Behavior-Invariant Task Representation Learning with Transformer-based World Models for Offline Meta-Reinforcement Learning
Pith reviewed 2026-06-28 19:24 UTC · model grok-4.3
The pith
Task representations from a Transformer world model stay the same regardless of the policy that collected the offline data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
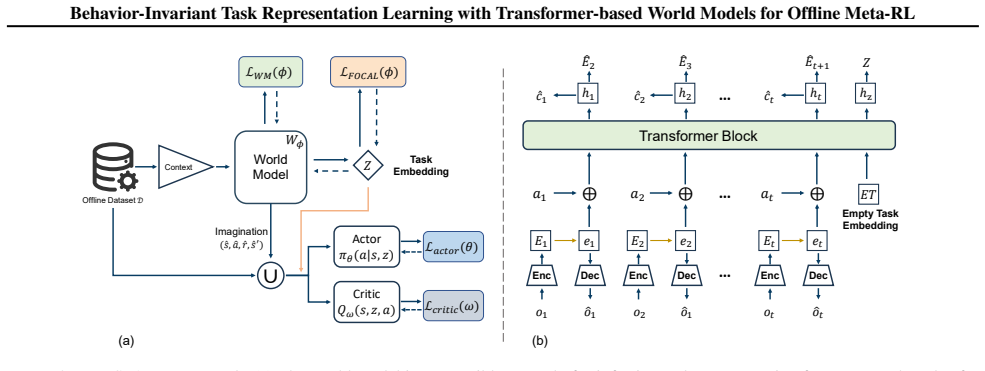
Integrating an information-theoretic task representation objective with a Transformer-based stochastic world model produces latent variables whose distribution is independent of the behavior policy that generated the offline data, thereby mitigating context distribution shift; a conservative value penalty on imagination-based rollouts simultaneously limits exploitation of model error and supports robust adaptation.
What carries the argument
The information-theoretic objective applied inside the Transformer-based stochastic world model, which isolates behavior-invariant latent variables that define each task.
If this is right
- Agents can adapt to unseen tasks from static datasets without suffering from context distribution shift caused by the original data-collection policy.
- The conservative penalty keeps the policy from exploiting errors in the world model during imagination-based planning.
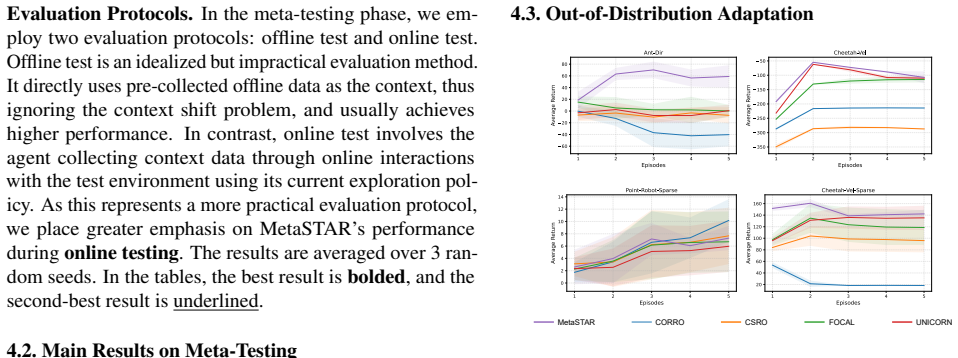
- Performance remains stable under out-of-distribution tasks and sparse-reward conditions.
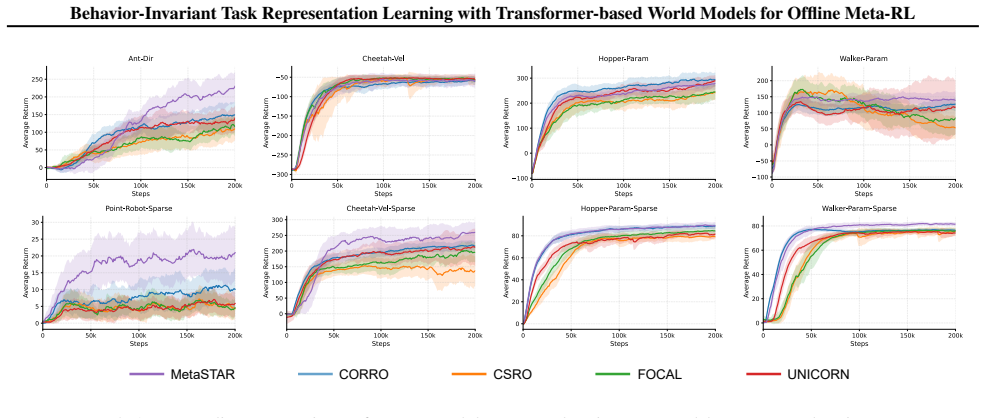
- The overall method yields higher success rates and better generalization than prior offline meta-RL approaches.
