SentGuard: Sentence-Level Streaming Guardrails for Large Language Models
Pith reviewed 2026-06-28 14:49 UTC · model grok-4.3
The pith
Sentence-level guardrails detect unsafe LLM output within two sentences during streaming generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
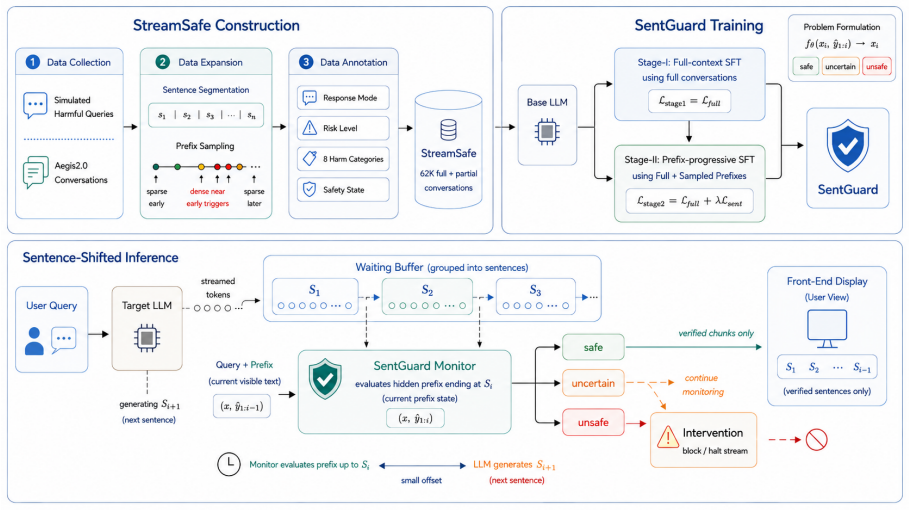
SentGuard runs in parallel with the target LLM by holding streamed tokens in a waiting buffer until sentence boundaries form, then assesses the current prefix for safety while the model decodes ahead, releasing only verified sentence chunks to the user.
What carries the argument
A lightweight waiting buffer that groups streamed tokens into sentence chunks for safety assessment at boundaries, combined with coarse-to-fine training to spot unsafe intent as soon as it appears.
If this is right
- Moderation decisions can occur after one or two sentences rather than after thousands of tokens.
- The same buffer mechanism keeps the user from seeing any unverified content.
- Per-sentence annotations make it possible to track how safety risks evolve across reasoning steps and final answers.
- The coarse-to-fine objective trains the guardrail to act at the earliest safe sentence boundary.
Where Pith is reading between the lines
- The approach could be tested with other natural chunk boundaries such as paragraphs or code blocks if sentences prove insufficient in some domains.
- StreamSafe-style annotations might help measure whether early detection reduces overall user exposure to harmful content in longer conversations.
- The parallel buffer design suggests a general pattern for any streaming task that needs partial verification before output is shown.
Load-bearing premise
That sentence boundaries supply enough context to judge emerging harm reliably without missing important signals inside sentences or adding too much delay.
What would settle it
A test set where a large share of harmful intent first appears inside a sentence rather than at its end, or where sentence-boundary checks produce substantially higher false-positive rates on safe but complex reasoning text.
Figures


read the original abstract
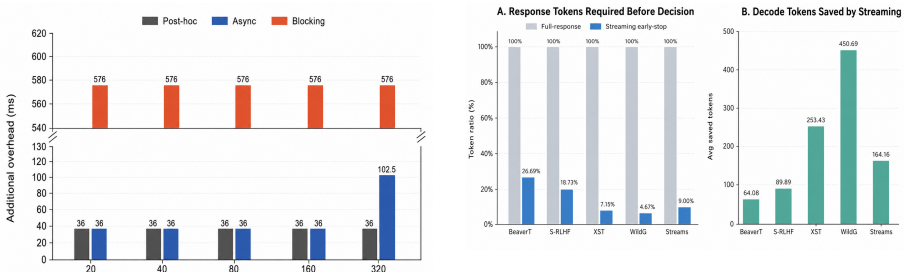
Large language models increasingly stream long, reasoning-intensive responses in real time, making when to moderate as critical as whether to moderate. Existing guardrails fall into two unsatisfactory extremes: response-level methods delay intervention until the full output is generated, whereas token-level methods act on incomplete semantics, often producing unstable decisions and excessive guard invocations. To address this challenge, we propose SentGuard, a sentence-level streaming guardrail that operates in parallel with generation. A lightweight waiting buffer groups streamed tokens into sentence chunks and releases only verified chunks to the user, introducing a small offset that enables SentGuard to assess the current prefix while the target LLM decodes subsequent content. To support this, we construct StreamSafe, a benchmark with structured per-sentence annotations across 8 harm categories, capturing the evolution of safety risks across both reasoning and response segments. We further train SentGuard with a coarse-to-fine objective to detect unsafe intent as soon as it emerges at sentence boundaries. Experiments on 5 safety benchmarks show that SentGuard outperforms existing baselines, detecting 90.5% of unsafe cases within two sentences while maintaining a low streaming false-positive rate of 7.41%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SentGuard, a sentence-level streaming guardrail for LLMs that uses a lightweight waiting buffer to group streamed tokens into sentence chunks, enabling safety assessment of the current prefix while generation continues. It constructs the StreamSafe benchmark with structured per-sentence annotations across 8 harm categories for both reasoning and response segments. The central empirical claim is that SentGuard, trained with a coarse-to-fine objective, outperforms baselines by detecting 90.5% of unsafe cases within two sentences at a streaming false-positive rate of 7.41% across 5 safety benchmarks.
