Multilingual Idioms in Sentences and Conversations Across High-, Medium-, and Low-Resource Languages
Pith reviewed 2026-06-28 14:35 UTC · model grok-4.3
The pith
State-of-the-art models understand idioms less accurately in low-resource languages, and literal readings are harder than figurative ones in every language tier tested.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
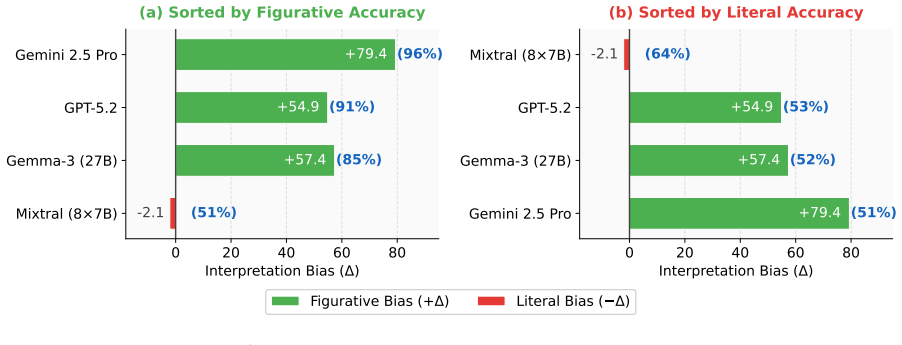
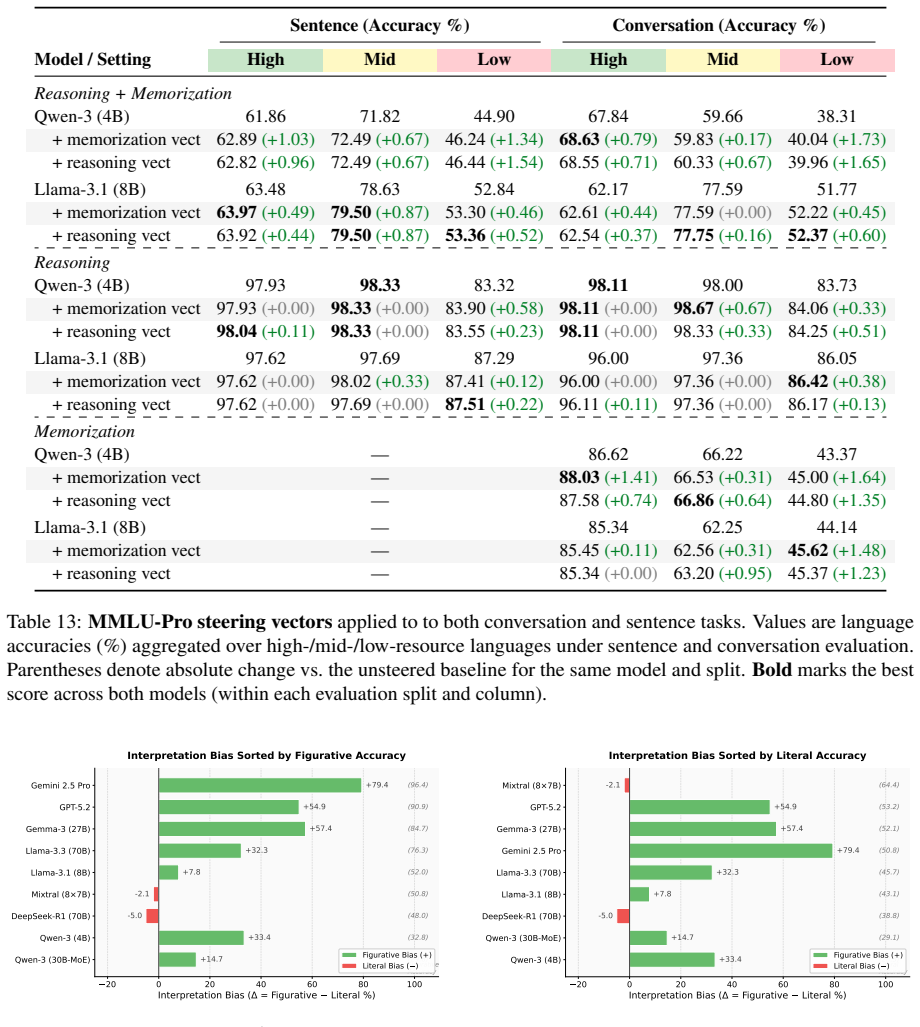
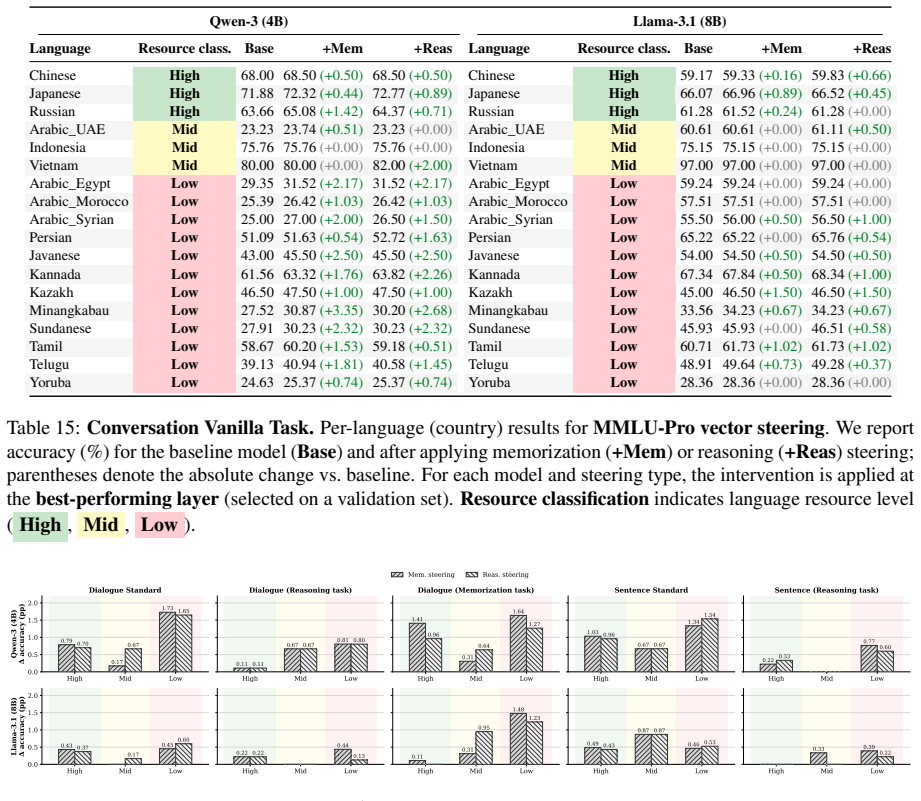
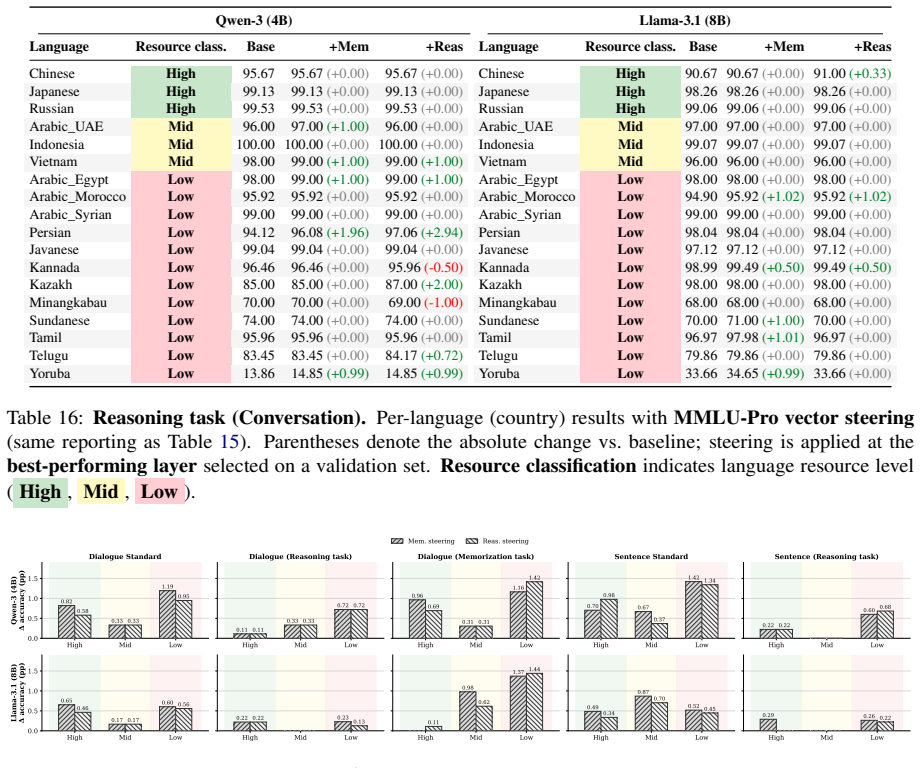
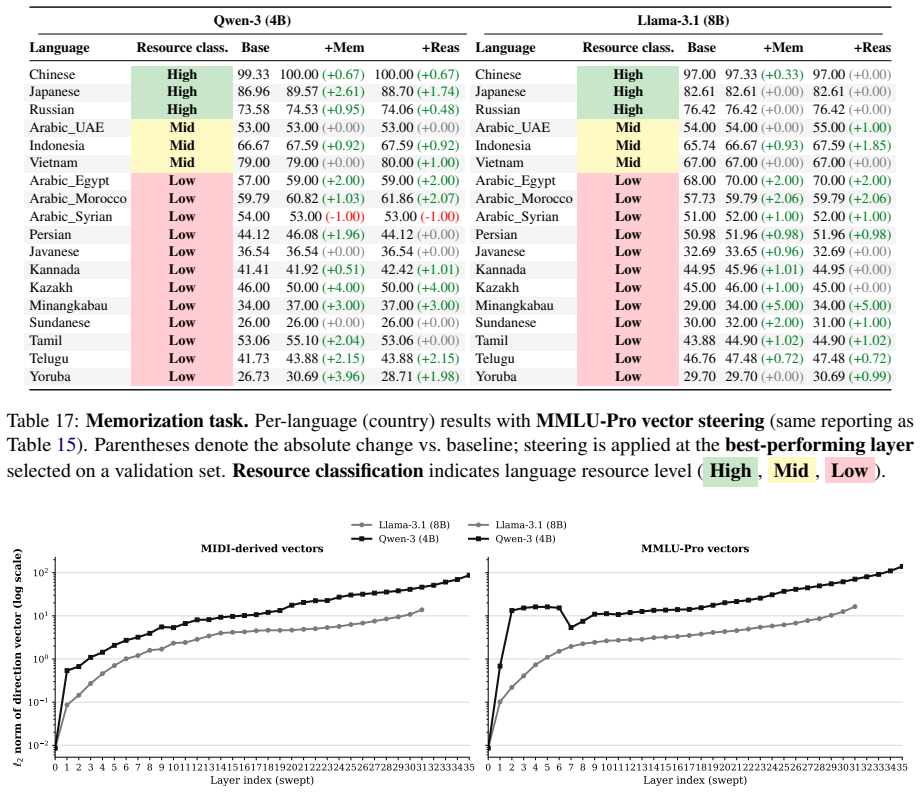
The central discovery is that idiom comprehension in multilingual models degrades in low-resource languages, literal interpretations are substantially harder than figurative ones across all tiers, and conversational context improves results without eliminating the disparities, as shown through benchmarking on the MIDI dataset of native-curated examples in sentence and conversational settings.