Where Pith is reading between the lines
- If the latent variables truly factor out policy effects, the same information-theoretic objective could be inserted into other model-based offline algorithms to reduce distribution shift.
- A direct test would measure whether the learned latents predict task identity better than they predict statistics of the collecting policy.
- Replacing the Transformer backbone with a different sequence model would show whether the invariance depends on the specific architecture.
Load-bearing premise
An information-theoretic penalty on the world model will force the extracted latent variables to have the same distribution no matter which policy collected the offline data.
What would settle it
Train the model on two separate offline datasets for identical tasks that were collected by behavior policies with clearly different state-action distributions; if the resulting latent distributions differ by more than sampling noise, the invariance claim is false.
Figures
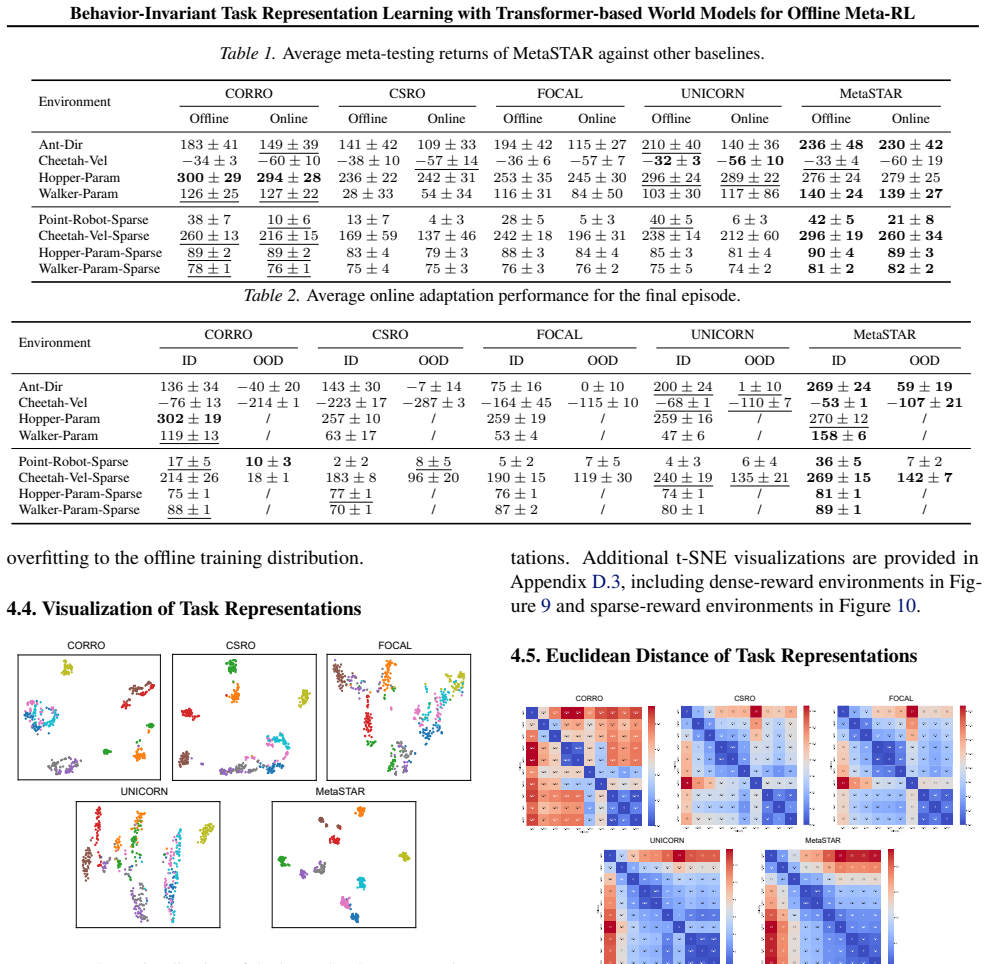
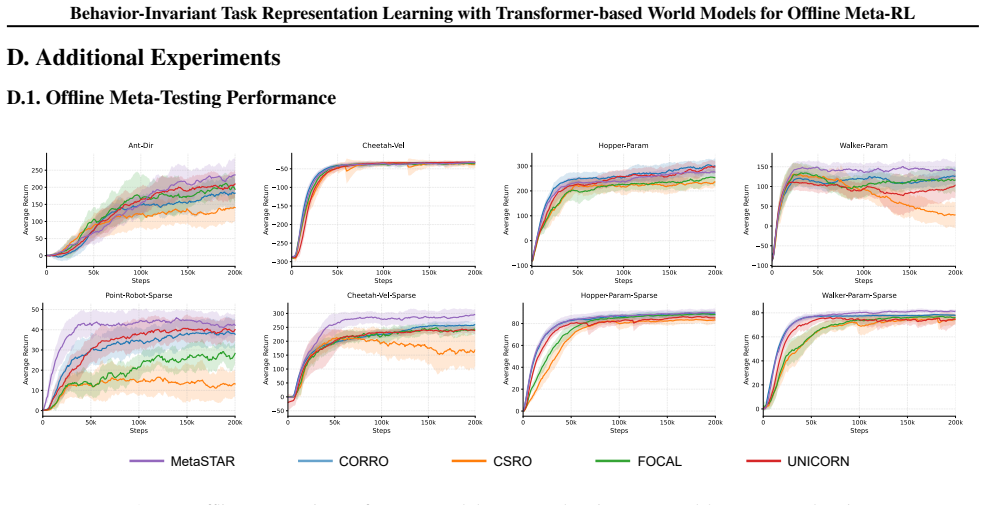
