FATE-VLA:Failue-aware test generation for vision-language-action models
Pith reviewed 2026-06-28 14:29 UTC · model grok-4.3
The pith
A failure-aware test generation method finds up to 29.7 percent more failures in vision-language-action robot models than static random benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
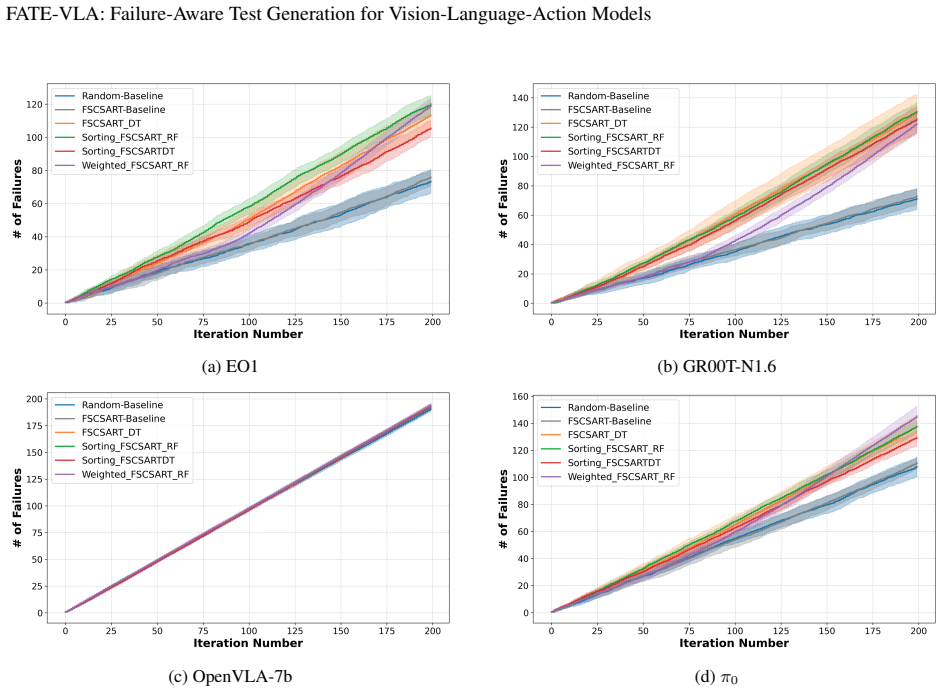
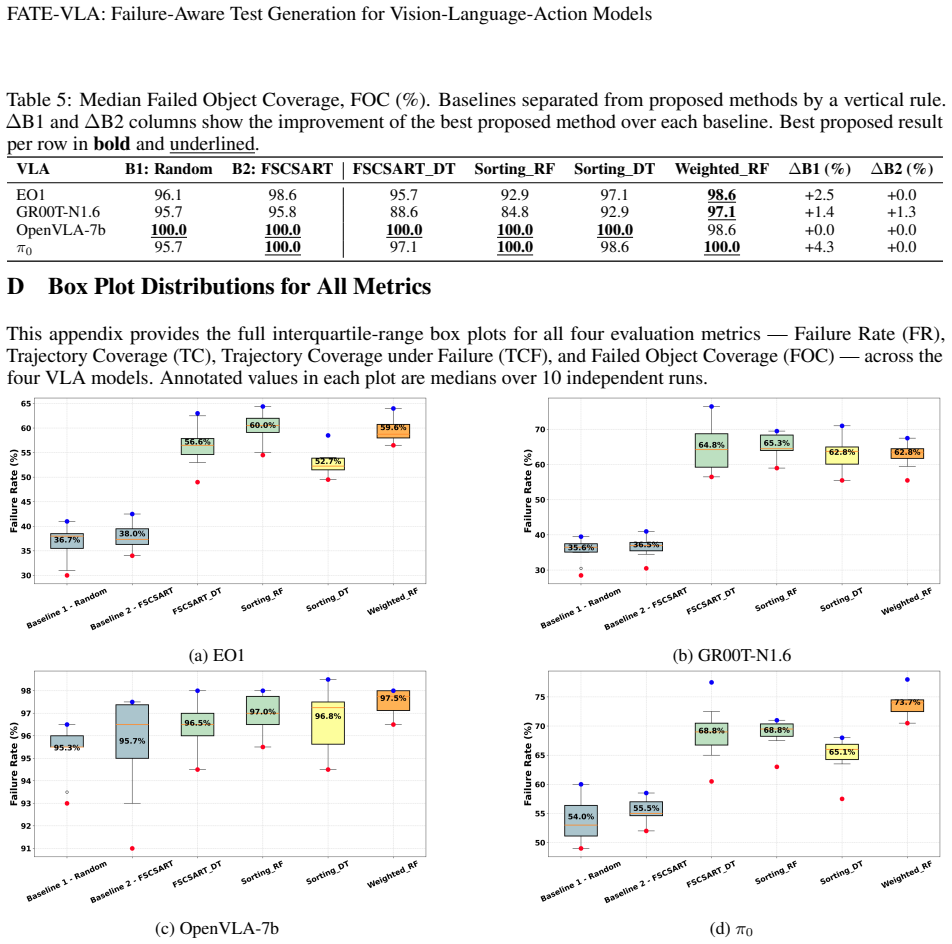
The failure-aware test-generation approach that combines diversity-driven exploration with surrogate models learned from observed executions steers testing toward high-risk yet diverse scene regions and uncovers substantially more failures (up to +29.7 percent over baselines) while exposing more diverse failure modes, as illustrated by one model's success rate dropping from 64.4 percent to 34.7 percent.
