An Open-Source Benchmark and Baseline for Multi-temporal Referring Segmentation
Pith reviewed 2026-06-28 17:38 UTC · model grok-4.3
The pith
MTRefSeg-R1 outperforms LVLM baselines on multi-temporal referring segmentation by pre-training on vision-only changes then fine-tuning on language-guided masks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
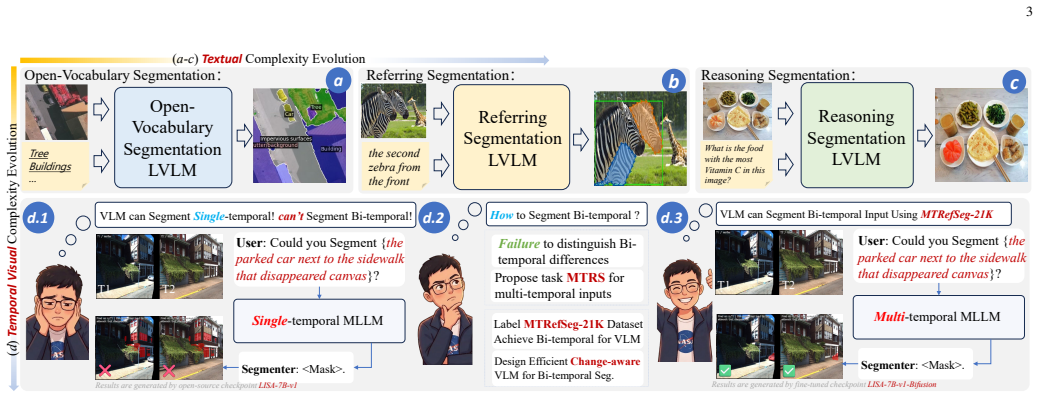
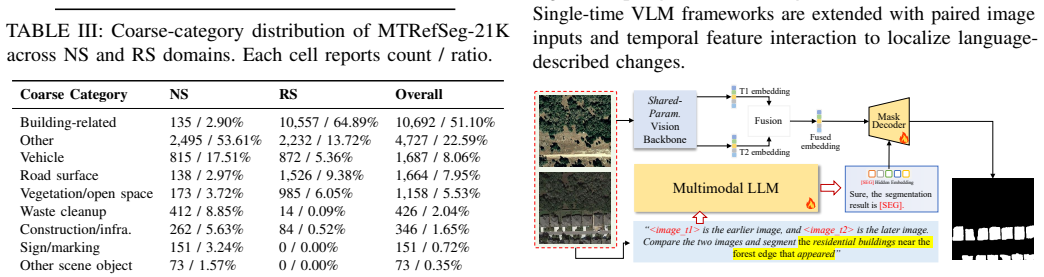
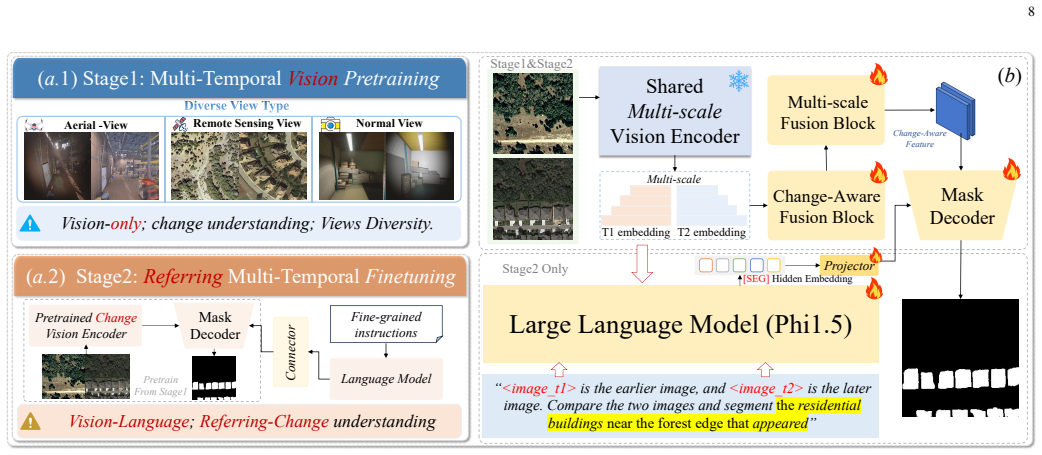
MTRefSeg-R1 explicitly models cross-temporal visual differences, aligns language instructions with temporal variations, and predicts referred change masks. It achieves this after first learning general temporal-change perception from 20K vision-only bi-temporal samples and then fine-tuning on the MTRefSeg-21K benchmark, yielding strong and often superior performance compared with existing LVLM baselines on the new task.
