STARFISH: faST Accuracy Recovery in pruned networks From Internal State Healing
Pith reviewed 2026-06-28 17:23 UTC · model grok-4.3
The pith
Pruned neural networks recover most accuracy by aligning internal states with the original model on a tiny unlabeled set.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
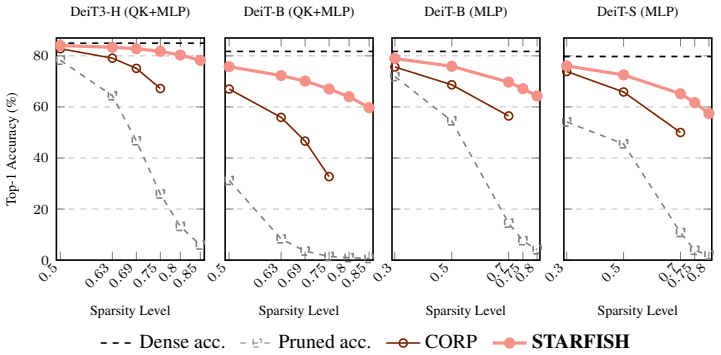
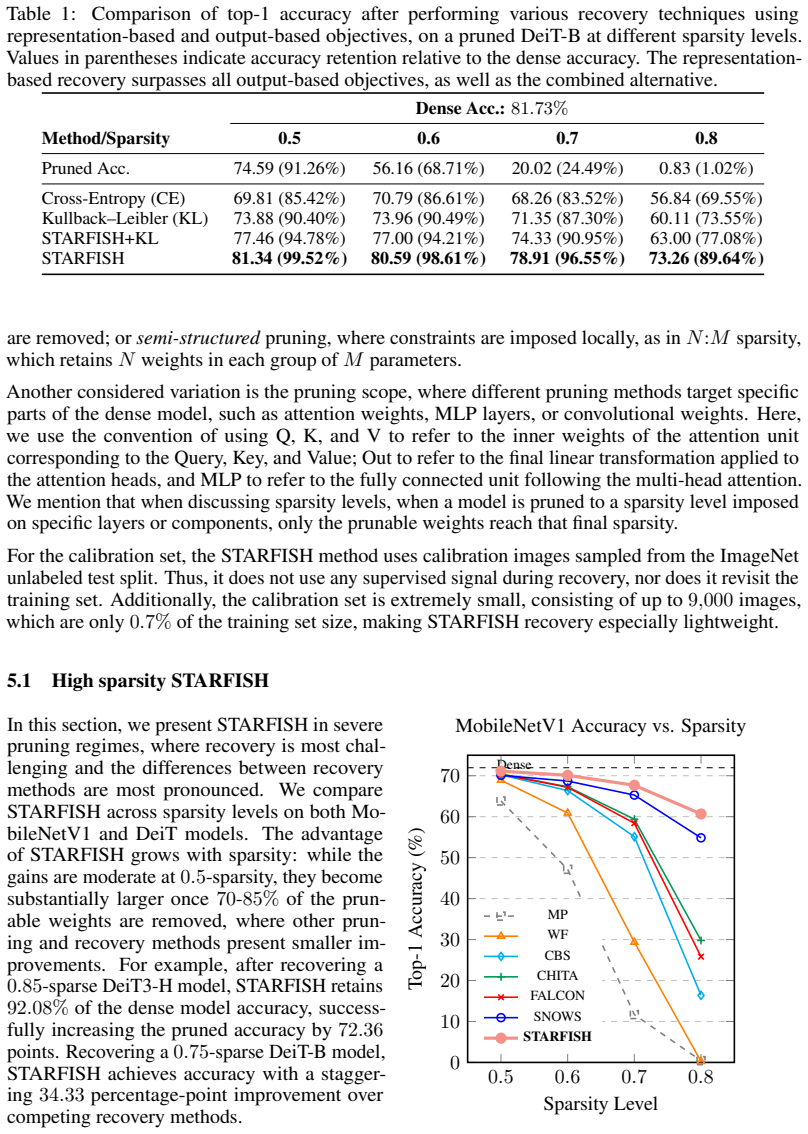
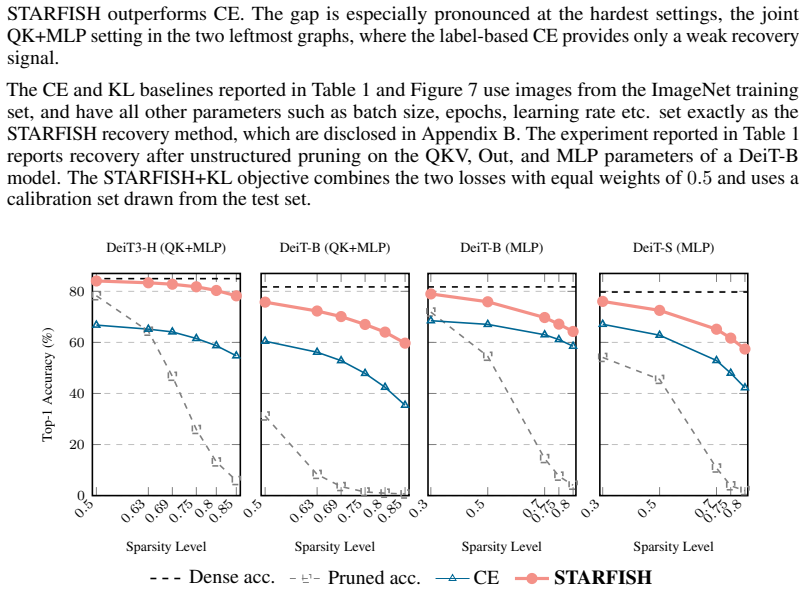
The paper claims that optimizing the pruned network to align its internal state representations with those of the original network using a tiny unlabeled calibration set recovers substantially more accuracy than existing healing techniques. On ViT-based networks this yields up to 22 percent better recovered accuracy after 50 percent weight removal; after 75 percent removal in a DeiT-B network for ImageNet it reaches 82 percent of the dense model's accuracy with only 0.4 percent of the training images as calibration data while competing methods reach only 40 percent.
What carries the argument
Internal state alignment optimization that minimizes differences in activations between the pruned and original networks on unlabeled examples.
If this is right
- At 50 percent pruning the method improves recovered accuracy by up to 22 percent over state-of-the-art healing on ViT networks.
- At 75 percent pruning on DeiT-B it recovers 82 percent of original accuracy using only 0.4 percent of training images as calibration.
- Healing succeeds without labeled data or complete retraining of the model.
- The advantage grows with more aggressive pruning ratios.
Where Pith is reading between the lines
- The alignment approach might extend to compression methods other than unstructured pruning.
- Internal representations appear to encode enough task information that matching them substitutes for label-driven fine-tuning.
- The small calibration requirement suggests possible on-device adaptation using private user data without sharing labels.
Load-bearing premise
