DeepLatent: Think with Images via Parallel Latent Visual Reasoning
Pith reviewed 2026-06-28 18:42 UTC · model grok-4.3
The pith
DeepLatent enables parallel latent visual reasoning by generating anchored 2D tokens and optimizing them with continuous-space RL.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
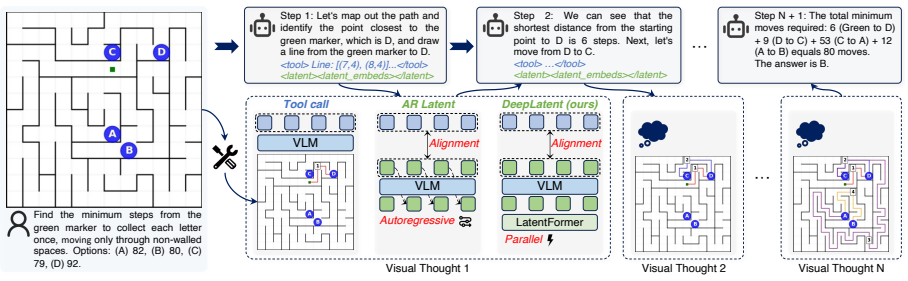
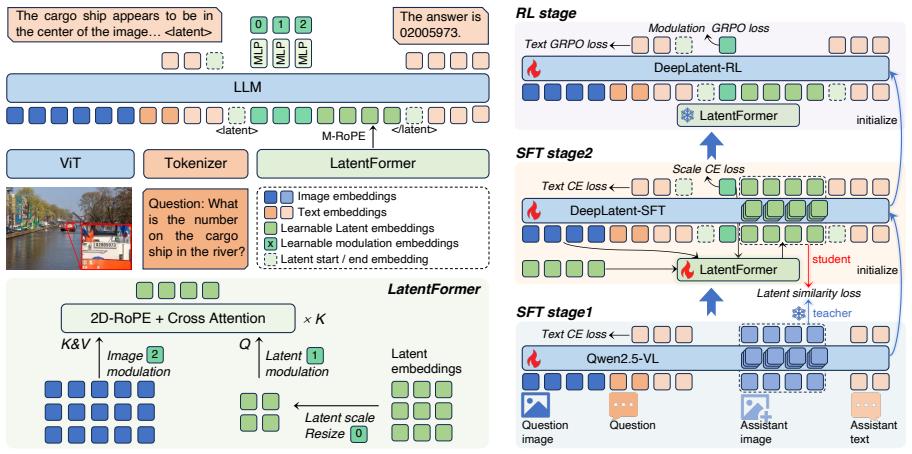
DeepLatent is a parallel framework for latent visual reasoning that uses LatentFormer to generate context-conditioned latent states in parallel with learnable 2D tokens anchored to original image features, combined with a continuous-space reinforcement learning algorithm to optimize latent modulation parameters directly in the embedding space, leading to state-of-the-art performance after knowledge distillation training on the DeepLatent-180K dataset.
What carries the argument
LatentFormer, a module that generates context-conditioned latent states in parallel using learnable 2D tokens anchored to original image features.
If this is right
- Extensive evaluations show state-of-the-art performance on multiple benchmarks.
- The continuous-space RL algorithm improves latent representation quality significantly.
- Knowledge distillation followed by RL provides effective training for the framework.
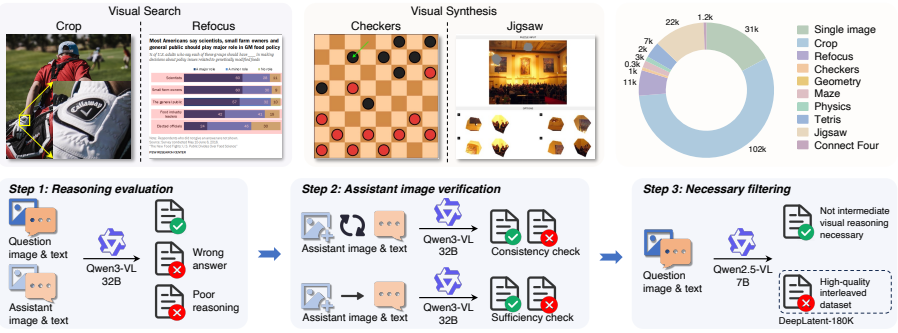
- The DeepLatent-180K dataset supports large-scale training for latent visual reasoning.
Where Pith is reading between the lines
- Such parallel methods could enable lower latency in applications requiring visual thinking steps.
- Anchoring to original features may preserve more accurate visual details during reasoning.
