Escaping the Mode Lottery: Multi-Response Training Improves Language Model Generalization
Pith reviewed 2026-06-28 19:35 UTC · model grok-4.3
The pith
Retaining multiple responses per prompt improves language model distributional generalization by addressing the mode lottery.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
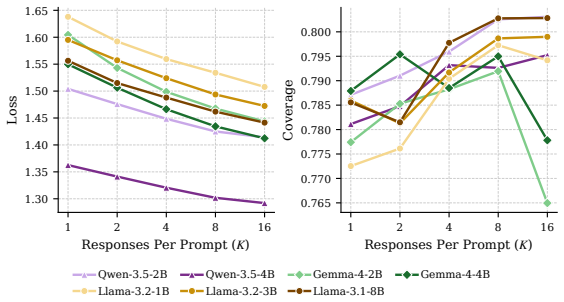
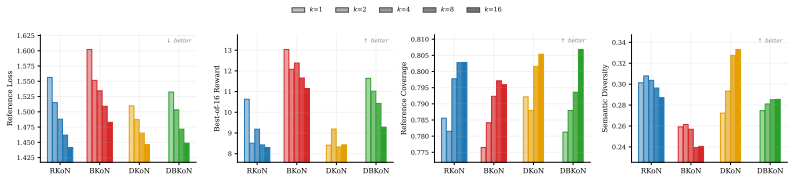
Multi-response training (MRT) improves distributional generalization by retaining multiple responses per prompt, countering the mode lottery in which single-response training over-represents a subset of plausible outputs; gains are largest in high response-diversity and low prompt-redundancy regimes, and Random-K-of-N selection is the unbiased default while reward-based selection can misalign gradients.
What carries the argument
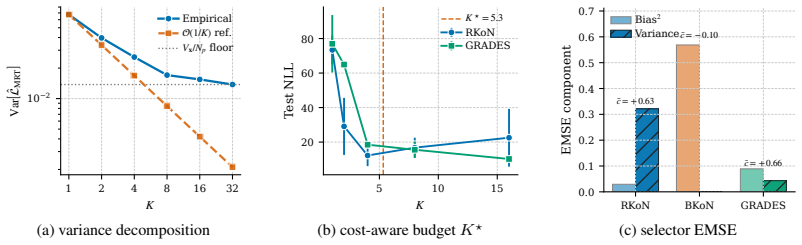
The variance-budget tradeoff, which separates uncertainty reduction from additional prompts (input distribution) from that provided by additional responses (conditional output distribution).
If this is right
- Random-K-of-N response selection remains unbiased for distributional fine-tuning.
- Reward-based selection can induce mode collapse by producing misaligned gradients.
- Submodular quality-diversity objectives provide an efficient alternative with theoretical guarantees.
- Large redundant corpora can exhibit an implicit multi-response effect.
Where Pith is reading between the lines
- Data collection priorities may shift toward response diversity rather than prompt volume in some regimes.
- The same allocation logic could extend to other conditional generative models.
- New evaluation benchmarks that explicitly measure multi-response coverage would make the effect easier to track.
Load-bearing premise
Prompts and responses function as distinct statistical resources that reduce different kinds of uncertainty.
What would settle it
A controlled experiment on a high-diversity dataset in which increasing the number of responses per prompt produces no improvement or a decline in distributional generalization metrics.
