GuidaPA: Privacy-Preserving Chatbot for Public Administration via Federated Learning
Pith reviewed 2026-06-28 17:02 UTC · model grok-4.3
The pith
Federated learning trains a public administration chatbot on local data without any central pooling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
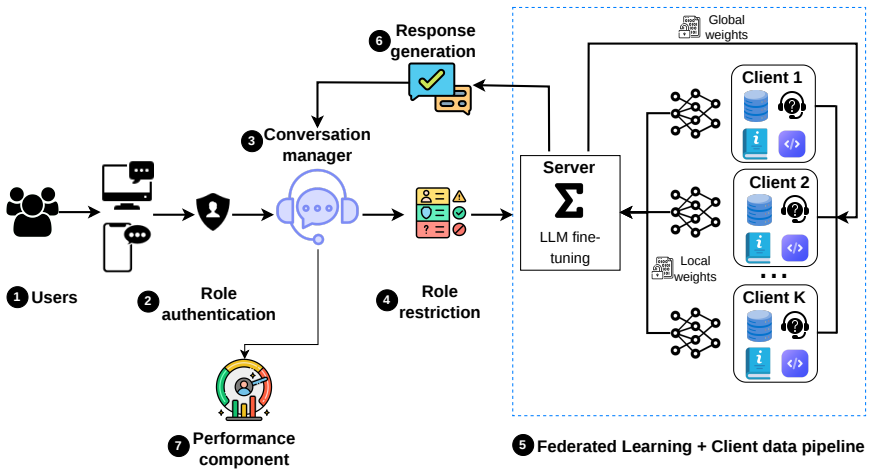
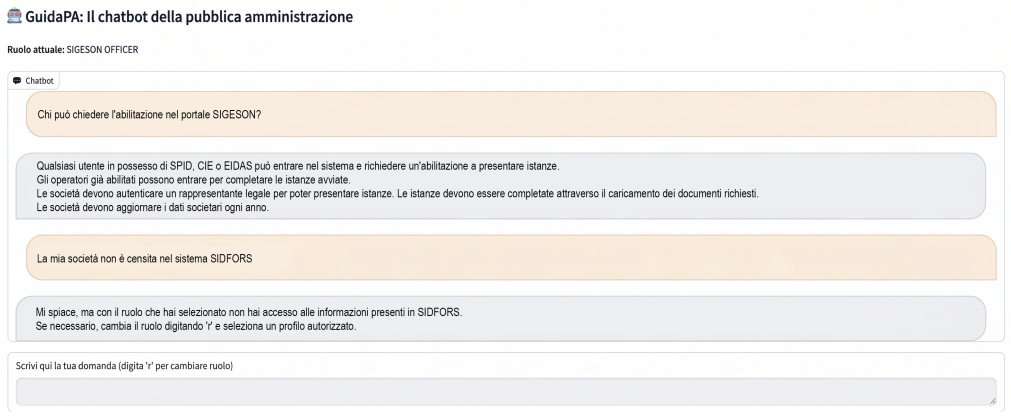
GuidaPA uses QLoRA (4-bit) federated fine-tuning over 15 rounds on an 80/20 split per client, with explicit non-IID monitoring, secure client-side preprocessing, and role-based access control. On public SIGESON and SIDFORS manuals as a proxy for restricted internal sources, the best federated model reaches ROUGE-1/2/L of 61.10/55.77/59.44, BLEU-4 of 45.02, and METEOR of 63.94, close to private centralized fine-tuning while data remains on-site. Domain fine-tuning lifts ROUGE-1 from 41.45 to 62.18 and BLEU-4 from 26.97 to 50.90 over the general-purpose baseline, indicating that federated learning can deliver high-quality conversational AI for public services without centralized data sharing.
What carries the argument
Parameter-efficient federated fine-tuning of large language models with QLoRA over multiple rounds, combined with non-IID effect monitoring and client-side secure preprocessing.
If this is right
- Federated learning can deliver high-quality conversational AI for public services without centralized data sharing.
