CART: Context-Anchored Recurrent Transformer -- A Parameter-Efficient Architecture with Learned Stability
Pith reviewed 2026-06-28 17:00 UTC · model grok-4.3
The pith
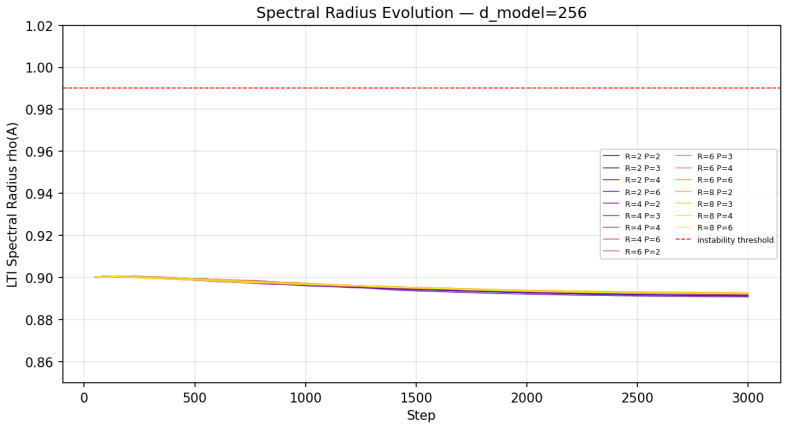
CART stabilizes recurrent transformers by anchoring a shared core to frozen prelude KV tensors and controlling updates with a learned LTI gate whose spectral radius stays in [0.79, 0.83].
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
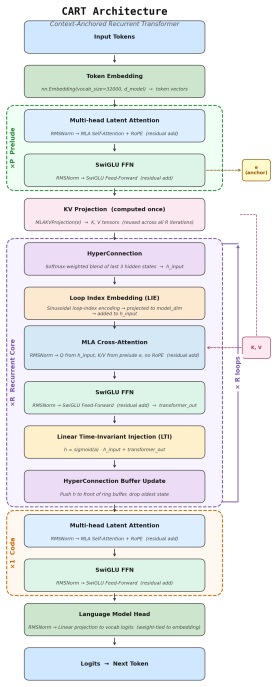
CART computes K and V once from a multi-layer prelude and lets the recurrent core cross-attend to those frozen tensors via multi-head latent attention while a learned LTI gate keeps the recurrence stable; its spectral radius settles in the narrow band [0.79, 0.83] across all 36 fully trained configurations, yet at d=1024 the model loses 1-2% at stored-parameter parity and about 10% at effective-parameter parity to a dense baseline.
What carries the argument
Multi-head latent attention that cross-attends the recurrent core to frozen prelude KV tensors, combined with the learned LTI gate that bounds the recurrence.
If this is right
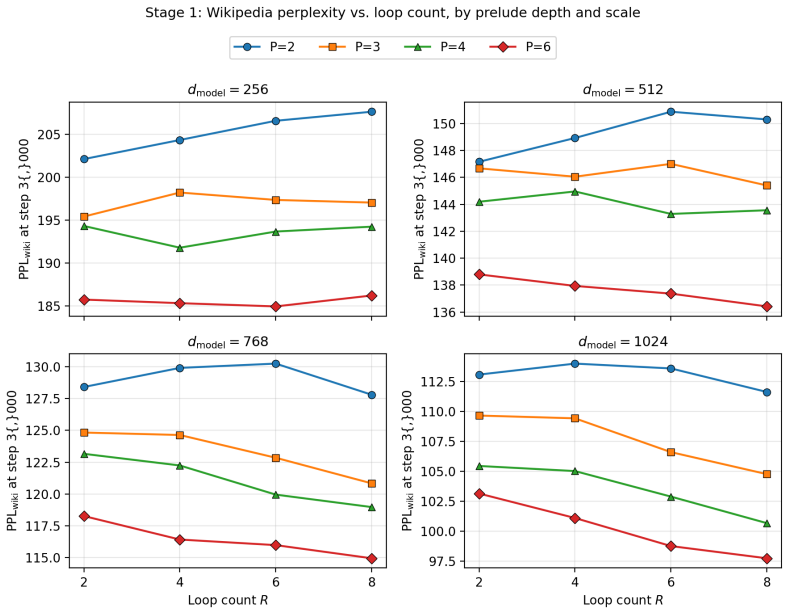
- Prelude depth dominates loop count in determining final performance across all tested widths.
- After full training the ranking of loop counts reverses, with R=6 becoming best for d greater than or equal to 512.
- The performance gap splits into roughly 5% from weight sharing and 5% from the heterogeneous prelude-anchor-core-coda structure.
- The hyper-connections, LTI gate, and loop-index embedding are each individually vestigial.
- Variable-R inference at test time degrades performance on both sides of the trained loop count.
Where Pith is reading between the lines
- If the recurrent machinery adds little beyond weight sharing, simpler shared-weight schemes without the full CART framing could narrow the remaining gap.