Figures
read the original abstract
Modern language-model fine-tuning typically pairs each prompt with a single response, even though many prompts admit multiple valid completions. This effectively reduces a multi-modal conditional distribution to a one-sample view, a phenomenon we call the "mode lottery," where training emphasizes a subset of plausible modes while leaving others underrepresented. We study multi-response training (MRT), which retains multiple responses per prompt, and develop a principled account of when and why it helps. Our key insight is that prompts and responses are distinct statistical resources: additional prompts reduce uncertainty about the input distribution, while additional responses reduce uncertainty about the conditional output distribution. This yields a variance-budget tradeoff that predicts when retaining multiple responses is worthwhile, shows diminishing returns as prompt-level uncertainty dominates, and explains why large redundant corpora can exhibit an implicit multi-response effect. We further analyze response selection, and show that Random-K-of-N is the unbiased default for distributional fine-tuning, reward-based selection can induce mode collapse, and a submodular quality-diversity objective provides an efficient alternative with theoretical guarantees. Controlled simulations validate the predicted variance and selection effects, including a striking failure mode where reward-only selection produces gradients misaligned with the true objective. Across structured and real-world datasets, including a new multi-prompt, multi-response benchmark, MRT consistently improves distributional generalization, with the largest gains in high response-diversity, low prompt-redundancy regimes. MRT reframes response multiplicity as a data-allocation problem with clear guidance: when responses are cheap and diverse, keeping more than one is not a heuristic, but a statistically grounded choice.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that standard single-response fine-tuning induces a 'mode lottery' by underrepresenting modes in multi-modal conditional distributions. It proposes multi-response training (MRT) and derives a variance-budget tradeoff in which additional prompts reduce input-distribution uncertainty while additional responses reduce conditional-output uncertainty; this tradeoff predicts when MRT is beneficial, shows diminishing returns, and explains implicit multi-response effects in large corpora. The paper analyzes response-selection strategies (Random-K-of-N as unbiased default, reward-based selection inducing mode collapse, submodular quality-diversity objective with guarantees), validates the predicted variance and selection effects in controlled simulations (including a reward-only failure mode), and reports consistent distributional-generalization gains on structured and real-world datasets plus a new multi-prompt/multi-response benchmark, largest in high response-diversity/low prompt-redundancy regimes.
Significance. If the variance-budget account is shown to govern real LLM fine-tuning dynamics and the empirical gains are robust to standard training confounders, the work supplies a statistically grounded data-allocation principle rather than a heuristic, together with a new benchmark and a theoretically motivated selection objective. The explicit identification of a reward-only misalignment failure mode is a useful cautionary result for the community.
major comments (1)
- [Controlled simulations] Controlled simulations section: the validation of the variance-budget tradeoff and selection effects employs simplified estimators and generative processes. These omit non-convex loss landscapes, parameter sharing across prompts, and gradient interference when multiple responses for the same prompt appear in a batch—precisely the features the skeptic note flags as potentially decisive for whether the tradeoff governs actual LLM training. Because this tradeoff is the load-bearing explanation for both the theoretical predictions and the reported real-dataset gains, the simulations must be shown to remain predictive once these dynamics are present; otherwise the central claim that MRT improvements are explained by the tradeoff rather than by other factors is not yet established.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for highlighting the importance of validating the variance-budget tradeoff under realistic training conditions. We address the single major comment below.
read point-by-point responses
-
Referee: [Controlled simulations] Controlled simulations section: the validation of the variance-budget tradeoff and selection effects employs simplified estimators and generative processes. These omit non-convex loss landscapes, parameter sharing across prompts, and gradient interference when multiple responses for the same prompt appear in a batch—precisely the features the skeptic note flags as potentially decisive for whether the tradeoff governs actual LLM training. Because this tradeoff is the load-bearing explanation for both the theoretical predictions and the reported real-dataset gains, the simulations must be shown to remain predictive once these dynamics are present; otherwise the central claim that MRT improvements are explained by the tradeoff rather than by other factors is not yet established.
Authors: We acknowledge that the controlled simulations employ simplified linear estimators and generative processes that do not capture non-convex optimization, parameter sharing, or intra-batch gradient interference. These choices were deliberate to isolate and exactly quantify the variance-budget tradeoff derived in the theory section, where closed-form variance expressions are available only under the simplified model. The simulations confirm the predicted effects of response multiplicity and selection strategies (including the reward-only misalignment failure mode) without confounding optimization artifacts. The real LLM experiments, which necessarily include non-convex landscapes, shared parameters, and batch-level interference, exhibit gains that align with the regimes predicted by the tradeoff (largest in high response-diversity, low prompt-redundancy settings). This consistency indicates that the statistical mechanism remains operative even when the omitted dynamics are present. We will revise the manuscript to add an explicit limitations paragraph in the simulations section clarifying the scope of the controlled setting and how the empirical results on actual models provide the bridge to full training dynamics. revision: partial
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The abstract presents the variance-budget tradeoff as a direct conceptual insight from distinguishing input vs. conditional-output uncertainty, without any equations, fitted parameters, or self-citations that reduce the central claim to its own inputs by construction. No load-bearing steps match the enumerated circularity patterns; the account is framed as an independent statistical framing that is then validated empirically on external datasets and simulations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Prompts and responses are distinct statistical resources: additional prompts reduce uncertainty about the input distribution while additional responses reduce uncertainty about the conditional output distribution.