What carries the argument
MTRefSeg-R1's two-stage training strategy that pre-trains general temporal-change perception on vision-only bi-temporal data before language-guided fine-tuning for mask prediction.
If this is right
- Direct inference performs poorly on MTRS while task-specific fine-tuning alone remains limited.
- Pre-training on vision-only bi-temporal samples improves subsequent language-guided temporal localization.
- The benchmark exposes the joint difficulty of temporal correspondence, language grounding, and mask prediction.
- Explicit cross-temporal difference modeling enables referred change mask prediction where baselines fall short.
Where Pith is reading between the lines
- The CRAFT-Agent construction method could generate data for longer-sequence or multi-view change tasks.
- Improved temporal reasoning in LVLMs may support applications such as monitoring land-use changes from satellite pairs.
- Success on this task suggests that staged training separating perception from language alignment could apply to other dynamic visual reasoning problems.
Load-bearing premise
The CRAFT-Agent pipeline with human auditing produces multi-temporal triplets whose language descriptions match genuine visual changes rather than generation artifacts.
What would settle it
Human audit of a random sample from MTRefSeg-21K reveals that more than 10 percent of language descriptions fail to correspond to actual visual differences, or ablation removing the 20K vision-only pre-training stage eliminates MTRefSeg-R1's performance advantage.
Figures





read the original abstract
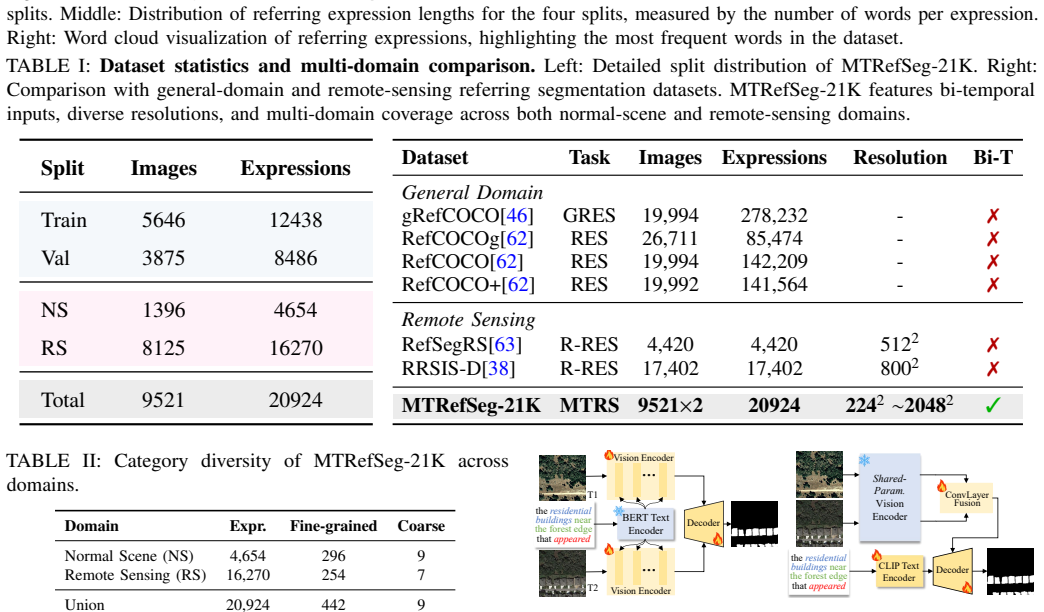
Large Vision-Language Models (LVLMs) have shown strong visual understanding and language-guided grounding abilities, yet their capacity for multi-temporal visual reasoning remains underexplored. To bridge this gap, we introduce \textbf{Multi-temporal Referring Segmentation (MTRS)}, a new task that aims to segment language-described temporal changes from multi-temporal images. MTRS extends conventional referring segmentation and change detection by jointly requiring temporal correspondence reasoning, language grounding, and pixel-level mask prediction. We propose \textbf{CRAFT-Agent}, an automated data construction pipeline with human auditing, and build \textbf{MTRefSeg-21K}, the first MTRS benchmark, containing 21K high-quality multi-temporal image-text-mask triplets across diverse scenes, viewpoints, and domains. Benchmarking a broad set of VLM- and LVLM-based models reveals that direct inference performs poorly, while task-specific fine-tuning remains limited. To address this, we propose \textbf{MTRefSeg-R1}, a change-aware LVLM framework trained with a two-stage strategy. It first learns general temporal-change perception from 20K vision-only bi-temporal samples, and is then fine-tuned on MTRefSeg-21K for fine-grained language-guided temporal localization. MTRefSeg-R1 explicitly models cross-temporal visual differences, aligns language instructions with temporal variations, and predicts referred change masks. Extensive experiments show that MTRefSeg-R1 achieves strong and often superior performance compared with existing LVLM baselines, demonstrating the challenge and potential of MTRS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Multi-temporal Referring Segmentation (MTRS) task, which requires jointly performing temporal correspondence reasoning, language grounding, and pixel-level mask prediction on multi-temporal images. It presents CRAFT-Agent, an automated data construction pipeline with human auditing, to build the MTRefSeg-21K benchmark of 21K image-text-mask triplets. It further proposes MTRefSeg-R1, a change-aware LVLM trained in two stages (first on 20K vision-only bi-temporal samples for general temporal-change perception, then fine-tuned on MTRefSeg-21K), and claims that MTRefSeg-R1 achieves strong and often superior performance relative to existing LVLM baselines.
