FocusDiT: Masking Queries in Diffusion Transformers for Fine-grained Image Generation
Pith reviewed 2026-06-28 15:23 UTC · model grok-4.3
The pith
Masking non-critical query tokens lets diffusion transformers allocate FFN decoding capacity to complex visual details.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
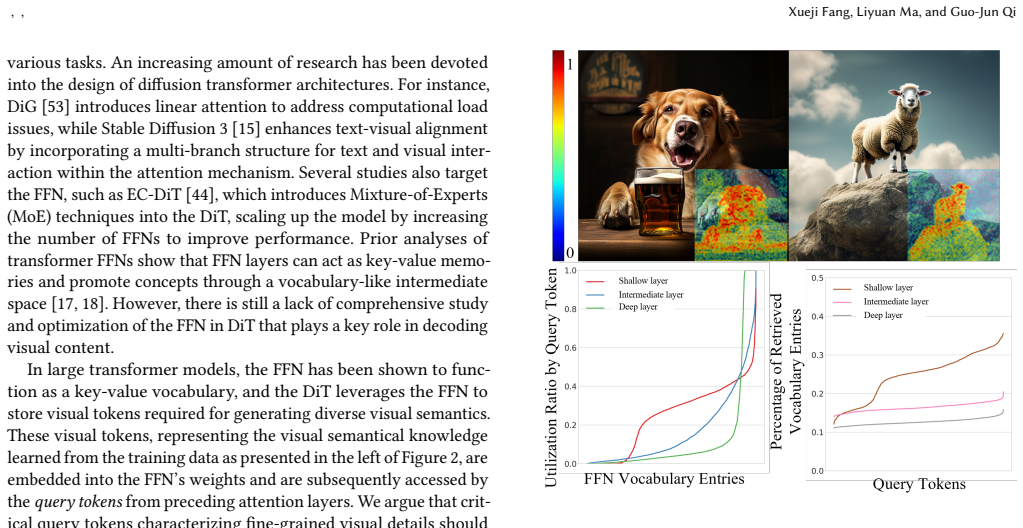
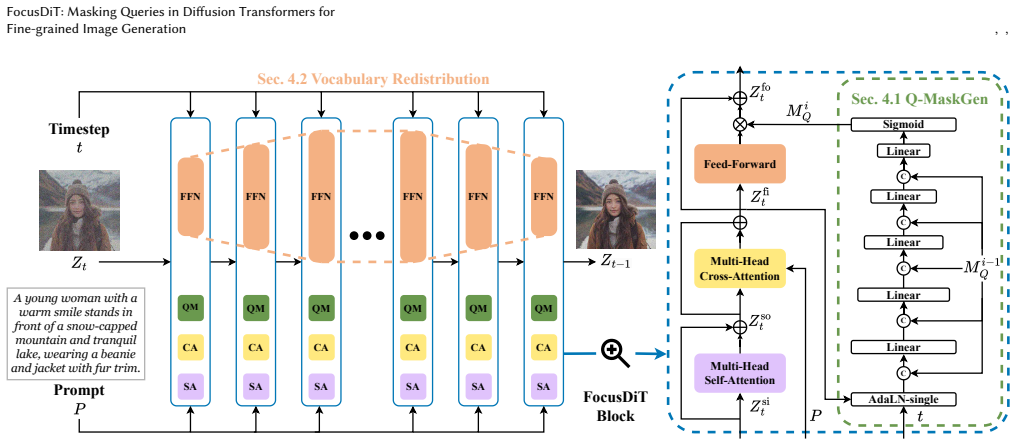
FocusDiT introduces a masking scheme that prevents non-critical query tokens from entering the FFN layers while allowing the remaining critical queries to receive full FFN processing. The masked queries retrieve visual tokens directly from the FFN vocabularies to decode their details. This mechanism concentrates the model's visual decoding resources on tokens that represent more complex image content, producing finer-grained results in text-to-image tasks.
What carries the argument
A query token masking scheme that restricts FFN input to critical tokens only, so that masked queries retrieve decoded visual content from the FFN vocabularies.
If this is right
- Critical query tokens receive higher-fidelity visual decoding from the FFN vocabulary.
- Masked queries can still recover their visual details by retrieval from the same vocabulary.
- The overall denoising process in diffusion transformers yields improved fine-grained outputs on text-to-image tasks.
- No architectural changes beyond the masking step are required to obtain the reported gains.
Where Pith is reading between the lines
- The same masking logic could be tested on video or 3D diffusion models where temporal or spatial complexity varies across tokens.
- If the FFN truly acts as a shared visual vocabulary, similar masking might reduce compute on simpler regions while preserving quality.
- One could measure whether the masking alters the distribution of attention weights among the unmasked tokens.
