Self-Improving Small Object Grounding in LVLMs
Pith reviewed 2026-06-28 15:46 UTC · model grok-4.3
The pith
Attention patterns inside large vision-language models encode enough information to select reliable boxes for small objects without any fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
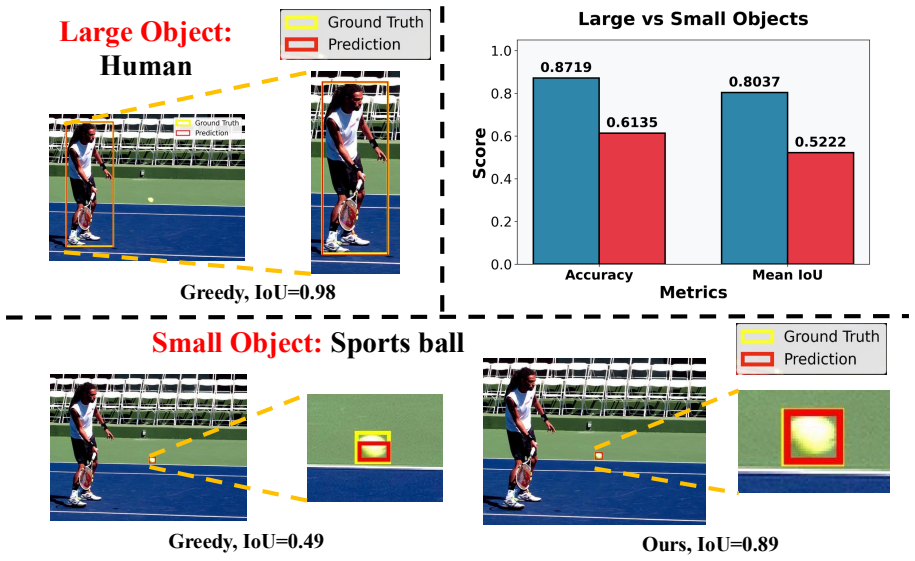
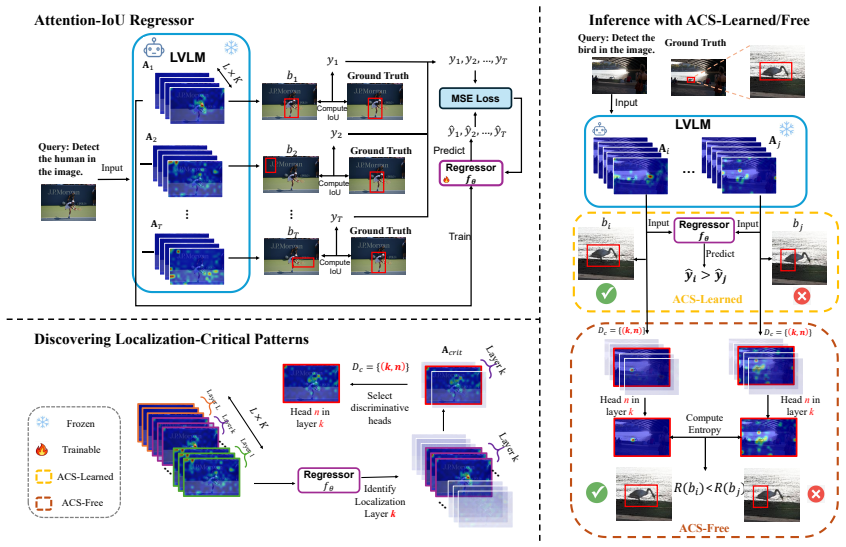
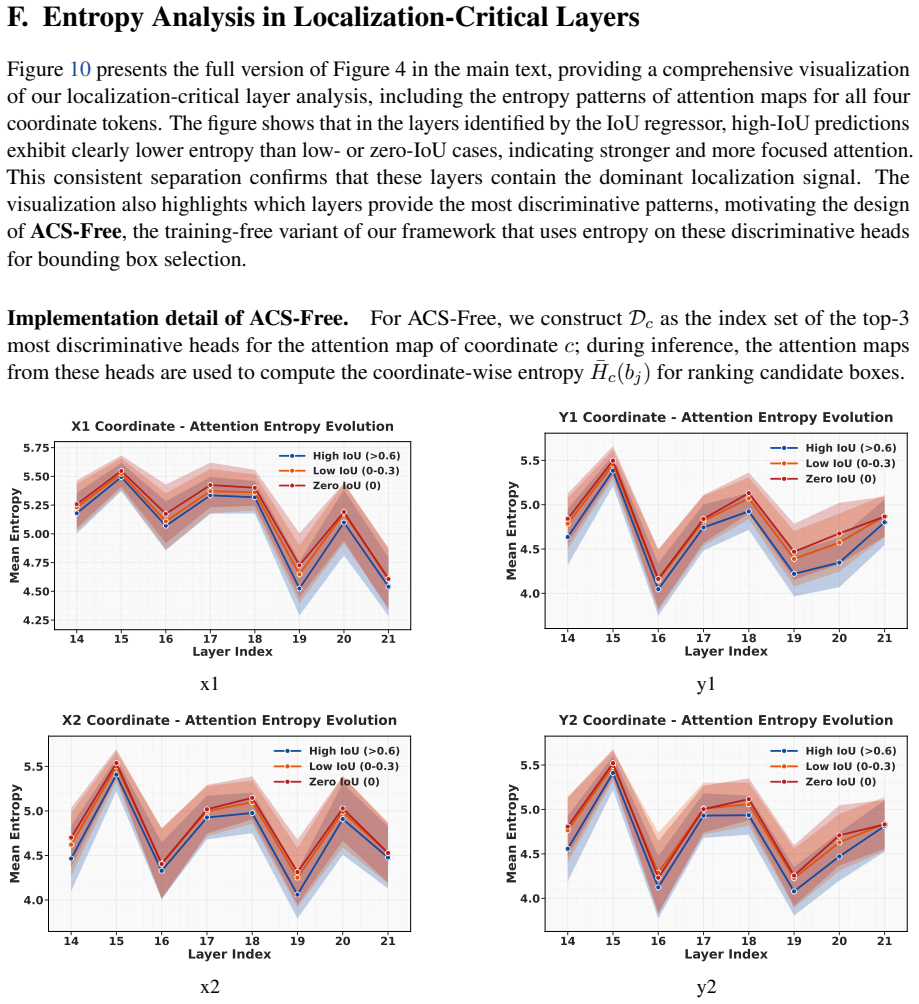
Attention structure in LVLMs encodes grounding quality. A lightweight IoU regressor trained solely on attention maps achieves strong IoU prediction with Pearson r greater than 0.67. This regressor powers the regressor-based variant of the Attention-based Candidate Selection framework, which selects the best box from multiple sampled candidates. By analyzing the regressor, the authors identify the most critical layers and heads and derive a training-free selector that ranks candidates by attention entropy on those heads, yielding up to 19 percent self-improvement on small-object localization on COCO and Objects365.
What carries the argument
Attention-based Candidate Selection (ACS) framework, where ACS-Free ranks candidate boxes by attention entropy computed on the subset of heads identified as most discriminative by an IoU regressor trained on attention maps.
If this is right
- Small-object localization accuracy rises by as much as 19 percent on COCO and Objects365 when the selector is applied.
- ACS-Free outperforms every other training-free baseline on the same task.
- The method improves both localization reliability and the interpretability of which heads matter for grounding.
- The regressor analysis directly reveals which transformer layers and heads are most critical for object grounding quality.
Where Pith is reading between the lines
- The same attention-derived signal could be used to self-correct other vision-language outputs such as region descriptions or visual question answering without additional labels.
- If the discriminative heads generalize across model families, the training-free selector could be applied to new LVLMs with no extra data collection.
- The entropy-ranking step suggests that internal attention diversity on specific heads serves as a proxy for localization certainty that may apply to related grounding problems.
Load-bearing premise
Attention maps produced by the base LVLM remain informative and consistent enough across images and models that a single regressor can be trained once and then used to both predict box quality and identify stable discriminative heads for entropy ranking.
What would settle it
Running the trained IoU regressor on attention maps extracted from a held-out LVLM or a new image distribution and obtaining Pearson r below 0.5 would show that the attention structure does not reliably encode grounding quality.