- Optimizing in continuous embedding space might apply to other types of latent reasoning beyond vision.
Load-bearing premise
Learnable 2D tokens generated in parallel and anchored to original image features produce latent states that capture effective visual information superior to autoregressive alternatives.
What would settle it
If evaluations on the benchmarks show that existing autoregressive latent methods achieve comparable or better performance than DeepLatent, the central claim would be falsified.
Figures


read the original abstract
The emerging paradigm of "thinking with images" embeds visual states into intermediate reasoning steps, defining a new frontier for Vision-Language Models. Existing approaches diverge along two lines. Tool-assisted methods apply explicit visual operations but suffer from high latency and restricted manipulation types. Latent reasoning methods autoregressively produce implicit visual states, but underperform tool-assisted methods, and their latent tokens fail to capture effective visual information. In this work, we propose DeepLatent, a parallel framework for latent visual reasoning. First, we introduce LatentFormer. It uses learnable 2D tokens to generate context-conditioned latent states in parallel, anchoring every visual update directly in the original image features. Second, we design a continuous-space reinforcement learning algorithm. It optimizes latent modulation parameters directly in the embedding space, significantly improving latent representation quality. The framework is trained via knowledge distillation followed by this continuous-space RL algorithm. Furthermore, we contribute DeepLatent-180K, a large-scale dataset tailored for latent visual reasoning. Extensive evaluations across multiple benchmarks demonstrate that DeepLatent achieves state-of-the-art performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DeepLatent, a parallel framework for latent visual reasoning in vision-language models. It introduces LatentFormer, which generates context-conditioned latent states in parallel via learnable 2D tokens anchored directly to original image features; a continuous-space reinforcement learning algorithm that optimizes latent modulation parameters in embedding space; training via knowledge distillation followed by this RL stage; and the DeepLatent-180K dataset. The central claim is that this approach overcomes limitations of both tool-assisted and autoregressive latent methods, achieving state-of-the-art performance across multiple benchmarks.
Significance. If the performance claims hold after proper validation, the work would advance the 'thinking with images' paradigm by replacing autoregressive latent generation with a parallel, anchored mechanism that could improve both effectiveness and efficiency. The continuous-space RL component and the contributed dataset represent potentially reusable contributions for future latent reasoning research.
major comments (2)
- [Abstract and §3 (Method)] The abstract and method description assert that parallel generation of anchored 2D tokens produces latent states superior to autoregressive alternatives, yet no ablation isolates this mechanism from the continuous-space RL stage, the distillation pre-training, or differences in compute/data. Without such controls, the SOTA claim cannot be attributed to the proposed parallel anchoring.
- [§5 (Experiments)] No quantitative results, tables, or error bars are referenced to support the 'state-of-the-art performance' assertion across benchmarks; the experimental section must include direct comparisons to the autoregressive latent baselines the paper criticizes, with statistical significance.
minor comments (2)
- [§3.1 (LatentFormer)] Clarify the precise fusion operation by which learnable 2D tokens are anchored to image features at each parallel step (e.g., cross-attention weights or concatenation details).
- [§4 (Dataset)] The dataset contribution (DeepLatent-180K) would benefit from a clearer description of its construction, size breakdown, and how it differs from existing visual reasoning datasets.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps clarify the attribution of our contributions and strengthens the experimental presentation. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract and §3 (Method)] The abstract and method description assert that parallel generation of anchored 2D tokens produces latent states superior to autoregressive alternatives, yet no ablation isolates this mechanism from the continuous-space RL stage, the distillation pre-training, or differences in compute/data. Without such controls, the SOTA claim cannot be attributed to the proposed parallel anchoring.
Authors: We agree that isolating the parallel anchored token mechanism is essential for attributing performance gains. In the revised manuscript we will add controlled ablations that disable the parallel 2D token generation while holding the continuous-space RL stage, distillation pre-training, compute budget, and data fixed, allowing direct comparison to autoregressive latent baselines under matched conditions. revision: yes
-
Referee: [§5 (Experiments)] No quantitative results, tables, or error bars are referenced to support the 'state-of-the-art performance' assertion across benchmarks; the experimental section must include direct comparisons to the autoregressive latent baselines the paper criticizes, with statistical significance.
