HMPO: Hybrid Median-length Policy Optimization for Chain-of-Thought Compression
Pith reviewed 2026-06-28 16:05 UTC · model grok-4.3
The pith
HMPO compresses chain-of-thought reasoning by 19 to 46 percent with negligible accuracy loss in a single training stage.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
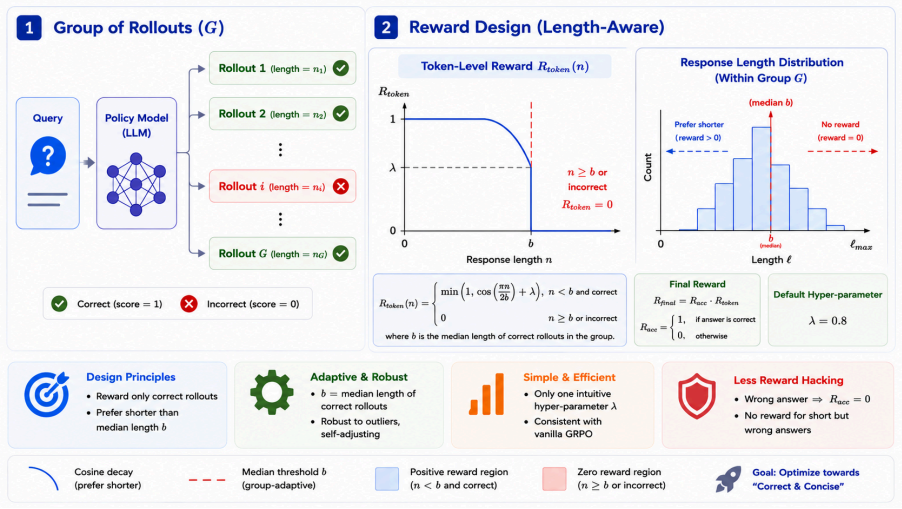
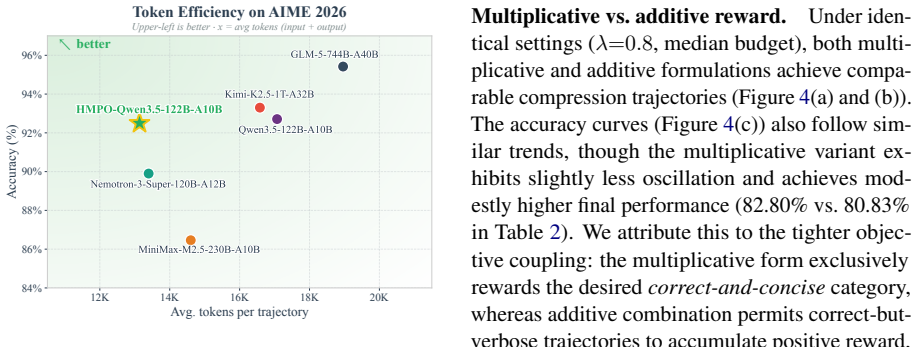
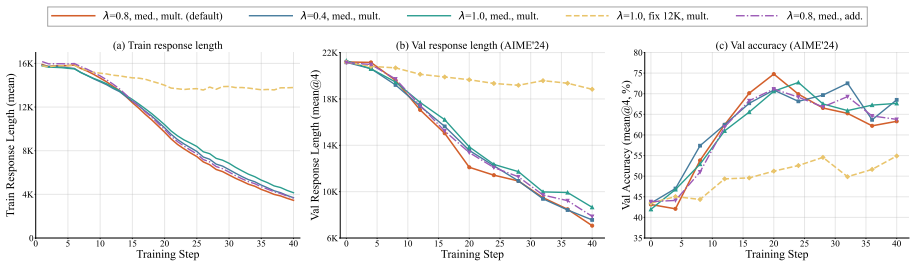
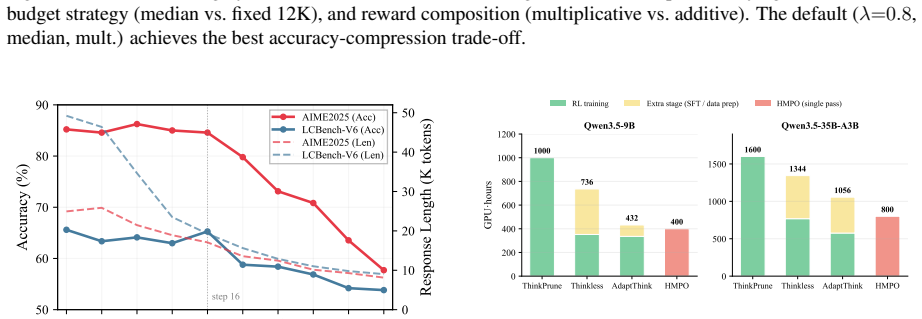
HMPO achieves 19%--46% token compression with negligible accuracy degradation across dense and Mixture-of-Experts models up to 122B parameters by deriving an adaptive median-based length budget from successful rollouts, applying a cosine-decay token reward, and using a multiplicative reward formulation that prioritizes answer correctness over length reduction.
