TimeSage-MT: A Multi-Turn Benchmark for Evaluating Agentic Time Series Reasoning
Pith reviewed 2026-06-28 16:51 UTC · model grok-4.3
The pith
A new multi-turn benchmark shows LLM agents suffer sharp drops on decision-oriented time series tasks due to memory and uncertainty failures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
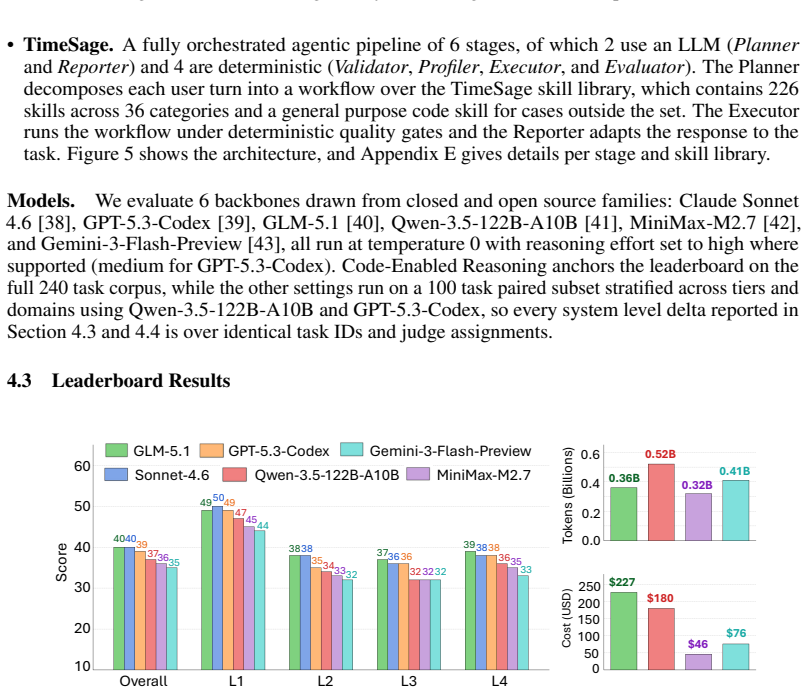
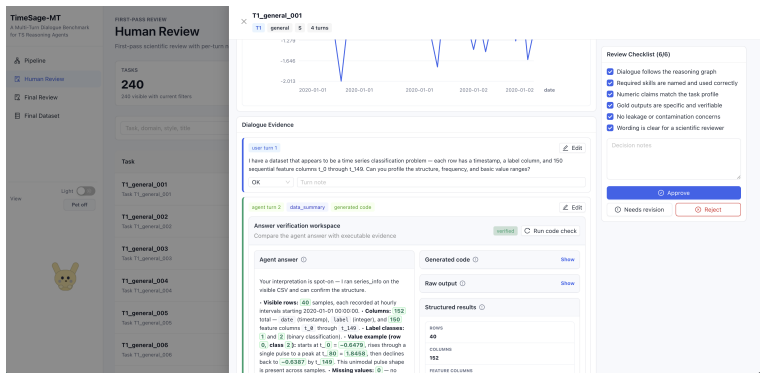
TimeSage-MT supplies a reproducible pipeline that turns real time series into multi-turn dialogues with checkable answers, yielding a 240-task benchmark across basic to decision-oriented analysis. When frontier LLMs and the TimeSage agent are tested under a unified protocol, performance falls sharply on the decision-oriented subset; the drops trace to shortcomings in memory for accumulated evidence, uncertainty handling, and domain-grounded choices.
What carries the argument
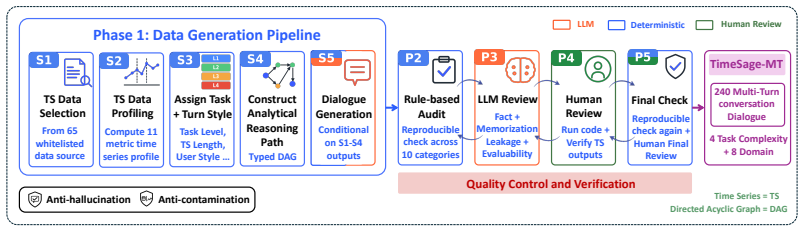
The reproducible pipeline that converts real-world time series data into multi-turn conversations carrying verifiable answers.
