Trans2Occ: Voxel Occupancy Estimation and Grasp for Transparent Objects from Simulation to Reality
Pith reviewed 2026-06-28 14:34 UTC · model grok-4.3
The pith
Voxel occupancy predicted from one RGB image transfers directly from simulation to real robotic grasping of transparent objects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
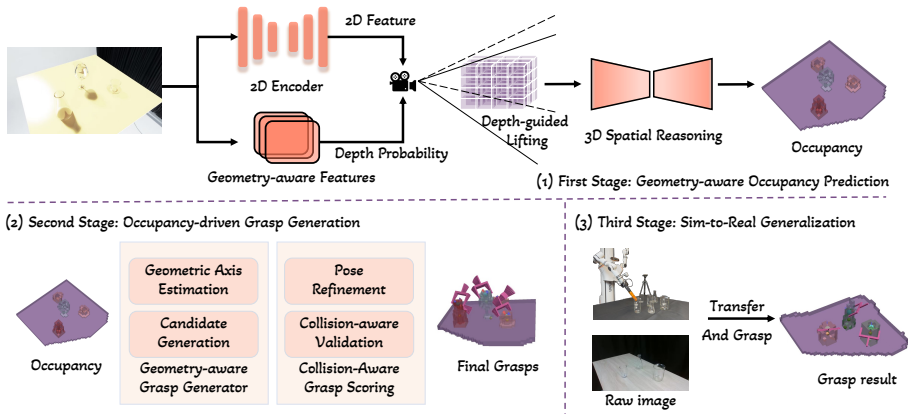
A neural network trained solely on simulated RGB-to-voxel-occupancy pairs produces geometry estimates for transparent objects that remain usable on real hardware, supporting reliable rule-based grasping without any fine-tuning or domain adaptation.
What carries the argument
The voxel occupancy grid output by a network that takes a single RGB image as input and labels each 3D cell as occupied or free.
If this is right
- Single-view perception suffices for 3D geometry of transparent objects.
- Simulation data alone can train models that deploy on physical robots.
- Simple occupancy-based rules can produce reliable grasps without full 3D reconstruction.
- The same pipeline scales to many object instances and lighting variations inside the simulator.
Where Pith is reading between the lines
- The method may apply to other depth-unreliable surfaces such as mirrors or water if similar simulation fidelity can be achieved.
- Multi-view or depth-completion pipelines could be replaced in settings where only one camera view is available.
- Performance would degrade if real objects exhibit optical properties outside the simulated material and lighting distributions.
Load-bearing premise
The simulation must produce RGB images whose refraction and reflection patterns match real transparent objects closely enough for direct transfer.
What would settle it
Compare predicted occupancy volumes against laser-scanned ground truth for real transparent objects whose materials or lighting conditions were absent from the simulation training set.
Figures



read the original abstract
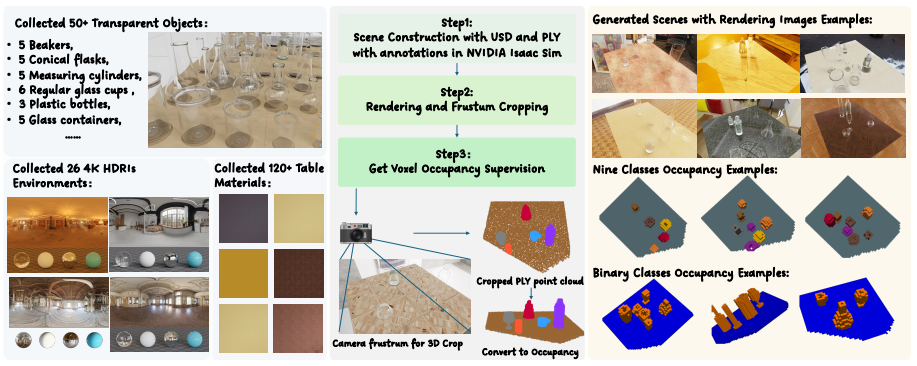
Transparent objects remain challenging for robotic perception due to unreliable depth sensing caused by refraction and reflection. While prior approaches rely on multi-view reconstruction or depth completion, they are often difficult to scale or deploy in real-world robotic systems. In this paper, we present a practical framework for transparent object perception and manipulation based on single-view RGB input. Our approach predicts voxel-space