Benchmarking LLM-as-a-Judge for Long-Form Output Evaluation
Pith reviewed 2026-06-28 15:25 UTC · model grok-4.3
The pith
Current LLM judges remain unstable when evaluating long-form outputs across scenarios.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
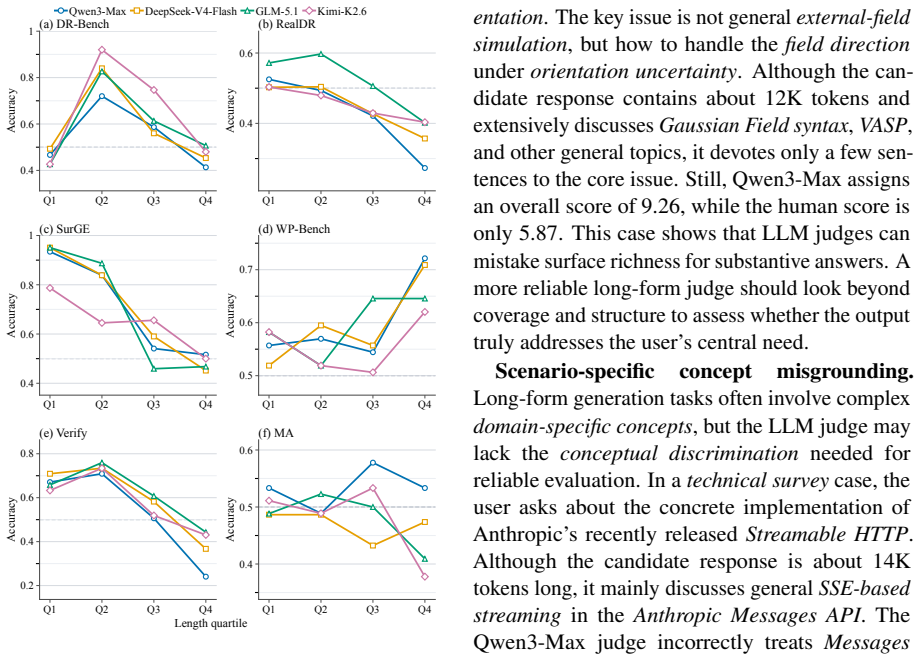
LongJudgeBench evaluates multiple LLM judges on long-form outputs and shows a substantial reliability gap where current judges remain unstable across scenarios, and rubrics or references are helpful but not always sufficient.
What carries the argument
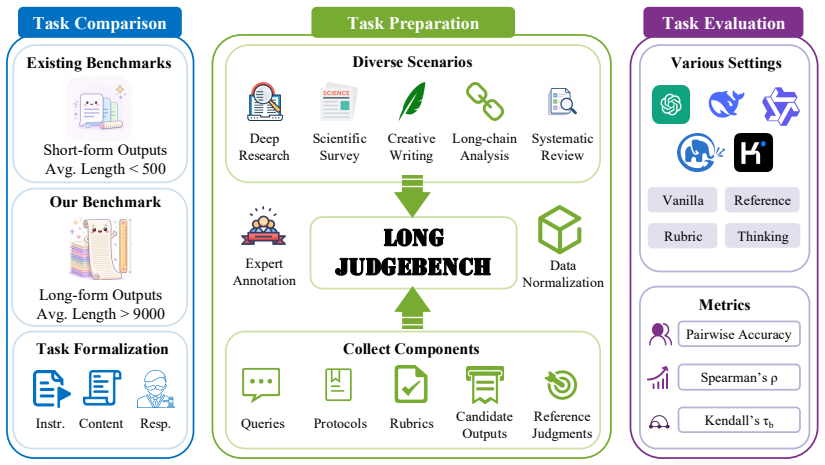
LongJudgeBench, a benchmark covering diverse real-world scenarios and judging protocols to meta-evaluate LLM judges on long-form outputs.
If this is right
- Future LLM-as-a-judge methods need to handle document-level assessments of organization, coverage, and consistency.
- Rubrics and references should be incorporated into judging protocols while recognizing their incomplete effect on stability.
- Evaluation setups for long-form outputs must account for scenario-specific quality criteria beyond length.
- Benchmarks like LongJudgeBench can guide development of more context-aware judging approaches.
Where Pith is reading between the lines
- Systems that rely on LLM judges for tasks such as report summarization or content review may need fallback mechanisms when judge outputs vary.
- Combining results from multiple distinct judging protocols could narrow the observed instability without new model training.