Load-bearing premise
That selectively preventing non-critical query tokens from entering the FFN will cause the remaining tokens to receive higher-quality visual decoding without introducing new artifacts or training instability.
What would settle it
Running the same text-to-image benchmarks with and without the masking scheme and finding no consistent gain in fine-detail metrics such as object boundary sharpness or texture fidelity.
Figures

read the original abstract
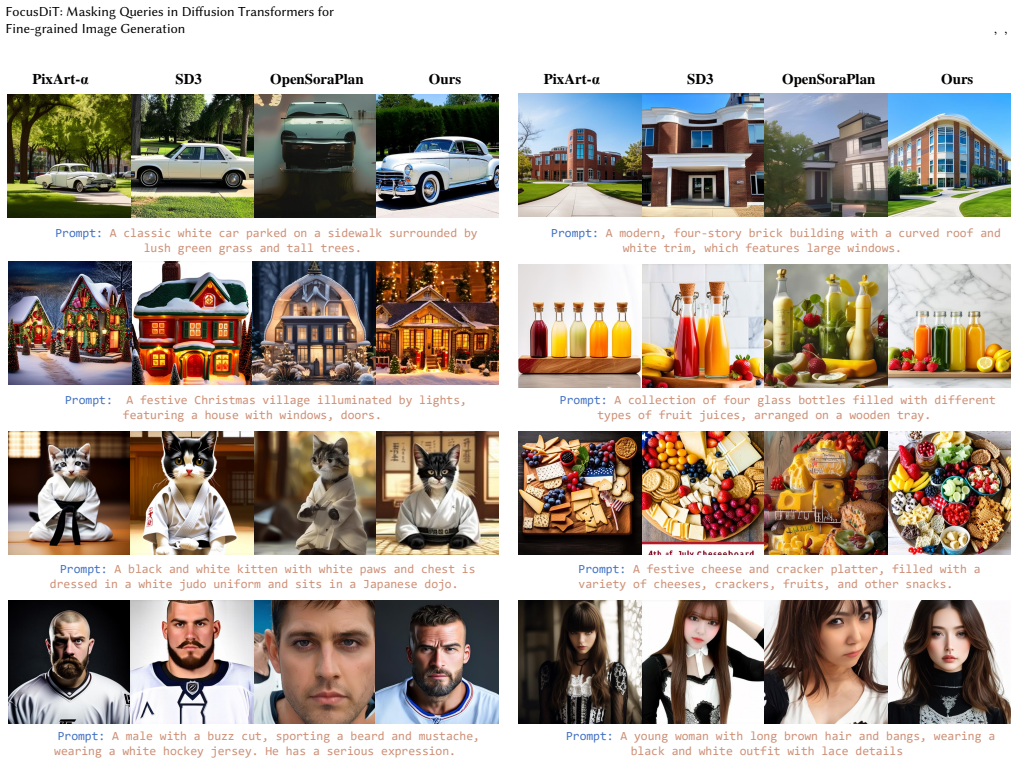
Diffusion transformer (DiT) has been widely adopted in the generative diffusion field, advancing the denoising of query tokens through attention and Feed-Forward (\text{FFN}) layers. FFN actually acts as the key-value vocabulary for decoding visual contents where the value embeds the visual semantical knowledge. We present that focusing on critical query tokens corresponding to more complex details and encouraging the model to improve these tokens is essential for fine-grained visual generation. To this end, we propose FocusDiT, which applies a Masking scheme to focus on critical query tokens that are exclusively fed into FFN. The masked queries can retrieve visual tokens from the FFN vocabularies, and use them to decode their visual details. Extensive text-to-image experiments validate the effectiveness of token masking in enhancing generative performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FocusDiT, a modification to Diffusion Transformers (DiT) that introduces a masking scheme on query tokens. Only critical query tokens (those corresponding to complex visual details) are fed into the FFN layers, which the authors interpret as key-value vocabularies for decoding visual semantics; masked queries retrieve visual tokens from these vocabularies to improve detail reconstruction. The central claim is that this selective focusing is essential for fine-grained text-to-image generation and is validated through extensive experiments.
Significance. If empirically substantiated, the method offers a lightweight, training-compatible intervention that prioritizes computational resources on high-complexity tokens without altering the core DiT architecture. This could be a practical contribution to improving local detail fidelity in diffusion-based generators, particularly if the masking mechanism proves stable across scales and datasets.
major comments (2)
- [Abstract] Abstract: the assertion that 'extensive text-to-image experiments validate the effectiveness of token masking' is unsupported by any reported metrics, ablation tables, baseline comparisons, or control descriptions. Without these data the central empirical claim cannot be evaluated for effect size, statistical significance, or robustness.
