Co-training with Ego-centric Video and Demonstration for Robot Navigation Task
Pith reviewed 2026-06-28 14:15 UTC · model grok-4.3
The pith
Joint training on human egocentric videos and robot demonstrations improves VLA model performance on mobile robot navigation tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
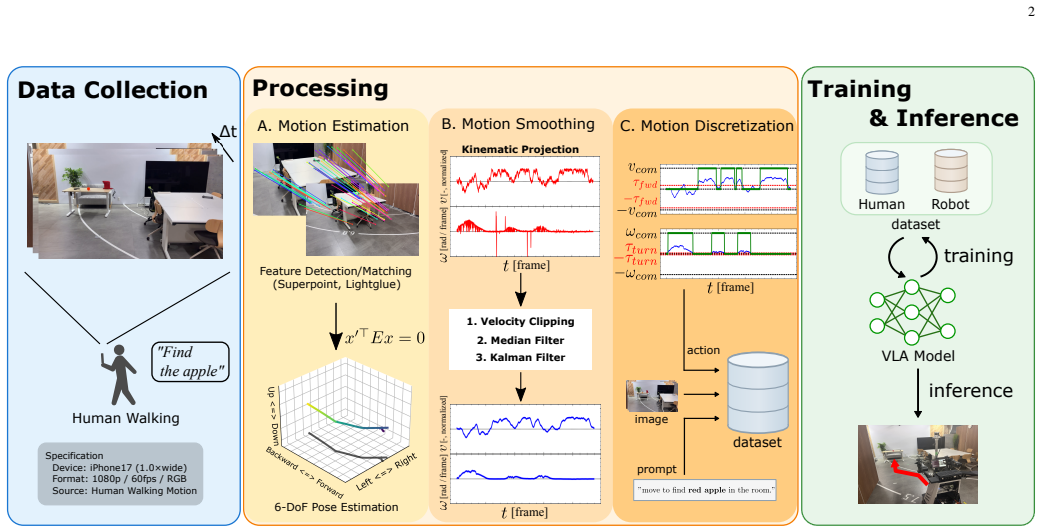
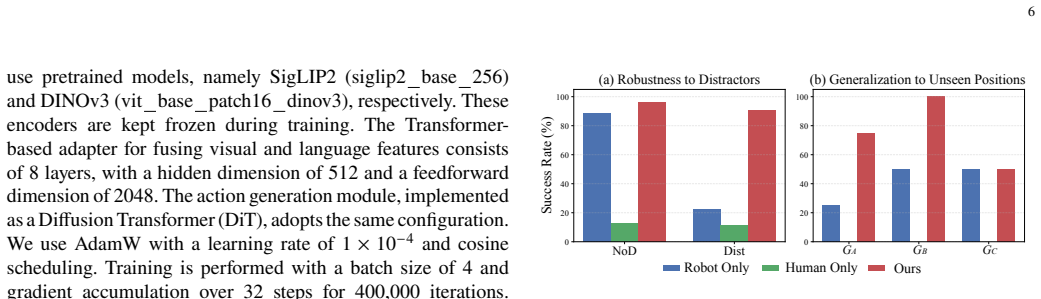
By estimating camera motion from human egocentric videos and transforming it into action representations compatible with ground mobile robots, the method creates usable imitation-learning datasets from human walks. Joint training of the VLA model on these human-derived datasets together with robot-collected data produces improved language-conditioned navigation compared with training on human data or robot data in isolation, as shown in fruit-search experiments.
What carries the argument
The motion-estimation and action-transformation pipeline that converts egocentric human walking videos into datasets compatible with ground mobile robot imitation learning.
If this is right
- Human egocentric videos become a scalable supplement to limited robot navigation data.
- The co-trained model shows stronger language understanding when directing the robot to search for specific objects.
- Action generation becomes more robust across variations in the navigation environment.
- The framework reduces reliance on costly robot data collection for similar mobile tasks.
Where Pith is reading between the lines
- The same video-to-action conversion could extend to other locomotion styles or indoor environments if the motion estimates remain reliable.
- Further gains might appear by mixing the converted human data with simulation rollouts before real-robot fine-tuning.
- Success on fruit search suggests the method could support other language-guided navigation goals such as object avoidance or room-to-room travel.
