Linguistics-Aware Non-Distortionary LLM Watermarking
Pith reviewed 2026-06-28 19:15 UTC · model grok-4.3
The pith
LUNA adapts watermark depth to part-of-speech entropy so LLM text stays detectable from output alone while keeping quality shifts smaller than prior methods across languages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
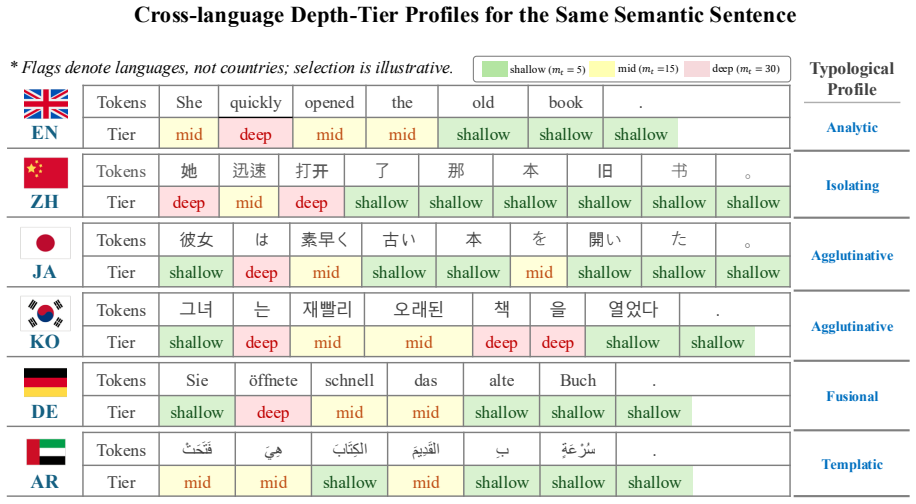
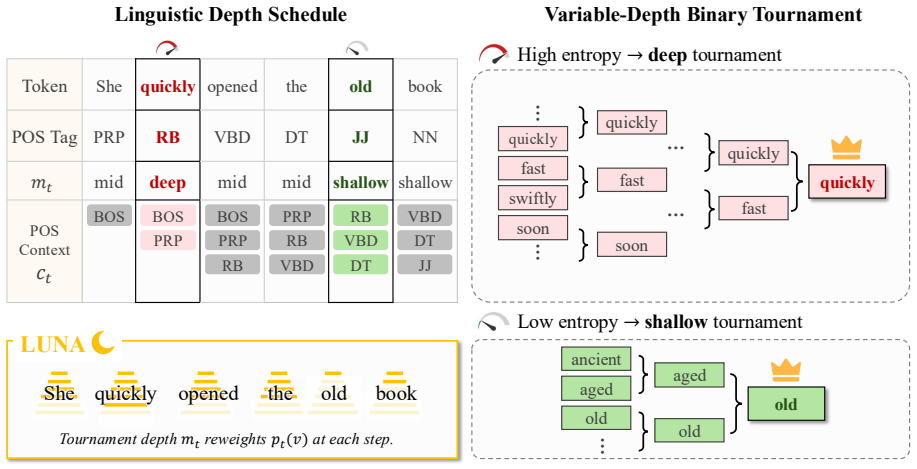
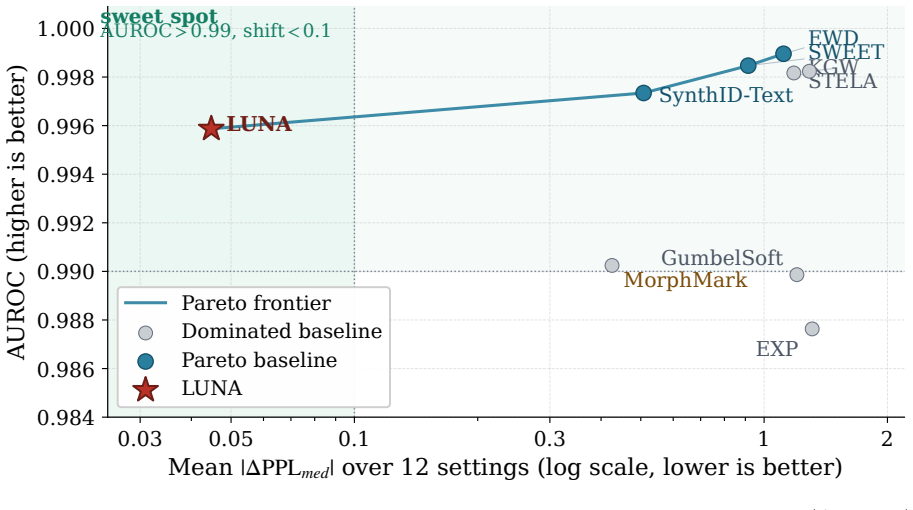
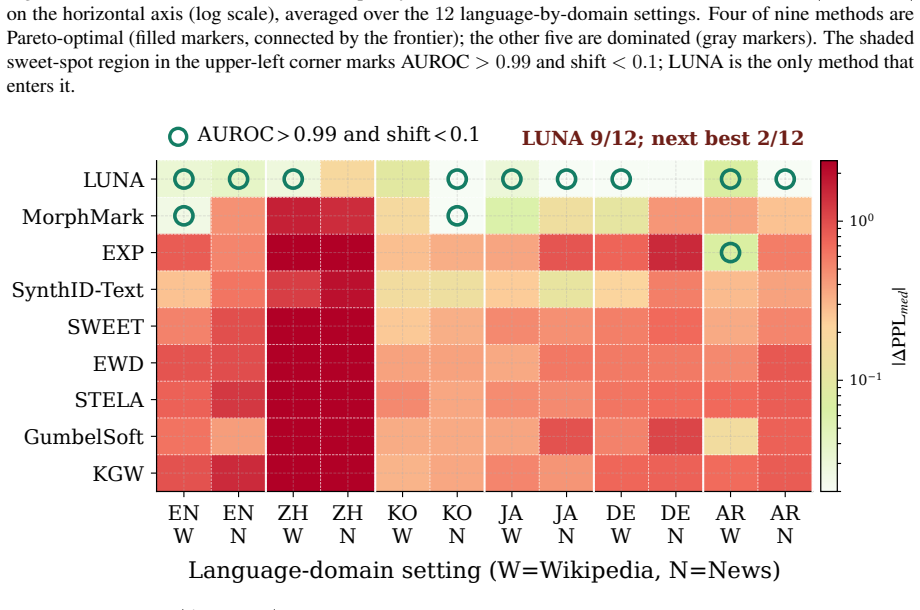
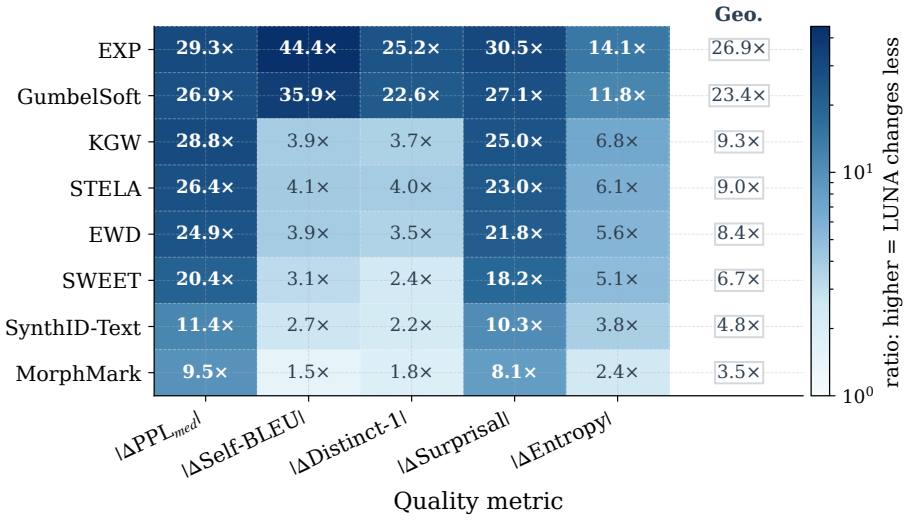
LUNA estimates normalized next-tag entropy from part-of-speech contexts in an external corpus and uses it to set the depth of a non-distortionary binary tournament sampler; the detector reconstructs the same schedule from text, a tokenizer, a tagger, and a secret key. In twelve language-domain settings it reaches an AUROC of 0.9959 and a mean absolute median perplexity shift of 0.045, with its 95 percent bootstrap interval below all baselines, while also recording the lowest shifts in Self-BLEU, Distinct-1, surprisal, and entropy. It is the only method that simultaneously exceeds 0.99 AUROC and stays below 0.1 perplexity shift in a majority of settings.