If this is right
- Agents must incorporate stronger memory mechanisms to track evidence across dialogue turns.
- Uncertainty quantification becomes necessary once tasks move beyond description to recommendation.
- Domain-specific decision rules cannot be supplied solely by general language models.
- A shared evaluation protocol now exists for measuring progress on agentic time series systems.
- Development effort should prioritize the transition from exploration to decision stages.
Where Pith is reading between the lines
- Similar pipeline methods could be applied to other sequential data types to create multi-turn agent benchmarks.
- Closing the observed gaps would directly improve reliability of conversational tools used for financial, medical, or operational forecasting.
- The benchmark isolates memory, uncertainty, and domain gaps that general scaling alone may not resolve.
- Public leaderboards built on this design could guide iterative agent improvements more precisely than single-turn tests.
Load-bearing premise
The generated conversations faithfully reproduce the way user goals evolve and evidence accumulates during actual time series decision work.
What would settle it
A side-by-side comparison in which domain experts judge that the benchmark tasks do not match the structure or difficulty of real deployed time series agent workflows would undermine the measured performance gaps.
Figures






read the original abstract
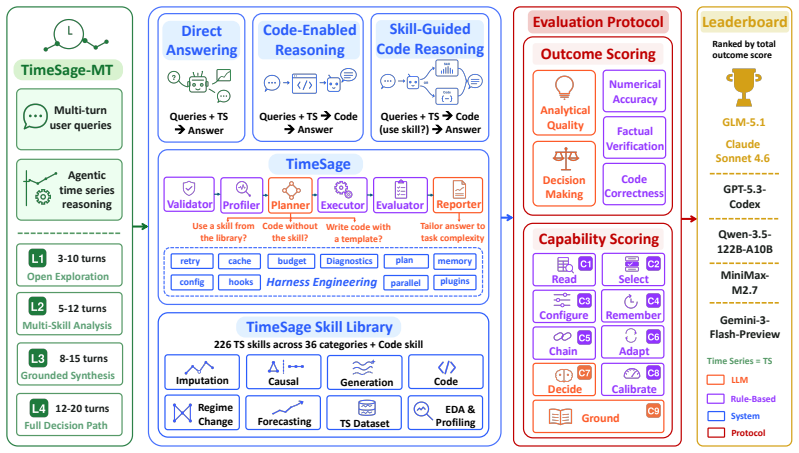
Time series data inform critical decisions across many real-world domains. While large language model (LLM) agents can analyze data through natural language and tools, it remains unclear whether they can conduct reliable time series analysis across multi-turn conversations. Existing benchmarks focus on single-step tasks such as forecasting and anomaly detection, overlooking practical workflows where user goals evolve, agents must build on prior analyses, and conclusions emerge from accumulated evidence. In this work, we introduce TimeSage-MT, a multi-turn benchmark for agentic time series reasoning with 240 tasks and 2,680 dialogue turns across 8 real-world domains, spanning basic exploration to decision-oriented analysis. TimeSage-MT is built through a reproducible pipeline that converts real-world time series data into multi-turn conversations with verifiable answers. It provides a unified evaluation protocol and public leaderboard for comparing time series agentic systems. To demonstrate the benchmark's utility, we evaluate frontier LLMs alongside TimeSage, a novel structured agent equipped with a comprehensive time series skill library. The results show sharp performance drops on decision-oriented tasks, driven by failures in memory, uncertainty handling, and domain-based decision making. TimeSage-MT exposes critical gaps in current agentic reasoning and provides a rigorous foundation for future development.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TimeSage-MT, a multi-turn benchmark with 240 tasks and 2,680 dialogue turns across 8 real-world domains for evaluating agentic time series reasoning. It describes a reproducible pipeline that converts real-world time series data into multi-turn conversations with verifiable answers, provides a unified evaluation protocol and public leaderboard, and evaluates frontier LLMs alongside a novel TimeSage agent. The results indicate sharp performance drops on decision-oriented tasks, attributed to failures in memory, uncertainty handling, and domain-based decision making.