Load-bearing premise
Estimating and converting camera motion from human videos produces action labels accurate enough for effective imitation learning on real robots.
What would settle it
If separate training on only the robot dataset or only the converted human dataset matches or exceeds the joint-training performance on the fruit-search navigation task, the benefit of co-training would be refuted.
Figures



read the original abstract
Vision-language-action (VLA) models are promising for diverse robotic tasks, but their performance heavily depends on large-scale high-quality training data, whose collection on real robots is costly and time-consuming. While prior work has explored augmenting manipulation datasets with egocentric human videos, applying such approaches to mobile robot navigation remains challenging due to viewpoint changes during locomotion. In this paper, we propose a framework that converts egocentric walking videos into datasets for mobile robot imitation learning. The proposed method estimates camera motion from human videos and transforms it into action representations compatible with ground mobile robots. By jointly training a VLA model on human-derived and robot-collected datasets, the model achieves improved language understanding and more robust action generation than training with either data source alone. Experiments on a fruit-search navigation task demonstrate that human egocentric videos provide an effective and scalable data source for mobile robot learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes converting egocentric human walking videos into training data for mobile robot imitation learning by estimating camera motion and mapping it to action representations compatible with ground robots. It then co-trains a vision-language-action (VLA) model on the resulting human-derived dataset together with robot-collected demonstrations, claiming improved language understanding and more robust action generation on a fruit-search navigation task relative to single-source training.
Significance. If the transformation produces action labels whose distribution is sufficiently close to real robot data and the reported gains are reproducible, the approach would provide a scalable route to augment costly robot navigation datasets with abundant human video, directly addressing data scarcity in VLA models for locomotion tasks.
major comments (2)
- [Abstract] Abstract: the central claim of performance gains from co-training rests on an unverified transformation step, yet the abstract supplies no quantitative metrics, baselines, statistical tests, or details on the motion-estimation pipeline, preventing evaluation of whether joint training improves rather than harms VLA performance.
- [Method] Method (camera-motion-to-action mapping): the claim that camera motion estimated from human videos can be transformed into action representations compatible with non-holonomic ground robots lacks error bounds, embodiment-specific corrections (e.g., differential-drive kinematics, speed scaling, head-motion artifacts), or ablations isolating the transformed data's contribution; this mapping is load-bearing for the augmentation argument.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below. Where the comments identify gaps in presentation or analysis, we have revised the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of performance gains from co-training rests on an unverified transformation step, yet the abstract supplies no quantitative metrics, baselines, statistical tests, or details on the motion-estimation pipeline, preventing evaluation of whether joint training improves rather than harms VLA performance.
Authors: We agree that the abstract should convey the key quantitative evidence. The revised abstract now includes the main performance numbers (success rate on the fruit-search task for co-training vs. robot-only and human-only baselines), a one-sentence description of the motion-estimation pipeline, and a note that the reported gains are statistically significant under a paired t-test. These additions are drawn directly from the experimental results already present in Section 4. revision: yes
-
Referee: [Method] Method (camera-motion-to-action mapping): the claim that camera motion estimated from human videos can be transformed into action representations compatible with non-holonomic ground robots lacks error bounds, embodiment-specific corrections (e.g., differential-drive kinematics, speed scaling, head-motion artifacts), or ablations isolating the transformed data's contribution; this mapping is load-bearing for the augmentation argument.
