MiCU: End-to-End Smart Home Command Understanding with Large Language Model
Pith reviewed 2026-06-28 17:11 UTC · model grok-4.3
The pith
MiCU adapts large language models to smart home commands by synthesizing data from user logs and using curriculum learning plus reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
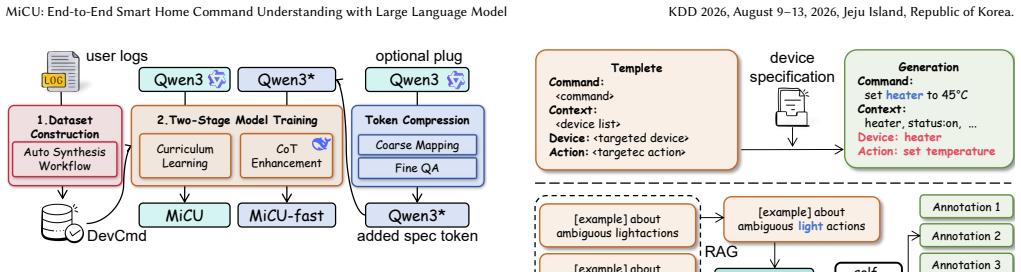
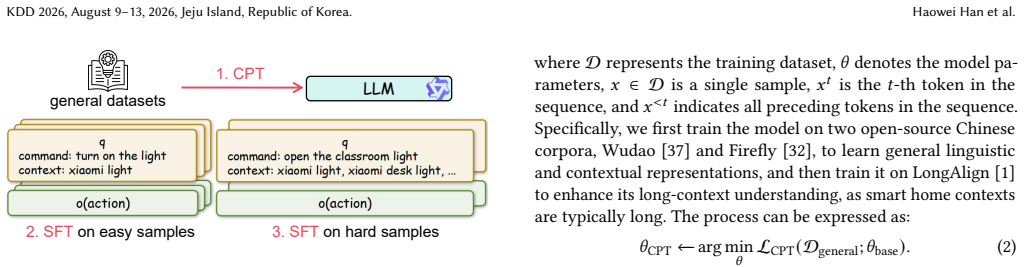
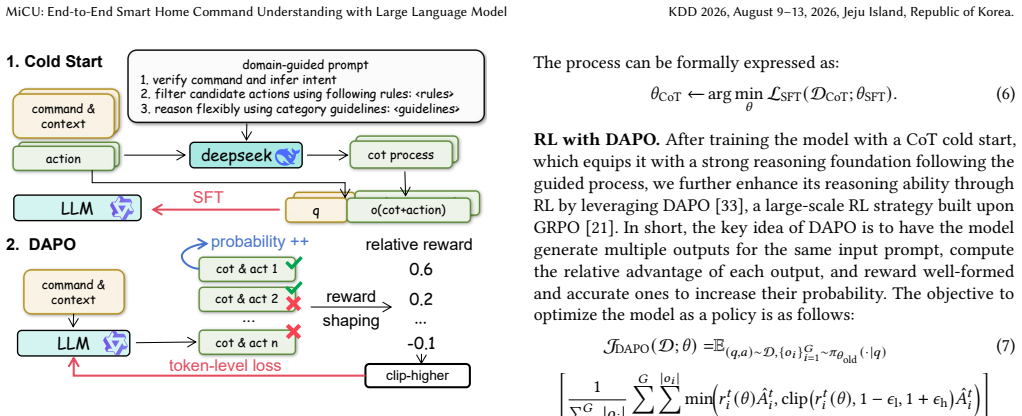
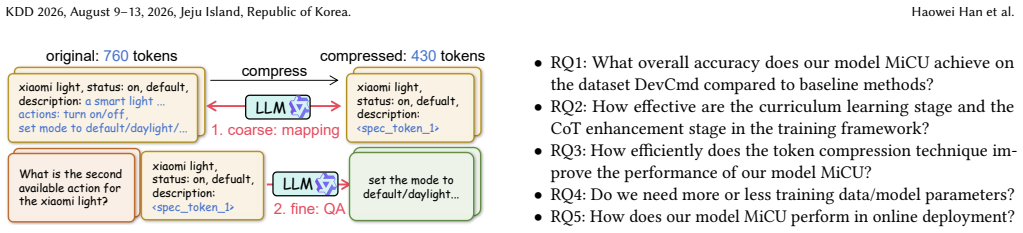
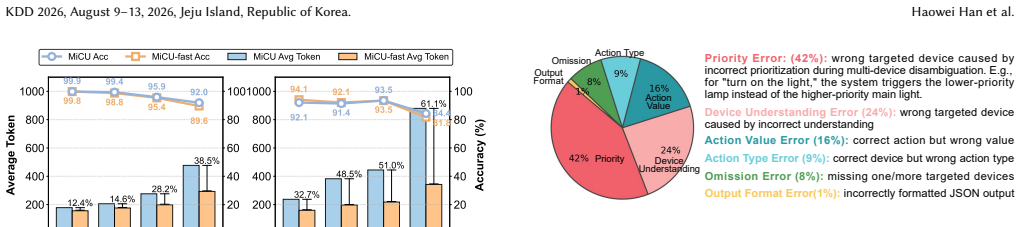
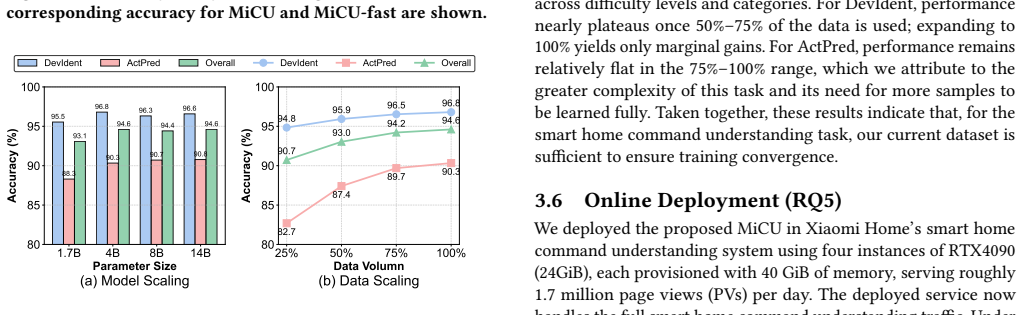
MiCU is created by first generating training data automatically from user logs with the aid of large language models, then applying curriculum learning to inject domain knowledge, followed by cold-start training and reinforcement learning that follows explicit domain thinking rules, and finally replacing device descriptions with a single special token for efficiency. On this foundation the model reaches an average accuracy gain of 20.01 percent across device categories over prior baselines. When deployed in the Xiaomi Home app it lowers the user correction rate by 1.57 percent and raises human-audited accuracy by 32.05 percent.
What carries the argument
The automated data synthesis workflow from user logs combined with curriculum learning, reinforcement learning guided by domain rules, and single-token compression of device descriptions.
If this is right
- The model delivers a 20.01 percent average accuracy increase across all device categories relative to baselines.
- Production use cuts the rate at which users must correct the system by 1.57 percent.
- Human-audited accuracy in the deployed app rises by 32.05 percent.
- The token compression step creates a faster variant that handles long device lists without extra cost.
Where Pith is reading between the lines
- The same log-driven synthesis and rule-guided reinforcement learning could be reused for command understanding in other structured environments such as vehicle controls or industrial interfaces.
- Single-token compression of repeated structured text may lower serving costs in any large-language-model application that repeatedly references catalogs or inventories.
- Daily traffic of 1.7 million page views supplies a continuous stream of new logs that can be fed back into the synthesis loop for ongoing adaptation.
Load-bearing premise
The examples created automatically from user logs and large language models match the distribution of real ambiguous commands well enough that gains observed on test sets carry over to live users.
What would settle it
Run the trained model on a fresh collection of ambiguous commands gathered directly from app users that were never seen during synthesis and check whether the 20 percent accuracy margin over baselines still holds.
