MOSAIC: Modular Orchestration for Structured Agentic Intelligence and Composition
Pith reviewed 2026-06-28 18:33 UTC · model grok-4.3
The pith
MOSAIC builds semantic task profiles and modular blueprints to ground LLM model selection in retrieved evidence and execution feedback.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
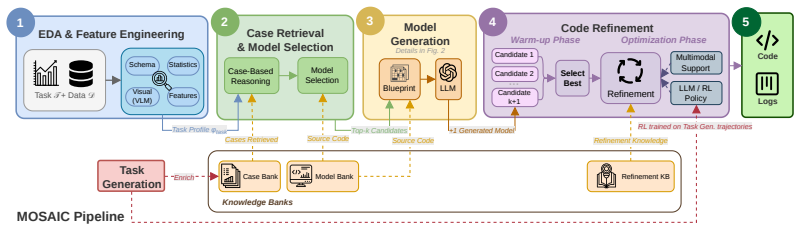
Given a task and dataset, MOSAIC builds a semantic task profile, retrieves prior cases and source-code modules, and constructs a blueprint specifying selected modelling components, composition, interface constraints, and execution requirements. Candidate models are generated from this blueprint, validated by execution, and refined using diagnostic feedback, training traces, task metrics, and a failure-aware reinforcement learning policy, producing improvements in task performance, execution success, and decision traceability on financial time-series tasks.
What carries the argument
The blueprint, an intermediate representation that specifies modelling components, composition, interface constraints, and execution requirements, which converts model selection into staged, context-grounded search.
If this is right
- Task performance, execution success, and decision traceability all increase relative to AutoML and unconstrained agentic baselines.
- Models better satisfy predictive accuracy, distributional fidelity, and downstream financial criteria such as risk and tail behaviour.
- Model selection becomes a reusable, staged process instead of one-off synthesis.
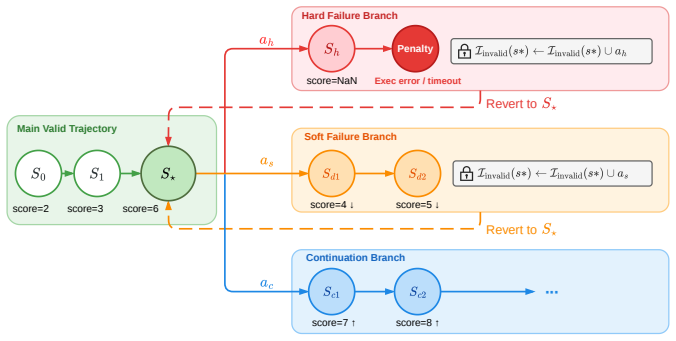
- Diagnostic feedback and failure-aware reinforcement learning enable iterative refinement grounded in execution traces.
Where Pith is reading between the lines
- The same profile-plus-blueprint pattern could be applied to other structured modeling domains such as computer vision pipelines or scientific simulation calibration.
- Over repeated tasks the growing library of retrieved modules could reduce the fraction of decisions that rely on fresh LLM synthesis.
- The failure-aware policy opens a path to agents that improve their own retrieval and blueprint construction rules across deployments.
Load-bearing premise
Building a semantic task profile and retrieving prior cases plus source-code modules will reliably ground LLM code generation and produce superior modeling decisions compared to unconstrained synthesis or standard search.
What would settle it
Run MOSAIC on a new financial dataset engineered so that retrieval returns no relevant prior cases or modules, then measure whether the performance and success-rate advantages over baselines disappear.
