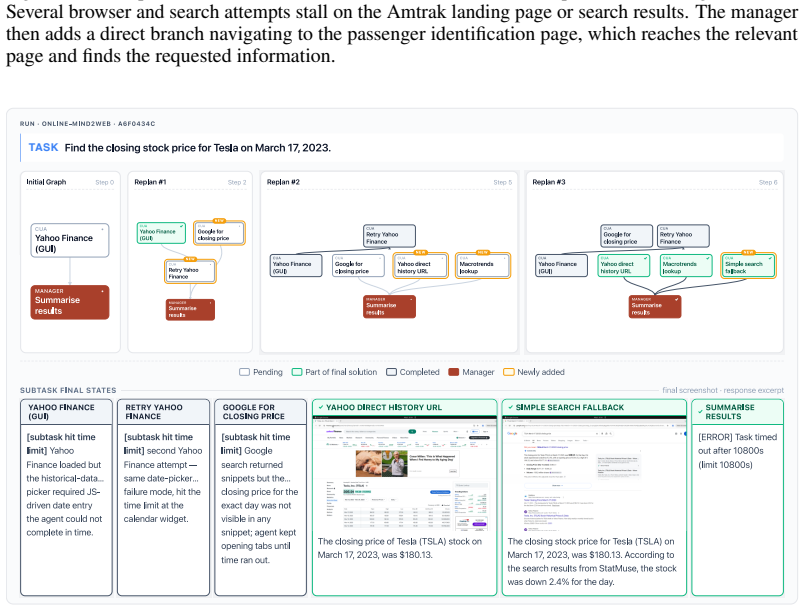
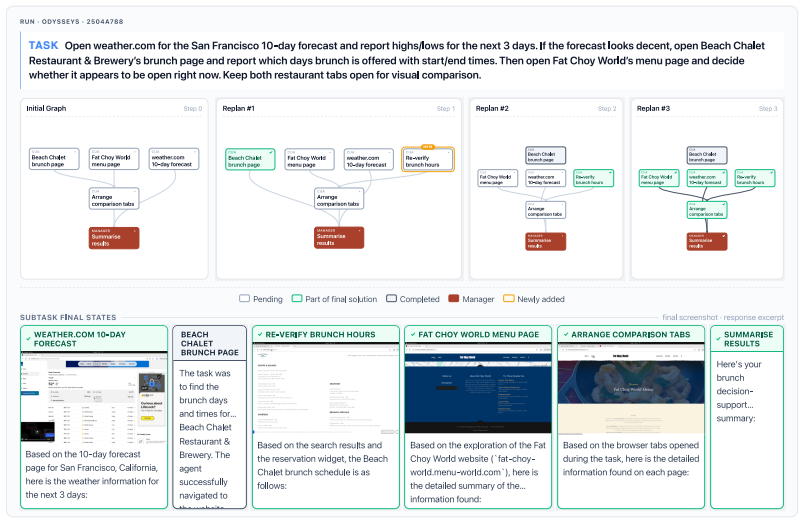
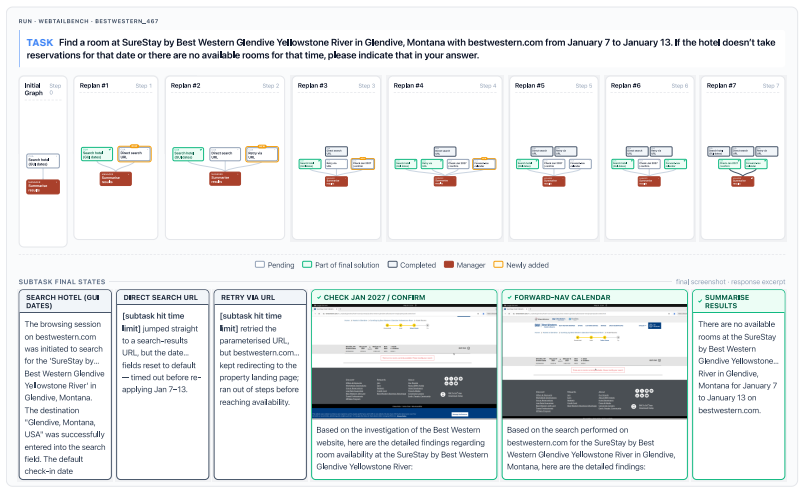
Multi-Agent Computer Use
Pith reviewed 2026-06-28 12:26 UTC · model grok-4.3
The pith
A manager LLM decomposes computer tasks into a DAG and runs parallel subagents to outperform single-agent baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
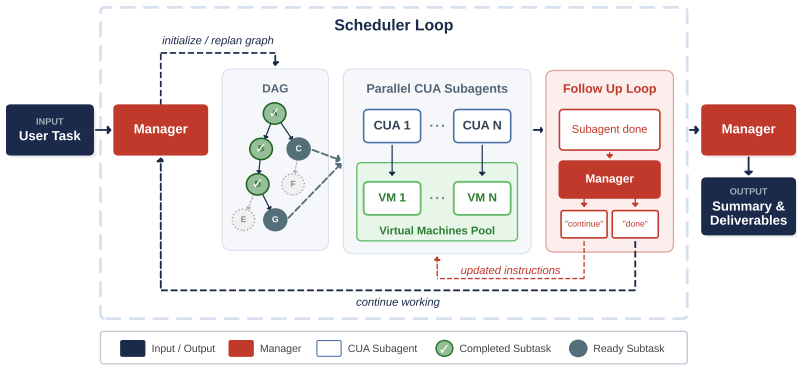
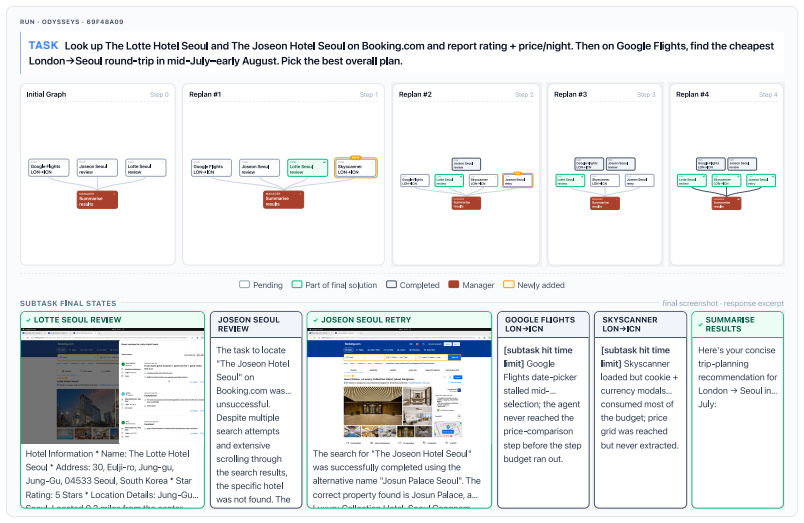
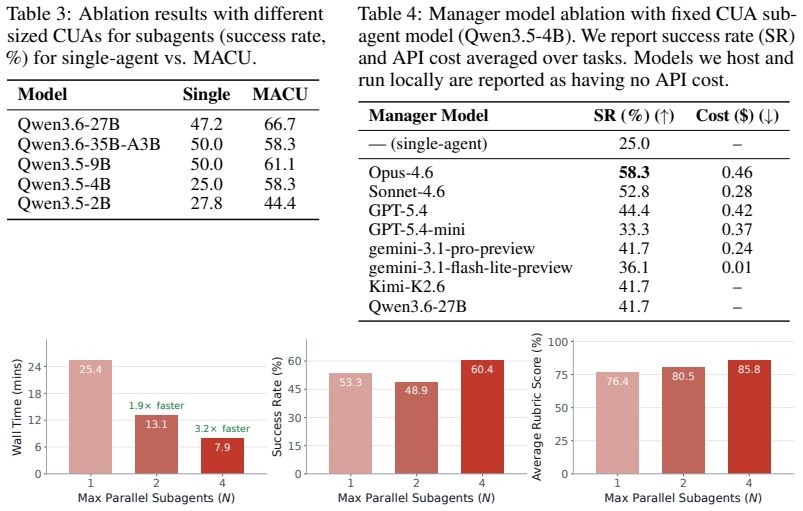
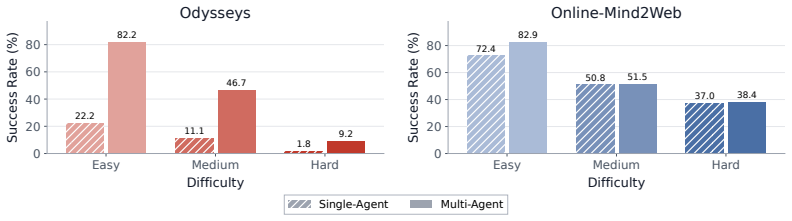
The paper establishes that a multi-agent computer use system outperforms strong single-agent baselines by 3.4-25.5 percent across desktop and web navigation benchmarks. The manager decomposes each task as a directed acyclic graph that encodes dependencies, dispatches parallel subagents to ready nodes, and continuously revises the graph as new information arrives. This structure retains observations that downstream agents could not re-observe and passes them forward. On the long-horizon Odysseys benchmark the approach also reduces average task completion wall-clock time by roughly 1.5 times while solving tasks that single agents cannot finish.
What carries the argument
The manager model that decomposes tasks into a directed acyclic graph (DAG), encodes dependencies and goals for subagents, dispatches parallel subagents to the ready frontier, and revises the DAG based on incoming findings.
If this is right