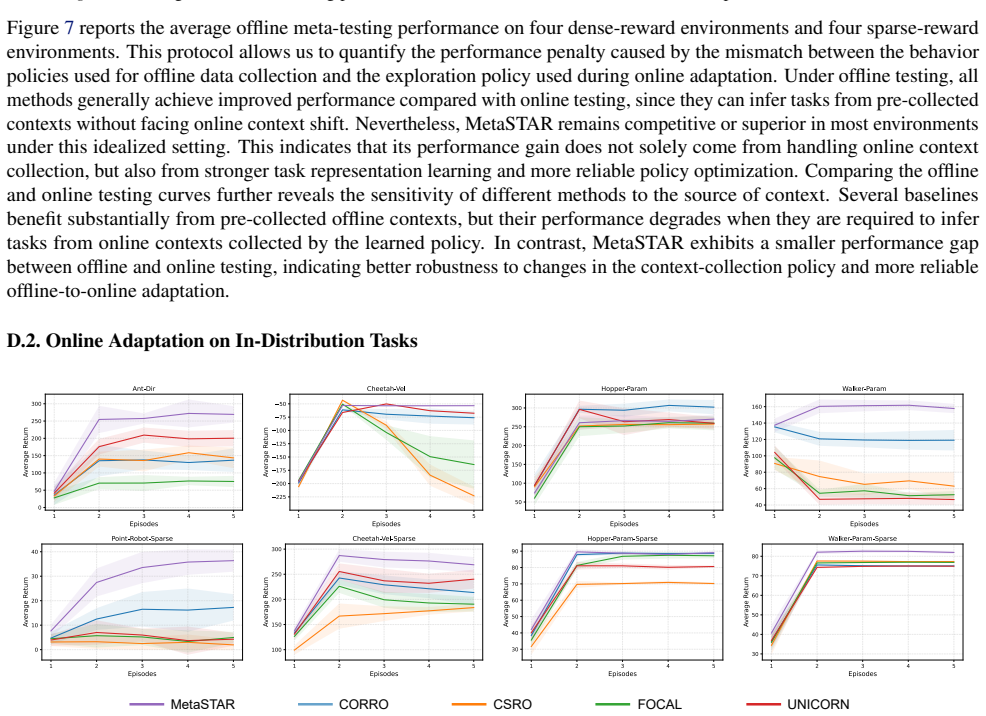
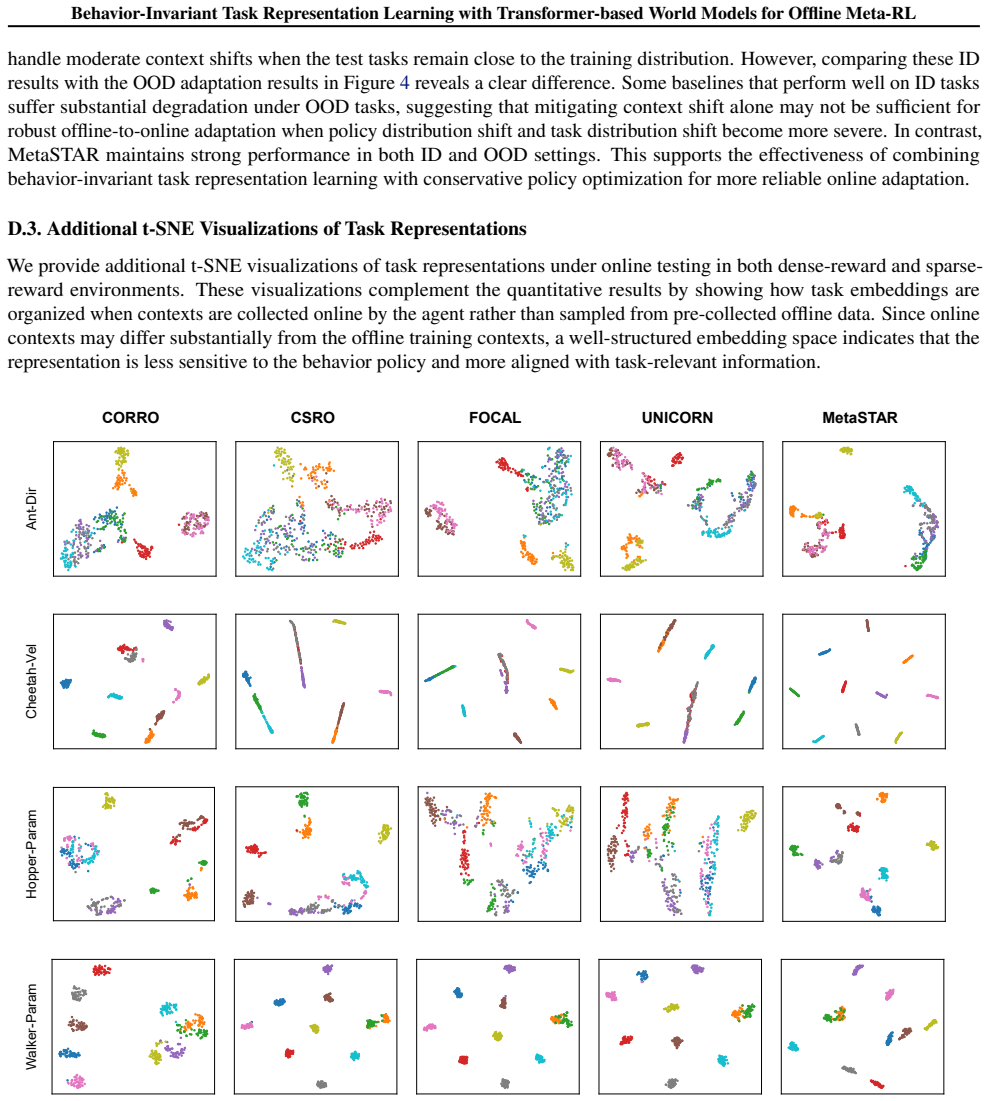

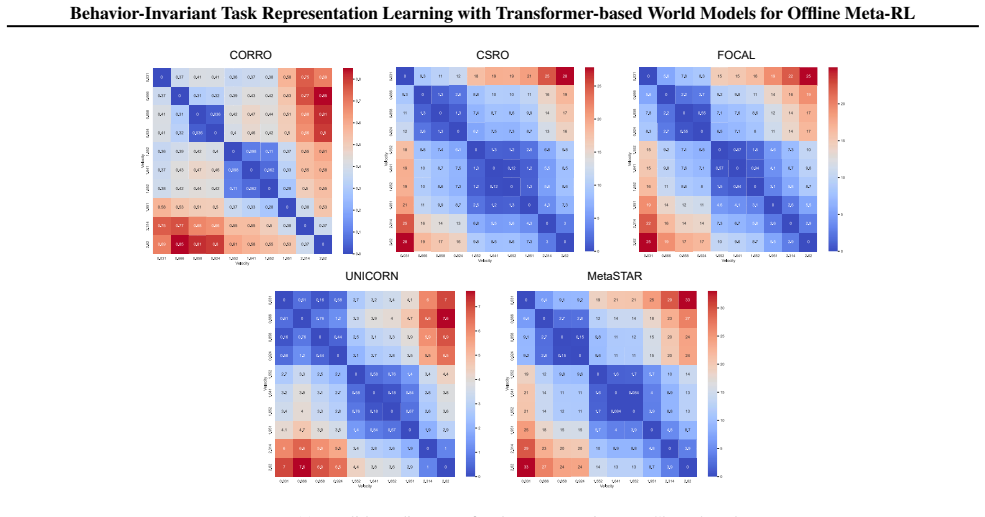
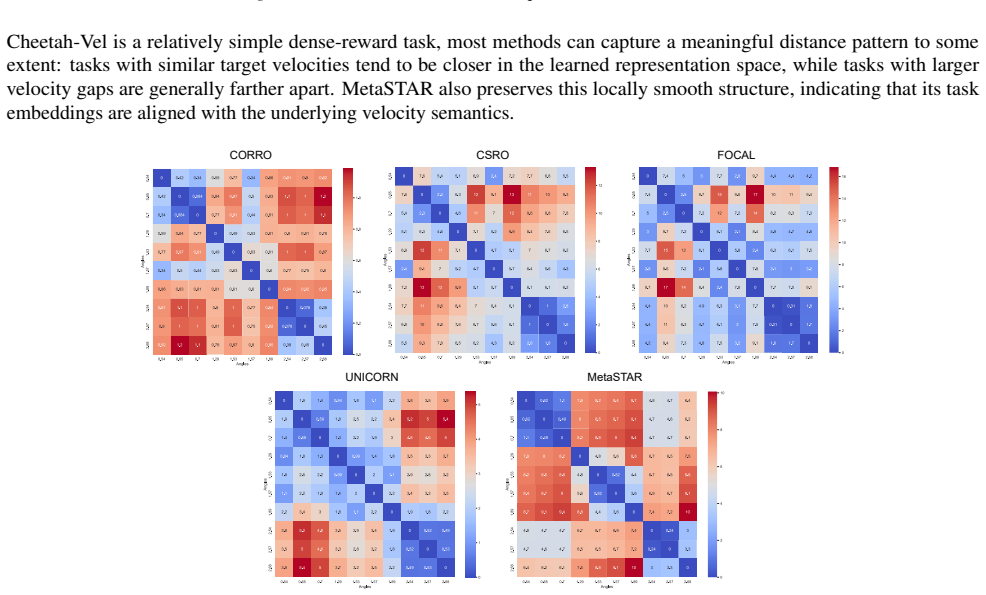
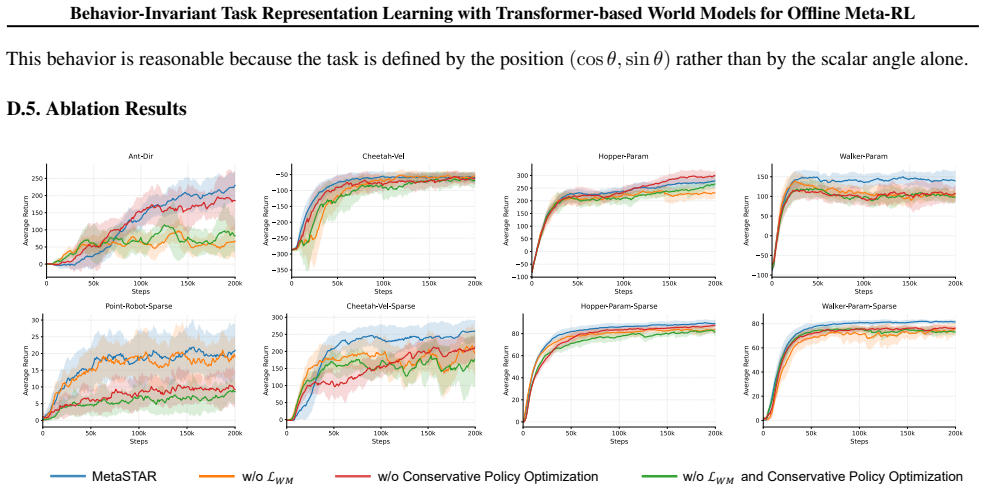
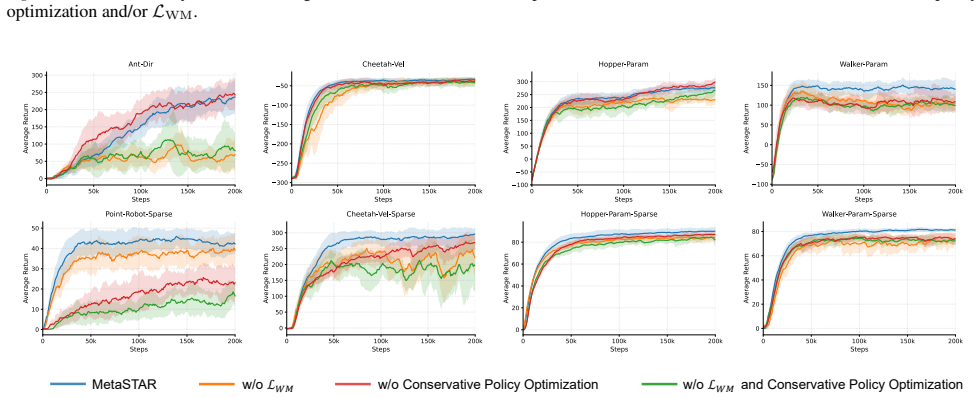
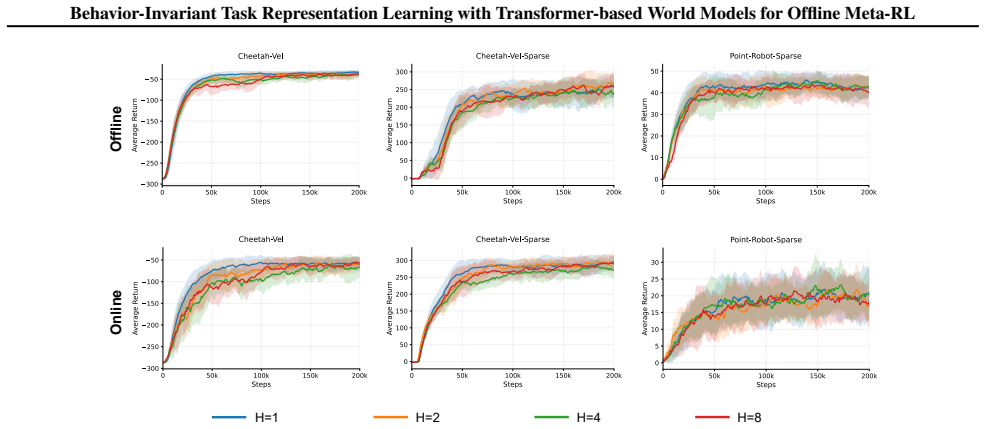
read the original abstract
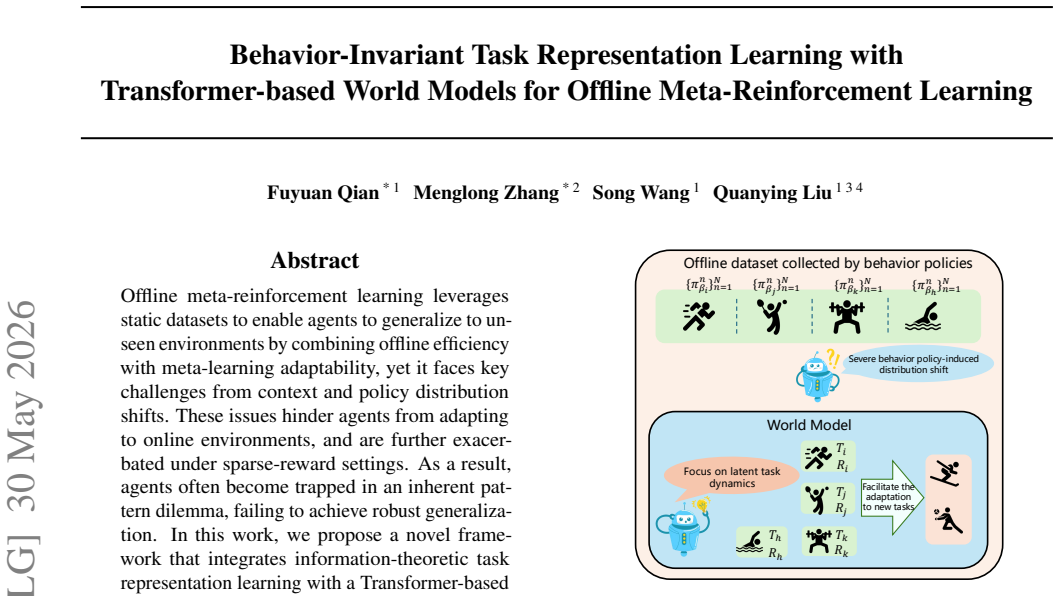
Offline meta-reinforcement learning leverages static datasets to enable agents to generalize to unseen environments by combining offline efficiency with meta-learning adaptability, yet it faces key challenges from context and policy distribution shifts. These issues hinder agents from adapting to online environments, and are further exacerbated under sparse-reward settings. As a result, agents often become trapped in an inherent pattern dilemma, failing to achieve robust generalization. In this work, we propose a novel framework that integrates information-theoretic task representation learning with a Transformer-based stochastic world model. Our approach extracts task-defining latent variables