Figures



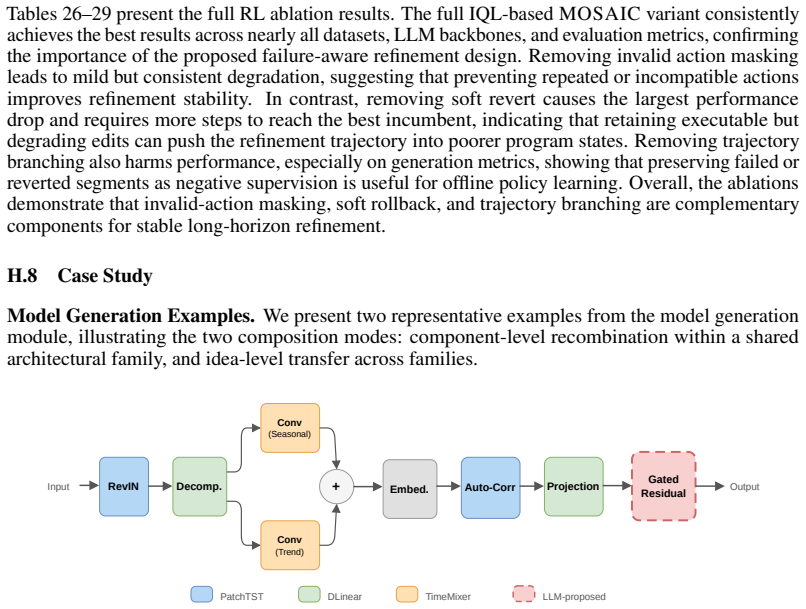
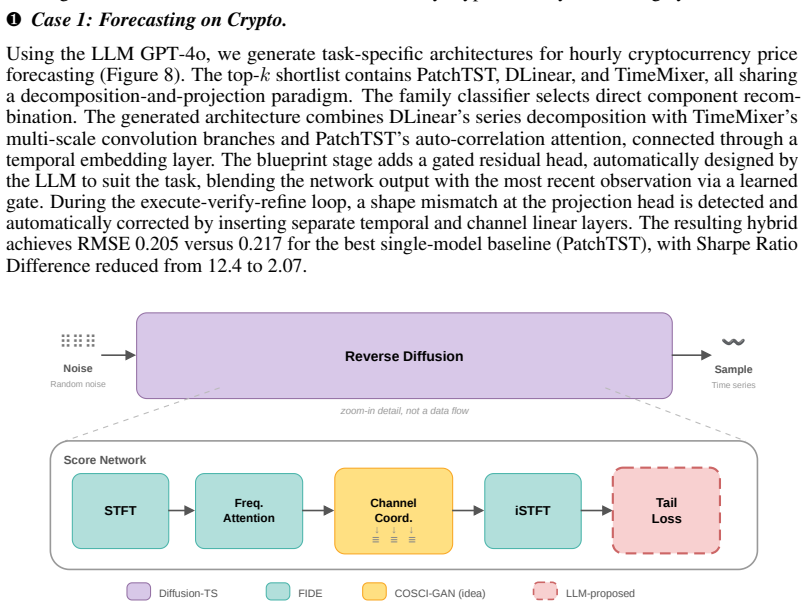
read the original abstract
Automated data science is a structured model-selection problem. A solution must choose data transformations, feature representations, architecture, training procedure, evaluation protocol, and refinement strategy for a task. AutoML systems automate parts of this process, but typically search within predefined pipeline, model, and hyperparameter spaces. LLM-based agents offer greater flexibility through retrieval, code generation, and execution feedback, yet their modelling decisions are often unstructured, difficult to verify, and hard to reuse. We introduce \textsc{MOSAIC} (Modular Orchestration for Structured Agentic Intelligence and Composition), a structured agentic framework for memory-grounded model selection and workflow construction. Given a task and dataset, \textsc{MOSAIC} builds a semantic task profile, retrieves prior cases and source-code modules, and constructs a blueprint: an intermediate representation specifying selected modelling components, composition, interface constraints, and execution requirements. This blueprint turns model selection into a staged, context-grounded search and grounds LLM-based code generation in retrieved evidence rather than unconstrained synthesis. Candidate models are validated by execution and refined using diagnostic feedback, training traces, task metrics, and a failure-aware reinforcement learning policy. We instantiate \textsc{MOSAIC} on financial time-series forecasting and generation, where models must satisfy predictive accuracy, distributional fidelity, execution reliability, and downstream financial criteria such as risk and tail behaviour. Experiments against AutoML and agentic baselines show that \textsc{MOSAIC} improves task performance, execution success, and decision traceability, demonstrating the value of treating automated data science as structured, reusable, and execution-grounded model selection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MOSAIC, a modular agentic framework for automated data science that constructs semantic task profiles, retrieves prior cases and code modules to build an intermediate blueprint representation of modeling components and constraints, grounds LLM code generation in retrieved evidence, and refines candidates via execution feedback and a failure-aware RL policy. It focuses on financial time-series forecasting and generation tasks and claims experimental improvements in task performance, execution success, and decision traceability over AutoML and agentic baselines.