- The consistent narrow stability band suggests learned LTI gates may transfer to stabilize other recurrent or state-space architectures.
- Prelude dominance implies that future designs should allocate more capacity to initial context encoding rather than repeated core passes.
- Degradation under variable R indicates that test-time depth scaling will need different training objectives than fixed-R training.
Load-bearing premise
That anchoring the recurrent core to frozen prelude KV tensors plus an LTI gate will produce recurrence whose performance scales comparably to a dense transformer at the same parameter count.
What would settle it
A head-to-head training run at d=1024 for 30,500 steps showing whether CART validation loss matches or beats a dense transformer of equal stored parameter count.
Figures
read the original abstract
We present CART (Context-Anchored Recurrent Transformer), a parameter-efficient language model that reuses a single shared core block R times across depth. Unlike prior looped transformers that recompute key-value tensors at every iteration, CART computes K and V once from a multi-layer prelude and has the recurrent core cross-attend to those frozen tensors via multi-head latent attention. A learned Linear Time-Invariant (LTI) gate keeps the recurrence stable: its spectral radius settles in a narrow band (rho in [0.79, 0.83]) across all 36 fully-trained configurations. We evaluate CART on single consumer GPUs in two stages: a 64-configuration screen at 3,000 steps, then 36 configurations (P=6, R in {6,8,10}, three seeds) trained for 30,500 steps (~1B tokens). Two patterns hold across widths d in {256,512,768,1024}: prelude depth P dominates loop count R, and the Stage-1 ranking of R reverses at full training (R=6 becomes best at d>=512). At the binding d=1024 parameter-parity test, CART does not beat a parameter-matched dense baseline, losing by 1-2% at stored-parameter parity and by ~10% at effective-parameter parity. Diagnostic ablations split the effective-parameter gap into ~5% from weight sharing and a residual ~5% from the heterogeneous prelude/anchor/core/coda framing; the recurrent-core machinery (hyper-connections, LTI gate, loop-index embedding) is individually vestigial. Variable-R inference degrades on both sides of the trained R, a negative result for test-time depth scaling under this recipe.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents CART, a parameter-efficient recurrent transformer that computes K and V once from a multi-layer prelude and has the recurrent core cross-attend to those frozen tensors via multi-head latent attention, with a learned LTI gate claimed to enforce stability (spectral radius rho settling in [0.79, 0.83] across 36 fully-trained runs). It reports two-stage training (64-config screen then 36 configs at 30,500 steps/~1B tokens) across widths d in {256,512,768,1024}, finding prelude depth P dominates loop count R, R=6 best at full training for d>=512, and that at d=1024 parameter parity CART loses to a dense baseline (1-2% at stored parity, ~10% at effective parity). Diagnostic ablations attribute ~5% of the gap to weight sharing and ~5% to the heterogeneous framing, with recurrent-core components (hyper-connections, LTI gate, loop-index embedding) individually vestigial; variable-R inference also degrades.
Significance. The manuscript's detailed empirical protocol—concrete training budgets, width sweeps, multiple seeds, parity tests, and explicit negative outcomes on both performance and test-time depth scaling—provides useful data on the limits of this recurrent recipe. If the stability attribution held, it would inform design of looped transformers; the reported negative results on scaling and the vestigial nature of the core machinery are themselves informative for the field.
major comments (1)
- [Abstract] Abstract: the central claim that the learned LTI gate 'keeps the recurrence stable' (with rho settling in the narrow band [0.79, 0.83] across all 36 configurations) is load-bearing for the title and abstract framing, yet the diagnostic ablations explicitly state that the recurrent-core machinery including the LTI gate is individually vestigial. This internal tension means the manuscript provides no evidence that the gate is responsible for the reported rho band or any performance benefit, weakening the 'learned stability' attribution.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We agree that the abstract framing creates an internal tension with the ablation results and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the learned LTI gate 'keeps the recurrence stable' (with rho settling in the narrow band [0.79, 0.83] across all 36 configurations) is load-bearing for the title and abstract framing, yet the diagnostic ablations explicitly state that the recurrent-core machinery including the LTI gate is individually vestigial. This internal tension means the manuscript provides no evidence that the gate is responsible for the reported rho band or any performance benefit, weakening the 'learned stability' attribution.