that are invariant to behavior policy, thereby effectively mitigating the context distribution shift. To further handle policy shift and model exploitation, we apply a conservative value penalty to imagination-based rollouts, preventing the policy from exploiting model inaccuracies while maintaining robust adaptation. Extensive evaluations demonstrate that our method outperforms state-of-the-art approaches, with superior stability and generalization under out-of-distribution and sparse-reward settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a framework for offline meta-reinforcement learning that integrates an information-theoretic objective for task representation learning inside a Transformer-based stochastic world model. The central claim is that this produces task latents z that are invariant to the behavior policy generating the offline data, thereby mitigating context distribution shift; a conservative value penalty is then applied to imagination-based rollouts to address policy shift and prevent model exploitation. The method is reported to outperform prior approaches on out-of-distribution and sparse-reward settings.
Significance. If the invariance property is actually realized by the objective and the conservative penalty demonstrably prevents exploitation without sacrificing adaptation, the work would address two load-bearing obstacles in offline meta-RL and could improve generalization from static datasets.
major comments (2)
- [Abstract] Abstract: the claim that the learned latents are 'invariant to behavior policy' is presented without any explicit invariance term (e.g., an adversarial discriminator on policy features or a KL(p(z|π_b1) || p(z|π_b2)) regularizer). Standard mutual-information objectives maximize I(context; z) but do not cancel dependence on π_b; no derivation or equation is supplied showing how invariance follows.
- [Abstract] Abstract: the conservative value penalty is described only at the level of 'preventing the policy from exploiting model inaccuracies.' Without the precise functional form (e.g., whether it is a penalty on the Q-function, a CQL-style term, or a model-uncertainty bonus) it is impossible to verify that the penalty simultaneously blocks exploitation and preserves the adaptation claimed in the meta-RL setting.