That optimizing the pruned network to align its internal state representations with those of the original network using only a tiny unlabeled calibration set will reliably recover accuracy without requiring labeled data or full retraining.
What would settle it
If STARFISH applied to the 75-percent-pruned DeiT-B model on ImageNet with 0.4 percent unlabeled calibration data fails to exceed the 40 percent recovery level of competing methods, the superiority claim would be falsified.
Figures


read the original abstract
Pruning is a process designed to reduce the number of weights in a large neural network. This can substantially speed up inference but might cause a considerable reduction in the model's accuracy, and thus it is usually followed by a healing process that regains some of the lost accuracy. In this paper, we propose a new healing method, STARFISH, that can recover (most of) the accuracy of any pruned network efficiently. The main idea of STARFISH is to optimize the pruned network to align with the original network's internal state representations using a tiny calibration set of unlabeled examples. For the common case of removing 50% of the weights, STARFISH healing improves the recovered accuracy by up to 22% over the state-of-the-art methods on ViT-based networks. Its advantage is even more pronounced under aggressive pruning. For example, after eliminating 75% of the weights in a DeiT-B network for ImageNet, STARFISH uses only 0.4% of the number of training images as a calibration set and recovers 82% of the original dense accuracy, whereas competing recovery techniques reach only 40% of the dense model accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes STARFISH, a pruning healing technique that recovers accuracy in pruned networks by aligning their internal state representations to those of the original dense model using a tiny unlabeled calibration set. It claims superior performance over state-of-the-art methods, with up to 22% better accuracy recovery for 50% pruning on ViT networks and, notably, 82% recovery of dense accuracy after 75% pruning on DeiT-B for ImageNet using only 0.4% of training images, compared to 40% for competitors.