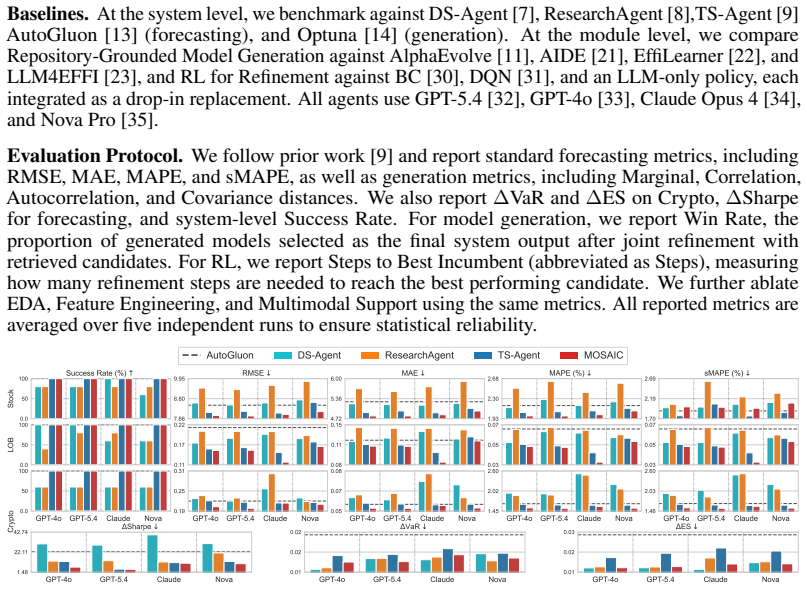
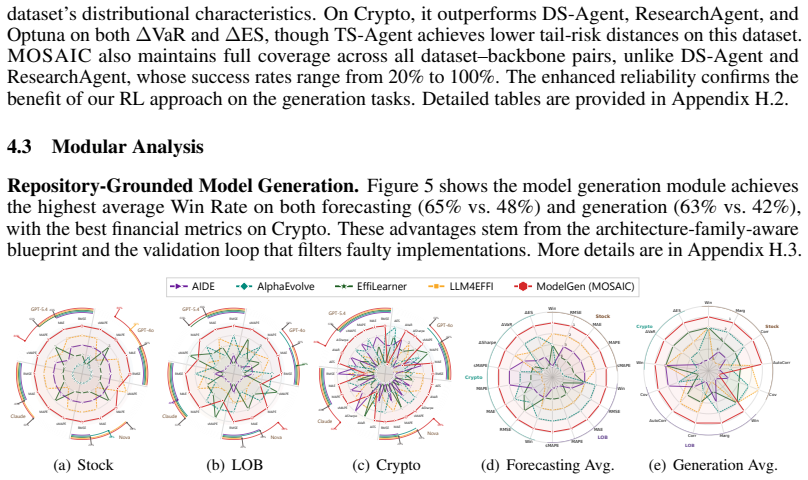
Significance. If the experimental claims hold with proper controls and metrics, the work could advance LLM-based automated data science by shifting from unstructured synthesis to structured, memory-grounded, and execution-verified model selection, potentially improving reusability and verifiability in agentic workflows.
major comments (2)
- [Abstract] Abstract: the central claim that 'Experiments against AutoML and agentic baselines show that MOSAIC improves task performance, execution success, and decision traceability' is unsupported because the abstract (and the query-supplied text) supplies no quantitative results, error bars, baseline details, dataset descriptions, or exclusion criteria, making it impossible to determine whether the data support the claim.
- [Abstract] Abstract: the description of blueprint construction, retrieval mechanism, and failure-aware reinforcement learning policy remains at a high level without specifying algorithms, similarity metrics, or how the staged search avoids the weaknesses of unconstrained synthesis, which is load-bearing for the claim that this grounds LLM decisions more reliably.
