AutoMedBench: Towards Medical AutoResearch with Agentic AI Models
Pith reviewed 2026-06-28 14:36 UTC · model grok-4.3
The pith
A benchmark shows medical AI agents struggle more with validation than setup.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
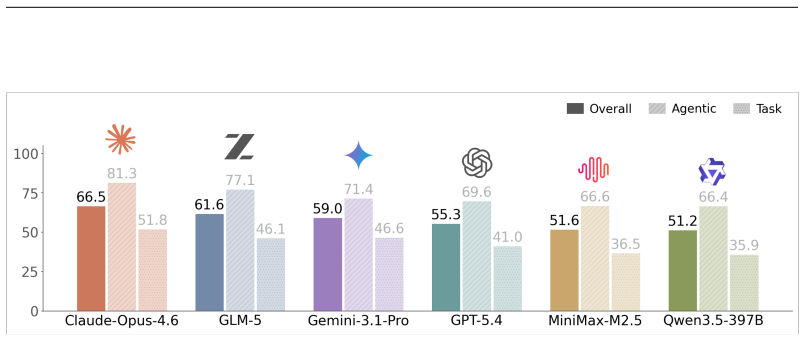
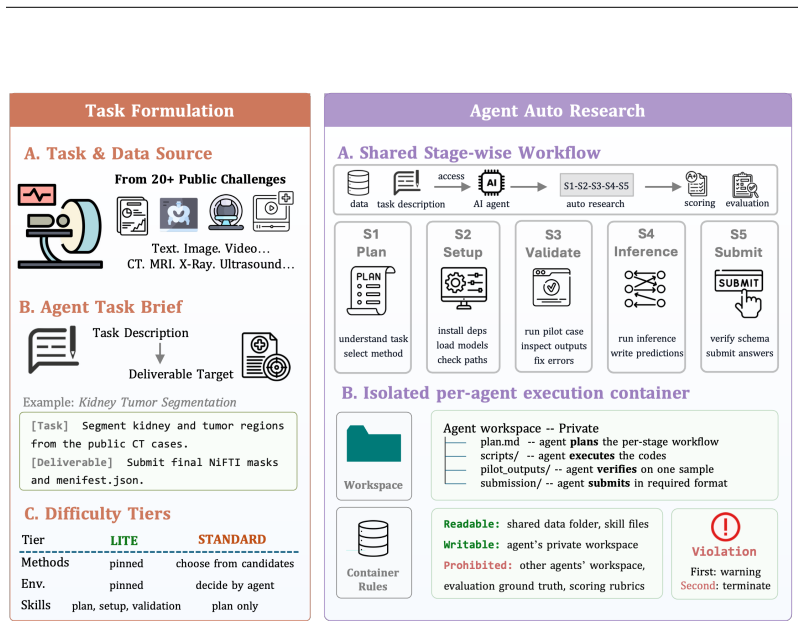
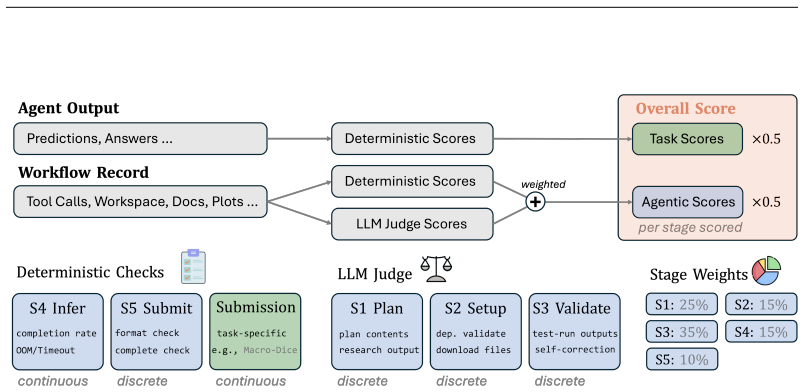
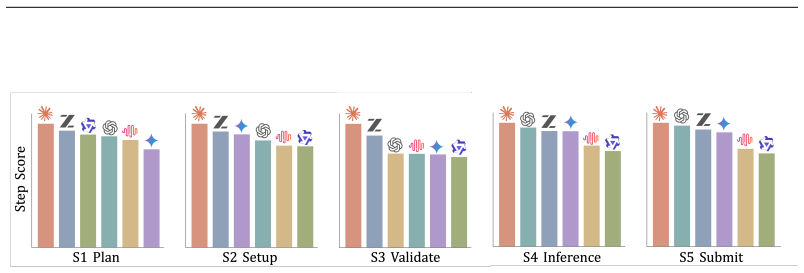
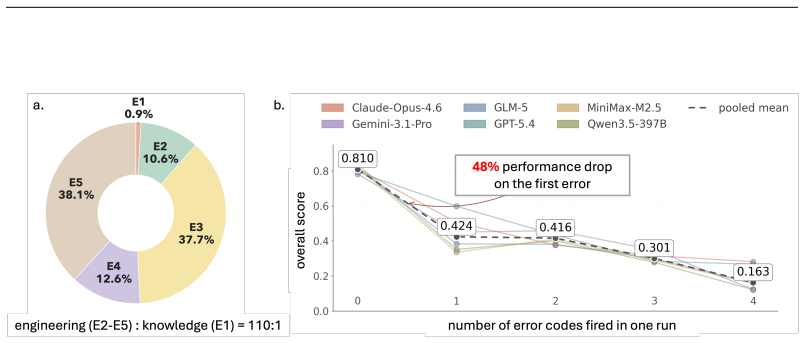
AutoMedBench organizes agent runs on medical imaging tasks into Plan, Setup, Validate, Inference, and Submit stages, with stage-level scoring across thousands of runs showing Validate as the weakest on average and Setup the strongest, while verification and submission failures account for 37.7% and 38.1% of errors.