Significance. Should the empirical results be reproducible and generalizable, the method offers a promising direction for efficient post-pruning recovery in large vision transformers, potentially lowering the barrier for deploying compressed models by minimizing data requirements and eliminating the need for labeled data in the healing phase. The internal state healing approach, if shown to work without overfitting to the calibration set, represents a practical advance in the field of model compression.
major comments (2)
- [Abstract] Abstract: The central claims regarding accuracy recovery percentages (e.g., 82% vs. 40% after 75% pruning) are stated without any accompanying description of the optimization objective, the specific internal states being aligned, the size and selection of the calibration set, or experimental protocols including number of runs and variance, which are necessary to evaluate if the results support the claims.
- [Abstract] Abstract: The assumption that matching internal activations on an unlabeled 0.4% subset of ImageNet will ensure accurate outputs on the full test distribution is load-bearing but unsupported in the provided text; no evidence or analysis is given to address potential issues with unrepresentative calibration data or lack of output-level supervision.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments on our manuscript. We address each major comment point by point below and will revise the abstract to improve clarity where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims regarding accuracy recovery percentages (e.g., 82% vs. 40% after 75% pruning) are stated without any accompanying description of the optimization objective, the specific internal states being aligned, the size and selection of the calibration set, or experimental protocols including number of runs and variance, which are necessary to evaluate if the results support the claims.
Authors: We agree that the abstract is highly condensed and could better contextualize the claims for readers. The optimization objective (minimizing distance between internal activations), the specific states aligned, calibration set details, and experimental protocols (including runs and variance) are fully described in Sections 3 and 4. In the revised version we will add a concise clause to the abstract referencing these elements without exceeding length limits. revision: yes
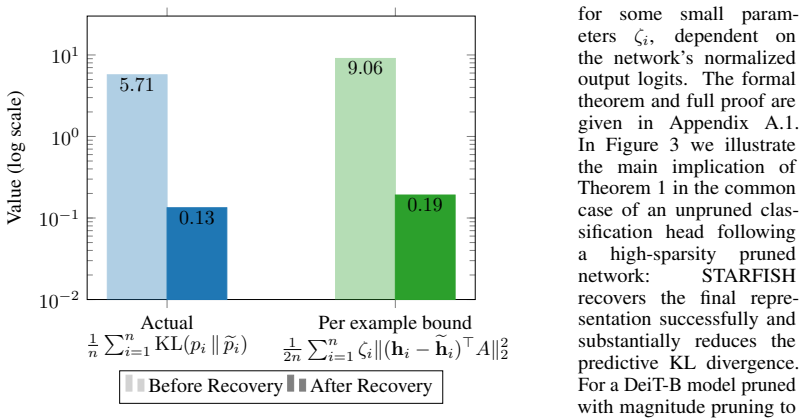
-
Referee: [Abstract] Abstract: The assumption that matching internal activations on an unlabeled 0.4% subset of ImageNet will ensure accurate outputs on the full test distribution is load-bearing but unsupported in the provided text; no evidence or analysis is given to address potential issues with unrepresentative calibration data or lack of output-level supervision.
