RescueBench: Can Embodied Agents Save Lives in the Wild ?
Pith reviewed 2026-06-28 15:07 UTC · model grok-4.3
The pith
Embodied agents fail to complete full search-and-rescue workflows because exploration and spatial memory remain unsolved bottlenecks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
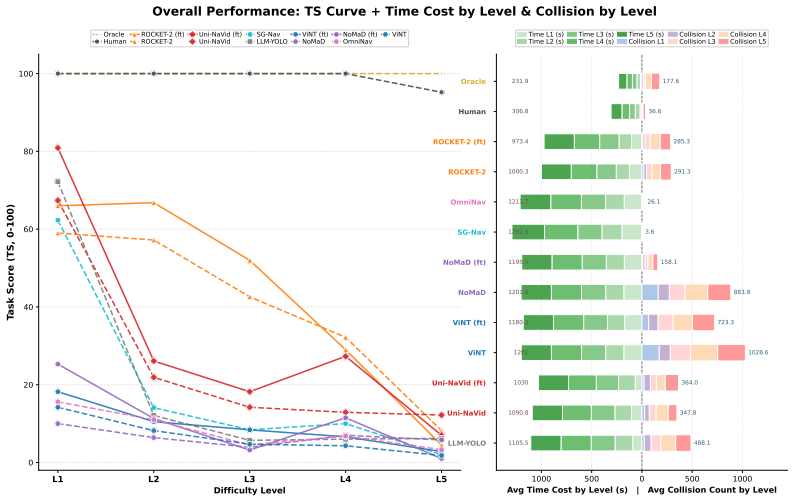
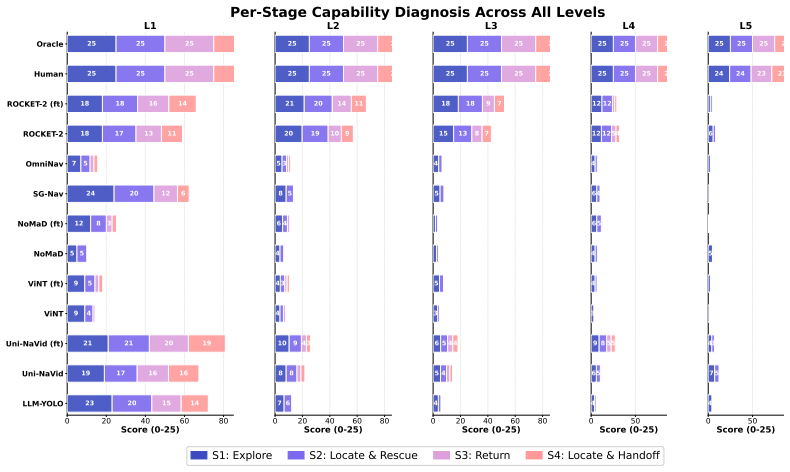
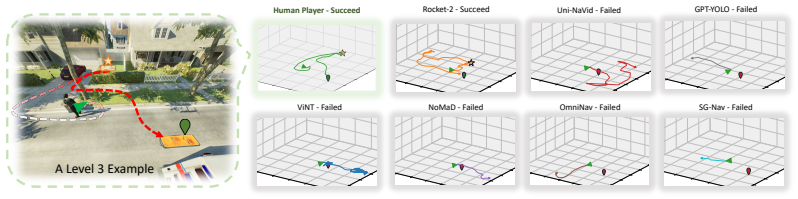
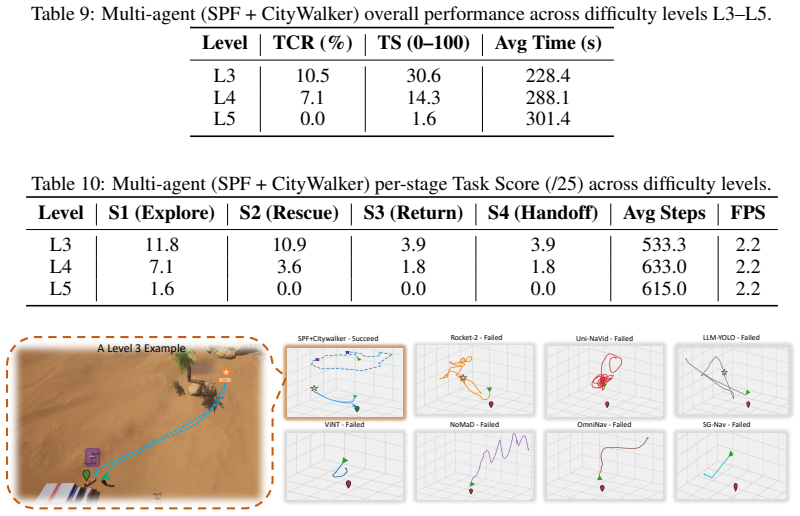
RescueBench instantiates search-and-rescue as a four-stage pipeline with progressive difficulty levels and automatic episode generation; stage-level evaluation of seven baselines reveals that none complete the full task at greatest difficulty, with autonomous exploration as the dominant failure mode and spatial memory as an independent second bottleneck.
