Citation Grounding: Detecting and Reducing LLM Citation Hallucinations via Legal Citation Graphs
Pith reviewed 2026-06-28 18:35 UTC · model grok-4.3
The pith
A citation graph from 100.8 million Ukrainian court decisions enables CG-DPO fine-tuning to 98.5% accuracy distinguishing correct legal citations from hallucinations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
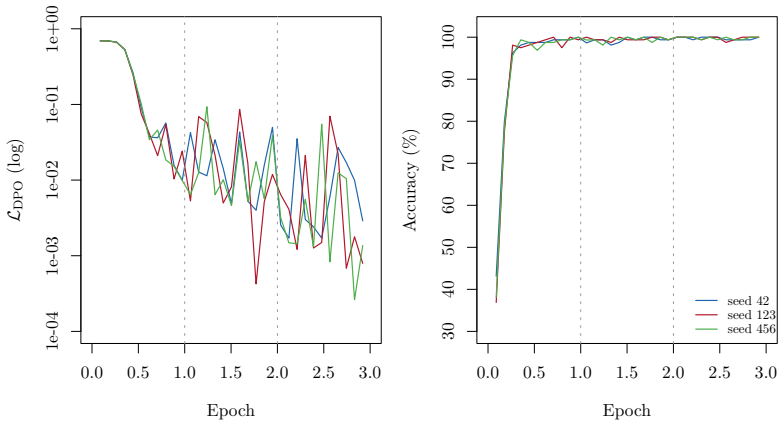
The central claim is that a citation graph extracted from 100.8 million Ukrainian court decisions supplies both a ground-truth verifier for the citation grounding metric and the source material for algorithmically generating preference pairs, allowing CG-DPO to fine-tune models that distinguish correct from corrupted legal citations at 98.5% mean validation accuracy.
What carries the argument
The citation graph of 502 million edges linking 21,736 statute nodes, which supplies verified citations that are corrupted via four targeted strategies to create preference pairs for CG-DPO training.
If this is right
- LLMs can be evaluated automatically for citation quality on any number of legal queries using the three-component CG score.
- Preference data for DPO can be produced at scale from existing court records without manual annotation.
- The separate precision, relevance, and temporality scores allow targeted diagnosis of specific hallucination failure modes.
- Open release of the graph and CG-DPO dataset supports repeated training and benchmarking of citation-aware models.
Where Pith is reading between the lines
- The same graph-construction and corruption approach could be replicated in other jurisdictions that publish structured court data.
- The method may transfer to non-legal domains that maintain reference graphs, such as scientific citations or regulatory documents.
- Pairing CG-DPO with retrieval-augmented generation could produce additive gains in citation reliability.
- Cross-lingual testing on English legal queries would reveal whether the Ukrainian-trained detector generalizes.
Load-bearing premise
The four targeted corruption strategies used to generate negative preference pairs produce examples that are representative of the actual hallucination patterns exhibited by the evaluated LLMs.
What would settle it