What carries the argument
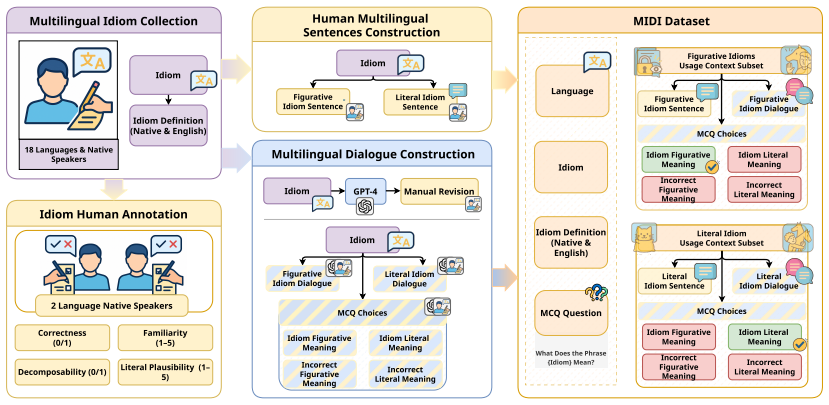
The MIDI dataset, which embeds idioms in sentence-level and conversational contexts and supplies both literal and figurative readings for high-, medium-, and low-resource languages.
If this is right
- Idiom comprehension accuracy decreases from high- to low-resource languages.
- Literal interpretations remain substantially harder than figurative ones in all resource tiers.
- Conversational context improves performance but does not close the gaps between resource levels or between literal and figurative readings.
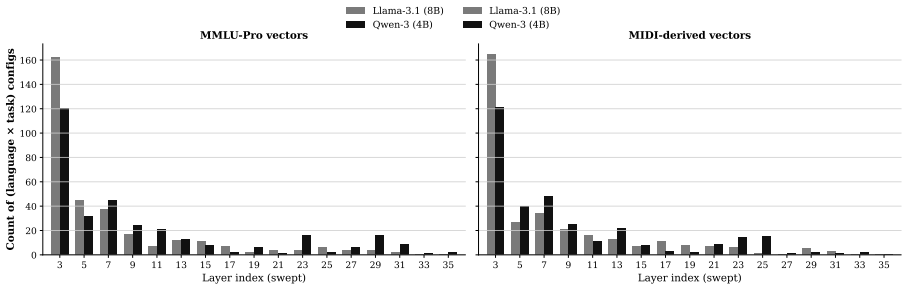
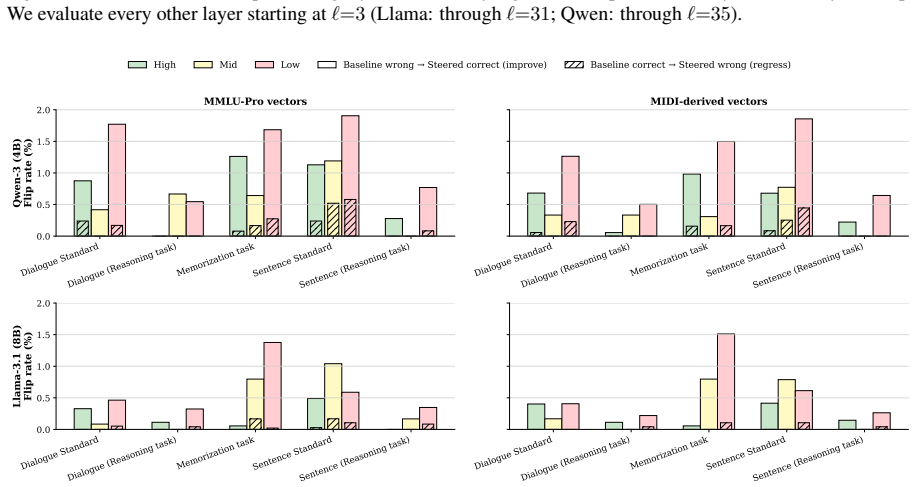
- Controlled interventions on model representations can distinguish memorization from reasoning about idioms.
