Enhancing LLM Metacognition via Cognitive Pairwise Training
Pith reviewed 2026-06-28 18:59 UTC · model grok-4.3
The pith
Pairwise comparisons of reasoning traces teach LLMs to internalize quality boundaries instead of memorizing refusals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
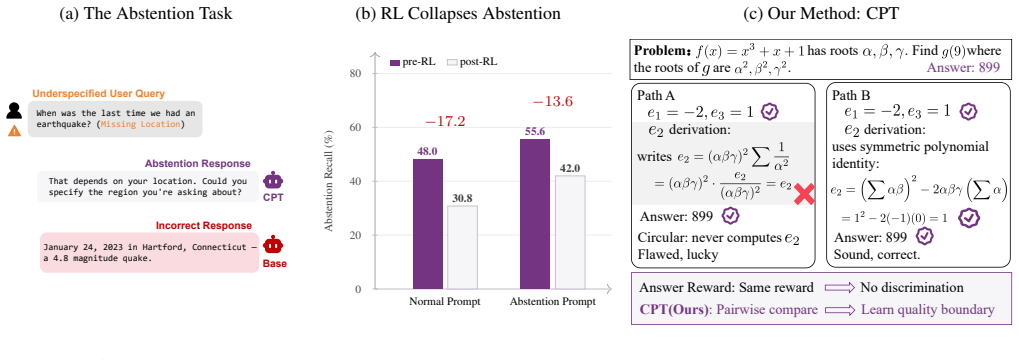
Cognitive Pairwise Training converts pairwise judgments over reasoning traces into a reusable alignment signal that lets models internalize a discrimination boundary between trustworthy and flawed reasoning, rather than memorizing refusal behaviors, and this boundary improves the reasoning-metacognition trade-off when combined with subsequent RL.
What carries the argument
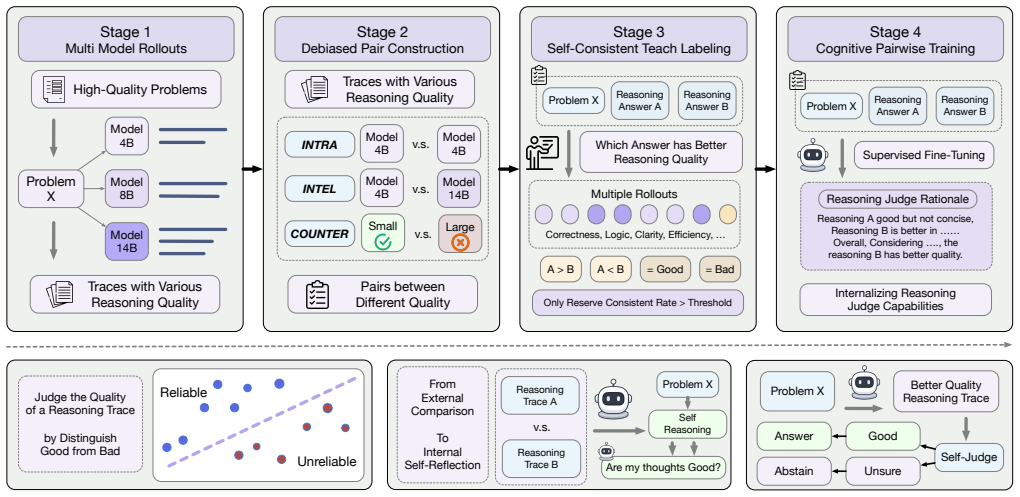
Cognitive Pairwise Training (CPT): a mid-training alignment stage that generates training signals from pairwise comparisons of reasoning traces to teach discrimination of reasoning quality.