Authors: The full manuscript provides empirical support for this assumption through generalization results across multiple architectures and pruning ratios (Section 4), plus robustness analysis to calibration set choice (Section 4.2). The lack of output-level supervision is intentional and validated by the observed correlation between internal alignment and test accuracy. We will add a brief supporting sentence to the abstract or introduction in revision. revision: partial
Circularity Check
No derivation chain; purely empirical method
full rationale
The paper proposes STARFISH as an optimization-based healing procedure that aligns internal activations of a pruned network to those of the dense model on a small unlabeled calibration set. No equations, fitted parameters, uniqueness theorems, or self-citations are presented as load-bearing steps in any derivation. All reported gains (e.g., 82% vs. 40% recovery) are experimental outcomes on ImageNet/ViT models, not quantities that reduce to the method's own inputs by construction. The approach is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Fast as chita: Neural network pruning with combinatorial optimization
Riade Benbaki, Wenyu Chen, Xiang Meng, Hussein Hazimeh, Natalia Ponomareva, Zhe Zhao, and Rahul Mazumder. Fast as chita: Neural network pruning with combinatorial optimization. InInternational Conference on Machine Learning, pages 2031–2049. PMLR, 2023
2031
-
[2]
Optimal brain connection: Towards efficient structural pruning.arXiv preprint arXiv:2508.05521, 2025
Shaowu Chen, Wei Ma, Binhua Huang, Qingyuan Wang, Guoxin Wang, Weize Sun, Lei Huang, and Deepu John. Optimal brain connection: Towards efficient structural pruning.arXiv preprint arXiv:2508.05521, 2025
-
[3]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. InInternational Conference on Machine Learning, pages 1597–1607. PMLR, 2020
2020
-
[4]
Imagenet: A large- scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large- scale hierarchical image database. In2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009
2009
-
[5]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[6]
Self-supervised representation learning: Introduction, advances, and challenges.IEEE Signal Processing Magazine, 39(3):42–62, 2022
Linus Ericsson, Henry Gouk, Chen Change Loy, and Timothy M Hospedales. Self-supervised representation learning: Introduction, advances, and challenges.IEEE Signal Processing Magazine, 39(3):42–62, 2022
2022
-
[7]
The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks
Jonathan Frankle and Michael Carbin. The lottery ticket hypothesis: Finding sparse, trainable neural networks.arXiv preprint arXiv:1803.03635, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[8]
Stabilizing the lottery ticket hypothesis,
Jonathan Frankle, Gintare Karolina Dziugaite, Daniel M Roy, and Michael Carbin. Stabilizing the lottery ticket hypothesis.arXiv preprint arXiv:1903.01611, 2019
-
[9]
Sparsegpt: Massive language models can be accurately pruned in one-shot
Elias Frantar and Dan Alistarh. Sparsegpt: Massive language models can be accurately pruned in one-shot. InInternational Conference on Machine Learning, pages 10323–10337. PMLR, 2023
2023
-
[10]
Bootstrap your own latent-a new approach to self-supervised learning.Advances in Neural Information Processing Systems, 33:21271–21284, 2020
Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Guo, Mohammad Gheshlaghi Azar, et al. Bootstrap your own latent-a new approach to self-supervised learning.Advances in Neural Information Processing Systems, 33:21271–21284, 2020
2020
-
[11]
Learning both weights and connections for efficient neural network.Advances in Neural Information Processing Systems, 28, 2015
Song Han, Jeff Pool, John Tran, and William Dally. Learning both weights and connections for efficient neural network.Advances in Neural Information Processing Systems, 28, 2015
2015
-
[12]
Babak Hassibi and David G. Stork. Second order derivatives for network pruning: Optimal brain surgeon. InAdvances in Neural Information Processing Systems, volume 5, 1992