occupancy directly from a single image, providing a geometry-aware representation that supports downstream robotic grasping. To enable large-scale training, we construct a simulation pipeline that generates paired RGB images and voxel occupancy annotations under diverse materials and lighting conditions. We demonstrate that the predicted occupancy representation is robust to domain shifts and transfers effectively from simulation to real-world robotic setups without fine-tuning. A simple rule-based grasping strategy built on top of the occupancy further achieves reliable grasp performance on transparent objects. Extensive experiments in both simulation and real-world environments show that our framework provides accurate 3D understanding and enables practical manipulation of transparent objects. These results suggest that single-view occupancy prediction offers a scalable and effective solution for transparent object perception in robotics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Trans2Occ, a framework that predicts voxel-space occupancy directly from single-view RGB images of transparent objects. A simulation pipeline generates large-scale paired RGB and voxel occupancy data under varied materials and lighting; a model is trained on this data and shown to transfer zero-shot to real robotic setups. A rule-based grasping strategy is then applied to the predicted occupancy. The authors report experiments demonstrating accurate 3D understanding and reliable manipulation in both simulation and real-world environments.
Significance. If the zero-shot sim-to-real transfer and grasping results hold, the work is significant for robotic perception. Transparent objects are a persistent challenge due to unreliable depth from refraction and reflection; a single-view occupancy representation that supports direct manipulation without multi-view reconstruction or real-data fine-tuning would be a practical advance. The simulation-based training approach is a clear strength, as it enables scalable data generation while avoiding the collection of real annotated transparent-object datasets.
minor comments (3)
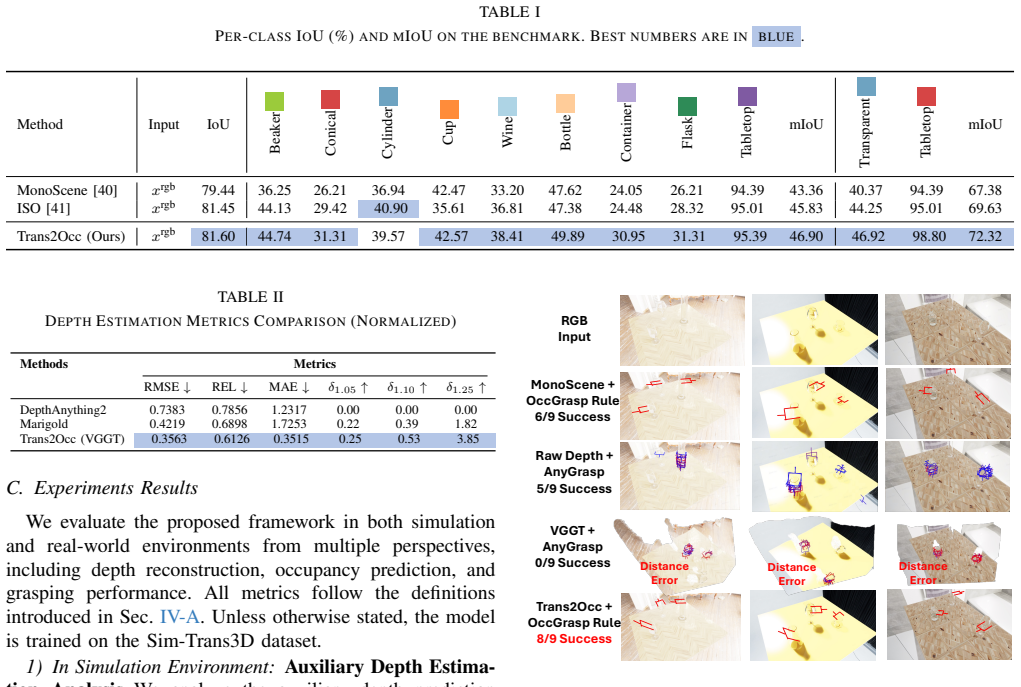
- [Abstract] Abstract: the statement that 'extensive experiments ... show that our framework provides accurate 3D understanding' would be strengthened by including one or two key quantitative metrics (e.g., occupancy IoU or grasp success rate) rather than remaining purely qualitative.
