Expected Value Alignment for Generative Reward Modeling in Formal Mathematics Verification
Pith reviewed 2026-06-28 17:30 UTC · model grok-4.3
The pith
Expected Value Alignment extracts continuous reward scores from a generative model's token logits on integer anchors while preserving discrete JSON output.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
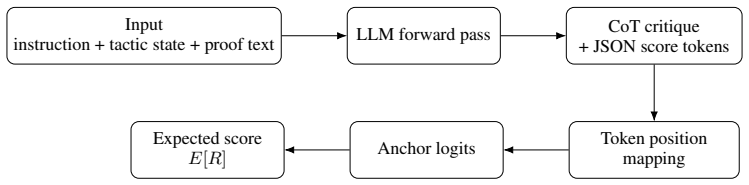
Expected Value Alignment enables a generative reward model to output both textual rationales and continuous scores by treating the integer score tokens as anchors and computing the expected value of the model's probability distribution over their logits, trained jointly with causal language modeling and an auxiliary regression loss.
What carries the argument
Expected Value Alignment (EVA), the procedure that derives a continuous reward as the expectation over logits of the anchor tokens for the integer score emitted in the model's structured JSON output.
If this is right
- The generative interface remains unchanged so textual rationales stay available for inspection.
- Discretization artifacts from tokenizing numeric values are reduced by using the full token distribution.
- The auxiliary loss on expected values allows joint optimization of language modeling and reward accuracy.
- Continuous scores become directly usable in reinforcement learning loops or best-first search for formal proofs.
Where Pith is reading between the lines
- The same expectation trick could be applied to other generative tasks that need numeric outputs without adding a separate regression head.
- Calibration quality of the resulting scores could be checked by measuring rank correlation against human ratings of reasoning step quality.
- If the base model's token probabilities remain poorly calibrated on score tokens, the continuous signals may still require post-hoc temperature scaling or other corrections.
Load-bearing premise
The expectation taken over the discrete token distribution on the score anchor tokens will produce a well-calibrated continuous reward that improves downstream search or reinforcement learning rather than simply capturing token-level artifacts.
What would settle it
A direct comparison on Lean 4 benchmarks in which search or RL guided by EVA-derived scores shows no increase in proof completion rate or step-level accuracy relative to standard generative reward models that output only discrete integers.
Figures
read the original abstract
Large Language Models (LLMs) are increasingly used with formal interactive theorem provers such as Lean 4. Scaling these systems with reinforcement learning or search methods requires process reward models (PRMs) that can evaluate intermediate reasoning steps. Existing reward-model designs expose a practical trade-off. Value-head models provide continuous scores but modify the generative model interface, while generative reward models preserve textual rationales but are poorly matched to continuous floating-point regression because numeric values are split across tokens. We introduce Expected Value Alignment (EVA), a reward-modeling procedure that keeps the surface output discrete while extracting continuous scores from the model's token distribution. The model emits integer scores in a structured JSON format, and EVA computes a continuous score as the expectation over the logits of the corresponding anchor tokens. Training combines the causal language modeling objective with an auxiliary mean squared error loss on these expected values. We instantiate EVA in \textit{Leibniz}, a reward model for Lean 4 formal verification, and evaluate it against zero-shot and reward-modeling baselines. The evaluation demonstrates that continuous logit-based scoring significantly reduces discretization artifacts while retaining the interpretability of generative critiques.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Expected Value Alignment (EVA), a reward-modeling procedure for generative models used with formal theorem provers such as Lean 4. The model emits discrete integer scores in structured JSON format under a causal language modeling objective, while continuous scores are extracted as the expectation over the logits of the corresponding anchor tokens; an auxiliary MSE loss is applied to these expected values during training. The method is instantiated as the Leibniz reward model and evaluated against zero-shot and other reward-modeling baselines, with the claim that the continuous logit-based scoring reduces discretization artifacts while preserving interpretability of generative critiques.
Significance. If the central claim holds, EVA would offer a practical resolution to the trade-off between generative reward models (which support textual rationales) and value-head models (which supply continuous scores) in process reward modeling for formal verification. This could facilitate more effective integration with search and reinforcement learning pipelines for scaling LLM-based theorem proving without modifying the generative interface.
major comments (2)
- [Abstract] Abstract: The load-bearing claim is that the expectation over anchor-token logits produces a continuous reward signal that reduces discretization artifacts and improves downstream search/RL performance. However, because the auxiliary MSE is applied directly to this expectation (derived from the same generative head trained to emit discrete integers), the manuscript must demonstrate via explicit ablation or comparison that the continuous score outperforms simply using the emitted integer mode; without such evidence the reduction could be an artifact of softmax smoothing rather than calibrated new information.
- [Abstract] Abstract: The evaluation is described only at a high level (against zero-shot and reward-modeling baselines). The manuscript needs to report concrete metrics (e.g., search success rate, proof-step accuracy) showing the continuous EVA scores yield measurable gains over the discrete baseline in the actual verification pipeline; absent these numbers the downstream-benefit claim remains unverified.
minor comments (1)
- [Abstract] The abstract refers to 'anchor tokens' without defining their selection or the precise computation of the expectation; a short methods paragraph or equation would clarify the procedure.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on clarifying the benefits of continuous scoring in EVA. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The load-bearing claim is that the expectation over anchor-token logits produces a continuous reward signal that reduces discretization artifacts and improves downstream search/RL performance. However, because the auxiliary MSE is applied directly to this expectation (derived from the same generative head trained to emit discrete integers), the manuscript must demonstrate via explicit ablation or comparison that the continuous score outperforms simply using the emitted integer mode; without such evidence the reduction could be an artifact of softmax smoothing rather than calibrated new information.
