I-WebGenBench : Evaluating Interactivity in LLM-Generated Scientific Web Applications
Pith reviewed 2026-06-28 18:50 UTC · model grok-4.3
The pith
PaperVoyager agent converts research papers into executable interactive web systems by explicitly modeling mechanisms and interaction logic.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that an end-to-end Paper-to-Interactive-System Agent can transform a research paper PDF into an executable interactive webpage without human intervention, and that the PaperVoyager framework, which explicitly models mechanisms and interaction logic during synthesis, produces higher-quality outputs than unstructured generation methods when evaluated against expert-built ground-truth systems on a benchmark of 19 papers.
What carries the argument
The Paper-to-Interactive-System Agent performing paper understanding, system modeling, and interactive webpage synthesis in sequence, with PaperVoyager as the structured framework that enforces explicit modeling of mechanisms and interaction logic.
If this is right
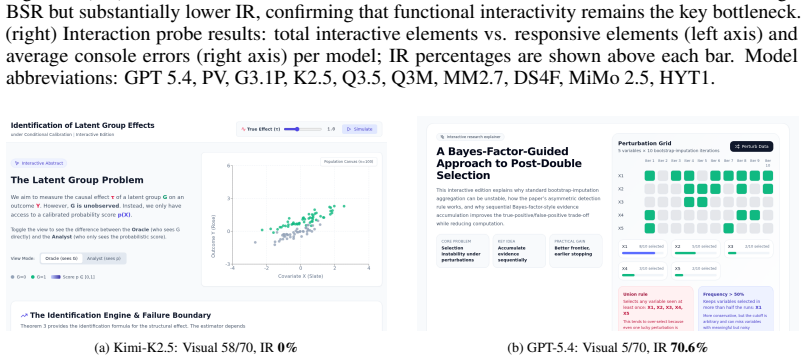
- Users gain the ability to manipulate inputs in the generated systems and observe corresponding dynamic behaviors and state transitions.
- Explicit modeling of mechanisms and interaction logic during generation leads to higher quality interactive systems than direct generation approaches.
- The method supplies a new paradigm in which scientific papers are understood through direct interaction rather than static summaries or documents.
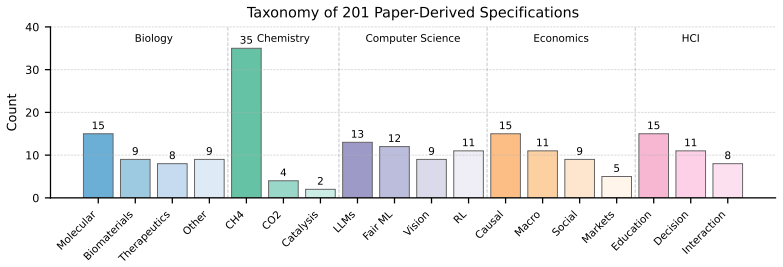
- The 19-paper benchmark enables systematic measurement of an agent's capacity to capture dynamic aspects of technical content.
Where Pith is reading between the lines
- The same structured modeling steps could be tested on technical documents outside scientific papers, such as engineering manuals or regulatory texts.
- Adding user studies that measure actual comprehension gains from interacting with the generated systems would test whether the quality improvements translate to better understanding.
- Expanding the benchmark with additional papers and expert systems could reveal whether the observed gains hold across a wider range of technical domains.
Load-bearing premise
The 19 expert-built interactive systems paired with the papers form a reliable ground truth that correctly captures the dynamic mechanisms and state transitions described in each paper.
What would settle it
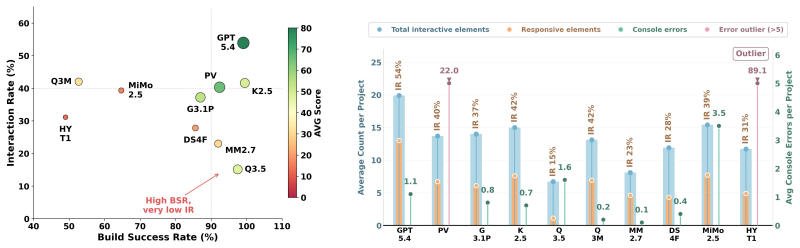
Independent experts rating PaperVoyager-generated systems as equivalent or inferior to baseline-generated systems on measures of functional correctness and fidelity to the original paper's described behaviors.
