MViewRouter: Internalizing Geometric Equivariance via Multi-view Alternating Attention for Combinatorial Routing
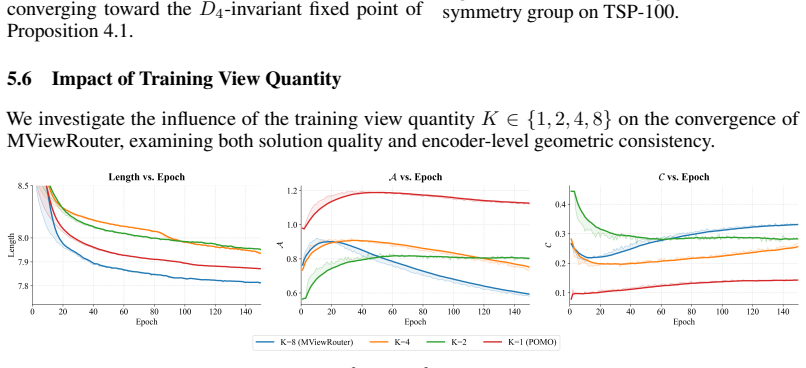
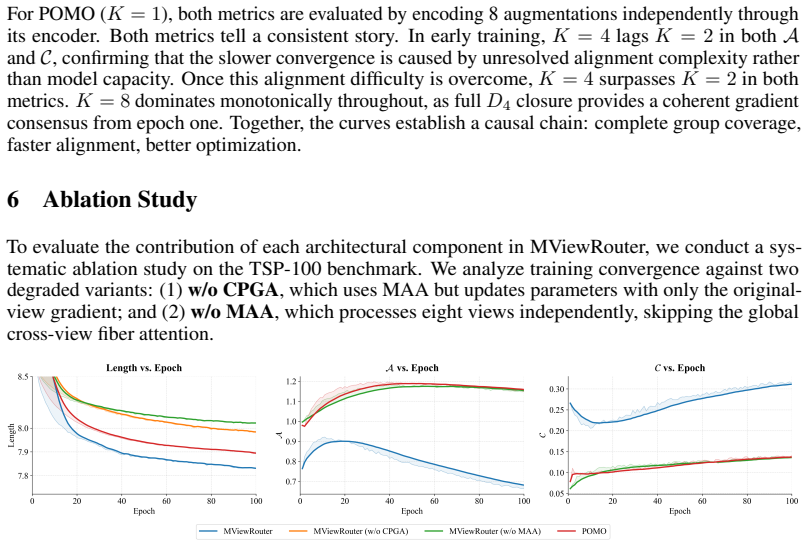
Pith reviewed 2026-06-28 17:45 UTC · model grok-4.3
The pith
MViewRouter internalizes geometric equivariance via multi-view alternating attention to produce invariant routing decisions
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
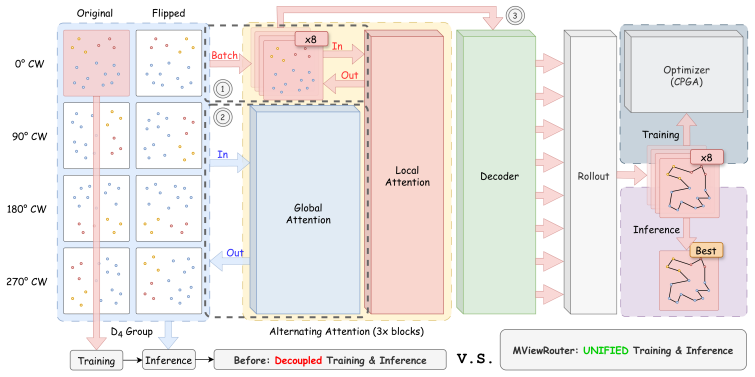
MViewRouter achieves invariant decision-making for routing problems by internalizing geometric equivariance as a structural inductive bias through its Multi-view Alternating Attention mechanism that enables parallel processing over the D4 symmetry group, combined with Collective Policy Gradient Aggregation for training.
