DSL-LLaDA: Scaling Continuous Denoising to 8B Masked Diffusion LMs
Pith reviewed 2026-06-28 17:37 UTC · model grok-4.3
The pith
A pretrained 8B masked diffusion language model can be lightly adapted in 1000 steps to support continuous embedding-space denoising that avoids the length-quality tradeoff of few-step decoding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
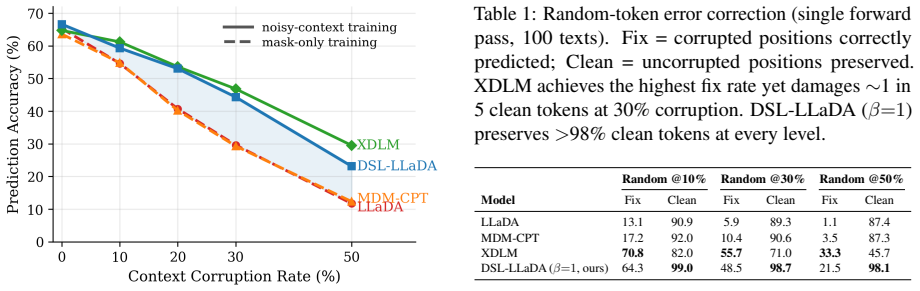
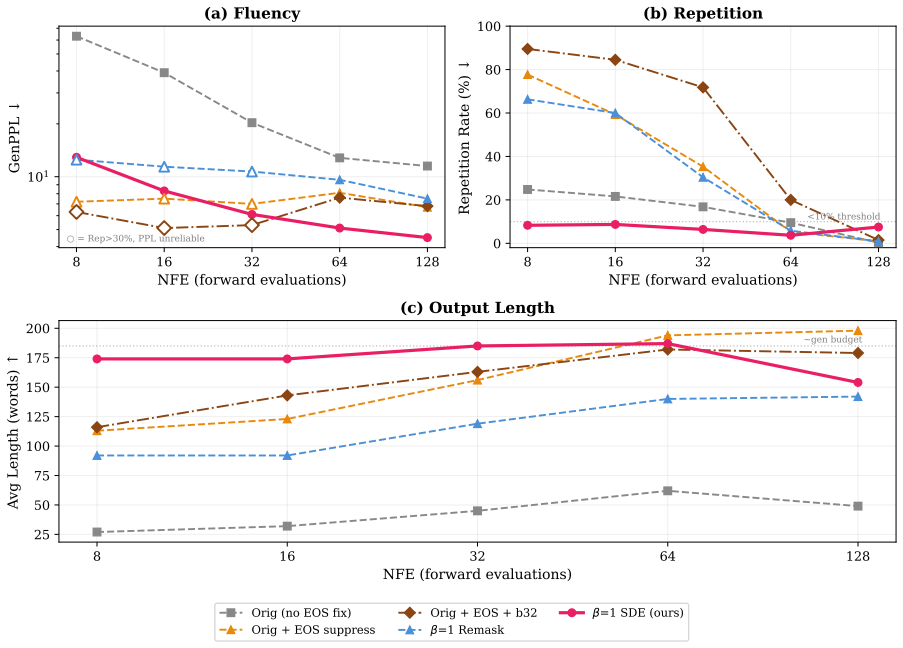
Starting from LLaDA-8B-Instruct, continue-pretraining for only 1000 steps with Discrete Stochastic Localization replaces binary masking with continuous per-token Gaussian noise as a soft mask. The resulting model supports continuous inference that evolves all positions jointly in embedding space and defers hard token commitment to the final step. On zero-shot summarization at low step budgets it achieves the best ROUGE-1 scores on all four benchmarks and largely avoids the premature-termination/repetition tradeoff of iterative unmasking; it also exhibits selective noisy-state robustness. Standard masked diffusion training with equivalent compute produces neither outcome.
What carries the argument
Discrete Stochastic Localization (DSL), which substitutes continuous per-token Gaussian noise for binary masks during the 1000-step adaptation to enable joint evolution of all token embeddings.
If this is right
- Continuous inference evolves all token positions jointly rather than unmasking them one step at a time.
- At step budgets of 16 or fewer the model records the highest ROUGE-1 on every tested summarization benchmark.
- The length-quality tradeoff of standard iterative unmasking is largely avoided.
- The model selectively corrects noisy tokens while leaving clean tokens unchanged.
- Neither continuous denoising nor selective robustness appears when the same compute is spent on standard masked diffusion training.