Figures

read the original abstract
Command understanding systems in smart home ecosystems can automate device control and substantially improve user experience. However, while they perform well on precise utterances (e.g., "turn on the bedroom light"), they struggle with ambiguous or misaligned commands (e.g., "make the bedroom cozy"). Large language models (LLMs) generalize well across various domains and can outperform traditional rule-based systems on such tasks, but their effectiveness is often constrained by scarce domain-specific data, insufficient task-specific adaptation, and high computational costs. In this paper, we propose an automated training data synthesis workflow using user logs and LLMs; then we build MiCU, a domain-specific LLM that excels at command understanding. Specifically, we employ curriculum learning to inject domain knowledge into the base LLM, then we enhance its reasoning ability via cold-start training combined with reinforcement learning (RL) guided by domain-specific thinking rules. Additionally, we introduce a token compression technique that condenses device description into a single special token, substantially reducing inference overhead and enabling \model-fast, an efficient variant optimized for long inputs. Extensive experiments show that MiCU significantly outperforms baselines, with an average accuracy gain of 20.01% across all device categories. We have deployed MiCU in the Xiaomi Home app, receiving approximately 1.7 million page views per day. Production evaluations show that MiCU reduces user correction rate by 1.57% and increases human audited accuracy by 32.05%. Our data and code are available at https://github.com/xiaomi-research/iot_spec_llm
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MiCU, a domain-specific LLM for smart home command understanding. It introduces an automated data synthesis workflow from user logs using LLMs, followed by curriculum learning to inject domain knowledge, cold-start training combined with RL guided by domain-specific thinking rules, and a token compression technique to create an efficient variant (MiCU-fast). Experiments report an average 20.01% accuracy gain over baselines across device categories, with production deployment in the Xiaomi Home app yielding a 1.57% reduction in user correction rate and 32.05% increase in human audited accuracy; code and data are released.
Significance. If the results hold under proper controls, the work demonstrates a practical pipeline for adapting LLMs to ambiguous command understanding in IoT settings with scarce domain data, combining synthetic data generation, curriculum/RL stages, and inference optimization. The production deployment metrics provide evidence of real-world utility beyond academic benchmarks.
major comments (2)
- [Abstract, §3] Abstract and §3 (data synthesis workflow): The headline 20.01% accuracy gain and production metrics rest on the claim that LLM-driven synthesis from user logs produces training examples whose ambiguity distribution matches real deployment commands, yet no quantitative validation (feature histograms, KL divergence, or human alignment scores on held-out real logs) is reported; without this, the gains risk being artifacts of the synthetic distribution rather than evidence of robust generalization.
- [Abstract, Experiments] Abstract and experimental section: The accuracy, correction-rate, and audited-accuracy figures are stated without dataset sizes, baseline model details, error bars, ablation results, or statistical significance tests, preventing assessment of whether the reported improvements are load-bearing or sensitive to experimental controls.
minor comments (2)
- [§4] The token-compression method is described as condensing device descriptions into a single special token, but the exact training objective and any impact on downstream accuracy are not quantified separately from the RL stage.
- [Production evaluation] Production metrics are given as point estimates (1.57%, 32.05%) without confidence intervals or description of the audit sample size and selection criteria.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which highlight important aspects for improving the clarity and rigor of our work. We address each major comment below and commit to revisions that incorporate the suggested enhancements.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (data synthesis workflow): The headline 20.01% accuracy gain and production metrics rest on the claim that LLM-driven synthesis from user logs produces training examples whose ambiguity distribution matches real deployment commands, yet no quantitative validation (feature histograms, KL divergence, or human alignment scores on held-out real logs) is reported; without this, the gains risk being artifacts of the synthetic distribution rather than evidence of robust generalization.
Authors: We concur that providing quantitative evidence of distribution alignment would strengthen the claims regarding the synthetic data's fidelity. Although the workflow is constructed to mirror real user log patterns and the production results offer supporting evidence of practical effectiveness, we will revise the manuscript to include comparative feature histograms, KL divergence metrics on ambiguity-related attributes, and human-rated alignment scores between synthetic and held-out real logs. These additions will appear in an expanded §3. revision: yes
-
Referee: [Abstract, Experiments] Abstract and experimental section: The accuracy, correction-rate, and audited-accuracy figures are stated without dataset sizes, baseline model details, error bars, ablation results, or statistical significance tests, preventing assessment of whether the reported improvements are load-bearing or sensitive to experimental controls.