- Domain fine-tuning via this method improves ROUGE-1 from 41.45 to 62.18 and BLEU-4 from 26.97 to 50.90 over the general-purpose baseline.
- The federated model achieves ROUGE and BLEU scores close to those of private centralized fine-tuning while data stays on-site.
- Explicit monitoring of non-IID effects supports stable training across separate public administration clients.
Where Pith is reading between the lines
- The same federated setup could be tested on other regulated domains that face similar data-pooling restrictions.
- Direct experiments with real restricted internal data would test how well the public-document proxy holds.
- Adding more clients or larger base models might expose limits of the current non-IID handling and QLoRA configuration.
Load-bearing premise
Public documentation from the two platforms serves as a valid proxy for the restricted internal sources that cannot be centrally pooled.
What would settle it
Running the identical federated protocol on actual restricted internal tickets and officer manuals and finding that the resulting model scores fall substantially below the centralized baseline or show no improvement over the general-purpose model.
Figures


read the original abstract
We present GuidaPA, a privacy-preserving chatbot for the Italian Public Administration (PA) trained via Federated Learning (FL) on documentation from two national PA platforms, SIGESON and SIDFORS. Our corpus includes approximately 8 pages of SIGESON manuals and 31 pages of SIDFORS manuals/FAQs; while this study uses public documentation as a safe proxy, the intended deployment extends to restricted internal sources (e.g., tickets, officer manuals, database extracts) that can not be centrally pooled due to regulatory and organizational constraints. GuidaPA integrates role-based access control, secure client-side preprocessing, explicit monitoring of non-IID effects, and parameter-efficient federated fine-tuning of large language models. Using QLoRA (4-bit) over 15 federated rounds with an 80/20 train-test split per client, we evaluate answer quality with ROUGE, BLEU-4, and METEOR. The best federated model achieves ROUGE-1/2/L of 61.10/55.77/59.44, BLEU-4 of 45.02, and METEOR of 63.94-close to private centralized fine-tuning while keeping data on-site. Compared to the general-purpose baseline, domain fine-tuning improves ROUGE-1 from 41.45 to 62.18 and BLEU-4 from 26.97 to 50.90. Overall, the results indicate that FL can deliver high-quality conversational AI for public services without centralized data sharing
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents GuidaPA, a privacy-preserving chatbot for the Italian Public Administration trained via federated learning on public documentation from the SIGESON and SIDFORS platforms (approximately 39 pages total). It employs QLoRA (4-bit) for parameter-efficient fine-tuning over 15 federated rounds with an 80/20 per-client train-test split, explicitly monitoring non-IID effects and incorporating role-based access control and secure preprocessing. The best federated model reports ROUGE-1/2/L of 61.10/55.77/59.44, BLEU-4 of 45.02, and METEOR of 63.94, close to private centralized fine-tuning, with domain adaptation improving ROUGE-1 from 41.45 to 62.18 and BLEU-4 from 26.97 to 50.90 over a general baseline. The study positions the public corpus as a safe proxy for restricted internal sources (tickets, officer manuals, database extracts) that cannot be centrally pooled.
Significance. If the proxy corpus is representative of the target distribution, the work provides concrete empirical evidence that federated learning with parameter-efficient techniques can deliver domain-specific conversational performance in regulated environments without data centralization. It credits the explicit non-IID monitoring, secure client-side steps, and direct comparison to centralized training on held-out splits. The results are direct measurements rather than derived quantities, supporting applicability to public administration use cases where privacy constraints apply.
major comments (2)
- [Abstract] Abstract and experimental evaluation: The headline claim that federated training yields performance 'close to private centralized fine-tuning' while enabling deployment to restricted internal sources rests on results from the public SIGESON/SIDFORS proxy corpus alone. No domain-shift analysis, vocabulary overlap statistics, or cross-domain evaluation is reported to test whether the observed ROUGE/BLEU/METEOR scores transfer to the actual target data (tickets, DB extracts) that cannot be pooled. This is load-bearing for the applicability claim.