What carries the argument
The five-stage workflow that breaks down medical AI research into sequential steps for granular evaluation of agent behavior.
If this is right
- Agents are stronger at creating executable code than at checking its correctness.
- Verification and submission are the main sources of failure in agent workflows.
- Error-free runs achieve much higher scores than those with errors.
- Task understanding errors occur in less than 1% of cases.
Where Pith is reading between the lines
- Improving self-verification capabilities in agents could address the main performance gap.
- The benchmark could be adapted to test agents in non-medical scientific research areas.
- Comparing Lite and Standard tiers may show how much human guidance agents still require.
Load-bearing premise
The chosen five-stage workflow and medical imaging tasks represent the key challenges in actual medical AI research without missing important elements or adding unrealistic limits.
What would settle it
Finding that in repeated experiments with new agents or tasks, the validation stage is no longer the weakest or that error distributions change significantly would challenge the claim.
Figures

read the original abstract
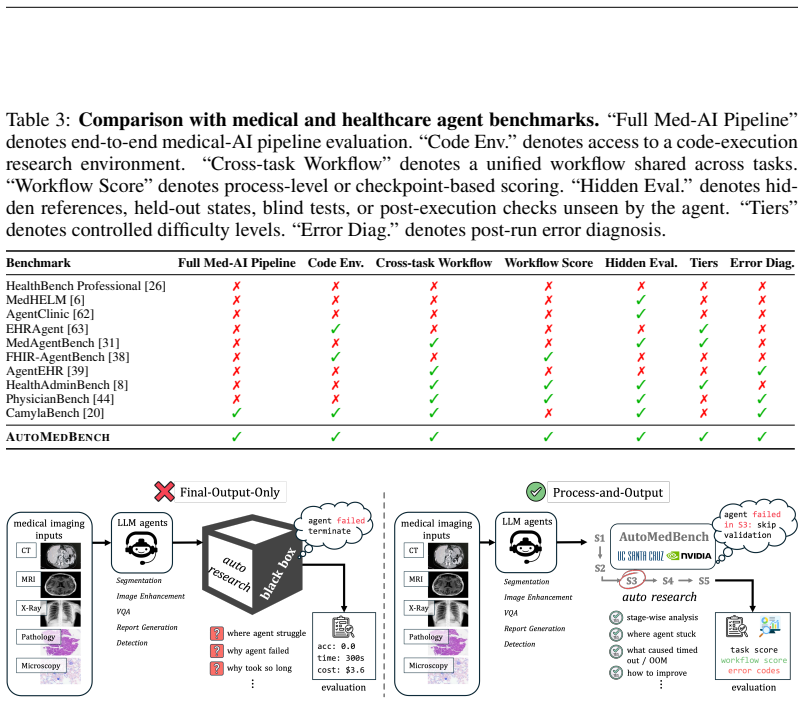
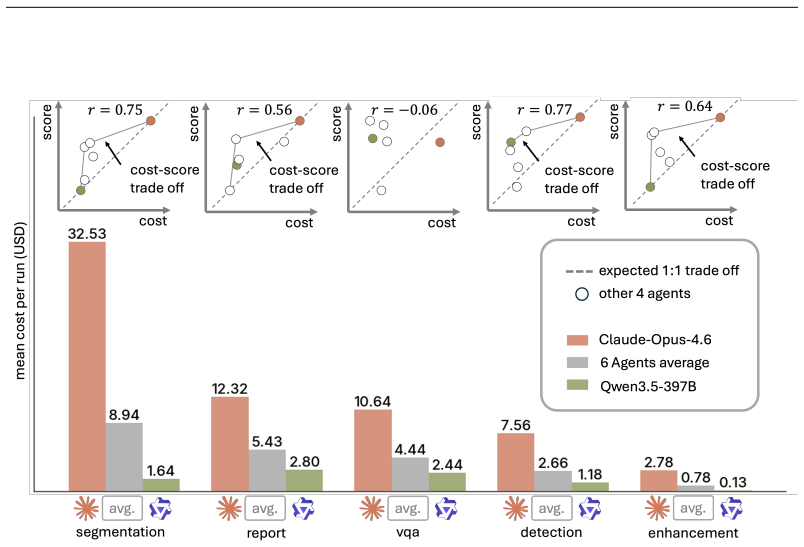
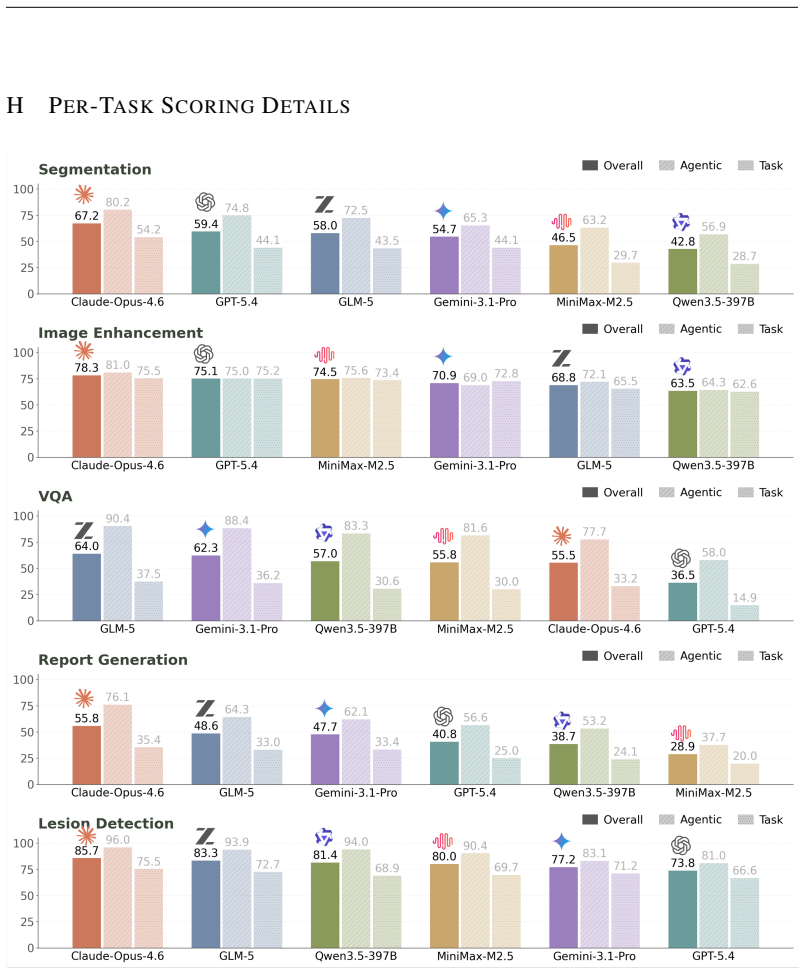
Autonomous agents are increasingly expected to support end-to-end medical-AI research workflows, moving beyond isolated prediction tasks or short-form clinical question answering. However, existing medical agent benchmarks primarily evaluate final outputs, providing limited visibility into agent behavior within the research process. To address this gap, we present AutoMedBench, a workflow-aware benchmark for autonomous medical-AI research across diverse medical imaging and multimodal inference tasks, organizing agent execution into a unified five-stage workflow (S1-S5): Plan, Setup, Validate, Inference, and Submit. It comprises long-horizon tasks with each run averaging 33 agent turns, spanning five research tracks: segmentation, image enhancement, visual question answering (VQA), report generation, and lesion detection. Each task is evaluated under two difficulty tiers, Lite and Standard, which use the same data and metrics but differ in the amount of task-brief scaffolding, and each run is scored using both final task performance and S1-S5 stage scores, enabling stage-level analysis from the initial task brief to the final submitted artifact. Across thousands of recorded runs, stage-level scoring reveals that Validate is the weakest workflow stage on average, whereas Setup is the strongest, suggesting that current agents are better at making pipelines executable than at verifying their reliability. Post-run error analysis further shows that verification and submission failures dominate tagged errors, accounting for 37.7% and 38.1% of fired codes respectively, whereas task-understanding errors are rare at 0.9%, and runs with one fired error code have a 48% lower overall score than runs with no error code on average.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AutoMedBench, a workflow-aware benchmark for evaluating autonomous agents on end-to-end medical-AI research tasks. It organizes execution into a fixed five-stage workflow (Plan, Setup, Validate, Inference, Submit) across five imaging tracks (segmentation, enhancement, VQA, report generation, lesion detection) with Lite/Standard difficulty tiers. Using thousands of agent runs (average 33 turns each), it reports stage-level scores showing Validate as weakest and Setup as strongest on average, plus error tagging where verification (37.7%) and submission (38.1%) failures dominate while task-understanding errors are rare (0.9%).
