Disentanglement-Based Equivariant Learning for Compositional VQA
Pith reviewed 2026-06-28 14:58 UTC · model grok-4.3
The pith
The DEAL framework disentangles concepts via causality-inspired interventions and enforces equivariant constraints to improve compositional VQA using only ground-truth answers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
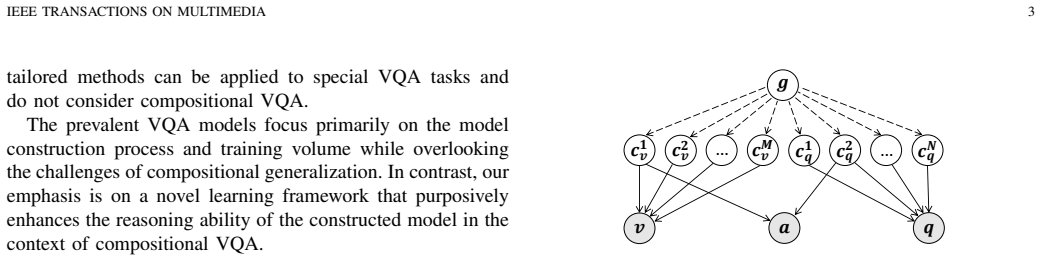
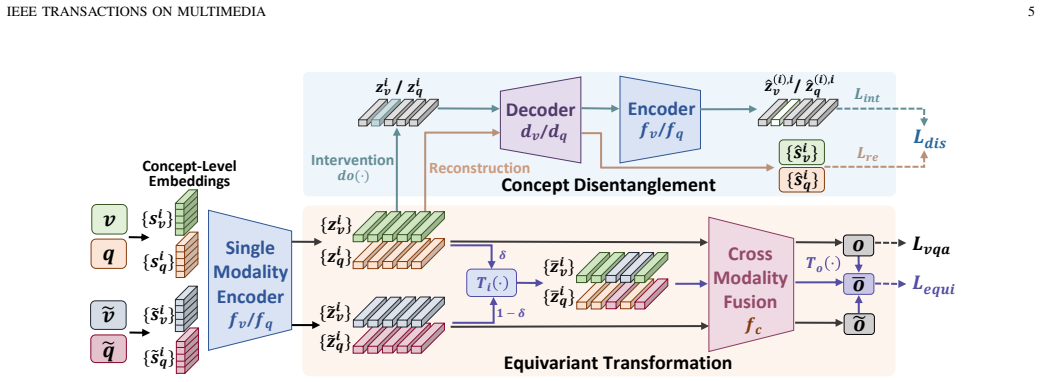
The central claim is that the Disentanglement-based EquivAriant Learning (DEAL) framework, by employing causality-inspired interventions to disentangle concepts from visual and textual inputs within a re-encoding framework and imposing equivariant constraints on compositional transformations, augments the compositional reasoning capacity of the model for VQA tasks.
What carries the argument
The DEAL framework, which disentangles concepts from visual and textual inputs via causality-inspired interventions inside a re-encoding process and then applies equivariant constraints after compositional transformation.
If this is right
- Models trained with DEAL generalize to novel visual and linguistic combinations on CLEVR-CoGenT and GQA-SGL without extra clues.
- Compositional variation is captured more effectively than in prior methods that overlook disentanglement.
- Training remains feasible in real-world VQA scenarios that supply only ground-truth answers.
- The re-encoding plus equivariance pipeline produces measurable gains over existing state-of-the-art approaches.
Where Pith is reading between the lines
- The same intervention-plus-equivariance pattern could be tested on other multimodal tasks that require recombining seen elements.
- Measuring whether the learned representations remain stable under small input perturbations would provide an independent check on successful disentanglement.
- Extending the method to video or multi-turn dialogue VQA would reveal whether the re-encoding step scales to richer temporal structure.
Load-bearing premise
Causality-inspired interventions can reliably disentangle underlying concepts from visual and textual inputs using only ground-truth answers.