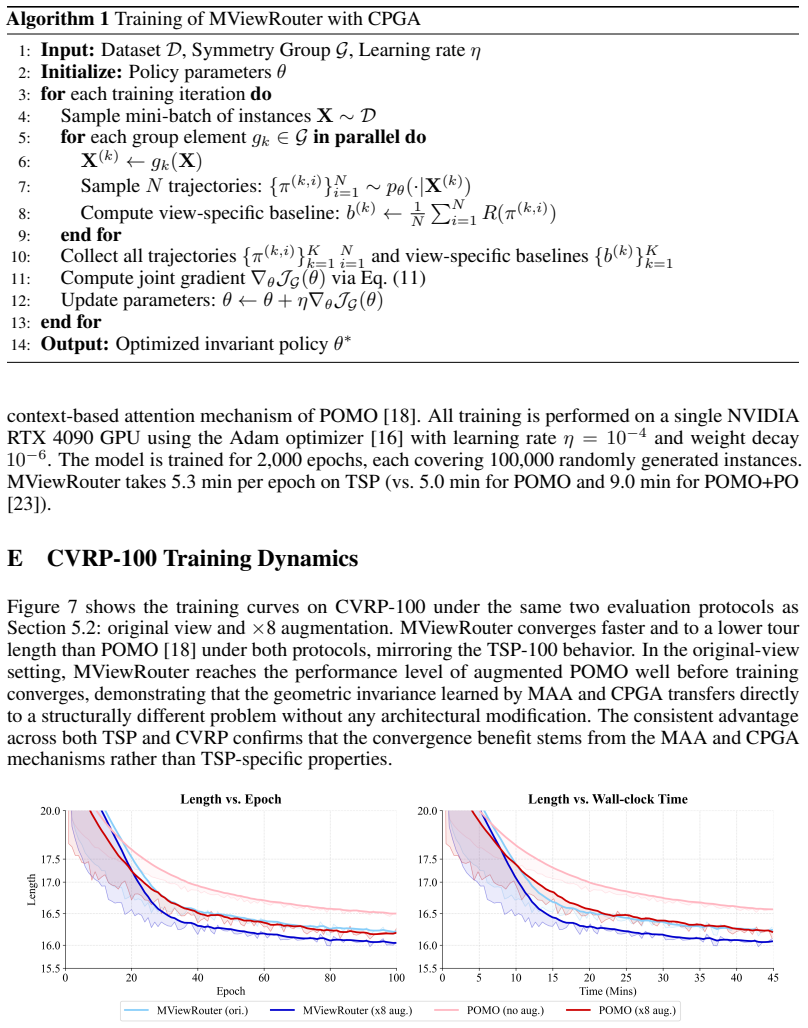
What carries the argument
Multi-view Alternating Attention (MAA) mechanism that alternates between intra-view relational modeling and inter-view feature alignment for parallel processing over the D4 symmetry group
If this is right
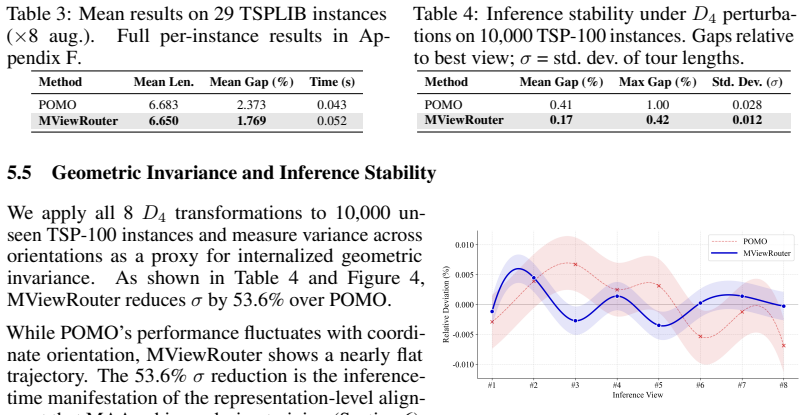
- Decisions remain consistent across all D4 transformations of the same routing instance without requiring data augmentation.