What carries the argument
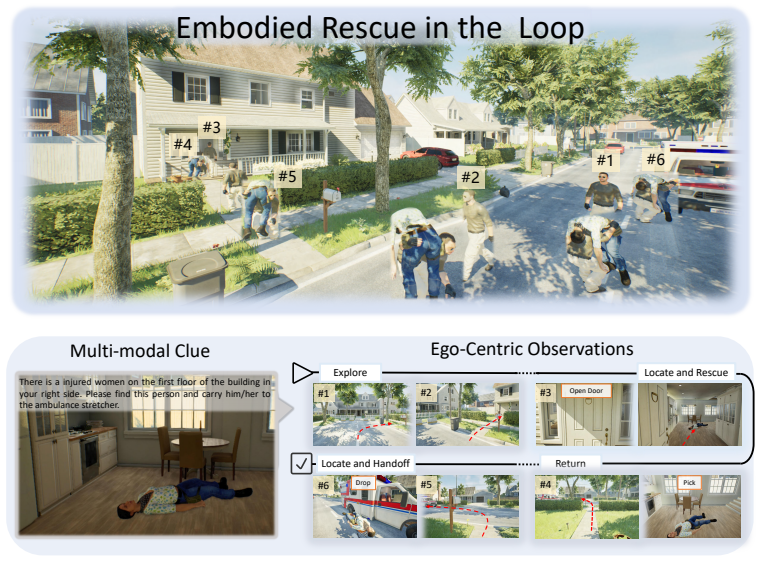
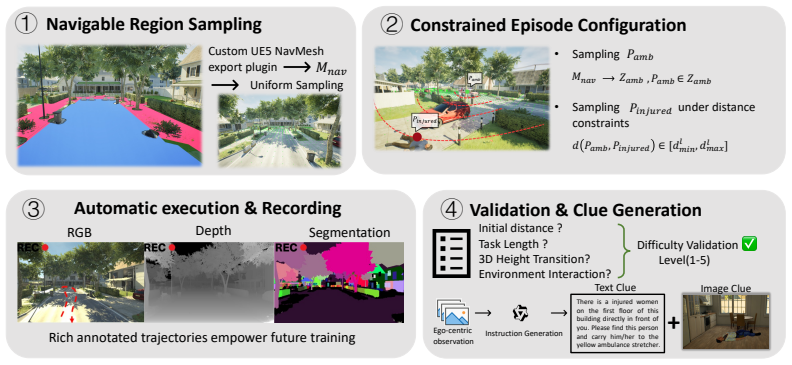
Four-stage pipeline (multimodal exploration, target rescue, memory-guided return, final handoff) evaluated across five difficulty levels with automatic episode generation and stage-level metrics.
If this is right
- Exploration failures dominate when environments grow complex and clues become ambiguous.
- Spatial memory limits act independently from exploration problems.
- Current topological visual-language navigation and map-based methods leave both issues unresolved.
- Stage-level metrics are required to separate compounded failures from isolated ones.
- Automatic episode generation supports scalable evaluation and training data creation.
Where Pith is reading between the lines
- Improving joint exploration and memory modules might raise completion rates on composed tasks.
- The same staged diagnostic approach could apply to other long-horizon embodied problems such as disaster response or indoor assistance.
- Testing the benchmark on physical robots would reveal whether simulation results transfer to real hardware.
Load-bearing premise
The four-stage pipeline and automatic episode generation accurately model how exploration and memory failures compound in real multimodal SAR workflows.
What would settle it
An agent that completes the full task at the greatest difficulty level would show the claim does not hold.