Authors: We agree that comprehensive reporting of experimental details is essential for reproducibility and assessment of robustness. In the revised version, we will expand the experimental section to report training and test dataset sizes, full descriptions of all baseline models, standard deviations or error bars from repeated experiments, complete ablation results, and appropriate statistical significance tests for the accuracy gains. Updated tables and text will reflect these additions. revision: yes
Circularity Check
No circularity; empirical training and evaluation pipeline
full rationale
The paper describes an automated data synthesis workflow from user logs and LLMs, followed by curriculum learning, cold-start training, RL with domain rules, and token compression. All headline results (20.01% accuracy gain, production metrics) are presented as direct outcomes of training and deployment evaluation rather than any derivation, fitted parameter, or self-citation that reduces to the inputs by construction. No equations or mathematical claims appear; the work is self-contained as standard empirical ML.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Yushi Bai, Xin Lv, Jiajie Zhang, Yuze He, Ji Qi, Lei Hou, Jie Tang, Yuxiao Dong, and Juanzi Li. 2024. LongAlign: A Recipe for Long Context Alignment of Large Language Models. InFindings of the Association for Computational Linguistics: EMNLP
2024
- [2]
-
[3]
Yi Gao, Kaijie Xiao, Fu Li, Weifeng Xu, Jiaming Huang, and Wei Dong. 2024. ChatIoT: Zero-code Generation of Trigger-action Based IoT Programs.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies (IMWUT) 8, 3, Article 103 (2024)
2024
-
[4]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al . 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Chuang Hu, Wei Bao, Dan Wang, and Fengming Liu. 2019. Dynamic Adaptive DNN Surgery for Inference Acceleration on the Edge. InProceedings of the IEEE Conference on Computer Communications (INFOCOM)
2019
-
[7]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. 2024. Gpt-4o system card.arXiv preprint arXiv:2410.21276(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [8]
-
[9]
Ehsan Kamalloo, Nouha Dziri, Charles Clarke, and Davood Rafiei. 2023. Evalu- ating open-domain question answering in the era of large language models. In Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL)
2023
-
[10]
Minjeong Kim, Gyuwan Kim, Sang-Woo Lee, and Jung-Woo Ha. 2021. St-bert: Cross-modal language model pre-training for end-to-end spoken language un- derstanding. InIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 7478–7482
2021
-
[11]
Evan King, Haoxiang Yu, Sangsu Lee, and Christine Julien. 2024. Sasha: Creative Goal-Oriented Reasoning in Smart Homes with Large Language Models.Pro- ceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies (IMWUT)8, 1, Article 12 (2024)
2024
-
[12]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al
-
[13]
In Advances in Neural Information Processing Systems (NeurIPS)
Retrieval-augmented generation for knowledge-intensive nlp tasks. In Advances in Neural Information Processing Systems (NeurIPS)
-
[14]
Yuhao Lin, Zhipeng Tang, Jiayan Tong, Junqing Xiao, Bin Lu, Yuhang Li, Chao Li, Zhiguo Zhang, Junhua Wang, Hao Luo, et al. 2026. FuxiShuffle: An Adaptive and Resilient Shuffle Service for Distributed Data Processing on Alibaba Cloud. arXiv preprint arXiv:2602.22580(2026). KDD 2026, August 9–13, 2026, Jeju Island, Republic of Korea. Haowei Han et al
-
[15]
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al . 2025. Deepseek- v3.2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Renze Lou, Kai Zhang, and Wenpeng Yin. 2024. Large language model instruction following: A survey of progresses and challenges.Computational Linguistics50, 3 (2024), 1053–1095
2024
-
[17]
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al
-
[18]
Self-refine: Iterative refinement with self-feedback.Advances in Neural Information Processing Systems (NeurIPS)(2023)
2023
-
[19]
Mahda Noura, Sebastian Heil, and Martin Gaedke. 2020. VISH: Does Your Smart Home Dialogue System Also Need Training Data?. InWeb Engineering, Maria Bielikova, Tommi Mikkonen, and Cesare Pautasso (Eds.). 171–187
2020
- [20]
-
[21]
Subhro Roy, Samuel Thomson, Tongfei Chen, Richard Shin, Adam Pauls, Jason Eisner, and Benjamin Van Durme. 2023. Benchclamp: A Benchmark for Evaluating Language Models on Syntactic and Semantic Parsing. InAdvances in Neural Information Processing Systems (NeurIPS)
2023
-
[22]
Pranab Sahoo, Ayush Kumar Singh, Sriparna Saha, Vinija Jain, Samrat Mondal, and Aman Chadha. 2024. A systematic survey of prompt engineering in large language models: Techniques and applications.arXiv preprint arXiv:2402.07927 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Tom Silver, Varun Hariprasad, Reece S Shuttleworth, Nishanth Kumar, Tomás Lozano-Pérez, and Leslie Pack Kaelbling. 2022. PDDL planning with pretrained large language models. InProceedings of the NeurIPS 2022 Workshop on Foundation Models for Decision Making
2022
-
[25]
Stefanie Tellex, Thomas Kollar, Steven Dickerson, Matthew Walter, Ashis Baner- jee, Seth Teller, and Nicholas Roy. 2011. Understanding natural language com- mands for robotic navigation and mobile manipulation. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI)
2011
-
[26]
Jianing Wang, Wenkang Huang, Minghui Qiu, Qiuhui Shi, Hongbin Wang, Xiang Li, and Ming Gao. 2022. Knowledge Prompting in Pre-trained Language Model for Natural Language Understanding. InProceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP)
2022
-
[27]
Yuxiang Wang, Chi Ma, Xiao Yan, Mincong Huang, Xiaoguang Li, Ruidong Han, Bin Yin, Shangyu Chen, Xiang Li, Fei Jiang, Lei Yu, Chuan Liu, Wei Lin, Haowei Han, Xiaokai Zhou, Bo Du, and Jiawei Jiang. 2026. MTGenRec: An Efficient Distributed Training System for Generative Recommendation Models in Meituan. InProceedings of the ACM SIGKDD Conference on Knowledg...