If this is right
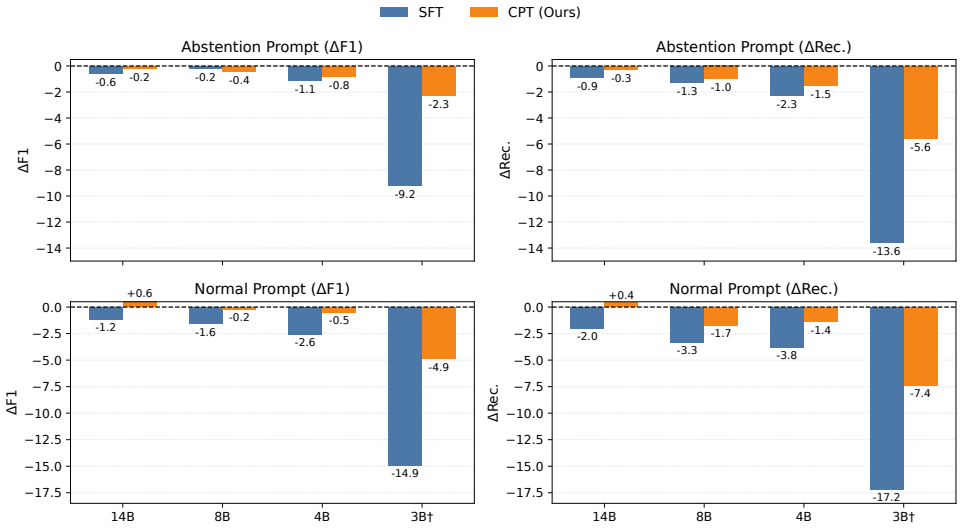
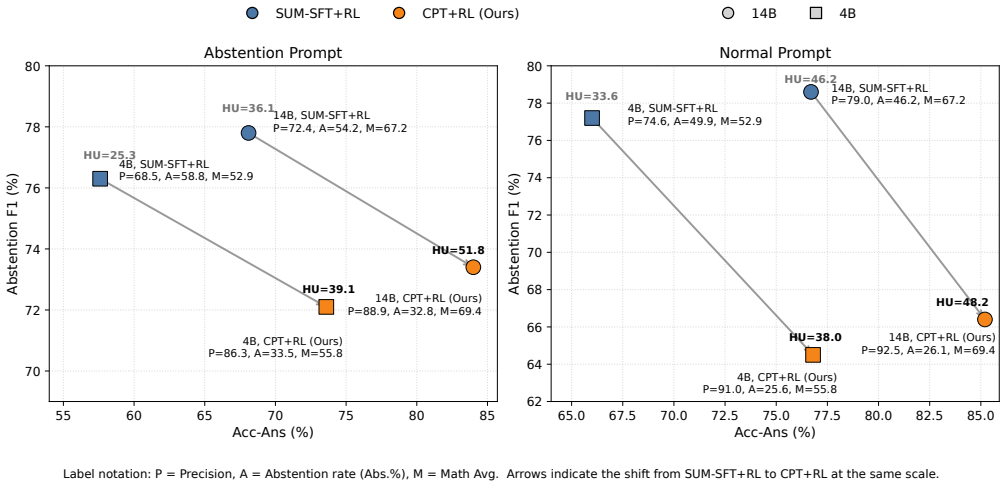
- CPT+RL yields higher math-average scores and abstention-F1 than the standard SFT+RL pipeline at 14B scale.
- The method produces measurable gains in trace quality and robustness across evaluation settings.
- The improvement in the reasoning-metacognition trade-off holds across multiple model scales and families.
- CPT acts as a reusable mid-training stage that can precede RL without requiring changes to the reward model.
Where Pith is reading between the lines
- The pairwise signal could be extended to non-math domains by collecting trace comparisons on other verifiable tasks.
- If the discrimination boundary generalizes, CPT might reduce the need for task-specific abstention fine-tuning.
- Combining CPT with outcome-level rewards may create models that abstain at the reasoning-step level rather than only at the final answer.
Load-bearing premise
That learning from pairwise comparisons of reasoning traces creates a generalizable boundary for reasoning quality that transfers beyond the training distribution rather than capturing only surface patterns.
What would settle it
Test CPT-trained models on a new task distribution where the surface features of good reasoning differ from those seen in training; if abstention-F1 and math accuracy both drop relative to SFT+RL baselines, the claim fails.
Figures

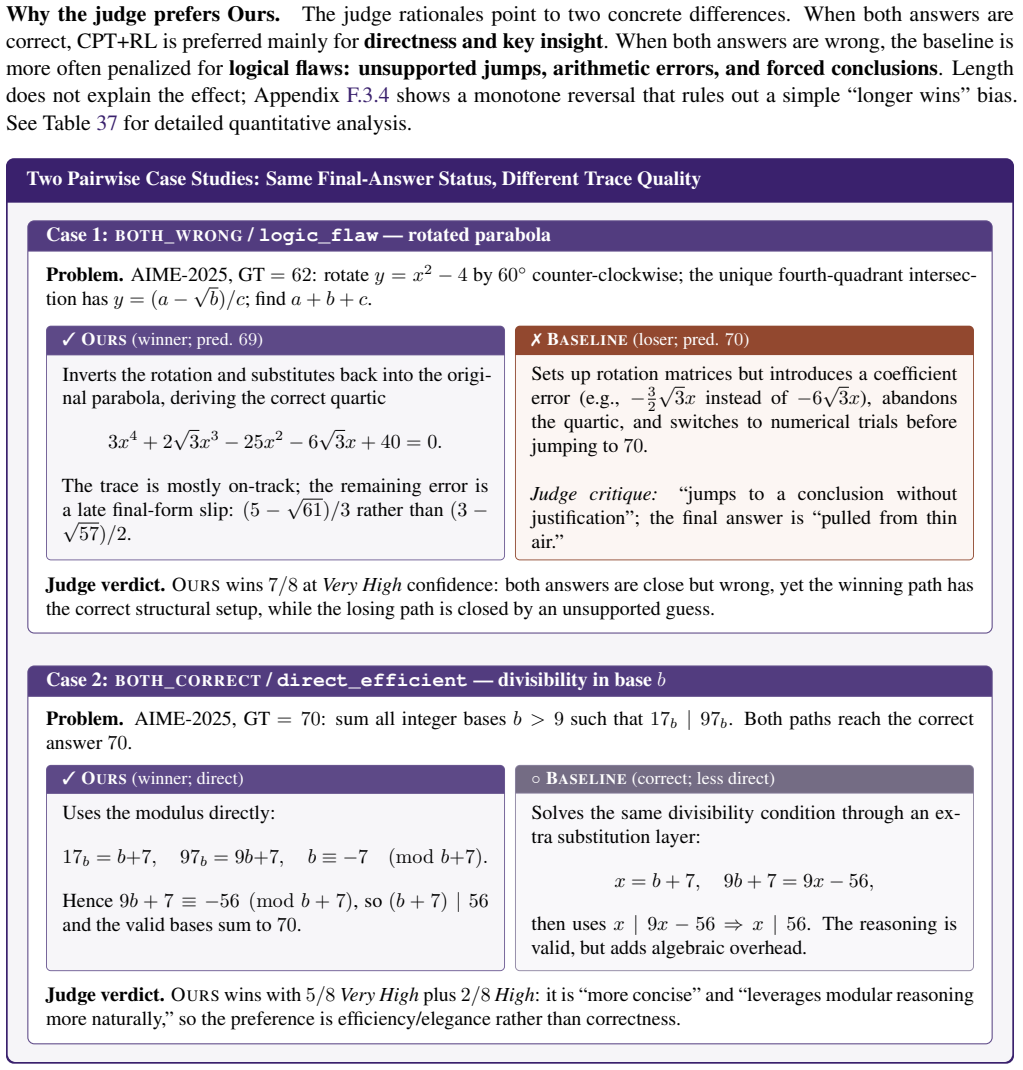
read the original abstract
Reinforcement learning with verifiable rewards (RLVR) has become central to LLM reasoning, but its outcome-level rewards can make models more willing to give confident answers when evidence or reasoning is unreliable. Existing SFT or RL methods mainly teach LLMs to refuse or express uncertainty at the response level, which can overfit abstention behavior rather than improve reasoning reliability. To address this limitation, we propose Cognitive Pairwise Training (CPT), a cognitive mid-training alignment stage that turns pairwise comparisons over reasoning traces into a reusable alignment signal. By learning to distinguish trustworthy from flawed reasoning, CPT encourages the model to internalize a reasoning-quality discrimination boundary rather than memorize surface refusal patterns. Across five model scales and three model families, CPT improves the reasoning--metacognition trade-off. At 14B, CPT+RL outperforms the standard SFT+RL pipeline by +2.2 math-average points and +5.2 abstention-F1 points. Further analyses show that CPT improves trace quality and exhibits