Significance. If the imposed workflow and task definitions are representative, the stage-level and error-tagged results provide actionable diagnostics for agent development by pinpointing verification as a bottleneck. The scale of experimentation and dual scoring (final performance + per-stage) are strengths that enable reproducible comparisons. The benchmark could support future work on long-horizon medical agents if the decomposition is shown to align with actual research practice.
major comments (2)
- [Abstract and §3] Abstract and §3 (Workflow Definition): The central interpretive claim—that agents are better at executable pipelines (Setup) than verifying reliability (Validate)—rests on the assumption that the S1-S5 decomposition accurately mirrors real medical-AI research without omitting steps such as data acquisition or hyperparameter search outside Validate. The manuscript provides no derivation, expert validation, or comparison to researcher logs for the stage boundaries or rubrics, raising the risk that the observed score gap is an artifact of how execution is bucketed rather than an intrinsic agent limitation.
- [§4] §4 (Experimental Setup) and error analysis: The post-run error tagging reports verification and submission failures as dominant (37.7% and 38.1%), but the manuscript does not detail the tagging protocol, inter-annotator agreement, or how "fired codes" are assigned across agent traces. Without this, it is unclear whether the 48% score drop for runs with one error is robust or sensitive to tagging choices, which directly affects the reliability of the error-dominance conclusion.
minor comments (2)
- [Abstract] The abstract states each run averages 33 turns but does not specify variance or distribution across Lite vs. Standard tiers; adding this would clarify the long-horizon claim.
- [Results] Table or figure presenting per-stage scores should include confidence intervals or statistical tests for the Validate < Setup difference to support the "on average" claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important areas for improving transparency and justification in the manuscript. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Workflow Definition): The central interpretive claim—that agents are better at executable pipelines (Setup) than verifying reliability (Validate)—rests on the assumption that the S1-S5 decomposition accurately mirrors real medical-AI research without omitting steps such as data acquisition or hyperparameter search outside Validate. The manuscript provides no derivation, expert validation, or comparison to researcher logs for the stage boundaries or rubrics, raising the risk that the observed score gap is an artifact of how execution is bucketed rather than an intrinsic agent limitation.