Where Pith is reading between the lines
- The same short adaptation recipe could be applied to other large pretrained masked diffusion models to test whether continuous denoising emerges at different scales.
- Selective noise robustness might improve performance on downstream tasks that involve noisy or partially corrupted inputs.
- If the continuous path generalizes, future work could explore whether the final hard-commitment step can be replaced by a learned projection without harming quality.
Load-bearing premise
That 1000 steps of continued pretraining with continuous Gaussian noise suffice to unlock effective continuous embedding-space denoising and selective robustness without full retraining or loss of core capabilities.
What would settle it
If the 1000-step adapted model still exhibits the same length-quality tradeoff on the four summarization benchmarks or fails to correct corrupted tokens while preserving clean ones, the central claim would not hold.
Figures

read the original abstract
Discrete Masked diffusion language models generate text by iterative parallel decoding, but few-step decoding suffers from a tradeoff between length and quality: with a fixed step budget, standard methods can generate a short, high-quality output, or they can produce long but repetitive text. Continuous denoising can sidestep this tradeoff by evolving all positions jointly in embedding space, but building such a model from scratch at scale remains an open problem. We show that a pretrained masked DLM can instead be lightly adapted to support continuous embedding-space denoising. Starting from LLaDA-8B-Instruct, we continue-pretrain for only 1,000 steps with Discrete Stochastic Localization (DSL), replacing binary masking with continuous per-token Gaussian noise as a soft mask. The adapted model supports continuous inference that evolves all positions jointly in embedding space and defers hard token commitment to the final step. On zero-shot summarization at low step budgets (<=16 forward passes), DSL-LLaDA-SDE achieves the best ROUGE-1 on all four benchmarks and largely avoids the premature-termination / repetition tradeoff of iterative unmasking. The same adaptation also yields selective noisy-state robustness: the model corrects corrupted tokens while preserving clean ones. Control experiments using standard masked diffusion training with the same compute demonstrate neither behavior.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DSL-LLaDA, which adapts the LLaDA-8B-Instruct masked diffusion LM using 1,000 steps of Discrete Stochastic Localization (DSL). This replaces binary masking with continuous per-token Gaussian noise as a soft mask during continued pretraining. The resulting model enables continuous inference in embedding space, deferring token commitment to the end. It demonstrates superior zero-shot summarization performance on four benchmarks at low step budgets (<=16 forward passes) using DSL-LLaDA-SDE, avoiding the length-quality tradeoff of standard iterative unmasking, and shows robustness to noisy states by correcting corrupted tokens while preserving clean ones. Control experiments with standard masked diffusion training at the same compute budget do not exhibit these properties.
Significance. If the empirical results hold, this work provides an efficient method to scale continuous denoising to 8B-parameter masked diffusion models without full retraining from scratch. The short adaptation period and explicit control experiments are strengths, as they attribute the benefits specifically to the DSL approach rather than additional compute. This could advance the field by offering a practical way to achieve joint embedding-space evolution and better few-step generation performance.
major comments (2)
- [Abstract] Abstract: the claim that DSL-LLaDA-SDE achieves the best ROUGE-1 on all four benchmarks at low step budgets lacks accompanying quantitative scores, variance estimates, or statistical tests; without these, the magnitude and reliability of the reported gains over iterative unmasking cannot be fully assessed.
- [Methods] The central claim that 1,000-step DSL adaptation suffices to unlock continuous embedding-space denoising and noisy-state robustness rests on the assumption that the Gaussian soft mask produces qualitatively different behavior than binary masking; an explicit comparison of the noise schedules or embedding trajectories (e.g., in the methods or appendix) is needed to rule out that the effect reduces to the extra compute alone.
minor comments (2)
- Clarify the precise four zero-shot summarization benchmarks and the exact definition of 'low step budgets (<=16 forward passes)' with a table of per-benchmark results.
- The control experiment description would benefit from a brief statement of the exact learning rate, batch size, and masking schedule used in the standard masked diffusion baseline to confirm identical compute.
Simulated Author's Rebuttal
We thank the referee for the positive recommendation of minor revision and the constructive feedback. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that DSL-LLaDA-SDE achieves the best ROUGE-1 on all four benchmarks at low step budgets lacks accompanying quantitative scores, variance estimates, or statistical tests; without these, the magnitude and reliability of the reported gains over iterative unmasking cannot be fully assessed.