Significance. If the generated tasks accurately instantiate evolving user goals and accumulated-evidence workflows, the benchmark would offer a useful resource for identifying limitations in current LLM agents for practical time series analysis and supporting future development. The reproducible pipeline, public leaderboard, and focus on multi-turn verifiable tasks are explicit strengths that facilitate community adoption and comparison.
major comments (2)
- [Abstract and pipeline description] Abstract and pipeline description: The interpretation that performance drops on decision-oriented tasks are driven by failures in memory, uncertainty handling, and domain-based decision making depends on the pipeline producing tasks that faithfully reflect evolving user goals and incremental evidence accumulation. The abstract states that the pipeline 'converts real-world time series data into multi-turn conversations with verifiable answers' but supplies no external anchor such as expert trace comparison or ecological validity metric to confirm that the generated dialogues match the statistical structure of genuine multi-turn analyst sessions; this assumption is load-bearing for the headline claims.
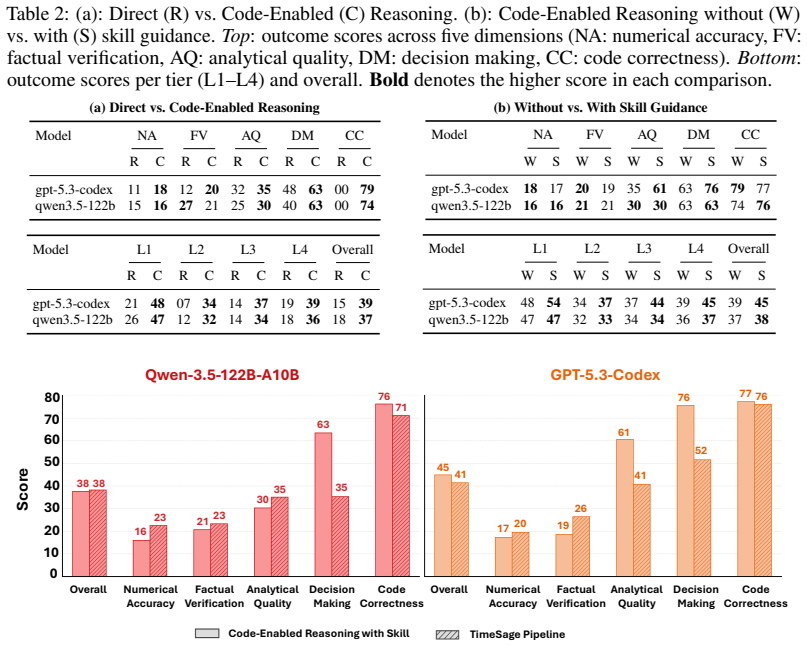
- [Results section (model evaluations)] Results section (model evaluations): The reported sharp performance drops across task types are presented without error bars, statistical significance tests, or controls for post-hoc selection of tasks or models. This omission prevents assessment of whether the observed differences reliably support the specific attributions to memory and uncertainty failures rather than variability in the 240-task set.
minor comments (1)
- [Introduction] The distinction between the TimeSage-MT benchmark and the TimeSage agent should be introduced with explicit notation in the introduction to avoid potential reader confusion in later sections.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: The interpretation that performance drops on decision-oriented tasks are driven by failures in memory, uncertainty handling, and domain-based decision making depends on the pipeline producing tasks that faithfully reflect evolving user goals and incremental evidence accumulation. The abstract states that the pipeline 'converts real-world time series data into multi-turn conversations with verifiable answers' but supplies no external anchor such as expert trace comparison or ecological validity metric to confirm that the generated dialogues match the statistical structure of genuine multi-turn analyst sessions; this assumption is load-bearing for the headline claims.