Figures








read the original abstract
Recent advances in visual language models have enabled autonomous agents for complex reasoning, tool use, and document understanding. However, existing document agents mainly transform papers into static artifacts such as summaries, webpages, or slides, which are insufficient for technical papers involving dynamic mechanisms and state transitions. In this work, we propose a Paper-to-Interactive-System Agent that converts research papers into executable interactive web systems. Given a PDF paper, the agent performs end-to-end processing without human intervention, including paper understanding, system modeling, and interactive webpage synthesis, enabling users to manipulate inputs and observe dynamic behaviors. To evaluate this task, we introduce a benchmark of 19 research papers paired with expert-built interactive systems as ground truth. We further propose PaperVoyager, a structured generation framework that explicitly models mechanisms and interaction logic during synthesis. Experiments show that PaperVoyager significantly improves the quality of generated interactive systems, offering a new paradigm for interactive scientific paper understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces I-WebGenBench, a benchmark of 19 research papers paired with expert-built interactive web systems as ground truth, and proposes PaperVoyager, a structured agent framework for end-to-end conversion of PDF papers into executable interactive web applications that model mechanisms and state transitions. It claims that PaperVoyager significantly outperforms prior approaches in generating high-quality interactive systems for dynamic scientific content.
Significance. If the evaluation holds, the work could establish a new paradigm for interactive scientific document understanding by moving beyond static summaries to manipulable web systems that capture dynamic behaviors, with potential applications in education and research dissemination.
major comments (2)
- [Benchmark section] Benchmark section (likely §4 or equivalent): The 19 expert-built interactive systems are presented as ground truth without any described construction protocol, expert selection criteria, inter-rater reliability metrics, coverage of state-transition types, or verification that the systems faithfully reproduce the original papers' dynamic mechanisms; this directly undermines the headline claim of significant quality improvements from PaperVoyager since all comparisons rest on this unvalidated reference.
- [Experiments section] Experiments section (likely §5): The abstract asserts 'significant improvement' from PaperVoyager but the provided text supplies no quantitative metrics, baselines, statistical tests, error analysis, or ablation results; without these, the central experimental claim cannot be evaluated for soundness or effect size.
minor comments (2)
- The title refers to I-WebGenBench while the abstract emphasizes PaperVoyager; clarify the relationship and ensure consistent naming throughout.
- Notation for system components (e.g., modeling of interaction logic) should be defined more explicitly if equations or pseudocode are present in later sections.
Simulated Author's Rebuttal
We thank the referee for these targeted comments on the benchmark and experimental evaluation. We agree that both sections require substantial expansion to make the claims fully evaluable, and we will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Benchmark section] Benchmark section (likely §4 or equivalent): The 19 expert-built interactive systems are presented as ground truth without any described construction protocol, expert selection criteria, inter-rater reliability metrics, coverage of state-transition types, or verification that the systems faithfully reproduce the original papers' dynamic mechanisms; this directly undermines the headline claim of significant quality improvements from PaperVoyager since all comparisons rest on this unvalidated reference.
Authors: We agree the current manuscript lacks sufficient detail on ground-truth construction. In the revision we will expand Section 4 with: (i) expert selection criteria (domain researchers with publication records in the target subfield), (ii) a step-by-step construction protocol, (iii) inter-rater reliability scores (Cohen’s kappa on a 20 % overlap subset), (iv) explicit coverage statistics across state-transition categories, and (v) a verification checklist confirming fidelity to each paper’s described mechanisms. These additions will be placed before the main results. revision: yes
-
Referee: [Experiments section] Experiments section (likely §5): The abstract asserts 'significant improvement' from PaperVoyager but the provided text supplies no quantitative metrics, baselines, statistical tests, error analysis, or ablation results; without these, the central experimental claim cannot be evaluated for soundness or effect size.