Where Pith is reading between the lines
- Low-resource languages may require dedicated idiom-focused data collection or augmentation strategies during pretraining.
- The observed gaps point to the need for model components that explicitly model non-compositional meaning shifts.
- Similar patterns might appear in other non-compositional phenomena such as metaphors or sarcasm across resource levels.
Load-bearing premise
Native speakers can reliably curate and label idioms with accurate literal and figurative readings that are consistent and representative across the selected languages, contexts, and resource tiers.
What would settle it
A finding that model accuracy on MIDI examples is independent of language resource level, or that literal and figurative accuracy are equal, would falsify the reported disparities.
Figures

read the original abstract
Idiomatic expressions pose a major challenge for multilingual NLP because their meanings shift between figurative and literal usage, often requiring context for accurate interpretation. Prior work has focused on high-resource languages typically evaluates isolated idiom-meaning questions, overlooking realistic discourse. We introduce MIDI, a multilingual idiom dataset spanning 3 high-, 3 medium-, and 12 low-resource languages, curated by native speakers. Unlike previous datasets, MIDI provides idioms embedded in both sentence-level and conversational contexts, capturing both literal and figurative readings. Benchmarking state-of-the-art models shows that idiom comprehension degrades in low-resource languages and that, in all resource tiers, literal interpretations are substantially harder than figurative ones. Conversational context improves performance but does not eliminate these disparities. Through controlled tests and interventions on hidden representations, we further separate memorization from reasoning, exposing core limitations of current models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MIDI, a multilingual idiom dataset spanning 3 high-, 3 medium-, and 12 low-resource languages, with idioms embedded in both sentence-level and conversational contexts and supplied with literal and figurative readings by native speakers. Benchmarking of state-of-the-art models shows performance degradation in low-resource languages, substantially greater difficulty with literal than figurative interpretations across all tiers, and partial improvement from conversational context that does not eliminate the gaps. Controlled interventions on hidden representations are used to separate memorization from reasoning.
Significance. If the labels prove reliable, MIDI would be a valuable new resource for evaluating idiom comprehension in realistic discourse across resource tiers, extending prior work that has focused mainly on high-resource languages and isolated sentences. The use of interventions to distinguish memorization from reasoning is a methodological strength that could help diagnose model limitations.
major comments (1)
- [Dataset construction section] Dataset construction section: No inter-annotator agreement metrics, held-out validation set, or cross-validation against existing idiom lexicons are reported for the native-speaker curated literal/figurative labels and contexts. This is load-bearing for the central claims, as higher label noise in the 12 low-resource languages (where inventories are smaller) could artifactually produce the reported resource-tier gaps and literal-vs-figurative disparity.
minor comments (2)
- [Abstract and benchmarking results section] Abstract and benchmarking results section: Explicit dataset sizes per language/tier, model specifications, exact evaluation metrics, and any statistical tests should be stated to support the performance claims.
- [Figures and tables] Figure and table captions: Some captions lack sufficient detail on what is being plotted (e.g., exact accuracy definitions or context conditions).
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of validating the MIDI labels. We address this point directly below and will strengthen the dataset construction section accordingly.
read point-by-point responses
-
Referee: [Dataset construction section] Dataset construction section: No inter-annotator agreement metrics, held-out validation set, or cross-validation against existing idiom lexicons are reported for the native-speaker curated literal/figurative labels and contexts. This is load-bearing for the central claims, as higher label noise in the 12 low-resource languages (where inventories are smaller) could artifactually produce the reported resource-tier gaps and literal-vs-figurative disparity.
