Test-Time Training for Zero-Resource Dense Retrieval Reranking
Pith reviewed 2026-06-28 16:47 UTC · model grok-4.3
The pith
DART adapts a bilinear scoring matrix at test time using pseudo-labels from initial retrieval to improve zero-resource reranking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
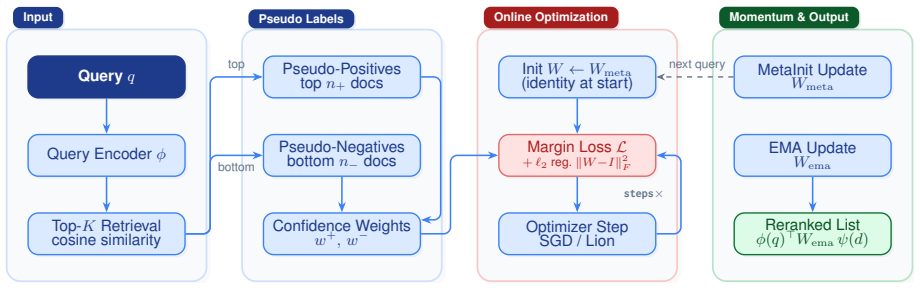
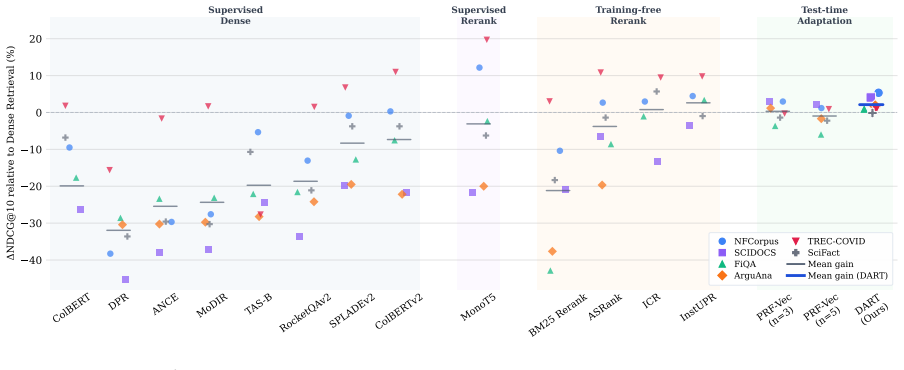
DART performs test-time training to adapt a bilinear scoring matrix W for each query, using top-ranked documents as pseudo-positive examples and bottom-ranked documents as pseudo-negative examples, achieving a mean per-dataset relative NDCG@10 gain of +2.1% over the dense retrieval baseline on six BEIR benchmarks with under 10ms additional latency per query.
What carries the argument
Bilinear scoring matrix W adapted via gradient updates on pseudo-labeled documents drawn from the initial dense retrieval ranking.
If this is right
- Reranking quality improves without any supervised training data or cross-encoder models.
- The method generalizes across domains in zero-resource settings.
- Added latency remains low enough for practical deployment.
- The same adaptation pattern can be applied on top of existing dense retrievers.
Where Pith is reading between the lines
- The technique may be most effective when the base retriever already achieves moderate recall.
- Similar per-query adaptation could be tested on other retrieval components such as query encoders.
- Varying the number of gradient steps or the margin loss weighting might further improve results on specific domains.
Load-bearing premise
The top and bottom documents from the initial dense retrieval provide reliable enough pseudo-positive and pseudo-negative examples to guide adaptation of the scoring matrix.
What would settle it
Performance would fall below the dense baseline on a benchmark where the initial retriever places most relevant documents outside its top ranks.