Apply the fine-tuned model to a fresh set of citations generated by the same commercial LLMs on the 100 queries and check whether its accuracy remains near 98.5% or aligns with the CG scores computed from the graph.
Figures
read the original abstract
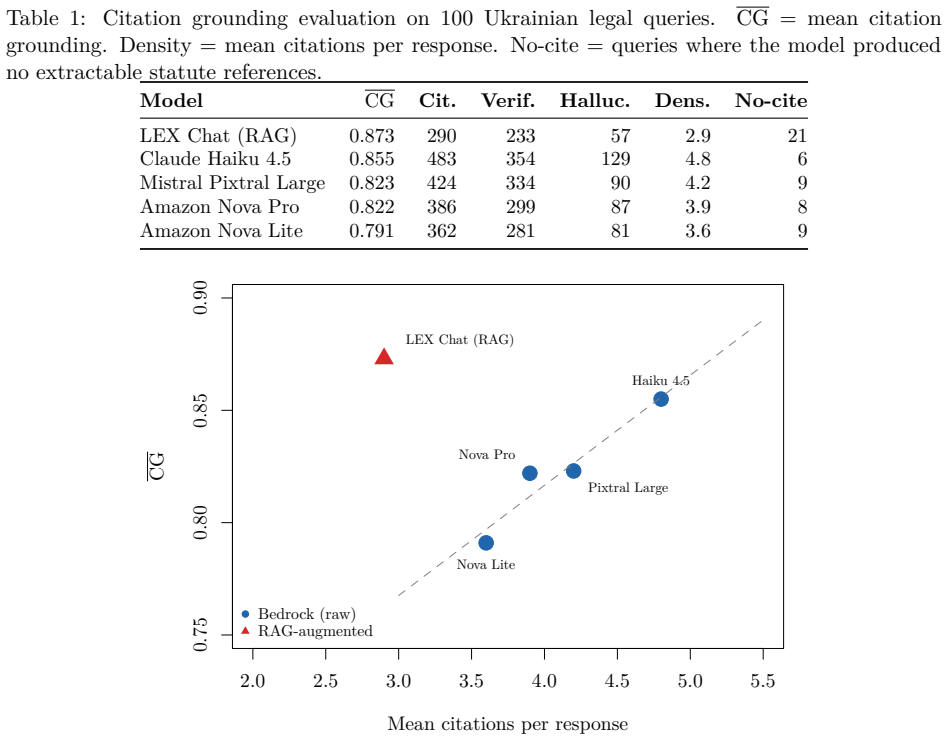
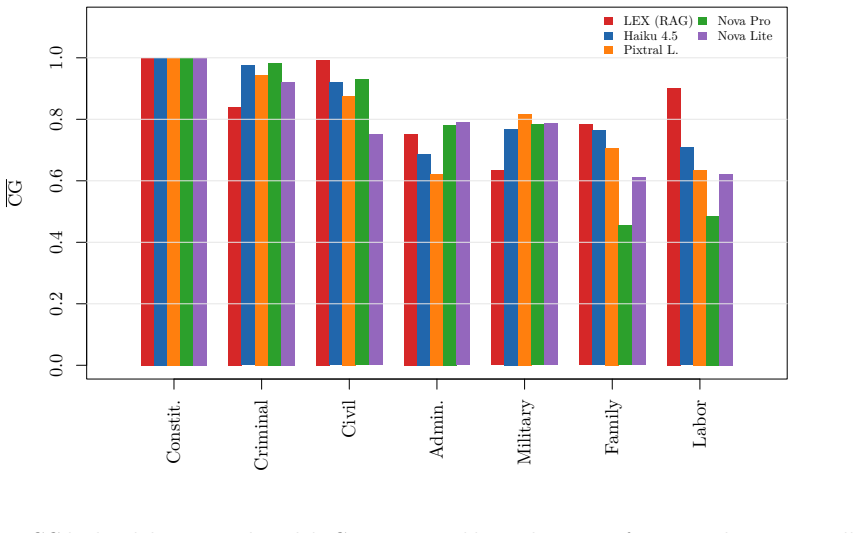
Large language models systematically hallucinate legal citations -- fabricating statute references, citing repealed provisions, and confusing jurisdictions -- yet no automated method exists to measure or reduce this behavior at scale. We propose citation grounding (CG), a metric that verifies LLM-generated legal citations against a ground-truth citation graph extracted from 100.8 million Ukrainian court decisions (502 million edges, 21,736 unique statute nodes). CG decomposes into three components -- citation precision (does the cited provision exist?), citation relevance (is it contextually appropriate?), and citation temporality (was it valid at the relevant date?) -- enabling differential diagnosis of hallucination types. Empirical evaluation on 100 Ukrainian legal queries across five systems -- four commercial LLMs via AWS Bedrock (Claude Haiku 4.5, Mistral Pixtral Large, Amazon Nova Pro/Lite) and one RAG-augmented production system -- reveals CG ranging from 0.791 to 0.873, with 13-21% of citations hallucinated. To reduce hallucinations without human annotation, we introduce Citation Grounding DPO (CG-DPO): a method that constructs preference pairs algorithmically by corrupting verified citations from real court decisions via four targeted strategies. On a dataset of 2,244 court decisions, a Qwen2.5-7B-Instruct model fine-tuned with LoRA achieves 98.5% mean validation accuracy in distinguishing correct from corrupted citations (rewards margin +14.9, std < 0.3 pp across 3 seeds). The citation graph, evaluation framework, and CG-DPO dataset are released as open resources.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that citation hallucinations in LLMs for legal citations can be measured using Citation Grounding (CG), a metric based on a large citation graph from Ukrainian court decisions, revealing 13-21% hallucination rates in five evaluated systems. It further claims that CG-DPO, using synthetic corruptions of real citations with four strategies to create preference pairs, allows fine-tuning a model to distinguish correct from incorrect citations with 98.5% validation accuracy.