What carries the argument
normalized next-tag entropy from part-of-speech contexts that sets the depth of a non-distortionary binary tournament sampler
If this is right
- Watermark evidence can be recovered from generated text without access to the original model or logits.
- The same secret key and tagger suffice for detection in any language for which an external tagged corpus exists.
- Quality metrics including perplexity, Self-BLEU, and entropy remain statistically closer to the unwatermarked baseline than with eight comparison methods.
- The regime of AUROC above 0.99 together with median perplexity shift below 0.1 becomes attainable in most language-domain pairs rather than only isolated cases.
Where Pith is reading between the lines
- The approach could be extended by replacing the external corpus with an online tagger that updates entropy estimates from the deployment domain itself.
- If the entropy schedule proves stable under domain shift, the same machinery might support watermarking of code or mathematical text by substituting appropriate tag sets.
- Detection cost scales only with the cost of tagging and entropy lookup, suggesting the method remains feasible for high-volume verification pipelines.
Load-bearing premise
Normalized next-tag entropy from an external corpus can be used to choose sampler depth so the watermark stays single-token non-distortionary and detectable from text alone across typologically diverse languages.
What would settle it
A new typologically distinct language where the 95 percent bootstrap interval for median perplexity shift overlaps any baseline interval while AUROC falls below 0.99.
Figures
read the original abstract
Watermarking should identify language-model output without degrading quality or limiting verification to the model provider. Multilingual deployment makes this harder because morphology, segmentation, and script change where watermark evidence can enter naturally. We introduce LUNA, a linguistically adaptive watermark that combines model-free detection with single-token non-distortion under the standard random-key model. LUNA estimates normalized next-tag entropy from part-of-speech contexts in an external corpus and uses it to set the depth of a non-distortionary binary tournament sampler; the detector reconstructs the same schedule from text, a tokenizer, a tagger, and a secret key. We evaluate six typologically diverse languages and two domains against eight primary baselines. LUNA attains an AUROC of 0.9959 and the lowest mean absolute median perplexity shift of 0.045 across the twelve settings; its 95% bootstrap interval [0.022, 0.073] lies below all baseline intervals. LUNA also records the lowest mean Self-BLEU, Distinct-1, surprisal, and entropy shifts. It is the only method that simultaneously achieves AUROC > 0.99 and an absolute median perplexity shift below 0.1 in a majority of settings, reaching this regime in 9 of the 12 settings while no baseline reaches it in more than 2. Our code is available at: https://github.com/Shinwoo-Park/luna_watermark
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LUNA, a linguistically adaptive LLM watermarking scheme that estimates normalized next-tag entropy from part-of-speech contexts in an external corpus to control the depth of a non-distortionary binary tournament sampler under the random-key model. This produces single-token watermarks detectable from text alone via a tokenizer, tagger, and secret key. Evaluation spans six typologically diverse languages and two domains against eight baselines; LUNA reports AUROC 0.9959, the lowest mean absolute median perplexity shift of 0.045 (95% bootstrap interval [0.022, 0.073]), and is the only method achieving AUROC > 0.99 together with absolute median perplexity shift < 0.1 in a majority (9/12) of settings. Code is released.