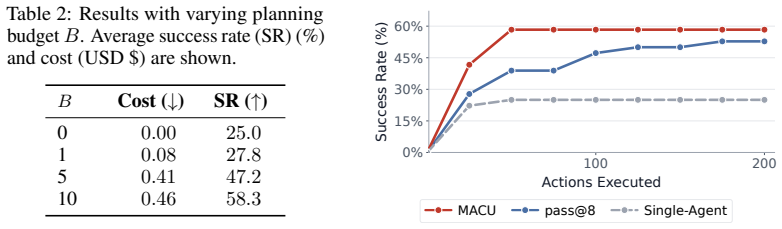
- MACU raises success rates by 3.4-25.5 percent on OSWorld, Online-Mind2Web, WebTailBench, and Odysseys.
- The method exhibits more favorable test-time scaling than single-agent baselines.
- It completes complex long-horizon tasks that single-agent systems cannot finish.
- Average task completion wall-clock time drops by a factor of roughly 1.5 on the Odysseys benchmark.
Where Pith is reading between the lines
- The DAG-plus-manager structure provides a general way to retain information across partially observable steps without requiring every subagent to re-observe the entire history.
- Parallel frontier execution could be tested on other sequential domains such as robotic manipulation or multi-step code generation where dependencies are explicit.
- The continuous revision loop suggests a route to agents that recover from early errors without restarting the entire plan.
- If the manager's revision quality improves with scale, the same architecture may support even longer tasks than those tested.
Load-bearing premise
The manager LLM can produce and maintain a useful DAG decomposition whose revisions based on subagent feedback reliably reduce overall error rates rather than introducing coordination overhead or plan errors.
What would settle it
A controlled comparison on a new long-horizon benchmark where the multi-agent system shows no accuracy gain or slower wall-clock time than the single-agent baseline across multiple runs.