Significance. If the benchmark triplets are shown to contain language descriptions that accurately and independently reflect genuine visual changes (rather than pipeline artifacts), the work would be significant for establishing the first dedicated benchmark and open-source baseline for MTRS. The explicit cross-temporal difference modeling and two-stage training strategy represent concrete technical contributions that could be built upon. The open-source release of the benchmark and code is a clear strength that supports reproducibility and further research in multi-temporal visual reasoning.
major comments (2)
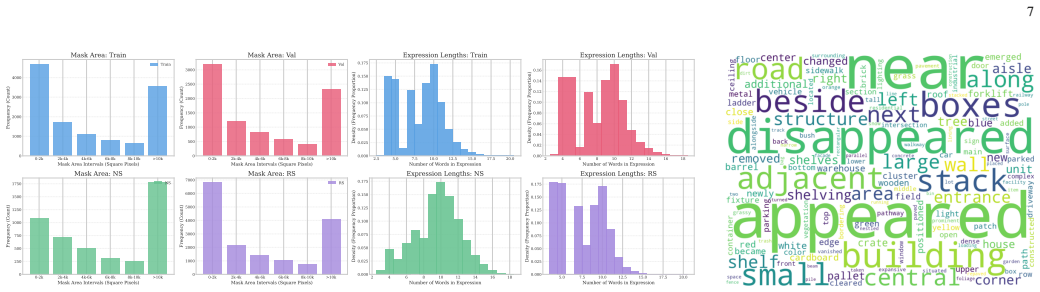
- [Benchmark construction (abstract and §3)] Benchmark construction (abstract and §3): The validity of all performance claims for MTRefSeg-R1 on MTRefSeg-21K depends on the triplets accurately reflecting genuine temporal differences. The description of human auditing provides no quantitative details such as rejection rates, inter-auditor agreement, or any post-audit verification that language descriptions match pixel-level evidence independently of CRAFT-Agent generation biases. This is load-bearing for the central claim.
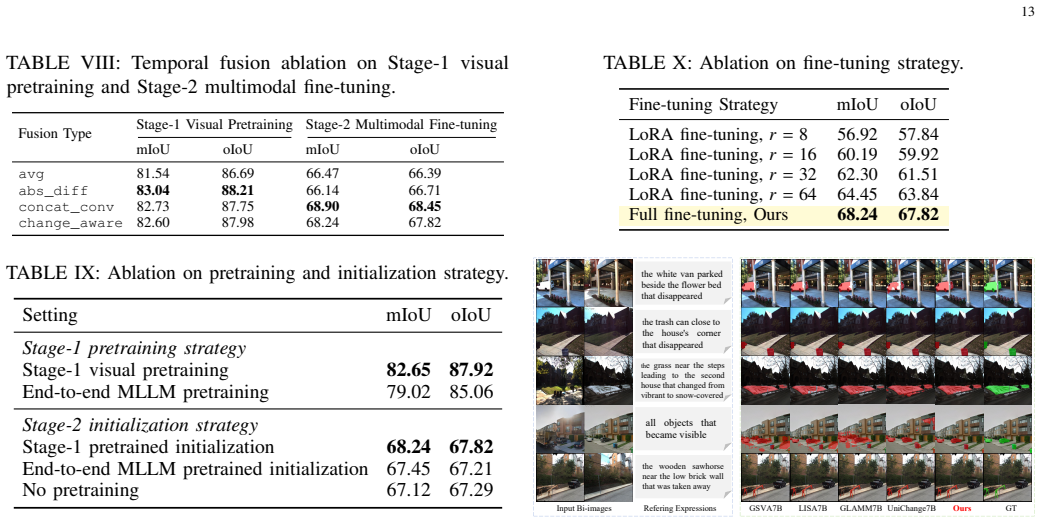
- [§5 (Experiments)] §5 (Experiments): The abstract asserts that direct inference performs poorly while MTRefSeg-R1 is superior, yet supplies no quantitative metrics, error bars, specific baseline implementations, or ablation results on the contribution of the two-stage training. Without these, the superiority claim cannot be evaluated for robustness.