Authors: The experimental section contains quantitative results and tables, but we acknowledge that explicit cross-references, error bars, and statistical tests may not be sufficiently prominent. We will revise §5 to include direct numerical comparisons against the autoregressive latent baselines, report error bars across multiple runs, and add statistical significance tests (e.g., paired t-tests) to support all SOTA claims. revision: yes
Circularity Check
No circularity: empirical architecture proposal with no derivation chain or self-referential predictions.
full rationale
The paper introduces DeepLatent as a new parallel latent reasoning framework using LatentFormer (learnable 2D tokens anchored to image features) and continuous-space RL, trained via distillation then RL, with a new dataset. All claims reduce to empirical benchmark results rather than any mathematical derivation, prediction, or first-principles result. No equations, uniqueness theorems, or fitted-parameter-as-prediction steps appear in the provided text. The SOTA claim is presented as an outcome of evaluations, not a constructed equivalence. This is a standard empirical ML contribution with no load-bearing self-citation or definitional circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Flamingo: a visual language model for few-shot learning , author=. Advances in neural information processing systems , volume=
-
[2]
International conference on machine learning , pages=
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[3]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[4]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[6]
2024 , eprint =
Hao Shao and Shengju Qian and Han Xiao and Guanglu Song and Zhuofan Zong and Letian Wang and Yu Liu and Hongsheng Li , title =. 2024 , eprint =
2024
-
[7]
Thinking with Images for Multimodal Reasoning: Foundations, Methods, and Future Frontiers
Thinking with images for multimodal reasoning: Foundations, methods, and future frontiers , author=. arXiv preprint arXiv:2506.23918 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
arXiv preprint arXiv:2411.19488 , year =
Jun Gao and Yongqi Li and Ziqiang Cao and Wenjie Li , title =. arXiv preprint arXiv:2411.19488 , year =
-
[9]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Look-back: Implicit visual re-focusing in mllm reasoning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[10]
Pyvision: Agentic vision with dynamic tooling.arXiv, 2507.07998, 2025
Pyvision: Agentic vision with dynamic tooling , author=. arXiv preprint arXiv:2507.07998 , year=
-
[11]
arXiv e-prints , pages=
Chain-of-focus: Adaptive visual search and zooming for multimodal reasoning via rl , author=. arXiv e-prints , pages=
-
[12]
arXiv preprint arXiv:2505.23558 , year=
Qwen look again: Guiding vision-language reasoning models to re-attention visual information , author=. arXiv preprint arXiv:2505.23558 , year=
-
[13]
The Latent Space: Foundation, Evolution, Mechanism, Ability, and Outlook
The latent space: Foundation, evolution, mechanism, ability, and outlook , author=. arXiv preprint arXiv:2604.02029 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
arXiv preprint arXiv:2510.12603 , year=
Reasoning in the dark: Interleaved vision-text reasoning in latent space , author=. arXiv preprint arXiv:2510.12603 , year=
-
[15]
Latent Implicit Visual Reasoning
Latent Implicit Visual Reasoning , author=. arXiv preprint arXiv:2512.21218 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
arXiv preprint arXiv:2603.25629 , year=
LanteRn: Latent Visual Structured Reasoning , author=. arXiv preprint arXiv:2603.25629 , year=
-
[17]
arXiv preprint arXiv:2512.21711 , year=
Do latent tokens think? a causal and adversarial analysis of chain-of-continuous-thought , author=. arXiv preprint arXiv:2512.21711 , year=
-
[18]
Plug-and-play grounding of reasoning in multimodal large language models , author=. arXiv preprint arXiv:2403.19322 , year=
-
[19]
VGR: Visual Grounded Reasoning
Vgr: Visual grounded reasoning , author=. arXiv preprint arXiv:2506.11991 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
arXiv e-prints , pages=
Don't Look Only Once: Towards Multimodal Interactive Reasoning with Selective Visual Revisitation , author=. arXiv e-prints , pages=
-
[21]
arXiv preprint arXiv:2505.20289 , year=
Visualtoolagent (vista): A reinforcement learning framework for visual tool selection , author=. arXiv preprint arXiv:2505.20289 , year=
-
[22]
WebWatcher: Breaking New Frontier of Vision-Language Deep Research Agent
Webwatcher: Breaking new frontier of vision-language deep research agent , author=. arXiv preprint arXiv:2508.05748 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Cmmcot: Enhancing complex multi-image comprehension via multi-modal chain-of-thought and memory augmentation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[24]
Training Large Language Models to Reason in a Continuous Latent Space
Training large language models to reason in a continuous latent space , author=. arXiv preprint arXiv:2412.06769 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Compressed Chain of Thought: Efficient Reasoning Through Dense Representations