Authors: We acknowledge that our pipeline, while reproducible and grounded in real-world time series data with verifiable answers, does not include direct expert trace comparisons or quantitative ecological validity metrics. The multi-turn structures are constructed to simulate evolving goals and evidence accumulation by design across the eight domains. We will revise the manuscript to expand the pipeline description with additional design rationale and add an explicit limitations paragraph discussing this point. revision: partial
-
Referee: The reported sharp performance drops across task types are presented without error bars, statistical significance tests, or controls for post-hoc selection of tasks or models. This omission prevents assessment of whether the observed differences reliably support the specific attributions to memory and uncertainty failures rather than variability in the 240-task set.
Authors: We agree that statistical support would strengthen the results presentation. In the revised manuscript we will add error bars (standard deviation across repeated evaluations where relevant), report statistical significance tests for key performance differences, and clarify selection procedures for tasks and models. revision: yes
Circularity Check
No circularity: benchmark construction and empirical evaluation are independent of fitted inputs or self-referential derivations
full rationale
The paper constructs TimeSage-MT via a reproducible pipeline that converts real-world time series into multi-turn dialogues, then reports empirical LLM performance on the resulting 240 tasks. No equations, parameter fits, or predictions are claimed; the central output is the benchmark itself plus observed failure modes on decision tasks. No self-citation chains, ansatzes, or uniqueness theorems are invoked to justify results. The pipeline fidelity assumption is an external validity concern, not a definitional reduction. This is a standard benchmark paper whose claims do not reduce to their own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Real-world time series data can be converted into multi-turn conversations with verifiable answers that reflect evolving user goals.
invented entities (2)
-
TimeSage-MT benchmark
no independent evidence
-
TimeSage agent
no independent evidence
Reference graph
Works this paper leans on
-
[1]
George E. P. Box, Gwilym M. Jenkins, Gregory C. Reinsel, and Greta M. Ljung.Time Series Analysis: Forecasting and Control. John Wiley & Sons, Hoboken, NJ, 5 edition, 2015
2015
-
[2]
Hyndman and George Athanasopoulos.Forecasting: Principles and Practice
Rob J. Hyndman and George Athanasopoulos.Forecasting: Principles and Practice. OTexts, 3 edition, 2021
2021
-
[3]
Mulvey, H
Yaxuan Kong, Yuqi Nie, Xiaowen Dong, John M. Mulvey, H. Vincent Poor, Qingsong Wen, and Stefan Zohren. Large language models for financial and investment management: Models, opportunities, and challenges.Journal of Portfolio Management, 51(2):211–231, 2024
2024
-
[4]
Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam
Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam. A time series is worth 64 words: Long-term forecasting with transformers. InInternational Conference on Learning Representations, 2023
2023
-
[5]
Sundial: A family of highly capable time series foundation models
Yong Liu, Guo Qin, Zhiyuan Shi, Zhi Chen, Caiyin Yang, Xiangdong Huang, Jianmin Wang, and Mingsheng Long. Sundial: A family of highly capable time series foundation models. InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research, pages 39295–39317. PMLR, 2025
2025
-
[6]
TimeFound: A foundation model for time series forecasting.arXiv preprint arXiv:2503.04118, 2025