Authors: We acknowledge that the version seen by the referee does not contain the full quantitative results. Section 5 will be expanded to report: concrete metrics (mechanism fidelity, interactivity score, execution success rate), three baselines (direct LLM prompting, ReAct-style agent, and a non-structured variant), paired statistical tests (Wilcoxon signed-rank with effect sizes), error analysis broken down by failure mode, and ablation results isolating the mechanism-modeling and interaction-logic modules. All numbers and significance statements will be added. revision: yes
Circularity Check
No circularity; evaluation uses externally constructed expert benchmark
full rationale
The paper introduces a benchmark consisting of 19 research papers paired with expert-built interactive systems as ground truth and evaluates the PaperVoyager framework against it. No equations, fitted parameters, self-citations, or ansatzes appear in the provided text. The quality improvement claim is measured against this externally described expert construction rather than reducing by definition or construction to the agent's own outputs or prior self-references. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ai pair programming in your terminal, 2024
Aider-AI. Ai pair programming in your terminal, 2024. URL https://github.com/Aider-AI/aider. Accessed: 2025-04-22
2024
-
[2]
SWE-Bench+: Enhanced Coding Benchmark for LLMs.arXiv preprint arXiv:2410.06992, 2024
Reem Aleithan, Haoran Xue, Mohammad Mahdi Mohajer, Elijah Nnorom, Gias Uddin, and Song Wang. Swe-bench+: Enhanced coding benchmark for llms.arXiv preprint arXiv:2410.06992, 2024
-
[3]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
Webvr: an interactive web browser for virtual environments
Emad Barsoum and Falko Kuester. Webvr: an interactive web browser for virtual environments. In Stereoscopic Displays and Virtual Reality Systems XII, volume 5664, pages 540–547. Spie, 2005
2005
-
[5]
pix2code: Generating Code from a Graphical User Interface Screenshot
Tony Beltramelli. pix2code: Generating code from a graphical user interface screenshot, 2017. URL https://arxiv.org/abs/1705.07962
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[6]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Webvln: Vision-and-language navigation on websites, 2023
Qi Chen, Dileepa Pitawela, Chongyang Zhao, Gengze Zhou, Hsiang-Ting Chen, and Qi Wu. Webvln: Vision-and-language navigation on websites, 2023
2023
-
[8]
Yang Chen, Minghao Liu, Yufan Shen, Yunwen Li, Tianyuan Huang, Xinyu Fang, Tianyu Zheng, Wenxuan Huang, Cheng Yang, Daocheng Fu, et al. Iwr-bench: Can lvlms reconstruct interactive webpage from a user interaction video?arXiv preprint arXiv:2509.24709, 2025
-
[9]
Paper2web: Let’s make your paper alive!arXiv preprint arXiv:2510.15842, 2025
Yuhang Chen, Tianpeng Lv, Siyi Zhang, Yixiang Yin, Yao Wan, Philip S Yu, and Dongping Chen. Paper2web: Let’s make your paper alive!arXiv preprint arXiv:2510.15842, 2025
-
[10]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with ad- vanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Github copilot, 2024
GitHub Copilot. Github copilot, 2024. URL https://github.com/features/copilot. Accessed: 2025-04-22
2024
-
[12]
Cursor: The ai code editor, 2024
Cursor. Cursor: The ai code editor, 2024. URLhttps://www.cursor.com/. Accessed: 2025-04-22
2024
-
[13]
PaperVoyager : Building Interactive Web with Visual Language Models
Dasen Dai, Biao Wu, Meng Fang, and Wenhao Wang. Papervoyager: Building interactive web with visual language models.arXiv preprint arXiv:2603.22999, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