- [Grasping strategy section] The description of the rule-based grasping strategy could clarify the exact geometric rules applied to the occupancy grid (e.g., how surface normals or grasp candidates are extracted) to allow reproducibility.
- [Figures] Figure captions for real-world results should explicitly state the number of trials, object materials, and lighting conditions shown to help readers assess the domain-shift robustness.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision for our work on Trans2Occ. The evaluation correctly highlights the value of the simulation pipeline for scalable data generation and the zero-shot sim-to-real transfer for single-view voxel occupancy prediction on transparent objects.
Circularity Check
No significant circularity
full rationale
The paper describes an empirical pipeline: a neural network is trained on paired simulated RGB images and voxel occupancy labels generated by a rendering engine, then evaluated zero-shot on real RGB images for occupancy prediction and downstream grasping. No derivation chain, equations, or fitted parameters reduce a claimed prediction to its own inputs by construction. No self-citation is invoked as a uniqueness theorem or load-bearing premise. The central claim rests on experimental transfer results rather than definitional equivalence or renamed known patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A simulation pipeline can generate paired RGB images and voxel occupancy labels that capture refraction and reflection effects for diverse transparent materials and lighting.
Reference graph
Works this paper leans on
-
[1]
Labutopia: High-fidelity simulation and hierarchical benchmark for scientific embodied agents,
R. Li, Z. Hu, W. Qu, J. Zhang, Z. Yin, S. Zhang, X. Huang, H. Wang, T. Wang, J. Panget al., “Labutopia: High-fidelity simulation and hierarchical benchmark for scientific embodied agents,”arXiv preprint arXiv:2505.22634, 2025
-
[2]
Autonomous chemical experiments: Challenges and perspectives on establishing a self-driving lab,
M. Seifrid, R. Pollice, A. Aguilar-Granda, Z. Morgan Chan, K. Hotta, C. T. Ser, J. Vestfrid, T. C. Wu, and A. Aspuru-Guzik, “Autonomous chemical experiments: Challenges and perspectives on establishing a self-driving lab,”Accounts of Chemical Research, vol. 55, no. 17, pp. 2454–2466, 2022
2022
-
[3]
AutoBio: A Simulation and Benchmark for Robotic Automation in Digital Biology Laboratory [J]
Z. Lan, Y . Jiang, R. Wang, X. Xie, R. Zhang, Y . Zhu, P. Li, T. Yang, T. Chen, H. Gaoet al., “Autobio: A simulation and benchmark for robotic automation in digital biology laboratory,”arXiv preprint arXiv:2505.14030, 2025
-
[4]
Chemistry3D: Robotic Interaction Benchmark for Chemistry Experiments [J]
S. Li, Y . Huang, C. Guo, T. Wu, J. Zhang, L. Zhang, and W. Ding, “Chemistry3d: Robotic interaction benchmark for chemistry experi- ments,”arXiv preprint arXiv:2406.08160, 2024
-
[5]
Seeing glass: joint point cloud and depth completion for transparent objects,
H. Xu, Y . R. Wang, S. Eppel, A. Aspuru-Guzik, F. Shkurti, and A. Garg, “Seeing glass: joint point cloud and depth completion for transparent objects,”arXiv preprint arXiv:2110.00087, 2021
-
[6]
Clear grasp: 3d shape estimation of transparent objects for manipulation,
S. Sajjan, M. Moore, M. Pan, G. Nagaraja, J. Lee, A. Zeng, and S. Song, “Clear grasp: 3d shape estimation of transparent objects for manipulation,” in2020 IEEE international conference on robotics and automation (ICRA). IEEE, 2020, pp. 3634–3642