- [Experimental evaluation] Experimental evaluation: The reported metric values and improvements (e.g., ROUGE-1 rising to 62.18) are given as single-point estimates without error bars, multiple random seeds, or statistical significance tests, despite the small total corpus (~39 pages) and per-client 80/20 splits. This weakens confidence in the asserted proximity to centralized training.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the importance of validating the proxy corpus and strengthening the experimental reporting. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental evaluation: The headline claim that federated training yields performance 'close to private centralized fine-tuning' while enabling deployment to restricted internal sources rests on results from the public SIGESON/SIDFORS proxy corpus alone. No domain-shift analysis, vocabulary overlap statistics, or cross-domain evaluation is reported to test whether the observed ROUGE/BLEU/METEOR scores transfer to the actual target data (tickets, DB extracts) that cannot be pooled. This is load-bearing for the applicability claim.
Authors: We agree that the applicability claim depends on the proxy's representativeness. The public SIGESON/SIDFORS corpus originates from the same national platforms that host restricted internal content and shares domain-specific terminology, structure, and question-answer formats. We will add a dedicated subsection with vocabulary overlap statistics (e.g., Jaccard similarity on tokenized terms) between the proxy and a general Italian baseline, plus explicit discussion of the proxy's role as a safe stand-in. Cross-domain evaluation on the actual restricted data (tickets, DB extracts) cannot be performed, as these cannot be pooled; this limitation is inherent to the privacy-preserving setting the work addresses. revision: partial
-
Referee: [Experimental evaluation] Experimental evaluation: The reported metric values and improvements (e.g., ROUGE-1 rising to 62.18) are given as single-point estimates without error bars, multiple random seeds, or statistical significance tests, despite the small total corpus (~39 pages) and per-client 80/20 splits. This weakens confidence in the asserted proximity to centralized training.
Authors: The small corpus size (~39 pages) and per-client splits constrain the statistical power of additional runs. We will revise the experimental section to acknowledge this limitation explicitly and report results from three independent random seeds (where feasible given compute) to indicate variability. The core comparison—federated versus centralized training on identical held-out splits—still provides direct evidence of proximity under the reported conditions. revision: partial
- Direct cross-domain evaluation or domain-shift analysis on the actual restricted internal sources (tickets, DB extracts) cannot be conducted, as these data cannot be centrally pooled due to regulatory constraints.
Circularity Check
No circularity; empirical metrics from held-out evaluation
full rationale
The paper reports direct ROUGE/BLEU/METEOR scores obtained by training QLoRA-adapted models via federated averaging and evaluating on per-client 80/20 held-out splits of the proxy corpus. No equations define target metrics in terms of fitted parameters, no predictions are statistically forced by construction, and no self-citation chains or uniqueness theorems underpin the central performance claims. The explicit acknowledgment that public SIGESON/SIDFORS manuals serve as proxy for restricted internal data is an assumption about data representativeness, not a definitional or fitted-input reduction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- Number of federated rounds
- Per-client train-test split
axioms (2)
- domain assumption Non-IID effects across clients can be monitored and do not prevent useful convergence in this setting
- standard math QLoRA 4-bit fine-tuning is compatible with federated aggregation for the chosen LLM
Reference graph
Works this paper leans on
-
[1]
Natural language processing for public services,
F. Barth ´elemy, N. Ghesqui `ere, N. Loozen, L. Matha, and E. Stani, “Natural language processing for public services,” Publications Office of the European Union, Luxembourg, Technical Report D02.01, Mar. 2022. [Online]. Available: https://interoperable-europe.ec. europa.eu/sites/default/files/inline-files/D02.01 Natural%20Language% 20Processing%20for%20P...
2022
-
[2]
Piano triennale per l’informatica nella pubblica amministrazione (2024–2026): Capitolo 5 – dati e intelligenza artificiale,
Agenzia per l’Italia Digitale (AGID) and T. per la Trasformazione Digitale, “Piano triennale per l’informatica nella pubblica amministrazione (2024–2026): Capitolo 5 – dati e intelligenza artificiale,” 2024, accessed April 2025. [Online]. Available: https://docs.italia.it/italia/piano-triennale-ict/pianotriennale-ict-doc/ it/2024-2026/capitolo-5 dati-e-in...