Figures

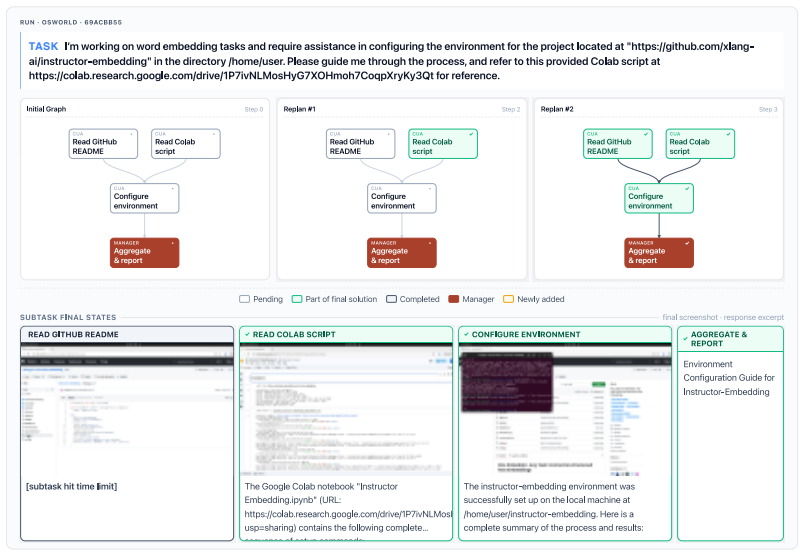
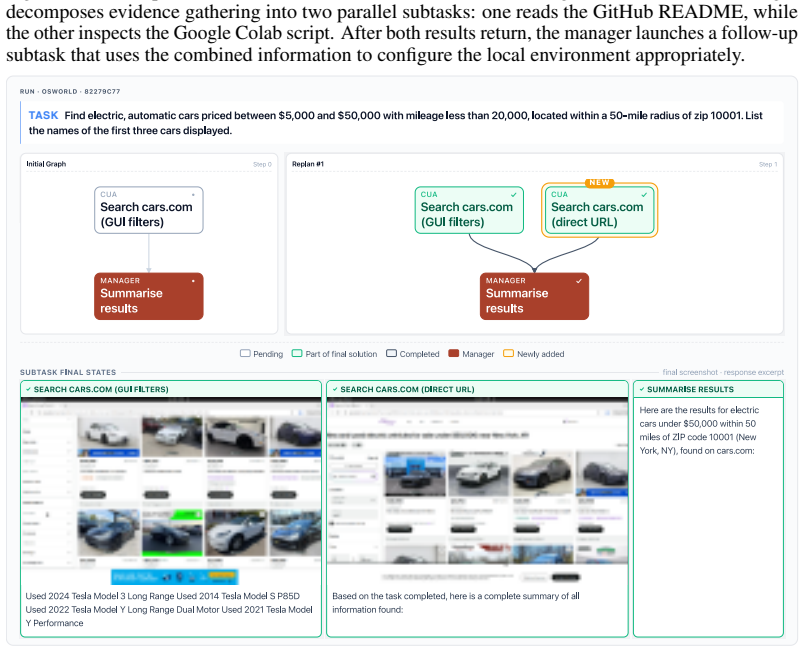
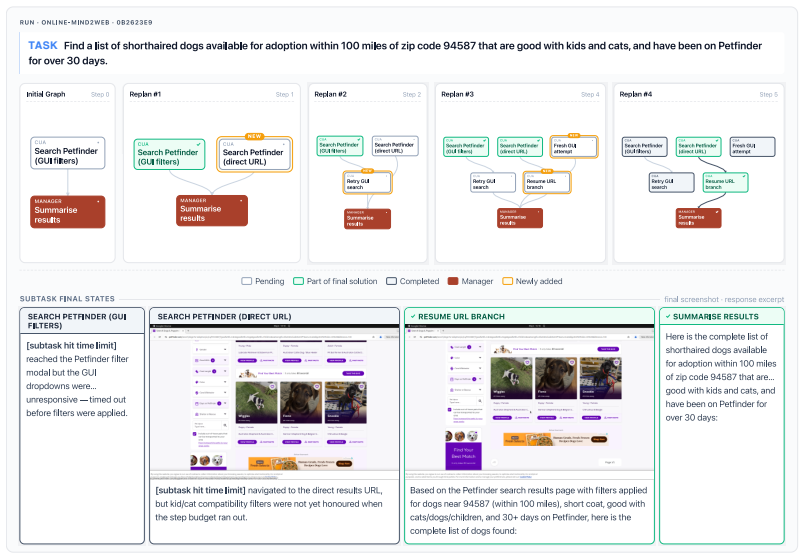
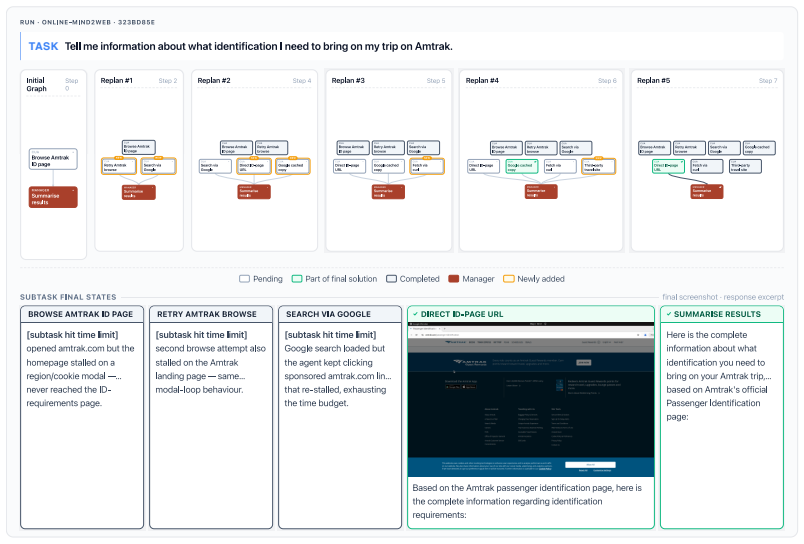



read the original abstract
Computer use agents (CUAs) today are primarily deployed as single serial agents. This setup is suboptimal for complex long-horizon tasks that benefit from task decomposition, parallel execution, and consistent re-planning based on new information. In this paper, we argue that we should instead move towards evaluating and building multi-agent computer use (MACU) systems. These systems, which emphasize planning and parallel execution, alleviate many of the shortcomings of single-agent CUAs. We propose a general multi-agent setup in which a manager model decomposes computer use tasks as a directed acyclic graph (DAG), encoding relevant dependencies and goals for subagents. At each iteration, the manager dispatches parallel CUA subagents to carry out nodes on the ready frontier of the DAG, and continuously revises the DAG (adding, canceling, or rewriting nodes) as new findings arrive from subagents. This design treats the partially observable environment of computer use as a first class challenge: information that downstream agents may not be able to re-observe are retained and passed forward through the manager and DAG structure. We demonstrate that MACU consistently improves over strong single-agent baselines by $3.4-25.5\%$ on desktop (OSWorld) and web navigation (Online-Mind2Web, WebTailBench, Odysseys) benchmarks, exhibits more favorable test-time scaling, and solves complex long-horizon tasks where single-agent CUAs get stuck. On Odysseys, a long-horizon web navigation benchmark, MACU improves average task completion wall-clock time by ${\sim} 1.5 \times$, demonstrating its efficacy in speeding up traditionally slow CUA pipelines. Our findings highlight that multi-agent coordination is a promising axis for scaling computer use agents to work productively for longer and more effectively. We release all code and interactive visualizations at https://jykoh.com/multi-agent-computer-use.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Multi-Agent Computer Use (MACU), in which a manager LLM decomposes computer-use tasks into a directed acyclic graph (DAG) that encodes dependencies and goals, dispatches parallel CUA subagents to execute ready nodes, and iteratively revises the DAG (add/cancel/rewrite nodes) on the basis of subagent feedback. The central empirical claim is that this design yields consistent gains of 3.4–25.5 % over strong single-agent baselines on OSWorld, Online-Mind2Web, WebTailBench and Odysseys, exhibits more favorable test-time scaling, solves long-horizon tasks where single agents stall, and delivers an approximately 1.5× reduction in wall-clock completion time on Odysseys. All code and visualizations are released.