Figures
read the original abstract
Dense retrievers excel at first-stage candidate generation but lack effective reranking in zero-resource settings. Existing approaches face a fundamental dilemma: cross-encoders deliver strong reranking quality but require costly supervised training and incur high latency, while unsupervised BM25 reranking consistently degrades dense retrieval performance on most of BEIR benchmarks. We propose DART (Dense Adaptive Reranking at Test-time), which resolves this dilemma by adapting the scoring function at inference time. For each query, the top-ranked documents serve as pseudo-positive examples and the bottom-ranked as pseudo-negative examples, providing noisy but readily available supervision to adapt a bilinear scoring matrix $W$ via a small number of gradient updates. We further introduce a confidence-weighted margin loss and a cross-query momentum buffer that warm-starts adaptation across queries. On six BEIR benchmarks, DART achieves a mean per-dataset relative NDCG@10 gain of +2.1% over the dense retrieval baseline with under 10ms additional latency per query, demonstrating a powerful capability for zero-shot performance enhancement and cross-domain generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DART for zero-resource dense retrieval reranking: for each query it adapts a bilinear scoring matrix W at test time by treating the initial dense retriever's top documents as pseudo-positives and bottom documents as pseudo-negatives, performing a few gradient steps under a confidence-weighted margin loss together with a cross-query momentum buffer. The central empirical claim is a mean per-dataset relative NDCG@10 gain of +2.1% over the dense baseline on six BEIR benchmarks, achieved with under 10 ms added latency per query.
Significance. If the gains are robust, the result would be significant for practical IR: it offers a lightweight, training-free way to improve first-stage dense retrievers without the latency of cross-encoders or the degradation often seen with unsupervised BM25 reranking. The explicit test-time adaptation and momentum buffer constitute a clear technical contribution over purely static unsupervised rerankers.
major comments (2)
- [Abstract] Abstract and method description: the +2.1% mean relative NDCG@10 claim is load-bearing for the paper's contribution, yet the abstract supplies no per-dataset breakdown, no correlation between baseline NDCG and observed gain, and no ablation that isolates the contribution (or harm) of the pseudo-labels; without these the net-positive effect of the adaptation cannot be verified.
- [Method] Method (pseudo-label construction): the adaptation procedure treats top-ranked documents as reliable pseudo-positives and bottom-ranked as pseudo-negatives; when the initial dense ranking has low recall or inverted ordering (common on some BEIR domains), this supervision becomes anti-correlated with true relevance, and no analysis or safeguard is described to detect or mitigate such cases.
minor comments (2)
- [Abstract] Abstract: the six BEIR benchmarks are not named, preventing immediate assessment of domain coverage and comparison with prior work.
- [Abstract] Abstract: no mention is made of the number of gradient steps, learning rate schedule, or exact form of the bilinear matrix W, all of which are free parameters that affect reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work's significance. We address each major comment below and outline the corresponding revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract and method description: the +2.1% mean relative NDCG@10 claim is load-bearing for the paper's contribution, yet the abstract supplies no per-dataset breakdown, no correlation between baseline NDCG and observed gain, and no ablation that isolates the contribution (or harm) of the pseudo-labels; without these the net-positive effect of the adaptation cannot be verified.
Authors: We agree that the abstract would be strengthened by including more supporting detail for the central claim. The full manuscript already reports per-dataset NDCG@10 results in Table 1, examines the relationship between baseline performance and observed gains in Section 4.3 and Figure 3, and isolates the contribution of the pseudo-labels via ablations in Section 5.2. In the revision we will expand the abstract with a concise per-dataset breakdown of relative gains and a brief reference to the ablations, making the net-positive effect verifiable from the abstract alone. revision: yes
-
Referee: [Method] Method (pseudo-label construction): the adaptation procedure treats top-ranked documents as reliable pseudo-positives and bottom-ranked as pseudo-negatives; when the initial dense ranking has low recall or inverted ordering (common on some BEIR domains), this supervision becomes anti-correlated with true relevance, and no analysis or safeguard is described to detect or mitigate such cases.