What carries the argument
Hybrid median-length policy optimization that sets its length target from the median of successful rollouts and combines it with cosine-decay and multiplicative rewards.
If this is right
- The same policy trained on mathematics transfers directly to code, science, and instruction-following tasks.
- The framework scales from 9B to 122B parameters in both dense and MoE architectures.
- Training cost falls substantially relative to prior multi-stage compression baselines.
- Inference token count drops 19 to 46 percent while answer accuracy stays essentially unchanged.
Where Pith is reading between the lines
- Length targets derived from successful rollouts may remove the need for per-task hyperparameter sweeps in other reinforcement-learning alignment settings.
- The multiplicative reward structure could be tested on additional trade-offs such as latency versus quality in non-reasoning tasks.
- Single-stage training on narrow data that still generalizes suggests similar compression policies might be learned from even smaller curated sets.
- If the median-budget mechanism holds at larger scales, it could support dynamic compression that adjusts automatically during deployment.
Load-bearing premise
That the median length of successful rollouts will supply a reliable, task-agnostic budget and that multiplying correctness and length rewards will block reward hacking on every domain and model scale.
What would settle it
An experiment on a new task where accuracy drops more than 2 percent at the reported compression ratios when the identical single-stage procedure is applied.
Figures



read the original abstract
Large language models achieve remarkable performance via extended chain-of-thought (CoT) reasoning, yet this lengthy process incurs substantial inference overhead. Existing CoT compression methods struggle with inflexible manual length budgets, computationally expensive multi-stage training pipelines, and fragile scalability restricted to small models. We propose HMPO (Hybrid Median-length Policy Optimization), a cost-effective, single-stage reinforcement learning framework. HMPO efficiently compresses CoT via three synergistic components: an adaptive median-based budget derived from successful rollouts to eliminate manual tuning, a cosine-decay token reward for smooth length penalization, and a multiplicative reward formulation that substantially mitigates trivial reward hacking by strictly prioritizing answer correctness. Trained exclusively on mathematical data, HMPO generalizes seamlessly across math, code, science, and instruction-following tasks. Extensive experiments scaling from 9B to 122B parameters across dense and Mixture-of-Experts (MoE) architectures demonstrate that HMPO achieves 19%--46% token compression with negligible accuracy degradation, all while drastically reducing training costs compared to existing multi-stage baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes HMPO, a single-stage reinforcement learning framework for chain-of-thought compression in large language models. It features an adaptive median-based budget from successful rollouts, cosine-decay token reward, and multiplicative reward formulation prioritizing correctness. Trained on mathematical data, it generalizes to other domains and achieves 19% to 46% token compression with negligible accuracy degradation on models up to 122B parameters, while lowering training costs versus multi-stage methods.