Figures
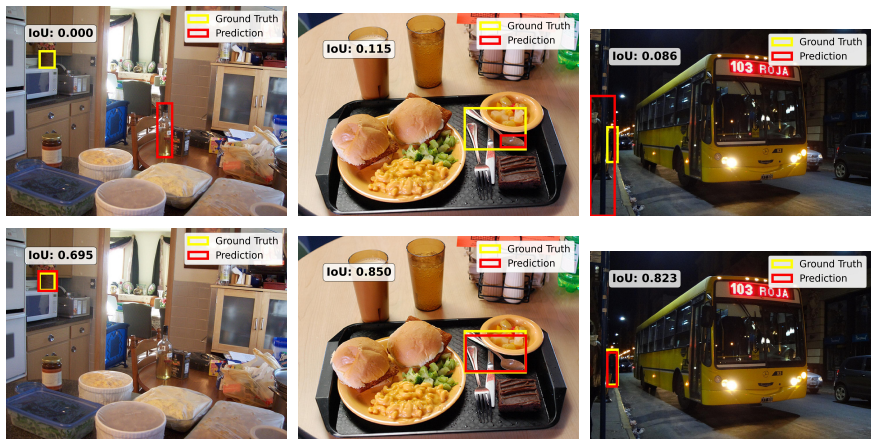



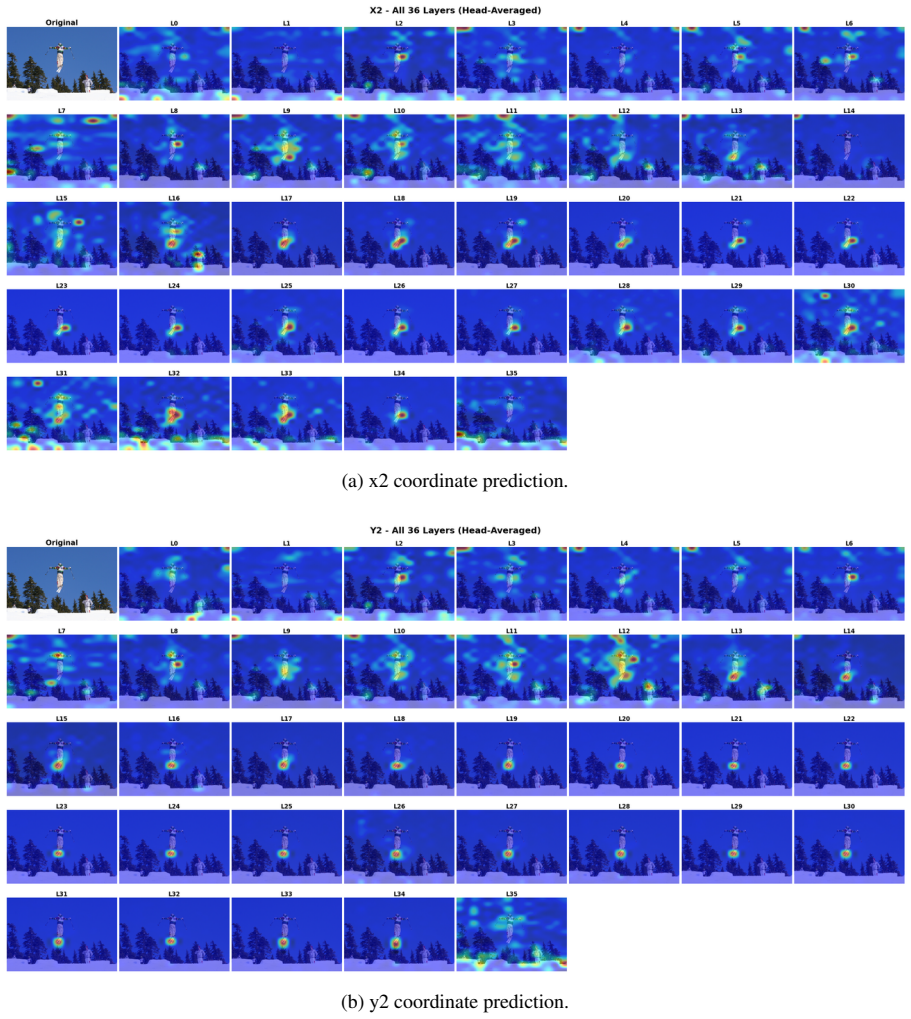





read the original abstract
Can internal attention patterns in Large Vision Language Models (LVLMs) identify reliable small-object boxes without fine-tuning? In this work, we provide an affirmative answer. Attention structure in LVLMs encodes grounding quality-a lightweight IoU regressor trained solely on attention maps achieves strong IoU prediction (Pearson r > 0.67). This regressor powers the regressor-based variant of our Attention-based Candidate Selection (ACS) framework, called ACS-Learned, which selects the best box from multiple sampled candidates to improve object grounding. By analyzing what the regressor learns, we reveal which transformer layers and heads are most critical and derive ACS-Free: a training-free selector that ranks candidates by attention entropy on these discriminative heads, with no learned component at inference. Experiments on COCO and Objects365 demonstrate up to 19% self-improvement on small object localization, with ACS-Free ranking best among all training-free methods, demonstrating that useful attention structure improves both localization reliability and interpretability in LVLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that attention patterns in LVLMs encode small-object grounding quality. A lightweight regressor trained only on attention maps achieves Pearson r > 0.67 for IoU prediction; this enables ACS-Learned (regressor-based candidate selection) and, via analysis of learned heads, a training-free ACS-Free variant that ranks candidates by attention entropy on discriminative heads. Experiments on COCO and Objects365 report up to 19% self-improvement in small-object localization, with ACS-Free outperforming other training-free baselines.