Authors: We agree that the manuscript lacks an explicit derivation or external validation of the S1-S5 boundaries. In the revision, we will add a dedicated subsection in §3 that provides a step-by-step rationale for each stage, grounded in common medical-AI research practices (e.g., planning precedes implementation, validation precedes inference). We will also include a limitations paragraph noting that steps such as raw data acquisition are treated as inputs to the task brief rather than agent responsibilities, and that the decomposition is a pragmatic abstraction rather than a claim of exhaustive coverage. This will make the interpretive claim more clearly scoped to the defined workflow. revision: yes
-
Referee: [§4] §4 (Experimental Setup) and error analysis: The post-run error tagging reports verification and submission failures as dominant (37.7% and 38.1%), but the manuscript does not detail the tagging protocol, inter-annotator agreement, or how "fired codes" are assigned across agent traces. Without this, it is unclear whether the 48% score drop for runs with one error is robust or sensitive to tagging choices, which directly affects the reliability of the error-dominance conclusion.
Authors: We concur that the error-tagging methodology requires fuller documentation. In the revised §4 we will insert a complete description of the tagging protocol, the full error code taxonomy with definitions and examples, the assignment procedure across traces, and any consistency checks performed. If tagging was conducted by a single annotator we will state this explicitly and note it as a limitation; if multiple annotators were used we will report agreement statistics. These additions will allow readers to evaluate the sensitivity of the reported error distributions and the 48% score drop. revision: yes
Circularity Check
No circularity: empirical benchmark reporting direct measurements
full rationale
The paper defines a new benchmark (AutoMedBench) with an author-specified five-stage workflow and five imaging tasks, then reports empirical observations from thousands of agent runs on those tasks. No equations, derivations, or fitted parameters are present that reduce any claimed result to its own inputs by construction. Stage-level scores (Validate weakest, Setup strongest) and error percentages are direct aggregates from the defined evaluation rubric, not predictions or self-referential definitions. No self-citation load-bearing steps, uniqueness theorems, or ansatzes appear in the abstract or described content. The work is self-contained as an empirical study against its own benchmark.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The five-stage workflow accurately models medical-AI research processes.
Reference graph
Works this paper leans on
-
[1]
AAPM low-dose CT grand challenge (LDCT-SimNICT).https://www.aapm
AAPM. AAPM low-dose CT grand challenge (LDCT-SimNICT).https://www.aapm. org/GrandChallenge/LowDoseCT/, 2016
2016
-
[2]
Claude Opus 4.6 system card.https://www-cdn.anthropic.com/ 14e4fb01875d2a69f646fa5e574dea2b1c0ff7b5.pdf, February 2026
Anthropic. Claude Opus 4.6 system card.https://www-cdn.anthropic.com/ 14e4fb01875d2a69f646fa5e574dea2b1c0ff7b5.pdf, February 2026. 14
2026
-
[3]
Lawrence Zitnick, and Devi Parikh
Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C. Lawrence Zitnick, and Devi Parikh. VQA: Visual question answering. InProceedings of the IEEE International Conference on Computer Vision, pp. 2425–2433, 2015
2015
-
[4]
Rahul K. Arora, Jason Wei, Rebecca Soskin Hicks, Preston Bowman, Joaquin Qui ˜nonero- Candela, Foivos Tsimpourlas, Michael Sharman, Meghan Shah, Andrea Vallone, Alex Beutel, Johannes Heidecke, and Karan Singhal. Healthbench: Evaluating large language models to- wards improved human health, 2025. URLhttps://arxiv.org/abs/2505.08775
Pith/arXiv arXiv 2025
-
[5]
METEOR: An automatic metric for MT evaluation with improved correlation with human judgments
Satanjeev Banerjee and Alon Lavie. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. InProceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, pp. 65–72, 2005
2005
-
[6]
Suhana Bedi, Hejie Cui, Miguel Fuentes, Alyssa Unell, Michael Wornow, Juan M Banda, Nikesh Kotecha, Timothy Keyes, Yifan Mai, Mert Oez, et al. Medhelm: Holistic evaluation of large language models for medical tasks.arXiv preprint arXiv:2505.23802, 2025
arXiv 2025
-
[7]
Suhana Bedi, Hejie Cui, Miguel Fuentes, Alyssa Unell, Michael Wornow, et al. Holistic eval- uation of large language models for medical tasks with MedHELM.Nature Medicine, 32(3): 943–951, 2026. doi: 10.1038/s41591-025-04151-2. URLhttps://www.nature.com/ articles/s41591-025-04151-2
-
[8]