Significance. If the empirical results are robust, this approach could substantially advance efficient inference for reasoning-capable LLMs by simplifying the training pipeline and eliminating manual length tuning, with broad applicability across model scales and architectures.
major comments (1)
- [Abstract] The abstract states experimental outcomes but supplies no information on baselines, evaluation metrics, statistical tests, or data exclusion rules, so it is impossible to determine whether the central claims are supported by the data.
Simulated Author's Rebuttal
We thank the referee for their feedback. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] The abstract states experimental outcomes but supplies no information on baselines, evaluation metrics, statistical tests, or data exclusion rules, so it is impossible to determine whether the central claims are supported by the data.
Authors: The abstract is a high-level summary constrained by length. Full details on baselines (multi-stage RL methods referenced in Related Work and Experiments), evaluation metrics (token reduction percentage and accuracy on math/code/science/instruction benchmarks), statistical considerations, and data exclusion criteria appear in Sections 3 (Method) and 4 (Experiments). We will revise the abstract to name the primary metrics and baseline category explicitly, while noting that exhaustive protocol details remain in the body. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The abstract and provided text describe HMPO as a single-stage RL framework whose core components—an adaptive median-based budget from successful rollouts, cosine-decay token reward, and multiplicative reward formulation—are explicitly presented as design choices and methodological decisions rather than quantities derived from or fitted to the target compression outcomes. No equations, self-citation chains, or load-bearing steps are shown that reduce the claimed results (19%-46% token compression with negligible accuracy loss) back to the inputs by construction. The generalization claims and cost reductions are framed as empirical outcomes of the chosen architecture, not tautological re-statements of fitted parameters. This is the most common honest finding for a methods paper whose central claims rest on external experimental validation rather than internal definitional equivalence.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Successful rollouts provide a reliable basis for setting an adaptive length budget that generalizes across tasks.
- domain assumption The multiplicative reward formulation strictly prioritizes correctness and thereby prevents trivial reward hacking.
invented entities (2)
-
cosine-decay token reward
no independent evidence
-
multiplicative reward formulation
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2601.20467 (2026)
Ctrlcot: Dual-granularity chain-of-thought compression for controllable reasoning.arXiv preprint arXiv:2601.20467. Gongfan Fang, Xinyin Ma, and Xinchao Wang. 2026. Thinkless: Llm learns when to think.Advances in neural information processing systems, 38:151268– 151295. Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ru...
-
[2]
ThinkPrune: Pruning Long Chain-of-Thought of LLMs via Reinforcement Learning
Thinkprune: Pruning long chain-of-thought of llms via reinforcement learning.arXiv preprint arXiv:2504.01296. Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richard- son, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, and 1 others. 2024. Openai o1 system card.arXiv preprint arXiv:2412.16720. Naman Jain, Alex Gu, Wen-Ding L...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
C3ot: Generating shorter chain-of-thought without compromising effectiveness. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 24312–24320. Haotian Luo, Li Shen, Haiying He, Yibo Wang, Shi- wei Liu, Wei Li, Naiqiang Tan, Xiaochun Cao, and Dacheng Tao. 2025. O1-pruner: Length- harmonizing fine-tuning for o1-like reasoning p...
-
[4]
Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models
Stop overthinking: A survey on efficient rea- soning for large language models.arXiv preprint arXiv:2503.16419. Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, and 1 others. 2022. Chain-of-thought prompting elic- its reasoning in large language models.Advances in neural information processing systems, 35:248...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
Heming Xia, Chak Tou Leong, Wenjie Wang, Yongqi Li, and Wenjie Li
The art of efficient reasoning: Data, reward, and optimization.arXiv preprint arXiv:2602.20945. Heming Xia, Chak Tou Leong, Wenjie Wang, Yongqi Li, and Wenjie Li. 2025. Tokenskip: Controllable chain-of-thought compression in llms. InProceed- ings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 3351–3363. An Yang, Anfeng L...