- Testing the benchmark on outputs from different generation models or domains would clarify how far the instability extends.
Load-bearing premise
The diverse real-world scenarios and judging protocols chosen for LongJudgeBench adequately represent the full range of challenges in long-form output evaluation.
What would settle it
Finding that one or more LLM judges produce stable high agreement with humans across all scenarios in LongJudgeBench plus additional unseen long-form tasks would disprove the reliability gap.
Figures
read the original abstract
As large language models (LLMs) are increasingly used for long-form generation, reliably evaluating long-form outputs has become a critical challenge. LLM-as-a-judge offers a scalable alternative to human evaluation, yet its reliability in long-form output evaluation remains underexamined: existing meta-evaluation benchmarks focus mainly on short-form outputs. Compared with short-form evaluation, long-form evaluation is not merely a matter of output length; it often requires judges to make more complex document-level assessments of overall organization, task-relevant coverage and depth, cross-section consistency, and scenario-specific quality criteria. In this work, we introduce LongJudgeBench, a comprehensive benchmark for evaluating LLM judges on long-form outputs across diverse real-world scenarios and judging protocols. We systematically evaluate a broad range of LLM judges, covering multiple base models and judging settings. Our results reveal a substantial reliability gap: current LLM judges remain unstable across scenarios, and rubrics or references are helpful but not always sufficient. We hope LongJudgeBench will support future research on more robust, context-aware, and human-aligned LLM-as-a-judge methods. Our code is available at https://github.com/cjj826/LongJudgeBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LongJudgeBench, a benchmark for meta-evaluating LLM-as-a-judge methods on long-form generation outputs. It covers multiple real-world scenarios and judging protocols (with/without rubrics or references), systematically tests a range of base models and settings, and reports that LLM judges exhibit substantial instability across scenarios while rubrics/references help but are not always sufficient. The work releases code and positions the benchmark as a resource for developing more robust long-form judges.
Significance. If the benchmark construction and evaluation protocols are shown to be representative, the results would establish a concrete reliability gap in current LLM judges for document-level criteria (organization, coverage, consistency, scenario-specific quality), motivating targeted improvements in context-aware judging methods. The public code release is a clear strength for reproducibility in an empirical benchmarking study.
major comments (2)
- [§3] §3 (LongJudgeBench construction): The claim of a 'substantial reliability gap' across scenarios rests on the assumption that the chosen scenarios and protocols adequately sample the document-level phenomena listed in the abstract (overall organization, task-relevant coverage and depth, cross-section consistency). No quantitative coverage analysis, inter-scenario difficulty calibration, or comparison against real-world long-form distributions is referenced, leaving open the possibility that observed instability is an artifact of the selected distribution rather than evidence of a general gap.
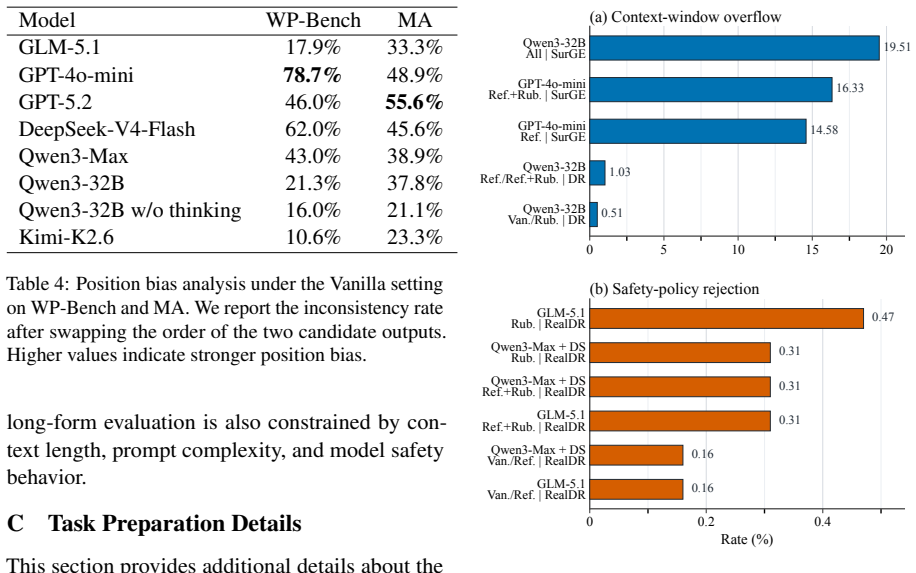
- [§4] §4 (Evaluation and results): The abstract and high-level findings mention instability and the partial helpfulness of rubrics/references, but the manuscript supplies no details on the precise metrics (e.g., agreement coefficients, variance decomposition), statistical tests for cross-scenario differences, or controls for prompt sensitivity and output-length effects. These omissions prevent verification that the reported gap is robust rather than sensitive to unstated implementation choices.
minor comments (2)
- [Abstract / Introduction] The abstract states that 'existing meta-evaluation benchmarks focus mainly on short-form outputs' but does not cite the specific short-form benchmarks being contrasted; adding 2-3 representative citations in the introduction would clarify the novelty positioning.