Agentic Reinforced Policy Optimization
Guanting Dong, Hangyu Mao, Kai Ma, Licheng Bao, Yifei Chen, Zhongyuan Wang, Zhongxia Chen, Jiazhen Du, Huiyang Wang, Fuzheng Zhang, Guorui Zhou, Yutao Zhu, Ji-Rong Wen, and Zhicheng Dou. Agentic reinforced policy optimization, 2025. URLhttps://arxiv.org/abs/2507.19849
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Iw-bench: Evaluating large multimodal models for converting image-to-web, 2024
Hongcheng Guo, Wei Zhang, Junhao Chen, Yaonan Gu, Jian Yang, Junjia Du, Binyuan Hui, Tianyu Liu, Jianxin Ma, Chang Zhou, and Zhoujun Li. Iw-bench: Evaluating large multimodal models for converting image-to-web, 2024. URLhttps://arxiv.org/abs/2409.18980
-
[17]
Measuring Coding Challenge Competence With APPS
Dan Hendrycks, Steven Basart, Saurav Kadavath, Mantas Mazeika, Akul Arora, Ethan Guo, Collin Burns, Samir Puranik, Horace He, Dawn Song, et al. Measuring coding challenge competence with apps.arXiv preprint arXiv:2105.09938, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[18]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar- Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code.arXiv preprint arXiv:2403.07974, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Webgen-r1: Incentivizing llms to generate functional and aesthetic websites with reinforcement learning
Juyong Jiang, Chansung Park, Jiasi Shen, Sunghun Kim, Jianguo Li, Yue Wang, et al. Webgen-r1: Incentivizing llms to generate functional and aesthetic websites with reinforcement learning
-
[20]
Webgen-r1: Incentivizing llms to generate functional and aesthetic websites with reinforcement learning
Juyong Jiang, Chansung Park, Jiasi Shen, Sunghun Kim, Jianguo Li, Yue Wang, et al. Webgen-r1: Incentivizing llms to generate functional and aesthetic websites with reinforcement learning. 2026. 10
2026
-
[21]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
WebCompass: Towards Multimodal Web Coding Evaluation for Code Language Models
Xinping Lei, Xinyu Che, Junqi Xiong, Chenchen Zhang, Yukai Huang, Chenyu Zhou, Haoyang Huang, Minghao Liu, Letian Zhu, Hongyi Ye, et al. Webcompass: Towards multimodal web coding evaluation for code language models.arXiv preprint arXiv:2604.18224, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
MiniMax-01: Scaling Foundation Models with Lightning Attention
Aonian Li, Bangwei Gong, Bo Yang, Boji Shan, Chang Liu, Cheng Zhu, Chunhao Zhang, Congchao Guo, Da Chen, Dong Li, et al. Minimax-01: Scaling foundation models with lightning attention.arXiv preprint arXiv:2501.08313, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Chenxu Liu, Yingjie Fu, Wei Yang, Ying Zhang, and Tao Xie. Webcoderbench: Benchmarking web applica- tion generation with comprehensive and interpretable evaluation metrics.arXiv preprint arXiv:2601.02430, 2026
-
[25]
RepoBench: Benchmarking Repository-Level Code Auto-Completion Systems
Tianyang Liu, Canwen Xu, and Julian McAuley. Repobench: Benchmarking repository-level code auto-completion systems.arXiv preprint arXiv:2306.03091, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Uxagent: An llm agent-based usability testing framework for web design
Yuxuan Lu, Bingsheng Yao, Hansu Gu, Jing Huang, Jessie Wang, Laurence Li, Jiri Gesi, Qi He, Toby Jia-Jun Li, and Dakuo Wang. Uxagent: An llm agent-based usability testing framework for web design. arXiv preprint arXiv:2502.12561, 2025
-
[27]
WebGen-Bench: Evaluating LLMs on generating interactive and functional websites from scratch, 2025
Zimu Lu, Yunqiao Yang, Houxing Ren, Haotian Hou, Han Xiao, Ke Wang, Weikang Shi, Aojun Zhou, Mingjie Zhan, and Hongsheng Li. Webgen-bench: Evaluating llms on generating interactive and functional websites from scratch.arXiv preprint arXiv:2505.03733, 2025