2026
-
[28]
Gang Wu, Liang Hu, Yuxiao Hu, Xingbo Xiong, and Feng Wang. 2025. LLM4TAP: LLM-Enhanced TAP Rule Recommendation.IEEE Internet of Things Journal12, 10 (2025), 13157–13169
2025
- [29]
-
[30]
Benfeng Xu, Licheng Zhang, Zhendong Mao, Quan Wang, Hongtao Xie, and Yongdong Zhang. 2020. Curriculum learning for natural language understand- ing. InProceedings of the Annual Meeting of the Association for Computational Linguistics (ACL)
2020
-
[31]
Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, and Daxin Jiang. 2023. Wizardlm: Empowering large language models to follow complex instructions. InProceedings of International Conference on Learning Representations (ICLR)
2023
-
[32]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Fangkai Yang, Pu Zhao, Zezhong Wang, Lu Wang, Bo Qiao, Jue Zhang, Mohit Garg, Qingwei Lin, Saravan Rajmohan, and Dongmei Zhang. 2023. Empower large language model to perform better on industrial domain-specific question answering. InProceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP))
2023
-
[34]
Jianxin Yang. 2023. Firefly. https://github.com/yangjianxin1/Firefly
2023
-
[35]
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. 2025. Dapo: An open- source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Zelle and Raymond J
John M. Zelle and Raymond J. Mooney. 1993. Learning semantic grammars with constructive inductive logic programming. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI)
1993
-
[37]
Shengyu Zhang, Linfeng Dong, Xiaoya Li, Sen Zhang, Xiaofei Sun, Shuhe Wang, Jiwei Li, Runyi Hu, Tianwei Zhang, Guoyin Wang, and Fei Wu. 2026. Instruction Tuning for Large Language Models: A Survey.ACM Computing Survey(2026)
2026
-
[38]
Zhuosheng Zhang, Yuwei Wu, Hai Zhao, Zuchao Li, Shuailiang Zhang, Xi Zhou, and Xiang Zhou. 2020. Semantics-aware BERT for language understanding. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI)
2020
-
[39]
Xue Zhao, Hanyu Zhao, Sha Yuan, and Yequan Wang. 2022. WuDaoCorpora Text. doi:10.57760/sciencedb.o00126.00004
-
[40]
Haoyu Zheng, Fangcheng Fu, Jia Wu, Binhang Yuan, Yongqiang Zhang, Hao Wang, Yuanyuan Zhu, Xiao Yan, and Jiawei Jiang. 2026. Efficient Serving for Dynamic Agent Workflows with Prediction-based KV-Cache Management.arXiv preprint arXiv:2605.06472(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[41]
Haoyu Zheng, Yongqiang Zhang, Fangcheng Fu, Xiaokai Zhou, Hao Luo, Hongchao Zhu, Yuanyuan Zhu, Hao Wang, Xiao Yan, and Jiawei Jiang. 2026. Scheduling LLM Inference with Uncertainty-Aware Output Length Predictions. arXiv preprint arXiv:2604.00499(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[42]
Instruction-Following Evaluation for Large Language Models
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. 2023. Instruction-following evaluation for large language models.arXiv preprint arXiv:2311.07911(2023). A Dataset Detail The DevCmd dataset comprises 50K samples across 28 distinct smart device categories, covering a comprehensive range of modern sma...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.