minor comments (1)
- [Abstract] Abstract: Including one or two key quantitative results (e.g., mIoU deltas versus the strongest baseline) would strengthen the summary of findings.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that strengthen the manuscript's claims regarding benchmark validity and experimental robustness.
read point-by-point responses
-
Referee: [Benchmark construction (abstract and §3)] Benchmark construction (abstract and §3): The validity of all performance claims for MTRefSeg-R1 on MTRefSeg-21K depends on the triplets accurately reflecting genuine temporal differences. The description of human auditing provides no quantitative details such as rejection rates, inter-auditor agreement, or any post-audit verification that language descriptions match pixel-level evidence independently of CRAFT-Agent generation biases. This is load-bearing for the central claim.
Authors: We agree that quantitative auditing statistics are essential to substantiate the benchmark's quality and independence from pipeline artifacts. In the revised manuscript, we will add rejection rates from the human auditing stage, inter-auditor agreement metrics (e.g., Cohen's kappa), and post-audit verification procedures confirming that language descriptions align with pixel-level changes. These additions will directly address the load-bearing concern for the central claims. revision: yes
-
Referee: [§5 (Experiments)] §5 (Experiments): The abstract asserts that direct inference performs poorly while MTRefSeg-R1 is superior, yet supplies no quantitative metrics, error bars, specific baseline implementations, or ablation results on the contribution of the two-stage training. Without these, the superiority claim cannot be evaluated for robustness.
Authors: Section 5 of the manuscript already reports quantitative performance metrics across multiple LVLM baselines on MTRefSeg-21K, showing MTRefSeg-R1's advantages. However, we acknowledge the absence of error bars, explicit baseline implementation details, and ablations isolating the two-stage training. In the revision, we will incorporate error bars from repeated runs, clarify baseline setups, and add an ablation study on the two-stage strategy to enable rigorous evaluation of the superiority claims. revision: yes
Circularity Check
No circularity: benchmark construction and model evaluation are independent of self-referential fits or definitions.
full rationale
The paper introduces a new task and benchmark (MTRefSeg-21K) via the CRAFT-Agent pipeline plus human auditing, then trains MTRefSeg-R1 in two stages on a separate 20K vision-only set before fine-tuning and comparing performance to external LVLM baselines. No equations, predictions, or central claims reduce by construction to author-defined inputs or self-citations; all reported results are empirical comparisons on the new data against independent models. This is a standard benchmark-plus-baseline paper with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Standard assumptions of deep learning optimization (gradient descent reaches useful minima on non-convex loss surfaces) and i.i.d. sampling of training examples
- domain assumption Human auditing of CRAFT-Agent outputs removes generation artifacts and yields faithful language-to-change correspondences
Reference graph
Works this paper leans on
-
[1]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat et al., “Gpt-4 technical report,” arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv et al., “Qwen3 technical report,” arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
J. Bai, S. Bai, Y . Chu, Z. Cui, K. Dang, X. Deng, Y . Fan, W. Ge, Y . Han, F. Huang et al., “Qwen technical report,” arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
F- lmm: Grounding frozen large multimodal models,
S. Wu, S. Jin, W. Zhang, L. Xu, W. Liu, W. Li, and C. C. Loy, “F- lmm: Grounding frozen large multimodal models,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025, pp. 24 710–24 721
2025
-
[5]
Uwbench: A comprehensive vision-language benchmark for underwater understanding,
D. Zhang, C. Rong, B. Li, F. Wang, Z. Zhao, J. Gao, and X. Li, “Uwbench: A comprehensive vision-language benchmark for underwater understanding,” arXiv preprint arXiv:2510.18262, 2025
-
[6]
Lisa: Reasoning segmentation via large language model,
