Med-HEAL: Analyzing and Mitigating Hallucinations in Medical LLMs with Hallucination-Aware In-Context Learning
Pith reviewed 2026-06-28 17:15 UTC · model grok-4.3
The pith
Self-critique improves accuracy on clinical questions for three of five medical LLMs without parameter updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
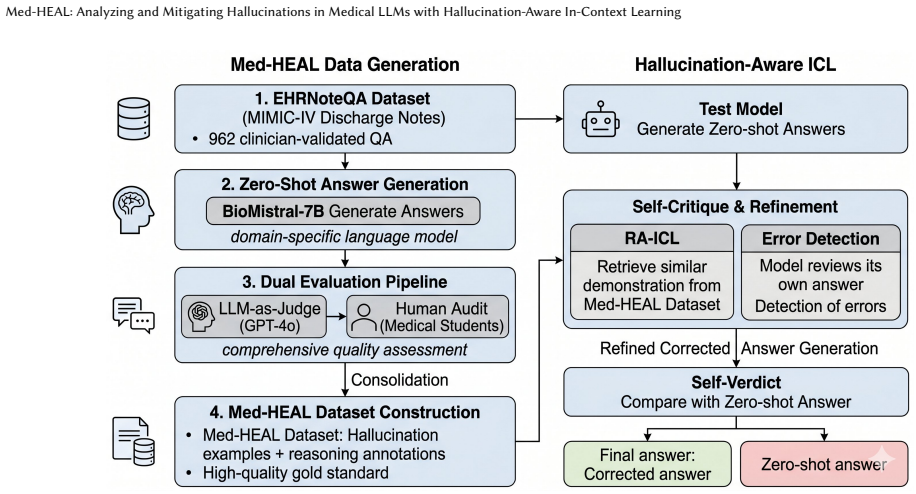
Med-HEAL constructs a hallucination dataset from BioMistral-7B responses on the EHRNoteQA benchmark drawn from MIMIC-IV discharge summaries, labels outputs via a dual GPT-4o and medical-student review pipeline, then shows that a self-critique pipeline improves accuracy for three of the five tested models (BioMistral, Llama-3.1, DeepSeek, Qwen2.5, Qwen3) at p < 0.05 while retrieval-augmented in-context learning is also examined.
What carries the argument
The self-critique pipeline in which the test model reviews its own answers to detect potential errors and regenerates responses for flagged cases.
If this is right
- Medical LLMs can achieve higher accuracy on clinical QA tasks through an inference-time self-critique step that requires no parameter changes.
- The constructed hallucination dataset with correctness judgments and reasoning-error annotations becomes reusable for studying mitigation methods.
- The same dual LLM-plus-human labeling process can be applied to annotate errors in other clinical reasoning tasks.
- Retrieval-augmented in-context learning that supplies hallucinated and corrected examples offers a second tested mitigation route.
Where Pith is reading between the lines
- The approach could be combined with human review in actual clinical workflows to catch remaining errors the model itself misses.
- Similar self-critique might reduce hallucinations when models reason over other structured medical data such as lab results or imaging reports.
- The framework provides a template for building domain-specific hallucination datasets in fields outside medicine where factual grounding matters.
- Testing whether the accuracy gains persist when questions are drawn from newer or more diverse hospital records would strengthen the result.
Load-bearing premise
The dual evaluation pipeline that combines GPT-4o judgments with medical student auditing produces reliable correctness labels and hallucination annotations.
What would settle it
Applying the identical self-critique procedure to a sixth open-source medical LLM on the same EHRNoteQA-derived questions and finding no statistically significant accuracy gain would falsify the reported benefit.