Reference graph
Works this paper leans on
-
[1]
DELIFT: Data efficient language model instruction fine-tuning
Ishika Agarwal, Krishnateja Killamsetty, Lucian Popa, and Marina Danilevsky. DELIFT: Data efficient language model instruction fine-tuning. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=Fty0wTcemV
2025
-
[2]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, et al. Constitutional ai: Harmlessness from ai feedback, 2022. URLhttps://arxiv.org/abs/2212.08073
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Peter L. Bartlett and Shahar Mendelson. Rademacher and gaussian complexities: risk bounds and structural results.J. Mach. Learn. Res., 3:463–482, March 2003. ISSN 1532-4435. URL https://dl.acm.org/doi/10.5555/944919.944944
-
[4]
A model of inductive bias learning.J
Jonathan Baxter. A model of inductive bias learning.J. Artif. Int. Res., 12(1):149–198, March
-
[5]
URLhttps://dl.acm.org/doi/10.5555/1622248.1622254
ISSN 1076-9757. URLhttps://dl.acm.org/doi/10.5555/1622248.1622254
-
[6]
Theoretical guarantees on the best-of-n alignment policy
Ahmad Beirami, Alekh Agarwal, Jonathan Berant, Alexander Nicholas D’Amour, Jacob Eisen- stein, Chirag Nagpal, and Ananda Theertha Suresh. Theoretical guarantees on the best-of-n alignment policy. InForty-second International Conference on Machine Learning, 2025. URL https://openreview.net/forum?id=u3U8qzFV7w
2025
-
[7]
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V . Le, Christopher Ré, and Azalia Mirhoseini. Large language monkeys: Scaling inference compute with repeated sampling, 2024. URLhttps://arxiv.org/abs/2407.21787
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Open problems and fundamental limitations of reinforcement learning from human feedback.Transactions on Machine Learning Research,
Stephen Casper, Xander Davies, Claudia Shi, et al. Open problems and fundamental limitations of reinforcement learning from human feedback.Transactions on Machine Learning Research,
-
[9]
URL https://openreview.net/forum?id=bx24KpJ4Eb
ISSN 2835-8856. URL https://openreview.net/forum?id=bx24KpJ4Eb. Survey Certification, Featured Certification
-
[10]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, et al. Evaluating large language models trained on code, 2021. URLhttps://arxiv.org/abs/2107.03374
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
Reward model ensembles help mitigate overoptimization
Thomas Coste, Usman Anwar, Robert Kirk, and David Krueger. Reward model ensembles help mitigate overoptimization. InThe Twelfth International Conference on Learning Representa- tions, 2024. URLhttps://openreview.net/forum?id=dcjtMYkpXx
2024
-
[12]
Ultrafeedback: boosting language models with scaled ai feedback
Ganqu Cui, Lifan Yuan, Ning Ding, Guanming Yao, Bingxiang He, Wei Zhu, Yuan Ni, Guotong Xie, Ruobing Xie, Yankai Lin, Zhiyuan Liu, and Maosong Sun. Ultrafeedback: boosting language models with scaled ai feedback. InProceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org, 2024. URL https://dl.acm.org/doi/10. 5555/3692070.3692454. 10
-
[13]
RAFT: Reward ranked finetuning for generative foundation model alignment.Transactions on Machine Learning Research, 2023
Hanze Dong, Wei Xiong, Deepanshu Goyal, Yihan Zhang, Winnie Chow, Rui Pan, Shizhe Diao, Jipeng Zhang, KaShun SHUM, and Tong Zhang. RAFT: Reward ranked finetuning for generative foundation model alignment.Transactions on Machine Learning Research, 2023. ISSN 2835-8856. URLhttps://openreview.net/forum?id=m7p5O7zblY
2023
-
[14]
Kakade, Jason D
Simon Shaolei Du, Wei Hu, Sham M. Kakade, Jason D. Lee, and Qi Lei. Few-shot learning via learning the representation, provably. InInternational Conference on Learning Representations,
-
[15]
URLhttps://openreview.net/forum?id=pW2Q2xLwIMD
-
[16]
Helping or herding? re- ward model ensembles mitigate but do not eliminate reward hacking
Jacob Eisenstein, Chirag Nagpal, Alekh Agarwal, Ahmad Beirami, Alexander Nicholas D’Amour, Krishnamurthy Dj Dvijotham, Adam Fisch, Katherine A Heller, Stephen Robert Pfohl, Deepak Ramachandran, Peter Shaw, and Jonathan Berant. Helping or herding? re- ward model ensembles mitigate but do not eliminate reward hacking. InFirst Conference on Language Modeling...