Congxi Xiao, Jingbo Zhou, Yixiong Xiao, Xinjiang Lu, Le Zhang, and Hui Xiong. TimeFound: A foundation model for time series forecasting.arXiv preprint arXiv:2503.04118, 2025
-
[7]
Unlocking the power of LSTM for long term time series forecasting
Yaxuan Kong, Zepu Wang, Yuqi Nie, Tian Zhou, Stefan Zohren, Yuxuan Liang, Peng Sun, and Qingsong Wen. Unlocking the power of LSTM for long term time series forecasting. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 11968–11976, 2025
2025
-
[8]
Leveraging large language models for time series forecasting: A systematic literature review.Knowledge- Based Systems, 343:115938, 2026
Gabriel Ikaro Fonseca de Paiva, Arthur Caio Vargas e Pinto, Marcos Antonio Alves, and Omid Orang. Leveraging large language models for time series forecasting: A systematic literature review.Knowledge- Based Systems, 343:115938, 2026
2026
-
[9]
TF-LLM: Enhanced time series analysis with time-frequency large language models.Neural Networks, 199:108687, 2026
Yuhang Zhang, Zitong Yu, Mingtong Dai, Yue Sun, and Tao Tan. TF-LLM: Enhanced time series analysis with time-frequency large language models.Neural Networks, 199:108687, 2026
2026
-
[10]
Muyan Weng, Defu Cao, Wei Yang, Yashaswi Sharma, and Yan Liu. TemporalBench: A benchmark for evaluating LLM-based agents on contextual and event-informed time series tasks.arXiv preprint arXiv:2602.13272, 2026
-
[11]
Webb, Rob J
Rakshitha Godahewa, Christoph Bergmeir, Geoffrey I. Webb, Rob J. Hyndman, and Pablo Montero-Manso. Monash time series forecasting archive. InProceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks. Neural Information Processing Systems Foundation, 2021
2021
-
[12]
The M4 competition: 100,000 time series and 61 forecasting methods.International Journal of Forecasting, 36(1):54–74, 2020
Spyros Makridakis, Evangelos Spiliotis, and Vassilios Assimakopoulos. The M4 competition: 100,000 time series and 61 forecasting methods.International Journal of Forecasting, 36(1):54–74, 2020
2020
-
[13]
Tsay, Themis Palpanas, and Michael J
John Paparrizos, Yuhao Kang, Paul Boniol, Ruey S. Tsay, Themis Palpanas, and Michael J. Franklin. TSB-UAD: An end-to-end benchmark suite for univariate time-series anomaly detection.Proceedings of the VLDB Endowment, 15(8):1697–1711, 2022
2022
-
[14]
Re- Act: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. Re- Act: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations, 2023
2023
-
[15]
LLM-based agents for tool learning: A survey
Weikai Xu, Chengrui Huang, Shen Gao, and Shuo Shang. LLM-based agents for tool learning: A survey. Data Science and Engineering, 10:533–563, 2025
2025
-
[16]
Tool learning with language models: A comprehensive survey of methods, pipelines, and benchmarks.Vicinagearth, 2(16), 2025
Jinyang Chen, Haolun Wu, Jianhong Pang, Yihua Wang, Dell Zhang, and Changzhi Sun. Tool learning with language models: A comprehensive survey of methods, pipelines, and benchmarks.Vicinagearth, 2(16), 2025
2025
-
[17]
Large Language Model Agent: A Survey on Methodology, Applications and Challenges
Junyu Luo, Weizhi Zhang, Ye Yuan, Yusheng Zhao, Junwei Yang, Yiyang Gu, Bohan Wu, Binqi Chen, et al. Large language model agent: A survey on methodology, applications and challenges.arXiv preprint arXiv:2503.21460, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Bingxi Zhao, Lin Geng Foo, Ping Hu, Christian Theobalt, Hossein Rahmani, and Jun Liu. LLM-based agentic reasoning frameworks: A survey from methods to scenarios.arXiv preprint arXiv:2508.17692, 2025
-
[19]
Survey on Evaluation of LLM-based Agents
Asaf Yehudai, Lilach Eden, Alan Li, Guy Uziel, Yilun Zhao, Roy Bar-Haim, Arman Cohan, and Michal Shmueli-Scheuer. Survey on evaluation of LLM-based agents.arXiv preprint arXiv:2503.16416, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