2024
-
[3]
European interoperability framework (eif): Promoting seamless public services across borders and sectors,
European Commission, “European interoperability framework (eif): Promoting seamless public services across borders and sectors,” 2017, cOM(2017) 134 final. [Online]. Available: https://eur-lex.europa.eu/ legal-content/EN/TXT/?uri=CELEX:52017DC0134
2017
-
[4]
Automating financial reporting with natural language processing: A review and case analysis,
A. T. Oyewole, O. B. Adeoye, W. A. Addy, C. C. Okoye, O. C. Ofodile, and C. E. Ugochukwu, “Automating financial reporting with natural language processing: A review and case analysis,”World Journal of Advanced Research and Reviews, vol. 21, no. 3, pp. 575–589, 2024
2024
-
[5]
Understanding the benefits and design of chatbots to meet the healthcare needs of migrant workers,
Y .-C. Tseng, W. Jarupreechachan, and T.-H. Lee, “Understanding the benefits and design of chatbots to meet the healthcare needs of migrant workers,”Proceedings of the ACM on Human-Computer Interaction, vol. 7, no. CSCW2, pp. 1–34, 2023
2023
-
[6]
Benefits, challenges, and methods of artificial intelligence (ai) chatbots in education: A systematic literature review
S. G ¨okc ¸earslan, C. Tosun, and Z. G. Erdemir, “Benefits, challenges, and methods of artificial intelligence (ai) chatbots in education: A systematic literature review.”International Journal of Technology in Education, vol. 7, no. 1, pp. 19–39, 2024
2024
-
[7]
Codice dell’amministrazione digitale (d.lgs. 82/2005),
Repubblica Italiana, “Codice dell’amministrazione digitale (d.lgs. 82/2005),” Codice dell’amministrazione digitale e successive modifiche, 2005, testo coordinato e aggiornamenti disponibili sul portale AgID. [Online]. Available: https://www.agid.gov.it/sites/default/files/ repository files/leggi decreti direttive/dl-7-marzo-2005-82 0.pdf
2005
-
[8]
T. Chen, M. Gasc ´o-Hernandez, and M. Esteve, “The adoption and implementation of artificial intelligence chatbots in public organizations: Evidence from u.s. state governments,”The American Review of Public Administration, vol. 54, no. 3, pp. 255–270, 2023, original work published 2024. [Online]. Available: https: //doi.org/10.1177/02750740231200522
-
[9]
Challenges of generative ai chatbots in public services: An integrative review,
R. Dreyling, T. Koppel, T. Tammet, and I. Pappel, “Challenges of generative ai chatbots in public services: An integrative review,” SSRN, Social Science Research Network, Tech. Report 4850714, 2024. [Online]. Available: https://ssrn.com/abstract=4850714
2024
-
[10]
Data- efficient fine-tuning for llm-based recommendation,
X. Lin, W. Wang, Y . Li, S. Yang, F. Feng, Y . Wei, and T.-S. Chua, “Data- efficient fine-tuning for llm-based recommendation,” inProceedings of the 47th international ACM SIGIR conference on research and development in information retrieval, 2024, pp. 365–374
2024
-
[11]
Retrieval- augmented generation for knowledge-intensive nlp tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. K ¨uttler, M. Lewis, W.-t. Yih, T. Rockt ¨aschelet al., “Retrieval- augmented generation for knowledge-intensive nlp tasks,”Advances in neural information processing systems, vol. 33, pp. 9459–9474, 2020
2020
-
[12]
Nota tematica n°1: Ai in public settings – status and perspectives,
Ministero dell’Economia e delle Finanze, Dipartimento del Tesoro, “Nota tematica n°1: Ai in public settings – status and perspectives,” Min- istero dell’Economia e delle Finanze, Dipartimento del Tesoro, Roma, Italia, Nota Tematica 1, Feb. 2024, iSSN 1972-4128. [Online]. Available: https://www.dt.mef.gov.it/it/news/2024/nota tematica 21022024.html