strong robustness and scalability across evaluation and training settings. Code and models are released at https://github.com/Tsinghua-dhy/CPT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Cognitive Pairwise Training (CPT), a cognitive mid-training alignment stage that converts pairwise comparisons over reasoning traces into an alignment signal. By training models to distinguish trustworthy from flawed reasoning, CPT is claimed to internalize a reasoning-quality discrimination boundary rather than surface-level refusal patterns. This is reported to improve the reasoning-metacognition trade-off over standard SFT+RL baselines. Across five model scales and three families, CPT+RL yields gains such as +2.2 math-average points and +5.2 abstention-F1 points at the 14B scale. Additional analyses indicate improved trace quality plus robustness and scalability; code and models are released.
Significance. If the results hold, the work offers a targeted mid-training intervention that addresses overconfidence in RLVR pipelines by focusing on reasoning quality rather than response-level abstention. The public release of code and models is a clear strength that enables direct verification and extension.
major comments (1)
- [Abstract and CPT description paragraph] Abstract and CPT description paragraph: the central claim that CPT produces a reusable, generalizable discrimination boundary (rather than task-specific surface patterns) requires explicit detail on pair construction and the provenance of the 'trustworthy vs flawed' labels. Without this, it is impossible to determine whether the reported gains reduce to standard preference optimization on the same traces or reflect the claimed mechanism.
minor comments (1)
- The abstract states that 'further analyses show... strong robustness and scalability across evaluation and training settings' but does not reference the specific sections or tables containing those controls.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on clarifying the CPT mechanism. We address the major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and CPT description paragraph] Abstract and CPT description paragraph: the central claim that CPT produces a reusable, generalizable discrimination boundary (rather than task-specific surface patterns) requires explicit detail on pair construction and the provenance of the 'trustworthy vs flawed' labels. Without this, it is impossible to determine whether the reported gains reduce to standard preference optimization on the same traces or reflect the claimed mechanism.