Significance. If the results hold, the work offers a practical middle ground between delayed full-response moderation and unstable token-level decisions for real-time LLM outputs. The StreamSafe benchmark, with its per-sentence labels, represents a useful contribution for evaluating streaming safety risks.
minor comments (2)
- [Abstract] The abstract introduces the 'coarse-to-fine objective' without elaboration; a brief definition or reference to its formulation in the methods section would improve clarity for readers.
- [Abstract] The claim of outperformance on 5 benchmarks would be strengthened by explicitly naming the baselines and directing readers to the corresponding table or figure in the experiments section.
Simulated Author's Rebuttal
We thank the referee for their positive summary of SentGuard and the StreamSafe benchmark, as well as the recommendation for minor revision. No major comments were provided in the report.
Circularity Check
No significant circularity
full rationale
The paper presents an empirical engineering contribution: a sentence-buffered streaming guardrail design, a new benchmark (StreamSafe) with per-sentence safety labels, a coarse-to-fine training objective, and concrete detection/false-positive metrics on five external safety benchmarks. No mathematical derivation chain, first-principles prediction, or fitted parameter is claimed; the central results are experimental measurements rather than quantities that reduce by construction to the method's own inputs or to self-citations. The provided abstract and skeptic summary contain no load-bearing self-referential steps matching any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
ShieldHead: Decoding-time Safeguard for Large Language Models , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[2]
2025 , eprint=
From Judgment to Interference: Early Stopping LLM Harmful Outputs via Streaming Content Monitoring , author=. 2025 , eprint=
2025
-
[3]
Proceedings of the AAAI Conference on Artificial Intelligence , year=
Swift: a scalable lightweight infrastructure for fine-tuning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , year=
-
[4]
Advances in Neural Information Processing Systems , volume=
Beavertails: Towards improved safety alignment of llm via a human-preference dataset , author=. Advances in Neural Information Processing Systems , volume=
-
[5]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Pku-saferlhf: Towards multi-level safety alignment for llms with human preference , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[6]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Xstest: A test suite for identifying exaggerated safety behaviours in large language models , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[7]
Advances in neural information processing systems , volume=
Wildguard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of llms , author=. Advances in neural information processing systems , volume=
-
[8]
Qwen3guard technical report , author=. arXiv preprint arXiv:2510.14276 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
arXiv preprint arXiv:2601.15588 , year=
YuFeng-XGuard: A Reasoning-Centric, Interpretable, and Flexible Guardrail Model for Large Language Models , author=. arXiv preprint arXiv:2601.15588 , year=
-
[11]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Update to GPT-5 System Card: GPT-5.2 , author=
-
[13]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
arXiv preprint arXiv:2601.11659 , year=
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes , author=. arXiv preprint arXiv:2601.11659 , year=
-
[15]
0: A diverse ai safety dataset and risks taxonomy for alignment of llm guardrails , author=
Aegis2. 0: A diverse ai safety dataset and risks taxonomy for alignment of llm guardrails , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[16]
Red Teaming Language Models with Language Models
Red teaming language models with language models , author=. arXiv preprint arXiv:2202.03286 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Jailbreaking ChatGPT via Prompt Engineering: An Empirical Study
Jailbreaking ChatGPT via Prompt Engineering: An Empirical Study , author=. arXiv preprint arXiv:2305.13860 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
arXiv preprint arXiv:2310.11986 , year=
Sociotechnical safety evaluation of generative ai systems , author=. arXiv preprint arXiv:2310.11986 , year=
-
[19]
arXiv preprint arXiv:2408.15221 , year=
LLM Defenses Are Not Robust to Multi-Turn Human Jailbreaks Yet , author=. arXiv preprint arXiv:2408.15221 , year=
-
[20]
2024 , url=
Pliny the Prompter , title=. 2024 , url=
2024
-
[21]
Constitutional AI: Harmlessness from AI Feedback
Constitutional ai: Harmlessness from ai feedback , author=. arXiv preprint arXiv:2212.08073 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned
Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned , author=. arXiv preprint arXiv:2209.07858 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
arXiv preprint arXiv:2501.00055 , year=
Llm-virus: Evolutionary jailbreak attack on large language models , author=. arXiv preprint arXiv:2501.00055 , year=