What would settle it
A controlled test in which ablating the intervention step or the equivariant constraint produces no drop in accuracy on novel concept combinations would show the mechanisms are not necessary.
Figures

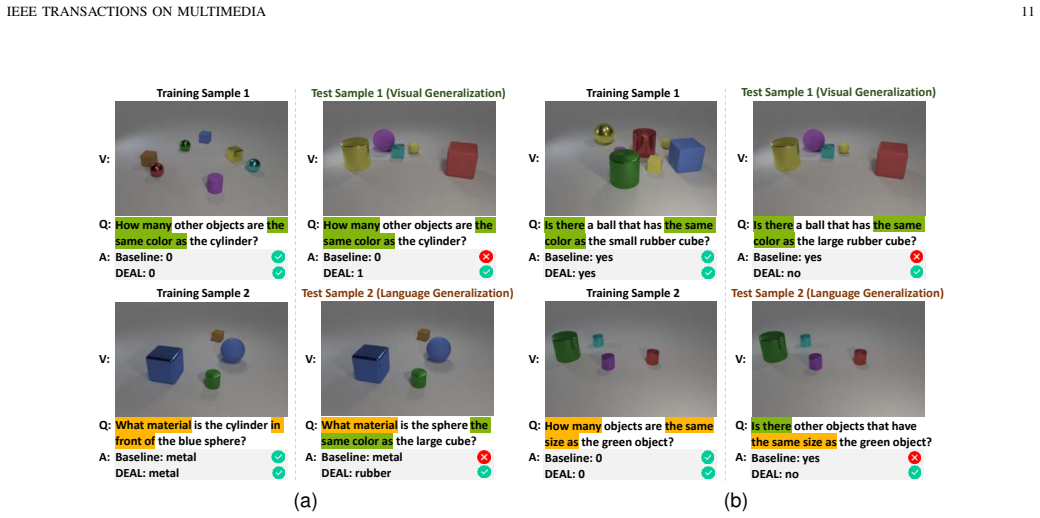
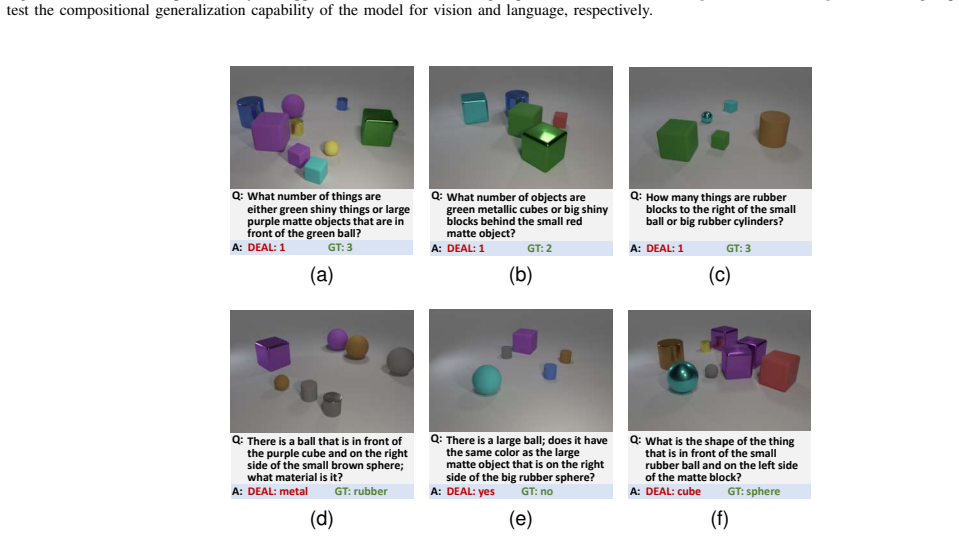
read the original abstract
Compositional visual question answering (VQA) represents a challenging yet fundamental task that requires models to comprehend novel combinations of previously learned concepts. The current methods often overlook the disentanglement of underlying concepts and are restricted in terms of their ability to effectively capture the compositional variation mechanism. Moreover, the state-of-the-art techniques depend on additional clues for training, which is not feasible in real-world VQA scenarios. To address these issues, in this paper, we introduce a novel Disentanglement-based EquivAriant Learning (DEAL) framework for compositional VQA, which is guided exclusively by ground-truth answers. In DEAL, we employ causality-inspired interventions to disentangle concepts derived from visual and textual inputs within a re-encoding framework. Based on the principle of equivariance, we subsequently perform a compositional transformation on the inference input and impose the equivariant constraint on the output to augment the compositional reasoning capacity of the model. Comprehensive experiments conducted on the benchmark CLEVR-CoGenT and GQA-SGL datasets validate the superiority of our proposed DEAL approach over the existing state-of-the-art methods for compositional VQA tasks in both visual and linguistic generalization settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a Disentanglement-based EquivAriant Learning (DEAL) framework for compositional VQA. It employs causality-inspired interventions within a re-encoding framework