Authors: We agree that the abstract and CPT description would benefit from explicit detail on pair construction and label provenance to support the claimed mechanism. In the full manuscript (Section 3), pairs are constructed by sampling two reasoning traces per question from the base model: one via standard CoT prompting and one via error-inducing perturbations (e.g., injected calculation or logic flaws). 'Trustworthy' vs 'flawed' labels are derived from step-level verification against ground-truth solutions or an external verifier, focusing on reasoning quality rather than final-answer match. This mid-training stage is intended to learn a generalizable discrimination boundary. We will revise the abstract and description paragraph to include a concise summary of this process with a pointer to Section 3, distinguishing it from standard preference optimization on the same traces. revision: yes
Circularity Check
No circularity; empirical method with independent results
full rationale
The paper introduces CPT as an empirical mid-training procedure based on pairwise reasoning trace comparisons and evaluates it through experiments across model scales and families, reporting gains relative to SFT+RL baselines. No equations, derivations, or parameter-fitting steps are described that could reduce predictions to inputs by construction. Claims rest on experimental outcomes rather than self-referential definitions or self-citation chains. The central distinction (internalized discrimination boundary vs. surface patterns) is tested via reported metrics and robustness analyses, not assumed via the method itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pairwise comparisons of reasoning traces provide a training signal that internalizes a reasoning-quality boundary rather than surface refusal patterns
Reference graph
Works this paper leans on
-
[1]
Kimi K2.5: Visual Agentic Intelligence
K. Team, T. Bai, Y . Bai, Y . Bao, S. Cai, Y . Cao, Y . Charles, H. Che, C. Chen, G. Chen,et al., “Kimi K2.5: Visual agentic intelligence,”arXiv preprint arXiv:2602.02276, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Qwen Team, “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
DeepSeek-V4: Towards highly efficient million-token context intelligence,
DeepSeek-AI, “DeepSeek-V4: Towards highly efficient million-token context intelligence,” 2026
2026
-
[4]
OpenClaw-RL: Train Any Agent Simply by Talking
Y . Wang, X. Chen, X. Jin, M. Wang, and L. Yang, “OpenClaw-RL: Train any agent simply by talking,”arXiv preprint arXiv:2603.10165, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Magpie: Alignment data synthesis from scratch by prompting aligned LLMs with nothing,
Z. Xu, F. Jiang, L. Niu, Y . Deng, R. Poovendran, Y . Choi, and B. Y . Lin, “Magpie: Alignment data synthesis from scratch by prompting aligned LLMs with nothing,” inInternational Conference on Learning Representa- tions (ICLR), 2025
2025
-
[6]
Tongyi DeepResearch Technical Report
T. D. Team, B. Li, B. Zhang, D. Zhang, F. Huang, G. Li, G. Chen, H. Yin, J. Wu, J. Zhou,et al., “Tongyi DeepResearch technical report,”arXiv preprint arXiv:2510.24701, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Language models are few-shot learners,
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-V oss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amodei...
1901
-
[8]
Agent hospital: A simulacrum of hospital with evolvable medical agents,
J. Li, Y . Lai, W. Li, J. Ren, M. Zhang, X. Kang, S. Wang, P. Li, Y .-Q. Zhang, W. Ma,et al., “Agent hospital: A simulacrum of hospital with evolvable medical agents,”ArXiv preprint, vol. abs/2405.02957, 2024
-
[9]
Cbr-rag: case-based reasoning for retrieval augmented generation in llms for legal question answering,
N. Wiratunga, R. Abeyratne, L. Jayawardena, K. Martin, S. Massie, I. Nkisi-Orji, R. Weerasinghe, A. Liret, and B. Fleisch, “Cbr-rag: case-based reasoning for retrieval augmented generation in llms for legal question answering,” inInternational Conference on Case-Based Reasoning, pp. 445–460, Springer, 2024
2024
-
[10]
Improving retrieval for rag based question answering models on financial documents,
S. Setty, H. Thakkar, A. Lee, E. Chung, and N. Vidra, “Improving retrieval for rag based question answering models on financial documents,”ArXiv preprint, vol. abs/2404.07221, 2024
-
[11]
WildClawBench: A Benchmark for Real-World, Long-Horizon Agent Evaluation
S. Ding, X. Dai, L. Xing, S. Ding, Z. Liu, Y . JingYi, P. Yang, Z. Zhang, X. Wei, X. Fang,et al., “WildClaw- Bench: A benchmark for real-world, long-horizon agent evaluation,”arXiv preprint arXiv:2605.10912, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Hallucinations Undermine Trust; Metacognition is a Way Forward