The UCR time series archive.IEEE/CAA Journal of Automatica Sinica, 6(6):1293–1305, 2019
Hoang Anh Dau, Anthony Bagnall, Kaveh Kamgar, Chin-Chia Michael Yeh, Yan Zhu, Shaghayegh Gharghabi, Chotirat Ann Ratanamahatana, and Eamonn Keogh. The UCR time series archive.IEEE/CAA Journal of Automatica Sinica, 6(6):1293–1305, 2019
2019
-
[21]
The UEA multivariate time series classification archive, 2018
Anthony Bagnall, Hoang Anh Dau, Jason Lines, Michael Flynn, James Large, Aaron Bostrom, Paul Southam, and Eamonn Keogh. The UEA multivariate time series classification archive, 2018.arXiv preprint arXiv:1811.00075, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[22]
Evaluating real-time anomaly detection algorithms–the Numenta anomaly benchmark
Alexander Lavin and Subutai Ahmad. Evaluating real-time anomaly detection algorithms–the Numenta anomaly benchmark. In2015 IEEE 14th International Conference on Machine Learning and Applications, pages 38–44. IEEE, 2015
2015
-
[23]
Chenxi Zhang, Ziliang Gan, Liyun Zhu, Youwei Pang, Qing Zhang, and Rongjunchen Zhang. Fin- MTM: A multi-turn multimodal benchmark for financial reasoning and agent evaluation.arXiv preprint arXiv:2602.03130, 2026
-
[24]
Large language models are zero-shot time series forecasters
Nate Gruver, Marc Finzi, Shikai Qiu, and Andrew Gordon Wilson. Large language models are zero-shot time series forecasters. InAdvances in Neural Information Processing Systems, volume 36, 2023
2023
-
[25]
Hao Xue and Flora D. Salim. PromptCast: A new prompt-based learning paradigm for time series forecasting.IEEE Transactions on Knowledge and Data Engineering, 36(11):6851–6864, 2024
2024
-
[26]
Zhang, Xiaoming Shi, Pin-Yu Chen, Yuxuan Liang, Yuan-Fang Li, Shirui Pan, and Qingsong Wen
Ming Jin, Shiyu Wang, Lintao Ma, Zhixuan Chu, James Y . Zhang, Xiaoming Shi, Pin-Yu Chen, Yuxuan Liang, Yuan-Fang Li, Shirui Pan, and Qingsong Wen. Time-LLM: Time series forecasting by reprogram- ming large language models. InInternational Conference on Learning Representations, 2024
2024
-
[27]
Maddix, Hao Wang, Michael W
Abdul Fatir Ansari, Lorenzo Stella, Caner Turkmen, Xiyuan Zhang, Pedro Mercado, Huibin Shen, Olek- sandr Shchur, Syama Sundar Rangapuram, Sebastian Pineda Arango, Shubham Kapoor, Jasper Zschiegner, Danielle C. Maddix, Hao Wang, Michael W. Mahoney, Kari Torkkola, Andrew Gordon Wilson, Michael Bohlke-Schneider, and Yuyang Wang. Chronos: Learning the languag...
2024
-
[28]
A decoder-only foundation model for time-series forecasting
Abhimanyu Das, Weihao Kong, Rajat Sen, and Yichen Zhou. A decoder-only foundation model for time-series forecasting. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 10148–10167. PMLR, 2024
2024
-
[29]
Unified training of universal time series forecasting transformers
Gerald Woo, Chenghao Liu, Akshat Kumar, Caiming Xiong, Silvio Savarese, and Doyen Sahoo. Unified training of universal time series forecasting transformers. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 53140–53164. PMLR, 2024
2024
-
[30]
UniTS: A unified multi-task time series model
Shanghua Gao, Teddy Koker, Owen Queen, Thomas Hartvigsen, Theodoros Tsiligkaridis, and Marinka Zitnik. UniTS: A unified multi-task time series model. InAdvances in Neural Information Processing Systems, volume 37, 2024
2024
-
[31]
Hyndman and Yeasmin Khandakar
Rob J. Hyndman and Yeasmin Khandakar. Automatic time series forecasting: The forecast package for R. Journal of Statistical Software, 27(3):1–22, 2008
2008
-
[32]
AutoGluon-TimeSeries: AutoML for probabilistic time series forecasting
Oleksandr Shchur, Ali Caner Turkmen, Nick Erickson, Huibin Shen, Alexander Shirkov, Tony Hu, and Bernie Wang. AutoGluon-TimeSeries: AutoML for probabilistic time series forecasting. InProceedings of the Second International Conference on Automated Machine Learning, volume 224 ofProceedings of Machine Learning Research, pages 9/1–21. PMLR, 2023