to disentangle concepts from visual and textual inputs, using only ground-truth answers for guidance. Equivariant constraints are then imposed after compositional transformations on inference inputs to enhance compositional reasoning. Experiments on CLEVR-CoGenT and GQA-SGL are reported to demonstrate superiority over existing state-of-the-art methods in both visual and linguistic generalization settings.
Significance. If the central claims hold, the work would be significant for compositional VQA by showing that disentanglement and equivariance can be achieved without additional clues or supervision, addressing a practical limitation of prior methods that rely on extra annotations. This could improve generalization to novel concept combinations in realistic scenarios. The approach combines ideas from causality and equivariance in a re-encoding setup, which, if verified with appropriate metrics and ablations, would offer a new direction for the field.
major comments (3)
- [Method (DEAL framework description)] The manuscript provides no explicit formulation, algorithm, or pseudocode for the causality-inspired interventions (e.g., do-interventions on specific visual or textual factors) within the re-encoding framework. Without this, it is impossible to determine whether the claimed disentanglement occurs or whether the re-encoder simply satisfies the equivariant loss on the training distribution.
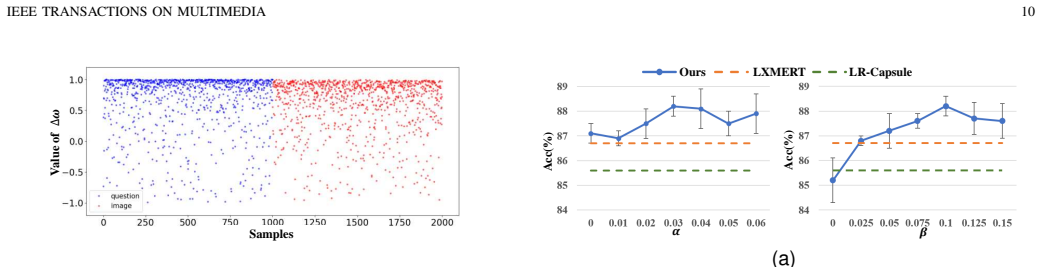
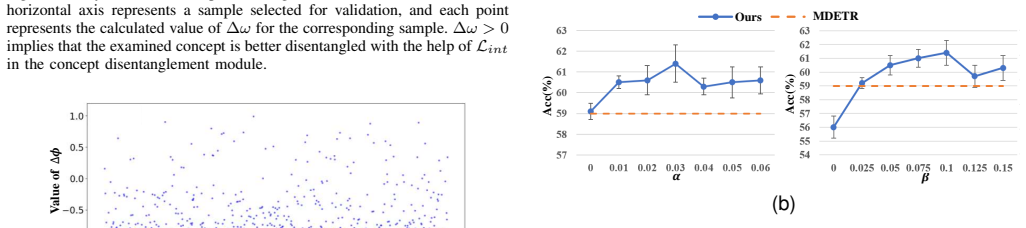
- [Experiments and results] No quantitative metrics confirming successful disentanglement are reported (e.g., DCI scores, concept probe accuracies, or mutual-information gaps between factors). This directly undermines the assertion that DEAL isolates underlying concepts using only ground-truth answers and enables compositional generalization beyond supervised baselines.