What carries the argument
The failure-aware test-generation approach that combines diversity-driven exploration with surrogate models learned from observed executions to steer testing toward high-risk scene regions.
If this is right
- Success rates measured on fixed task suites would no longer serve as reliable indicators of deployed performance.
- Diverse failure modes that remain hidden under random sampling would become visible during testing.
- VLA evaluation would need to move from passive measurement on static suites to adaptive, failure-seeking generation.
- The structure of model weaknesses could be mapped systematically before real-world use.
Where Pith is reading between the lines
- The same active-search principle could be tested on other embodied policies that operate in continuous high-dimensional spaces.
- If surrogate-guided search consistently locates failure clusters, it might reduce the total number of physical trials needed for thorough robustness checks.
- Deployment pipelines could incorporate periodic re-testing with the adaptive generator after model updates or environment changes.
Load-bearing premise
Surrogate models built from observed executions can reliably locate high-risk yet diverse regions in high-dimensional embodied spaces without bias or oversight of clustered failures.
What would settle it
Run the new method and the selected baselines on the same four VLA models under identical conditions and count both the total failures found and the number of distinct failure modes; if the new method does not exceed the baselines by a clear margin, the performance claim does not hold.
Figures
read the original abstract
Vision-Language-Action (VLA) models are increasingly used as generalist robot policies, yet their evaluation still relies largely on static benchmarks that randomly sample task scenes. In high-dimensional embodied spaces, failures are sparse and clustered, so static benchmarking can underestimate robustness risks. We reframe VLA evaluation as an active failure-discovery problem and propose a failure-aware test-generation approach that combines diversity-driven exploration with surrogate models learned from observed executions. The method steers testing toward high-risk yet diverse scene regions. Across four state-of-the-art VLA models, it uncovers substantially more failures (up to +29.7 % over selected baselines) while revealing more diverse failure modes. This mean that, for instance, in the case of GR00T-N1.6, success rate dropped from 64.4% to 34.7%. More broadly, our findings call for a shift in VLA evaluation: from passive measurement on fixed task suites to adaptive, failure-seeking test generation that exposes the structure of model weaknesses before deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FATE-VLA, a failure-aware test generation framework for vision-language-action (VLA) models. It reframes evaluation as an active discovery problem, combining diversity-driven exploration with surrogate models trained on observed executions to steer testing toward high-risk yet diverse scene regions in high-dimensional embodied spaces. The central empirical claim is that the approach uncovers up to 29.7% more failures than selected baselines across four state-of-the-art VLA models while exposing more diverse failure modes; an illustrative result is that success rate on GR00T-N1.6 drops from 64.4% to 34.7%. The work advocates shifting VLA evaluation from passive static benchmarks to adaptive, failure-seeking test generation.
Significance. If the reported gains and diversity improvements hold under rigorous controls, the work would meaningfully advance VLA evaluation by demonstrating that static random sampling underestimates robustness risks in sparse, clustered failure regimes. It provides a concrete, deployable alternative that could improve safety assessment prior to real-world use of generalist robot policies.
major comments (2)
- [Abstract] Abstract: the quantitative claim of 'up to +29.7 % over selected baselines' and the GR00T-N1.6 success-rate drop are presented without any definition of the baselines, number of trials, statistical tests, or error bars; this information is load-bearing for assessing whether the gains reflect true improvement rather than experimental artifacts.
