' are claimed without naming specific datasets, metrics, or competing methods, reducing clarity.
- [Abstract] Abstract: The GitHub link is provided but no implementation details (e.g., auxiliary pathway architecture, loss formulations for attention/distribution matching) are summarized.
Simulated Author's Rebuttal
We thank the referee for their comments. We address each major comment below, clarifying the empirical basis for our claims while agreeing to revisions that improve the abstract's presentation and add requested controls.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that Video LLMs establish a 'continuous manifold, token interface' is presented as a discovery but lacks any supporting derivation, equation, or empirical verification (e.g., no manifold dimensionality analysis, continuity metric, or ablation showing standalone token operation). This assumption is load-bearing for the entire V-LynX alignment procedure.
Authors: The claim originates from empirical observations of visual token behavior within Video LLMs, as analyzed through attention patterns and statistical properties in Sections 3 and 4 of the manuscript. These sections include continuity metrics derived from attention matching and ablations demonstrating standalone token operation. We agree the abstract states the claim too concisely without explicit cross-references. We will revise the abstract to frame the finding as empirically supported and direct readers to the relevant analysis sections. revision: yes
-
Referee: [Abstract] Abstract: The assertion that alignment of attention responses and statistical distributions on unpaired data 'ensures manifold compatibility while preserving integrity' is stated without controls, error bars, or comparison to paired-supervision baselines, making it impossible to assess whether the method actually avoids degradation or requires hidden paired data.
Authors: The experimental results (Sections 5 and 6) report multiple ablations confirming preservation of base model performance on original video tasks, using unpaired data only, along with comparisons showing advantages over alternative alignment strategies. To strengthen verifiability, we will add error bars to the main result tables and include a direct paired-supervision baseline comparison in the revised version. revision: yes
Circularity Check
No significant circularity detected in provided text
full rationale
The abstract and description introduce a claimed phenomenon (continuous manifold token interface in Video LLMs) and a method (V-LynX alignment via attention and distribution matching on unpaired data) at a conceptual level only. No equations, parameter-fitting procedures, self-citations, or derivation steps are present that could reduce any claim to its own inputs by construction. The central claims cannot be shown to collapse into self-definition or fitted renamings from the given material, consistent with the absence of load-bearing mathematical content.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al. Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Chen, S., Li, H., Wang, Q., Zhao, Z., Sun, M., Zhu, X., and Liu, J. Vast: A vision-audio-subtitle-text omni-modality foundation model and dataset. InNeurIPS, 2023a. Chen, S., Wu, Y ., Wang, C., Liu, S., Tompkins, D., Chen, Z., Che, W., Yu, X., and Wei, F. Beats: Audio pre-training with acoustic tokenizers. InICML, 2023b. Chen, S., Chen, X., Zhang, C., Li,...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
The Power of Scale for Parameter-Efficient Prompt Tuning
Lester, B., Al-Rfou, R., and Constant, N. The power of scale for parameter-efficient prompt tuning.arXiv preprint arXiv:2104.08691,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
VideoChat: Chat-Centric Video Understanding
Li, G., Hou, W., and Hu, D. Progressive spatiotemporal perception for audio-visual question answering. InACM MM, 2023a. Li, K., He, Y ., Wang, Y ., Li, Y ., Wang, W., Luo, P., Wang, Y ., Wang, L., and Qiao, Y . Videochat: Chat-centric video understanding.arXiv preprint arXiv:2305.06355, 2023b. Li, K., Wang, Y ., He, Y ., Li, Y ., Wang, Y ., Liu, Y ., Wang...