Significance. If the reported gains can be shown to arise specifically from the DAG coordination and revision mechanism rather than from raw parallelism or extra compute, the work would supply a concrete, reproducible axis for scaling computer-use agents to longer horizons. The public release of code and interactive visualizations is a clear strength that supports direct verification and follow-on research.
major comments (3)
- [Experiments section] Experiments section (and any associated tables/figures reporting the 3.4–25.5 % and 1.5× figures): the manuscript compares MACU only against single-agent baselines. No control condition is described that runs multiple independent subagents (or a non-DAG parallel scheduler) under an identical total LLM budget. Without this ablation it is impossible to isolate whether the observed improvements are attributable to the manager’s DAG decomposition and revision loop or simply to increased parallelism, which directly bears on the central mechanistic claim.
- [§4] §4 (or wherever the Odysseys wall-clock results appear): the 1.5× speedup is reported without accompanying run counts, error bars, or statistical tests. If these details are absent, the reliability of the long-horizon timing claim cannot be assessed and the result remains vulnerable to the possibility that a few favorable runs drive the aggregate.
- [Method section] Method section describing the manager’s revision step: the paper states that the manager “continuously revises the DAG … as new findings arrive,” yet provides no quantitative breakdown of how often revisions add versus cancel nodes, nor any measurement of coordination overhead versus parallelism benefit. This information is required to evaluate whether the revision mechanism reliably reduces error rates or introduces plan errors that offset the reported gains.
minor comments (2)
- [Abstract / Introduction] The abstract and introduction repeatedly use the phrase “strong single-agent baselines” without an explicit citation or table entry listing the exact model, prompting, and tool-use configuration of each baseline; adding this reference would improve clarity.
- [Figures] Figure captions and axis labels in the scaling plots should explicitly state the total token budget or number of parallel agents used at each point so that readers can directly compare MACU against a matched-compute single-agent curve.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each of the three major comments below and outline the corresponding revisions.
read point-by-point responses
-
Referee: [Experiments section] Experiments section (and any associated tables/figures reporting the 3.4–25.5 % and 1.5× figures): the manuscript compares MACU only against single-agent baselines. No control condition is described that runs multiple independent subagents (or a non-DAG parallel scheduler) under an identical total LLM budget. Without this ablation it is impossible to isolate whether the observed improvements are attributable to the manager’s DAG decomposition and revision loop or simply to increased parallelism, which directly bears on the central mechanistic claim.
Authors: We agree that the current single-agent baselines do not fully isolate the contribution of the DAG coordination and revision mechanism from raw parallelism. In the revised manuscript we will add a control condition that runs multiple independent subagents (without the manager or DAG) under a matched total LLM call budget on the same benchmarks. This will allow direct comparison of the structured decomposition/revision loop against unstructured parallelism. revision: yes
-
Referee: [§4] §4 (or wherever the Odysseys wall-clock results appear): the 1.5× speedup is reported without accompanying run counts, error bars, or statistical tests. If these details are absent, the reliability of the long-horizon timing claim cannot be assessed and the result remains vulnerable to the possibility that a few favorable runs drive the aggregate.
Authors: We will augment the Odysseys wall-clock results with the number of independent runs performed, standard error bars, and appropriate statistical tests (e.g., paired t-test or Wilcoxon) to substantiate the reported 1.5× improvement. revision: yes
-
Referee: [Method section] Method section describing the manager’s revision step: the paper states that the manager “continuously revises the DAG … as new findings arrive,” yet provides no quantitative breakdown of how often revisions add versus cancel nodes, nor any measurement of coordination overhead versus parallelism benefit. This information is required to evaluate whether the revision mechanism reliably reduces error rates or introduces plan errors that offset the reported gains.
Authors: We will add a quantitative breakdown of revision actions (frequency of add / cancel / rewrite operations) extracted from the released execution logs, together with an analysis of coordination overhead (manager calls) versus net parallelism benefit, to be included in the revised Method section. revision: yes
Circularity Check
No circularity; purely empirical evaluation on public benchmarks
full rationale
The paper proposes a multi-agent computer-use architecture (manager + DAG decomposition + subagents) and reports direct empirical gains on named external benchmarks (OSWorld, Online-Mind2Web, WebTailBench, Odysseys). No equations, fitted parameters, uniqueness theorems, or self-citation chains are invoked to derive performance claims; results are measured wall-clock and success-rate deltas against single-agent baselines. The central claim therefore does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can follow instructions to decompose tasks, execute sub-tasks, and report findings in a format usable by the manager.