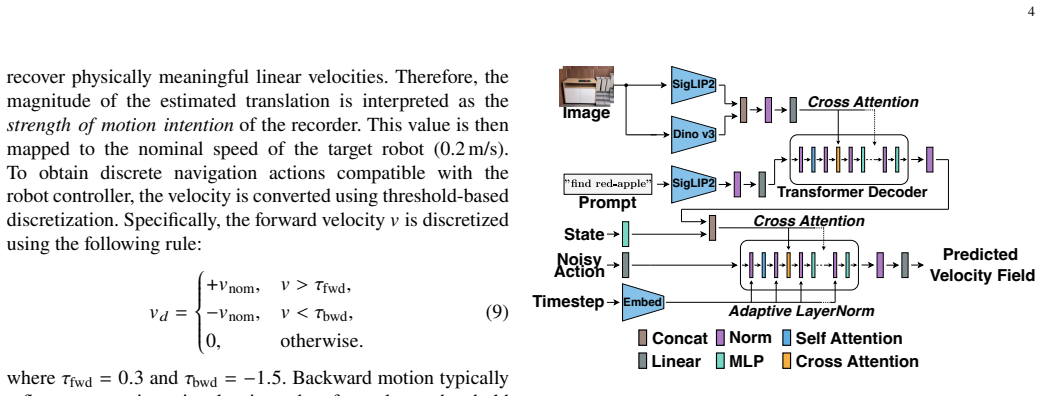
Authors: Section 3.2 already describes the SLAM-based camera-motion estimation and the subsequent linear-velocity / angular-velocity mapping. In response to this comment we have added: (i) quantitative error bounds obtained by comparing estimated trajectories against ground-truth motion on a held-out set of human videos, (ii) explicit handling of differential-drive kinematics and speed scaling, (iii) a filtering step for head-motion artifacts, and (iv) an ablation that trains the VLA model with and without the transformed human data while keeping all other factors fixed. These additions appear in a new subsection 3.3 and in the experimental tables. revision: yes
Circularity Check
No circularity: experimental claims rest on data comparisons, not self-defined quantities
full rationale
The paper describes a data-conversion pipeline (camera-motion estimation followed by action mapping) and reports empirical gains from joint VLA training on human-derived plus robot data. No equations, fitted parameters, or derivation steps appear in the provided text. The central result is an experimental comparison (joint training vs. single-source baselines), which is falsifiable against held-out robot performance and does not reduce to a self-citation, ansatz, or renaming of inputs. The transformation step is presented as a methodological choice whose validity is tested downstream rather than assumed by definition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Survey of imitation learning for robotic manipulation,
B. Fang, S. Jia, D. Guo, M. Xu, S. Wen, and F. Sun, “Survey of imitation learning for robotic manipulation,”International Journal of Intelligent Robotics and Applications, vol. 3, no. 4, pp. 362–369, 2019. [Online]. Available: https://doi.org/10.1007/s41315-019-00103-5
-
[2]
A survey of imitation learning: Algorithms, recent developments, and challenges,
M. Zare, P. M. Kebria, A. Khosravi, and S. Nahavandi, “A survey of imitation learning: Algorithms, recent developments, and challenges,” IEEE Transactions on Cybernetics, vol. 54, no. 12, pp. 7173–7186, 2024
2024
-
[3]
OpenVLA: An Open-Source Vision-Language-Action Model
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn, “Openvla: An open-source vision-language-action model,” 2024. [Online]. Available: https://arxiv.org/abs/2406.09246
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky, “𝜋 0: A vision-language-action flow model for general robot control,” 2026. [Online]. Availabl...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
RT-1: Robotics Transformer for Real-World Control at Scale
A. Brohan, N. Brown, J. Carbajal, Y. Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Hausman, A. Herzog, J. Hsu, J. Ibarz, B. Ichter, A. Irpan, T. Jackson, S. Jesmonth, N. J. Joshi, R. Julian, D. Kalashnikov, Y. Kuang, I. Leal, K.-H. Lee, S. Levine, Y. Lu, U. Malla, D. Manjunath, I. Mordatch, O. Nachum, C. Parada, J. Peralta, E. Perez, K. Pertsch, J. Q...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Rt-2: Vision-language-action models transfer web knowledge to robotic control,
B. Zitkovich and et al., “Rt-2: Vision-language-action models transfer web knowledge to robotic control,” inCoRL, 2023
2023
-
[7]
RoboNet: Large-Scale Multi-Robot Learning
S. Dasari, F. Ebert, S. Tian, S. Nair, B. Bucher, K. Schmeckpeper, S. Singh, S. Levine, and C. Finn, “Robonet: Large-scale multi-robot learning,” 2020. [Online]. Available: https://arxiv.org/abs/1910.11215
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[8]
Bridgedata v2: A dataset for robot learning at scale,
H. R. Walke, K. Black, T. Z. Zhao, Q. Vuong, C. Zheng, P. Hansen- Estruch, A. W. He, V. Myers, M. J. Kim, M. Du, A. Lee, K. Fang, C. Finn, and S. Levine, “Bridgedata v2: A dataset for robot learning at scale,” inProceedings of The 7th Conference on Robot Learning, ser. Proceedings of Machine Learning Research, J. Tan, M. Toussaint, and K. Darvish, Eds., v...