2024
-
[13]
Trasformazione digitale della pubblica amministrazione: Metodi per l’interoperabilit `a e lo sviluppo di e-service,
G. Bellitti, C. Colasanti, and M. Fedeli, “Trasformazione digitale della pubblica amministrazione: Metodi per l’interoperabilit `a e lo sviluppo di e-service,” 2023, consulted April 2025. [Online]. Available: https://www.istat.it/wp-content/uploads/2024/01/ Trasformazione-digitale-della-Pubblica-Amministrazione-Ebook.pdf
2023
-
[14]
Non-iid data in federated learning: A systematic review with taxonomy, metrics, methods, frame- works and future directions,
D. M. Jimenez G, D. Solans, M. Heikkila, A. Vitaletti, N. Kourtellis, A. Anagnostopoulos, and I. Chatzigiannakis, “Non-iid data in federated learning: A systematic review with taxonomy, metrics, methods, frame- works and future directions,”arXiv e-prints, pp. arXiv–2411, 2024
2024
-
[15]
A state-of-the-art survey on solving non-iid data in federated learning,
X. Ma, J. Zhu, Z. Lin, S. Chen, and Y . Qin, “A state-of-the-art survey on solving non-iid data in federated learning,”Future Generation Computer Systems, vol. 135, pp. 244–258, 2022
2022
-
[16]
A natural language processing model for the development of an italian-language chatbot for public administration,
A. Piizzi, D. Vavallo, G. Lazzo, S. Dimola, and E. Zazzera, “A natural language processing model for the development of an italian-language chatbot for public administration,” 2024
2024
-
[17]
Guapp: A conversational agent for job recommendation for the italian public administration,
V . Bellini, G. M. Biancofiore, T. Di Noia, E. Di Sciascio, F. Narducci, and C. Pomo, “Guapp: A conversational agent for job recommendation for the italian public administration,” in2020 IEEE Conference on Evolving and Adaptive Intelligent Systems (EAIS). IEEE, 2020, pp. 1–7
2020
-
[18]
A chatbot for searching and exploring open data: Implementation and evaluation in e-government,
I. Cantador, J. Viejo-Tard ´ıo, M. E. Cort ´es-Cediel, and M. P. Rodr´ıguez Bol´ıvar, “A chatbot for searching and exploring open data: Implementation and evaluation in e-government,” inProceedings of the 22nd Annual International Conference on Digital Government Research, 2021, pp. 168–179
2021
-
[19]
Transforming the communication between citizens and government through ai-guided chatbots,
A. Androutsopoulou, N. Karacapilidis, E. Loukis, and Y . Charalabidis, “Transforming the communication between citizens and government through ai-guided chatbots,”Government information quarterly, vol. 36, no. 2, pp. 358–367, 2019
2019
-
[20]
Fedbot: En- hancing privacy in chatbots with federated learning,
A. Ait-Mlouk, S. Alawadi, S. Toor, and A. Hellander, “Fedbot: En- hancing privacy in chatbots with federated learning,”arXiv preprint arXiv:2304.03228, 2023
arXiv 2023
-
[21]
Scan: A health- care personalized chatbot with federated learning based gpt,
S. Puppala, I. Hossain, M. J. Alam, and S. Talukder, “Scan: A health- care personalized chatbot with federated learning based gpt,” in2024 IEEE 48th Annual Computers, Software, and Applications Conference (COMPSAC). IEEE, 2024, pp. 1945–1951
2024
-
[22]
Boulez: A chatbot-based federated learning system for distance learning,
S. D’Urso, F. Sciarrone, and M. Temperini, “Boulez: A chatbot-based federated learning system for distance learning,” in2023 27th Inter- national Conference Information Visualisation (IV). IEEE, 2023, pp. 210–215