Reference graph
Works this paper leans on
-
[1]
Agent S2: A Compositional Generalist-Specialist Framework for Computer Use Agents
Saaket Agashe, Kyle Wong, Vincent Tu, Jiachen Yang, Ang Li, and Xin Eric Wang. Agent s2: A compositional generalist-specialist framework for computer use agents.arXiv preprint arXiv:2504.00906, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Gym-Anything: Turn any Software into an Agent Environment
Pranjal Aggarwal, Graham Neubig, and Sean Welleck. Gym-anything: Turn any software into an agent environment.arXiv preprint arXiv:2604.06126, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Why Do LLM-based Web Agents Fail? A Hierarchical Planning Perspective
Mohamed Aghzal, Gregory J Stein, and Ziyu Yao. Why do llm-based web agents fail? a hierarchical planning perspective.arXiv preprint arXiv:2603.14248, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
How we built our multi-agent research system
Anthropic. How we built our multi-agent research system. https://www.anthropic.com/ engineering/multi-agent-research-system, June 2025. Accessed: 2026-04-29
2025
-
[5]
Claude Opus 4.6 System Card
Anthropic. Claude Opus 4.6 System Card. https://www-cdn.anthropic.com/ 0dd865075ad3132672ee0ab40b05a53f14cf5288.pdf, February 2026. Published Febru- ary 6, 2026
2026
-
[6]
Fara-7b: An efficient agentic model for computer use.arXiv preprint arXiv:2511.19663, 2025
Ahmed Awadallah, Yash Lara, Raghav Magazine, Hussein Mozannar, Akshay Nambi, Yash Pandya, Aravind Rajeswaran, Corby Rosset, Alexey Taymanov, Vibhav Vineet, et al. Fara-7b: An efficient agentic model for computer use.arXiv preprint arXiv:2511.19663, 2025
-
[7]
Windows agent arena: Evaluating multi-modal os agents at scale.ICML, 2025
Rogerio Bonatti, Dan Zhao, Francesco Bonacci, Dillon Dupont, Sara Abdali, Yinheng Li, Yadong Lu, Justin Wagle, Kazuhito Koishida, Arthur Bucker, et al. Windows agent arena: Evaluating multi-modal os agents at scale.ICML, 2025
2025
-
[8]
Agentverse: Facilitating multi-agent collaboration and exploring emergent behaviors
Weize Chen, Yusheng Su, Jingwei Zuo, Cheng Yang, Chenfei Yuan, Chi-Min Chan, Heyang Yu, Yaxi Lu, Yi-Hsin Hung, Chen Qian, et al. Agentverse: Facilitating multi-agent collaboration and exploring emergent behaviors. InICLR, 2023
2023
-
[9]
Trends in cooperative distributed problem solving.IEEE Transactions on knowledge and data Engineering, 1989
Edmund H Durfee, Victor R Lesser, and Daniel D Corkill. Trends in cooperative distributed problem solving.IEEE Transactions on knowledge and data Engineering, 1989
1989
-
[10]
Apurva Gandhi, Satyaki Chakraborty, Xiangjun Wang, Aviral Kumar, and Graham Neubig. Recursive agent optimization.arXiv preprint arXiv:2605.06639, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Jiayi Geng and Graham Neubig. Effective strategies for asynchronous software engineering agents.arXiv preprint arXiv:2603.21489, 2026
-
[12]
Juraj Gottweis, Wei-Hung Weng, Alexander Daryin, Tao Tu, Anil Palepu, Petar Sirkovic, Artiom Myaskovsky, Felix Weissenberger, Keran Rong, Ryutaro Tanno, et al. Towards an ai co-scientist. arXiv preprint arXiv:2502.18864, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
MolmoWeb: Open Visual Web Agent and Open Data for the Open Web
Tanmay Gupta, Piper Wolters, Zixian Ma, Peter Sushko, Rock Yuren Pang, Diego Llanes, Yue Yang, Taira Anderson, Boyuan Zheng, Zhongzheng Ren, et al. Molmoweb: Open visual web agent and open data for the open web.arXiv preprint arXiv:2604.08516, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
Webvoyager: Building an end-to-end web agent with large multimodal models.ACL, 2024
Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, and Dong Yu. Webvoyager: Building an end-to-end web agent with large multimodal models.ACL, 2024
2024
-
[15]
Metagpt: Meta programming for a multi-agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, et al. Metagpt: Meta programming for a multi-agent collaborative framework. InICLR, 2023. 11
2023
-
[16]
Odysseys: Benchmarking web agents on realistic long horizon tasks.arXiv, 2026
Lawrence Keunho Jang, Jing Yu Koh, Daniel Fried, and Ruslan Salakhutdinov. Odysseys: Benchmarking web agents on realistic long horizon tasks.arXiv, 2026
2026
-
[17]
Visualwebarena: Evaluating multimodal agents on realistic visual web tasks.ACL, 2024
Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Russ Salakhutdinov, and Daniel Fried. Visualwebarena: Evaluating multimodal agents on realistic visual web tasks.ACL, 2024