Significance. If the central performance claims and the POS-entropy-controlled sampler hold under full verification of the derivations and controls, the work would advance multilingual watermarking by delivering high detectability without quality degradation or provider-only verification. The open release of code and the breadth of the evaluation (six languages, two domains, eight baselines, bootstrap intervals) are concrete strengths that support reproducibility and falsifiability.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. The report highlights the evaluation breadth, code release, and performance claims as strengths supporting reproducibility.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's central construction estimates normalized next-tag entropy from part-of-speech contexts in an external corpus to control binary tournament sampler depth; detection reconstructs the identical schedule from text, tokenizer, tagger and key alone. No equation or step reduces by construction to a parameter fitted on the evaluation data itself. Performance metrics (AUROC 0.9959, median perplexity shift 0.045) are obtained by direct comparison against eight baselines on six languages and two domains, with no self-citation load-bearing the uniqueness claim and no ansatz or renaming that collapses the result to its inputs. The derivation therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Normalized next-tag entropy estimated from POS contexts in an external corpus can be used to set the depth of a non-distortionary binary tournament sampler
Reference graph
Works this paper leans on
-
[1]
EXAONE 3.5: Series of large language models for real-world use cases
EXAONE 3.5: Series of Large Language Models for Real-world Use Cases , author=. arXiv preprint arXiv:2412.04862 , year=
-
[2]
Procedia Computer Science , year=
Martins, Pedro Henrique and Fernandes, Patrick and Alves, Jo. Procedia Computer Science , year=
-
[3]
Sengupta, Neha and Sahu, Sunil Kumar and Jia, Bokang and Katipomu, Satheesh and Li, Haonan and Koto, Fajri and Marshall, William and Gosal, Gurpreet and Liu, Cynthia and Chen, Zhiming and others , journal=
-
[4]
and Nguyen, Thien Huu
Nguyen, Thuat and Nguyen, Chien Van and Lai, Viet Dac and Man, Hieu and Ngo, Nghia Trung and Dernoncourt, Franck and Rossi, Ryan A. and Nguyen, Thien Huu. C ultura X : A Cleaned, Enormous, and Multilingual Dataset for Large Language Models in 167 Languages. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resou...
2024
-
[5]
Wikimedia Wikipedia Dataset , author =
-
[6]
Saiful and Mubasshir, Kazi and Li, Yuan-Fang and Kang, Yong-Bin and Rahman, M
Hasan, Tahmid and Bhattacharjee, Abhik and Islam, Md. Saiful and Mubasshir, Kazi and Li, Yuan-Fang and Kang, Yong-Bin and Rahman, M. Sohel and Shahriyar, Rifat. XL -Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages. Findings of the Association for Computational Linguistics (ACL). 2021
2021
-
[7]
MLSUM : The Multilingual Summarization Corpus
Scialom, Thomas and Dray, Paul-Alexis and Lamprier, Sylvain and Piwowarski, Benjamin and Staiano, Jacopo. MLSUM : The Multilingual Summarization Corpus. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020
2020
-
[8]
S udachi: a J apanese T okenizer for B usiness
Takaoka, Kazuma and Hisamoto, Sorami and Kawahara, Noriko and Sakamoto, Miho and Uchida, Yoshitaka and Matsumoto, Yuji. S udachi: a J apanese T okenizer for B usiness. Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC). 2018
2018
-
[9]
CAM e L Tools: An Open Source Python Toolkit for A rabic Natural Language Processing
Obeid, Ossama and Zalmout, Nasser and Khalifa, Salam and Taji, Dima and Oudah, Mai and Alhafni, Bashar and Inoue, Go and Eryani, Fadhl and Erdmann, Alexander and Habash, Nizar. CAM e L Tools: An Open Source Python Toolkit for A rabic Natural Language Processing. Proceedings of the Twelfth Language Resources and Evaluation Conference (LREC). 2020
2020
-
[10]
2026 , note =
Park, Shinwoo and Park, Hyejin and An, Hyeseon and Han, Yo-Sub , booktitle =. 2026 , note =
2026
-
[11]
G umbel S oft: Diversified Language Model Watermarking via the G umbel M ax-trick
Fu, Jiayi and Zhao, Xuandong and Yang, Ruihan and Zhang, Yuansen and Chen, Jiangjie and Xiao, Yanghua. G umbel S oft: Diversified Language Model Watermarking via the G umbel M ax-trick. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL). 2024