2020
-
[7]
Clearpose: Large-scale transparent object dataset and benchmark,
X. Chen, H. Zhang, Z. Yu, A. Opipari, and O. Chadwicke Jenkins, “Clearpose: Large-scale transparent object dataset and benchmark,” in European conference on computer vision. Springer, 2022, pp. 381– 396
2022
-
[8]
Dex-nerf: Using a neural radiance field to grasp transparent objects,
J. Ichnowski, Y . Avigal, J. Kerr, and K. Goldberg, “Dex-nerf: Using a neural radiance field to grasp transparent objects,”arXiv preprint arXiv:2110.14217, 2021
-
[9]
Residual-nerf: Learning residual nerfs for transparent object manipulation,
B. P. Duisterhof, Y . Mao, S. H. Teng, and J. Ichnowski, “Residual-nerf: Learning residual nerfs for transparent object manipulation,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 13 918–13 924
2024
-
[10]
Evo-nerf: Evolving nerf for sequen- tial robot grasping of transparent objects,
J. Kerr, L. Fu, H. Huang, Y . Avigal, M. Tancik, J. Ichnowski, A. Kanazawa, and K. Goldberg, “Evo-nerf: Evolving nerf for sequen- tial robot grasping of transparent objects,” in6th annual conference on robot learning, 2022
2022
-
[11]
Lb-nerf: light bending neural radiance fields for transparent medium,
T. Fujitomi, K. Sakurada, R. Hamaguchi, H. Shishido, M. Onishi, and Y . Kameda, “Lb-nerf: light bending neural radiance fields for transparent medium,” in2022 IEEE International Conference on Image Processing (ICIP). IEEE, 2022, pp. 2142–2146
2022
-
[12]
X. Chen, J. Liu, H. Zhao, G. Zhou, and Y .-Q. Zhang, “Nerrf: 3d recon- struction and view synthesis for transparent and specular objects with neural refractive-reflective fields,”arXiv preprint arXiv:2309.13039, 2023
-
[13]
Tsgs: Improving gaussian splatting for transparent surface reconstruction via normal and de-lighting priors,
M. Li, P. Pang, H. Fan, H. Huang, and Y . Yang, “Tsgs: Improving gaussian splatting for transparent surface reconstruction via normal and de-lighting priors,” inProceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 7220–7229
2025
-
[14]
Transparentgs: Fast inverse rendering of trans- parent objects with gaussians,
L. Huang, D. Ye, J. Dan, C. Tao, H. Liu, K. Zhou, B. Ren, Y . Li, Y . Guo, and J. Guo, “Transparentgs: Fast inverse rendering of trans- parent objects with gaussians,”ACM Transactions on Graphics (TOG), vol. 44, no. 4, pp. 1–17, 2025
2025
-
[15]
Transplat: Surface embedding-guided 3d gaussian splatting for transparent object ma- nipulation,
J. Kim, J. Noh, D.-G. Lee, and A. Kim, “Transplat: Surface embedding-guided 3d gaussian splatting for transparent object ma- nipulation,”arXiv preprint arXiv:2502.07840, 2025
-
[16]
Clear-splatting: Learning residual gaussian splats for transparent object manipulation,
A. Agrawal, R. Roy, B. P. Duisterhof, K. B. Hekkadka, H. Chen, and J. Ichnowski, “Clear-splatting: Learning residual gaussian splats for transparent object manipulation,” inRoboNerF: 1st Workshop On Neural Fields In Robotics at ICRA 2024, 2024
2024
-
[18]
Transcg: A large-scale real- world dataset for transparent object depth completion and a grasping baseline,
H. Fang, H.-S. Fang, S. Xu, and C. Lu, “Transcg: A large-scale real- world dataset for transparent object depth completion and a grasping baseline,”IEEE Robotics and Automation Letters, vol. 7, no. 3, pp. 7383–7390, 2022
2022
-
[19]
J. Liu, H. Ma, Y . Guo, Y . Zhao, C. Zhang, W. Sui, and W. Zou, “Monocular depth estimation and segmentation for transparent ob- ject with iterative semantic and geometric fusion,”arXiv preprint arXiv:2502.14616, 2025