Figures
read the original abstract
Hallucinations in medical large language models (LLMs) pose serious risks for clinical decision support, particularly when models must reason over complex electronic health records (EHRs). However, existing benchmarks often lack a realistic clinical context and provide limited insight into how hallucinations can be mitigated in practice. We introduce Med-HEAL, a framework for systematically identifying, analyzing, and mitigating hallucinations in medical LLMs using clinically grounded data. Building on the EHRNoteQA benchmark derived from MIMIC-IV discharge summaries, we construct a hallucination dataset by evaluating BioMistral-7B on open-ended clinical question answering tasks. Model outputs are labeled through a dual evaluation pipeline that combines LLM-as-a-Judge assessment (GPT-4o) with human auditing by medical student reviewers, producing correctness judgments and annotations of reasoning errors via a custom web-based evaluation system. We then leverage this dataset to investigate mitigation strategies: a self-critique pipeline, in which the test model reviews its own answers to detect potential errors and regenerates responses for flagged cases, and retrieval-augmented in-context learning (RA-ICL), which exposes the model to hallucinated and corrected examples. Experiments across five open-source LLMs-BioMistral, Llama-3.1, DeepSeek, Qwen2.5, and Qwen3, show that the self-critique strategy improves accuracy for three of five models (p < 0.05) without requiring parameter updates. Med-HEAL provides both a reusable hallucination dataset and a practical framework for studying and mitigating hallucinations in medical LLMs, supporting safer deployment of AI systems in clinical environments. Our code and data are publicly available at https://github.com/yimingliao-blad/med-heal.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce the Med-HEAL framework for identifying, analyzing, and mitigating hallucinations in medical LLMs. It constructs a hallucination dataset by running BioMistral-7B on the EHRNoteQA benchmark (derived from MIMIC-IV), labeling outputs via a dual pipeline of GPT-4o LLM-as-Judge plus medical-student auditing, then tests self-critique and RA-ICL mitigation strategies across five open-source LLMs, reporting statistically significant accuracy gains (p < 0.05) from self-critique on three of the five models without parameter updates. Code and data are released publicly.
Significance. If the dual-pipeline correctness labels can be validated, the work supplies a reusable clinical hallucination dataset and a practical, training-free mitigation technique that could improve safety of LLM-based clinical QA. The public release of code and data is a clear strength for reproducibility.
major comments (1)
- [Abstract and Methods (dual evaluation pipeline)] Abstract and Methods (dual evaluation pipeline): The correctness judgments that determine both the hallucination dataset labels and the accuracy metrics rest on the dual GPT-4o + medical-student pipeline. No inter-rater agreement statistic, no validation against board-certified physicians, and no error analysis of GPT-4o medical judgments are reported. This is load-bearing for the central empirical claims.
minor comments (2)
- [Results] Results: Absolute accuracy deltas, effect sizes, and full per-model baseline tables are not provided alongside the p < 0.05 statements, making it hard to judge practical significance.
- [Abstract] Abstract: The five models are listed but exact versions, parameter counts, and which three showed improvement are not cross-referenced to the experimental tables.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the evaluation pipeline, which is indeed central to our claims. We address the concerns point-by-point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: Abstract and Methods (dual evaluation pipeline): The correctness judgments that determine both the hallucination dataset labels and the accuracy metrics rest on the dual GPT-4o + medical-student pipeline. No inter-rater agreement statistic, no validation against board-certified physicians, and no error analysis of GPT-4o medical judgments are reported. This is load-bearing for the central empirical claims.
Authors: We agree the dual pipeline requires stronger validation reporting. In revision we will: (1) compute and report inter-rater agreement (Cohen's kappa) between GPT-4o labels and medical-student audits, plus agreement among student reviewers where multiple annotations exist; (2) add an error analysis of GPT-4o judgments on a random 10% subset, categorizing disagreement types; (3) explicitly state the absence of board-certified physician validation as a limitation due to resource constraints, while noting that medical students were supervised by clinical faculty. These changes will appear in Methods, Results, and a new Limitations section. revision: partial
Circularity Check
No circularity; empirical results from external model runs on constructed dataset.