Figures


read the original abstract
Search-and-rescue (SAR) requires embodied agents to explore unfamiliar environments under multimodal uncertainty, perform multi-stage interactions, and retrieve spatial memory over long horizons. Existing benchmarks typically evaluate these capabilities in isolation, leaving unclear how failures compound when they must be composed in realistic workflows. We introduce RescueBench, a photo-realistic diagnostic benchmark that instantiates SAR as a four-stage pipeline: multimodal exploration, target rescue, memory-guided return, and final handoff. By combining sequential task composition with stage-level evaluation, RescueBench enables analysis of how exploration and memory failures propagate through embodied rescue workflows. It contains five progressive difficulty levels that vary in environmental complexity, clue ambiguity, and spatial hierarchy, along with an automatic episode generation and annotation pipeline for scalable evaluation and training. We evaluate seven baselines, an oracle reference, and human players, showing that no baselines complete the full task at the greatest difficulty. Stage-level diagnosis identifies autonomous exploration as the dominant failure mode and spatial memory as a second, independent bottleneck, suggesting that these limitations are not resolved by current topological visual-language navigation or map-based methods. Code is available in https://github.com/wukui-muc/RescueBench
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RescueBench, a photo-realistic benchmark for embodied search-and-rescue (SAR) agents framed as a four-stage pipeline (multimodal exploration, target rescue, memory-guided return, final handoff) with five difficulty levels and an automatic episode generation pipeline. It evaluates seven baselines plus oracle and human controls, reporting that no baseline completes the full task at maximum difficulty and that stage-level analysis isolates autonomous exploration as the primary failure mode with spatial memory as a secondary, independent bottleneck not resolved by existing topological VLN or map-based methods.
Significance. If the evaluation details and stage-level metrics hold, the benchmark would be a useful addition to the embodied AI literature by enabling diagnosis of how exploration and memory failures compound in a multi-stage workflow, beyond the isolated capabilities tested in prior VLN or navigation benchmarks. The automatic generation pipeline and code release support scalability and reproducibility.
major comments (2)
- [§4] §4 (Experiments) and associated tables: the stage-level metrics used to diagnose exploration as the dominant failure mode and spatial memory as an independent bottleneck are referenced but not presented with quantitative values, error bars, or per-baseline breakdowns; without these, the independence claim and the conclusion that current methods do not resolve the bottlenecks cannot be directly verified.
- [§3 and §4.1] §3 (Benchmark Design) and §4.1 (Baselines): the seven baselines are named but their concrete adaptations to the four-stage pipeline (e.g., how memory is maintained across stages or how the handoff is implemented) receive no implementation or hyperparameter details, making it impossible to assess whether the reported failures are due to the methods themselves or to the evaluation setup.
minor comments (1)
- [Abstract] The abstract packs the pipeline description, difficulty levels, and failure-mode conclusions into a single paragraph; separating the benchmark contribution from the empirical findings would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the presentation of experimental results and baseline details. We address each major comment below.
read point-by-point responses
-
Referee: [§4] §4 (Experiments) and associated tables: the stage-level metrics used to diagnose exploration as the dominant failure mode and spatial memory as an independent bottleneck are referenced but not presented with quantitative values, error bars, or per-baseline breakdowns; without these, the independence claim and the conclusion that current methods do not resolve the bottlenecks cannot be directly verified.
Authors: We agree that the stage-level metrics are referenced in the text but lack the full quantitative presentation, including per-baseline values, error bars, and breakdowns, which prevents direct verification of the independence claim. In the revised manuscript we will add expanded tables in §4 (or a new supplementary table) reporting these metrics for all stages, baselines, and difficulty levels. revision: yes
-
Referee: [§3 and §4.1] §3 (Benchmark Design) and §4.1 (Baselines): the seven baselines are named but their concrete adaptations to the four-stage pipeline (e.g., how memory is maintained across stages or how the handoff is implemented) receive no implementation or hyperparameter details, making it impossible to assess whether the reported failures are due to the methods themselves or to the evaluation setup.