-
[20]
Learning depth estimation for transparent and mirror surfaces,
A. Costanzino, P. Z. Ramirez, M. Poggi, F. Tosi, S. Mattoccia, and L. Di Stefano, “Learning depth estimation for transparent and mirror surfaces,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 9244–9255
2023
-
[21]
Tode-trans: Transparent object depth estimation with transformer,
K. Chen, S. Wang, B. Xia, D. Li, Z. Kan, and B. Li, “Tode-trans: Transparent object depth estimation with transformer,”arXiv preprint arXiv:2209.08455, 2022
-
[22]
Dfnet-trans: An end- to-end multibranching network for depth estimation for transparent objects,
X. Meng, J. Wen, Y . Li, C. Wang, and J. Zhang, “Dfnet-trans: An end- to-end multibranching network for depth estimation for transparent objects,”Computer Vision and Image Understanding, vol. 240, p. 103914, 2024
2024
-
[23]
Robotic perception of transparent objects: A review,
J. Jiang, G. Cao, J. Deng, T.-T. Do, and S. Luo, “Robotic perception of transparent objects: A review,”IEEE Transactions on Artificial Intelligence, vol. 5, no. 6, pp. 2547–2567, 2023
2023
-
[24]
Seg- menting transparent objects in the wild,
E. Xie, W. Wang, W. Wang, M. Ding, C. Shen, and P. Luo, “Seg- menting transparent objects in the wild,” inEuropean conference on computer vision. Springer, 2020, pp. 696–711
2020
-
[25]
Polarimetric inverse rendering for transparent shapes reconstruction,
M. Shao, C. Xia, D. Duan, and X. Wang, “Polarimetric inverse rendering for transparent shapes reconstruction,”IEEE Transactions on Multimedia, vol. 26, pp. 7801–7811, 2024
2024
-
[26]
Deep polarization cues for transparent object segmenta- tion,
A. Kalra, V . Taamazyan, S. K. Rao, K. Venkataraman, R. Raskar, and A. Kadambi, “Deep polarization cues for transparent object segmenta- tion,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 8602–8611
2020
-
[27]
Glass segmentation using intensity and spectral polarization cues,
H. Mei, B. Dong, W. Dong, J. Yang, S.-H. Baek, F. Heide, P. Peers, X. Wei, and X. Yang, “Glass segmentation using intensity and spectral polarization cues,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 12 622–12 631
2022
-
[28]
Transdiff: Diffusion-based method for manipulating transparent objects using a single rgb-d image,
H. Wang, K. Zhou, B. Gu, Z. Feng, W. Wang, P. Sun, Y . Xiao, J. Zhang, and H. Dong, “Transdiff: Diffusion-based method for manipulating transparent objects using a single rgb-d image,”arXiv preprint arXiv:2503.12779, 2025
-
[29]
Close the sim2real gap via physically-based structured light synthetic data simulation,
K. Bai, L. Zhang, Z. Chen, F. Wan, and J. Zhang, “Close the sim2real gap via physically-based structured light synthetic data simulation,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 17 035–17 041
2024
-
[30]
Tgf-net: Sim2real transparent object 6d pose estimation based on geometric fusion,
H. Yu, S. Li, H. Liu, C. Xia, W. Ding, and B. Liang, “Tgf-net: Sim2real transparent object 6d pose estimation based on geometric fusion,” IEEE Robotics and Automation Letters, vol. 8, no. 6, pp. 3868–3875, 2023
2023
-
[31]
Mvtrans: Multi-view perception of transparent objects,
Y . R. Wang, Y . Zhao, H. Xu, S. Eppel, A. Aspuru-Guzik, F. Shkurti, and A. Garg, “Mvtrans: Multi-view perception of transparent objects,” arXiv preprint arXiv:2302.11683, 2023
-
[32]
Through the looking glass: Neural 3d reconstruction of transparent shapes,