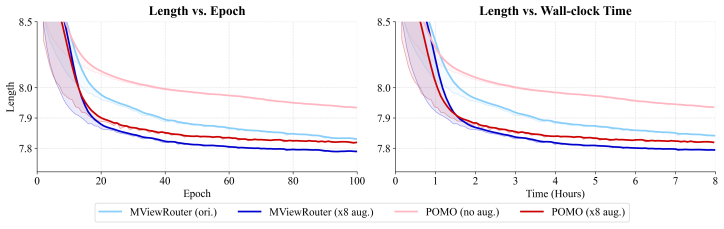
- Training converges faster and more stably because gradients are aggregated from multiple symmetric views.
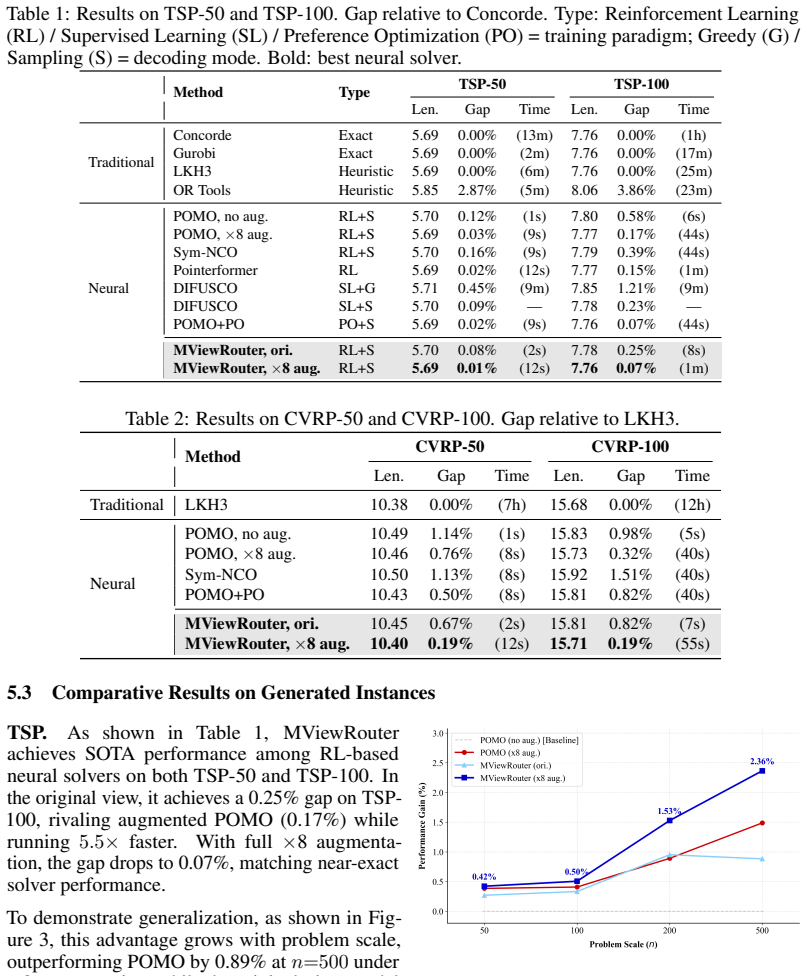
- Zero-shot performance improves on unseen TSP and CVRP instances, including real-world TSPLIB benchmarks.
- The same framework applies to both TSP and CVRP while maintaining competitive solution quality.
Where Pith is reading between the lines
- The same multi-view structure could be tested on other geometric combinatorial problems such as the knapsack or scheduling tasks that also admit rotations and reflections.
- If the invariance holds, the method would reduce the volume of augmented training data needed for routing models in practice.
- Extending the symmetry group beyond D4 might reveal whether the approach scales to problems with continuous rotations or 3D symmetries.
Load-bearing premise
That parallel processing over the D4 symmetry group via alternating intra- and inter-view attention is sufficient to internalize geometric equivariance as a structural inductive bias that produces invariant decisions for routing problems.
What would settle it
A direct test in which MViewRouter outputs different routes for an instance and its 90-degree rotation or reflection would show that the claimed invariance does not hold.