- The weakest assumption—that restricting FFN access to non-critical tokens will improve visual decoding quality without introducing artifacts or training instability—is stated but not accompanied by any diagnostic experiments (e.g., FID on masked vs. unmasked regions, stability curves, or failure-case analysis). This assumption is load-bearing for the practical utility of the method.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We will revise the manuscript to strengthen the empirical support for our claims as detailed below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'extensive text-to-image experiments validate the effectiveness of token masking' is unsupported by any reported metrics, ablation tables, baseline comparisons, or control descriptions. Without these data the central empirical claim cannot be evaluated for effect size, statistical significance, or robustness.
Authors: We accept this criticism. The current manuscript does not provide the requested quantitative details to support the abstract claim. In the revision we will add specific metrics (e.g., FID scores), ablation tables, baseline comparisons, and explicit control descriptions to the experimental section and update the abstract to reference them directly. revision: yes
-
Referee: The weakest assumption—that restricting FFN access to non-critical tokens will improve visual decoding quality without introducing artifacts or training instability—is stated but not accompanied by any diagnostic experiments (e.g., FID on masked vs. unmasked regions, stability curves, or failure-case analysis). This assumption is load-bearing for the practical utility of the method.
Authors: We agree that diagnostic evidence is needed. We will incorporate the suggested experiments in the revised manuscript, including FID comparisons between masked and unmasked regions, training stability curves, and failure-case analysis to confirm the absence of artifacts or instability. revision: yes
Circularity Check
No significant circularity
full rationale
The paper proposes FocusDiT as an empirical masking technique applied to query tokens in diffusion transformers, with the central claim that selectively feeding critical tokens into the FFN improves fine-grained generation. This is presented as an architectural modification validated by text-to-image experiments rather than any first-principles derivation, mathematical prediction, or fitted parameter renamed as output. No equations, self-citations as load-bearing premises, or reductions of results to inputs by construction appear in the abstract or described method. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al . 2025. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Li Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, Clarence Ng, Ricky Wang, and Aditya Ramesh. 2024. Video generation models as world simulators. (2024). https://openai.com/research/video-generation-models-as-world-simulators
2024
- [3]
- [4]
-
[5]
Junsong Chen, Jincheng Yu, Chongjian Ge, Lewei Yao, Enze Xie, Yue Wu, Zhong- dao Wang, James Kwok, Ping Luo, Huchuan Lu, et al. 2023. Pixart-𝛼: Fast training of diffusion transformer for photorealistic text-to-image synthesis.arXiv preprint arXiv:2310.00426(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Mengzhao Chen, Wenqi Shao, Peng Xu, Mingbao Lin, Kaipeng Zhang, Fei Chao, Rongrong Ji, Yu Qiao, and Ping Luo. 2023. Diffrate: Differentiable compression rate for efficient vision transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision. 17164–17174
2023
-
[7]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al . 2024. Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling.arXiv preprint arXiv:2412.05271(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Scaling Instruction-Finetuned Language Models
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Web- son, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dea...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2210.11416 2022
-
[9]
Florinel-Alin Croitoru, Vlad Hondru, Radu Tudor Ionescu, and Mubarak Shah
-
[10]
Diffusion models in vision: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence45, 9 (2023), 10850–10869
2023
-
[11]
Yutao Cui, Tianhui Song, Gangshan Wu, and Limin Wang. 2024. Mixformerv2: Efficient fully transformer tracking.Advances in Neural Information Processing Systems36 (2024)
2024
- [12]
- [13]
-
[14]
Caption Emporium. 2024. coyo-hd-11m-llavanext. https://huggingface.co/ datasets/CaptionEmporium/coyo-hd-11m-llavanext
2024
-
[15]
Caption Emporium. 2024. midjourney-niji-1m-llavanext. https://huggingface.co/ datasets/CaptionEmporium/conceptual-captions-cc12m-llavanext
2024
-
[16]
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. 2024. Scaling rectified flow transformers for high-resolution image synthesis. InForty- first International Conference on Machine Learning
2024
-
[17]
Zhengcong Fei, Mingyuan Fan, Changqian Yu, Debang Li, and Junshi Huang
- [18]
- [19]
-
[20]
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. 2020. Transformer feed-forward layers are key-value memories.arXiv preprint arXiv:2012.14913 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[21]
Dhruba Ghosh, Hannaneh Hajishirzi, and Ludwig Schmidt. 2024. Geneval: An object-focused framework for evaluating text-to-image alignment.Advances in Neural Information Processing Systems36 (2024)
2024
-
[22]