X. Lai, Z. Tian, Y . Chen, Y . Li, Y . Yuan, S. Liu, and J. Jia, “Lisa: Reasoning segmentation via large language model,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 9579–9589
2024
-
[7]
Remotesam: Towards segment anything for earth observation,
L. Yao, F. Liu, D. Chen, C. Zhang, Y . Wang, Z. Chen, W. Xu, S. Di, and Y . Zheng, “Remotesam: Towards segment anything for earth observation,” in Proceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 3027–3036
2025
-
[8]
Videoglamm: A large multimodal model for pixel-level visual grounding in videos,
S. Munasinghe, H. Gani, W. Zhu, J. Cao, E. Xing, F. S. Khan, and S. Khan, “Videoglamm: A large multimodal model for pixel-level visual grounding in videos,” in Proceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 19 036–19 046
2025
-
[9]
Glamm: Pixel grounding large multimodal model,
H. Rasheed, M. Maaz, S. Shaji, A. Shaker, S. Khan, H. Cholakkal, R. M. Anwer, E. Xing, M.-H. Yang, and F. S. Khan, “Glamm: Pixel grounding large multimodal model,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 13 009–13 018
2024
-
[10]
Ai flow: Perspectives, scenarios, and approaches,
H. An, W. Hu, S. Huang, S. Huang, R. Li, Y . Liang, J. Shao, Y . Song, Z. Wang, C. Yuanet al., “Ai flow: Perspectives, scenarios, and approaches,” Vicinagearth, vol. 3, no. 1, p. 1, 2026
2026
-
[11]
arXiv preprint arXiv:2512.05107 , year=
F. Xu, G. Zhai, X. Kong, T. Fu, D. F. Gordon, X. An, and B. Busam, “Stare-vla: Progressive stage-aware reinforcement for fine-tuning vision- language-action models,” arXiv preprint arXiv:2512.05107, 2025
-
[12]
Fine-grained preference optimization improves spatial reasoning in vlms,
Y . Shen, Y . Liu, J. Zhu, X. Cao, X. Zhang, Y . He, W. Ye, J. M. Rehg, and I. Lourentzou, “Fine-grained preference optimization improves spatial reasoning in vlms,” arXiv preprint arXiv:2506.21656, 2025
-
[13]
Toward cognitive supersensing in multimodal large language model,
B. Li, Y . Shen, Y . Liu, Y . Xu, J. Liu, X. Li, Z. Li, J. Zhu, Y . Zhong, F. Lan et al., “Toward cognitive supersensing in multimodal large language model,” arXiv preprint arXiv:2602.01541, 2026
-
[14]
Egoforge: Goal-directed egocentric world simulator,
Y . Shen, J. Liu, X. Li, Y . Liu, B. Li, H. Yang, W. Jia, Y . Li, T. Yu, J. M. Rehg et al., “Egoforge: Goal-directed egocentric world simulator,” arXiv preprint arXiv:2603.20169, 2026
-
[15]
A. Sarkar, M. Y . I. Idris, and Z. Yu, “Reasoning in computer vi- sion: Taxonomy, models, tasks, and methodologies,” arXiv preprint arXiv:2508.10523, 2025
-
[16]
Towards transparent ai: A survey on explainable large language models,
A. Palikhe, Z. Yu, Z. Wang, and W. Zhang, “Towards transparent ai: A survey on explainable large language models,” arXiv preprint arXiv:2506.21812, 2025
-
[17]
Yielding unblemished aesthetics through a unified network for visual imperfections removal in generated images,
Z. Yu and C. S. Chan, “Yielding unblemished aesthetics through a unified network for visual imperfections removal in generated images,” AAAI 2025, vol. 39, no. 9, pp. 9716–9724, 2025
2025
-
[18]
Cotextor: Training- free modular multilingual text editing via layered disentanglement and depth-aware fusion,
Z. Yu, M. Y . I. IDRIS, P. Wang, and R. Qureshi, “Cotextor: Training- free modular multilingual text editing via layered disentanglement and depth-aware fusion,” in NeurIPS 2025, 2025
2025
-
[19]
Forgetme: Benchmarking the selective forgetting capabilities of generative models,
Z. Yu, M. Y . I. Idris, P. Wang, Y . Xia, and Y . Xiang, “Forgetme: Benchmarking the selective forgetting capabilities of generative models,” EAAI, vol. 161, p. 112087, 2025
2025
-
[20]
Tri- subspaces disentanglement for multimodal sentiment analysis,
C. Meng, J. Luo, Z. Yan, Z. Yu, R. Fu, Z. Gan, and C. Ouyang, “Tri- subspaces disentanglement for multimodal sentiment analysis,” CVPR 2026, 2026
2026
-
[21]
Generative video compression: towards 0.01% compression rate for video transmission,
X. Chen, J. Luo, J. Xu, F. Yi, C. Zhang, and X. Li, “Generative video compression: towards 0.01% compression rate for video transmission,” Vicinagearth, vol. 3, no. 1, p. 7, 2026
2026
-
[22]
Geobench-vlm: Benchmarking vision-language models for geospatial tasks,
M. Danish, M. A. Munir, S. R. A. Shah, K. Kuckreja, F. S. Khan, P. Fraccaro, A. Lacoste, and S. Khan, “Geobench-vlm: Benchmarking vision-language models for geospatial tasks,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 7132–7142