- [Experiments and results] The abstract and reported experiments assert superiority on CLEVR-CoGenT and GQA-SGL but include no ablation studies, error analysis, or comparison isolating the contribution of the intervention and equivariant components. This makes it impossible to verify that the gains are attributable to the proposed DEAL mechanism rather than other implementation choices.
minor comments (1)
- [Abstract] The acronym expansion 'Disentanglement-based EquivAriant Learning' uses a non-standard capitalization in 'EquivAriant'; clarify whether this is intentional or a typographical variant of 'equivariant'.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our paper. We address each major comment below and will incorporate the suggested changes in a revised version.
read point-by-point responses
-
Referee: [Method (DEAL framework description)] The manuscript provides no explicit formulation, algorithm, or pseudocode for the causality-inspired interventions (e.g., do-interventions on specific visual or textual factors) within the re-encoding framework. Without this, it is impossible to determine whether the claimed disentanglement occurs or whether the re-encoder simply satisfies the equivariant loss on the training distribution.
Authors: We agree that an explicit formulation is necessary for clarity. In the revised manuscript, we will provide detailed equations for the causality-inspired interventions on visual and textual factors in the re-encoding framework, as well as pseudocode for the DEAL training procedure. This will demonstrate how disentanglement is achieved guided solely by ground-truth answers. revision: yes
-
Referee: [Experiments and results] No quantitative metrics confirming successful disentanglement are reported (e.g., DCI scores, concept probe accuracies, or mutual-information gaps between factors). This directly undermines the assertion that DEAL isolates underlying concepts using only ground-truth answers and enables compositional generalization beyond supervised baselines.
Authors: The primary evaluation in the manuscript is on the compositional VQA performance. To further support the disentanglement claims, we will add quantitative metrics including DCI scores and concept probe accuracies in the experiments section of the revision. revision: yes
-
Referee: [Experiments and results] The abstract and reported experiments assert superiority on CLEVR-CoGenT and GQA-SGL but include no ablation studies, error analysis, or comparison isolating the contribution of the intervention and equivariant components. This makes it impossible to verify that the gains are attributable to the proposed DEAL mechanism rather than other implementation choices.
Authors: We will include comprehensive ablation studies and error analysis in the revised manuscript to isolate the contributions of the intervention and equivariant components, thereby verifying that the performance gains stem from the DEAL framework. revision: yes
Circularity Check
No circularity: empirical framework with no visible self-referential derivations
full rationale
The abstract presents DEAL as a novel framework using causality-inspired interventions within a re-encoding setup and equivariant constraints, guided solely by ground-truth answers. No equations, parameter-fitting steps, uniqueness theorems, or self-citations are quoted or described that would reduce any claimed prediction or disentanglement result to a fitted input or prior author work by construction. The contribution is framed as an empirical method validated on CLEVR-CoGenT and GQA-SGL, without a closed derivational chain that collapses to its own definitions. This qualifies as a self-contained proposal whose validity rests on external experimental outcomes rather than internal redefinition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Vqa: Visual question answering,
S. Antol, A. Agrawal, J. Lu, M. Mitchell, D. Batra, C. L. Zitnick, and D. Parikh, “Vqa: Visual question answering,” inProceedings of the IEEE International Conference on Computer Vision (ICCV), December 2015. 1
2015
-
[2]
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation,
J. Li, D. Li, C. Xiong, and S. Hoi, “Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation,” inInternational Conference on Machine Learning. PMLR, 2022, pp. 12 888–12 900. 1
2022
-
[3]
Image as a foreign language: Beit pretraining for vision and vision-language tasks,
W. Wang, H. Bao, L. Dong, J. Bjorck, Z. Peng, Q. Liu, K. Aggarwal, O. K. Mohammed, S. Singhal, S. Somet al., “Image as a foreign language: Beit pretraining for vision and vision-language tasks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 19 175–19 186. 1, 2
2023
-
[4]
Connectionism and cognitive archi- tecture: A critical analysis,
J. A. Fodor and Z. W. Pylyshyn, “Connectionism and cognitive archi- tecture: A critical analysis,”Cognition, vol. 28, no. 1-2, pp. 3–71, 1988. 1
1988
-
[5]
Systematic Generalization: What Is Required and Can It Be Learned?