2024
-
[17]
Scaling laws for reward model overoptimization
Leo Gao, John Schulman, and Jacob Hilton. Scaling laws for reward model overoptimization. In Proceedings of the 40th International Conference on Machine Learning, ICML’23. JMLR.org,
-
[18]
URLhttps://dl.acm.org/doi/10.5555/3618408.3618845
-
[19]
Tilmann Gneiting and Adrian E Raftery. Strictly proper scoring rules, prediction, and estimation. Journal of the American Statistical Association, 102(477):359–378, 2007. doi: 10.1198/ 016214506000001437. URLhttps://doi.org/10.1198/016214506000001437
-
[20]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, et al. The llama 3 herd of models, 2024. URLhttps://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Reinforced Self-Training (ReST) for Language Modeling
Caglar Gulcehre, Tom Le Paine, Srivatsan Srinivasan, Ksenia Konyushkova, Lotte Weerts, Abhishek Sharma, Aditya Siddhant, Alex Ahern, Miaosen Wang, Chenjie Gu, Wolfgang Macherey, Arnaud Doucet, Orhan Firat, and Nando de Freitas. Reinforced self-training (rest) for language modeling, 2023. URLhttps://arxiv.org/abs/2308.08998
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Submodularity for data selection in machine translation
Katrin Kirchhoff and Jeff Bilmes. Submodularity for data selection in machine translation. In Alessandro Moschitti, Bo Pang, and Walter Daelemans, editors,Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 131–141, Doha, Qatar, October 2014. Association for Computational Linguistics. doi: 10.3115/v1/ D14-...
work page doi:10.3115/v1/ 2014
-
[23]
Science354(6317), 1240–1241 (2016) https://doi.org/10.1126/science
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, Thomas Hubert, Peter Choy, Cyprien de Masson d’Autume, Igor Babuschkin, Xinyun Chen, Po-Sen Huang, Johannes Welbl, Sven Gowal, Alexey Cherepanov, James Molloy, Daniel J. Mankowitz, Esme Sutherland Robson, Pushm...
-
[24]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe Twelfth International Conference on Learning Representations, 2024. URL https: //openreview.net/forum?id=v8L0pN6EOi
2024
-
[25]
A class of submodular functions for document summarization
Hui Lin and Jeff Bilmes. A class of submodular functions for document summarization. In Dekang Lin, Yuji Matsumoto, and Rada Mihalcea, editors,Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, pages 510–520, Portland, Oregon, USA, June 2011. Association for Computational Linguistics. URLh...