Authors: We agree that the current manuscript provides insufficient implementation details on how each baseline is adapted to the four-stage pipeline, including memory handling across stages and handoff mechanics, as well as the specific hyperparameters. In the revision we will add a dedicated subsection (or appendix) in §4.1 with these concrete adaptations and hyperparameter settings for all seven baselines. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper introduces RescueBench as an empirical diagnostic benchmark for embodied SAR tasks, with claims resting on observed performance of seven baselines, oracle, and human controls across a four-stage pipeline and five difficulty levels. No mathematical derivations, fitted parameters, or predictions appear; stage-level failure mode analysis (exploration as dominant, spatial memory as secondary) is presented as a direct outcome of the evaluations rather than a reduction to inputs by construction. Automatic episode generation is framed as a scalability engineering choice, not a self-referential model. No self-citation load-bearing steps or uniqueness theorems are invoked. The derivation chain is self-contained as standard benchmark reporting.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The photo-realistic simulation and four-stage task composition reflect real-world multimodal uncertainty and long-horizon memory demands in SAR.
Reference graph
Works this paper leans on
-
[1]
Carlos Osorio Quero and Jose Martinez-Carranza. Unmanned aerial systems in search and rescue: A global perspective on current challenges and future applications.International 9 Journal of Disaster Risk Reduction, 118:105199, 2025
2025
-
[2]
Tenenbaum, and Chuang Gan
Qinhong Zhou, Sunli Chen, Yisong Wang, Haozhe Xu, Weihua Du, Hongxin Zhang, Yilun Du, Joshua B. Tenenbaum, and Chuang Gan. HAZARD challenge: Embodied decision making in dynamically changing environments. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[3]
Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments
Peter Anderson, Qi Wu, Damien Teney, Jake Bruce, Mark Johnson, Niko Sunderhauf, Ian Reid, Stephen Gould, and Anton van den Hengel. Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments. In2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3674–3683. IEEE Computer Society, 2018
2018
-
[4]
Beyond the nav- graph: Vision-and-language navigation in continuous environments
Jacob Krantz, Erik Wijmans, Arjun Majumdar, Dhruv Batra, and Stefan Lee. Beyond the nav- graph: Vision-and-language navigation in continuous environments. InEuropean Conference on Computer Vision, pages 104–120. Springer, 2020
2020
-
[5]
Learning semantic-agnostic and spatial-aware representation for generalizable visual-audio navigation.IEEE Robotics and Automation Letters, 8(6):3900–3907, 2023
Hongcheng Wang, Yuxuan Wang, Fangwei Zhong, Mingdong Wu, Jianwei Zhang, Yizhou Wang, and Hao Dong. Learning semantic-agnostic and spatial-aware representation for generalizable visual-audio navigation.IEEE Robotics and Automation Letters, 8(6):3900–3907, 2023
2023
-
[6]
Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
2023
-
[7]
Calvin: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics and Automation Letters, 7(3):7327–7334, 2022
Oier Mees, Lukas Hermann, Erick Rosete-Beas, and Wolfram Burgard. Calvin: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics and Automation Letters, 7(3):7327–7334, 2022
2022
-
[8]
Citywalker: Learning embodied urban navigation from web-scale videos
Xinhao Liu, Jintong Li, Yicheng Jiang, Niranjan Sujay, Zhicheng Yang, Juexiao Zhang, John Abanes, Jing Zhang, and Chen Feng. Citywalker: Learning embodied urban navigation from web-scale videos. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 6875–6885, 2025
2025
-
[9]
Urbannav: Learning language-guided embodied urban navigation from web-scale human trajectories
Yanghong Mei, Yirong Yang, Longteng Guo, Qunbo Wang, Ming-Ming Yu, Xingjian He, Wenjun Wu, and Jing Liu. Urbannav: Learning language-guided embodied urban navigation from web-scale human trajectories. InProceedings of the AAAI Conference on Artificial Intelligence, pages 18505–18513, 2026