2024
-
[12]
Krishna, Kalpesh and Song, Yixiao and Karpinska, Marzena and Wieting, John and Iyyer, Mohit , booktitle=
-
[13]
Watermarking
Aaronson, Scott and Kirchner, Hendrik , year =. Watermarking
-
[14]
Proceedings of the 37th Conference on Learning Theory (COLT) , year =
Undetectable Watermarks for Language Models , author =. Proceedings of the 37th Conference on Learning Theory (COLT) , year =
-
[15]
A Confederacy of Models: a Comprehensive Evaluation of LLM s on Creative Writing
G \'o mez-Rodr \'i guez, Carlos and Williams, Paul. A Confederacy of Models: a Comprehensive Evaluation of LLM s on Creative Writing. Findings of the Association for Computational Linguistics (EMNLP). 2023
2023
-
[16]
Assisting in Writing W ikipedia-like Articles From Scratch with Large Language Models
Shao, Yijia and Jiang, Yucheng and Kanell, Theodore and Xu, Peter and Khattab, Omar and Lam, Monica. Assisting in Writing W ikipedia-like Articles From Scratch with Large Language Models. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL). 2024
2024
-
[17]
Fine-tuning Large Language Models for Improving Factuality in Legal Question Answering
Hu, Yinghao and Gan, Leilei and Xiao, Wenyi and Kuang, Kun and Wu, Fei. Fine-tuning Large Language Models for Improving Factuality in Legal Question Answering. Proceedings of the 31st International Conference on Computational Linguistics (COLING). 2025
2025
-
[18]
B io M istral: A Collection of Open-Source Pretrained Large Language Models for Medical Domains
Labrak, Yanis and Bazoge, Adrien and Morin, Emmanuel and Gourraud, Pierre-Antoine and Rouvier, Mickael and Dufour, Richard. B io M istral: A Collection of Open-Source Pretrained Large Language Models for Medical Domains. Findings of the Association for Computational Linguistics (ACL). 2024
2024
-
[19]
On Large Language Models' Hallucination with Regard to Known Facts
Jiang, Che and Qi, Biqing and Hong, Xiangyu and Fu, Dayuan and Cheng, Yang and Meng, Fandong and Yu, Mo and Zhou, Bowen and Zhou, Jie. On Large Language Models' Hallucination with Regard to Known Facts. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL). 2024
2024
-
[20]
Disinformation Capabilities of Large Language Models
Vykopal, Ivan and Pikuliak, Mat \'u s and Srba, Ivan and Moro, Robert and Macko, Dominik and Bielikova, Maria. Disinformation Capabilities of Large Language Models. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL). 2024
2024
-
[21]
Proceedings of International Conference on Machine Learning (ICML) , year =
Watermark Stealing in Large Language Models , author =. Proceedings of International Conference on Machine Learning (ICML) , year =
-
[22]
Proceedings of International Conference on Machine Learning (ICML) , year =
De-mark: Watermark Removal in Large Language Models , author =. Proceedings of International Conference on Machine Learning (ICML) , year =
-
[23]
IEEE Conference on Secure and Trustworthy Machine Learning (SaTML) , year=
MARKMyWORDS: Analyzing and Evaluating Language Model Watermarks , author=. IEEE Conference on Secure and Trustworthy Machine Learning (SaTML) , year=
-
[24]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Judging LLM-as-a-judge with MT-bench and Chatbot Arena , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[25]
Can Large Language Models Be an Alternative to Human Evaluations?
Chiang, Cheng-Han and Lee, Hung-yi. Can Large Language Models Be an Alternative to Human Evaluations?. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL). 2023
2023
-
[26]
DITTO : A Spoofing Attack Framework on Watermarked LLM s via Knowledge Distillation
An, Hyeseon and Park, Shinwoo and Woo, Suyeon and Han, Yo-Sub. DITTO : A Spoofing Attack Framework on Watermarked LLM s via Knowledge Distillation. Proceedings of the 19th Conference of the E uropean Chapter of the A ssociation for C omputational L inguistics (EACL). 2026
2026
-
[27]
M ark LLM : An Open-Source Toolkit for LLM Watermarking
Pan, Leyi and Liu, Aiwei and He, Zhiwei and Gao, Zitian and Zhao, Xuandong and Lu, Yijian and Zhou, Binglin and Liu, Shuliang and Hu, Xuming and Wen, Lijie and King, Irwin and Yu, Philip S. M ark LLM : An Open-Source Toolkit for LLM Watermarking. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: System Demonstrations ...