G. Yona, M. Geva, and Y . Matias, “Hallucinations undermine trust; metacognition is a way forward,”arXiv preprint arXiv:2605.01428, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Metacognition and cognitive monitoring: A new area of cognitive-developmental inquiry,
J. H. Flavell, “Metacognition and cognitive monitoring: A new area of cognitive-developmental inquiry,”Amer- ican Psychologist, vol. 34, no. 10, pp. 906–911, 1979
1979
-
[14]
Language Models (Mostly) Know What They Know
S. Kadavath, T. Conerly, A. Askell, T. Henighan, D. Drain, E. Perez, N. Schiefer, Z. Hatfield-Dodds, N. Das- Sarma, E. Tran-Johnson, S. Johnston, S. El-Showk, A. Jones, N. Elhage, T. Hume, A. Chen, Y . Bai, S. Bow- man, S. Fort, D. Ganguli, D. Hernandez, J. Jacobson, J. Kernion, S. Kravec, L. Lovitt, K. Ndousse, C. Olsson, S. Ringer, D. Amodei, T. Brown, ...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning,
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Bi,et al., “Deepseek-r1 incentivizes reasoning in llms through reinforcement learning,”Nature, vol. 645, no. 8081, pp. 633–638, 2025
2025
-
[16]
Are reasoning models more prone to hallucination?,
Z. Yao, Y . Liu, Y . Chen, J. Chen, J. Fang, L. Hou, J. Li, and T.-S. Chua, “Are reasoning models more prone to hallucination?,”arXiv preprint arXiv:2505.23646, 2025
-
[17]
Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models
Y . Sui, Y .-N. Chuang, G. Wang, J. Zhang, T. Zhang, J. Yuan, H. Liu, A. Wen, S. Zhong, N. Zou, H. Chen, and X. Hu, “Stop overthinking: A survey on efficient reasoning for large language models,”arXiv preprint arXiv:2503.16419, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Auditing meta-cognitive hallucinations in reason- ing large language models,
H. Lu, Y . Liu, J. Xu, G. Nan, Y . Yu, Z. Chen, and K. Wang, “Auditing meta-cognitive hallucinations in reason- ing large language models,”arXiv preprint arXiv:2505.13143, 2025. Accepted by NeurIPS 2025
-
[19]
The hallucination tax of reinforcement finetuning,
L. Song, T. Shi, and J. Zhao, “The hallucination tax of reinforcement finetuning,” inFindings of the Association for Computational Linguistics: EMNLP 2025(C. Christodoulopoulos, T. Chakraborty, C. Rose, and V . Peng, eds.), (Suzhou, China), pp. 2105–2120, Association for Computational Linguistics, Nov. 2025
2025
-
[20]
A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions,
L. Huang, W. Yu, W. Ma, W. Zhong, Z. Feng, H. Wang, Q. Chen, W. Peng, X. Feng, B. Qin, and T. Liu, “A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions,”ACM Transactions on Information Systems, vol. 43, no. 2, pp. 1–55, 2024
2024
-
[21]
A survey of confidence estimation and calibration in large language models,
J. Geng, F. Cai, Y . Wang, H. Kober, W. Buntine, and G. Haffari, “A survey of confidence estimation and calibration in large language models,” inProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp. 6577–6595, 2024. 16
2024
-
[22]
R-tuning: Instructing large language models to say ‘i don’t know’,
H. Zhang, S. Diao, Y . Lin, Y . Fung, Q. Lian, X. Wang, Y . Chen, H. Ji, and T. Zhang, “R-tuning: Instructing large language models to say ‘i don’t know’,” inProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp. 7113–7139, 2024
2024
-
[23]
Beyond “i don’t know
J. Ren, A. Wang, Y . Lai, X. Wang, L. Gong, W. Li, W. Ma, and Y . Liu, “Beyond “i don’t know”: Evaluating LLM self-awareness in discriminating data and model uncertainty,” 2026
2026
-
[24]
Inference-time scaling for generalist reward modeling,
Z. Liu, P. Wang, R. Xu, S. Ma, C. Ruan, P. Li, Y . Liu, and Y . Wu, “Inference-time scaling for generalist reward modeling,”arXiv preprint arXiv:2504.02495, 2025
-
[25]
Let’s verify step by step,
H. Lightman, V . Kosaraju, Y . Burda, H. Edwards, B. Baker, T. Lee, J. Leike, J. Schulman, I. Sutskever, and K. Cobbe, “Let’s verify step by step,” inInternational Conference on Learning Representations, vol. 2024, pp. 39578–39601, 2024
2024
-
[26]
Agent Learning via Early Experience
K. Zhang, X. Chen, B. Liu, T. Xue, Z. Liao, Z. Liu, X. Wang, Y . Ning, Z. Chen, X. Fu,et al., “Agent learning via early experience,”arXiv preprint arXiv:2510.08558, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
General agents need world models,
J. Richens, T. Everitt, and D. Abel, “General agents need world models,” inInternational Conference on Machine Learning, pp. 51659–51687, PMLR, 2025
2025
-
[28]
Model Spec Midtraining: Improving How Alignment Training Generalizes
C. Li, S. Price, S. Marks, and J. Kutasov, “Model spec midtraining: Improving how alignment training gener- alizes,”arXiv preprint arXiv:2605.02087, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Training language models to follow instructions with human feedback,