2023
-
[33]
White, Doug Burger, and Chi Wang
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Ahmed Awadallah, Ryen W. White, Doug Burger, and Chi Wang. AutoGen: Enabling next-gen LLM applications via multi-agent conversation. InConference on Language Modeling, 2024
2024
-
[34]
CAMEL: Communicative agents for “mind” exploration of large scale language model society
Guohao Li, Hasan Abed Al Kader Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. CAMEL: Communicative agents for “mind” exploration of large scale language model society. In Advances in Neural Information Processing Systems, volume 36, pages 51991–52008, 2023
2023
-
[35]
TaskWeaver: A code-first agent framework.arXiv preprint arXiv:2311.17541, 2023
Bo Qiao, Liqun Li, Xu Zhang, Shilin He, Yu Kang, Chaoyun Zhang, Fangkai Yang, Hang Dong, Jue Zhang, Lu Wang, Minghua Ma, Pu Zhao, Si Qin, Xiaoting Qin, Chao Du, Yong Xu, Qingwei Lin, Saravan Rajmohan, and Dongmei Zhang. TaskWeaver: A code-first agent framework.arXiv preprint arXiv:2311.17541, 2023
-
[36]
Introducing claude opus 4.6
Anthropic. Introducing claude opus 4.6. https://www.anthropic.com/news/claude-opus-4-6 , February 2026. Accessed: 2026-05-05. 12
2026
-
[37]
Introducing gpt-5.4
OpenAI. Introducing gpt-5.4. https://openai.com/index/introducing-gpt-5-4/ , March 2026. Accessed: 2026-05-05
2026
-
[38]
Introducing claude sonnet 4.6
Anthropic. Introducing claude sonnet 4.6. https://www.anthropic.com/news/claude-sonnet-4-6 , February 2026. Accessed: 2026-05-05
2026
-
[39]
Introducing gpt-5.3-codex
OpenAI. Introducing gpt-5.3-codex. https://openai.com/index/introducing-gpt-5-3-codex/ , February 2026. Accessed: 2026-05-05
2026
-
[40]
Glm-5.1: Towards long-horizon tasks
Z.AI. Glm-5.1: Towards long-horizon tasks. https://z.ai/blog/glm-5.1 , April 2026. Accessed: 2026-05-05
2026
-
[41]
Qwen3.5-122b-a10b
Qwen Team. Qwen3.5-122b-a10b. https://huggingface.co/Qwen/Qwen3.5-122B-A10B , March
-
[42]
Accessed: 2026-05-05
2026
-
[43]
MiniMax M2.7: Early echoes of self-evolution
MiniMax. MiniMax M2.7: Early echoes of self-evolution. https://www.minimax.io/news/minima x-m27-en, March 2026. Accessed: 2026-05-05
2026
-
[44]
LLM?” indicates whether the phase calls a language model. “Det.?
Google. Gemini 3 Flash Preview. https://blog.google/products-and-platforms/products/ge mini/gemini-3-flash/, December 2025. Accessed: 2026-05-05. 13 A Design Rationale for TimeSage-MT Benchmark Existing time series benchmarks ask one question per task: forecast the next 24 steps; generate a time series; or find anomalies in a stream. However, real analysi...
2025
-
[45]
Cover every reasoning-graph node in at least one agent turn
-
[46]
Use only canonical skill names from the registry
-
[47]
Start with a user turn and preserve open-loop evaluability: user turns may reference prior concrete state but must not depend on the scripted agent’s opinions
-
[48]
Do not leak held-out rows, held-out values, split boundary indices, total length, or held-out row counts
-
[49]
# SKILL_USED: <skill_name>
Every analytical agent turn must include reference_code with "# SKILL_USED: <skill_name>" and print every digit-bearing narrative claim
-
[50]
L3 must include synthesis gold; L4 must end with decision_json
-
[51]
Output exactly the requested number of turns as JSON only. B.6 P2: Reproducibility Audit P2 runs 46 deterministic checks grouped into 10 categories, all auditable from the task output. A task is held back from P3 until every P2 check passes. Table 11 describes each check its subchecks. B.7 P3: LLM Cross-Family Review P3 runs an anti-bias LLM audit. The mo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.