2024
-
[28]
2024 , howpublished =
Regulation (. 2024 , howpublished =
2024
-
[29]
ACM Computing Surveys , year=
A Survey of Text Watermarking in the Era of Large Language Models , author=. ACM Computing Surveys , year=
-
[30]
From Intentions to Techniques: A Comprehensive Taxonomy and Challenges in Text Watermarking for Large Language Models
Lalai, Harsh Nishant and Anantha Ramakrishnan, Aashish and Shah, Raj Sanjay and Lee, Dongwon. From Intentions to Techniques: A Comprehensive Taxonomy and Challenges in Text Watermarking for Large Language Models. Findings of the Association for Computational Linguistics (NAACL). 2025
2025
-
[31]
Proceedings of the AAAI Conference on Artificial Intelligence , year=
Can Watermarking Large Language Models Prevent Copyrighted Text Generation and Hide Training Data? , author=. Proceedings of the AAAI Conference on Artificial Intelligence , year=
-
[32]
Advances in Neural Information Processing Systems (NeurIPS) , year =
WaterMax: Breaking the LLM Watermark Detectability-Robustness-Quality Trade-Off , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[33]
International Conference on Machine Learning (ICML) , year=
A Watermark for Large Language Models , author=. International Conference on Machine Learning (ICML) , year=
-
[34]
Who Wrote this Code? Watermarking for Code Generation
Lee, Taehyun and Hong, Seokhee and Ahn, Jaewoo and Hong, Ilgee and Lee, Hwaran and Yun, Sangdoo and Shin, Jamin and Kim, Gunhee. Who Wrote this Code? Watermarking for Code Generation. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL). 2024
2024
-
[35]
An Entropy-based Text Watermarking Detection Method
Lu, Yijian and Liu, Aiwei and Yu, Dianzhi and Li, Jingjing and King, Irwin. An Entropy-based Text Watermarking Detection Method. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL). 2024
2024
-
[36]
M orph M ark: Flexible Adaptive Watermarking for Large Language Models
Wang, Zongqi and Gu, Tianle and Wu, Baoyuan and Yang, Yujiu. M orph M ark: Flexible Adaptive Watermarking for Large Language Models. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL). 2025
2025
-
[37]
Park, Shinwoo and Park, Hyejin and Ahn, Hyeseon and Han, Yo-Sub , booktitle=
-
[38]
Transactions on Machine Learning Research , year=
Robust Distortion-free Watermarks for Language Models , author=. Transactions on Machine Learning Research , year=
-
[39]
Nature , year=
Scalable Watermarking for Identifying Large Language Model Outputs , author=. Nature , year=
-
[40]
W at ME : Towards Lossless Watermarking Through Lexical Redundancy
Chen, Liang and Bian, Yatao and Deng, Yang and Cai, Deng and Li, Shuaiyi and Zhao, Peilin and Wong, Kam-Fai. W at ME : Towards Lossless Watermarking Through Lexical Redundancy. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL). 2024
2024
-
[41]
1998 , publisher=
WordNet: An Electronic Lexical Database , author=. 1998 , publisher=
1998
-
[42]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year=
Context-aware Watermark with Semantic Balanced Green-red Lists for Large Language Models , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year=
2024
-
[43]
S em S tamp: A Semantic Watermark with Paraphrastic Robustness for Text Generation
Hou, Abe and Zhang, Jingyu and He, Tianxing and Wang, Yichen and Chuang, Yung-Sung and Wang, Hongwei and Shen, Lingfeng and Van Durme, Benjamin and Khashabi, Daniel and Tsvetkov, Yulia. S em S tamp: A Semantic Watermark with Paraphrastic Robustness for Text Generation. Proceedings of the 2024 Conference of the North American Chapter of the Association for...