Figures
read the original abstract
Combinatorial routing problems such as the Traveling Salesman Problem (TSP) and the Capacitated Vehicle Routing Problem (CVRP) are fundamental NP-hard problems with broad real-world applications. While recent deep reinforcement learning methods have shown promising performance, they typically handle geometric symmetries only through data augmentation, resulting in inconsistent decisions and limited generalization. To address this issue, we propose MViewRouter, a multi-view framework that internalizes geometric equivariance as a structural inductive bias to achieve invariant decision-making across routing problem variants. Our approach introduces a Multi-view Alternating Attention (MAA) mechanism that enables parallel processing over the $D_4$ symmetry group, alternating between intra-view relational modeling and inter-view feature alignment. Furthermore, we optimize the policy via Collective Policy Gradient Aggregation (CPGA), leveraging consensus gradients from multiple symmetric views to stabilize training and accelerate convergence. Experiments on TSP and CVRP benchmarks, as well as real-world TSPLIB instances, demonstrate that MViewRouter achieves competitive solution quality and strong zero-shot generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MViewRouter, a multi-view deep RL framework for combinatorial routing problems (TSP, CVRP). It introduces Multi-view Alternating Attention (MAA) to process inputs in parallel over the D4 symmetry group by alternating intra-view relational modeling and inter-view feature alignment, thereby internalizing geometric equivariance as a structural inductive bias for invariant decisions. A Collective Policy Gradient Aggregation (CPGA) procedure aggregates gradients across symmetric views for training. Experiments on standard benchmarks and TSPLIB instances are reported to yield competitive solution quality and strong zero-shot generalization without data augmentation.
Significance. If the central invariance claim holds with supporting derivations or metrics, the work would demonstrate a structural alternative to data augmentation for symmetry handling in routing RL, potentially improving generalization. The framing as an inductive bias rather than post-hoc augmentation is a constructive direction for combinatorial optimization.
major comments (2)
- [Abstract / MAA description] Abstract and method description: the claim that MAA 'internalizes geometric equivariance' and produces 'invariant decision-making' is load-bearing for the contribution, yet no explicit construction is supplied showing how attention weights or embeddings transform under the generators of D4 (90° rotations, reflections). No invariance metric (e.g., output consistency under group actions on the same instance) or proof sketch is referenced.
- [Experiments] Experiments section: the reported 'competitive solution quality and strong zero-shot generalization' cannot be evaluated without ablation tables isolating the contribution of MAA versus CPGA, without error bars or statistical tests across random seeds, and without baselines that also incorporate D4 augmentation or equivariant layers.
minor comments (2)
- Notation: ensure the precise definition of the D4 group action on node coordinates and edge features is stated before the MAA equations.
- Clarify whether CPGA reduces to standard policy gradient when the number of views is one, to separate the symmetry-handling benefit from the aggregation technique.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of the invariance properties and the experimental evaluation.
read point-by-point responses
-
Referee: [Abstract / MAA description] Abstract and method description: the claim that MAA 'internalizes geometric equivariance' and produces 'invariant decision-making' is load-bearing for the contribution, yet no explicit construction is supplied showing how attention weights or embeddings transform under the generators of D4 (90° rotations, reflections). No invariance metric (e.g., output consistency under group actions on the same instance) or proof sketch is referenced.
Authors: We agree that the manuscript would be strengthened by an explicit construction. In the revision we will add a subsection deriving the transformation rules for embeddings and attention weights under the generators of D4, together with a quantitative invariance metric that measures output consistency on transformed instances. revision: yes
-
Referee: [Experiments] Experiments section: the reported 'competitive solution quality and strong zero-shot generalization' cannot be evaluated without ablation tables isolating the contribution of MAA versus CPGA, without error bars or statistical tests across random seeds, and without baselines that also incorporate D4 augmentation or equivariant layers.
Authors: We concur that these elements are required for a complete evaluation. The revised manuscript will include ablation tables separating MAA and CPGA, report means and standard deviations with statistical tests over multiple seeds, and add baselines that apply D4 data augmentation as well as equivariant layers. revision: yes
Circularity Check
No circularity: architectural proposal with external empirical claims
full rationale
The abstract and description frame MViewRouter as introducing a new MAA mechanism for parallel D4 processing and CPGA for gradient aggregation, presented as a structural inductive bias whose performance is evaluated on TSP/CVRP benchmarks and TSPLIB instances. No quoted equations, self-citations, or derivation steps reduce any central claim (equivariant decisions or zero-shot generalization) to fitted parameters or prior outputs by construction. The inductive-bias argument is an architectural hypothesis whose validity is left to external verification rather than internal self-definition or renaming.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The D4 symmetry group captures the relevant geometric symmetries for TSP and CVRP instances.