- [Abstract] Abstract: the surrogate-model component is described only at the level of 'learned from observed executions' with no architecture, training objective, uncertainty quantification, or validation procedure against held-out failure clusters; this directly bears on the central claim because, in sparse clustered regimes, an under-specified surrogate risks missing modes or introducing bias as highlighted by the stress-test concern.
minor comments (1)
- [Abstract] Abstract: grammatical error 'This mean that' should read 'This means that'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that the high-level presentation of results requires additional context to allow readers to assess the claims, and we will revise the abstract accordingly while preserving its conciseness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the quantitative claim of 'up to +29.7 % over selected baselines' and the GR00T-N1.6 success-rate drop are presented without any definition of the baselines, number of trials, statistical tests, or error bars; this information is load-bearing for assessing whether the gains reflect true improvement rather than experimental artifacts.
Authors: We agree the abstract should briefly contextualize the reported numbers. In the revised version we will specify the baselines (random sampling and a diversity-only ablation), note that results are averaged over 5 independent runs with standard deviation reported, and state that the reported improvements are statistically significant under a paired t-test (p < 0.05). The full experimental protocol, trial counts, and error-bar details already appear in Section 4; the abstract revision will point readers to those results without expanding length substantially. revision: yes
-
Referee: [Abstract] Abstract: the surrogate-model component is described only at the level of 'learned from observed executions' with no architecture, training objective, uncertainty quantification, or validation procedure against held-out failure clusters; this directly bears on the central claim because, in sparse clustered regimes, an under-specified surrogate risks missing modes or introducing bias as highlighted by the stress-test concern.
Authors: We will add one concise sentence to the abstract summarizing the surrogate: a lightweight MLP ensemble trained with binary cross-entropy on execution outcomes to predict failure probability, with uncertainty obtained via disagreement among ensemble members, and validated via held-out cluster recall. The full architecture, training objective, and validation procedure against held-out failure clusters are already provided in Section 3.2; the abstract change will make this explicit at the summary level. revision: yes
Circularity Check
No circularity: empirical testing method with no self-referential derivations or fitted predictions
full rationale
The paper describes a failure-aware test generation approach that combines diversity-driven exploration with surrogate models learned from observed executions. No equations, fitted parameters, or derivation steps are presented in the provided text that reduce by construction to the method's own inputs. The central claims are empirical performance improvements on VLA models, not mathematical predictions derived from self-defined quantities or self-citations. The approach is presented as a novel combination of existing techniques without load-bearing self-referential elements.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
MANGO: Automated Multi-Agent Test Oracle Generation for Vision-Language-Action Models
MANGO uses Generator, Assessor, and Judge agents to create reusable atomic tasks and fine-grained oracles from natural language, evaluated on LIBERO_10 and RoboCasa benchmarks for comparable failure detection with bet...
Reference graph
Works this paper leans on
-
[1]
Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Abhishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