D. Bahdanau, S. Murty, M. Noukhovitch, T. H. Nguyen, H. de Vries, and A. Courville, “Systematic generalization: What is required and can it be learned?”arXiv preprint arXiv:1811.12889, 2018. 1
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[6]
Closure: Assessing systematic general- ization of clevr models,
D. Bahdanau, H. de Vries, T. J. O’Donnell, S. Murty, P. Beaudoin, Y . Bengio, and A. Courville, “Closure: Assessing systematic general- ization of clevr models,”arXiv preprint arXiv:1912.05783, 2019. 1, 2, 3
-
[7]
A benchmark for systematic generalization in grounded language under- standing,
L. Ruis, J. Andreas, M. Baroni, D. Bouchacourt, and B. M. Lake, “A benchmark for systematic generalization in grounded language under- standing,”Advances in neural information processing systems, vol. 33, pp. 19 861–19 872, 2020. 1
2020
-
[8]
How modular should neural module networks be for systematic generalization?
V . D’Amario, T. Sasaki, and X. Boix, “How modular should neural module networks be for systematic generalization?”Advances in Neural Information Processing Systems, vol. 34, pp. 23 374–23 385, 2021. 1, 2, 3
2021
-
[9]
Meta module network for compositional visual reasoning,
W. Chen, Z. Gan, L. Li, Y . Cheng, W. Wang, and J. Liu, “Meta module network for compositional visual reasoning,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2021, pp. 655–664. 1, 3, 7, 8
2021
-
[10]
Transformer module networks for systematic generalization in visual question answering,
M. Yamada, V . D’Amario, K. Takemoto, X. Boix, and T. Sasaki, “Transformer module networks for systematic generalization in visual question answering,”IEEE Transactions on Pattern Analysis and Ma- chine Intelligence, 2024. 1, 2, 3, 6, 7, 8
2024
-
[11]
Detection-based intermediate supervision for visual question answering,
Y . Liu, D. Peng, W. Wei, Y . Fu, W. Xie, and D. Chen, “Detection-based intermediate supervision for visual question answering,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 12, 2024, pp. 14 061–14 068. 1, 2, 3
2024
-
[12]
Neural module networks,
J. Andreas, M. Rohrbach, T. Darrell, and D. Klein, “Neural module networks,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 39–48. 1, 2, 3
2016
-
[13]
Linguistically routing capsule network for out-of-distribution visual question answering,
Q. Cao, W. Wan, K. Wang, X. Liang, and L. Lin, “Linguistically routing capsule network for out-of-distribution visual question answering,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 1614–1623. 1, 2, 3, 8
2021
-
[14]
Neural- symbolic vqa: Disentangling reasoning from vision and language under- standing,
K. Yi, J. Wu, C. Gan, A. Torralba, P. Kohli, and J. Tenenbaum, “Neural- symbolic vqa: Disentangling reasoning from vision and language under- standing,”Advances in neural information processing systems, vol. 31,
-
[15]
Multimodal graph networks for composi- tional generalization in visual question answering,
R. Saqur and K. Narasimhan, “Multimodal graph networks for composi- tional generalization in visual question answering,”Advances in Neural Information Processing Systems, vol. 33, pp. 3070–3081, 2020. 1, 3
2020
-
[16]
Compositional generalization in neuro- symbolic visual question answering,
A. Dahlgren and S. Dan, “Compositional generalization in neuro- symbolic visual question answering,” inInternational Joint Conference on Artificial Intelligence 2023 Workshop on Knowledge-Based Compo- sitional Generalization, 2023. 1, 3
2023
-
[17]
Mdetr-modulated detection for end-to-end multi-modal understanding,
A. Kamath, M. Singh, Y . LeCun, G. Synnaeve, I. Misra, and N. Carion, “Mdetr-modulated detection for end-to-end multi-modal understanding,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 1780–1790. 1, 2, 3, 7, 8
2021
-
[18]
Exploring the effect of primitives for compositional generalization in vision-and-language,