minor comments (1)
- The abstract states that 'extensive evaluations demonstrate' superiority but supplies no benchmark names, dataset sizes, or quantitative metrics, preventing any assessment of the strength of the empirical claims.
Simulated Author's Rebuttal
We thank the referee for these precise observations on the abstract. Both comments identify areas where the abstract's wording exceeds what is explicitly derived or specified in the manuscript. We will revise the abstract accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the learned latents are 'invariant to behavior policy' is presented without any explicit invariance term (e.g., an adversarial discriminator on policy features or a KL(p(z|π_b1) || p(z|π_b2)) regularizer). Standard mutual-information objectives maximize I(context; z) but do not cancel dependence on π_b; no derivation or equation is supplied showing how invariance follows.
Authors: The referee is correct that a standard mutual-information objective does not automatically cancel dependence on the behavior policy π_b, and the manuscript supplies neither an explicit invariance regularizer nor a derivation establishing invariance. The abstract therefore overstates the property. We will revise the abstract to replace the phrase 'invariant to behavior policy' with 'that mitigate context distribution shift arising from behavior policy variations', consistent with the experimental claims and the introduction. A clarifying sentence on the objective's limitations will be added to the methods section. revision: yes
-
Referee: [Abstract] Abstract: the conservative value penalty is described only at the level of 'preventing the policy from exploiting model inaccuracies.' Without the precise functional form (e.g., whether it is a penalty on the Q-function, a CQL-style term, or a model-uncertainty bonus) it is impossible to verify that the penalty simultaneously blocks exploitation and preserves the adaptation claimed in the meta-RL setting.