full rationale
The paper's central claim is an empirical observation: self-critique improves accuracy (p<0.05) on three of five LLMs. This is obtained by running the models, applying the mitigation strategy, and measuring accuracy via the described dual pipeline. No equations, fitted parameters renamed as predictions, or self-citation chains reduce the result to its inputs by construction. The evaluation pipeline is an external measurement step, not a self-referential definition. The work is self-contained against its own benchmarks and external models.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption GPT-4o combined with medical student review can accurately identify hallucinations and reasoning errors in clinical QA outputs
Reference graph
Works this paper leans on
-
[1]
Asma Ben Abacha, Chaitanya Shivade, and Dina Demner-Fushman. 2019. Overview of the MEDIQA 2019 shared task on textual inference, question entail- ment and question answering. InProceedings of the 18th bioNLP workshop and shared task. 370–379
2019
-
[2]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [3]
-
[4]
Monica Agrawal, Stefan Hegselmann, Hunter Lang, Yoon Kim, and David Sontag
-
[5]
In Proceedings of the 2022 conference on empirical methods in natural language processing
Large language models are few-shot clinical information extractors. In Proceedings of the 2022 conference on empirical methods in natural language processing. 1998–2022
2022
-
[6]
Ekin Akyürek, Dale Schuurmans, Jacob Andreas, Tengyu Ma, and Denny Zhou
-
[7]
What learning algorithm is in-context learning? investigations with linear models.arXiv preprint arXiv:2211.15661(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
Asma Ben Abacha and Dina Demner-Fushman. 2019. A question-entailment approach to question answering.BMC bioinformatics20, 1 (2019), 511
2019
-
[9]
Stephanie Cabral, Daniel Restrepo, Zahir Kanjee, Philip Wilson, Byron Crowe, Raja-Elie Abdulnour, and Adam Rodman. 2024. Clinical reasoning of a generative artificial intelligence model compared with physicians.JAMA internal medicine 184, 5 (2024), 581–583
2024
-
[10]
Zeming Chen, Alejandro Hernández Cano, Angelika Romanou, Antoine Bon- net, Kyle Matoba, Francesco Salvi, Matteo Pagliardini, Simin Fan, Andreas Köpf, Amirkeivan Mohtashami, and others. 2023. Meditron-70b: Scaling medical pre- training for large language models.arXiv preprint arXiv:2311.16079(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Philip Chung, Akshay Swaminathan, Alex J Goodell, Yeasul Kim, S Mom- sen Reincke, Lichy Han, Ben Deverett, Mohammad Amin Sadeghi, Abdel-Badih Ariss, Marc Ghanem, and others. 2025. Verifying Facts in Patient Care Docu- ments Generated by Large Language Models Using Electronic Health Records. NEJM AI3, 1 (2025), AIdbp2500418
2025
-
[12]
DeepSeek-AI. 2025. DeepSeek-R1-Distill-Llama-8B. https://huggingface.co/ deepseek-ai/DeepSeek-R1-Distill-Llama-8B
2025
-
[13]
Shehzaad Dhuliawala, Mojtaba Komeili, Jing Xu, Roberta Raileanu, Xian Li, Asli Celikyilmaz, and Jason Weston. 2024. Chain-of-verification reduces hallucina- tion in large language models. InFindings of the association for computational linguistics: ACL 2024. 3563–3578. Med-HEAL: Analyzing and Mitigating Hallucinations in Medical LLMs with Hallucination-Aw...