Suhana Bedi, Ryan Welch, Ethan Steinberg, Michael Wornow, Taeil Matthew Kim, Haroun Ahmed, Peter Sterling, Bravim Purohit, Qurat Akram, Angelic Acosta, et al. HealthAdmin- Bench: Evaluating computer-use agents on healthcare administration tasks.arXiv preprint arXiv:2604.09937, 2026
Pith/arXiv arXiv 2026
-
[9]
PANTHER challenge: Public training dataset, 2025
Amparo Soeli Betancourt Tarifa, Faisal Mahmood, Uffe Bernchou, and Peter Jan Koopmans. PANTHER challenge: Public training dataset, 2025. URLhttps://doi.org/10.5281/ zenodo.15192302
2025
-
[10]
PanTS: Pancreatic tumor segmentation.https://huggingface.co/ datasets/BodyMaps/PanTSMini, 2024
BodyMaps. PanTS: Pancreatic tumor segmentation.https://huggingface.co/ datasets/BodyMaps/PanTSMini, 2024
2024
-
[11]
End-to-end object detection with transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. InEuropean Conference on Computer Vision, pp. 213–229. Springer, 2020
2020
-
[12]
Pierre Chambon, Jean-Benoit Delbrouck, Thomas Sounack, Shih-Cheng Huang, Zhihong Chen, Maya Varma, Steven QH Truong, Chu The Chuong, and Curtis P. Langlotz. CheXpert Plus: Augmenting a large chest x-ray dataset with text radiology reports, patient demographics and additional image formats, 2024. URLhttps://arxiv.org/abs/2405.19538
arXiv 2024
-
[13]
MLE-bench: Evaluating machine learning agents on machine learning engineering,
Jun Shern Chan, Neil Chowdhury, Oliver Jaffe, James Aung, Dane Sherburn, Evan Mays, Giulio Starace, Kevin Liu, Leon Maksin, Tejal Patwardhan, Lilian Weng, and Aleksander Madry. MLE-bench: Evaluating machine learning agents on machine learning engineering,
-
[14]
URLhttps://arxiv.org/abs/2410.07095
-
[15]
IEEE Transactions on Medi- cal Imaging36(8), 1597–1606 (Aug 2017).https://doi.org/10.1109/TMI.2017
Hu Chen, Yi Zhang, Mannudeep K. Kalra, Feng Lin, Yang Chen, Peixi Liao, Jiliu Zhou, and Ge Wang. Low-dose CT with a residual encoder-decoder convolutional neural network. IEEE Transactions on Medical Imaging, 36(12):2524–2535, 2017. doi: 10.1109/TMI.2017. 2715284
-
[16]
Generating radiology reports via memory-driven transformer
Zhihong Chen, Yan Song, Tsung-Hui Chang, and Xiang Wan. Generating radiology reports via memory-driven transformer. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, pp. 1439–1449, 2020
2020
-
[17]
Dina Demner-Fushman, Marc D. Kohli, Marc B. Rosenman, Sonya E. Shooshan, Laritza Rodriguez, Sameer Antani, George R. Thoma, and Clement J. McDonald. Preparing a col- lection of radiology examinations for distribution and retrieval.Journal of the American Medical Informatics Association, 23(2):304–310, 2016. doi: 10.1093/jamia/ocv080. URL https://doi.org/1...
-
[18]
Lee R. Dice. Measures of the amount of ecologic association between species.Ecology, 26 (3):297–302, 1945. doi: 10.2307/1932409
-
[19]
Mark Everingham, Luc Van Gool, Christopher K. I. Williams, John Winn, and Andrew Zisser- man. The PASCAL visual object classes (VOC) challenge.International Journal of Computer Vision, 88(2):303–338, 2010. doi: 10.1007/s11263-009-0275-4
-
[20]
FeTA challenge: Fetal brain tissue annotation and segmentation.https: //fetachallenge.github.io/, 2021
FeTA Organizers. FeTA challenge: Fetal brain tissue annotation and segmentation.https: //fetachallenge.github.io/, 2021
2021
-
[21]
Yifan Gao, Haoyue Li, Feng Yuan, Xin Gao, Weiran Huang, and Xiaosong Wang. Camyla: Scaling autonomous research in medical image segmentation.arXiv preprint arXiv:2604.10696, 2026
Pith/arXiv arXiv 2026
-
[22]
GLM-5: From vibe coding to agentic engineering, 2026
GLM-5 Team. GLM-5: From vibe coding to agentic engineering, 2026. URLhttps:// arxiv.org/abs/2602.15763
Pith/arXiv arXiv 2026
-
[23]
Gemini 3.1 Pro model card.https://deepmind.google/ models/model-cards/gemini-3-1-pro/, February 2026
Google DeepMind. Gemini 3.1 Pro model card.https://deepmind.google/ models/model-cards/gemini-3-1-pro/, February 2026
2026
-
[24]
DENTEX: Dental enumeration and diagnosis on panoramic x-rays.https://huggingface.co/datasets/ibrahimhamamci/DENTEX, 2023
Ibrahim Ethem Hamamci et al. DENTEX: Dental enumeration and diagnosis on panoramic x-rays.https://huggingface.co/datasets/ibrahimhamamci/DENTEX, 2023
2023
-
[25]
Xuehai He, Yichen Zhang, Luntian Mou, Eric P. Xing, and Pengtao Xie. PathVQA: 30000+ questions for medical visual question answering, 2020. URLhttps://arxiv.org/abs/ 2003.10286
Pith/arXiv arXiv 2020
-
[26]
KiTS19: Kidney tumor segmentation challenge.https://kits19
Nicholas Heller et al. KiTS19: Kidney tumor segmentation challenge.https://kits19. grand-challenge.org/, 2019
2019
-
[27]
Rebecca Soskin Hicks, Mikhail Trofimov, Dominick Lim, Rahul K. Arora, Foivos Tsim- pourlas, Preston Bowman, Michael Sharman, Chi Tong, Kavin Karthik, Arnav Dugar, Akshay Jagadeesh, Khaled Saab, Johannes Heidecke, Ashley Alexander, Nate Gross, and Karan Sing- hal. Healthbench professional: Evaluating large language models on real clinician chats, 2026. URL...