Significance. If the synthetic corruption strategies are representative of real LLM hallucination patterns, this work provides a scalable, annotation-free approach to both measuring and mitigating citation hallucinations in legal domains. The release of the citation graph, evaluation framework, and dataset as open resources strengthens the contribution. The concrete empirical results on hallucination rates add value, though the gap between synthetic validation and real-world detection limits immediate impact.
major comments (1)
- [CG-DPO validation (abstract and methods)] The 98.5% mean validation accuracy (rewards margin +14.9, std < 0.3 pp across 3 seeds) for the Qwen2.5-7B-Instruct model is obtained by training and testing on preference pairs generated from the same four targeted corruption strategies applied to verified citations. This does not establish detection capability on the actual hallucination patterns in the five evaluated LLMs on the 100 queries, which may involve different error distributions (e.g., jurisdiction confusion or date-specific validity failures) not among the four strategies.
minor comments (2)
- [Abstract] The abstract reports CG scores from 0.791 to 0.873 and 13-21% hallucinated citations but provides no details on query selection for the 100 Ukrainian legal queries or validation of the citation graph's completeness (502 million edges, 21,736 statute nodes).
- [Evaluation framework] The decomposition of CG into citation precision, relevance, and temporality is described at a high level, but the manuscript does not specify the exact graph-based operationalization or thresholds used for each component in the empirical evaluation.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights an important distinction in our evaluation of CG-DPO. We respond to the major comment below.
read point-by-point responses
-
Referee: The 98.5% mean validation accuracy (rewards margin +14.9, std < 0.3 pp across 3 seeds) for the Qwen2.5-7B-Instruct model is obtained by training and testing on preference pairs generated from the same four targeted corruption strategies applied to verified citations. This does not establish detection capability on the actual hallucination patterns in the five evaluated LLMs on the 100 queries, which may involve different error distributions (e.g., jurisdiction confusion or date-specific validity failures) not among the four strategies.
Authors: We agree that the reported validation accuracy reflects performance on held-out synthetic preference pairs generated from the same four corruption strategies used in training. This setup demonstrates that the model successfully learns to distinguish correct citations from the targeted corruptions in an annotation-free manner, but it does not directly measure generalization to the precise error distributions in the outputs of the five evaluated LLMs. The four strategies were designed to instantiate the three CG components (existence, relevance, temporality) based on hallucination types observed during our initial LLM evaluations; however, we acknowledge that patterns such as jurisdiction confusion may not be fully covered. We will revise the manuscript to explicitly note this limitation in the abstract and methods, clarifying the scope of the CG-DPO results while retaining the claim that the approach provides a scalable starting point for reducing hallucinations. revision: yes
Circularity Check
No significant circularity; external graph and real citations provide independent signal
full rationale
The ground-truth citation graph is extracted from 100.8 million external Ukrainian court decisions (502M edges), independent of the evaluated LLMs or the DPO training. CG-DPO constructs preference pairs by applying four corruption strategies to verified real citations from court decisions; the 98.5% validation accuracy is a standard supervised metric on held-out pairs drawn from the same synthetic distribution. No derivation step reduces by construction to its own inputs, no self-citation chain is load-bearing, and the reported hallucination rates (13-21%) on the five LLMs are computed directly against the external graph. The setup is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The citation graph extracted from 100.8 million Ukrainian court decisions accurately captures valid, temporally scoped statute references.
Reference graph
Works this paper leans on
-
[1]
A mathematical approach to the study of the United States Code.Physica A, 389(19):4195–4200, 2010
Michael J Bommarito and Daniel Martin Katz. A mathematical approach to the study of the United States Code.Physica A, 389(19):4195–4200, 2010
2010
-
[2]
Falkor-IRAC: Graph-Constrained Generation for Verified Legal Reasoning in Indian Judicial AI
Joy Bose. Falkor-IRAC: Graph-constrained generation for verified legal reasoning in Indian judicial AI.arXiv preprint arXiv:2605.14665, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
LexGLUE: A benchmark dataset for legal lan- guage understanding in English
Ilias Chalkidis, Abhik Jana, Dirk Hartung, Michael Bommarito, Ion Androutsopoulos, Daniel Martin Katz, and Nikolaos Aletras. LexGLUE: A benchmark dataset for legal lan- guage understanding in English. InProceedings of ACL, 2022
2022
-
[4]
ChatGPT goes to law school.Journal of Legal Education, 71(3), 2023
Jonathan H Choi, Kristin E Hickman, Amy Monahan, and Daniel Schwarcz. ChatGPT goes to law school.Journal of Legal Education, 71(3), 2023
2023
-
[5]
SaulLM-7B: A pioneering large language model for law.arXiv preprint arXiv:2403.03883, 2024
Pierre Colombo, Telmo Pires, Rui Vieira, et al. SaulLM-7B: A pioneering large language model for law.arXiv preprint arXiv:2403.03883, 2024
-
[6]
Unsupervised cross-lingual representation learning at scale
Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wen- zek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer, and Veselin Stoyanov. Unsupervised cross-lingual representation learning at scale. InProceedings of ACL, 2020
2020
-
[7]
Large legal fictions: Profiling legal hallucinations in large language models.Journal of Legal Analysis, 16(1):64–93, 2024
Matthew Dahl, Varun Magesh, Mirac Suzgun, and Daniel E Ho. Large legal fictions: Profiling legal hallucinations in large language models.Journal of Legal Analysis, 16(1):64–93, 2024
2024
-
[8]
Network analysis and the law: Measuring the legal importance of precedents at the U.S
James H Fowler, Timothy R Johnson, James F Spriggs, Sangick Jeon, and Paul J Wahlbeck. Network analysis and the law: Measuring the legal importance of precedents at the U.S. Supreme Court.Political Analysis, 15(3):324–346, 2007. 1Citation graph:https://huggingface.co/datasets/overthelex/ua-court-citation-graph. Code and data: https://huggingface.co/datase...