-
[24]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Harmbench: A standardized evaluation framework for automated red teaming and robust refusal , author=. arXiv preprint arXiv:2402.04249 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
ACL , year=
Word-level textual adversarial attacking as combinatorial optimization , author=. ACL , year=
-
[26]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Universal and transferable adversarial attacks on aligned language models , author=. arXiv preprint arXiv:2307.15043 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
IEEE SaTML , year=
Jailbreaking black box large language models in twenty queries , author=. IEEE SaTML , year=
-
[28]
Tree of at- tacks: Jailbreaking black-box LLMs automati- cally.NeurIPS, 2024
Tree of Attacks: Jailbreaking Black-Box LLMs Automatically , author=. arXiv preprint arXiv:2312.02119 , year=
-
[29]
arXiv preprint arXiv:2407.16667 , year=
Redagent: Red teaming large language models with context-aware autonomous language agent , author=. arXiv preprint arXiv:2407.16667 , year=
-
[30]
arXiv preprint arXiv:2503.15754 , year=
Autoredteamer: Autonomous red teaming with lifelong attack integration , author=. arXiv preprint arXiv:2503.15754 , year=
-
[31]
ICLR , year=
Autodan-turbo: A lifelong agent for strategy self-exploration to jailbreak llms , author=. ICLR , year=
-
[32]
AAAI , year=
Codeattack: Code-based adversarial attacks for pre-trained programming language models , author=. AAAI , year=
-
[33]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages=
2019
-
[34]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Roberta: A robustly optimized bert pretraining approach , author=. arXiv preprint arXiv:1907.11692 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[35]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Llama guard: Llm-based input-output safeguard for human-ai conversations , author=. arXiv preprint arXiv:2312.06674 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
arXiv preprint arXiv:2411.10414 , year=
Llama guard 3 vision: Safeguarding human-ai image understanding conversations , author=. arXiv preprint arXiv:2411.10414 , year=
-
[37]
ShieldGemma: Generative AI Content Moderation Based on Gemma
Shieldgemma: Generative ai content moderation based on gemma , author=. arXiv preprint arXiv:2407.21772 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Advances in Neural Information Processing Systems , volume=
From judgment to interference: Early stopping llm harmful outputs via streaming content monitoring , author=. Advances in Neural Information Processing Systems , volume=
-
[39]
Disentangled Safety Adapters Enable Efficient Guardrails and Flexible Inference-Time Alignment
Disentangled Safety Adapters Enable Efficient Guardrails and Flexible Inference-Time Alignment , author=. arXiv preprint arXiv:2506.00166 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
GPTFUZZER: Red Teaming Large Language Models with Auto-Generated Jailbreak Prompts
GPTFUZZER: Red teaming large language models with auto-generated jailbreak prompts , author=. arXiv preprint arXiv:2309.10253 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
arXiv preprint arXiv:2601.01592 , year=
Openrt: An open-source red teaming framework for multimodal llms , author=. arXiv preprint arXiv:2601.01592 , year=
-
[42]
arXiv preprint arXiv:2510.05025 , year=
Imperceptible jailbreaking against large language models , author=. arXiv preprint arXiv:2510.05025 , year=
-
[43]
arXiv preprint arXiv:2509.19870 , year=
Freezevla: Action-freezing attacks against vision-language-action models , author=. arXiv preprint arXiv:2509.19870 , year=
-
[44]
Evolve the Method, Not the Prompts: Evolutionary Synthesis of Jailbreak Attacks on LLMs
Evolve the method, not the prompts: Evolutionary synthesis of jailbreak attacks on llms , author=. arXiv preprint arXiv:2511.12710 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
OPT: Open Pre-trained Transformer Language Models
Opt: Open pre-trained transformer language models , author=. arXiv preprint arXiv:2205.01068 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
Forty-first International Conference on Machine Learning , year=
Executable code actions elicit better llm agents , author=. Forty-first International Conference on Machine Learning , year=
-
[47]
Advances in neural information processing systems , volume=
Large language models are zero-shot reasoners , author=. Advances in neural information processing systems , volume=
-
[48]
arXiv preprint arXiv:2503.24047 , year=
Towards scientific intelligence: A survey of llm-based scientific agents , author=. arXiv preprint arXiv:2503.24047 , year=
-
[49]
Your Agent, Their Asset: A Real-World Safety Analysis of OpenClaw
Your agent, their asset: A real-world safety analysis of openclaw , author=. arXiv preprint arXiv:2604.04759 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
arXiv preprint arXiv:2510.09694 , year=
Kelp: A Streaming Safeguard for Large Models via Latent Dynamics-Guided Risk Detection , author=. arXiv preprint arXiv:2510.09694 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.