2026
-
[10]
Trackvla: Embodied visual tracking in the wild.arXiv pre-print, 2025
Shaoan Wang, Jiazhao Zhang, Minghan Li, Jiahang Liu, Anqi Li, Kui Wu, Fangwei Zhong, Junzhi Yu, Zhizheng Zhang, and He Wang. Trackvla: Embodied visual tracking in the wild. arXiv preprint arXiv:2505.23189, 2025
-
[11]
Jiahang Liu, Yunpeng Qi, Jiazhao Zhang, Minghan Li, Shaoan Wang, Kui Wu, Hanjing Ye, Hong Zhang, Zhibo Chen, Fangwei Zhong, et al. Trackvla++: Unleashing reasoning and memory capabilities in vla models for embodied visual tracking.arXiv preprint arXiv:2510.07134, 2025
-
[12]
Embrace-3k: Embodied reasoning and action in complex environments, 2025
Mingxian Lin, Wei Huang, Yitang Li, Chengjie Jiang, Kui Wu, Fangwei Zhong, Shengju Qian, Xin Wang, and Xiaojuan Qi. Embrace-3k: Embodied reasoning and action in complex environments, 2025
2025
-
[13]
Embodiedbench: Comprehensive benchmarking multi-modal large language models for vision-driven embodied agents
Rui Yang, Hanyang Chen, Junyu Zhang, Mark Zhao, Cheng Qian, Kangrui Wang, Qineng Wang, Teja Venkat Koripella, Marziyeh Movahedi, Manling Li, et al. Embodiedbench: Comprehensive benchmarking multi-modal large language models for vision-driven embodied agents. In International Conference on Machine Learning, pages 70576–70631. PMLR, 2025
2025
-
[14]
Unrealzoo: Enriching photo-realistic virtual worlds for embodied ai
Fangwei Zhong, Kui Wu, Churan Wang, Hao Chen, Hai Ci, Zhoujun Li, and Yizhou Wang. Unrealzoo: Enriching photo-realistic virtual worlds for embodied ai. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 5769–5779, 2025
2025
-
[15]
Xavier Puig, Eric Undersander, Andrew Szot, Mikael Dallaire Cote, Tsung-Yen Yang, Ruslan Partsey, Ruta Desai, Alexander William Clegg, Michal Hlavac, So Yeon Min, et al. Habitat 3.0: A co-habitat for humans, avatars and robots.arXiv preprint arXiv:2310.13724, 2023. 10
-
[16]
Simworld: An open-ended realistic simulator for autonomous agents in physical and social worlds, 2025
Jiawei Ren, Yan Zhuang, Xiaokang Ye, Lingjun Mao, Xuhong He, Jianzhi Shen, Mrinaal Dogra, Yiming Liang, Ruixuan Zhang, Tianai Yue, et al. Simworld: An open-ended realistic simulator for autonomous agents in physical and social worlds, 2025
2025
-
[17]
Vlm can be a good assistant: Enhancing embodied visual tracking with self-improving vision-language models
Kui Wu, Shuhang Xu, Hao Chen, Churan Wang, Zhoujun Li, Yizhou Wang, and Fangwei Zhong. Vlm can be a good assistant: Enhancing embodied visual tracking with self-improving vision-language models. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 13154–13161. IEEE, 2025
2025
-
[18]
Alfred: A benchmark for interpreting grounded instructions for everyday tasks
Mohit Shridhar, Jesse Thomason, Daniel Gordon, Yonatan Bisk, Winson Han, Roozbeh Mot- taghi, Luke Zettlemoyer, and Dieter Fox. Alfred: A benchmark for interpreting grounded instructions for everyday tasks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10740–10749, 2020
2020
-
[19]
Unrealcv: Virtual worlds for computer vision
Weichao Qiu, Fangwei Zhong, Yi Zhang, Siyuan Qiao, Zihao Xiao, Tae Soo Kim, Yizhou Wang, and Alan Yuille. Unrealcv: Virtual worlds for computer vision. InProceedings of the 2017 ACM on Multimedia Conference, pages 1221–1224, 2017
2017
-
[20]
Hierarchical instruction-aware embodied visual tracking, 2025
Kui Wu, Hao Chen, Churan Wang, Fakhri Karray, Zhoujun Li, Yizhou Wang, and Fangwei Zhong. Hierarchical instruction-aware embodied visual tracking, 2025
2025
-
[21]
Adatracker: Learning adaptive in-context policy for cross-embodiment active visual tracking.IEEE Robotics and Automation Letters, 2026
Kui Wu, Hao Chen, Jinzhu Han, Haijun Liu, Churan Wang, Yizhou Wang, Zhoujun Li, Si Liu, and Fangwei Zhong. Adatracker: Learning adaptive in-context policy for cross-embodiment active visual tracking.IEEE Robotics and Automation Letters, 2026
2026
-
[22]
Proactive multi-camera collaboration for 3d human pose estimation