-
[28]
Samuel Miserendino, Michele Wang, Tejal Patwardhan, and Johannes Heidecke. Swe-lancer: Can frontier llms earn $1 million from real-world freelance software engineering?arXiv preprint arXiv:2502.12115, 2025
-
[29]
Octopack: Instruction tuning code large language models
Niklas Muennighoff, Qian Liu, Armel Zebaze, Qinkai Zheng, Binyuan Hui, Terry Yue Zhuo, Swayam Singh, Xiangru Tang, Leandro V on Werra, and Shayne Longpre. Octopack: Instruction tuning code large language models. InNeurIPS 2023 Workshop on Instruction Tuning and Instruction Following, 2023
2023
-
[30]
Presentagent: Multimodal agent for presentation video generation
Jingwei Shi, Zeyu Zhang, Biao Wu, Yanjie Liang, Meng Fang, Ling Chen, and Yang Zhao. Presentagent: Multimodal agent for presentation video generation. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 760–773, 2025
2025
-
[31]
De- sign2Code: Benchmarking multimodal code generation for automated front-end engineering
Chenglei Si, Yanzhe Zhang, Ryan Li, Zhengyuan Yang, Ruibo Liu, and Diyi Yang. Design2code: Benchmarking multimodal code generation for automated front-end engineering, 2025. URL https: //arxiv.org/abs/2403.03163
-
[32]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaugh- lin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Kimi Team, Angang Du, Bohong Yin, Bowei Xing, Bowen Qu, Bowen Wang, Cheng Chen, Chenlin Zhang, Chenzhuang Du, Chu Wei, et al. Kimi-vl technical report.arXiv preprint arXiv:2504.07491, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Kuang-Da Wang, Zhao Wang, Yotaro Shimose, Wei-Yao Wang, and Shingo Takamatsu. Webgen-v bench: Structured representation for enhancing visual design in llm-based web generation and evaluation.arXiv preprint arXiv:2510.15306, 2025
-
[35]
Openhands: An open platform for ai software developers as generalist agents
Xingyao Wang, Boxuan Li, Yufan Song, Frank F Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, et al. Openhands: An open platform for ai software developers as generalist agents. InThe Thirteenth International Conference on Learning Representations, 2024
2024
-
[36]
Introducing devin, the first ai software engineer, 2024
Scott Wu. Introducing devin, the first ai software engineer, 2024. URL https://cognition.ai/blog/ introducing-devin. Accessed: 2025-04-22
2024
-
[37]
Agentless: Demystifying LLM-based Software Engineering Agents
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. Agentless: Demystifying llm-based software engineering agents.arXiv preprint arXiv:2407.01489, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Interaction2code: Benchmarking mllm-based interactive webpage code generation from interactive prototyping
Jingyu Xiao, Yuxuan Wan, Yintong Huo, Zixin Wang, Xinyi Xu, Wenxuan Wang, Zhiyao Xu, Yuhang Wang, and Michael R Lyu. Interaction2code: Benchmarking mllm-based interactive webpage code generation from interactive prototyping. In2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE), pages 241–253. IEEE, 2025. 11
2025
- [39]
- [40]
-
[41]
LLM Xiaomi, Bingquan Xia, Bowen Shen, Dawei Zhu, Di Zhang, Gang Wang, Hailin Zhang, Huaqiu Liu, Jiebao Xiao, Jinhao Dong, et al. Mimo: Unlocking the reasoning potential of language model–from pretraining to posttraining.arXiv preprint arXiv:2505.07608, 2025
-
[42]
Swe-fixer: Training open-source llms for effective and efficient github issue resolution, 2025
Chengxing Xie, Bowen Li, Chang Gao, He Du, Wai Lam, Difan Zou, and Kai Chen. Swe-fixer: Training open-source llms for effective and efficient github issue resolution, 2025. URL https://arxiv.org/ abs/2501.05040