Simulated Author's Rebuttal
We thank the referee for their detailed comments on the abstract. We agree that abstracts must balance conciseness with sufficient support for claims and address each point below, proposing targeted revisions to the abstract where helpful while preserving its high-level nature.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'Experiments against AutoML and agentic baselines show that MOSAIC improves task performance, execution success, and decision traceability' is unsupported because the abstract (and the query-supplied text) supplies no quantitative results, error bars, baseline details, dataset descriptions, or exclusion criteria, making it impossible to determine whether the data support the claim.
Authors: Abstracts conventionally summarize contributions without full quantitative detail to remain readable; the supporting results (including metrics, baselines, datasets, and statistical details) appear in Sections 4–5. To address the concern directly, we will revise the abstract to incorporate 1–2 key quantitative highlights (e.g., relative gains in forecasting accuracy and execution success) drawn from the experimental tables, while staying within length limits. revision: yes
-
Referee: [Abstract] Abstract: the description of blueprint construction, retrieval mechanism, and failure-aware reinforcement learning policy remains at a high level without specifying algorithms, similarity metrics, or how the staged search avoids the weaknesses of unconstrained synthesis, which is load-bearing for the claim that this grounds LLM decisions more reliably.
Authors: The abstract is deliberately high-level; the concrete mechanisms—semantic task profiling, embedding-based retrieval, blueprint schema, staged search constraints, and the failure-aware RL update rule—are specified in Section 3, with pseudocode and similarity metrics. The abstract’s role is to outline the overall approach rather than replicate algorithmic detail. We can add a brief clause to the abstract emphasizing that the blueprint “grounds generation in retrieved modules and constraints” if the referee finds this improves clarity. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper is a system-description manuscript introducing the MOSAIC framework for structured agentic model selection. The abstract and supplied text contain no equations, no fitted parameters presented as predictions, no self-referential derivations, and no load-bearing self-citations that reduce the central claims to their own inputs by construction. Claims rest on the empirical comparison to AutoML and agentic baselines rather than on any mathematical chain that collapses into a tautology or renamed input. The derivation chain is therefore self-contained as an engineering proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Domingos
Pedro M. Domingos. A few useful things to know about machine learning.Commun. ACM, pages 78–87, 2012
2012
-
[2]
Auto-sklearn 2.0: Hands-free automl via meta-learning.JMLR, pages 1–61, 2022
Matthias Feurer, Katharina Eggensperger, Stefan Falkner, Marius Lindauer, and Frank Hutter. Auto-sklearn 2.0: Hands-free automl via meta-learning.JMLR, pages 1–61, 2022
2022
-
[3]
Auto-weka: Combined selection and hyperparameter optimization of classification algorithms
Chris Thornton, Frank Hutter, Holger H Hoos, and Kevin Leyton-Brown. Auto-weka: Combined selection and hyperparameter optimization of classification algorithms. InKDD, pages 847–855, 2013
2013
-
[4]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InICLR, 2023
2023
-
[5]
V oyager: An open-ended embodied agent with large language models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models. Trans. Mach. Learn. Res., 2024
2024
-
[6]
Weijie Lv, Xuan Xia, and Sheng-Jun Huang. Codeact: Code adaptive compute-efficient tuning framework for code llms.arXiv preprint arXiv:2408.02193, 2024
-
[7]
Ds-agent: Automated data science by empowering large language models with case-based reasoning
Siyuan Guo, Cheng Deng, Ying Wen, Hechang Chen, Yi Chang, and Jun Wang. Ds-agent: Automated data science by empowering large language models with case-based reasoning. In ICML, pages 16813–16848, 2024