2025
-
[23]
Geomag: A vision-language model for pixel-level fine-grained remote sensing image parsing,
X. Ma, J. Li, C. Pei, and H. Liu, “Geomag: A vision-language model for pixel-level fine-grained remote sensing image parsing,” in Proceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 5441–5450
2025
-
[24]
Geopixel: Pixel grounding large multimodal model in remote sensing,
A. Shabbir, M. Zumri, M. Bennamoun, F. S. Khan, and S. Khan, “Geopixel: Pixel grounding large multimodal model in remote sensing,” arXiv preprint arXiv:2501.13925, 2025
-
[25]
Dinov3-powered multi- task foundation model for quantitative remote sensing estimation,
Z. Yu, M. Y . I. Idris, P. Wang, and R. Qureshi, “Dinov3-powered multi- task foundation model for quantitative remote sensing estimation,” AAAI 2026, vol. 40, no. 48, pp. 41 455–41 456, 2026
2026
-
[26]
Visualizing our changing earth: A creative ai framework for democratizing environmental storytelling through satellite imagery,
Z. Yu, M. Y . I. Idris, and P. Wang, “Visualizing our changing earth: A creative ai framework for democratizing environmental storytelling through satellite imagery,” in NeurIPS 2025, 2025
2025
-
[27]
Spatiotemporal alignment for remote sensing image recovery via terrain-aware diffusion,
Z. Yu, H. Jiang, P. Wang, Z. Lin, and Y . Xiang, “Spatiotemporal alignment for remote sensing image recovery via terrain-aware diffusion,” ICASSP 2026, 2026
2026
-
[28]
B. Li, F. Wang, D. Zhang, Z. Zhao, J. Gao, and X. Li, “Maris: Marine open-vocabulary instance segmentation with geometric enhancement and semantic alignment,” arXiv preprint arXiv:2510.15398, 2025
-
[29]
Convolutions die hard: Open-vocabulary segmentation with single frozen convolutional clip,
Q. Yu, J. He, X. Deng, X. Shen, and L.-C. Chen, “Convolutions die hard: Open-vocabulary segmentation with single frozen convolutional clip,” Advances in Neural Information Processing Systems, vol. 36, pp. 32 215–32 234, 2023
2023
-
[30]
Diffusion models for open-vocabulary segmentation,
L. Karazija, I. Laina, A. Vedaldi, and C. Rupprecht, “Diffusion models for open-vocabulary segmentation,” in European Conference on Computer Vision. Springer, 2024, pp. 299–317
2024
-
[31]
Cat- seg: Cost aggregation for open-vocabulary semantic segmentation,
S. Cho, H. Shin, S. Hong, A. Arnab, P. H. Seo, and S. Kim, “Cat- seg: Cost aggregation for open-vocabulary semantic segmentation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 4113–4123
2024
-
[32]
Exploring the underwater world segmentation without extra training,
B. Li, T. Huo, D. Zhang, Z. Zhao, J. Gao, and X. Li, “Exploring the underwater world segmentation without extra training,” arXiv preprint arXiv:2511.07923, 2025
-
[33]
Exploring efficient open-vocabulary segmentation in the remote sensing,
B. Li, H. Dong, D. Zhang, Z. Zhao, J. Gao, and X. Li, “Exploring efficient open-vocabulary segmentation in the remote sensing,” arXiv preprint arXiv:2509.12040, 2025
-
[34]
A simple framework for open-vocabulary segmentation and detection,
H. Zhang, F. Li, X. Zou, S. Liu, C. Li, J. Yang, and L. Zhang, “A simple framework for open-vocabulary segmentation and detection,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 1020–1031
2023
-
[35]
Open-vocabulary universal image segmentation with maskclip,
Z. Ding, J. Wang, and Z. Tu, “Open-vocabulary universal image segmentation with maskclip,” arXiv preprint arXiv:2208.08984, 2022
-
[36]
Polyformer: Referring image segmentation as sequential polygon generation,
J. Liu, H. Ding, Z. Cai, Y . Zhang, R. K. Satzoda, V . Mahadevan, and R. Manmatha, “Polyformer: Referring image segmentation as sequential polygon generation,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 18 653–18 663
2023
-
[37]
Toward robust referring image segmentation,
J. Wu, X. Li, X. Li, H. Ding, Y . Tong, and D. Tao, “Toward robust referring image segmentation,” IEEE Transactions on Image Processing, vol. 33, pp. 1782–1794, 2024
2024
-
[38]
Rotated multi-scale interaction network for referring remote sensing image seg- mentation,
S. Liu, Y . Ma, X. Zhang, H. Wang, J. Ji, X. Sun, and R. Ji, “Rotated multi-scale interaction network for referring remote sensing image seg- mentation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 26 658–26 668
2024
-
[39]
Lqmformer: Language-aware query mask transformer for referring image segmentation,