Authors: We agree that explicit validation metrics would increase confidence in the labels. In the revision we will add inter-annotator agreement figures computed on the subset of items that received multiple independent native-speaker annotations, together with a description of the annotation protocol. A held-out validation subset can also be designated and reported. Cross-validation against external lexicons is feasible only for the high- and medium-resource languages; for the twelve low-resource languages no comparable public resources with literal/figurative distinctions exist, and we will state this limitation explicitly. We note, however, that the literal-versus-figurative performance gap is observed uniformly across all three resource tiers, including the high-resource languages where label quality is least likely to be an issue. This pattern is difficult to attribute solely to differential noise in the low-resource portion of the data. revision: partial
Circularity Check
No circularity: purely empirical dataset creation and benchmarking
full rationale
The paper introduces the MIDI dataset (curated by native speakers) and reports empirical model evaluations on sentence vs. conversational contexts, literal vs. figurative readings, and resource tiers. No equations, fitted parameters, derivations, or predictions appear in the abstract or described content. No self-citations are invoked to justify core claims. The results are direct measurements on the constructed data and do not reduce to any input by construction. This is a standard empirical NLP study with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Idiomatic expressions have distinguishable literal and figurative meanings that native speakers can consistently identify and label.
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark , author=. Advances in Neural Information Processing Systems , volume=
-
[2]
The State and Fate of Linguistic Diversity and Inclusion in the NLP World
Joshi, Pratik and Santy, Sebastin and Budhiraja, Amar and Bali, Kalika and Choudhury, Monojit. The State and Fate of Linguistic Diversity and Inclusion in the NLP World. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.560
-
[3]
arXiv preprint arXiv:2207.04672 , year=
No language left behind: Scaling human-centered machine translation , author=. arXiv preprint arXiv:2207.04672 , year=
-
[4]
Non-compositional Expression Generation and its Continual Learning
Zhou, Jianing and Bhat, Suma. Non-compositional Expression Generation and its Continual Learning. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.166
-
[5]
First Conference on Language Modeling , year=
Enhancing Language Models with Idiomatic Reasoning , author=. First Conference on Language Modeling , year=
-
[6]
, author=
Multiword expressions. , author=. Handbook of natural language processing , volume=
-
[7]
Acta Universitatis Sapientiae, Philologica , volume=
About the definition, classification, and translation strategies of idioms , author=. Acta Universitatis Sapientiae, Philologica , volume=. 2016 , publisher=
2016
-
[8]
Journal of memory and language , volume=
The comprehension of idioms , author=. Journal of memory and language , volume=. 1988 , publisher=
1988
-
[9]
Can Transformer be Too Compositional? Analysing Idiom Processing in Neural Machine Translation
Dankers, Verna and Lucas, Christopher and Titov, Ivan. Can Transformer be Too Compositional? Analysing Idiom Processing in Neural Machine Translation. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.252
-
[10]
Rolling the DICE on Idiomaticity: How LLM s Fail to Grasp Context
Mi, Maggie and Villavicencio, Aline and Moosavi, Nafise Sadat. Rolling the DICE on Idiomaticity: How LLM s Fail to Grasp Context. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.362
-
[11]
ID 10 M : Idiom Identification in 10 Languages
Tedeschi, Simone and Martelli, Federico and Navigli, Roberto. ID 10 M : Idiom Identification in 10 Languages. Findings of the Association for Computational Linguistics: NAACL 2022. 2022. doi:10.18653/v1/2022.findings-naacl.208
-
[12]
A Hard Nut to Crack: Idiom Detection with Conversational Large Language Models
De Luca Fornaciari, Francesca and Altuna, Bego \ n a and Gonzalez-Dios, Itziar and Melero, Maite. A Hard Nut to Crack: Idiom Detection with Conversational Large Language Models. Proceedings of the 4th Workshop on Figurative Language Processing (FigLang 2024). 2024. doi:10.18653/v1/2024.figlang-1.5
-
[13]
Comparative Study of Multilingual Idioms and Similes in Large Language Models
Khoshtab, Paria and Namazifard, Danial and Masoudi, Mostafa and Akhgary, Ali and Mahdizadeh Sani, Samin and Yaghoobzadeh, Yadollah. Comparative Study of Multilingual Idioms and Similes in Large Language Models. Proceedings of the 31st International Conference on Computational Linguistics. 2025
2025
-
[14]
Transactions of the Association for Computational Linguistics , volume =
Zeng, Ziheng and Bhat, Suma , title =. Transactions of the Association for Computational Linguistics , volume =. 2021 , month =. doi:10.1162/tacl_a_00442 , url =
-
[15]
Multilingual Multi-Figurative Language Detection
Lai, Huiyuan and Toral, Antonio and Nissim, Malvina. Multilingual Multi-Figurative Language Detection. Findings of the Association for Computational Linguistics: ACL 2023. 2023. doi:10.18653/v1/2023.findings-acl.589
-
[16]
and Tanner, Darren , title =
Bulkes, Nyssa Z. and Tanner, Darren , title =. Behavior Research Methods , volume =. 2017 , doi =
2017
-
[17]
Cecilia Liu, Chen and Koto, Fajri and Baldwin, Timothy and Gurevych, Iryna. Are Multilingual LLM s Culturally-Diverse Reasoners? An Investigation into Multicultural Proverbs and Sayings. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 20...