2024
-
[8]
Researchagent: Iterative research idea generation over scientific literature with large language models
Jinheon Baek, Sujay Kumar Jauhar, Silviu Cucerzan, and Sung Ju Hwang. Researchagent: Iterative research idea generation over scientific literature with large language models. In NAACL, pages 6709–6738, 2025
2025
-
[9]
Yihao Ang, Yifan Bao, Lei Jiang, Jiajie Tao, Anthony K. H. Tung, Lukasz Szpruch, and Hao Ni. Structured agentic workflows for financial time-series modeling with llms and reflective feedback. InICAIF, 2025
2025
-
[10]
Reflexion: Language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. InNeurIPS, pages 8634–8652, 2023
2023
-
[11]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Alexander Novikov, Ngân V˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco JR Ruiz, Abbas Mehrabian, M. Pawan Kumar, Abigail See, Swarat Chaudhuri, George Holland, Alex Davies, Sebas- tian Nowozin, Pushmeet Kohli, and Matej Balog. Alphaevolve: A coding agent for scientific and algori...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Kevin Ellis, Lionel Wong, Maxwell Nye, Mathias Sable-Meyer, Luc Cary, Lore Anaya Pozo, Luke Hewitt, Armando Solar-Lezama, and Joshua B Tenenbaum. Dreamcoder: growing gener- alizable, interpretable knowledge with wake–sleep bayesian program learning.Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, 2023
2023
-
[13]
Autogluon-timeseries: Automl for probabilistic time series forecasting
Oleksandr Shchur, Ali Caner Turkmen, Nick Erickson, Huibin Shen, Alexander Shirkov, Tony Hu, and Bernie Wang. Autogluon-timeseries: Automl for probabilistic time series forecasting. InICLR, pages 9–1, 2023
2023
-
[14]
Optuna: A next-generation hyperparameter optimization framework
Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, and Masanori Koyama. Optuna: A next-generation hyperparameter optimization framework. InKDD, pages 2623–2631, 2019
2019
-
[15]
Neural architecture search with reinforcement learning
Barret Zoph and Quoc V Le. Neural architecture search with reinforcement learning. InICLR, 2017
2017
-
[16]
Neural architecture search: A survey
Thomas Elsken, Jan Hendrik Metzen, and Frank Hutter. Neural architecture search: A survey. Journal of Machine Learning Research, pages 1–21, 2019
2019
-
[17]
Darts: Differentiable architecture search
Hanxiao Liu, Karen Simonyan, and Yiming Yang. Darts: Differentiable architecture search. In ICLR, 2018
2018
-
[18]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The ai scien- tist: Towards fully automated open-ended scientific discovery.arXiv preprint arXiv:2408.06292, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Agent laboratory: Using llm agents as research assistants
Samuel Schmidgall, Yusheng Su, Ze Wang, Ximeng Sun, Jialian Wu, Xiaodong Yu, Jiang Liu, Michael Moor, Zicheng Liu, and Emad Barsoum. Agent laboratory: Using llm agents as research assistants. InEMNLP, pages 5977–6043, 2025
2025
-
[20]
Michelle Yuan, Khushbu Pahwa, Shuaichen Chang, Mustafa Kaba, Jiarong Jiang, Xiaofei Ma, Yi Zhang, and Monica Sunkara. Automated composition of agents: A knapsack approach for agentic component selection.arXiv preprint arXiv:2510.16499, 2025
-
[21]
AIDE: AI-Driven Exploration in the Space of Code
Zhengyao Jiang, Dominik Schmidt, Dhruv Srikanth, Dixing Xu, Ian Kaplan, Deniss Ja- cenko, and Yuxiang Wu. Aide: Ai-driven exploration in the space of code.arXiv preprint arXiv:2502.13138, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Effilearner: Enhancing efficiency of generated code via self-optimization
Dong Huang, Jianbo Dai, Han Weng, Puzhen Wu, Yuhao Qing, Heming Cui, Zhijiang Guo, and Jie Zhang. Effilearner: Enhancing efficiency of generated code via self-optimization. In NeurIPS, 2024
2024
-
[23]
LLM4EFFI: leveraging large language models to enhance code efficiency and correctness
Tong Ye, Weigang Huang, Xuhong Zhang, Tengfei Ma, Peiyu Liu, Jianwei Yin, and Wenhai Wang. LLM4EFFI: leveraging large language models to enhance code efficiency and correctness. arXiv preprint arXiv:2502.18489, 2025
-
[24]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human fee...