Authors: This is a valid concern. While DART yields positive gains on all six evaluated BEIR datasets, the manuscript does not contain an explicit analysis of pseudo-label quality under low-recall initial rankings or any safeguard mechanism. In the revision we will add a dedicated discussion (new subsection in Section 4) that correlates initial recall@100 with adaptation gain and identifies domains where gains are smaller. We will also describe a lightweight safeguard based on monitoring the adaptation loss and will report preliminary results on its effect; a more comprehensive mitigation strategy would require additional experiments. revision: partial
Circularity Check
No circularity: explicit test-time adaptation evaluated on independent ground truth
full rationale
The paper describes DART as an explicit adaptation procedure: for each query it treats the initial dense retriever's top documents as pseudo-positives and bottom documents as pseudo-negatives, then performs a few gradient steps on a bilinear matrix W using a confidence-weighted margin loss. The central empirical claim (+2.1% mean relative NDCG@10 on six BEIR benchmarks) is obtained by comparing the adapted ranking against the datasets' external ground-truth relevance labels. No equation, loss term, or performance metric is shown to be equivalent by construction to the input ranking or to any fitted quantity derived from the target NDCG; the adaptation is a genuine optimization step whose output is measured externally. No self-citation chain or uniqueness theorem is invoked to justify the result.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of gradient updates
- adaptation learning rate
axioms (1)
- domain assumption Top-ranked documents are sufficiently reliable pseudo-positives and bottom-ranked are pseudo-negatives for the current query.
Reference graph
Works this paper leans on
-
[1]
2022 , publisher=
Pretrained transformers for text ranking: Bert and beyond , author=. 2022 , publisher=
2022
-
[2]
Information Processing & Management , volume=
A deep look into neural ranking models for information retrieval , author=. Information Processing & Management , volume=. 2020 , publisher=
2020
-
[3]
Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) , pages=
Dense passage retrieval for open-domain question answering , author=. Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) , pages=
2020
-
[4]
Sentence-bert: Sentence embeddings using siamese bert-networks , author=. Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) , pages=
2019
-
[5]
Proceedings of the 47th international ACM SIGIR conference on research and development in information retrieval , pages=
C-pack: Packed resources for general chinese embeddings , author=. Proceedings of the 47th international ACM SIGIR conference on research and development in information retrieval , pages=
-
[6]
Passage Re-ranking with BERT , author=. arXiv preprint arXiv:1901.04085 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[7]
Findings of the association for computational linguistics: EMNLP 2020 , pages=
Document ranking with a pretrained sequence-to-sequence model , author=. Findings of the association for computational linguistics: EMNLP 2020 , pages=
2020
-
[8]
Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
Colbertv2: Effective and efficient retrieval via lightweight late interaction , author=. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
2022
-
[9]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
Is ChatGPT good at search? investigating large language models as re-ranking agents , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
2023
-
[10]
arXiv preprint arXiv:2309.15088 , year=
Rankvicuna: Zero-shot listwise document reranking with open-source large language models , author=. arXiv preprint arXiv:2309.15088 , year=
-
[11]
arXiv preprint arXiv:2502.18418 , year=
Rank1: Test-time compute for reranking in information retrieval , author=. arXiv preprint arXiv:2502.18418 , year=
-
[12]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages=
2019
-
[13]
Proceedings of the 2022 conference of the North American chapter of the association for computational linguistics: human language technologies , pages=
GPL: Generative pseudo labeling for unsupervised domain adaptation of dense retrieval , author=. Proceedings of the 2022 conference of the North American chapter of the association for computational linguistics: human language technologies , pages=
2022
-
[14]
Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
Augmenting passage representations with query generation for enhanced cross-lingual dense retrieval , author=. Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[15]
arXiv preprint arXiv:2212.08841 , year=