-
[6]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Edward Yeo, Yuxuan Tong, Morry Niu, Graham Neu- big, and Xiang Yue. 2025. Demystifying long chain-of-thought reasoning in llms.arXiv preprint arXiv:2502.03373. Wenhao Zeng, Yaoning Wang, Chao Hu, Yuling Shi, Chengcheng Wan, Hongyu Zhang, and Xiaodong Gu. 2025. Pruning the unsurprising: Efficient code...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
arithmetic sequences of integers
Redundant verification of obvious con- straints: The Base Model spends ∼800 char- acters debating whether d must be an integer, considering fractional d values and ruling them out—a conclusion that follows trivially from “arithmetic sequences of integers.”
-
[8]
Is there any possibility that d is negative and 24, 34 are terms before 4?
Repeated self-questioning: The thinking trace revisits whether d can be negative multiple times (“Is there any possibility that d is negative and 24, 34 are terms before 4?”), each time reaching the same conclusion thatd >0
-
[9]
In contrast, HMPO’s reasoning is structured as a concise step-by-step outline:
Over-elaboration of basic steps: Computing gcd(20,30) = 10 and listing its divisors is ex- panded across ∼500 characters with intermedi- ate prime factorization steps. In contrast, HMPO’s reasoning is structured as a concise step-by-step outline:
-
[10]
Identify constraints → formulate (k1−1)d= 20,(k 2−1)d= 30
-
[11]
Determine d|gcd(20,30) = 10 , positive divi- sors{1,2,5,10}
-
[12]
ComputeT 10 = 4 + 9dfor eachd, sum them
-
[13]
HMPO eliminates the redundant self-debate while retaining all logically necessary steps
Brief arithmetic verification: 13+22+49+94 = 178. HMPO eliminates the redundant self-debate while retaining all logically necessary steps. The final response is also more concise (1,560 vs. 2,198 chars) while containing identical mathematical con- tent. C.2 LiveCodeBench: Code Generation Statistics. • Base Model: thinking = 136,169 chars, response = 13,48...
-
[14]
Problem reformulation: Both correctly iden- tify that the cost formula uses a prefix sum of nums. The Base Model spends ∼5K chars re-reading the problem statement and second- guessing its interpretation before reaching this conclusion; HMPO verifies it against examples in∼1K chars
-
[15]
HMPO directly formulates the 2D DP and proceeds to optimization
DP formulation: The Base Model explores mul- tiple DP formulations (DP[i] , DP[i][m] , back to DP[i][m] with restructuring) before settling on the correct one. HMPO directly formulates the 2D DP and proceeds to optimization
-
[16]
Convex hull trick derivation: The Base Model derives CHT from scratch with extensive alge- braic manipulation (∼20K chars), while HMPO recognizes the standard pattern (minimizing mx+b with monotone queries) and applies it in∼5K chars
-
[17]
HMPO produces a clean code-only response (3.6K chars) without redundant expla- nation
Implementation: The Base Model’s response includes both a lengthy explanation of the ap- proach (10K chars)andthe code (3.5K chars), with the explanation repeating much of the thinking. HMPO produces a clean code-only response (3.6K chars) without redundant expla- nation. The key insight is that HMPO does not sacrifice algorithmic sophistication—it still ...
2026
-
[18]
HMPO verifies once and moves forward
Elimination of redundant verification: The Base Model repeatedly re-checks conclusions it has already established. HMPO verifies once and moves forward
-
[19]
It converges on the correct method faster, suggest- ing the RL training has taught the model to rec- ognize solution patterns more efficiently
Direct problem-solving: HMPO avoids explor- ing and discarding suboptimal approaches. It converges on the correct method faster, suggest- ing the RL training has taught the model to rec- ognize solution patterns more efficiently
-
[20]
Wait, if we define DP[i] as the min cost for prefix i ending withsomenumber of subarrays, that equation is wrong because the new subarray needs to know m
Concise final responses: HMPO produces shorter final answers/code without redundant re- explanation of the reasoning already performed in the thinking block. These patterns explain why moderate compres- sion (42–46%) can preserve or evenimproveaccu- racy: by removing self-contradicting explorations and repetitive verification, the model reduces op- portun...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.