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, et al., “Training language models to follow instructions with human feedback,” inAdvances in Neural Infor- mation Processing Systems, vol. 35, pp. 27730–27744, 2022
2022
-
[30]
Judging LLM-as-a-Judge with MT-Bench and chatbot arena,
L. Zheng, W.-L. Chiang, Y . Sheng, S. Zhuang, Z. Wu, Y . Zhuang, Z. Lin, Z. Li, D. Li, E. Xing,et al., “Judging LLM-as-a-Judge with MT-Bench and chatbot arena,” inAdvances in Neural Information Processing Systems, vol. 36, 2023
2023
-
[31]
Large Language Models are not Fair Evaluators
P. Wang, L. Li, L. Chen, Z. Cai, D. Zhu, B. Lin, Y . Cao, Q. Liu, T. Liu, and Z. Sui, “Large language models are not fair evaluators,”arXiv preprint arXiv:2305.17926, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
The False Promise of Imitating Proprietary LLMs
A. Gudibande, E. Wallace, C. Snell, X. Geng, H. Liu, P. Abbeel, S. Levine, and D. Song, “The false promise of imitating proprietary LLMs,”arXiv preprint arXiv:2305.15717, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan,et al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
T. Olmo, A. Ettinger, A. Bertsch, B. Kuehl, D. Graham, D. Heineman, D. Groeneveld, F. Brahman, F. Timbers, H. Ivison,et al., “Olmo 3,”arXiv preprint arXiv:2512.13961, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Abstentionbench: Reasoning LLMs fail on unanswer- able questions,
P. Kirichenko, M. Ibrahim, K. Chaudhuri, and S. J. Bell, “Abstentionbench: Reasoning LLMs fail on unanswer- able questions,”arXiv preprint arXiv:2506.09038, 2025
-
[36]
Self-refine: Iterative refinement with self-feedback,
A. Madaan, N. Tandon, P. Gupta, S. Hallinan, L. Gao, S. Wiegreffe, U. Alon, N. Dziri, S. Prabhumoye, Y . Yang, S. Gupta, B. P. Majumder, K. Hermann, S. Welleck, A. Yazdanbakhsh, and P. Clark, “Self-refine: Iterative refinement with self-feedback,” inAdvances in Neural Information Processing Systems, 2023
2023
-
[37]
Reflexion: Language agents with verbal reinforcement learning,
N. Shinn, F. Cassano, E. Berman, A. Gopinath, K. Narasimhan, and S. Yao, “Reflexion: Language agents with verbal reinforcement learning,” inAdvances in Neural Information Processing Systems, 2023. 17
2023
-
[38]
Beyond Binary Rewards: Training LMs to Reason About Their Uncertainty
M. Damani, I. Puri, S. Slocum, I. Shenfeld, L. Choshen, Y . Kim, and J. Andreas, “Beyond binary rewards: Training LMs to reason about their uncertainty,”arXiv preprint arXiv:2507.16806, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
D. Bani-Harouni, C. Pellegrini, P. Stangel, E. Özsoy, M. Keicher, and N. Navab, “Rewarding doubt: A reinforcement learning approach to confidence calibration of large language models,”arXiv preprint arXiv:2503.02623, 2025. Accepted at ICLR 2026
-
[40]
MASH: Modeling Abstention via Selective Help-Seeking
M. O. Gul, C. Cardie, and T. Goyal, “Pay-per-search models are abstention models,”arXiv preprint arXiv:2510.01152, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
SelectLLM: Query-aware efficient selection algorithm for large language models,
K. K. Maurya, K. A. Srivatsa, and E. Kochmar, “SelectLLM: Query-aware efficient selection algorithm for large language models,” inFindings of the Association for Computational Linguistics: ACL 2025, 2025
2025
-
[42]
H. Chenet al., “Know more, know clearer: A meta-cognitive framework for knowledge augmentation in large language models,”arXiv preprint arXiv:2602.12996, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[43]
SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the Wild
W. Zeng, Y . Huang, Q. Liu, W. Liu, K. He, Z. Ma, and J. He, “Simplerl-zoo: Investigating and taming zero reinforcement learning for open base models in the wild,”arXiv preprint arXiv:2503.18892, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Q. Yu, Z. Zhang, R. Zhu, Y . Yuan, X. Zuo, Y . Yue, T. Fan, G. Liu, L. Liu, X. Liu,et al., “DAPO: An open-source LLM reinforcement learning system at scale,”arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Measuring Mathematical Problem Solving With the MATH Dataset
D. Hendrycks, C. Burns, S. Kadavath, A. Arora, S. Basart, E. Tang, D. Song, and J. Steinhardt, “Measuring mathematical problem solving with the MATH dataset,”arXiv preprint arXiv:2103.03874, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[46]
C. He, R. Luo, Y . Bai, S. Hu, Z. L. Thai, J. Shen, J. Hu, X. Han, Y . Huang, Y . Zhang,et al., “Olympiadbench: A challenging benchmark for promoting AGI with olympiad-level bilingual multimodal scientific problems,” arXiv preprint arXiv:2402.14008, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