2007
-
[9]
Dan Hendrycks, Collin Burns, Anya Chen, and Spencer Ball
Neel Guha, Julian Nyarko, Daniel E Ho, Christopher Ré, Adam Chilton, Alex Nanamori, Nils Holzenberger, et al. LegalBench: A collaboratively built benchmark for measuring le- gal reasoning in large language models. InNeurIPS Datasets and Benchmarks Track, 2023. arXiv:2308.11462
-
[10]
LoRA: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shanan Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InICLR, 2022
2022
-
[11]
GPT-4 passes the bar exam.Philosophical Transactions of the Royal Society A, 382(2270), 2024
Daniel Martin Katz, Michael James Bommarito, Shang Gao, and Pablo Arredondo. GPT-4 passes the bar exam.Philosophical Transactions of the Royal Society A, 382(2270), 2024
2024
-
[12]
Hallucination-free? assessing the reliability of leading AI legal research tools
Varun Magesh, Faiz Surani, Matthew Dahl, Mirac Suzgun, Christopher D Manning, and Daniel E Ho. Hallucination-free? assessing the reliability of leading AI legal research tools. Journal of Empirical Legal Studies, 22:216–242, 2025. arXiv:2405.20362
-
[13]
The network of French legal codes
Pierre Mazzega, Danièle Bourcier, and Romain Boulet. The network of French legal codes. Artificial Intelligence and Law, 17(3), 2009
2009
-
[14]
FActScore: Fine-grained atomic evaluation of factual precision in long form text generation
Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Wei Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. FActScore: Fine-grained atomic evaluation of factual precision in long form text generation. InProceedings of EMNLP, 2023
2023
-
[15]
Emergence of hierarchy in networked endorsement dynam- ics.Proceedings of the National Academy of Sciences, 118(16), 2021
Enys Mones and Adam Arvidsson. Emergence of hierarchy in networked endorsement dynam- ics.Proceedings of the National Academy of Sciences, 118(16), 2021
2021
-
[16]
LEX- TREME: A multi-lingual and multi-task benchmark for the legal domain
Joel Niklaus, Veton Matoshi, Pooja Rani, Andrea Gallucci, and Matthias Stuermer. LEX- TREME: A multi-lingual and multi-task benchmark for the legal domain. InFindings of EMNLP, 2023
2023
-
[17]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. InNeurIPS, 2022
2022
-
[18]
Volodymyr Ovcharov. Automatic construction of a legal citation graph from 100 million Ukrainian court decisions: Large-scale extraction, topological analysis, and ontology-driven clustering.arXiv preprint arXiv:2605.15362, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
PhD thesis, National Academy of Sciences of Ukraine, 2026
Volodymyr V Ovcharov.Methods for Ensuring Verifiability of Large Language Models in the Legal Domain. PhD thesis, National Academy of Sciences of Ukraine, 2026
2026
-
[20]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. InNeurIPS, 2023
2023
-
[21]
Tobias Schimanski, Jingwei Ni, Mathias Kraus, and Markus Leippold. CiteAudit: You cited it, but did you read it? A benchmark for verifying scientific references in the LLM era.arXiv preprint arXiv:2602.23452, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
Here’s what happens when your lawyer uses ChatGPT.The New York Times, May 2023
Benjamin Weiser. Here’s what happens when your lawyer uses ChatGPT.The New York Times, May 2023. 13
2023
-
[23]
Determining authority of dutch case law
Radboud Winkels, Jelle de Ruyter, and Henryk Kroese. Determining authority of dutch case law. InProceedings of JURIX, 2011
2011
-
[24]
An Yang, Baosong Yang, et al. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115, 2024. 14
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.