-
[18]
Libben, Maya R. and Titone, Debra A. , title =. Memory & Cognition , year =. doi:10.3758/MC.36.6.1103 , url =
-
[19]
Memorization or Reasoning? Exploring the Idiom Understanding of LLM s
Kim, Jisu and Shin, Youngwoo and Hwang, Uiji and Choi, Jihun and Xuan, Richeng and Kim, Taeuk. Memorization or Reasoning? Exploring the Idiom Understanding of LLM s. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1099
-
[20]
LI dioms: A Multilingual Linked Idioms Data Set
Moussallem, Diego and Sherif, Mohamed Ahmed and Esteves, Diego and Zampieri, Marcos and Ngonga Ngomo, Axel-Cyrille. LI dioms: A Multilingual Linked Idioms Data Set. Proceedings of the Eleventh International Conference on Language Resources and Evaluation ( LREC 2018). 2018
2018
-
[21]
MAGPIE : A Large Corpus of Potentially Idiomatic Expressions
Haagsma, Hessel and Bos, Johan and Nissim, Malvina. MAGPIE : A Large Corpus of Potentially Idiomatic Expressions. Proceedings of the Twelfth Language Resources and Evaluation Conference. 2020
2020
-
[22]
Tayyar Madabushi, Harish and Gow-Smith, Edward and Scarton, Carolina and Villavicencio, Aline. AS titch I n L anguage M odels: Dataset and Methods for the Exploration of Idiomaticity in Pre-Trained Language Models. Findings of the Association for Computational Linguistics: EMNLP 2021. 2021. doi:10.18653/v1/2021.findings-emnlp.294
-
[23]
2023 , eprint =
Steering Language Models With Activation Engineering , author =. 2023 , eprint =
2023
-
[24]
The Reasoning-Memorization Interplay in Language Models Is Mediated by a Single Direction
Hong, Yihuai and Cao, Meng and Zhou, Dian and Yu, Lei and Jin, Zhijing. The Reasoning-Memorization Interplay in Language Models Is Mediated by a Single Direction. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.1111
-
[25]
2025 , eprint=
Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities , author=. 2025 , eprint=
2025
-
[26]
2025 , eprint=
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author=. 2025 , eprint=
2025
-
[27]
2025 , eprint=
Gemma 3 Technical Report , author=. 2025 , eprint=
2025
-
[28]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[29]
2024 , eprint=
Mixtral of Experts , author=. 2024 , eprint=
2024
-
[30]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[31]
2025 , url=
GPT-5 System Card , author=. 2025 , url=
2025
-
[32]
doi:10.5281/zenodo.12608602 , url =
Gao, Leo and Tow, Jonathan and Abbasi, Baber and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and Le Noac'h, Alain and Li, Haonan and McDonell, Kyle and Muennighoff, Niklas and Ociepa, Chris and Phang, Jason and Reynolds, Laria and Schoelkopf, Hailey and Skowron, Aviya and Sutawika, Lintang...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.