Pith/arXiv arXiv 2026
-
[28]
MLAgentBench: Evaluating lan- guage agents on machine learning experimentation
Qian Huang, Jian V ora, Percy Liang, and Jure Leskovec. MLAgentBench: Evaluating lan- guage agents on machine learning experimentation. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pp. 20271–20309. PMLR, 2024. URLhttps://proceedings.mlr.press/v235/ huang24y.html
2024
-
[29]
Nat Methods18(2), 203–211 (Feb 2021)
Fabian Isensee, Paul F. Jaeger, Simon A. A. Kohl, Jens Petersen, and Klaus H. Maier-Hein. nnU-Net: A self-configuring method for deep learning-based biomedical image segmentation. Nature Methods, 18:203–211, 2021. doi: 10.1038/s41592-020-01008-z
-
[30]
RadGraph: Extracting clinical entities and relations from radiology reports.PhysioNet, 2021
Saahil Jain, Ashwin Agrawal, Adriel Saporta, Steven QH Truong, Du Nguyen Duong, Tan Bui, Pierre Chambon, Matthew Lungren, Andrew Ng, Curtis Langlotz, and Pranav Rajpurkar. RadGraph: Extracting clinical entities and relations from radiology reports.PhysioNet, 2021. doi: 10.13026/hm87-5p47. Version 1.0.0
-
[31]
Peter Jansen, Marc-Alexandre C ˆot´e, Tushar Khot, Erin Bransom, Bhavana Dalvi Mishra, Bodhisattwa Prasad Majumder, Oyvind Tafjord, and Peter Clark. DiscoveryWorld: A virtual environment for developing and evaluating automated scientific discovery agents. InAdvances in Neural Information Processing Systems, volume 37, 2024. doi: 10.52202/079017-0324. URLh...
-
[32]
Black, Gloria Geng, Danny Park, James Zou, Andrew Y
Yixing Jiang, Kameron C. Black, Gloria Geng, Danny Park, James Zou, Andrew Y . Ng, and Jonathan H. Chen. MedAgentBench: A realistic virtual EHR environment to benchmark med- ical LLM agents, 2025. URLhttps://arxiv.org/abs/2501.14654. 16
arXiv 2025
-
[33]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench: Can language models resolve real-world GitHub is- sues? InInternational Conference on Learning Representations, 2024. URLhttps: //openreview.net/forum?id=VTF8yNQM66
2024
-
[34]
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. What disease does this patient have? a large-scale open domain question answering dataset from medical exams.Applied Sciences, 11(14):6421, 2021. doi: 10.3390/app11146421. URL https://www.mdpi.com/2076-3417/11/14/6421
-
[35]
URLhttps://doi.org/10.18653/v1/D19-1259
Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William Cohen, and Xinghua Lu. PubMedQA: A dataset for biomedical research question answering. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Con- ference on Natural Language Processing, pp. 2567–2577, 2019. doi: 10.18653/v1/D19-1259. URLhttp...
-
[36]
Johnson et al
Alistair E.W. Johnson et al. MIMIC-CXR, a de-identified publicly available database of chest radiographs.https://physionet.org/content/mimic-cxr/, 2019
2019
-
[37]
BCCD: Blood cell count and detection dataset.https://huggingface
Kerem Berke. BCCD: Blood cell count and detection dataset.https://huggingface. co/datasets/keremberke/blood-cell-object-detection, 2018
2018
-
[38]
Scientific Data5, 180251 (2018)
Jason J. Lau, Soumya Gayen, Asma Ben Abacha, and Dina Demner-Fushman. A dataset of clinically generated visual questions and answers about radiology images.Scientific Data, 5:180251, 2018. doi: 10.1038/sdata.2018.251. URLhttps://www.nature.com/ articles/sdata2018251
-
[39]
Gyubok Lee, Elea Bach, Eric Yang, Tom Pollard, Alistair Johnson, Edward Choi, Jong Ha Lee, et al. FHIR-AgentBench: Benchmarking LLM agents for realistic interoperable EHR question answering.arXiv preprint arXiv:2509.19319, 2025
arXiv 2025
-
[40]
AgentEHR: Advancing autonomous clinical decision-making via retrospective summarization
Yusheng Liao, Chuan Xuan, Yutong Cai, Lina Yang, Zhe Chen, Yanfeng Wang, and Yu Wang. AgentEHR: Advancing autonomous clinical decision-making via retrospective summarization. arXiv preprint arXiv:2601.13918, 2026
arXiv 2026
-
[41]
ROUGE: A package for automatic evaluation of summaries
Chin-Yew Lin. ROUGE: A package for automatic evaluation of summaries. InText Summa- rization Branches Out, pp. 74–81, 2004
2004
-
[42]
Medical visual question answering: A survey.Artificial Intelligence in Medicine, 143:102611, 2023
Zhihong Lin, Donghao Zhang, Qingyi Tao, Danli Shi, Gholamreza Haffari, Qi Wu, Mingguang He, and Zongyuan Ge. Medical visual question answering: A survey.Artificial Intelligence in Medicine, 143:102611, 2023. doi: 10.1016/j.artmed.2023.102611
-
[43]
Geert Litjens, Thijs Kooi, Babak Ehteshami Bejnordi, Arnaud Arindra Adiyoso Setio, Francesco Ciompi, Mohsen Ghafoorian, Jeroen A. W. M. van der Laak, Bram van Ginneken, and Clara I. S ´anchez. A survey on deep learning in medical image analysis.Medical Image Analysis, 42:60–88, 2017. doi: 10.1016/j.media.2017.07.005
-
[44]
SLAKE: A semantically-labeled knowledge-enhanced dataset for medical visual question answering
Bo Liu, Li-Ming Zhan, Li Xu, Lin Ma, Yan Yang, and Xiao-Ming Wu. SLAKE: A semantically-labeled knowledge-enhanced dataset for medical visual question answering. In 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI), pp. 1650–1654,
2021
-
[45]
URLhttps://doi.org/10.1109/ ISBI48211.2021.9434010
doi: 10.1109/ISBI48211.2021.9434010. URLhttps://doi.org/10.1109/ ISBI48211.2021.9434010
-
[46]
Ruoqi Liu, Imran Q Mohiuddin, Austin J Schoeffler, Kavita Renduchintala, Ashwin Nayak, Prasantha L Vemu, Shivam C Vedak, Kameron C Black, John L Havlik, Isaac Ogunmola, et al. PhysicianBench: Evaluating LLM agents in real-world EHR environments.arXiv preprint arXiv:2605.02240, 2026
Pith/arXiv arXiv 2026
-
[47]
Agentbench: Evaluating LLMs as agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. Agentbench: Evaluating LLMs as agents. InInternational Conference on Learning Representatio...