Compressed chain of thought: Efficient reasoning through dense representations , author=. arXiv preprint arXiv:2412.13171 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
LaRS: Latent reasoning skills for chain-of-thought reasoning , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[27]
Forty-first International Conference on Machine Learning , year=
Prismatic vlms: Investigating the design space of visually-conditioned language models , author=. Forty-first International Conference on Machine Learning , year=
-
[28]
PaliGemma: A versatile 3B VLM for transfer
Paligemma: A versatile 3b vlm for transfer , author=. arXiv preprint arXiv:2407.07726 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Softcot: Soft chain-of-thought for efficient reasoning with llms , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[30]
arXiv preprint arXiv:2510.24514 , year=
Latent sketchpad: Sketching visual thoughts to elicit multimodal reasoning in mllms , author=. arXiv preprint arXiv:2510.24514 , year=
-
[31]
arXiv preprint arXiv:2602.20980 , year=
Crystal: Spontaneous emergence of visual latents in mllms , author=. arXiv preprint arXiv:2602.20980 , year=
-
[32]
arXiv preprint arXiv:2511.11007 , year=
Vismem: Latent vision memory unlocks potential of vision-language models , author=. arXiv preprint arXiv:2511.11007 , year=
-
[33]
Think with 3d: Geometric imagination grounded spatial reasoning from limited views , author=. arXiv preprint arXiv:2510.18632 , year=
-
[34]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
L2V-CoT: Cross-Modal Transfer of Chain-of-Thought Reasoning via Latent Intervention , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[35]
arXiv preprint arXiv:2603.13366 , year=
Thinking in uncertainty: Mitigating hallucinations in mlrms with latent entropy-aware decoding , author=. arXiv preprint arXiv:2603.13366 , year=
-
[36]
Imagination Helps Visual Reasoning, But Not Yet in Latent Space
Imagination helps visual reasoning, but not yet in latent space , author=. arXiv preprint arXiv:2602.22766 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Llava-cot: Let vision language models reason step-by-step , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[38]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Improve vision language model chain-of-thought reasoning , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[39]
Advances in Neural Information Processing Systems , volume=
Mulberry: Empowering mllm with o1-like reasoning and reflection via collective monte carlo tree search , author=. Advances in Neural Information Processing Systems , volume=
-
[40]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
R1-onevision: Advancing generalized multimodal reasoning through cross-modal formalization , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[41]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Vision-r1: Incentivizing reasoning capability in multimodal large language models , author=. arXiv preprint arXiv:2503.06749 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Vtool-r1: Vlms learn to think with images via reinforcement learning on multimodal tool use , author=. arXiv preprint arXiv:2505.19255 , year=
-
[44]
V-thinker: Interactive thinking with images
V-thinker: Interactive thinking with images , author=. arXiv preprint arXiv:2511.04460 , year=
-
[45]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Vipergpt: Visual inference via python execution for reasoning , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[46]
Thyme: Think beyond images , author=. arXiv preprint arXiv:2508.11630 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Visual programming: Compositional visual reasoning without training , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[48]
DeepEyes: Incentivizing "Thinking with Images" via Reinforcement Learning
Deepeyes: Incentivizing" thinking with images" via reinforcement learning , author=. arXiv preprint arXiv:2505.14362 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
2025 , howpublished=
Thinking with Images , author=. 2025 , howpublished=
2025
-
[50]
Advances in Neural Information Processing Systems , volume=
Visual cot: Advancing multi-modal language models with a comprehensive dataset and benchmark for chain-of-thought reasoning , author=. Advances in Neural Information Processing Systems , volume=
-
[51]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Dyfo: A training-free dynamic focus visual search for enhancing lmms in fine-grained visual understanding , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[52]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Divide, conquer and combine: A training-free framework for high-resolution image perception in multimodal large language models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[53]
International Conference on Learning Representations , volume=
Cogcom: A visual language model with chain-of-manipulations reasoning , author=. International Conference on Learning Representations , volume=
-
[54]
arXiv e-prints , pages=
GRIT: Teaching MLLMs to Think with Images , author=. arXiv e-prints , pages=
-
[55]
arXiv preprint arXiv:2501.05452 , year =