2024
-
[18]
Tree search for language model agents.TMLR, 2025
Jing Yu Koh, Stephen McAleer, Daniel Fried, and Ruslan Salakhutdinov. Tree search for language model agents.TMLR, 2025
2025
-
[19]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention.SOPS, 2023
2023
-
[20]
InfoSeeker: A Scalable Hierarchical Parallel Agent Framework for Web Information Seeking
Ka Yiu Lee, Yuxuan Huang, Zhiyuan He, Huichi Zhou, Weilin Luo, Kun Shao, Meng Fang, and Jun Wang. Infoseeker: A scalable hierarchical parallel agent framework for web information seeking.arXiv preprint arXiv:2604.02971, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Infantagent-next: A multimodal generalist agent for automated computer interaction.NeurIPS, 2025
Bin Lei, Weitai Kang, Zijian Zhang, Winson Chen, Xi Xie, Shan Zuo, Mimi Xie, Ali Payani, Mingyi Hong, Yan Yan, et al. Infantagent-next: A multimodal generalist agent for automated computer interaction.NeurIPS, 2025
2025
-
[22]
In-the-flow agentic system optimization for effective planning and tool use.ICLR, 2025
Zhuofeng Li, Haoxiang Zhang, Seungju Han, Sheng Liu, Jianwen Xie, Yu Zhang, Yejin Choi, James Zou, and Pan Lu. In-the-flow agentic system optimization for effective planning and tool use.ICLR, 2025
2025
-
[23]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The ai scien- tist: Towards fully automated open-ended scientific discovery.arXiv preprint arXiv:2408.06292, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Weblinx: Real-world website navigation with multi-turn dialogue.ICML, 2024
Xing Han Lù, Zdenˇek Kasner, and Siva Reddy. Weblinx: Real-world website navigation with multi-turn dialogue.ICML, 2024
2024
-
[25]
Rethinking thinking tokens: Llms as improvement operators.arXiv preprint arXiv:2510.01123, 2025
Lovish Madaan, Aniket Didolkar, Suchin Gururangan, John Quan, Ruan Silva, Ruslan Salakhut- dinov, Manzil Zaheer, Sanjeev Arora, and Anirudh Goyal. Rethinking thinking tokens: Llms as improvement operators.arXiv preprint arXiv:2510.01123, 2025
-
[26]
Malt: Improving reasoning with multi-agent llm training.COLM, 2025
Sumeet Ramesh Motwani, Chandler Smith, Rocktim Jyoti Das, Rafael Rafailov, Ivan Laptev, Philip HS Torr, Fabio Pizzati, Ronald Clark, and Christian Schroeder de Witt. Malt: Improving reasoning with multi-agent llm training.COLM, 2025
2025
-
[27]
Learning to orchestrate agents in natural language with the conductor.ICLR, 2026
Stefan Nielsen, Edoardo Cetin, Peter Schwendeman, Qi Sun, Jinglue Xu, and Yujin Tang. Learning to orchestrate agents in natural language with the conductor.ICLR, 2026
2026
-
[28]
GPT-5.4 Thinking System Card
OpenAI. GPT-5.4 Thinking System Card. OpenAI Deployment Safety Hub, https: //deploymentsafety.openai.com/gpt-5-4-thinking , March 2026. Published March 5, 2026
2026
-
[29]
Learning to reason across parallel samples for llm reasoning.arXiv preprint arXiv:2506.09014, 2025
Jianing Qi, Xi Ye, Hao Tang, Zhigang Zhu, and Eunsol Choi. Learning to reason across parallel samples for llm reasoning.arXiv preprint arXiv:2506.09014, 2025
-
[30]
Scaling large language model-based multi-agent collabora- tion.ICLR, 2025
Chen Qian, Zihao Xie, Yifei Wang, Wei Liu, Kunlun Zhu, Hanchen Xia, Yufan Dang, Zhuoyun Du, Weize Chen, Cheng Yang, et al. Scaling large language model-based multi-agent collabora- tion.ICLR, 2025
2025
-
[31]
Qwen3.6-Plus: Towards real world agents
Qwen Team. Qwen3.6-Plus: Towards real world agents. https://qwen.ai/blog?id=qwen3. 6, April 2026
2026
-
[32]
A framework for distributed problem solving.IJCAI, 1979
Reid G Smith. A framework for distributed problem solving.IJCAI, 1979
1979
-
[33]
Coact-1: Computer-using agents with coding as actions.ICLR, 2026
Linxin Song, Yutong Dai, Viraj Prabhu, Jieyu Zhang, Taiwei Shi, Li Li, Junnan Li, Silvio Savarese, Zeyuan Chen, Jieyu Zhao, et al. Coact-1: Computer-using agents with coding as actions.ICLR, 2026. 12
2026
-
[34]
Kimi K2: Open Agentic Intelligence
Kimi Team, Yifan Bai, Yiping Bao, Y Charles, Cheng Chen, Guanduo Chen, Haiting Chen, Huarong Chen, Jiahao Chen, Ningxin Chen, et al. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Qwen Team. Qwen3.5-omni technical report.arXiv preprint arXiv:2604.15804, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
Inducing programmatic skills for agentic tasks.COLM, 2025