Significance. If the reported correlations and improvements hold under proper controls, the work would demonstrate that internal attention structure can be leveraged for reliable localization and interpretability gains without fine-tuning or external labels at inference. The derivation of a training-free selector from the regressor analysis is a notable strength if the selected heads prove stable.
major comments (3)
- [§4 and Experiments] §4 (Regressor training) and Experiments: The central claim that attention maps are sufficiently informative and stable for a generalizable IoU regressor (r > 0.67) and for identifying heads usable across images/models rests on the regressor evaluation. No details are provided on train/test splits for the regressor, cross-model testing, or whether the same heads transfer without retraining; this directly affects whether ACS-Free can be applied without model-specific labels.
- [Table 2 / main results] Table 2 / main results: The 19% improvement and ranking of ACS-Free are reported, but without statistical significance tests, standard errors across seeds, or explicit baseline implementations (including how candidate boxes are sampled), it is impossible to assess whether the gains are robust or attributable to post-hoc head selection.
- [§5.3] §5.3 (head analysis): The claim that the regressor reveals 'most critical' layers/heads for ACS-Free assumes the learned weights generalize; if the regressor was fit on a single LVLM architecture, the entropy selector may not transfer, undermining the training-free claim.
minor comments (2)
- [Abstract and §3] Abstract and §3: 'Pearson r > 0.67' should specify the exact value, confidence interval, and number of samples for reproducibility.
- [§3] Notation for attention maps and entropy computation should be formalized with an equation to avoid ambiguity in the ACS-Free definition.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to incorporate additional details, clarifications, and robustness checks where appropriate.
read point-by-point responses
-
Referee: [§4 and Experiments] §4 (Regressor training) and Experiments: The central claim that attention maps are sufficiently informative and stable for a generalizable IoU regressor (r > 0.67) and for identifying heads usable across images/models rests on the regressor evaluation. No details are provided on train/test splits for the regressor, cross-model testing, or whether the same heads transfer without retraining; this directly affects whether ACS-Free can be applied without model-specific labels.
Authors: We agree that these details are necessary for assessing generalizability. The regressor was trained on an 80/20 random split of attention-IoU pairs generated from COCO images using the target LVLM; we will explicitly state this split (and the resulting test-set Pearson r) in the revised §4. Our experiments are conducted on a single LVLM architecture, with heads identified and used per-model; ACS-Free therefore requires no additional labels at inference for that model. We will add a limitations paragraph clarifying that cross-model transfer of the selected heads is not claimed and is left for future work. revision: yes
-
Referee: [Table 2 / main results] Table 2 / main results: The 19% improvement and ranking of ACS-Free are reported, but without statistical significance tests, standard errors across seeds, or explicit baseline implementations (including how candidate boxes are sampled), it is impossible to assess whether the gains are robust or attributable to post-hoc head selection.
Authors: We acknowledge the need for these controls. In the revision we will report standard errors over five random seeds for all methods in Table 2 and include paired t-test p-values for the reported improvements versus baselines. We will also expand the experimental setup section to detail the candidate sampling procedure (temperature-based decoding with fixed prompt) and the exact re-implementations of the training-free baselines used for comparison. revision: yes
-
Referee: [§5.3] §5.3 (head analysis): The claim that the regressor reveals 'most critical' layers/heads for ACS-Free assumes the learned weights generalize; if the regressor was fit on a single LVLM architecture, the entropy selector may not transfer, undermining the training-free claim.