2023
-
[9]
Ego4d: Around the world in 3,000 hours of egocentric video,
K. Grauman and et al., “Ego4d: Around the world in 3,000 hours of egocentric video,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2022, pp. 18 995–19 012
2022
-
[10]
Navgpt: Explicit reasoning in vision-and-language navigation with large language models,
G. Zhou, Y. Hong, and Q. Wu, “Navgpt: Explicit reasoning in vision-and-language navigation with large language models,” Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 7, p. 7641–7649, Mar. 2024. [Online]. Available: https://ojs.aaai.org/index.php/AAAI/article/view/28597
2024
-
[11]
Lm-nav: Robotic navigation with large pre-trained models of language, vision, and action,
D. Shah, B. Osi ´nski, b. ichter, and S. Levine, “Lm-nav: Robotic navigation with large pre-trained models of language, vision, and action,” in Proceedings of The 6th Conference on Robot Learning, ser. Proceedings of Machine Learning Research, K. Liu, D. Kulic, and J. Ichnowski, Eds., vol. 205. PMLR, 14–18 Dec 2023, pp. 492–504. [Online]. Available: https...
2023
-
[12]
Visual language maps for robot navigation,
C. Huang, O. Mees, A. Zeng, and W. Burgard, “Visual language maps for robot navigation,” in2023 IEEE International Conference on Robotics and Automation (ICRA), 2023, pp. 10 608–10 615
2023
-
[13]
Transformer-based model for monocular visual odometry: A video understanding approach,
A. O. Franc ¸ani and M. R. O. A. Maximo, “Transformer-based model for monocular visual odometry: A video understanding approach,”IEEE Access, vol. 13, pp. 13 959–13 971, 2025
2025
-
[14]
Superpoint: Self- supervised interest point detection and description,
D. DeTone, T. Malisiewicz, and A. Rabinovich, “Superpoint: Self- supervised interest point detection and description,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, June 2018
2018
-
[15]
Lightglue: Local feature matching at light speed,
P. Lindenberger, P.-E. Sarlin, and M. Pollefeys, “Lightglue: Local feature matching at light speed,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2023, pp. 17 627– 17 638
2023
-
[16]
Scale invariant feature transform,
T. Lindeberg, “Scale invariant feature transform,” pp. 10 491–, 2012, qC 20120524. [Online]. Available: http://www.scholarpedia.org/article/ Scale Invariant Feature Transform
2012
-
[17]
Orb: An efficient alternative to sift or surf,
E. Rublee, V. Rabaud, K. Konolige, and G. Bradski, “Orb: An efficient alternative to sift or surf,” in2011 International Conference on Computer Vision, 2011, pp. 2564–2571
2011
-
[18]
Hartley and A
R. Hartley and A. Zisserman,Multiple View Geometry in Computer Vision, 2nd ed. Cambridge University Press, 2003
2003
-
[19]
M. A. Fischler and R. C. Bolles, “Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography,”Commun. ACM, vol. 24, no. 6, p. 381–395, Jun. 1981. [Online]. Available: https://doi.org/10.1145/358669.358692
-
[20]
Sigmoid loss for language image pre-training,
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer, “Sigmoid loss for language image pre-training,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2023, pp. 11 975–11 986
2023
-
[21]
O. Sim ´eoni, H. V. Vo, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V. Khalidov, M. Szafraniec, S. Yi, M. Ramamonjisoa, F. Massa, D. Haziza, L. Wehrstedt, J. Wang, T. Darcet, T. Moutakanni, L. Sentana, C. Roberts, A. Vedaldi, J. Tolan, J. Brandt, C. Couprie, J. Mairal, H. J ´egou, P. Labatut, and P. Bojanowski, “Dinov3,” 2025. [Online]. Available: http...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Scalable diffusion models with transformers,
W. Peebles and S. Xie, “Scalable diffusion models with transformers,”
-
[23]
Scalable Diffusion Models with Transformers
[Online]. Available: https://arxiv.org/abs/2212.09748
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Flow Matching for Generative Modeling
Y. Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,” 2023. [Online]. Available: https://arxiv.org/abs/2210.02747
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Cobot magic,
AgileX, “Cobot magic,” Accessed:2026-02-21, https://global.agilex.ai/ products/cobot-magic
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.