Zora Zhiruo Wang, Apurva Gandhi, Graham Neubig, and Daniel Fried. Inducing programmatic skills for agentic tasks.COLM, 2025
2025
-
[37]
Agent workflow memory
Zora Zhiruo Wang, Jiayuan Mao, Daniel Fried, and Graham Neubig. Agent workflow memory. ICML, 2025
2025
-
[38]
John wiley & sons, 2009
Michael Wooldridge.An introduction to multiagent systems. John wiley & sons, 2009
2009
-
[39]
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments.NeurIPS, 2024
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh J Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, et al. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments.NeurIPS, 2024
2024
-
[40]
Trinity: An evolved llm coordinator.ICLR, 2026
Jinglue Xu, Qi Sun, Peter Schwendeman, Stefan Nielsen, Edoardo Cetin, and Yujin Tang. Trinity: An evolved llm coordinator.ICLR, 2026
2026
-
[41]
An illusion of progress? assessing the current state of web agents.COLM, 2025
Tianci Xue, Weijian Qi, Tianneng Shi, Chan Hee Song, Boyu Gou, Dawn Song, Huan Sun, and Yu Su. An illusion of progress? assessing the current state of web agents.COLM, 2025
2025
-
[42]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InICLR, 2022
2022
-
[43]
Building the proactive, multi-agent ar- chitecture powering scouts
Yutori team. Building the proactive, multi-agent ar- chitecture powering scouts. https://yutori.com/blog/ building-the-proactive-multi-agent-architecture-powering-scouts , De- cember 2025. Accessed: 2026-04-29
2025
-
[44]
Alex L Zhang, Tim Kraska, and Omar Khattab. Recursive language models.arXiv preprint arXiv:2512.24601, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
AgentOrchestra: Orchestrating Multi-Agent Intelligence with the Tool-Environment-Agent(TEA) Protocol
Wentao Zhang, Liang Zeng, Yuzhen Xiao, Yongcong Li, Ce Cui, Yilei Zhao, Rui Hu, Yang Liu, Yahui Zhou, and Bo An. Agentorchestra: Orchestrating multi-agent intelligence with the tool-environment-agent (tea) protocol.arXiv preprint arXiv:2506.12508, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Wenting Zhao, Pranjal Aggarwal, Swarnadeep Saha, Asli Celikyilmaz, Jason Weston, and Ilia Kulikov. The majority is not always right: Rl training for solution aggregation.arXiv preprint arXiv:2509.06870, 2025
-
[47]
Webarena: A realistic web environment for building autonomous agents.ICLR, 2024
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. Webarena: A realistic web environment for building autonomous agents.ICLR, 2024
2024
-
[48]
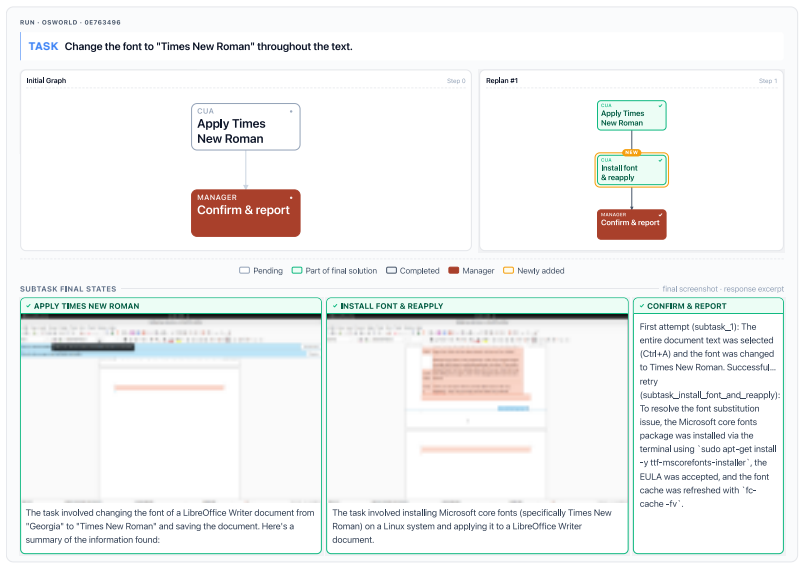
Times New Roman
Mingchen Zhuge, Wenyi Wang, Louis Kirsch, Francesco Faccio, Dmitrii Khizbullin, and Jürgen Schmidhuber. Language agents as optimizable graphs.ICML, 2024. 13 A Additional Experimental Details Table 7: Experimental settings used by the main MACU experiments. Setting Value Manager provider and model Anthropicclaude-opus-4-6 CUA worker for main experimentsQwe...
2024
-
[49]
Open Terminal
First, open a terminal (right-click on the desktop and select “Open Terminal”, or find Terminal in the application menu, or press Ctrl+Alt+T)
-
[50]
If prompted for a license agreement, accept it (press Tab to highlight OK/Yes, then Enter)
Install Microsoft core fonts by running:sudo apt-get update && sudo apt-get install -y ttf-mscorefonts-installer. If prompted for a license agreement, accept it (press Tab to highlight OK/Yes, then Enter). If that package name doesn’t work, try:sudo apt-get install -y fonts-liberation(Liberation Serif is metrically equivalent to Times New Roman, but the a...
-
[51]
After installation, run:fc-cache -fv
-
[52]
Close the terminal and go back to LibreOffice Writer with Dublin_Zoo_Intro.docx
-
[53]
Close and reopen the document (File > Close, then File > Recent Documents or reopen from Desktop) so LibreOffice picks up the newly installed fonts
-
[54]
Select all text with Ctrl+A
-
[55]
Times New Roman
Click on the font name dropdown, type “Times New Roman”, and press Enter
-
[56]
Verify there is NO warning about font substitution
-
[57]
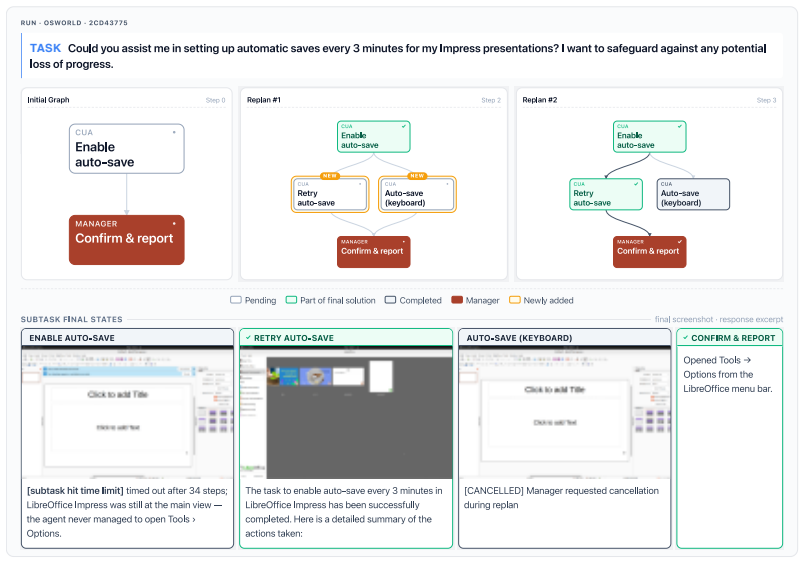
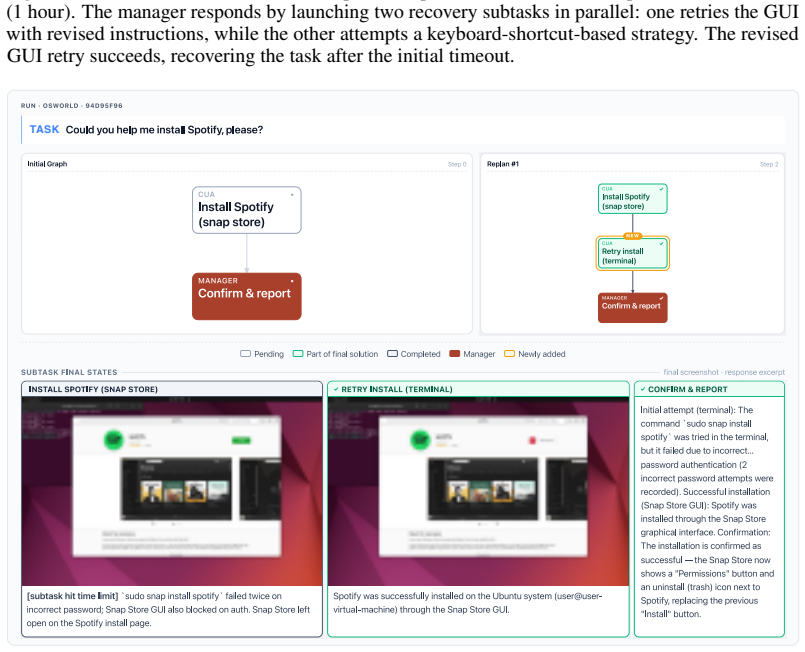
Save the document with Ctrl+S. The file is located at/home/user/Desktop/Dublin_Zoo_Intro.docx. 19 TASK Figure 8: In this task, the initial GUI attempt to set up automatic saves hits the per-subtask time limit (1 hour). The manager responds by launching two recovery subtasks in parallel: one retries the GUI with revised instructions, while the other attemp...