Authors: We agree that a direct ablation against the emitted integer mode is required to isolate the contribution of the expectation. The current evaluations compare EVA to zero-shot and other reward-modeling baselines, but do not include this specific discrete-mode control. In the revised manuscript we will add an explicit ablation that reports downstream search success rates and proof-step accuracy when using the continuous expectation versus the integer mode, confirming that gains arise from calibrated continuous information rather than softmax smoothing alone. revision: yes
-
Referee: [Abstract] Abstract: The evaluation is described only at a high level (against zero-shot and reward-modeling baselines). The manuscript needs to report concrete metrics (e.g., search success rate, proof-step accuracy) showing the continuous EVA scores yield measurable gains over the discrete baseline in the actual verification pipeline; absent these numbers the downstream-benefit claim remains unverified.
Authors: We will revise the abstract and results sections to foreground concrete quantitative metrics. The revised version will explicitly tabulate search success rates, proof-step accuracy, and related pipeline metrics for the continuous EVA scores versus the discrete integer baseline (as well as the other baselines already present), thereby verifying the claimed downstream improvements in the Lean 4 verification setting. revision: yes
Circularity Check
No circularity: EVA is an extraction procedure with independent auxiliary loss
full rationale
The abstract and description present EVA as computing a continuous expectation over anchor-token logits from a model trained to emit discrete integer scores in JSON, combined with a standard causal LM objective plus auxiliary MSE on those expectations. No equations, self-citations, or derivations are shown that reduce the claimed continuous score to a fitted parameter or target defined by the same data; the targets for MSE are external (proof-step correctness), and the extraction step does not rename or force the output by construction. This matches the default expectation of a self-contained method without load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations , year =
Lightman, Hunter and Kosaraju, Vineet and Burda, Yura and Edwards, Harri and Baker, Bowen and Lee, Teddy and Leike, Jan and Schulman, John and Sutskever, Ilya and Cobbe, Karl , title =. International Conference on Learning Representations , year =
-
[2]
and Leike, Jan and Lowe, Ryan , title =
Ouyang, Long and Wu, Jeffrey and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and Schulman, John and Hilton, Jacob and Kelton, Fraser and Miller, Luke and Simens, Maddie and Askell, Amanda and Welinder, Peter and Christiano, Paul F. and Leike, Jan and Lowe...
-
[3]
Proximal Policy Optimization Algorithms
Schulman, John and Wolski, Filip and Dhariwal, Prafulla and Radford, Alec and Klimov, Oleg , title =. arXiv preprint arXiv:1707.06347 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Efficient Selectivity and Backup Operators in Monte-Carlo Tree Search , booktitle =
Coulom, R. Efficient Selectivity and Backup Operators in Monte-Carlo Tree Search , booktitle =
-
[5]
de Moura, Leonardo and Ullrich, Sebastian , title =. Automated Deduction -- CADE 28 , series =. doi:10.1007/978-3-030-79876-5_37 , year =
-
[6]
Generative Language Modeling for Automated Theorem Proving
Polu, Stanislas and Sutskever, Ilya , title =. arXiv preprint arXiv:2009.03393 , year =
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[7]
International Conference on Learning Representations , year =
Zheng, Kunhao and Han, Jesse Michael and Polu, Stanislas , title =. International Conference on Learning Representations , year =
-
[8]
and Gu, Alex and Chalamala, Rahul and Song, Peiyang and Yu, Shixing and Godil, Saad and Prenger, Ryan and Anandkumar, Anima , title =
Yang, Kaiyu and Swope, Aidan M. and Gu, Alex and Chalamala, Rahul and Song, Peiyang and Yu, Shixing and Godil, Saad and Prenger, Ryan and Anandkumar, Anima , title =. Advances in Neural Information Processing Systems , volume =
-
[9]
and Zhang, Hao and Gonzalez, Joseph E
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , title =. Advances in Neural Information Processing Systems , volume =
-
[10]
and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , title =
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , title =. International Conference on Learning Representations , year =
-
[11]
Yang, An and Yang, Baosong and Zhang, Beichen and Hui, Binyuan and Zheng, Bo and Yu, Bowen and Li, Chengyuan and Liu, Dayiheng and Huang, Fei and Wei, Haoran and Lin, Huan and Yang, Jian and Tu, Jianhong and Zhang, Jianwei and Yang, Jianxin and Yang, Jiaxi and Zhou, Jingren and Lin, Junyang and Dang, Kai and Lu, Keming and Bao, Keqin and Yang, Kexin and Y...
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
and Le, Quoc V
Wei, Jason and Wang, Xuezhi and Schuurmans, Dale and Bosma, Maarten and Ichter, Brian and Xia, Fei and Chi, Ed H. and Le, Quoc V. and Zhou, Denny , title =. Advances in Neural Information Processing Systems , volume =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.