Xingyu Fu and Minqian Liu and Zhengyuan Yang and John Corring and Yijuan Lu and Jianwei Yang and Dan Roth and Dinei Florencio and Cha Zhang , title =. arXiv preprint arXiv:2501.05452 , year =
-
[56]
Advances in Neural Information Processing Systems , volume=
Visual sketchpad: Sketching as a visual chain of thought for multimodal language models , author=. Advances in Neural Information Processing Systems , volume=
-
[57]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Visual program distillation: Distilling tools and programmatic reasoning into vision-language models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[58]
arXiv preprint arXiv:2512.05665 , year=
Interleaved latent visual reasoning with selective perceptual modeling , author=. arXiv preprint arXiv:2512.05665 , year=
-
[59]
arXiv preprint arXiv:2601.10129 , year=
LaViT: Aligning Latent Visual Thoughts for Multi-modal Reasoning , author=. arXiv preprint arXiv:2601.10129 , year=
-
[60]
LaRe: Latent Refocusing for Multimodal Reasoning
Multimodal Reasoning via Latent Refocusing , author=. arXiv preprint arXiv:2511.02360 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[61]
Imagine while Reasoning in Space: Multimodal Visualization-of-Thought
Imagine while reasoning in space: Multimodal visualization-of-thought , author=. arXiv preprint arXiv:2501.07542 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[62]
arXiv preprint arXiv:2512.18745 , year=
InSight-o3: Empowering Multimodal Foundation Models with Generalized Visual Search , author=. arXiv preprint arXiv:2512.18745 , year=
-
[63]
arXiv preprint arXiv:2507.16746 , year=
Zebra-cot: A dataset for interleaved vision language reasoning , author=. arXiv preprint arXiv:2507.16746 , year=
-
[64]
Reasoning Within the Mind: Dynamic Multimodal Interleaving in Latent Space
Reasoning within the mind: Dynamic multimodal interleaving in latent space , author=. arXiv preprint arXiv:2512.12623 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[65]
arXiv preprint arXiv:2505.22525 , year =
Thinking with Generated Images , author =. arXiv preprint arXiv:2505.22525 , year =
-
[66]
Chameleon: Mixed-Modal Early-Fusion Foundation Models
Chameleon: Mixed-modal early-fusion foundation models , author=. arXiv preprint arXiv:2405.09818 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[67]
Mini-o3: Scaling Up Reasoning Patterns and Interaction Turns for Visual Search
Mini-o3: Scaling up reasoning patterns and interaction turns for visual search , author=. arXiv preprint arXiv:2509.07969 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[68]
arXiv preprint arXiv:2511.21395 , year=
Monet: Reasoning in latent visual space beyond images and language , author=. arXiv preprint arXiv:2511.21395 , year=
-
[69]
Latent visual reasoning , author=. arXiv preprint arXiv:2509.24251 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[70]
arXiv preprint arXiv:2602.13738 , year=
OneLatent: Single-Token Compression for Visual Latent Reasoning , author=. arXiv preprint arXiv:2602.13738 , year=
-
[71]
Multimodal Latent Reasoning via Predictive Embeddings
Multimodal Latent Reasoning via Predictive Embeddings , author=. arXiv preprint arXiv:2604.08065 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[72]
arXiv preprint arXiv:2508.12587 , year=
Multimodal chain of continuous thought for latent-space reasoning in vision-language models , author=. arXiv preprint arXiv:2508.12587 , year=
-
[73]
Pixel Reasoner: Incentivizing Pixel-Space Reasoning with Curiosity-Driven Reinforcement Learning
Pixel reasoner: Incentivizing pixel-space reasoning with curiosity-driven reinforcement learning , author=. arXiv preprint arXiv:2505.15966 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[74]
arXiv preprint arXiv:2511.19418 , year=
Chain-of-visual-thought: Teaching vlms to see and think better with continuous visual tokens , author=. arXiv preprint arXiv:2511.19418 , year=
-
[75]
Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, and Saining Xie
Sketch-in-latents: Eliciting unified reasoning in mllms , author=. arXiv preprint arXiv:2512.16584 , year=
-
[76]
OpenThinkIMG: Learning to Think with Images via Visual Tool Reinforcement Learning
Openthinkimg: Learning to think with images via visual tool reinforcement learning , author=. arXiv preprint arXiv:2505.08617 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[77]
Vision-aligned Latent Reasoning for Multi-modal Large Language Model
Vision-aligned Latent Reasoning for Multi-modal Large Language Model , author=. arXiv preprint arXiv:2602.04476 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[78]
Machine Mental Imagery: Empower Multimodal Reasoning with Latent Visual Tokens
Machine mental imagery: Empower multimodal reasoning with latent visual tokens , author=. arXiv preprint arXiv:2506.17218 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[79]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
V*: Guided visual search as a core mechanism in multimodal llms , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[80]
arXiv preprint arXiv:2601.19834 , year=
Visual Generation Unlocks Human-Like Reasoning through Multimodal World Models , author=. arXiv preprint arXiv:2601.19834 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.