-
[58]
Do NOT manufacture parallelism by inventing additional websites, sources, or actions that the task did not ask for
**Exploit natural parallelism**: Decompose into parallel subtasks only when the task itself clearly requires independent pieces of work (e.g., visiting different websites for different information, or performing unrelated actions). Do NOT manufacture parallelism by inventing additional websites, sources, or actions that the task did not ask for
-
[59]
If the task says "find X," search on one appropriate site -- do not fan out across multiple competing sites unless the task explicitly asks to compare across sources
**Faithful decomposition**: Only include subtasks that are explicitly stated or clearly implied by the task. If the task says "find X," search on one appropriate site -- do not fan out across multiple competing sites unless the task explicitly asks to compare across sources
-
[60]
**Respect dependencies**: If a subtask needs the output of another subtask (e.g., using a price from one site to make a decision on another), it must declare that dependency
-
[61]
A single subtask is perfectly valid if the task is inherently sequential or targets a single site
**Minimal decomposition**: Prefer fewer, coarser subtasks over many fine-grained ones. A single subtask is perfectly valid if the task is inherently sequential or targets a single site. Only split when there is a clear, task-driven reason for each independent branch
-
[62]
A subtask should typically involve interacting with one website or a small set of closely related pages
**Atomic subtasks**: Each subtask should be a self-contained unit of work that one subagent can complete independently. A subtask should typically involve interacting with one website or a small set of closely related pages
-
[63]
**Clear outputs**: Each subtask must specify what information or browser state it produces, so dependent subtasks know what inputs they will receive
-
[64]
Find a Hotel in New York City with lowest price possible for 2 adults next weekend
**Final aggregation**: There should always be a final subtask that synthesizes results from all other subtasks into the final deliverable (summary, document, spreadsheet, etc.). ## How to Decompose Tasks When analyzing a task: - Read the task carefully and identify only the actions and websites it actually requires. - Do NOT add extra websites or sources ...
-
[65]
**After a CUA subtask finishes.** You look at its result (text response + screenshot) and decide whether the PENDING portion of the graph should be modified in light of the new information
-
[66]
The focus subtask shown to you is a currently-running CUA subtask (its screenshot reflects live state, not a final result)
**Spare-capacity consult — worker slots are idle.** No new work can be scheduled from the current pending set, but parallelism is available. The focus subtask shown to you is a currently-running CUA subtask (its screenshot reflects live state, not a final result). This trigger fires only when `spare_slots > 0`. Your job is to decide how to use the idle ca...
-
[67]
Structural variants
**Mid-run check-in on a running subtask.** The focus subtask has accumulated enough steps to warrant an assessment of its progress. This trigger fires regardless of whether spare worker slots are available and at most once per subtask. Your job is to decide whether to let it continue, cancel it, or cancel + replace it with a revised instruction.`spare_slo...
-
[68]
Cancellation
You MUST NOT modify or remove any subtask whose id appears in`frozen_ids`OR`running_ids`.` frozen_ids`lists COMPLETED subtasks — their results are permanent; if a completed subtask failed and you want to retry it, ADD a new subtask with a different id that reruns the work (the original failed subtask stays in the graph as-is).`running_ids`lists CURRENTLY-...
-
[69]
You MUST NOT introduce dependency cycles
-
[70]
Continued on next page 32 Table 12: Replanning manager prompt
Every dependency id you declare on a new or modified subtask must reference either: (a) a subtask that already exists in the current graph (completed, running, or pending), or (b) another subtask that you are adding in THIS decision. Continued on next page 32 Table 12: Replanning manager prompt. (continued) Prompt text
-
[71]
You MUST NOT change the id or`agent_type`of`final_aggregation`. You MAY edit its`instruction `and`dependencies`if you are adding or removing upstream subtasks -- in fact, whenever you add a new subtask (including a structural variant) that the final answer should incorporate, you MUST update`final_aggregation.dependencies`to include it
-
[72]
cua"`or`
Every new subtask must have:`id`(unique, not colliding with any existing id),`agent_type`(`" cua"`or`"manager"`),`description`,`dependencies`(list), and`instruction`. CUA-type subtasks must also include an`outputs`list
-
[73]
Replanning is expensive and churning the graph unnecessarily is worse than leaving it alone
Prefer`no_change`when the situation does not meaningfully improve by modifying the graph. Replanning is expensive and churning the graph unnecessarily is worse than leaving it alone
-
[74]
The user prompt will tell you how many replans remain after this call
You have a FINITE replanning budget per task run. The user prompt will tell you how many replans remain after this call. Treat each replan as a scarce resource
-
[75]
I think a different approach would work better
**Structural variants:** A`variant_of`entry in`add[]`MUST reference an existing CUA subtask and have`agent_type: "cua"`. The variant's`dependencies`MUST match the`variant_of`subtask's current dependencies unless you have a specific reason to change them (so the variant forks from the same preconditions as its original, not from the original itself — a var...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.