invented entities (2)
-
Multi-view Alternating Attention (MAA)
no independent evidence
-
Collective Policy Gradient Aggregation (CPGA)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Concorde tsp solver, 2006
David Applegate, Ribert Bixby, Vasek Chvatal, and William Cook. Concorde tsp solver, 2006
2006
-
[2]
Vivit: A video vision transformer
Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lu ˇci´c, and Cordelia Schmid. Vivit: A video vision transformer. InProceedings of the IEEE/CVF international conference on computer vision, pages 6836–6846, 2021
2021
-
[3]
Some applications of the generalized vehicle routing problem.Journal of the operational research society, 61(7):1072–1077, 2010
Roberto Baldacci, Enrico Bartolini, and Gilbert Laporte. Some applications of the generalized vehicle routing problem.Journal of the operational research society, 61(7):1072–1077, 2010
2010
-
[4]
Neural Combinatorial Optimization with Reinforcement Learning
Irwan Bello, Hieu Pham, Quoc V Le, Mohammad Norouzi, and Samy Bengio. Neural combina- torial optimization with reinforcement learning.arXiv preprint arXiv:1611.09940, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[5]
Machine learning for combinatorial optimization: a methodological tour d’horizon.European Journal of Operational Research, 290(2):405–421, 2021
Yoshua Bengio, Andrea Lodi, and Antoine Prouvost. Machine learning for combinatorial optimization: a methodological tour d’horizon.European Journal of Operational Research, 290(2):405–421, 2021
2021
-
[6]
Geometric Deep Learning: Grids, Groups, Graphs, Geodesics, and Gauges
Michael M Bronstein, Joan Bruna, Taco Cohen, and Petar Veliˇckovi´c. Geometric deep learning: Grids, groups, graphs, geodesics, and gauges.arXiv preprint arXiv:2104.13478, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Simulation-guided beam search for neural combinatorial optimization
Jinho Choo, Yeong-Dae Kwon, Jihoon Kim, Jeongwoo Jae, André Hottung, Kevin Tierney, and Youngjune Gwon. Simulation-guided beam search for neural combinatorial optimization. Advances in Neural Information Processing Systems, 35:8760–8772, 2022
2022
-
[8]
Bq-nco: Bisimulation quotienting for efficient neural combinatorial optimization.Advances in Neural Information Processing Systems, 36:77416–77429, 2023
Darko Drakulic, Sofia Michel, Florian Mai, Arnaud Sors, and Jean-Marc Andreoli. Bq-nco: Bisimulation quotienting for efficient neural combinatorial optimization.Advances in Neural Information Processing Systems, 36:77416–77429, 2023
2023
-
[9]
Invit: A generalizable routing problem solver with invariant nested view transformer
Han Fang, Zhihao Song, Paul Weng, and Yutong Ban. Invit: A generalizable routing problem solver with invariant nested view transformer. InInternational Conference on Machine Learning, pages 12973–12992. PMLR, 2024
2024
-
[10]
Winner takes it all: Training performant rl populations for combinatorial optimization.Advances in Neural Information Processing Systems, 36:48485–48509, 2023
Nathan Grinsztajn, Daniel Furelos-Blanco, Shikha Surana, Clément Bonnet, and Tom Barrett. Winner takes it all: Training performant rl populations for combinatorial optimization.Advances in Neural Information Processing Systems, 36:48485–48509, 2023
2023
-
[11]
An extension of the lin-kernighan-helsgaun tsp solver for constrained traveling salesman and vehicle routing problems.Roskilde: Roskilde University, 12:966–980, 2017
Keld Helsgaun. An extension of the lin-kernighan-helsgaun tsp solver for constrained traveling salesman and vehicle routing problems.Roskilde: Roskilde University, 12:966–980, 2017
2017
-
[12]
André Hottung and Kevin Tierney. Neural large neighborhood search for the capacitated vehicle routing problem.arXiv preprint arXiv:1911.09539, 2019
-
[13]
André Hottung, Yeong-Dae Kwon, and Kevin Tierney. Efficient active search for combinatorial optimization problems.arXiv preprint arXiv:2106.05126, 2021
-
[14]
Pointerformer: Deep reinforced multi-pointer transformer for the traveling salesman problem
Yan Jin, Yuandong Ding, Xuanhao Pan, Kun He, Li Zhao, Tao Qin, Lei Song, and Jiang Bian. Pointerformer: Deep reinforced multi-pointer transformer for the traveling salesman problem. InProceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 8132–8140, 2023
2023
-
[15]
Sym-nco: Leveraging symmetricity for neural combinatorial optimization.Advances in Neural Information Processing Systems, 35:1936– 1949, 2022
Minsu Kim, Junyoung Park, and Jinkyoo Park. Sym-nco: Leveraging symmetricity for neural combinatorial optimization.Advances in Neural Information Processing Systems, 35:1936– 1949, 2022
1936
-
[16]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[17]
Attention, Learn to Solve Routing Problems!