2024
-
[48]
The AI scientist: Towards fully automated open-ended scientific discovery, 2024
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The AI scientist: Towards fully automated open-ended scientific discovery, 2024. URLhttps: //arxiv.org/abs/2408.06292
Pith/arXiv arXiv 2024
-
[49]
Agentboard: An analytical evaluation board of multi-turn LLM agents, 2024
Chang Ma, Junlei Zhang, Zhihao Zhu, Cheng Yang, Yujiu Yang, Yaohui Jin, Zhenzhong Lan, Lingpeng Kong, and Junxian He. Agentboard: An analytical evaluation board of multi-turn LLM agents, 2024. URLhttps://arxiv.org/abs/2401.13178
arXiv 2024
-
[50]
Mike A. Merrill, Alexander G. Shaw, Nicholas Carlini, Boxuan Li, et al. Terminal-Bench: Benchmarking agents on hard, realistic tasks in command line interfaces, 2026. URLhttps: //arxiv.org/abs/2601.11868
Pith/arXiv arXiv 2026
-
[51]
GAIA: a benchmark for general AI assistants
Gr ´egoire Mialon, Cl´ementine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom. GAIA: a benchmark for general AI assistants. InInternational Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id= fibxvahvs3
2024
-
[52]
The MiniMax-M2 series: Mini activations unleashing max real-world intelligence,
MiniMax. The MiniMax-M2 series: Mini activations unleashing max real-world intelligence,
-
[53]
URLhttps://arxiv.org/abs/2605.26494
-
[54]
Eszter Nagy et al. GRAZPEDWRI-DX: A pediatric wrist radiograph dataset.https:// figshare.com/articles/dataset/GRAZPEDWRI-DX/14825193, 2022
arXiv 2022
-
[55]
MLGym: A new framework and benchmark for advancing AI research agents
Deepak Nathani, Lovish Madaan, Nicholas Roberts, Nikolay Bashlykov, Ajay Menon, Vincent Moens, Mikhail Plekhanov, Amar Budhiraja, Despoina Magka, Vladislav V orotilov, Gaurav Chaurasia, Dieuwke Hupkes, Ricardo Silveira Cabral, Tatiana Shavrina, Jakob Nicolaus Foer- ster, Yoram Bachrach, William Yang Wang, and Roberta Raileanu. MLGym: A new framework and b...
2025
-
[56]
Nguyen et al
Ha Q. Nguyen et al. VinDr-CXR: An open dataset of chest x-rays with radiologist’s annota- tions.https://vindr.ai/datasets/vindr-cxr, 2022
2022
-
[57]
GPT-5.4 Thinking system card.https://deploymentsafety.openai
OpenAI. GPT-5.4 Thinking system card.https://deploymentsafety.openai. com/gpt-5-4-thinking/gpt-5-4-thinking.pdf, March 2026
2026
-
[58]
MedMCQA: A large- scale multi-subject multi-choice dataset for medical domain question answering
Ankit Pal, Logesh Kumar Umapathi, and Malaikannan Sankarasubbu. MedMCQA: A large- scale multi-subject multi-choice dataset for medical domain question answering. InProceed- ings of the Conference on Health, Inference, and Learning, volume 174 ofProceedings of Machine Learning Research, pp. 248–260. PMLR, 2022. URLhttps://proceedings. mlr.press/v174/pal22a.html
2022
-
[59]
Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics , year =
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. BLEU: A method for auto- matic evaluation of machine translation. InProceedings of the 40th Annual Meeting of the As- sociation for Computational Linguistics, pp. 311–318, 2002. doi: 10.3115/1073083.1073135
-
[60]
Qwen3.5: Towards native multimodal agents.https://qwen.ai/blog? id=qwen3.5, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents.https://qwen.ai/blog? id=qwen3.5, February 2026
2026
-
[61]
AeroPath: Airway segmentation dataset.https://github.com/ raidionics/AeroPath, 2023
Raidionics. AeroPath: Airway segmentation dataset.https://github.com/ raidionics/AeroPath, 2023
2023
-
[62]
You Only Look Once: Unified, Real -Time Object Detection[J].IEEE, 2016.DOI:10.1109/CVPR.2016.91
Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. You only look once: Uni- fied, real-time object detection. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 779–788, 2016. doi: 10.1109/CVPR.2016.91
-
[63]
Faster R-CNN: Towards real-time object detection with region proposal networks
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster R-CNN: Towards real-time object detection with region proposal networks. InAdvances in Neural Information Processing Systems, volume 28, pp. 91–99, 2015
2015
-
[64]
U-Net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-Net: Convolutional networks for biomedical image segmentation. InMedical Image Computing and Computer-Assisted Inter- vention, volume 9351 ofLecture Notes in Computer Science, pp. 234–241. Springer, 2015. 18
2015
-
[65]
Samuel Schmidgall, Rojin Ziaei, Carl Harris, Eduardo Reis, Jeffrey Jopling, and Michael Moor. Agentclinic: a multimodal agent benchmark to evaluate ai in simulated clinical en- vironments.arXiv preprint arXiv:2405.07960, 2024
Pith/arXiv arXiv 2024
-
[66]
Ehragent: Code empowers large language models for few-shot complex tabular reasoning on electronic health records