2024
-
[14]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. 2024. The Llama 3 Herd of Models.arXiv preprint arXiv:2407.21783(2024). https://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [15]
-
[16]
Shivam Garg, Dimitris Tsipras, Percy S Liang, and Gregory Valiant. 2022. What can transformers learn in-context? a case study of simple function classes.Ad- vances in neural information processing systems35 (2022), 30583–30598
2022
-
[17]
Zorik Gekhman, Gal Yona, Roee Aharoni, Matan Eyal, Amir Feder, Roi Reichart, and Jonathan Herzig. 2024. Does fine-tuning llms on new knowledge encourage hallucinations?. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 7765–7784
2024
-
[18]
Ian J Goodfellow, Mehdi Mirza, Da Xiao, Aaron Courville, and Yoshua Bengio
-
[19]
An empirical investigation of catastrophic forgetting in gradient-based neural networks.arXiv preprint arXiv:1312.6211(2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[20]
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, and others. 2024. A survey on llm-as-a-judge.The Innovation(2024)
2024
-
[21]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. 2025. DeepSeek-R1 incen- tivizes reasoning in LLMs through reinforcement learning.Nature645, 8081 (2025), 633–638
2025
-
[22]
Tianyu Han, Lisa C Adams, Jens-Michalis Papaioannou, Paul Grundmann, Tom Oberhauser, Alexei Figueroa, Alexander Löser, Daniel Truhn, and Keno K Bressem. 2023. MedAlpaca–an open-source collection of medical conversational AI models and training data.arXiv preprint arXiv:2304.08247(2023)
-
[23]
Yue Jiang, Jiawei Chen, Dingkang Yang, Mingcheng Li, Shunli Wang, Tong Wu, Ke Li, and Lihua Zhang. 2025. Comt: Chain-of-medical-thought reduces hallu- cination in medical report generation. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5
2025
-
[24]
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. 2021. What disease does this patient have? a large-scale open domain question answering dataset from medical exams.Applied Sciences11, 14 (2021), 6421
2021
-
[25]
Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William Cohen, and Xinghua Lu. 2019. Pubmedqa: A dataset for biomedical research question answering. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP). 2567–2577
2019
-
[26]
Alistair Johnson, Lucas Bulgarelli, Tom Pollard, Steven Horng, Leo Anthony Celi, and Roger Mark. 2020. Mimic-iv.PhysioNet. A vailable online at: https://physionet. org/content/mimiciv/1.0/(accessed August 23, 2021)(2020), 49–55
2020
-
[27]
Alistair EW Johnson, Tom J Pollard, Lu Shen, Li-wei H Lehman, Mengling Feng, Mohammad Ghassemi, Benjamin Moody, Peter Szolovits, Leo Anthony Celi, and Roger G Mark. 2016. MIMIC-III, a freely accessible critical care database. Scientific data3, 1 (2016), 1–9
2016
- [28]
-
[29]
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. 2017. Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences114, 13 (2017), 3521– 3526
2017
-
[30]
Sunjun Kweon, Jiyoun Kim, Heeyoung Kwak, Dongchul Cha, Hangyul Yoon, Kwang Kim, Jeewon Yang, Seunghyun Won, and Edward Choi. 2024. Ehrnoteqa: An llm benchmark for real-world clinical practice using discharge summaries. Advances in Neural Information Processing Systems37 (2024), 124575–124611
2024
-
[31]
Yanis Labrak, Adrien Bazoge, Emmanuel Morin, Pierre-antoine Gourraud, Mick- aël Rouvier, and Richard Dufour. 2024. BioMistral: a collection of open-source pretrained large language models for medical domains. In62th annual meeting of the association for computational linguistics (ACL’24)
2024
-
[32]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, and others. 2020. Retrieval-augmented generation for knowledge- intensive nlp tasks.Advances in neural information processing systems33 (2020), 9459–9474
2020
-
[33]
Yuchong Li, Xiaojun Zeng, Chihua Fang, Jian Yang, Fucang Jia, and Lei Zhang
- [34]
-
[35]
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023. G-eval: NLG evaluation using gpt-4 with better human alignment. InProceedings of the 2023 conference on empirical methods in natural language processing. 2511–2522
2023
-
[36]