2023
-
[23]
Federated large language models: Current progress and future directions,
Y . Yao, J. Zhang, J. Wu, C. Huang, Y . Xia, T. Yu, R. Zhang, S. Kim, R. Rossi, A. Liet al., “Federated large language models: Current progress and future directions,”arXiv preprint arXiv:2409.15723, 2024
Pith/arXiv arXiv 2024
-
[24]
Flora: Federated fine-tuning large language models with heterogeneous low- rank adaptations,
Z. Wang, Z. Shen, Y . He, G. Sun, H. Wang, L. Lyu, and A. Li, “Flora: Federated fine-tuning large language models with heterogeneous low- rank adaptations,”Advances in Neural Information Processing Systems, vol. 37, pp. 22 513–22 533, 2024
2024
-
[25]
Sidfors: Sistema per dichiarazione fornitura di reti/servizi di comunicazione elettronica,
Ministero delle Imprese e del Made in Italy, “Sidfors: Sistema per dichiarazione fornitura di reti/servizi di comunicazione elettronica,” Portale operativo per autorizzazioni generali in materia di reti e servizi di comunicazione elettronica, MIMIT – DGTEL, 2024. [Online]. Available: https://sidfors.mise.gov.it/
2024
-
[26]
Sigeson: Sistema di gestione delle reti di radiodiffusione sonora,
——, “Sigeson: Sistema di gestione delle reti di radiodiffusione sonora,” Portale operativo per la gestione amministrativa delle reti di radiodiffusione sonora, MIMIT – DGTEL, 2024. [Online]. Available: https://fm-dab.mise.gov.it/
2024
-
[27]
Formalizing and benchmarking prompt injection attacks and defenses,
Y . Liu, Y . Jia, R. Geng, J. Jia, and N. Z. Gong, “Formalizing and benchmarking prompt injection attacks and defenses,” in33rd USENIX Security Symposium (USENIX Security 24), 2024, pp. 1831–1847
2024
-
[28]
Fedartml: A tool to facilitate the generation of non-iid datasets in a controlled way to support federated learning research,
D. M. J. Gutierrez, A. Anagnostopoulos, I. Chatzigiannakis, and A. Vi- taletti, “Fedartml: A tool to facilitate the generation of non-iid datasets in a controlled way to support federated learning research,”IEEE Access, vol. 12, pp. 81 004–81 016, 2024
2024
-
[29]
Flower: A friendly federated learning research framework,
D. J. Beutel, T. Topal, A. Mathur, X. Qiu, J. Fernandez-Marques, Y . Gao, L. Sani, K. H. Li, T. Parcollet, P. P. B. de Gusm ˜aoet al., “Flower: A friendly federated learning research framework,”arXiv preprint arXiv:2007.14390, 2020
Pith/arXiv arXiv 2007
-
[30]
Towards a more comprehensive evaluation for italian llms,
L. Moroni, S. Conia, F. Martelli, and R. Navigli, “Towards a more comprehensive evaluation for italian llms,” inProceedings of the 10th Italian Conference on Computational Linguistics (CLiC-it 2024), 2024, pp. 584–599
2024
-
[31]
Minerva llms: The first family of large language models trained from scratch on italian data,
R. Orlando, L. Moroni, P.-L. H. Cabot, S. Conia, E. Barba, S. Orlandini, G. Fiameni, and R. Navigli, “Minerva llms: The first family of large language models trained from scratch on italian data,” inProceedings of the 10th Italian conference on computational linguistics (CLiC-it 2024), 2024, pp. 707–719
2024
-
[32]
Transformers: State- of-the-art natural language processing,
T. Wolf, L. Debut, V . Sanh, J. Chaumond, C. Delangue, A. Moi, P. Cistac, T. Rault, R. Louf, M. Funtowicz, J. Davison, S. Shleifer, P. von Platen, C. Ma, Y . Jernite, J. Plu, C. Xu, T. L. Scao, S. Gugger, M. Drame, Q. Lhoest, and A. Rush, “Transformers: State- of-the-art natural language processing,” inProceedings of the 2020 Conference on Empirical Metho...