Z. Li, Y .-Y . Yeh, and M. Chandraker, “Through the looking glass: Neural 3d reconstruction of transparent shapes,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 1262–1271
2020
-
[33]
Cleardepth: enhanced stereo perception of transparent objects for robotic manipulation,
K. Bai, H. Zeng, L. Zhang, Y . Liu, H. Xu, Z. Chen, and J. Zhang, “Cleardepth: enhanced stereo perception of transparent objects for robotic manipulation,”arXiv preprint arXiv:2409.08926, 2024
-
[34]
Fdct: Fast depth completion for transparent objects,
T. Li, Z. Chen, H. Liu, and C. Wang, “Fdct: Fast depth completion for transparent objects,”IEEE Robotics and Automation Letters, vol. 8, no. 9, pp. 5823–5830, 2023
2023
-
[35]
Rgb-d local implicit function for depth completion of transparent objects,
L. Zhu, A. Mousavian, Y . Xiang, H. Mazhar, J. van Eenbergen, S. Debnath, and D. Fox, “Rgb-d local implicit function for depth completion of transparent objects,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 4649–4658
2021
-
[36]
Glass segmentation with rgb-thermal image pairs,
D. Huo, J. Wang, Y . Qian, and Y .-H. Yang, “Glass segmentation with rgb-thermal image pairs,”IEEE Transactions on Image Processing, vol. 32, pp. 1911–1926, 2023
1911
-
[37]
Domain randomization-enhanced depth simulation and restoration for perceiving and grasping specular and transparent objects,
Q. Dai, J. Zhang, Q. Li, T. Wu, H. Dong, Z. Liu, P. Tan, and H. Wang, “Domain randomization-enhanced depth simulation and restoration for perceiving and grasping specular and transparent objects,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 374–391
2022
-
[38]
Asgrasp: Generalizable transparent object reconstruction and grasping from rgb- d active stereo camera,
J. Shi, A. Yong, Y . Jin, D. Li, H. Niu, Z. Jin, and H. Wang, “Asgrasp: Generalizable transparent object reconstruction and grasping from rgb- d active stereo camera,”CoRR, 2024
2024
-
[39]
Tom-net: Learning transparent object matting from a single image,
G. Chen, K. Han, and K.-Y . K. Wong, “Tom-net: Learning transparent object matting from a single image,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 9233–9241
2018
-
[40]
Monoscene: Monocular 3d semantic scene completion,
A.-Q. Cao and R. De Charette, “Monoscene: Monocular 3d semantic scene completion,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 3991–4001
2022
-
[41]
Monocular occupancy prediction for scalable indoor scenes,
H. Yu, Y . Wang, Y . Chen, and Z. Zhang, “Monocular occupancy prediction for scalable indoor scenes,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 38–54
2024
-
[42]
Depth anything v2,
L. Yang, B. Kang, Z. Huang, Z. Zhao, X. Xu, J. Feng, and H. Zhao, “Depth anything v2,”Advances in Neural Information Processing Systems, vol. 37, pp. 21 875–21 911, 2024
2024
-
[43]
Repurposing diffusion-based image generators for monocular depth estimation,
B. Ke, A. Obukhov, S. Huang, N. Metzger, R. C. Daudt, and K. Schindler, “Repurposing diffusion-based image generators for monocular depth estimation,” inProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[44]
Anygrasp: Robust and efficient grasp perception in spatial and temporal domains,
H.-S. Fang, C. Wang, H. Fang, M. Gou, J. Liu, H. Yan, W. Liu, Y . Xie, and C. Lu, “Anygrasp: Robust and efficient grasp perception in spatial and temporal domains,”IEEE Transactions on Robotics, vol. 39, no. 5, pp. 3929–3945, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.