2022
-
[25]
Eureka: Human-level reward design via coding large language model
Yecheng Jason Ma, William Liang, Guanzhi Wang, De-An Huang, Osbert Bastani, Dinesh Jayaraman, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Eureka: Human-level reward design via coding large language model. InICLR, 2024
2024
-
[26]
Offline reinforcement learning with implicit q-learning.ICLR, 2022
Ilya Kostrikov, Ashvin Nair, and Sergey Levine. Offline reinforcement learning with implicit q-learning.ICLR, 2022
2022
-
[27]
A closer look at invalid action masking in policy gradient algorithms
Shengyi Huang and Santiago Ontañón. A closer look at invalid action masking in policy gradient algorithms. InFLAIRS, 2022
2022
-
[28]
Safe reinforcement learning via shielding
Mohammed Alshiekh, Roderick Bloem, Rüdiger Ehlers, Bettina Könighofer, Scott Niekum, and Ufuk Topcu. Safe reinforcement learning via shielding. InAAAI, pages 2669–2678, 2018
2018
-
[29]
Ctbench: Cryptocurrency time series generation benchmark
Yihao Ang, Qiang Wang, Qiang Huang, Yifan Bao, Xinyu Xi, Anthony KH Tung, Chen Jin, and Zhiyong Huang. Ctbench: Cryptocurrency time series generation benchmark. InICLR, 2026. 11
2026
-
[30]
Alvinn: An autonomous land vehicle in a neural network
Dean A Pomerleau. Alvinn: An autonomous land vehicle in a neural network. InNeurIPS, 1988
1988
-
[31]
Rusu, Joel Veness, Marc G
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin A. Riedmiller, Andreas Fidjeland, Georg Ostrovski, Stig Pe- tersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan Wierstra, Shane Legg, and Demis Hassabis. Human-level control through deep reinforcemen...
2015
-
[32]
OpenAI. Gpt-5 system card.https://arxiv.org/abs/2601.03267, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
OpenAI. Gpt-4 technical report.https://arxiv.org/abs/2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
System card: Claude opus 4 & claude sonnet 4
Anthropic. System card: Claude opus 4 & claude sonnet 4. https://www.anthropic.com/, 2025
2025
-
[35]
The amazon nova family of models: Technical report and model card.https://assets.amazon.science/, 2025
Amazon Artificial General Intelligence. The amazon nova family of models: Technical report and model card.https://assets.amazon.science/, 2025
2025
-
[36]
Sig-wasserstein gans for time series generation
Hao Ni, Lukasz Szpruch, Marc Sabate-Vidales, Baoren Xiao, Magnus Wiese, and Shujian Liao. Sig-wasserstein gans for time series generation. InICAIF, pages 1–8, 2021
2021
-
[37]
Pcf-gan: generating sequential data via the characteristic function of measures on the path space
Hang Lou, Siran Li, and Hao Ni. Pcf-gan: generating sequential data via the characteristic function of measures on the path space. InNeurIPS, pages 39755–39781, 2023
2023
-
[38]
Regime-switching Financial Time-Series Generation
Hao Ni, Lukasz Szpruch, and Jiajie Tao. Regime-switching Financial Time-Series Generation. https://github.com/tjj0502/hackathon_starting_kit, 2023. ICAIF 2023 Hackathon
2023
-
[39]
Crypto Market Simulation for Risk Es- timation
Hao Ni, Lukasz Szpruch, Jiajie Tao, and Yang Long. Crypto Market Simulation for Risk Es- timation. https://hackathon.deepintomlf.ai/competitions/40, 2024. Antalpha ICAIF 2024 Hackathon
2024
-
[40]
Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting
Haixu Wu, Jiehui Xu, Jianmin Wang, and Mingsheng Long. Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting. InNeurIPS, pages 22419– 22430, 2021
2021
-
[41]
A time series is worth 64 words: Long-term forecasting with transformers
Yuqi Nie, Nam H Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam. A time series is worth 64 words: Long-term forecasting with transformers. InICLR, 2023
2023
-
[42]
Timesnet: Temporal 2d-variation modeling for general time series analysis