Hai Ci, Mickel Liu, Xuehai Pan, fangwei zhong, and Yizhou Wang. Proactive multi-camera collaboration for 3d human pose estimation. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[23]
Communication-efficient desire alignment for embodied agent-human adaptation
Yuanfei Wang, Xinju Huang, Fangwei Zhong, Yaodong Yang, Yizhou Wang, Yuanpei Chen, and Hao Dong. Communication-efficient desire alignment for embodied agent-human adaptation. arXiv preprint arXiv:2505.22503, 2025
-
[24]
Empowering embodied visual tracking with visual foundation models and offline rl
Fangwei Zhong, Kui Wu, Hai Ci, Churan Wang, and Hao Chen. Empowering embodied visual tracking with visual foundation models and offline rl. InEuropean Conference on Computer Vision, pages 139–155, 2024
2024
-
[25]
Partnr: A benchmark for planning and reasoning in embodied multi-agent tasks
Matthew Chang, Gunjan Chhablani, Alexander Clegg, Mikael Dallaire Cote, Ruta Desai, Michal Hlavac, Vladimir Karashchuk, Jacob Krantz, Roozbeh Mottaghi, Priyam Parashar, et al. Partnr: A benchmark for planning and reasoning in embodied multi-agent tasks. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[26]
Coherent: Collaboration of heterogeneous multi-robot system with large language models
Kehui Liu, Zixin Tang, Dong Wang, Zhigang Wang, Xuelong Li, and Bin Zhao. Coherent: Collaboration of heterogeneous multi-robot system with large language models. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 10208–10214. IEEE, 2025
2025
-
[27]
Ultralytics YOLO, January 2023
Glenn Jocher, Jing Qiu, and Ayush Chaurasia. Ultralytics YOLO, January 2023
2023
-
[28]
Uni-navid: A video-based vision-language-action model for unifying embodied navigation tasks.Robotics: Science and Systems, 2025
Jiazhao Zhang, Kunyu Wang, Shaoan Wang, Minghan Li, Haoran Liu, Songlin Wei, Zhongyuan Wang, Zhizheng Zhang, and He Wang. Uni-navid: A video-based vision-language-action model for unifying embodied navigation tasks.Robotics: Science and Systems, 2025
2025
-
[29]
Vint: A foundation model for visual navigation
Dhruv Shah, Ajay Sridhar, Nitish Dashora, Kyle Stachowicz, Kevin Black, Noriaki Hirose, and Sergey Levine. Vint: A foundation model for visual navigation. InConference on Robot Learning, pages 711–733. PMLR, 2023
2023
-
[30]
Nomad: Goal masked diffusion policies for navigation and exploration
Ajay Sridhar, Dhruv Shah, Catherine Glossop, and Sergey Levine. Nomad: Goal masked diffusion policies for navigation and exploration. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 63–70. IEEE, 2024
2024
-
[31]
Sg-nav: Online 3d scene graph prompting for llm-based zero-shot object navigation.Advances in neural information processing systems, 37:5285–5307, 2024
Hang Yin, Xiuwei Xu, Zhenyu Wu, Jie Zhou, and Jiwen Lu. Sg-nav: Online 3d scene graph prompting for llm-based zero-shot object navigation.Advances in neural information processing systems, 37:5285–5307, 2024. 11
2024
-
[32]
Omninav: A unified framework for prospective exploration and visual-language navigation
Xinda Xue, Junjun Hu, Minghua Luo, Xie Shichao, Jintao Chen, Zixun Xie, Quan Kuichen, GuoWei, Zedong Chu, Mu Xu, and Zhengzhou Zhu. Omninav: A unified framework for prospective exploration and visual-language navigation. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[33]
Shaofei Cai, Zhancun Mu, Anji Liu, and Yitao Liang. Rocket-2: Steering visuomotor policy via cross-view goal alignment.arXiv preprint arXiv:2503.02505, 2025
-
[34]
Sakoe and S
H. Sakoe and S. Chiba. Dynamic programming algorithm optimization for spoken word recognition.IEEE transactions on acoustics, speech, and signal processing, 26(1):43–49, 1978
1978
-
[35]
(fine-tuned)
Daniel Fried, Ronghang Hu, V olkan Cirik, Anna Rohrbach, Jacob Andreas, Louis-Philippe Morency, Taylor Berg-Kirkpatrick, Kate Saenko, Dan Klein, and Trevor Darrell. Speaker- follower models for vision-and-language navigation.Advances in neural information processing systems, 31, 2018. 12 Appendix This appendix is organized into three parts. Section B exte...