Authors: We concur that the current abstract over-attributes stability to the LTI gate. The reported rho band is an empirical observation from the 36 fully-trained runs that include the gate, but the diagnostic ablations show the gate (along with other recurrent-core elements) is vestigial with respect to performance, and we have no separate experiments isolating whether the gate is causally responsible for producing or maintaining that specific rho range. We will therefore revise the abstract and title framing to remove the causal phrasing 'keeps the recurrence stable' and the 'learned stability' attribution, reporting instead the observed rho values as a descriptive property of the trained models without claiming the gate enforces it. The revised abstract will also note the vestigial nature of the core components for consistency. revision: yes
Circularity Check
No circularity: purely empirical architecture with no derivation chain
full rationale
The paper advances CART via a sequence of training runs (64-config screen then 36 full trainings), ablations, and direct performance measurements on consumer GPUs. No equations, uniqueness theorems, or first-principles derivations are presented that could reduce to fitted inputs or self-citations by construction. The LTI gate's reported spectral-radius band is an observed outcome of training, not a prediction derived from prior fitted quantities. Ablations are likewise direct experimental removals. All load-bearing claims are therefore falsifiable against external training runs and do not collapse into self-definition or renamed fits.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Hung-Hsuan Chen. Thinking deeper, not longer: Depth-recurrent transformers for compositional generalization.arXiv preprint arXiv:2603.21676,
-
[2]
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
arXiv:2502.05171. Kye Gomez. OpenMythos: A theoretical reconstruction of the Claude Mythos architecture. https: //github.com/kyegomez/OpenMythos,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Recurrent-Depth Transformer with MoE, MLA, LTI-stable injection, and ACT halting. Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Hierarchical vs. Flat Iteration in Shared-Weight Transformers
Sang-Il Han. Hierarchical vs. flat iteration in shared-weight transformers.arXiv preprint arXiv:2604.14442,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
29 Renjie He. RD-ViT: Recurrent-depth vision transformer for semantic segmentation with reduced data dependence.arXiv preprint arXiv:2605.03999,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Perceiver: General perception with iterative attention
arXiv:2103.03206. Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, et al. Perceiver IO: A general architecture for structured inputs and outputs. InInternational Conference on Learning Representations,
-
[7]
Perceiver IO: A General Architecture for Structured Inputs & Outputs
arXiv:2107.14795. Ahmadreza Jeddi, Marco Ciccone, and Babak Taati. LoopFormer: Elastic-depth looped trans- formers for latent reasoning via shortcut modulation. InInternational Conference on Learning Representations,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[9]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
Aixin Liu et al. DeepSeek-V2: A strong, economical, and efficient mixture-of-experts language model.arXiv preprint arXiv:2405.04434, 2024a. Zechun Liu, Changsheng Zhao, Forrest Iandola, Chen Lai, Yuandong Tian, Igor Fedorov, Yunyang Xiong, Ernie Chang, Yangyang Shi, Raghuraman Krishnamoorthi, Liangzhen Lai, and Vikas Chandra. MobileLLM: Optimizing sub-bil...
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
RWKV: Reinventing RNNs for the Transformer Era
Bo Peng, Eric Alcaide, Quentin Anthony, Alon Albalak, Samuel Arcadinho, Stella Biderman, Huanqi Cao, Xin Cheng, Michael Chung, et al. RWKV: Reinventing RNNs for the transformer era.arXiv preprint arXiv:2305.13048,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Hayden Prairie, Zachary Novack, Taylor Berg-Kirkpatrick, and Daniel Y . Fu. Parcae: Scaling laws for stable looped language models.arXiv preprint arXiv:2604.12946,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
How Much Is One Recurrence Worth? Iso-Depth Scaling Laws for Looped Language Models
Kristian Schwethelm, Daniel Rueckert, and Georgios Kaissis. How much is one recurrence worth? Iso-depth scaling laws for looped language models.arXiv preprint arXiv:2604.21106,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
GLU Variants Improve Transformer
Noam Shazeer. GLU variants improve transformer.arXiv preprint arXiv:2002.05202,
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[14]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
30 Bohong Wu, Mengzhao Chen, Xiang Luo, Shen Yan, Qifan Yu, Fan Xia, Tianqi Zhang, Hongrui Zhan, Zheng Zhong, Xun Zhou, Siyuan Qiao, and Xingyan Bin. Parallel loop transformer for efficient test-time computation scaling.arXiv preprint arXiv:2510.24824,
-
[16]
SpiralFormer: Looped Transformers Can Learn Hierarchical Dependencies via Multi-Resolution Recursion
Chengting Yu, Xiaobo Shu, Yadao Wang, Yizhen Zhang, Haoyi Wu, You Wu, Rujiao Long, Ziheng Chen, Yuchi Xu, Wenbo Su, and Bo Zheng. SpiralFormer: Looped transformers can learn hierarchical dependencies via multi-resolution recursion.arXiv preprint arXiv:2602.11698,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Abbas Zeitoun, Lucas Torroba-Hennigen, and Yoon Kim. Hyperloop transformers.arXiv preprint arXiv:2604.21254,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
arXiv preprint arXiv:2409.19606 , year =
Defa Zhang et al. Hyper-connections.arXiv preprint arXiv:2409.19606, 2024a. Peiyuan Zhang, Guangtao Zeng, Tianduo Wang, and Wei Lu. TinyLlama: An open-source small language model.arXiv preprint arXiv:2401.02385, 2024b. 31
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.