Authors: The head analysis and resulting entropy selector in §5.3 are derived from and applied to the same single LVLM used throughout the paper; no cross-model generalization of the selected heads is asserted. We will revise the wording in §5.3 and the abstract to make this scope explicit and to avoid any implication that the entropy selector transfers without re-derivation on a new model. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and reader summary show a standard supervised setup: a regressor is trained on attention maps to predict an external IoU metric (Pearson r reported as empirical result). ACS-Learned uses this regressor for selection, while ACS-Free derives discriminative heads from the same regressor and applies entropy ranking without learned parameters at inference. No quoted equations or steps reduce by construction to fitted inputs, self-definitions, or self-citation load-bearing chains. The central claims rest on external evaluation (COCO, Objects365) rather than tautological renaming or ansatz smuggling. This is the expected non-finding for a paper whose derivation remains independent of its own outputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
ICML 2024 Tutorial: Physics of Language Models, July 2024
Zeyuan Allen-Zhu. ICML 2024 Tutorial: Physics of Language Models, July 2024. Project page: https://physics.allen-zhu.com/
2024
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Unveiling visual perception in language models: An attention head analysis approach
Jing Bi, Junjia Guo, Yunlong Tang, Lianggong Bruce Wen, Zhang Liu, Bingjie Wang, and Chenliang Xu. Unveiling visual perception in language models: An attention head analysis approach. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 4135–4144, 2025
2025
-
[4]
Shikra: Unleashing Multimodal LLM's Referential Dialogue Magic
Keqin Chen, Zhao Zhang, Weili Zeng, Richong Zhang, Feng Zhu, and Rui Zhao. Shikra: Unleashing multimodal llm’s referential dialogue magic.arXiv preprint arXiv:2306.15195, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
arXiv preprint arXiv:2503.01773 , year=
Shiqi Chen, Tongyao Zhu, Ruochen Zhou, Jinghan Zhang, Siyang Gao, Juan Carlos Niebles, Mor Geva, Junxian He, Jiajun Wu, and Manling Li. Why is spatial reasoning hard for vlms? an attention mechanism perspective on focus areas.arXiv preprint arXiv:2503.01773, 2025
-
[6]
Visual chain-of-thought prompting for knowledge-based visual reasoning
Zhenfang Chen, Qinhong Zhou, Yikang Shen, Yining Hong, Zhiqing Sun, Dan Gutfreund, and Chuang Gan. Visual chain-of-thought prompting for knowledge-based visual reasoning. InPro- ceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 1254–1262, 2024
2024
-
[7]
Vision-language models can self-improve reasoning via reflection
Kanzhi Cheng, Li YanTao, Fangzhi Xu, Jianbing Zhang, Hao Zhou, and Yang Liu. Vision-language models can self-improve reasoning via reflection. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 8876–8892, 2025
2025
-
[8]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
John Wiley & Sons, 1999
Thomas M Cover.Elements of information theory. John Wiley & Sons, 1999
1999
-
[10]
Molmo and pixmo: Open weights and open data for state-of-the-art vision-language models
Matt Deitke, Christopher Clark, Sangho Lee, Rohun Tripathi, Yue Yang, Jae Sung Park, Moham- madreza Salehi, Niklas Muennighoff, Kyle Lo, Luca Soldaini, et al. Molmo and pixmo: Open weights and open data for state-of-the-art vision-language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 91–104, 2025. 11
2025
-
[11]
Your large vision-language model only needs a few attention heads for visual grounding
Seil Kang, Jinyeong Kim, Junhyeok Kim, and Seong Jae Hwang. Your large vision-language model only needs a few attention heads for visual grounding. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 9339–9350, 2025
2025
-
[12]
Segment anything
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. InProceedings of the IEEE/CVF international conference on computer vision, pages 4015–4026, 2023
2023
-
[13]
Lisa: Reasoning segmentation via large language model
Xin Lai, Zhuotao Tian, Yukang Chen, Yanwei Li, Yuhui Yuan, Shu Liu, and Jiaya Jia. Lisa: Reasoning segmentation via large language model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9579–9589, 2024
2024
-
[14]