C. Li, Z. Li, C. Jing, Y . Jia, and Y . Wu, “Exploring the effect of primitives for compositional generalization in vision-and-language,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 19 092–19 101. 1, 2, 3
2023
-
[19]
Towards a Definition of Disentangled Representations
I. Higgins, D. Amos, D. Pfau, S. Racaniere, L. Matthey, D. Rezende, and A. Lerchner, “Towards a definition of disentangled representations,” arXiv preprint arXiv:1812.02230, 2018. 2
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[20]
Causal inference in statistics: An overview,
J. Pearl, “Causal inference in statistics: An overview,” 2009. 2, 3, 4
2009
-
[21]
Group equivariant convolutional networks,
T. Cohen and M. Welling, “Group equivariant convolutional networks,” inInternational conference on machine learning. PMLR, 2016, pp. 2990–2999. 2, 3, 6
2016
-
[22]
Mutan: Multi- modal tucker fusion for visual question answering,
H. Ben-Younes, R. Cadene, M. Cord, and N. Thome, “Mutan: Multi- modal tucker fusion for visual question answering,” inProceedings of the IEEE international conference on computer vision, 2017, pp. 2612–
2017
-
[23]
Joint embedding vqa model based on dynamic word vector,
Z. Ma, W. Zheng, X. Chen, and L. Yin, “Joint embedding vqa model based on dynamic word vector,”PeerJ Computer Science, vol. 7, p. e353, 2021. 2
2021
-
[24]
Where to look: Focus regions for visual question answering,
K. J. Shih, S. Singh, and D. Hoiem, “Where to look: Focus regions for visual question answering,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 4613–4621. 2
2016
-
[25]
J. Mao, C. Gan, P. Kohli, J. B. Tenenbaum, and J. Wu, “The neuro- symbolic concept learner: Interpreting scenes, words, and sentences from natural supervision,”arXiv preprint arXiv:1904.12584, 2019. 2
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[26]
Visual question answering with dense inter-and intra-modality interactions,
F. Liu, J. Liu, Z. Fang, R. Hong, and H. Lu, “Visual question answering with dense inter-and intra-modality interactions,”IEEE Transactions on Multimedia, vol. 23, pp. 3518–3529, 2020. 2
2020
-
[27]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017. 2, 4, 7
2017
-
[28]
Lxmert: Learning cross-modality encoder representations from transformers,
H. Tan and M. Bansal, “Lxmert: Learning cross-modality encoder representations from transformers,”arXiv preprint arXiv:1908.07490,
-
[29]
Boosting generic visual-linguistic representation with dynamic contexts,
G. Ma, Y . Bai, W. Zhang, T. Yao, B. Shihada, and T. Mei, “Boosting generic visual-linguistic representation with dynamic contexts,”IEEE Transactions on Multimedia, vol. 25, pp. 8445–8457, 2023. 2
2023
-
[30]
Mm- llms: Recent advances in multimodal large language models.arXiv preprint arXiv:2401.13601, 2024
D. Zhang, Y . Yu, J. Dong, C. Li, D. Su, C. Chu, and D. Yu, “Mm-llms: Recent advances in multimodal large language models,”arXiv preprint arXiv:2401.13601, 2024. 2
-
[31]
Exploring compositional generalization of large language models,
H. Yang, H. Lu, W. Lam, and D. Cai, “Exploring compositional generalization of large language models,” inProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 4: Student Research Workshop), 2024, pp. 16–24. 2
2024
-
[32]
Learning, reasoning, and compositional gen- eralisation in multimodal language models,
A. Dahlgren Lindstr ¨om, “Learning, reasoning, and compositional gen- eralisation in multimodal language models,” Ph.D. dissertation, Ume ˚a University, 2024. 2
2024
-
[33]
An empirical study of gpt-3 for few-shot knowledge-based vqa,
Z. Yang, Z. Gan, J. Wang, X. Hu, Y . Lu, Z. Liu, and L. Wang, “An empirical study of gpt-3 for few-shot knowledge-based vqa,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 3, 2022, pp. 3081–3089. 2
2022
-
[34]
Learning to supervise knowledge retrieval over a tree structure for visual question answering,