Authors: We agree that including the specific scores would strengthen the abstract. In the revision we will update the abstract to report the ROUGE-1 values achieved by DSL-LLaDA-SDE (and the main baselines) on each of the four benchmarks at the low step budgets, with a reference to the full tables that already contain variance estimates and evaluation details. revision: yes
-
Referee: [Methods] The central claim that 1,000-step DSL adaptation suffices to unlock continuous embedding-space denoising and noisy-state robustness rests on the assumption that the Gaussian soft mask produces qualitatively different behavior than binary masking; an explicit comparison of the noise schedules or embedding trajectories (e.g., in the methods or appendix) is needed to rule out that the effect reduces to the extra compute alone.
Authors: The control experiments already isolate the contribution of DSL from compute: the identical 1,000-step budget and base model are used with standard binary masking, yet neither continuous denoising nor noisy-state robustness appears. This directly attributes the qualitative difference to the Gaussian soft-mask formulation rather than extra training. The methodological distinction between binary masking and continuous per-token Gaussian noise is described in Section 3; we do not consider an additional trajectory comparison necessary to support the claims. revision: no
Circularity Check
No significant circularity
full rationale
The paper describes an empirical adaptation procedure: a 1,000-step continued pretraining of LLaDA-8B-Instruct that replaces binary masking with continuous per-token Gaussian noise. All reported performance claims (ROUGE scores on summarization, robustness to noise, comparison to masked-diffusion controls) rest on experimental measurements rather than any derivation chain. No equations, uniqueness theorems, or ansatzes are invoked whose validity depends on self-citation or on quantities defined in terms of the target outputs. The control experiments directly test the contribution of the DSL adaptation, confirming that the observed behaviors are not forced by the training setup itself.
Axiom & Free-Parameter Ledger
free parameters (2)
- continued pretraining steps =
1000
- Gaussian noise parameters
axioms (1)
- domain assumption Continuous per-token Gaussian noise can serve as an effective soft mask enabling joint embedding-space denoising in a pretrained masked DLM.
Reference graph
Works this paper leans on
-
[1]
Penedo, Guilherme and Kydl. The. Advances in Neural Information Processing Systems , volume=
-
[2]
International Conference on Learning Representations , year=
The Curious Case of Neural Text Degeneration , author=. International Conference on Learning Representations , year=
-
[3]
International Conference on Learning Representations , year=
Neural Text Generation with Unlikelihood Training , author=. International Conference on Learning Representations , year=
-
[4]
LLaDA2.0: Scaling Up Diffusion Language Models to 100B
LLaDA 2.0: Scaling Up Diffusion Language Models to 100B , author=. arXiv preprint arXiv:2512.15745 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
SDAR: A Synergistic Diffusion-AutoRegression Paradigm for Scalable Sequence Generation , author=. arXiv preprint arXiv:2510.06303 , year=
-
[6]
arXiv preprint arXiv:2601.07351 , year=
Beyond Hard Masks: Progressive Token Evolution for Diffusion Language Models , author=. arXiv preprint arXiv:2601.07351 , year=
-
[7]
Advances in Neural Information Processing Systems , volume=
Large Language Diffusion Models , author=. Advances in Neural Information Processing Systems , volume=
-
[8]
Advances in Neural Information Processing Systems , volume=
Simple and Effective Masked Diffusion Language Models , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
Proceedings of the 41st International Conference on Machine Learning , year=
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution , author=. Proceedings of the 41st International Conference on Machine Learning , year=
-
[10]
Discrete Stochastic Localization for Non-autoregressive Generation
Discrete Stochastic Localization for Non-autoregressive Generation , author=. arXiv preprint arXiv:2602.16169 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
The Thirteenth International Conference on Learning Representations , year=
Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[12]
Mercury: Ultra-Fast Language Models Based on Diffusion
Mercury: Ultra-Fast Language Models Based on Diffusion , author=. arXiv preprint arXiv:2506.17298 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Proceedings of the 42nd International Conference on Machine Learning , year=
Train for the Worst, Plan for the Best: Understanding Token Ordering in Masked Diffusions , author=. Proceedings of the 42nd International Conference on Machine Learning , year=
-
[14]
arXiv preprint arXiv:2602.01362 , year=