1992
-
[13]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[14]
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
Andrew G Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, and Hartwig Adam. Mobilenets: Efficient convolutional neural networks for mobile vision applications.arXiv preprint arXiv:1704.04861, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[15]
Similarity of neural network representations revisited
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Similarity of neural network representations revisited. InInternational Conference on Machine Learning, pages 3519–3529. PMLR, 2019
2019
-
[16]
Soft threshold weight reparameterization for learnable sparsity
Aditya Kusupati, Vivek Ramanujan, Raghav Somani, Mitchell Wortsman, Prateek Jain, Sham Kakade, and Ali Farhadi. Soft threshold weight reparameterization for learnable sparsity. In International conference on machine learning, pages 5544–5555. PMLR, 2020. 10
2020
-
[17]
Cap: Correlation-aware pruning for highly-accurate sparse vision models.Advances in Neural Information Processing Systems, 36:28805–28831, 2023
Denis Kuznedelev, Eldar Kurti ´c, Elias Frantar, and Dan Alistarh. Cap: Correlation-aware pruning for highly-accurate sparse vision models.Advances in Neural Information Processing Systems, 36:28805–28831, 2023
2023
-
[18]
A fast post-training pruning framework for transformers.Advances in Neural Information Processing Systems, 35:24101–24116, 2022
Woosuk Kwon, Sehoon Kim, Michael W Mahoney, Joseph Hassoun, Kurt Keutzer, and Amir Gholami. A fast post-training pruning framework for transformers.Advances in Neural Information Processing Systems, 35:24101–24116, 2022
2022
-
[19]
Optimal brain damage.Advances in Neural Information Processing Systems, 2:598–605, 1989
Yann LeCun, John Denker, and Sara Solla. Optimal brain damage.Advances in Neural Information Processing Systems, 2:598–605, 1989
1989
-
[20]
Ryan Lucas and Rahul Mazumder. Preserving deep representations in one-shot pruning: A hessian-free second-order optimization framework.arXiv preprint arXiv:2411.18376, 2024
-
[21]
Proving the lottery ticket hypothesis: Pruning is all you need
Eran Malach, Gilad Yehudai, Shai Shalev-Schwartz, and Ohad Shamir. Proving the lottery ticket hypothesis: Pruning is all you need. InInternational Conference on Machine Learning, pages 6682–6691. PMLR, 2020
2020
-
[22]
Falcon: Flop-aware com- binatorial optimization for neural network pruning
Xiang Meng, Wenyu Chen, Riade Benbaki, and Rahul Mazumder. Falcon: Flop-aware com- binatorial optimization for neural network pruning. InInternational Conference on Artificial Intelligence and Statistics, pages 4384–4392. PMLR, 2024
2024
-
[23]
Softmax is 1/2-lipschitz: A tight bound across all ℓp norms.arXiv preprint arXiv:2510.23012, 2025
Pravin Nair. Softmax is 1/2-lipschitz: A tight bound across all ℓp norms.arXiv preprint arXiv:2510.23012, 2025
-
[24]
An Introduction to Convolutional Neural Networks
Keiron O’Shea and Ryan Nash. An introduction to convolutional neural networks.arXiv preprint arXiv:1511.08458, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[25]
What’s hidden in a randomly weighted neural network? InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11893–11902, 2020
Vivek Ramanujan, Mitchell Wortsman, Aniruddha Kembhavi, Ali Farhadi, and Mohammad Rastegari. What’s hidden in a randomly weighted neural network? InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11893–11902, 2020
2020
-
[26]
Comparing rewinding and fine-tuning in neural network pruning.arXiv preprint arXiv:2003.02389, 2020
Alex Renda, Jonathan Frankle, and Michael Carbin. Comparing rewinding and fine-tuning in neural network pruning.arXiv preprint arXiv:2003.02389, 2020
-
[27]
FitNets: Hints for Thin Deep Nets
Adriana Romero, Nicolas Ballas, Samira Ebrahimi Kahou, Antoine Chassang, Carlo Gatta, and Yoshua Bengio. Fitnets: Hints for thin deep nets, 2015. URL https://arxiv.org/abs/ 1412.6550