N. A. Shah, V . VS, and V . M. Patel, “Lqmformer: Language-aware query mask transformer for referring image segmentation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 12 903–12 913
2024
-
[40]
A survey of language-guided video object segmentation: from referring to reasoning,
Y . Shen and D. Zhang, “A survey of language-guided video object segmentation: from referring to reasoning,” Vicinagearth, vol. 2, no. 1, pp. 1–20, 2025. 16
2025
-
[41]
Adaptive selection based referring image segmentation,
P. Yue, J. Lin, S. Zhang, J. Hu, Y . Lu, H. Niu, H. Ding, Y . Zhang, G. Jiang, L. Cao et al., “Adaptive selection based referring image segmentation,” in Proceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 1101–1110
2024
-
[42]
Rsrefseg: Refer- ring remote sensing image segmentation with foundation models,
K. Chen, J. Zhang, C. Liu, Z. Zou, and Z. Shi, “Rsrefseg: Refer- ring remote sensing image segmentation with foundation models,” in IGARSS 2025-2025 IEEE International Geoscience and Remote Sensing Symposium. IEEE, 2025, pp. 1070–1074
2025
-
[43]
Referring remote sensing image segmentation with cross-view semantics interaction network,
J. Yang, L. Zhang, and H. Lu, “Referring remote sensing image segmentation with cross-view semantics interaction network,” arXiv preprint arXiv:2508.01331, 2025
-
[44]
Deris: Decoupling perception and cognition for enhanced referring image segmentation through loopback synergy,
M. Dai, W. Cheng, J.-j. Liu, S. Yang, W. Cai, Y . Sun, and W. Yang, “Deris: Decoupling perception and cognition for enhanced referring image segmentation through loopback synergy,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 19 936–19 946
2025
-
[45]
Lavt: Language-aware vision transformer for referring image segmentation,
Z. Yang, J. Wang, Y . Tang, K. Chen, H. Zhao, and P. H. Torr, “Lavt: Language-aware vision transformer for referring image segmentation,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 18 155–18 165
2022
-
[46]
Gres: Generalized referring expression segmentation,
C. Liu, H. Ding, and X. Jiang, “Gres: Generalized referring expression segmentation,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 23 592–23 601
2023
-
[47]
Mask grounding for referring image segmentation,
Y . X. Chng, H. Zheng, Y . Han, X. Qiu, and G. Huang, “Mask grounding for referring image segmentation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 26 573–26 583
2024
-
[48]
Segllm: Multi-round reasoning segmentation,
X. Wang, S. Zhang, S. Li, K. Kallidromitis, K. Li, Y . Kato, K. Kozuka, and T. Darrell, “Segllm: Multi-round reasoning segmentation,” arXiv preprint arXiv:2410.18923, 2024
-
[49]
Reasoning segmentation for images and videos: A survey,
Y . Shen, C. Li, F. Xiong, J.-O. Jeong, T. Wang, M. Latman, and M. Unberath, “Reasoning segmentation for images and videos: A survey,” arXiv preprint arXiv:2505.18816, 2025
-
[50]
Seg-Zero: Reasoning-Chain Guided Segmentation via Cognitive Reinforcement
Y . Liu, B. Peng, Z. Zhong, Z. Yue, F. Lu, B. Yu, and J. Jia, “Seg-zero: Reasoning-chain guided segmentation via cognitive reinforcement,” arXiv preprint arXiv:2503.06520, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Lisa++: An improved baseline for reasoning segmentation with large language model,
S. Yang, T. Qu, X. Lai, Z. Tian, B. Peng, S. Liu, and J. Jia, “Lisa++: An improved baseline for reasoning segmentation with large language model,” arXiv preprint arXiv:2312.17240, 2023
-
[52]
Dataset on underwater change detection,
M. Radolko, F. Farhadifard, and U. F. von Lukas, “Dataset on underwater change detection,” in OCEANS 2016 MTS/IEEE Monterey. IEEE, 2016, pp. 1–8
2016
-
[53]
Mds- net: An image-text enhanced multimodal dual-branch siamese network for remote sensing change detection,
T. Wang, T. Bai, C. Xu, E. Zhang, B. Liu, X. Zhao, and H. Zhang, “Mds- net: An image-text enhanced multimodal dual-branch siamese network for remote sensing change detection,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2025
2025
-
[54]
Qrs-trs: Style transfer-based image-to-image translation for carbon stock estimation in quantitative remote sensing,
Z. Yu, J. Wang, H. Chen, and M. Y . I. Idris, “Qrs-trs: Style transfer-based image-to-image translation for carbon stock estimation in quantitative remote sensing,” IEEE Access, 2025
2025
-
[55]
Dynamicearth: How far are we from open-vocabulary change detection?