-
[43]
Web-bench: A llm code benchmark based on web standards and frameworks, 2025
Kai Xu, YiWei Mao, XinYi Guan, and ZiLong Feng. Web-bench: A llm code benchmark based on web standards and frameworks, 2025. URLhttps://arxiv.org/abs/2505.07473
-
[44]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems, 37:50528–50652, 2024
John Yang, Carlos Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems, 37:50528–50652, 2024
2024
-
[46]
John Yang, Carlos E Jimenez, Alex L Zhang, Kilian Lieret, Joyce Yang, Xindi Wu, Ori Press, Niklas Muennighoff, Gabriel Synnaeve, Karthik R Narasimhan, et al. Swe-bench multimodal: Do ai systems generalize to visual software domains?arXiv preprint arXiv:2410.03859, 2024
-
[47]
Webshop: Towards scalable real-world web interaction with grounded language agents, 2022
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. Webshop: Towards scalable real-world web interaction with grounded language agents, 2022
2022
-
[48]
Xing, Xiaodan Liang, and Zhiqiang Shen
Sukmin Yun, Haokun Lin, Rusiru Thushara, Mohammad Qazim Bhat, Yongxin Wang, Zutao Jiang, Mingkai Deng, Jinhong Wang, Tianhua Tao, Junbo Li, Haonan Li, Preslav Nakov, Timothy Baldwin, Zhengzhong Liu, Eric P. Xing, Xiaodan Liang, and Zhiqiang Shen. Web2code: A large-scale webpage-to-code dataset and evaluation framework for multimodal llms, 2024. URLhttps:/...
-
[49]
Fengji Zhang, Bei Chen, Yue Zhang, Jacky Keung, Jin Liu, Daoguang Zan, Yi Mao, Jian-Guang Lou, and Weizhu Chen. Repocoder: Repository-level code completion through iterative retrieval and generation. arXiv preprint arXiv:2303.12570, 2023
-
[50]
Shudan Zhang, Hanlin Zhao, Xiao Liu, Qinkai Zheng, Zehan Qi, Xiaotao Gu, Xiaohan Zhang, Yuxiao Dong, and Jie Tang. Naturalcodebench: Examining coding performance mismatch on humaneval and natural user prompts.arXiv preprint arXiv:2405.04520, 2024
-
[51]
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions
Terry Yue Zhuo, Minh Chien Vu, Jenny Chim, Han Hu, Wenhao Yu, Ratnadira Widyasari, Imam Nur Bani Yusuf, Haolan Zhan, Junda He, Indraneil Paul, et al. Bigcodebench: Benchmarking code generation with diverse function calls and complex instructions.arXiv preprint arXiv:2406.15877, 2024. 12 A Implementation Details In our experiments, for each model we consis...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
Element Enumeration: We traverse the fully rendered page to identify interactive elements (e.g., buttons, range sliders, select menus), annotating them with bounding-box coordinates for robust targeting
-
[53]
Semantic Action Mapping: Elements are assigned canonical interactions based on their HTML semantics (e.g., populating text inputs, setting sliders to midpoints) to prevent arbitrary failure modes
-
[54]
Task Definition
DOM Mutation Observation: For each action, we capture the DOM state before and after execution using aMutationObserverconfigured to track child lists, subtrees, and attributes. Here, ∆DOM (a, p) = 1 if action a triggers at least one DOM mutation. While BSR and IR provide binary indicators of structural viability, assessing the scientific fidelity and educ...
-
[55]
Block Pipeline
Results/Analysis (interactive charts), and 5) Conclusion (synthesis). Technical Constraints: • Output a structured natural language specification focusing on UI components, state variables, and visual logic. • Ensure the specification is entirely in the requested output language. Figure 6: System prompt for the PDF-to-Specification stage. This identifies ...
-
[56]
Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.