2024
-
[44]
k- S em S tamp: A Clustering-Based Semantic Watermark for Detection of Machine-Generated Text
Hou, Abe and Zhang, Jingyu and Wang, Yichen and Khashabi, Daniel and He, Tianxing. k- S em S tamp: A Clustering-Based Semantic Watermark for Detection of Machine-Generated Text. Findings of the Association for Computational Linguistics (ACL). 2024
2024
-
[45]
Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering , pages=
CodeMark: Imperceptible Watermarking for Code Datasets against Neural Code Completion Models , author=. Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering , pages=
-
[46]
C ode IP : A Grammar-Guided Multi-Bit Watermark for Large Language Models of Code
Guan, Batu and Wan, Yao and Bi, Zhangqian and Wang, Zheng and Zhang, Hongyu and Zhou, Pan and Sun, Lichao. C ode IP : A Grammar-Guided Multi-Bit Watermark for Large Language Models of Code. Findings of the Association for Computational Linguistics (EMNLP). 2024
2024
-
[47]
Marking Code Without Breaking It: Code Watermarking for Detecting LLM -Generated Code
Kim, Jungin and Park, Shinwoo and Han, Yo-Sub. Marking Code Without Breaking It: Code Watermarking for Detecting LLM -Generated Code. Findings of the A ssociation for C omputational L inguistics (EACL). 2026
2026
-
[48]
Towards Codable Watermarking for Injecting Multi-Bits Information to
Lean Wang and Wenkai Yang and Deli Chen and Hao Zhou and Yankai Lin and Fandong Meng and Jie Zhou and Xu Sun , booktitle=. Towards Codable Watermarking for Injecting Multi-Bits Information to
-
[49]
Robust Multi-bit Natural Language Watermarking through Invariant Features
Yoo, KiYoon and Ahn, Wonhyuk and Jang, Jiho and Kwak, Nojun. Robust Multi-bit Natural Language Watermarking through Invariant Features. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL). 2023
2023
-
[50]
Advancing Beyond Identification: Multi-bit Watermark for Large Language Models
Yoo, KiYoon and Ahn, Wonhyuk and Kwak, Nojun. Advancing Beyond Identification: Multi-bit Watermark for Large Language Models. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL). 2024
2024
-
[51]
Where Am I From? Identifying Origin of LLM -generated Content
Li, Liying and Bai, Yihan and Cheng, Minhao. Where Am I From? Identifying Origin of LLM -generated Content. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2024
2024
-
[52]
arXiv preprint arXiv:2305.08883 , year=
Watermarking Text Generated by Black-Box Language Models , author=. arXiv preprint arXiv:2305.08883 , year=
-
[53]
arXiv preprint arXiv:2410.02099 , year=
A Watermark for Black-Box Language Models , author=. arXiv preprint arXiv:2410.02099 , year=
-
[54]
P ost M ark: A Robust Blackbox Watermark for Large Language Models
Chang, Yapei and Krishna, Kalpesh and Houmansadr, Amir and Wieting, John Frederick and Iyyer, Mohit. P ost M ark: A Robust Blackbox Watermark for Large Language Models. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2024
2024
-
[55]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Watermarking Makes Language Models Radioactive , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[56]
Can LLM Watermarks Robustly Prevent Unauthorized Knowledge Distillation?
Pan, Leyi and Liu, Aiwei and Huang, Shiyu and Lu, Yijian and Hu, Xuming and Wen, Lijie and King, Irwin and Yu, Philip S. Can LLM Watermarks Robustly Prevent Unauthorized Knowledge Distillation?. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL). 2025
2025
-
[57]
Can Watermarks Survive Translation? On the Cross-lingual Consistency of Text Watermark for Large Language Models
He, Zhiwei and Zhou, Binglin and Hao, Hongkun and Liu, Aiwei and Wang, Xing and Tu, Zhaopeng and Zhang, Zhuosheng and Wang, Rui. Can Watermarks Survive Translation? On the Cross-lingual Consistency of Text Watermark for Large Language Models. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024
2024
-
[58]
Qwen2.5 Technical Report , author=. arXiv preprint arXiv:2412.15115 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[59]
2024 , url=
Llama 3.2: Revolutionizing Edge AI and Vision with Open, Customizable Models , author=. 2024 , url=
2024
-
[60]
A Survey on Detection of LLM s-Generated Content
Yang, Xianjun and Pan, Liangming and Zhao, Xuandong and Chen, Haifeng and Petzold, Linda Ruth and Wang, William Yang and Cheng, Wei. A Survey on Detection of LLM s-Generated Content. Findings of the Association for Computational Linguistics (EMNLP). 2024
2024
-
[61]