Haixu Wu, Tengge Hu, Yong Liu, Hang Zhou, Jianmin Wang, and Mingsheng Long. Timesnet: Temporal 2d-variation modeling for general time series analysis. InICLR, 2023
2023
-
[43]
Are transformers effective for time series forecasting? InAAAI, pages 11121–11128, 2023
Ailing Zeng, Muxi Chen, Lei Zhang, and Qiang Xu. Are transformers effective for time series forecasting? InAAAI, pages 11121–11128, 2023
2023
-
[44]
Timemixer: Decomposable multiscale mixing for time series forecasting
Shiyu Wang, Haixu Wu, Xiaoming Shi, Tengge Hu, Huakun Luo, Lintao Ma, James Y Zhang, and Jun Zhou. Timemixer: Decomposable multiscale mixing for time series forecasting. In ICLR, 2024
2024
-
[45]
Time-series generative adversarial networks
Jinsung Yoon, Daniel Jarrett, and Mihaela Van der Schaar. Time-series generative adversarial networks. InNeurIPS, pages 5509–5519, 2019
2019
-
[46]
Real-valued (Medical) Time Series Generation with Recurrent Conditional GANs
Cristóbal Esteban, Stephanie L Hyland, and Gunnar Rätsch. Real-valued (medical) time series generation with recurrent conditional gans.arXiv preprint arXiv:1706.02633, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[47]
Quant gans: deep genera- tion of financial time series.Quantitative Finance, pages 1419–1440, 2020
Magnus Wiese, Robert Knobloch, Ralf Korn, and Peter Kretschmer. Quant gans: deep genera- tion of financial time series.Quantitative Finance, pages 1419–1440, 2020
2020
-
[48]
Generating multivariate time series with common source coordinated gan (cosci-gan)
Ali Seyfi, Jean-Francois Rajotte, and Raymond Ng. Generating multivariate time series with common source coordinated gan (cosci-gan). InNeurIPS, pages 32777–32788, 2022
2022
-
[49]
Abhyuday Desai, Cynthia Freeman, Zuhui Wang, and Ian Beaver. Timevae: A variational auto-encoder for multivariate time series generation.arXiv preprint arXiv:2111.08095, 2021
-
[50]
Diffusion-ts: Interpretable diffusion for general time series generation
Xinyu Yuan and Yan Qiao. Diffusion-ts: Interpretable diffusion for general time series genera- tion.arXiv preprint arXiv:2403.01742, 2024. 12
-
[51]
Haixin Wang, Jiashu Pan, Hao Wu, Fan Zhang, and Tailin Wu. Fourierflow: Frequency-aware flow matching for generative turbulence modeling.arXiv preprint arXiv:2506.00862, 2025
-
[52]
Deep latent state space models for time-series generation
Linqi Zhou, Michael Poli, Winnie Xu, Stefano Massaroli, and Stefano Ermon. Deep latent state space models for time-series generation. InICML, pages 42625–42643, 2023
2023
-
[53]
Fide: Frequency-inflated conditional diffusion model for extreme-aware time series generation
Asadullah Hill Galib, Pang-Ning Tan, and Lifeng Luo. Fide: Frequency-inflated conditional diffusion model for extreme-aware time series generation. InNeurIPS, pages 114434–114457, 2024
2024
-
[54]
Testing for unit roots in autoregressive-moving average models of unknown order.Biometrika, pages 599–607, 1984
Said E Said and David A Dickey. Testing for unit roots in autoregressive-moving average models of unknown order.Biometrika, pages 599–607, 1984. 13 A Task Generation Details We employ an automated task-generation module to construct diverse, executable time-series fore- casting and generation tasks, forming a scalable corpus of tasks that can be converted...
1984
-
[55]
and PatchTST [41](Transformer-based), TimesNet [42](temporal CNN), DLinear [43](linear), and TimeMixer [44](token-mixing). For generation, it includes ten models: TimeGAN [45], RCGAN [46], PCFGAN [37], QuantGAN [47], COSCIGAN [48] (GAN-based), TimeV AE [49] (V AE-based), DiffusionTS [50] (diffusion-based), FourierFlow [51] (flow-based), and LS4 [52], FIDE...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.