Balancing Understanding and Generation in Discrete Diffusion Models , author=. arXiv preprint arXiv:2602.01362 , year=
-
[15]
Dream 7B: Diffusion Large Language Models
Dream 7B: Diffusion Large Language Models , author=. arXiv preprint arXiv:2508.15487 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Advances in Neural Information Processing Systems , volume=
Simplified and Generalized Masked Diffusion for Discrete Data , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
Diffusion-
Li, Xiang Lisa and Thickstun, John and Gulrajani, Ishaan and Liang, Percy and Hashimoto, Tatsunori B , booktitle=. Diffusion-
-
[18]
Continuous diffusion for categorical data
Continuous Diffusion for Categorical Data , author=. arXiv preprint arXiv:2211.15089 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Advances in Neural Information Processing Systems , volume=
Likelihood-Based Diffusion Language Models , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
2023 , address=
Han, Xiaochuang and Kumar, Sachin and Tsvetkov, Yulia , booktitle=. 2023 , address=
2023
-
[21]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
A Cheaper and Better Diffusion Language Model with Soft-Masked Noise , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=. 2023 , address=
2023
-
[22]
Advances in Neural Information Processing Systems , volume=
Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
Advances in Neural Information Processing Systems , volume=
Remasking Discrete Diffusion Models with Inference-Time Scaling , author=. Advances in Neural Information Processing Systems , volume=
-
[24]
Fine-Tuning Masked Diffusion for Provable Self-Correction
Fine-Tuning Masked Diffusion for Provable Self-Correction , author=. arXiv preprint arXiv:2510.01384 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
arXiv preprint arXiv:2505.18456 , year=
Anchored Diffusion Language Model , author=. arXiv preprint arXiv:2505.18456 , year=
-
[26]
Pillutla, Krishna and Swayamdipta, Swabha and Zellers, Rowan and Thickstun, John and Welleck, Sean and Choi, Yejin and Harchaoui, Zaid , booktitle=
-
[27]
and Lapata, Mirella , booktitle=
Narayan, Shashi and Cohen, Shay B. and Lapata, Mirella , booktitle=. Don't Give Me the Details, Just the Summary!. 2018 , address=
2018
-
[28]
Abstractive Text Summarization using Sequence-to-sequence
Nallapati, Ramesh and Zhou, Bowen and dos Santos, Cicero and G. Abstractive Text Summarization using Sequence-to-sequence. Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning , pages=. 2016 , address=
2016
-
[29]
2019 , address=
Kornilova, Anastassia and Eidelman, Vladimir , booktitle=. 2019 , address=
2019
-
[30]
Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers) , pages=
A Discourse-Aware Attention Model for Abstractive Summarization of Long Documents , author=. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers) , pages=. 2018 , address=
2018
-
[31]
arXiv preprint arXiv:2512.10858 , year=
Scaling Behavior of Discrete Diffusion Language Models , author=. arXiv preprint arXiv:2512.10858 , year=
-
[32]
LangFlow: Continuous Diffusion Rivals Discrete in Language Modeling
LangFlow: Continuous Diffusion Rivals Discrete in Language Modeling , author=. arXiv preprint arXiv:2604.11748 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Advances in Neural Information Processing Systems , volume=
Denoising Diffusion Probabilistic Models , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
The Eleventh International Conference on Learning Representations , year=
Flow Matching for Generative Modeling , author=. The Eleventh International Conference on Learning Representations , year=
-
[35]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Empowering Diffusion Models on the Embedding Space for Text Generation , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=. 2024 , address=
2024
-
[36]
Shen, Junzhe and Zhao, Jieru and He, Ziwei and Lin, Zhouhan , journal=
-
[37]
Flow Map Language Models: One-step Language Modeling via Continuous Denoising
Flow Map Language Models: One-step Language Modeling via Continuous Denoising , author=. arXiv preprint arXiv:2602.16813 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Liu, Aiwei and He, Minghua and Zeng, Shaoxun and Zhang, Sijun and Zhang, Linhao and Wu, Chuhan and Jia, Wei and Liu, Yuan and Zhou, Xiao and Zhou, Jie , journal=
-
[39]
Introspective Diffusion Language Models
Introspective Diffusion Language Models , author=. arXiv preprint arXiv:2604.11035 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
, journal=
Liang, Yihao and Wang, Ze and Chen, Hao and Sun, Ximeng and Wu, Jialian and Yu, Xiaodong and Liu, Jiang and Barsoum, Emad and Liu, Zicheng and Jha, Niraj K. , journal=
-
[41]
Kim, Minseo and Xu, Chenfeng and Hooper, Coleman and Singh, Harman and Athiwaratkun, Ben and Zhang, Ce and Keutzer, Kurt and Gholami, Amir , journal=
-
[42]
Training Verifiers to Solve Math Word Problems
Training Verifiers to Solve Math Word Problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.