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Prefix-Tuning: Optimizing Continuous Prompts for Generation
Li, W., Tang, R., Li, C., Zhang, C., Vulic, I., and Søgaard, A. Lost in embeddings: Information loss in vision-language models. InEMNLP Findings, 2025b. Li, X. L. and Liang, P. Prefix-tuning: Optimizing continuous prompts for generation.arXiv preprint arXiv:2101.00190,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
SGDR: Stochastic Gradient Descent with Warm Restarts
Loshchilov, I. and Hutter, F. Sgdr: Stochastic gra- dient descent with warm restarts.arXiv preprint arXiv:1608.03983,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Sun, G., Yu, W., Tang, C., Chen, X., Tan, T., Li, W., Lu, L., Ma, Z., Wang, Y ., and Zhang, C. video-salmonn: Speech-enhanced audio-visual large language models. arXiv preprint arXiv:2406.15704,
-
[8]
Tang, C., Li, Y ., Yang, Y ., Zhuang, J., Sun, G., Li, W., Ma, Z., and Zhang, C. video-salmonn 2: Captioning- enhanced audio-visual large language models.arXiv preprint arXiv:2506.15220,
-
[9]
Team, Q. et al. Qwen2 technical report.arXiv preprint arXiv:2407.10671,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Xu, M., Gao, M., Gan, Z., Chen, H.-Y ., Lai, Z., Gang, H., Kang, K., and Dehghan, A. Slowfast-llava: A strong training-free baseline for video large language models. arXiv preprint arXiv:2407.15841, 2024a. Xu, R., Wang, X., Wang, T., Chen, Y ., Pang, J., and Lin, D. Pointllm: Empowering large language models to understand point clouds. InECCV, 2024b. Yang...
-
[11]
Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding
Zhang, H., Li, X., and Bing, L. Video-llama: An instruction- tuned audio-visual language model for video understand- ing.arXiv preprint arXiv:2306.02858,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
LLaVA-Video: Video Instruction Tuning With Synthetic Data
Zhang, Y ., Wu, J., Li, W., Li, B., Ma, Z., Liu, Z., and Li, C. Video instruction tuning with synthetic data.arXiv preprint arXiv:2410.02713,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Zhou, D.-W., Zhang, Y ., Wang, Y ., Ning, J., Ye, H.-J., Zhan, D.-C., and Liu, Z. Learning without forgetting for vision- language models.IEEE TPAMI, pp. 4489–4504, 2025a. Zhou, J., Shu, Y ., Zhao, B., Wu, B., Liang, Z., Xiao, S., Qin, M., Yang, X., Xiong, Y ., Zhang, B., et al. Mlvu: Benchmarking multi-task long video understanding. In CVPR, 2025b. Zhu, ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Training details We optimize all models with AdamW (Loshchilov & Hutter, 2019)
0.79 0.35 1.02 0.47 31.65 0.9539 InternVL-2.5-4B (Chen et al., 2024b) 0.92 0.11 1.01 0.29 41.71 0.9930 A.3. Training details We optimize all models with AdamW (Loshchilov & Hutter, 2019). For both interface alignment and instruction tuning, we apply a linear warm-up over the first 3% of iterations and use cosine annealing for learning rate decay (Loshchil...
2019
-
[15]
between frame and vocabulary embeddings across four Video LLMs, including LLaV A-OV-0.5B, -7B (Li et al., 2025a), Qwen2.5-VL-3B (Bai et al., 2025), and InternVL2.5-4B (Chen et al., 2024b), as shown in Table B1. Across all backbones, projected frame embeddings show much smaller pairwise cosine distances than vocabulary embeddings, 13 V-LynX: Token Interfac...
2025
-
[16]
We report the accuracy (Acc.)
15.1 - V-LynX-3B (Ours) 59.7 (60.0) 165.5M With InternVL-2.5 InternVL-2.5-4B (Chen et al., 2024b) 44.0 (50.6) - V-LynX-4B (Ours)61.1 (63.5)144.9M Table B4.Performance comparisons on A V-Human of A VUT (Yang et al., 2025). We report the accuracy (Acc.). Method Acc. (%) Visual MLLMs GPT-4o 56.62 Qwen2-VL-7B 58.38 LLaV A-Video-7B 56.52 InternVL2-8B 45.9 VILA...
2025
-
[17]
and InternVL-2.5-4B (Chen et al., 2024b), and evaluate them on SQA3D. As shown in Table B3, V-LynX consistently improves all baselines: V-LynX-0.5B and V-LynX-7B achieve 52.2 and 60.5 EM@1 with LLaV A-OV , while V-LynX-3B improves Qwen2.5-VL-3B from 15.1 to 59.7 EM@1. InternVL-2.5-4B already provides a strong baseline of 44.0 EM@1, partly because ScanQA w...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.