N. Xu, Z. Lu, H. Tian, R. Kang, J. Cao, Y . Zhang, and A.-A. Liu, “Learning to supervise knowledge retrieval over a tree structure for visual question answering,”IEEE Transactions on Multimedia, 2024. 2
2024
-
[35]
Towards causal vqa: Revealing and reducing spurious correlations by invariant and covariant semantic editing,
V . Agarwal, R. Shetty, and M. Fritz, “Towards causal vqa: Revealing and reducing spurious correlations by invariant and covariant semantic editing,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 9690–9698. 2
2020
-
[36]
Film: Visual reasoning with a general conditioning layer,
E. Perez, F. Strub, H. De Vries, V . Dumoulin, and A. Courville, “Film: Visual reasoning with a general conditioning layer,” inProceedings of the AAAI conference on artificial intelligence, vol. 32, no. 1, 2018. 3, 7, 8
2018
-
[37]
Transparency by design: Closing the gap between performance and interpretability in visual reasoning,
D. Mascharka, P. Tran, R. Soklaski, and A. Majumdar, “Transparency by design: Closing the gap between performance and interpretability in visual reasoning,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 4942–4950. 3, 7, 8
2018
-
[38]
Lexsym: Compositionality as lexical symmetry,
E. Aky ¨urek and J. Andreas, “Lexsym: Compositionality as lexical symmetry,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2023, pp. 639–
2023
-
[39]
3, 8 IEEE TRANSACTIONS ON MULTIMEDIA 14
-
[40]
Disentangled representation learning,
X. Wang, H. Chen, Z. Wu, W. Zhuet al., “Disentangled representation learning,”IEEE Transactions on Pattern Analysis and Machine Intelli- gence, 2024. 3
2024
-
[41]
Robustly disentangled causal mechanisms: Validating deep representations for interventional robustness,
R. Suter, D. Miladinovic, B. Sch ¨olkopf, and S. Bauer, “Robustly disentangled causal mechanisms: Validating deep representations for interventional robustness,” inInternational Conference on Machine Learning. PMLR, 2019, pp. 6056–6065. 3
2019
-
[42]
On causally disentangled representations,
A. G. Reddy, V . N. Balasubramanianet al., “On causally disentangled representations,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 7, 2022, pp. 8089–8097. 3, 4
2022
-
[43]
SceneGraphFusion: Incremental 3d scene graph prediction from RGB-d sequences,
M. Yang, F. Liu, Z. Chen, X. Shen, J. Hao, and J. Wang, “Causalvae: Disentangled representation learning via neural structural causal models,” in2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2021. [Online]. Available: http://dx.doi.org/10.1109/cvpr46437.2021.00947 3
-
[44]
A meta-transfer objective for learning to disentangle causal mechanisms,
Y . Bengio, D. Tristan, N. Rahaman, K. Rosemary, S. Lachapelle, O. Bi- laniuk, A. Goyal, and C. Pal, “A meta-transfer objective for learning to disentangle causal mechanisms,”arXiv: Learning,arXiv: Learning, Jan
-
[45]
Disen- tangled generative causal representation learning,
X. Shen, F. Liu, H. Dong, Q. Lian, Z. Chen, and T. Zhang, “Disen- tangled generative causal representation learning,”Cornell University - arXiv,Cornell University - arXiv, May 2021. 3
2021
-
[46]
Equivariant flows: Exact likeli- hood generative learning for symmetric densities,
J. K ¨ohler, L. Klein, and F. No ´e, “Equivariant flows: Exact likeli- hood generative learning for symmetric densities,”Cornell University - arXiv,Cornell University - arXiv, Jun 2020. 3
2020
-
[47]
Group equivariant capsule networks,
J. Lenssen, M. Fey, and P. Libuschewski, “Group equivariant capsule networks,”Neural Information Processing Systems,Neural Information Processing Systems, Jun 2018. 3
2018
-
[48]
Learning generalized transformation equivariant representations via autoencoding transforma- tions,
G.-J. Qi, L. Zhang, F. Lin, and X. Wang, “Learning generalized transformation equivariant representations via autoencoding transforma- tions,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 4, pp. 2045–2057, 2020. 3, 6