Wouter Kool, Herke Van Hoof, and Max Welling. Attention, learn to solve routing problems! arXiv preprint arXiv:1803.08475, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[18]
Pomo: Policy optimization with multiple optima for reinforcement learning.Advances in Neural Information Processing Systems, 33:21188–21198, 2020
Yeong-Dae Kwon, Jinho Choo, Byoungjip Kim, Iljoo Yoon, Youngjune Gwon, and Seungjai Min. Pomo: Policy optimization with multiple optima for reinforcement learning.Advances in Neural Information Processing Systems, 33:21188–21198, 2020. 10
2020
-
[19]
Zijun Liao, Jinbiao Chen, Debing Wang, Zizhen Zhang, and Jiahai Wang. Bopo: Neural combinatorial optimization via best-anchored and objective-guided preference optimization. arXiv preprint arXiv:2503.07580, 2025
-
[20]
A learning-based iterative method for solving vehicle routing problems
Hao Lu, Xingwen Zhang, and Shuang Yang. A learning-based iterative method for solving vehicle routing problems. InInternational conference on learning representations, 2019
2019
-
[21]
Learning to search feasible and infeasible regions of routing problems with flexible neural k-opt.Advances in Neural Information Processing Systems, 36:49555–49578, 2023
Yining Ma, Zhiguang Cao, and Yeow Meng Chee. Learning to search feasible and infeasible regions of routing problems with flexible neural k-opt.Advances in Neural Information Processing Systems, 36:49555–49578, 2023
2023
-
[22]
Reinforcement learning for solving the vehicle routing problem.Advances in neural information processing systems, 31, 2018
Mohammadreza Nazari, Afshin Oroojlooy, Lawrence Snyder, and Martin Takác. Reinforcement learning for solving the vehicle routing problem.Advances in neural information processing systems, 31, 2018
2018
-
[23]
Preference optimization for combinatorial optimization problems
Mingjun Pan, Guanquan Lin, You-Wei Luo, Bin Zhu, Zhien Dai, Lijun Sun, and Chun Yuan. Preference optimization for combinatorial optimization problems. InForty-second International Conference on Machine Learning, 2025
2025
-
[24]
H-tsp: Hierarchically solving the large-scale traveling salesman problem
Xuanhao Pan, Yan Jin, Yuandong Ding, Mingxiao Feng, Li Zhao, Lei Song, and Jiang Bian. H-tsp: Hierarchically solving the large-scale traveling salesman problem. InProceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 9345–9353, 2023
2023
-
[25]
Optimization with gurobi and python.INESC Porto and Universidade do Porto„ Porto, Portugal, 1, 2011
Joo Pedro Pedroso. Optimization with gurobi and python.INESC Porto and Universidade do Porto„ Porto, Portugal, 1, 2011
2011
-
[26]
10,000 optimal cvrp solutions for testing machine learning based heuristics
Eduardo Queiroga, Ruslan Sadykov, Eduardo Uchoa, and Thibaut Vidal. 10,000 optimal cvrp solutions for testing machine learning based heuristics. InAAAI-22 workshop on machine learning for operations research (ML4OR), 2021
2021
-
[27]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[28]
Tsplib—a traveling salesman problem library.ORSA journal on computing, 3 (4):376–384, 1991
Gerhard Reinelt. Tsplib—a traveling salesman problem library.ORSA journal on computing, 3 (4):376–384, 1991
1991
-
[29]
E (n) equivariant graph neural networks
Vıctor Garcia Satorras, Emiel Hoogeboom, and Max Welling. E (n) equivariant graph neural networks. InInternational conference on machine learning, pages 9323–9332. PMLR, 2021
2021
-
[30]
Multi-task learning as multi-objective optimization.Advances in neural information processing systems, 31, 2018