Smaller Language Models are Better Zero-shot Machine-Generated Text Detectors
Mireshghallah, Niloofar and Mattern, Justus and Gao, Sicun and Shokri, Reza and Berg-Kirkpatrick, Taylor. Smaller Language Models are Better Zero-shot Machine-Generated Text Detectors. Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (EACL). 2024
2024
-
[62]
Beat LLMs at Their Own Game: Zero-Shot LLM -Generated Text Detection via Querying ChatGPT
Zhu, Biru and Yuan, Lifan and Cui, Ganqu and Chen, Yangyi and Fu, Chong and He, Bingxiang and Deng, Yangdong and Liu, Zhiyuan and Sun, Maosong and Gu, Ming. Beat LLMs at Their Own Game: Zero-Shot LLM -Generated Text Detection via Querying ChatGPT. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2023
2023
-
[63]
DetectLLM: Leveraging Log Rank Information for Zero-Shot Detection of Machine-Generated Text
Su, Jinyan and Zhuo, Terry and Wang, Di and Nakov, Preslav. DetectLLM: Leveraging Log Rank Information for Zero-Shot Detection of Machine-Generated Text. Findings of the Association for Computational Linguistics (EMNLP). 2023
2023
-
[64]
Mitchell, Eric and Lee, Yoonho and Khazatsky, Alexander and Manning, Christopher D and Finn, Chelsea , booktitle=
-
[65]
2020 , url=
Matthew Honnibal and Ines Montani and Sofie Van Landeghem and Adriane Boyd , title=. 2020 , url=
2020
-
[66]
The Stem Cell Hypothesis: Dilemma behind Multi-Task Learning with Transformer Encoders
He, Han and Choi, Jinho D. The Stem Cell Hypothesis: Dilemma behind Multi-Task Learning with Transformer Encoders. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2021
2021
-
[67]
K at F ish N et: Detecting LLM -Generated K orean Text through Linguistic Feature Analysis
Park, Shinwoo and Kim, Shubin and Kim, Do-Kyung and Han, Yo-Sub. K at F ish N et: Detecting LLM -Generated K orean Text through Linguistic Feature Analysis. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL). 2025
2025
-
[68]
Korean Journal of Digital Humanities , year=
Kiwi: Developing a Korean Morphological Analyzer Based on Statistical Language Models and Skip-Bigram , author=. Korean Journal of Digital Humanities , year=
-
[69]
and Cho, Sungzoon , booktitle=
Park, Eunjeong L. and Cho, Sungzoon , booktitle=
-
[70]
First Conference on Language Modeling (COLM) , year=
Does Incomplete Syntax Influence Korean Language Model? Focusing on Word Order and Case Markers , author=. First Conference on Language Modeling (COLM) , year=
-
[71]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL)
Yoon, Soyoung and Park, Sungjoon and Kim, Gyuwan and Cho, Junhee and Park, Kihyo and Kim, Gyu Tae and Seo, Minjoon and Oh, Alice. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL). 2023
2023
-
[72]
K orean Language Modeling via Syntactic Guide
Kim, Hyeondey and Kim, Seonhoon and Kang, Inho and Kwak, Nojun and Fung, Pascale. K orean Language Modeling via Syntactic Guide. Proceedings of the Thirteenth Language Resources and Evaluation Conference (LREC). 2022
2022
-
[73]
Optimizing Language Augmentation for Multilingual Large Language Models: A Case Study on K orean
Choi, ChangSu and Jeong, Yongbin and Park, Seoyoon and Won, Inho and Lim, HyeonSeok and Kim, SangMin and Kang, Yejee and Yoon, Chanhyuk and Park, Jaewan and Lee, Yiseul and Lee, HyeJin and Hahm, Younggyun and Kim, Hansaem and Lim, KyungTae. Optimizing Language Augmentation for Multilingual Large Language Models: A Case Study on K orean. Proceedings of the...
2024
-
[74]
Park, Kyubyong and Lee, Joohong and Jang, Seongbo and Jung, Dawoon. Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing (AACL). 2020
2020
-
[75]
B LEU: a Method for Automatic Evaluation of Machine Translation
Papineni, Kishore and Roukos, Salim and Ward, Todd and Zhu, Wei-Jing. B LEU: a Method for Automatic Evaluation of Machine Translation. Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. 2002
2002
-
[76]
ROUGE : A Package for Automatic Evaluation of Summaries
Lin, Chin-Yew. ROUGE : A Package for Automatic Evaluation of Summaries. Text Summarization Branches Out. 2004
2004
-
[77]
1989 , publisher=
Language Universals and Linguistic Typology: Syntax and Morphology , author=. 1989 , publisher=
1989
-
[78]
1981 , publisher=
Mandarin Chinese: A Functional Reference Grammar , author=. 1981 , publisher=
1981
-
[79]
2001 , publisher=
The Korean Language , author=. 2001 , publisher=
2001
-
[80]
Zhengmian Hu and Lichang Chen and Xidong Wu and Yihan Wu and Hongyang Zhang and Heng Huang , booktitle=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.