K. Li, X. Cao, Y . Deng, C. Pang, Z. Xin, D. Meng, and Z. Wang, “Dynamicearth: How far are we from open-vocabulary change detection?” arXiv preprint arXiv:2501.12931, 2025
-
[56]
Semantic-cd: Remote sensing image semantic change detection towards open-vocabulary setting,
Y . Zhu, L. Li, K. Chen, C. Liu, F. Zhou, and Z. Shi, “Semantic-cd: Remote sensing image semantic change detection towards open-vocabulary setting,” in IGARSS 2025-2025 IEEE International Geoscience and Remote Sensing Symposium. IEEE, 2025, pp. 6388–6392
2025
-
[57]
Unichange: Unifying change detection with multimodal large language model,
X. Zhang, D. Li, X. Dong, T. Wu, H. Yu, J. Wang, Q. Li, and X. Li, “Unichange: Unifying change detection with multimodal large language model,” arXiv preprint arXiv:2511.02607, 2025
-
[58]
Referring change detection in remote sensing imagery,
Y . Korkmaz, J. N. Paranjape, C. M. de Melo, and V . M. Patel, “Referring change detection in remote sensing imagery,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2026, pp. 106–116
2026
-
[59]
Changechat: An interactive model for remote sensing change analysis via multimodal instruction tuning,
P. Deng, W. Zhou, and H. Wu, “Changechat: An interactive model for remote sensing change analysis via multimodal instruction tuning,” in ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[60]
Segchange-r1: Llm-augmented remote sensing change detec- tion,
F. Zhou, “Segchange-r1: Llm-augmented remote sensing change detec- tion,” arXiv preprint arXiv:2506.17944, 2025
-
[61]
X. Lu, J. Yuan, R. Niu, Y . Hu, and F. Wang, “Viewpoint integration and registration with vision language foundation model for image change understanding,” arXiv preprint arXiv:2309.08585, 2023
-
[62]
Modeling context in referring expressions,
L. Yu, P. Poirson, S. Yang, A. C. Berg, and T. L. Berg, “Modeling context in referring expressions,” in European conference on computer vision. Springer, 2016, pp. 69–85
2016
-
[63]
Rrsis: Referring remote sensing image segmentation,
Z. Yuan, L. Mou, Y . Hua, and X. X. Zhu, “Rrsis: Referring remote sensing image segmentation,” IEEE Transactions on Geoscience and Remote Sensing, vol. 62, pp. 1–12, 2024
2024
-
[64]
Bert: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” in Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), 2019, pp. 4171–4186
2019
-
[65]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark et al., “Learning transferable visual models from natural language supervision,” in International conference on machine learning. PMLR, 2021, pp. 8748–8763
2021
-
[66]
Cris: Clip- driven referring image segmentation,
Z. Wang, Y . Lu, Q. Li, X. Tao, Y . Guo, M. Gong, and T. Liu, “Cris: Clip- driven referring image segmentation,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 11 686– 11 695
2022
-
[67]
Exploring fine-grained image-text alignment for referring remote sensing image segmentation,
S. Lei, X. Xiao, T. Zhang, H.-C. Li, Z. Shi, and Q. Zhu, “Exploring fine-grained image-text alignment for referring remote sensing image segmentation,” IEEE Transactions on Geoscience and Remote Sensing, 2024
2024
-
[68]
Gsva: Generalized segmentation via multimodal large language models,
Z. Xia, D. Han, Y . Han, X. Pan, S. Song, and G. Huang, “Gsva: Generalized segmentation via multimodal large language models,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 3858–3869
2024
-
[69]
UniGeoSeg: Towards Unified Open-World Segmentation for Geospatial Scenes
S. Ni, D. Wang, H. Chen, H. Guo, N. Zhang, and J. Zhang, “Unigeoseg: Towards unified open-world segmentation for geospatial scenes,” arXiv preprint arXiv:2511.23332, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[70]
Segearth-r1: Geospatial pixel reasoning via large language model,
K. Li, Z. Xin, L. Pang, C. Pang, Y . Deng, J. Yao, G. Xia, D. Meng, Z. Wang, and X. Cao, “Segearth-r1: Geospatial pixel reasoning via large language model,” arXiv preprint arXiv:2504.09644, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.