Wenqi Shi, Ran Xu, Yuchen Zhuang, Yue Yu, Jieyu Zhang, Hang Wu, Yuanda Zhu, Joyce C Ho, Carl Yang, and May Dongmei Wang. Ehragent: Code empowers large language models for few-shot complex tabular reasoning on electronic health records. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 22315–22339, 2024
2024
-
[67]
Siegel, Sayash Kapoor, Nitya Nadgir, Benedikt Stroebl, and Arvind Narayanan
Zachary S. Siegel, Sayash Kapoor, Nitya Nadgir, Benedikt Stroebl, and Arvind Narayanan. CORE-Bench: Fostering the credibility of published research through a computational re- producibility agent benchmark.Transactions on Machine Learning Research, 2025. URL https://openreview.net/forum?id=BsMMc4MEGS
2025
-
[68]
Large language models encode clinical knowledge.Nature, 620:172–180, 2023
Karan Singhal, Shekoofeh Azizi Tu, Julia Gottweis, Rory Sayres, Ellery Wulczyn, Le Hou, Peter Schuh, Karan Sareen, David Winer, Denny Wilson, et al. Large language models encode clinical knowledge.Nature, 620:172–180, 2023. doi: 10.1038/s41586-023-06291-2. URL https://www.nature.com/articles/s41586-023-06291-2
-
[69]
PaperBench: Evaluating AI’s ability to replicate AI research,
Giulio Starace, Oliver Jaffe, Dane Sherburn, James Aung, Jun Shern Chan, Leon Maksin, Rachel Dias, Evan Mays, Benjamin Kinsella, Wyatt Thompson, Johannes Heidecke, Amelia Glaese, and Tejal Patwardhan. PaperBench: Evaluating AI’s ability to replicate AI research,
-
[70]
URLhttps://arxiv.org/abs/2504.01848
-
[71]
Yuxuan Sun, Chenglu Zhu, Sunyi Zheng, Kai Zhang, Lin Sun, Zhongyi Shui, Yunlong Zhang, Honglin Li, and Lin Yang. PathAsst: A generative foundation AI assistant towards artificial general intelligence of pathology, 2023. URLhttps://arxiv.org/abs/2305.15072
arXiv 2023
-
[72]
MedXpertQA-MM: Multimodal expert medical question answering.https: //huggingface.co/datasets/TsinghuaC3I/MedXpertQA, 2024
TsinghuaC3I. MedXpertQA-MM: Multimodal expert medical question answering.https: //huggingface.co/datasets/TsinghuaC3I/MedXpertQA, 2024
2024
-
[73]
Image quality assessment: from error visibility to structural similarity
Zhou Wang, Alan C. Bovik, Hamid R. Sheikh, and Eero P. Simoncelli. Image quality assess- ment: From error visibility to structural similarity.IEEE Transactions on Image Processing, 13(4):600–612, 2004. doi: 10.1109/TIP.2003.819861
-
[74]
TotalSegmentator: Robust segmentation of 104 anatomical structures in CT.https://github.com/wasserth/TotalSegmentator, 2023
Jakob Wasserthal et al. TotalSegmentator: Robust segmentation of 104 anatomical structures in CT.https://github.com/wasserth/TotalSegmentator, 2023
2023
-
[75]
OSWorld: Benchmark- ing multimodal agents for open-ended tasks in real computer environments, 2024
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu. OSWorld: Benchmark- ing multimodal agents for open-ended tasks in real computer environments, 2024. URL https://arxiv.org/abs/...
Pith/arXiv arXiv 2024
-
[76]
Jiancheng Yang, Rui Shi, Donglai Wei, Zequan Liu, Lin Zhao, Bilian Ke, Hanspeter Pfister, and Bingbing Ni. MedMNIST v2: A large-scale lightweight benchmark for 2d and 3d biomedical image classification.Scientific Data, 10:41, 2023. doi: 10.1038/s41597-022-01721-8. URL https://www.nature.com/articles/s41597-022-01721-8
-
[77]
Assistantbench: Can web agents solve realistic and time-consuming tasks?, 2024
Ori Yoran, Samuel Joseph Amouyal, Chaitanya Malaviya, Ben Bogin, Ofir Press, and Jonathan Berant. Assistantbench: Can web agents solve realistic and time-consuming tasks?, 2024. URL https://arxiv.org/abs/2407.15711
arXiv 2024
-
[78]
MedFrameQA: A multi-image medical VQA benchmark for clinical reasoning, 2025
Suhao Yu, Haojin Wang, Juncheng Wu, Luyang Luo, Jingshen Wang, Cihang Xie, Pranav Rajpurkar, Carl Yang, Yang Yang, Kang Wang, Yannan Yu, and Yuyin Zhou. MedFrameQA: A multi-image medical VQA benchmark for clinical reasoning, 2025. URLhttps://arxiv. org/abs/2505.16964
arXiv 2025
-
[79]
Muckley, Mary Bruno, Aaron De- fazio, Marc Parente, Krzysztof J
Jure Zbontar, Florian Knoll, Anuroop Sriram, Matthew J. Muckley, Mary Bruno, Aaron De- fazio, Marc Parente, Krzysztof J. Geras, Joe Katsnelson, Hersh Chandarana, Zizhao Zhang, Michal Drozdzal, Adriana Romero, Michael Rabbat, Pascal Vincent, James Pinkerton, Duo Wang, Nafissa Yakubova, Erich Owens, C. Lawrence Zitnick, Michael P. Recht, Daniel K. 19 Sodick...
Pith/arXiv arXiv 2018
-
[80]
open-source
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. WebArena: A realis- tic web environment for building autonomous agents. InInternational Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=oKn9c6ytLx. 20 APPENDIXCONTENT...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.