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[28]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter.arXiv preprint arXiv:1910.01108, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[29]
Woodfisher: Efficient second-order approximation for neural network compression.Advances in Neural Information Processing Systems, 33:18098–18109, 2020
Sidak Pal Singh and Dan Alistarh. Woodfisher: Efficient second-order approximation for neural network compression.Advances in Neural Information Processing Systems, 33:18098–18109, 2020
2020
-
[30]
Contrastive representation distillation
Yonglong Tian, Dilip Krishnan, and Phillip Isola. Contrastive representation distillation. In International Conference on Learning Representations (ICLR), 2020
2020
-
[31]
Training data-efficient image transformers & distillation through attention
Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Hervé Jégou. Training data-efficient image transformers & distillation through attention. In International Conference on Machine Learning, pages 10347–10357. PMLR, 2021
2021
-
[32]
Deit iii: Revenge of the vit
Hugo Touvron, Matthieu Cord, and Hervé Jégou. Deit iii: Revenge of the vit. InEuropean Conference on Computer Vision, pages 516–533. Springer, 2022
2022
-
[33]
The combinatorial brain sur- geon: Pruning weights that cancel one another in neural networks
Xin Yu, Thiago Serra, Srikumar Ramalingam, and Shandian Zhe. The combinatorial brain sur- geon: Pruning weights that cancel one another in neural networks. InInternational Conference on Machine Learning, pages 25668–25683. PMLR, 2022
2022
-
[34]
Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer
Sergey Zagoruyko and Nikos Komodakis. Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. InInternational Conference on Learning Representations (ICLR), 2017. 11
2017
-
[35]
CORP: Closed-Form One-shot Representation-Preserving Structured Pruning for Transformers
Boxiang Zhang and Baijian Yang. Corp: Closed-form one-shot representation-preserving structured pruning for vision transformers.arXiv preprint arXiv:2602.05243, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
Savit: Structure-aware vision transformer pruning via collaborative optimization.Advances in Neural Information Processing Systems, 35:9010–9023, 2022
Chuanyang Zheng, Kai Zhang, Zhi Yang, Wenming Tan, Jun Xiao, Ye Ren, Shiliang Pu, et al. Savit: Structure-aware vision transformer pruning via collaborative optimization.Advances in Neural Information Processing Systems, 35:9010–9023, 2022
2022
-
[37]
To prune, or not to prune: exploring the efficacy of pruning for model compression
Michael Zhu and Suyog Gupta. To prune, or not to prune: exploring the efficacy of pruning for model compression.arXiv preprint arXiv:1710.01878, 2017. A Representation alignment A.1 Representation bound for KL divergence We state the definitions and the theorem from Section 4. For an input xi ∈S cal, we denote by hi,ehi ∈R dout the last hidden representat...
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[38]
Hence ζi ≤ 1 2 , and consequently Z 1 0 (1−t) ∆z ⊤ i ∇2ψ(zi +t∆z i)∆zi dt≤ 1 4 ∥∆zi∥2 2
But its Jacobian is the Hessian of the log-sum-exp function, thus for every t∈[0,1] , ∆z⊤ i ∇2ψ(zi +t∆z i)∆zi ≤ 1 2 ∥∆zi∥2 2. Hence ζi ≤ 1 2 , and consequently Z 1 0 (1−t) ∆z ⊤ i ∇2ψ(zi +t∆z i)∆zi dt≤ 1 4 ∥∆zi∥2 2. From (4) we get KL(pi ∥epi)≤ 1 2 ζi∥∆zi∥2 2 ≤ 1 4 ∥∆zi∥2 2.(6) It remains to relate the logit error to representation and head recovery. Since...
-
[39]
Although this bound still upper-bounds the empirical KL divergence, it is much looser than the local, batch-dependent bound
Substituting these worst-case constants yields the global bound shown in Figure 5. Although this bound still upper-bounds the empirical KL divergence, it is much looser than the local, batch-dependent bound. Figure 6 visualizes the empirical distributions of Mi and ζi over the calibration examples and compares them to their corresponding global upper boun...