2045
-
[49]
Equivariant and invariant grounding for video question answering,
Y . Li, X. Wang, J. Xiao, and T.-S. Chua, “Equivariant and invariant grounding for video question answering,” inProceedings of the 30th ACM International Conference on Multimedia, 2022, pp. 4714–4722. 3, 6
2022
-
[50]
Vilt: Vision-and-language transformer without convolution or region supervision,
W. Kim, B. Son, and I. Kim, “Vilt: Vision-and-language transformer without convolution or region supervision,” inInternational Conference on Machine Learning. PMLR, 2021, pp. 5583–5594. 4, 8
2021
-
[51]
M. Arjovsky, L. Bottou, I. Gulrajani, and D. Lopez-Paz, “Invariant risk minimization,”arXiv preprint arXiv:1907.02893, 2019. 4
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[52]
Bottom-up and top-down attention for image captioning and visual question answering,
P. Anderson, X. He, C. Buehler, D. Teney, M. Johnson, S. Gould, and L. Zhang, “Bottom-up and top-down attention for image captioning and visual question answering,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 6077–6086. 4, 7
2018
-
[53]
Auto-Encoding Variational Bayes
D. P. Kingma and M. Welling, “Auto-encoding variational bayes,”arXiv preprint arXiv:1312.6114, 2013. 5
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[54]
Grad-cam: Visual explanations from deep networks via gradient-based localization,
R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra, “Grad-cam: Visual explanations from deep networks via gradient-based localization,” inProceedings of the IEEE international conference on computer vision, 2017, pp. 618–626. 6
2017
-
[55]
Clevr: A diagnostic dataset for compositional language and elementary visual reasoning,
J. Johnson, B. Hariharan, L. Van Der Maaten, L. Fei-Fei, C. Lawrence Zitnick, and R. Girshick, “Clevr: A diagnostic dataset for compositional language and elementary visual reasoning,” inProceed- ings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 2901–2910. 6
2017
-
[56]
Making the v in vqa matter: Elevating the role of image understanding in visual question answering,
Y . Goyal, T. Khot, D. Summers-Stay, D. Batra, and D. Parikh, “Making the v in vqa matter: Elevating the role of image understanding in visual question answering,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 6904–6913. 6
2017
-
[57]
Gqa: A new dataset for real-world visual reasoning and compositional question answering,
D. A. Hudson and C. D. Manning, “Gqa: A new dataset for real-world visual reasoning and compositional question answering,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 6700–6709. 7
2019
-
[58]
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll ´ar, and C. L. Zitnick,Microsoft COCO: Common Objects in Context, Jan 2014, p. 740–755. [Online]. Available: http: //dx.doi.org/10.1007/978-3-319-10602-1 48 7, 8, 9
-
[59]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,”arXiv preprint arXiv:1810.04805, 2018. 7
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[60]
Faster r-cnn: Towards real-time object detection with region proposal networks,
S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: Towards real-time object detection with region proposal networks,”Advances in neural information processing systems, vol. 28, 2015. 7 Zhou Dureceived the B.E. degree at the School of Information Science and Technology from the Southwest Jiaotong University (SWJTU), Chengdu, China. He is currently work...
2015
-
[61]
He was a Research Assistant and a Senior Research Associate with the City University of Hong Kong, Hong Kong, from 2003 to 2004 and from 2007 to 2009, respectively. He was with the School of Computer Science, Carnegie Mellon University, Pittsburgh, PA, USA, and with the School of Information and Computer Science, University of California at Irvine, Irvine...
2003
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.