2011
-
[26]
What makes good data for alignment? a comprehensive study of automatic data selection in instruction tuning
Wei Liu, Weihao Zeng, Keqing He, Yong Jiang, and Junxian He. What makes good data for alignment? a comprehensive study of automatic data selection in instruction tuning. In The Twelfth International Conference on Learning Representations, 2024. URL https:// openreview.net/forum?id=BTKAeLqLMw. 11
2024
-
[27]
#instag: Instruction tagging for analyzing supervised fine-tuning of large language models
Keming Lu, Hongyi Yuan, Zheng Yuan, Runji Lin, Junyang Lin, Chuanqi Tan, Chang Zhou, and Jingren Zhou. #instag: Instruction tagging for analyzing supervised fine-tuning of large language models. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=pszewhybU9
2024
-
[28]
The benefit of multitask representation learning.J
Andreas Maurer, Massimiliano Pontil, and Bernardino Romera-Paredes. The benefit of multitask representation learning.J. Mach. Learn. Res., 17(1):2853–2884, January 2016. ISSN 1532-4435. URLhttps://dl.acm.org/doi/10.5555/2946645.3007034
-
[29]
London Mathematical Society Lecture Note Series
Colin McDiarmid.On the method of bounded differences, page 148–188. London Mathematical Society Lecture Note Series. Cambridge University Press, 1989. URL https://www.cambridge.org/core/books/abs/surveys-in-combinatorics-1989/ on-the-method-of-bounded-differences/AABA597B562BDA7D89C6077E302694FB
1989
-
[30]
Accelerated greedy algorithms for maximizing submodular set functions
Michel Minoux. Accelerated greedy algorithms for maximizing submodular set functions. In J. Stoer, editor,Optimization Techniques, pages 234–243, Berlin, Heidelberg, 1978. Springer Berlin Heidelberg. ISBN 978-3-540-35890-9. URL https://link.springer. com/chapter/10.1007/BFb0006528
-
[31]
MIT Press, 2nd edition, 2018
Mehryar Mohri, Afshin Rostamizadeh, and Ameet Talwalkar.Foundations of Machine Learning. MIT Press, 2nd edition, 2018. URL https://mitpress.ublish.com/ebook/ foundations-of-machine-learning--2-preview/7093/Cover
2018
-
[32]
G. L. Nemhauser, L. A. Wolsey, and M. L. Fisher. An analysis of approximations for maximizing submodular set functions–i.Math. Program., 14(1):265–294, December 1978. ISSN 0025-5610. doi: 10.1007/BF01588971. URLhttps://doi.org/10.1007/BF01588971
-
[33]
Active learning for convolutional neural networks: A core-set approach
Ozan Sener and Silvio Savarese. Active learning for convolutional neural networks: A core-set approach. InInternational Conference on Learning Representations, 2018. URL https: //openreview.net/forum?id=H1aIuk-RW
2018
-
[34]
Cambridge University Press, 2014
Shai Shalev-Shwartz and Shai Ben-David.Understanding Machine Learning: From Theory to Algorithms. Cambridge University Press, 2014. URL https://www.cambridge.org/core/ books/understanding-machine-learning/3059695661405D25673058E43C8BE2A6
-
[35]
Scaling LLM test- time compute optimally can be more effective than scaling parameters for reasoning
Charlie Victor Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling LLM test- time compute optimally can be more effective than scaling parameters for reasoning. In The Thirteenth International Conference on Learning Representations, 2025. URL https: //openreview.net/forum?id=4FWAwZtd2n
2025
-
[36]
Scaling data diversity for fine-tuning language models in human alignment
Feifan Song, Bowen Yu, Hao Lang, Haiyang Yu, Fei Huang, Houfeng Wang, and Yongbin Li. Scaling data diversity for fine-tuning language models in human alignment. In Nicoletta Calzolari, Min-Yen Kan, Veronique Hoste, Alessandro Lenci, Sakriani Sakti, and Nianwen Xue, editors,Proceedings of the 2024 Joint International Conference on Computational Linguistics...
2024
-
[37]
Principle-driven self-alignment of language models from scratch with minimal human supervision
Zhiqing Sun, Yikang Shen, Qinhong Zhou, Hongxin Zhang, Zhenfang Chen, David Daniel Cox, Yiming Yang, and Chuang Gan. Principle-driven self-alignment of language models from scratch with minimal human supervision. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URLhttps://openreview.net/forum?id=p40XRfBX96
2023
-
[38]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, et al. Llama 2: Open foundation and fine-tuned chat models, 2023. URLhttps://arxiv.org/abs/2307.09288
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Provable meta-learning of linear represen- tations
Nilesh Tripuraneni, Chi Jin, and Michael Jordan. Provable meta-learning of linear represen- tations. In Marina Meila and Tong Zhang, editors,Proceedings of the 38th International Conference on Machine Learning, volume 139 ofProceedings of Machine Learning Research, pages 10434–10443. PMLR, 18–24 Jul 2021. URL https://proceedings.mlr.press/ v139/tripuranen...