Kai Han, An Xiao, Enhua Wu, Jianyuan Guo, Chunjing Xu, and Yunhe Wang
-
[23]
Transformer in transformer.Advances in neural information processing systems34 (2021), 15908–15919
2021
-
[24]
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. 2017. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems30 (2017)
2017
-
[25]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models.Advances in neural information processing systems33 (2020), 6840–6851. FocusDiT: Masking Queries in Diffusion Transformers for Fine-grained Image Generation , ,
2020
-
[26]
Zhengbao Jiang, Frank F Xu, Jun Araki, and Graham Neubig. 2020. How can we know what language models know?Transactions of the Association for Computa- tional Linguistics8 (2020), 423–438
2020
-
[27]
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. 2022. Elucidating the design space of diffusion-based generative models.Advances in neural information processing systems35 (2022), 26565–26577
2022
-
[28]
2024.Open-Sora-Plan
PKU-Yuan Lab and Tuzhan AI etc. 2024.Open-Sora-Plan. https://doi.org/10.5281/ zenodo.10948109
2024
-
[29]
2024.FLUX.1-dev Model Documentation
Black Forest Labs. 2024.FLUX.1-dev Model Documentation. https://huggingface. co/black-forest-labs/FLUX.1-dev Accessed: 2024-11-09
2024
-
[30]
2024.FLUX.1-schnell Model Documentation
Black Forest Labs. 2024.FLUX.1-schnell Model Documentation. https:// huggingface.co/black-forest-labs/FLUX.1-schnell Accessed: 2024-11-09
2024
-
[31]
Daiqing Li, Ales Kamko, Ehsan Akhgari, Ali Sabet, Linmiao Xu, and Suhail Doshi
-
[32]
Playground v2.5: Three Insights towards Enhancing Aesthetic Quality in Text-to-Image Generation.arXiv preprint arXiv:2402.17245(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le
-
[34]
Flow matching for generative modeling.arXiv preprint arXiv:2210.02747 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[35]
I Loshchilov. 2017. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[36]
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. 2022. Locating and editing factual associations in GPT.Advances in Neural Information Processing Systems35 (2022), 17359–17372
2022
-
[37]
Alexander Quinn Nichol and Prafulla Dhariwal. 2021. Improved denoising diffu- sion probabilistic models. InInternational conference on machine learning. PMLR, 8162–8171
2021
-
[38]
Pavlov, A
I. Pavlov, A. Ivanov, and S. Stafievskiy. 2023. Text-to-Image Benchmark: A benchmark for generative models. https://github.com/boomb0om/text2image- benchmark. Version 0.1.0
2023
-
[39]
William Peebles and Saining Xie. 2023. Scalable diffusion models with transform- ers. InProceedings of the IEEE/CVF International Conference on Computer Vision. 4195–4205
2023
-
[40]
Jonathan Pilault, Mahan Fathi, Orhan Firat, Chris Pal, Pierre-Luc Bacon, and Ross Goroshin. 2024. Block-state transformers.Advances in Neural Information Processing Systems36 (2024)
2024
-
[41]
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. 2023. Sdxl: Improving latent diffusion models for high-resolution image synthesis.arXiv preprint arXiv:2307.01952 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. InInternational conference on machine learning. PMLR, 8748–8763
2021
-
[43]
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen
-
[44]
Hierarchical text-conditional image generation with clip latents.arXiv preprint arXiv:2204.061251, 2 (2022), 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[45]
Yongming Rao, Wenliang Zhao, Benlin Liu, Jiwen Lu, Jie Zhou, and Cho-Jui Hsieh
-
[46]
Advances in neural information processing systems34 (2021), 13937–13949
Dynamicvit: Efficient vision transformers with dynamic token sparsification. Advances in neural information processing systems34 (2021), 13937–13949
2021
-
[47]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-Resolution Image Synthesis With Latent Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 10684–10695
2022
-
[48]
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. 2015. U-net: Convolu- tional networks for biomedical image segmentation. InMedical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18. Springer, 234–241
2015
-
[49]
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. 2022. Laion-5b: An open large-scale dataset for training next generation image-text models.Advances in Neural Information Processing Systems 35 (2022), 25278–25294
2022
-
[50]
Jiaming Song, Chenlin Meng, and Stefano Ermon. 2020. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
- [51]
-
[52]
Genmo Team. 2024. Mochi 1. https://github.com/genmoai/models
2024
-
[53]
A Vaswani. 2017. Attention is all you need.Advances in Neural Information Processing Systems(2017)
2017
- [54]
-
[55]
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. 2024. Imagereward: Learning and evaluating human prefer- ences for text-to-image generation.Advances in Neural Information Processing Systems36 (2024)
2024
-
[56]
Yunzhi Yao, Shaohan Huang, Li Dong, Furu Wei, Huajun Chen, and Ningyu Zhang. 2022. Kformer: Knowledge injection in transformer feed-forward layers. InCCF International Conference on Natural Language Processing and Chinese Computing. Springer, 131–143
2022
- [57]
-
[58]
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. 2023. Adding conditional con- trol to text-to-image diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision. 3836–3847
2023
- [59]
- [60]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.