- [Figures/Tables] Figure and table captions should explicitly state the number of scenarios, models, and runs per condition to allow readers to assess statistical power without cross-referencing the text.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address the two major comments below, indicating where revisions will be made to improve clarity and rigor.
read point-by-point responses
-
Referee: [§3] §3 (LongJudgeBench construction): The claim of a 'substantial reliability gap' across scenarios rests on the assumption that the chosen scenarios and protocols adequately sample the document-level phenomena listed in the abstract (overall organization, task-relevant coverage and depth, cross-section consistency). No quantitative coverage analysis, inter-scenario difficulty calibration, or comparison against real-world long-form distributions is referenced, leaving open the possibility that observed instability is an artifact of the selected distribution rather than evidence of a general gap.
Authors: We agree that the generalizability of the reliability gap would be strengthened by explicit discussion of scenario selection and coverage. In the revised version we will add a dedicated paragraph in §3 that (a) maps each scenario to the document-level criteria named in the abstract, (b) reports basic inter-scenario statistics (token length, number of sections, domain), and (c) explains the rationale for choosing these particular real-world tasks. A full quantitative comparison against an exhaustive corpus of long-form distributions is not feasible within the scope of the present study, as no such standardized reference corpus exists; we will therefore frame the added material as a qualitative and descriptive calibration rather than a statistical proof of representativeness. revision: yes
-
Referee: [§4] §4 (Evaluation and results): The abstract and high-level findings mention instability and the partial helpfulness of rubrics/references, but the manuscript supplies no details on the precise metrics (e.g., agreement coefficients, variance decomposition), statistical tests for cross-scenario differences, or controls for prompt sensitivity and output-length effects. These omissions prevent verification that the reported gap is robust rather than sensitive to unstated implementation choices.
Authors: The referee correctly identifies that the current §4 lacks sufficient methodological detail. We will expand this section to specify: the exact agreement coefficients computed (Cohen’s κ, Krippendorff’s α, and pairwise accuracy), the variance-decomposition approach used to quantify scenario-level instability, the statistical tests (e.g., Friedman test with post-hoc Nemenyi) applied to cross-scenario differences, and the controls implemented for prompt phrasing and output-length normalization. These additions will be accompanied by the corresponding formulas and implementation notes so that readers can reproduce the robustness checks. revision: yes
Circularity Check
No circularity: empirical benchmarking with direct evaluations
full rationale
This is a purely empirical benchmarking paper that constructs LongJudgeBench, runs LLM judges under various protocols, and reports observed instability from those runs. No equations, fitted parameters, predictions, or derivations are present in the provided text. The central claim follows from direct measurement on the benchmark rather than any self-definitional loop, fitted-input-as-prediction, or self-citation chain that reduces the result to its own inputs by construction. Scenario representativeness is an external-validity assumption, not a circularity in any derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Long-form evaluation requires complex document-level assessments of organization, coverage, consistency, and scenario-specific criteria beyond short-form metrics.