2021
-
[40]
Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InThe Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=1PL1NIMMrw
2023
-
[41]
Smith, Daniel Khashabi, and Hannaneh Hajishirzi
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-instruct: Aligning language models with self-generated instruc- tions. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors,Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long ...
-
[42]
Dai, and Quoc V Le
Jason Wei, Maarten Bosma, Vincent Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M. Dai, and Quoc V Le. Finetuned language models are zero-shot learners. In International Conference on Learning Representations, 2022. URL https://openreview. net/forum?id=gEZrGCozdqR
2022
-
[43]
Submodularity in data subset selection and active learning
Kai Wei, Rishabh Iyer, and Jeff Bilmes. Submodularity in data subset selection and active learning. In Francis Bach and David Blei, editors,Proceedings of the 32nd International Conference on Machine Learning, volume 37 ofProceedings of Machine Learning Research, pages 1954–1963, Lille, France, 07–09 Jul 2015. PMLR. URL https://proceedings.mlr. press/v37/...
1954
-
[44]
Inference scaling laws: An empirical analysis of compute-optimal inference for LLM problem-solving
Yangzhen Wu, Zhiqing Sun, Shanda Li, Sean Welleck, and Yiming Yang. Inference scaling laws: An empirical analysis of compute-optimal inference for LLM problem-solving. In The Thirteenth International Conference on Learning Representations, 2025. URL https: //openreview.net/forum?id=VNckp7JEHn
2025
-
[45]
Less: selecting influential data for targeted instruction tuning
Mengzhou Xia, Sadhika Malladi, Suchin Gururangan, Sanjeev Arora, and Danqi Chen. Less: selecting influential data for targeted instruction tuning. InProceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org, 2024. URLhttps://dl.acm.org/ doi/10.5555/3692070.3694291
-
[46]
Magpie: Alignment data synthesis from scratch by prompting aligned LLMs with nothing
Zhangchen Xu, Fengqing Jiang, Luyao Niu, Yuntian Deng, Radha Poovendran, Yejin Choi, and Bill Yuchen Lin. Magpie: Alignment data synthesis from scratch by prompting aligned LLMs with nothing. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=Pnk7vMbznK
2025
-
[47]
RRHF: Rank responses to align language models with human feedback
Hongyi Yuan, Zheng Yuan, Chuanqi Tan, Wei Wang, Songfang Huang, and Fei Huang. RRHF: Rank responses to align language models with human feedback. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum? id=EdIGMCHk4l
2023
-
[48]
STar: Bootstrapping reasoning with reasoning
Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah Goodman. STar: Bootstrapping reasoning with reasoning. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors, Advances in Neural Information Processing Systems, 2022. URL https://openreview.net/ forum?id=_3ELRdg2sgI
2022
-
[49]
LIMA: Less is more for alignment
Chunting Zhou, Pengfei Liu, Puxin Xu, Srini Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, LILI YU, Susan Zhang, Gargi Ghosh, Mike Lewis, Luke Zettlemoyer, and Omer Levy. LIMA: Less is more for alignment. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URLhttps://openreview.net/forum?id=KBMOKmX2he
2023
-
[50]
prompts” and∼N p/C“responses
Banghua Zhu, Evan Frick, Tianhao Wu, Hanlin Zhu, Karthik Ganesan, Wei-Lin Chiang, Jian Zhang, and Jiantao Jiao. Starling-7b: Improving helpfulness and harmlessness with RLAIF. InFirst Conference on Language Modeling, 2024. URL https://openreview.net/forum? id=GqDntYTTbk. 13 A Extended Related Work Response multiplicity in post-training and inference.Moder...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.