Authors: We agree that the abstract gives only a high-level description and does not state the functional form. The precise implementation appears in the methods; to address the comment we will expand the abstract by one sentence to indicate that the penalty is applied to Q-value estimates on imagined rollouts. This revision will make the mechanism verifiable from the abstract alone while preserving conciseness. revision: yes
Circularity Check
No circularity; invariance presented as modeling outcome without definitional reduction
full rationale
The provided abstract and context describe an information-theoretic objective inside a Transformer world model whose output is asserted to be behavior-invariant latents. No equations, fitted parameters renamed as predictions, or self-citation chains are visible that would make the invariance equivalent to the input objective by construction. The claim is therefore a modeling assertion rather than a tautological step, and the derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Burchi, M. and Timofte, R. Mudreamer: Learning predictive world models without reconstruction.arXiv preprint arXiv:2405.15083,
-
[2]
Burchi, M. and Timofte, R. Learning transformer-based world models with contrastive predictive coding.arXiv preprint arXiv:2503.04416,
-
[3]
Transdreamer: Rein- forcement learning with transformer world models,
Chen, C., Wu, Y .-F., Yoon, J., and Ahn, S. Transdreamer: Reinforcement learning with transformer world models. arXiv preprint arXiv:2202.09481,
-
[4]
RL$^2$: Fast Reinforcement Learning via Slow Reinforcement Learning
Duan, Y ., Schulman, J., Chen, X., Bartlett, P. L., Sutskever, I., and Abbeel, P. Rl2: Fast reinforcement learn- ing via slow reinforcement learning.arXiv preprint arXiv:1611.02779,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Ha, D. and Schmidhuber, J. World models.arXiv preprint arXiv:1803.10122,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Training Agents Inside of Scalable World Models
Hafner, D., Pasukonis, J., Ba, J., and Lillicrap, T. Mastering diverse control tasks through world models.Nature, pp. 1–7, 2025a. Hafner, D., Yan, W., and Lillicrap, T. Training agents inside of scalable world models.arXiv preprint arXiv:2509.24527, 2025b. Kingma, D. P. and Welling, M. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Li, L., Yang, R., and Luo, D. Focal: Efficient fully- offline meta-reinforcement learning via distance met- ric learning and behavior regularization.arXiv preprint arXiv:2010.01112,
-
[8]
Transformers are sample-efficient world models
Micheli, V ., Alonso, E., and Fleuret, F. Transform- ers are sample-efficient world models.arXiv preprint arXiv:2209.00588,
-
[9]
Rimon, Z., Jurgenson, T., Krupnik, O., Adler, G., and Tamar, A. Mamba: an effective world model approach for meta- reinforcement learning.arXiv preprint arXiv:2403.09859,
-
[10]
arXiv preprint arXiv:2303.07109 (2023)
Robine, J., H ¨oftmann, M., Uelwer, T., and Harmeling, S. Transformer-based world models are happy with 100k interactions.arXiv preprint arXiv:2303.07109,
-
[11]
doi: 10.1109/IROS.2012. 6386109. Wang, J., Zhang, J., Jiang, H., Zhang, J., Wang, L., and Zhang, C. Offline meta reinforcement learning with in- distribution online adaptation. InInternational Confer- ence on Machine Learning, pp. 36626–36669. PMLR,
-
[12]
Drivedreamer: Towards real-world-drive world models for autonomous driving
Wang, X., Zhu, Z., Huang, G., Chen, X., Zhu, J., and Lu, J. Drivedreamer: Towards real-world-drive world models for autonomous driving. InEuropean Conference on Computer Vision, pp. 55–72. Springer, 2024a. Wang, Y ., He, J., Fan, L., Li, H., Chen, Y ., and Zhang, Z. Driving into the future: Multiview visual forecasting and planning with world model for au...
-
[13]
Zintgraf, L., Shiarlis, K., Igl, M., Schulze, S., Gal, Y ., Hof- mann, K., and Whiteson, S. Varibad: A very good method for bayes-adaptive deep rl via meta-learning.arXiv preprint arXiv:1910.08348,
-
[14]
Therefore, the table should be interpreted mainly as a relative comparison under the same hardware and implementation setting
We note that the absolute wall-clock time may vary across machines due to differences in CPU performance, memory bandwidth, data loading efficiency, and software configuration. Therefore, the table should be interpreted mainly as a relative comparison under the same hardware and implementation setting. Table 3.Training time comparison on a single RTX 4090...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.