2020
-
[33]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “Lora: Low-rank adaptation of large language models.” ICLR, vol. 1, no. 2, p. 3, 2022
2022
-
[34]
Qlora: Efficient finetuning of quantized llms,
T. Dettmers, A. Pagnoni, A. Holtzman, and L. Zettlemoyer, “Qlora: Efficient finetuning of quantized llms,”Advances in neural information processing systems, vol. 36, pp. 10 088–10 115, 2023
2023
-
[35]
Flowertune: A cross- domain benchmark for federated fine-tuning of large language models,
Y . Gao, M. R. Scamarcia, J. Fernandez-Marques, M. Naseri, C. S. Ng, D. Stripelis, Z. Li, T. Shen, J. Bai, D. Chenet al., “Flowertune: A cross- domain benchmark for federated fine-tuning of large language models,” arXiv preprint arXiv:2506.02961, 2025
arXiv 2025
-
[36]
Unveiling llm evaluation focused on metrics: Challenges and solutions,
T. Hu and X.-H. Zhou, “Unveiling llm evaluation focused on metrics: Challenges and solutions,” 2024. [Online]. Available: https: //arxiv.org/abs/2404.09135
arXiv 2024
-
[37]
Benchmarking llm powered chatbots: Methods and metrics,
D. Banerjee, P. Singh, A. Avadhanam, and S. Srivastava, “Benchmarking llm powered chatbots: Methods and metrics,” 2023. [Online]. Available: https://arxiv.org/abs/2308.04624
arXiv 2023
-
[38]
Lawsuit: a large expert- written summarization dataset of italian constitutional court verdicts,
L. Ragazzi, G. Moro, S. Guidi, and G. Frisoni, “Lawsuit: a large expert- written summarization dataset of italian constitutional court verdicts,” Artificial Intelligence and Law, pp. 1–37, 2024
2024
-
[39]
It5: Text-to-text pretraining for italian language understanding and generation,
G. Sarti and M. Nissim, “It5: Text-to-text pretraining for italian language understanding and generation,”arXiv preprint arXiv:2203.03759, 2022
arXiv 2022
-
[40]
Addressing hallucinations with rag and nmiss in italian healthcare llm chatbots,
M. P. Priola, “Addressing hallucinations with rag and nmiss in italian healthcare llm chatbots,”arXiv preprint arXiv:2412.04235, 2024
arXiv 2024
-
[41]
Federated and edge learning for large language models,
F. Piccialli, D. Chiaro, P. Qi, V . Bellandi, and E. Damiani, “Federated and edge learning for large language models,”Information Fusion, vol. 117, p. 102840, 2025
2025
-
[42]
Federated fine-tuning of large language models under heterogeneous tasks and client re- sources,
J. Bai, D. Chen, B. Qian, L. Yao, and Y . Li, “Federated fine-tuning of large language models under heterogeneous tasks and client re- sources,”Advances in Neural Information Processing Systems, vol. 37, pp. 14 457–14 483, 2024
2024
-
[43]
Rlhf deciphered: A critical analysis of reinforcement learning from human feedback for llms,
S. Chaudhari, P. Aggarwal, V . Murahari, T. Rajpurohit, A. Kalyan, K. Narasimhan, A. Deshpande, and B. Castro da Silva, “Rlhf deciphered: A critical analysis of reinforcement learning from human feedback for llms,”ACM Computing Surveys, 2024
2024
-
[44]
Federated optimization in heterogeneous networks,
T. Li, A. K. Sahu, M. Zaheer, M. Sanjabi, A. Talwalkar, and V . Smith, “Federated optimization in heterogeneous networks,”Proceedings of Machine learning and systems, vol. 2, pp. 429–450, 2020
2020
-
[45]
Measuring the effects of non- identical data distribution for federated visual classification,
T.-M. H. Hsu, H. Qi, and M. Brown, “Measuring the effects of non- identical data distribution for federated visual classification,”arXiv preprint arXiv:1909.06335, 2019
Pith/arXiv arXiv 1909
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.