Text4seg: Reimagining image segmentation as text generation.arXiv preprint arXiv:2410.09855, 2024
Mengcheng Lan, Chaofeng Chen, Yue Zhou, Jiaxing Xu, Yiping Ke, Xinjiang Wang, Litong Feng, and Wayne Zhang. Text4seg: Reimagining image segmentation as text generation.arXiv preprint arXiv:2410.09855, 2024
-
[15]
Jiaxi Li, Yucheng Shi, Jin Lu, and Ninghao Liu. Mits: Enhanced tree search reasoning for llms via pointwise mutual information.arXiv preprint arXiv:2510.03632, 2025
-
[16]
Making language models better reasoners with step-aware verifier
Yifei Li, Zeqi Lin, Shizhuo Zhang, Qiang Fu, Bei Chen, Jian-Guang Lou, and Weizhu Chen. Making language models better reasoners with step-aware verifier. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5315–5333, 2023
2023
-
[17]
Yiwei Li, Yikang Liu, Jiaqi Guo, Lin Zhao, Zheyuan Zhang, Xiao Chen, Boris Mailhe, Ankush Mukherjee, Terrence Chen, and Shanhui Sun. Rau: Reference-based anatomical understanding with vision language models.arXiv preprint arXiv:2509.22404, 2025
-
[18]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[19]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014
2014
-
[20]
Training-free open-ended object detection and segmenta- tion via attention as prompts.Advances in Neural Information Processing Systems, 37:69588–69606, 2024
Zhiwei Lin, Yongtao Wang, and Zhi Tang. Training-free open-ended object detection and segmenta- tion via attention as prompts.Advances in Neural Information Processing Systems, 37:69588–69606, 2024
2024
-
[21]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
2023
-
[22]
Seg-Zero: Reasoning-Chain Guided Segmentation via Cognitive Reinforcement
Yuqi Liu, Bohao Peng, Zhisheng Zhong, Zihao Yue, Fanbin Lu, Bei Yu, and Jiaya Jia. Seg-zero: Reasoning-chain guided segmentation via cognitive reinforcement.arXiv preprint arXiv:2503.06520, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Mutual reasoning makes smaller llms stronger problem-solvers.arXiv preprint arXiv:2408.06195, 2024
Zhenting Qi, Mingyuan Ma, Jiahang Xu, Li Lyna Zhang, Fan Yang, and Mao Yang. Mutual reasoning makes smaller llms stronger problem-solvers.arXiv preprint arXiv:2408.06195, 2024
-
[24]
Pixellm: Pixel reasoning with large multimodal model
Zhongwei Ren, Zhicheng Huang, Yunchao Wei, Yao Zhao, Dongmei Fu, Jiashi Feng, and Xiaojie Jin. Pixellm: Pixel reasoning with large multimodal model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26374–26383, 2024
2024
-
[25]
Grad-cam: visual explanations from deep networks via gradient-based localization
Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-cam: visual explanations from deep networks via gradient-based localization. International journal of computer vision, 128:336–359, 2020. 12
2020
-
[26]
Objects365: A large-scale, high-quality dataset for object detection
Shuai Shao, Zeming Li, Tianyuan Zhang, Chao Peng, Gang Yu, Xiangyu Zhang, Jing Li, and Jian Sun. Objects365: A large-scale, high-quality dataset for object detection. InProceedings of the IEEE/CVF international conference on computer vision, pages 8430–8439, 2019
2019
-
[27]
Groundvlp: Harnessing zero- shot visual grounding from vision-language pre-training and open-vocabulary object detection
Haozhan Shen, Tiancheng Zhao, Mingwei Zhu, and Jianwei Yin. Groundvlp: Harnessing zero- shot visual grounding from vision-language pre-training and open-vocabulary object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 4766–4775, 2024
2024
-
[28]
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
Haozhan Shen, Peng Liu, Jingcheng Li, Chunxin Fang, Yibo Ma, Jiajia Liao, Qiaoli Shen, Zilun Zhang, Kangjia Zhao, Qianqian Zhang, Ruochen Xu, and Tiancheng Zhao. Vlm-r1: A stable and generalizable r1-style large vision-language model.arXiv preprint arXiv:2504.07615, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Yucheng Shi, Quanzheng Li, Jin Sun, Xiang Li, and Ninghao Liu. Enhancing cognition and explainability of multimodal foundation models with self-synthesized data.arXiv preprint arXiv:2502.14044, 2025
-
[30]
Searchrag: Can search engines be helpful for llm-based medical question answering? In2025 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), pages 4051–4056
Yucheng Shi, Tianze Yang, Canyu Chen, Quanzheng Li, Tianming Liu, Xiang Li, and Ninghao Liu. Searchrag: Can search engines be helpful for llm-based medical question answering? In2025 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), pages 4051–4056. IEEE, 2025