2024
-
[2]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Calvin: A benchmark for language- conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics and Automation Letters, 7(3):7327–7334, 2022
Oier Mees, Lukas Hermann, Erick Rosete-Beas, and Wolfram Burgard. Calvin: A benchmark for language- conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics and Automation Letters, 7(3):7327–7334, 2022
2022
-
[4]
Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776– 44791, 2023
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776– 44791, 2023
2023
-
[5]
Jiayuan Gu, Fanbo Xiang, Xuanlin Li, Zhan Ling, Xiqiang Liu, Tongzhou Mu, Yihe Tang, Stone Tao, Xinyue Wei, Yunchao Yao, et al. Maniskill2: A unified benchmark for generalizable manipulation skills.arXiv preprint arXiv:2302.04659, 2023
-
[7]
Adaptive random testing
Tsong Yueh Chen, Hing Leung, and Ieng Kei Mak. Adaptive random testing. InAnnual Asian Computing Science Conference, pages 320–329. Springer, 2004
2004
-
[8]
Replication package for paper fate-vla: Failure-aware test generation for vision-language-action models, May 2026
Arusa Kanwal, Pablo Valle, Shaukat Ali, and Aitor Arrieta. Replication package for paper fate-vla: Failure-aware test generation for vision-language-action models, May 2026. https://github.com/pablovalle/FATE-VLA
2026
-
[9]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Model
Delin Qu, Haoming Song, Qizhi Chen, Yuanqi Yao, Xinyi Ye, Yan Ding, Zhigang Wang, JiaYuan Gu, Bin Zhao, Dong Wang, et al. Spatialvla: Exploring spatial representations for visual-language-action model.arXiv preprint arXiv:2501.15830, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
NVIDIA, :, Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi "Jim" Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, Joel Jang, Zhenyu Jiang, Jan Kautz, Kaushil Kundalia, Lawrence Lao, Zhiqi Li, Zongyu Lin, Kevin Lin, Guilin Liu, Edith Llontop, Loic Magne, Ajay Mandlekar, Avnish Narayan, Soroush Nasiriany, Scott Reed, Y...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Zhilinsky.π 0: A visi...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Delin Qu, Haoming Song, Qizhi Chen, Zhaoqing Chen, Xianqiang Gao, Xinyi Ye, Qi Lv, Modi Shi, Guanghui Ren, Cheng Ruan, Maoqing Yao, Haoran Yang, Jiacheng Bao, Bin Zhao, and Dong Wang. Eo-1: Interleaved vision-text-action pretraining for general robot control, 2025.https://arxiv.org/abs/2508.21112
-
[14]
Vlatest: Testing and evaluating vision-language-action models for robotic manipulation.Proceedings of the ACM on Software Engineering, 2(FSE):1615–1638, 2025
Zhijie Wang, Zhehua Zhou, Jiayang Song, Yuheng Huang, Zhan Shu, and Lei Ma. Vlatest: Testing and evaluating vision-language-action models for robotic manipulation.Proceedings of the ACM on Software Engineering, 2(FSE):1615–1638, 2025
2025
-
[15]
Eva-vla: Evaluating vision-language-action models’ robustness under real-world physical variations
Hanqing Liu, Shouwei Ruan, Jiahuan Long, Junqi Wu, Jiacheng Hou, Huili Tang, Tingsong Jiang, Weien Zhou, and Wen Yao. Eva-vla: Evaluating vision-language-action models’ robustness under real-world physical variations. arXiv preprint arXiv:2509.18953, 2025
-
[16]
Jierui Peng, Yanyan Zhang, Yicheng Duan, Tuo Liang, Vipin Chaudhary, and Yu Yin. Nebula: Do we evaluate vision-language-action agents correctly?, 2025.https://arxiv.org/abs/2510.16263
-
[17]
Uncovering Linguistic Fragility in Vision-Language-Action Models via Diversity-Aware Red Teaming
Baoshun Tong, Haoran He, Ling Pan, Yang Liu, and Liang Lin. Uncovering linguistic fragility in vision-language- action models via diversity-aware red teaming.arXiv preprint arXiv:2604.05595, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Vlabench: A large-scale benchmark for language-conditioned robotics manipulation with long-horizon reasoning tasks