2018
-
[36]
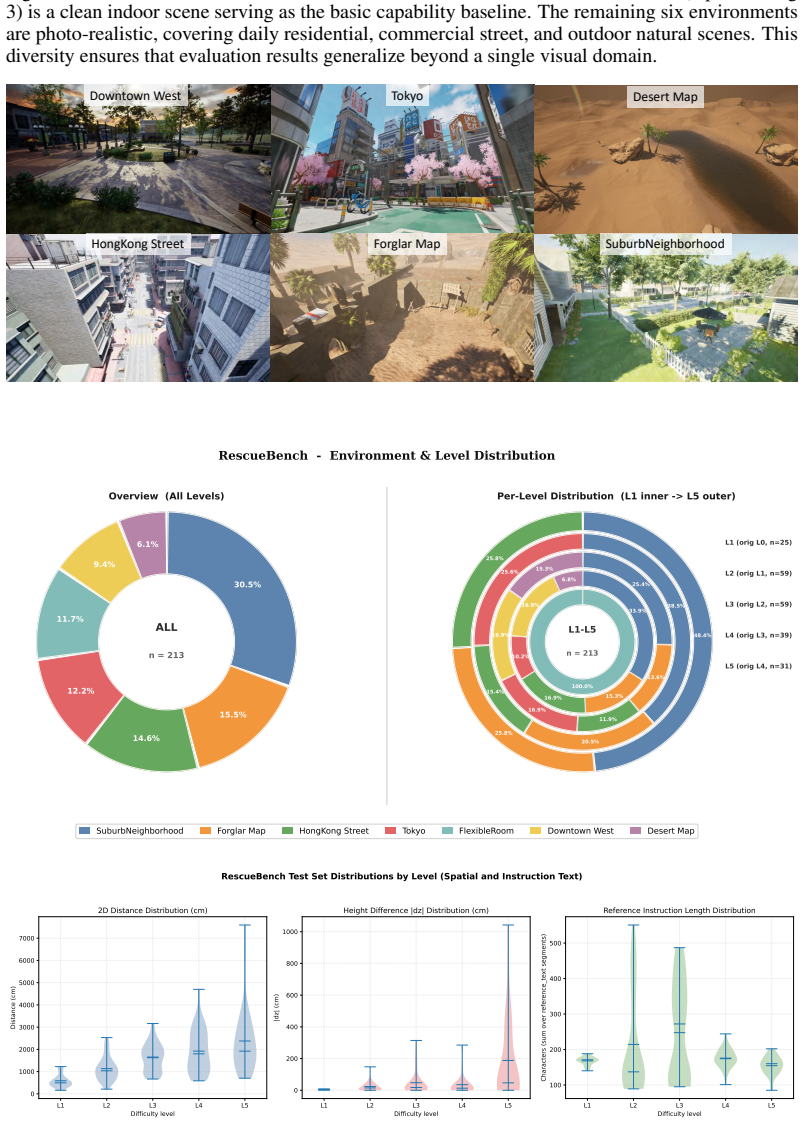
The remaining six environments are photo-realistic, covering daily residential, commercial street, and outdoor natural scenes
is a clean indoor scene serving as the basic capability baseline. The remaining six environments are photo-realistic, covering daily residential, commercial street, and outdoor natural scenes. This diversity ensures that evaluation results generalize beyond a single visual domain. Downtown WestTokyo Desert Map HongKongStreetForglarMapSuburbNeighborhood AL...
2000
-
[37]
For L1–L2, episodes with significant ∆z are rejected, keeping these levels on flat terrain
3D elevation change (∆z).For L5, the expert trajectory must have a minimum elevation change ∆zmin (approximately one full floor height, 3–4 m), ensuring that the agent must traverse staircases, ramps, or multi-level platforms. For L1–L2, episodes with significant ∆z are rejected, keeping these levels on flat terrain. For L3–L4, moderate elevation changes ...
-
[38]
This ensures that these levels test interaction-conditional navigation rather than open-space traversal alone
Environment interaction.For L4–L5, the expert trajectory must contain at least one navigable interaction element (if the interaction exists in the environment): a door, gate, or narrow passageway that requires the agent to actively engage with the environment structure. This ensures that these levels test interaction-conditional navigation rather than ope...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.