Reference graph
Works this paper leans on
-
[1]
ACM transactions on intelligent systems and technology , volume=
A survey on evaluation of large language models , author=. ACM transactions on intelligent systems and technology , volume=. 2024 , publisher=
2024
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Advances in neural information processing systems , volume=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. Advances in neural information processing systems , volume=
-
[5]
LLMs-as-Judges: A Comprehensive Survey on LLM-based Evaluation Methods
Llms-as-judges: a comprehensive survey on llm-based evaluation methods , author=. arXiv preprint arXiv:2412.05579 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
Rewardbench: Evaluating reward models for language modeling , author=. Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
2025
-
[7]
RewardBench 2: Advancing Reward Model Evaluation
Rewardbench 2: Advancing reward model evaluation , author=. arXiv preprint arXiv:2506.01937 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
International Conference on Learning Representations , volume=
Judgebench: A benchmark for evaluating llm-based judges , author=. International Conference on Learning Representations , volume=
-
[9]
International Conference on Learning Representations , volume=
Evaluating large language models at evaluating instruction following , author=. International Conference on Learning Representations , volume=
-
[10]
Advances in Neural Information Processing Systems , volume=
Improving context-aware preference modeling for language models , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
Proceedings of the 40th annual meeting of the Association for Computational Linguistics , pages=
Bleu: a method for automatic evaluation of machine translation , author=. Proceedings of the 40th annual meeting of the Association for Computational Linguistics , pages=
-
[12]
Text summarization branches out , pages=
Rouge: A package for automatic evaluation of summaries , author=. Text summarization branches out , pages=
-
[13]
BERTScore: Evaluating Text Generation with BERT
Bertscore: Evaluating text generation with bert , author=. arXiv preprint arXiv:1904.09675 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[14]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
ChatEval: Towards Better LLM-Based Evaluators through Multi-Agent Debate , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[15]
Proceedings of the 33rd ACM International Conference on Information and Knowledge Management (CIKM) , year=
PRE: A Peer Review Based Large Language Model Evaluator , author=. Proceedings of the 33rd ACM International Conference on Information and Knowledge Management (CIKM) , year=
-
[16]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Auto-PRE: An Automatic and Cost-Efficient Peer-Review Framework for Language Generation Evaluation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[17]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Joint evaluation of answer and reasoning consistency for hallucination detection in large reasoning models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[18]
Proceedings of the 18th conference of the european chapter of the association for computational linguistics: system demonstrations , pages=
Ragas: Automated evaluation of retrieval augmented generation , author=. Proceedings of the 18th conference of the european chapter of the association for computational linguistics: system demonstrations , pages=
-
[19]
Advances in Neural Information Processing Systems , volume=
Long-form factuality in large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
Skill Retrieval Augmentation for Agentic AI
Skill retrieval augmentation for agentic ai , author=. arXiv preprint arXiv:2604.24594 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
Parametric retrieval augmented generation , author=. Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[22]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Augmenting Multi-Agent Communication with State Delta Trajectory , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[23]
arXiv preprint arXiv:2512.02772 , year=
Towards Unification of Hallucination Detection and Fact Verification for Large Language Models , author=. arXiv preprint arXiv:2512.02772 , year=
-
[24]
Proceedings of the 2024 Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region , pages=
Mitigating entity-level hallucination in large language models , author=. Proceedings of the 2024 Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region , pages=
2024
-
[25]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Unsupervised real-time hallucination detection based on the internal states of large language models , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[26]
International Conference on Learning Representations , volume=
Prometheus: Inducing fine-grained evaluation capability in language models , author=. International Conference on Learning Representations , volume=
-
[27]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
G-eval: NLG evaluation using gpt-4 with better human alignment , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
2023
-
[28]
Transactions of the Association for Computational Linguistics , volume=
Towards question-answering as an automatic metric for evaluating the content quality of a summary , author=. Transactions of the Association for Computational Linguistics , volume=. 2021 , publisher=
2021
-
[29]
DeepResearch Bench: A Comprehensive Benchmark for Deep Research Agents
Deepresearch bench: A comprehensive benchmark for deep research agents , author=. arXiv preprint arXiv:2506.11763 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
ELI5: Long form question answering , author=. Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
-
[31]
SurGE: A Benchmark and Evaluation Framework for Scientific Survey Generation
Surge: A benchmark and evaluation framework for scientific survey generation , author=. arXiv preprint arXiv:2508.15658 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
arXiv preprint arXiv:2510.14616 , year=
Beyond Correctness: Evaluating Subjective Writing Preferences Across Cultures , author=. arXiv preprint arXiv:2510.14616 , year=
-
[33]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Verifybench: A systematic benchmark for evaluating reasoning verifiers across domains , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[34]
Openai gpt-5 system card , author=. arXiv preprint arXiv:2601.03267 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
GLM-5: from Vibe Coding to Agentic Engineering
Glm-5: from vibe coding to agentic engineering , author=. arXiv preprint arXiv:2602.15763 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Kimi K2: Open Agentic Intelligence
Kimi k2: Open agentic intelligence , author=. arXiv preprint arXiv:2507.20534 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Long-form RewardBench: Evaluating Reward Models for Long-form Generation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[38]
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence , author=
-
[39]
Benchmarking
Xie, Anzhe and Su, Weihang and Zhou, Yujia and Liu, Yiqun and Ai, Qingyao , year =. Benchmarking
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.