Solving quantitative reasoning problems with language models,
A. Lewkowycz, A. Andreassen, D. Dohan, E. Dyer, H. Michalewski, V . Ramasesh, A. Slone, C. Anil, I. Schlag, T. Gutman-Solo,et al., “Solving quantitative reasoning problems with language models,”Advances in Neural Information Processing Systems, vol. 35, pp. 3843–3857, 2022
2022
-
[48]
AIMO validation AMC: Problems from AMC 12 2022–2023
AI-MO, “AIMO validation AMC: Problems from AMC 12 2022–2023.”https://huggingface.co/ datasets/AI-MO/aimo-validation-amc, 2024. Contains 83 problems from AMC 12 2022 and AMC 12 2023
2022
-
[49]
AIMO validation AIME: Problems from AIME 2022–2024
AI-MO, “AIMO validation AIME: Problems from AIME 2022–2024.”https://huggingface.co/ datasets/AI-MO/aimo-validation-aime, 2024. Contains 90 problems from AIME 2022–2024
2022
-
[50]
Direct preference optimization: Your language model is secretly a reward model,
R. Rafailov, A. Sharma, E. Mitchell, S. Ermon, C. D. Manning, and C. Finn, “Direct preference optimization: Your language model is secretly a reward model,”Advances in Neural Information Processing Systems, vol. 36, 2024
2024
-
[51]
Hybridflow: A flexible and efficient rlhf framework,
G. Sheng, C. Zhang, Z. Ye, X. Wu, W. Zhang, R. Zhang, Y . Peng, H. Lin, and C. Wu, “Hybridflow: A flexible and efficient rlhf framework,” inProceedings of the Twentieth European Conference on Computer Systems, pp. 1279–1297, 2025
2025
-
[52]
Efficient memory management for large language model serving with PagedAttention,
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. E. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory management for large language model serving with PagedAttention,” inProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, pp. 611–626, 2023. 18
2023
-
[53]
DRAGged into conflicts: Detecting and addressing conflicting sources in search-augmented LLMs,
A. Cattan, A. Jacovi, A. Fabrikant, J. Herzig, R. Aharoni, H. Rashkin, D. Reitter, R. Tsarfaty, and D. Das, “DRAGged into conflicts: Detecting and addressing conflicting sources in search-augmented LLMs,”arXiv preprint arXiv:2506.08500, 2025
-
[54]
JustRL: Scaling a 1.5b LLM with a simple RL recipe,
B. He, Z. Qu, Z. Liu, Y . Chen, Y . Zuo, C. Qian, K. Zhang, W. Chen, C. Xiao, G. Cui,et al., “JustRL: Scaling a 1.5b LLM with a simple RL recipe,”arXiv preprint arXiv:2512.16649, 2025
-
[55]
Ur2: Unify rag and reasoning through reinforcement learning,
W. Li, B. Xiang, X. Wang, Z. Gou, W. Ma, and Y . Liu, “Ur2: Unify rag and reasoning through reinforcement learning,” 2026
2026
-
[56]
OpenMathReasoning: A large-scale dataset for mathematical reasoning
NVIDIA, “OpenMathReasoning: A large-scale dataset for mathematical reasoning.”https:// huggingface.co/datasets/nvidia/OpenMathReasoning, 2025. Released under CC-BY-4.0; in- cludes COT, TIR, and genselect subsets
2025
-
[57]
Deepscaler: Surpassing o1-preview with a 1.5b model by scaling rl
M. Luo, S. Tan, J. Wong, X. Shi, W. Y . Tang, M. Roongta, C. Cai, J. Luo, L. E. Li, R. A. Popa, and I. Stoica, “Deepscaler: Surpassing o1-preview with a 1.5b model by scaling rl.”https://pretty-radio-b75.notion.site/ DeepScaleR-Surpassing-O1-Preview-with-a-1-5B-Model-by-Scaling-RL-19681902c1468005bed8ca303013a4e2,
-
[58]
ALCUNA: Large language models meet new knowledge,
X. Yin, B. Huang, and X. Wan, “ALCUNA: Large language models meet new knowledge,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 1397–1414, 2023
2023
-
[59]
BBQ: A hand-built bias benchmark for question answering,
A. Parrish, A. Chen, N. Nangia, V . Padmakumar, J. Phang, J. Thompson, P. M. Htut, and S. R. Bowman, “BBQ: A hand-built bias benchmark for question answering,” inFindings of the Association for Computational Linguistics: ACL 2022, pp. 2086–2105, 2022
2022
-
[60]
Beyond the imitation game: Quantifying and extrapolating the capabilities of language models,
A. Srivastava, A. Rastogi, A. Rao,et al., “Beyond the imitation game: Quantifying and extrapolating the capabilities of language models,”Transactions on Machine Learning Research, 2023
2023
-
[61]
The art of saying no: Contextual noncompliance in language models,
F. Brahman, S. Kumar, V . Balachandran, P. Dasigi, V . Pyatkin, A. Ravichander, S. Wiegreffe, N. Dziri, K. Chandu, J. Hessel,et al., “The art of saying no: Contextual noncompliance in language models,”arXiv preprint arXiv:2407.12043, 2024
-
[62]
Won’t get fooled again: Answering questions with false premises,
S. Hu, Y . Luo, H. Wang, X. Cheng, Z. Liu, and M. Sun, “Won’t get fooled again: Answering questions with false premises,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics, pp. 8653–8665, 2023
2023
-
[63]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