2000
-
[40]
A.2 Recovery vs
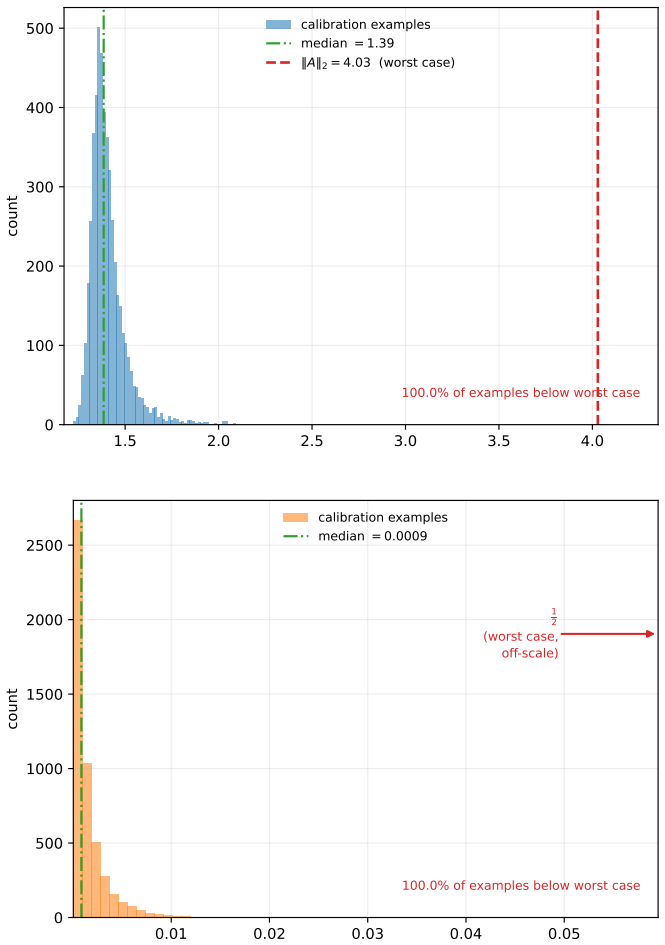
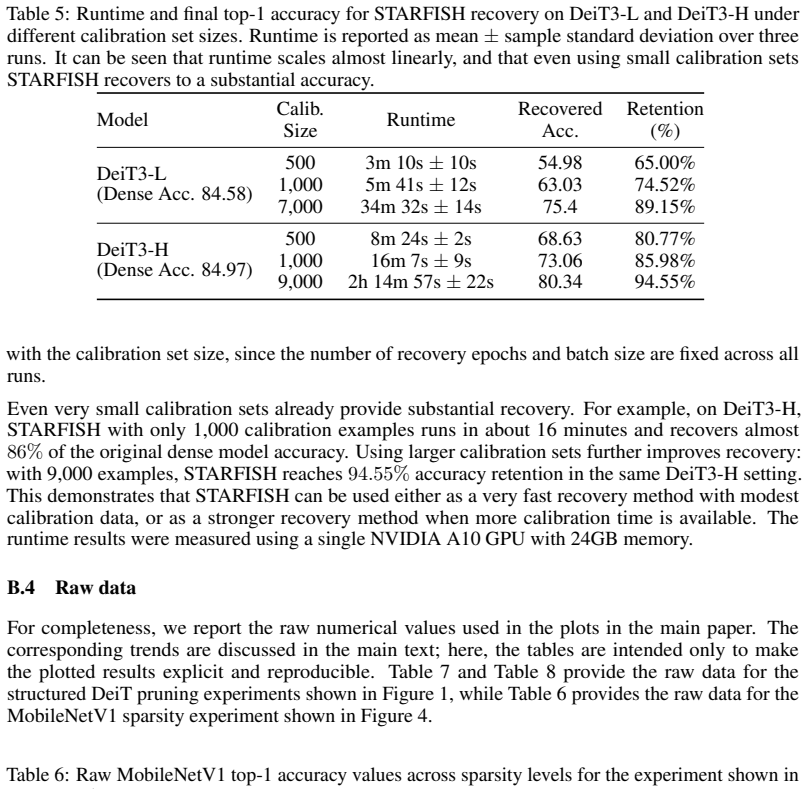
In both cases, the realized data-dependent quantities are substantially smaller than their worst-case bounds, explaining why the local batch-dependent KL bound in Figure 5 is much tighter than the corresponding global bound. A.2 Recovery vs. fine-tuning: further experiment and details In Section 4.1, we compared STARFISH to standard output-level recovery ...
1965
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.