2025
-
[31]
Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps
Karen Simonyan. Deep inside convolutional networks: Visualising image classification models and saliency maps.arXiv preprint arXiv:1312.6034, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[32]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Follow the wisdom of the crowd: Effective text generation via minimum bayes risk decoding
Mirac Suzgun, Luke Melas-Kyriazi, and Dan Jurafsky. Follow the wisdom of the crowd: Effective text generation via minimum bayes risk decoding. InFindings of the Association for Computational Linguistics: ACL 2023, pages 4265–4293, 2023
2023
-
[34]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdh- ery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[36]
Controlmllm: Training-free visual prompt learning for multimodal large language models.Advances in Neural Information Processing Systems, 37:45206–45234, 2024
Mingrui Wu, Xinyue Cai, Jiayi Ji, Jiale Li, Oucheng Huang, Gen Luo, Hao Fei, Guannan Jiang, Xiaoshuai Sun, and Rongrong Ji. Controlmllm: Training-free visual prompt learning for multimodal large language models.Advances in Neural Information Processing Systems, 37:45206–45234, 2024
2024
-
[37]
F-lmm: Grounding frozen large multimodal models
Size Wu, Sheng Jin, Wenwei Zhang, Lumin Xu, Wentao Liu, Wei Li, and Chen Change Loy. F-lmm: Grounding frozen large multimodal models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 24710–24721, 2025
2025
-
[38]
Can LLMs Express Their Uncertainty? An Empirical Evaluation of Confidence Elicitation in LLMs
Miao Xiong, Zhiyuan Hu, Xinyang Lu, Yifei Li, Jie Fu, Junxian He, and Bryan Hooi. Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms.arXiv preprint arXiv:2306.13063, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Concept-Centric Token Interpretation for Vector-Quantized Generative Models
Tianze Yang, Yucheng Shi, Mengnan Du, Xuansheng Wu, Qiaoyu Tan, Jin Sun, and Ninghao Liu. Concept-centric token interpretation for vector-quantized generative models.arXiv preprint arXiv:2506.00698, 2025. 13
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Tree of thoughts: Deliberate problem solving with large language models.Advances in neural information processing systems, 36:11809–11822, 2023
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models.Advances in neural information processing systems, 36:11809–11822, 2023
2023
-
[41]
Rod-mllm: Towards more reliable object detection in multimodal large language models
Heng Yin, Yuqiang Ren, Ke Yan, Shouhong Ding, and Yongtao Hao. Rod-mllm: Towards more reliable object detection in multimodal large language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14358–14368, June 2025
2025
-
[42]
Griffon v2: Advancing multimodal perception with high-resolution scaling and visual-language co-referring
Yufei Zhan, Shurong Zheng, Yousong Zhu, Hongyin Zhao, Fan Yang, Ming Tang, and Jinqiao Wang. Griffon v2: Advancing multimodal perception with high-resolution scaling and visual-language co-referring. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22947–22957, 2025
2025
-
[43]
Jiarui Zhang, Mahyar Khayatkhoei, Prateek Chhikara, and Filip Ilievski. Towards perceiving small visual details in zero-shot visual question answering with multimodal llms.arXiv preprint arXiv:2310.16033, 2023
-
[44]
Attention entropy is a key factor: An analysis of parallel context encoding with full-attention-based pre-trained language models
Zhisong Zhang, Yan Wang, Xinting Huang, Tianqing Fang, Hongming Zhang, Chenlong Deng, Shuaiyi Li, and Dong Yu. Attention entropy is a key factor: An analysis of parallel context encoding with full-attention-based pre-trained language models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ...
2025
-
[45]
bbox_2d": [x1, y1, x2, y2],
Xingyi Zhou, Rohit Girdhar, Armand Joulin, Philipp Krähenbühl, and Ishan Misra. Detecting twenty-thousand classes using image-level supervision. InEuropean conference on computer vision, pages 350–368. Springer, 2022. 14 APPENDIX Appendix Table of Contents Appendix Section Page A. Training Setup for the Attention-IoU Regressor15 B. Differential Entropy of...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.