D. Rein, B. L. Hou, A. C. Stickland, J. Petty, R. Y . Pang, J. Dirani, J. Michael, and S. R. Bowman, “GPQA: A graduate-level google-proof Q&A benchmark,”arXiv preprint arXiv:2311.12022, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[64]
Training Verifiers to Solve Math Word Problems
K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, et al., “Training verifiers to solve math word problems,”arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[65]
Knowledge of knowledge: Exploring known- unknowns uncertainty with large language models,
A. Amayuelas, K. Wong, L. Pan, W. Chen, and W. Wang, “Knowledge of knowledge: Exploring known- unknowns uncertainty with large language models,” inFindings of the Association for Computational Linguis- tics: ACL 2024, 2024
2024
-
[66]
MediQ: Question- asking LLMs and a benchmark for reliable interactive clinical reasoning,
S. S. Li, V . Balachandran, S. Feng, J. S. Ilgen, E. Pierson, P. W. Koh, and Y . Tsvetkov, “MediQ: Question- asking LLMs and a benchmark for reliable interactive clinical reasoning,” inAdvances in Neural Information Processing Systems, vol. 37, pp. 28858–28888, 2024. 19
2024
-
[67]
Measuring Massive Multitask Language Understanding
D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt, “Measuring massive multitask language understanding,”arXiv preprint arXiv:2009.03300, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[68]
Evaluating the moral beliefs encoded in LLMs,
N. Scherrer, C. Shi, A. Feder, and D. M. Blei, “Evaluating the moral beliefs encoded in LLMs,” inAdvances in Neural Information Processing Systems, vol. 36, pp. 51778–51809, 2023
2023
-
[69]
MuSiQue: Multihop questions via single-hop question composition,
H. Trivedi, N. Balasubramanian, T. Khot, and A. Sabharwal, “MuSiQue: Multihop questions via single-hop question composition,”Transactions of the Association for Computational Linguistics, vol. 10, pp. 539–554, 2022
2022
-
[70]
(QA)2: Question answering with questionable assumptions,
N. Kim, P. M. Htut, S. R. Bowman, and J. Petty, “(QA)2: Question answering with questionable assumptions,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics, 2023
2023
-
[71]
A dataset of information-seeking questions and answers anchored in research papers,
P. Dasigi, K. Lo, I. Beltagy, A. Cohan, N. A. Smith, and M. Gardner, “A dataset of information-seeking questions and answers anchored in research papers,” inProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics, pp. 4599–4610, 2021
2021
-
[72]
SituatedQA: Incorporating extra-linguistic contexts into QA,
M. J. Q. Zhang and E. Choi, “SituatedQA: Incorporating extra-linguistic contexts into QA,” inProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp. 7371–7387, 2021
2021
-
[73]
Know what you don’t know: Unanswerable questions for SQuAD,
P. Rajpurkar, R. Jia, and P. Liang, “Know what you don’t know: Unanswerable questions for SQuAD,” in Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, pp. 784–789, 2018
2018
-
[74]
Benchmarking hallucination in large language models based on unanswerable math word problem,
Y . Sun, Z. Yin, Q. Guo, J. Wu, X. Qiu, and H. Zhao, “Benchmarking hallucination in large language models based on unanswerable math word problem,”arXiv preprint arXiv:2403.03558, 2024
-
[75]
WorldSense: A synthetic benchmark for grounded reasoning in large language models,
Y . Benchekroun, M. Dervishi, M. Ibrahim, J.-B. Gaya, X. Martinet, G. Mialon, T. Scialom, E. Dupoux, D. Hup- kes, and P. Vincent, “WorldSense: A synthetic benchmark for grounded reasoning in large language models,” arXiv preprint arXiv:2311.15930, 2023
-
[76]
A coefficient of agreement for nominal scales,
J. Cohen, “A coefficient of agreement for nominal scales,”Educational and Psychological Measurement, vol. 20, no. 1, pp. 37–46, 1960
1960
-
[77]
The measurement of observer agreement for categorical data,
J. R. Landis and G. G. Koch, “The measurement of observer agreement for categorical data,”Biometrics, vol. 33, no. 1, pp. 159–174, 1977
1977
-
[78]
Measuring nominal scale agreement among many raters,
J. L. Fleiss, “Measuring nominal scale agreement among many raters,”Psychological Bulletin, vol. 76, no. 5, pp. 378–382, 1971
1971
-
[79]
Quagmires in SFT-RL post-training: When high SFT scores mislead and what to use instead,
F. Kang, M. Kuchnik, K. Padthe, M. Vlastelica, R. Jia, C.-J. Wu,et al., “Quagmires in SFT-RL post-training: When high SFT scores mislead and what to use instead,”arXiv preprint arXiv:2510.01624, 2025
-
[80]
Beyond Two-Stage Training: Cooperative SFT and RL for LLM Reasoning
L. Chen, P. Han,et al., “Beyond two-stage training: Cooperative SFT and RL for LLM reasoning,”arXiv preprint arXiv:2509.06948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.