Man Luo, Xin Xu, Zhuyun Dai, Panupong Pasupat, Mehran Kazemi, Chitta Baral, Vaiva Imbrasaite, and Vincent Y Zhao. 2024. Dr. ICL: Demonstration-retrieved in-context learning.Data Intelligence6, 4 (2024), 909–922
2024
-
[37]
Renqian Luo, Liai Sun, Yingce Xia, Tao Qin, Sheng Zhang, Hoifung Poon, and Tie-Yan Liu. 2022. BioGPT: generative pre-trained transformer for biomedical text generation and mining.Briefings in Bioinformatics23, 6 (2022)
2022
- [38]
-
[39]
Jianmo Ni, Chen Qu, Jing Lu, Zhuyun Dai, Gustavo Hernandez Abrego, Ji Ma, Vincent Zhao, Yi Luan, Keith Hall, Ming-Wei Chang, et al . 2022. Large dual encoders are generalizable retrievers. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 9844–9855
2022
- [40]
- [41]
-
[42]
2009.The probabilistic relevance frame- work: BM25 and beyond
Stephen Robertson and Hugo Zaragoza. 2009.The probabilistic relevance frame- work: BM25 and beyond. Vol. 4. Now Publishers Inc
2009
-
[43]
Walter J Rogan and Beth Gladen. 1978. Estimating prevalence from the results of a screening test.American journal of epidemiology107, 1 (1978), 71–76
1978
-
[44]
Ohad Rubin, Jonathan Herzig, and Jonathan Berant. 2022. Learning to retrieve prompts for in-context learning. InProceedings of the 2022 conference of the North American chapter of the association for computational linguistics: human language technologies. 2655–2671
2022
-
[45]
Karan Singhal, Shekoofeh Azizi, Tao Tu, S Sara Mahdavi, Jason Wei, Hyung Won Chung, Nathan Scales, Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl, and others. 2023. Large language models encode clinical knowledge.Nature620, 7972 (2023), 172–180
2023
-
[46]
Karan Singhal, Tao Tu, Juraj Gottweis, Rory Sayres, Ellery Wulczyn, Mohamed Amin, Le Hou, Kevin Clark, Stephen R Pfohl, Heather Cole-Lewis, et al . 2025. Toward expert-level medical question answering with large language models. Nature medicine31, 3 (2025), 943–950
2025
-
[47]
Jun Sun, Yiteng Pan, and Xiaohu Yan. 2025. Improving intermediate reasoning in zero-shot chain-of-thought for large language models with filter supervisor-self correction.Neurocomputing620 (2025), 129219
2025
- [48]
-
[49]
Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou
-
[50]
Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers.Advances in neural information processing systems33 (2020), 5776–5788
2020
-
[51]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reason- ing in large language models.Advances in neural information processing systems 35 (2022), 24824–24837
2022
-
[52]
Chaoyi Wu, Weixiong Lin, Xiaoman Zhang, Ya Zhang, Weidi Xie, and Yanfeng Wang. 2024. PMC-LLaMA: toward building open-source language models for medicine.Journal of the American Medical Informatics Association31, 9 (2024), 1833–1843
2024
- [53]
-
[54]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tianyi T...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[56]
Cyril Zakka, Rohan Shad, Akash Chaurasia, Alex R Dalal, Jennifer L Kim, Michael Moor, Robyn Fong, Curran Phillips, Kevin Alexander, Euan Ashley, and others
-
[57]
Nejm ai1, 2 (2024), AIoa2300068
Almanac—retrieval-augmented language models for clinical medicine. Nejm ai1, 2 (2024), AIoa2300068
2024
-
[58]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems36 (2023), 46595–46623. Liao et al. A Supplementary Materials The following supplementary materials provide ex...
2023
-
[59]
These models are particularly attractive to healthcare institutions because they can run locally while maintaining competitive performance
and QwQ-32B [ 49] have shown promising performance in complex diagnostic reasoning tasks. These models are particularly attractive to healthcare institutions because they can run locally while maintaining competitive performance. B.2 Study of Medical LLM Hallucinations A growing body of work has developed benchmarks to evaluate large language models (LLMs...
-
[60]
similarly evaluate patient-specific reasoning and fact verifica- tion using real hospital records. Beyond EHRs, datasets such as MedCaseReasoning [48] leverage thousands of clinical case reports from PubMed Central to evaluate diagnostic reasoning processes, while Med-HALT [36] uses standardized medical examinations and PubMed abstracts to test hallucinat...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.