Unsupervised dense retrieval deserves better positive pairs: Scalable augmentation with query extraction and generation , author=. arXiv preprint arXiv:2212.08841 , year=
-
[16]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
UDAPDR: unsupervised domain adaptation via LLM prompting and distillation of rerankers , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
2023
-
[17]
ACM SIGIR Forum , volume=
Relevance-based language models , author=. ACM SIGIR Forum , volume=. 2017 , organization=
2017
-
[18]
ACM Transactions on Information Systems , volume=
Pseudo relevance feedback with deep language models and dense retrievers: Successes and pitfalls , author=. ACM Transactions on Information Systems , volume=. 2023 , publisher=
2023
-
[19]
ACM Transactions on the Web , volume=
ColBERT-PRF: Semantic pseudo-relevance feedback for dense passage and document retrieval , author=. ACM Transactions on the Web , volume=. 2023 , publisher=
2023
-
[20]
arXiv preprint arXiv:2503.14887 , year=
Pseudo Relevance Feedback is Enough to Close the Gap Between Small and Large Dense Retrieval Models , author=. arXiv preprint arXiv:2503.14887 , year=
-
[21]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Text embeddings by weakly-supervised contrastive pre-training , author=. arXiv preprint arXiv:2212.03533 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
International conference on machine learning , pages=
Test-time training with self-supervision for generalization under distribution shifts , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[23]
Advances in Neural Information Processing Systems , volume=
Ttt++: When does self-supervised test-time training fail or thrive? , author=. Advances in Neural Information Processing Systems , volume=
-
[24]
arXiv preprint arXiv:2411.07279 , year=
The surprising effectiveness of test-time training for few-shot learning , author=. arXiv preprint arXiv:2411.07279 , year=
-
[25]
MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models
Metamath: Bootstrap your own mathematical questions for large language models , author=. arXiv preprint arXiv:2309.12284 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Advances in neural information processing systems , volume=
Symbolic discovery of optimization algorithms , author=. Advances in neural information processing systems , volume=
-
[27]
BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models
Beir: A heterogenous benchmark for zero-shot evaluation of information retrieval models , author=. arXiv preprint arXiv:2104.08663 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
Asrank: Zero-shot re-ranking with answer scent for document retrieval , author=. Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
2025
-
[29]
arXiv preprint arXiv:2410.02642 , year=
Attention in large language models yields efficient zero-shot re-rankers , author=. arXiv preprint arXiv:2410.02642 , year=
-
[30]
arXiv preprint arXiv:2403.16435 , year=
InstUPR: Instruction-based unsupervised passage reranking with large language models , author=. arXiv preprint arXiv:2403.16435 , year=
-
[31]
IEEE transactions on big data , volume=
Billion-scale similarity search with GPUs , author=. IEEE transactions on big data , volume=. 2019 , publisher=
2019
-
[32]
2009 , publisher=
The probabilistic relevance framework: BM25 and beyond , author=. 2009 , publisher=
2009
-
[33]
arXiv preprint arXiv:2510.05396 , year=
Scalable In-context Ranking with Generative Models , author=. arXiv preprint arXiv:2510.05396 , year=
-
[34]
Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval , pages=
Colbert: Efficient and effective passage search via contextualized late interaction over bert , author=. Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval , pages=
-
[35]
Findings of the Association for Computational Linguistics: ACL 2022 , pages=
Zero-shot dense retrieval with momentum adversarial domain invariant representations , author=. Findings of the Association for Computational Linguistics: ACL 2022 , pages=
2022
-
[36]
arXiv preprint arXiv:2007.00808 , year=
Approximate nearest neighbor negative contrastive learning for dense text retrieval , author=. arXiv preprint arXiv:2007.00808 , year=
-
[37]
Efficiently Teaching an Effective Dense Retriever with Balanced Topic Aware Sampling , year =
Hofst\". Efficiently Teaching an Effective Dense Retriever with Balanced Topic Aware Sampling , year =. Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =. doi:10.1145/3404835.3462891 , abstract =
-
[38]
Unsupervised Dense Information Retrieval with Contrastive Learning , author=. Trans. Mach. Learn. Res. , year=
-
[39]
Nature , year=
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning , author=. Nature , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.