Ozan Sener and Vladlen Koltun. Multi-task learning as multi-objective optimization.Advances in neural information processing systems, 31, 2018
2018
-
[31]
Difusco: Graph-based diffusion solvers for combinatorial optimization.Advances in neural information processing systems, 36:3706–3731, 2023
Zhiqing Sun and Yiming Yang. Difusco: Graph-based diffusion solvers for combinatorial optimization.Advances in neural information processing systems, 36:3706–3731, 2023
2023
-
[32]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[33]
Pointer networks.Advances in neural information processing systems, 28, 2015
Oriol Vinyals, Meire Fortunato, and Navdeep Jaitly. Pointer networks.Advances in neural information processing systems, 28, 2015
2015
-
[34]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025
2025
-
[35]
Simple statistical gradient-following algorithms for connectionist reinforce- ment learning.Machine learning, 8(3):229–256, 1992
Ronald J Williams. Simple statistical gradient-following algorithms for connectionist reinforce- ment learning.Machine learning, 8(3):229–256, 1992
1992
-
[36]
Learning improvement heuristics for solving routing problems.IEEE transactions on neural networks and learning systems, 33(9):5057–5069, 2021
Yaoxin Wu, Wen Song, Zhiguang Cao, Jie Zhang, and Andrew Lim. Learning improvement heuristics for solving routing problems.IEEE transactions on neural networks and learning systems, 33(9):5057–5069, 2021. 11
2021
-
[37]
Multi-decoder attention model with embedding glimpse for solving vehicle routing problems
Liang Xin, Wen Song, Zhiguang Cao, and Jie Zhang. Multi-decoder attention model with embedding glimpse for solving vehicle routing problems. InProceedings of the AAAI conference on artificial intelligence, volume 35, pages 12042–12049, 2021
2021
-
[38]
Liang Xin, Wen Song, Zhiguang Cao, and Jie Zhang. Neurolkh: Combining deep learning model with lin-kernighan-helsgaun heuristic for solving the traveling salesman problem.Advances in Neural Information Processing Systems, 34:7472–7483, 2021
2021
-
[39]
Gradient surgery for multi-task learning.Advances in neural information processing systems, 33:5824–5836, 2020
Tianhe Yu, Saurabh Kumar, Abhishek Gupta, Sergey Levine, Karol Hausman, and Chelsea Finn. Gradient surgery for multi-task learning.Advances in neural information processing systems, 33:5824–5836, 2020
2020
-
[40]
Combining reinforcement learning with lin-kernighan-helsgaun algorithm for the traveling salesman problem
Jiongzhi Zheng, Kun He, Jianrong Zhou, Yan Jin, and Chu-Min Li. Combining reinforcement learning with lin-kernighan-helsgaun algorithm for the traveling salesman problem. InPro- ceedings of the AAAI conference on artificial intelligence, volume 35, pages 12445–12452, 2021. 12 AD 4 Symmetry Group Transformations The D4 dihedral group consists of 8 isometri...
2021
-
[41]
Overall and per-instance analysis.MViewRouter improves over POMO on 22 of 29 instances, with a 25.5% relative reduction in mean optimality gap (2.373% → 1.769%)
and MViewRouter use ×8 augmentation with a model trained on TSP-100, evaluated zero-shot without retraining or fine-tuning. Overall and per-instance analysis.MViewRouter improves over POMO on 22 of 29 instances, with a 25.5% relative reduction in mean optimality gap (2.373% → 1.769%). The gains are most pronounced on instances where POMO’s gap is large, s...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.