Shiduo Zhang, Zhe Xu, Peiju Liu, Xiaopeng Yu, Yuan Li, Qinghui Gao, Zhaoye Fei, Zhangyue Yin, Zuxuan Wu, Yu-Gang Jiang, et al. Vlabench: A large-scale benchmark for language-conditioned robotics manipulation with long-horizon reasoning tasks. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11142–11152, 2025
2025
-
[19]
LIBERO-Plus: In-depth Robustness Analysis of Vision-Language-Action Models
Senyu Fei, Siyin Wang, Junhao Shi, Zihao Dai, Jikun Cai, Pengfang Qian, Li Ji, Xinzhe He, Shiduo Zhang, Zhaoye Fei, et al. Libero-plus: In-depth robustness analysis of vision-language-action models.arXiv preprint arXiv:2510.13626, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Libero-x: Robustness litmus for vision-language-action models.arXiv preprint arXiv:2602.06556, 2026
Guodong Wang, Chenkai Zhang, Qingjie Liu, Jinjin Zhang, Jiancheng Cai, Junjie Liu, and Xinmin Liu. Libero-x: Robustness litmus for vision-language-action models.arXiv preprint arXiv:2602.06556, 2026
-
[21]
Safe: Multitask failure detection for vision-language-action models.Advances in Neural Information Processing Systems, 38:40041–40076, 2026
Qiao Gu, Yuanliang Ju, Shengxiang Sun, Igor Gilitschenski, Haruki Nishimura, Masha Itkina, and Florian Shkurti. Safe: Multitask failure detection for vision-language-action models.Advances in Neural Information Processing Systems, 38:40041–40076, 2026
2026
-
[22]
Alec Farid, David Snyder, Allen Z Ren, and Anirudha Majumdar. Failure prediction with statistical guarantees for vision-based robot control.arXiv preprint arXiv:2202.05894, 2022
-
[23]
Adaptive stress testing: Finding likely failure events with reinforcement learning.Journal of Artificial Intelligence Research, 69:1165–1201, 2020
Ritchie Lee, Ole J Mengshoel, Anshu Saksena, Ryan W Gardner, Daniel Genin, Joshua Silbermann, Michael Owen, and Mykel J Kochenderfer. Adaptive stress testing: Finding likely failure events with reinforcement learning.Journal of Artificial Intelligence Research, 69:1165–1201, 2020
2020
-
[24]
Efficient online testing for dnn-enabled systems using surrogate-assisted and many-objective optimization
Fitash Ul Haq, Donghwan Shin, and Lionel Briand. Efficient online testing for dnn-enabled systems using surrogate-assisted and many-objective optimization. InProceedings of the 44th international conference on software engineering, pages 811–822, 2022
2022
-
[25]
Metamorphic testing of vision-language action-enabled robots
Pablo Valle, Sergio Segura, Shaukat Ali, and Aitor Arrieta. Metamorphic testing of vision-language action-enabled robots. InProceedings of the 19th IEEE International Conference on Software Testing, Verification and Validation (ICST 2026), Daejeon, Republic of Korea, May 2026. IEEE.https://arxiv.org/abs/2602.22579
-
[26]
Wilbert Pumacay, Ishika Singh, Jiafei Duan, Ranjay Krishna, Jesse Thomason, and Dieter Fox. The colosseum: A benchmark for evaluating generalization for robotic manipulation.arXiv preprint arXiv:2402.08191, 2024
-
[27]
Coverage-guided fuzz testing for cyber-physical systems
Sanaz Sheikhi, Edward Kim, Parasara Sridhar Duggirala, and Stanley Bak. Coverage-guided fuzz testing for cyber-physical systems. In2022 ACM/IEEE 13th International Conference on Cyber-Physical Systems (ICCPS), pages 24–33. IEEE, 2022
2022
-
[28]
Roboarena: Distributed real-world evaluation of generalist robot policies
Pranav Atreya, Karl Pertsch, Tony Lee, Moo Jin Kim, Arhan Jain, Artur Kuramshin, Clemens Eppner, Cyrus Neary, Edward Hu, Fabio Ramos, et al. Roboarena: Distributed real-world evaluation of generalist robot policies. arXiv preprint arXiv:2506.18123, 2025
-
[29]
Evaluating Real-World Robot Manipulation Policies in Simulation
Xuanlin Li, Kyle Hsu, Jiayuan Gu, Karl Pertsch, Oier Mees, Homer Rich Walke, Chuyuan Fu, Ishikaa Lunawat, Isabel Sieh, Sean Kirmani, Sergey Levine, Jiajun Wu, Chelsea Finn, Hao Su, Quan Vuong, and Ted Xiao. Evaluating real-world robot manipulation policies in simulation.arXiv preprint arXiv:2405.05941, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
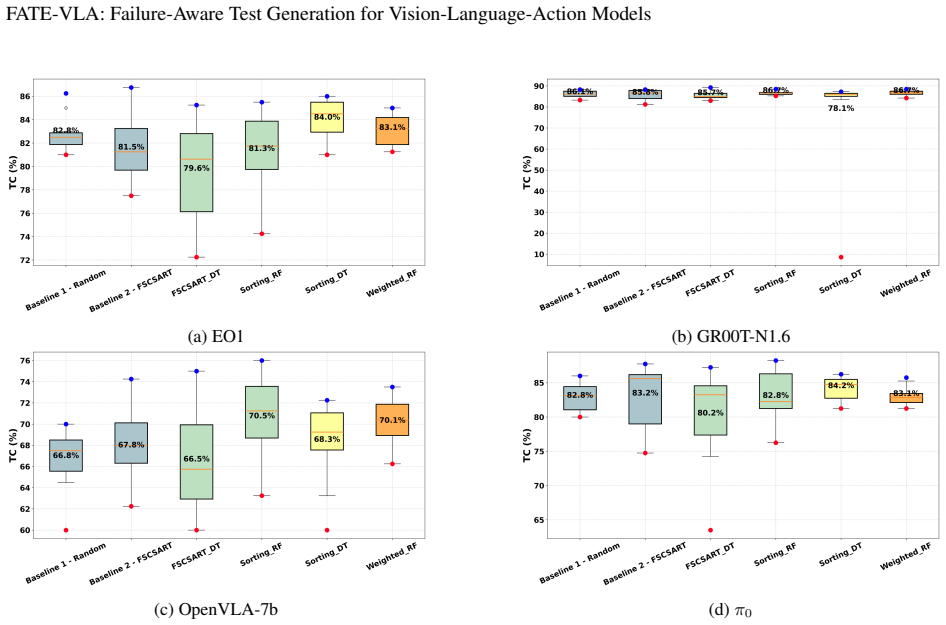
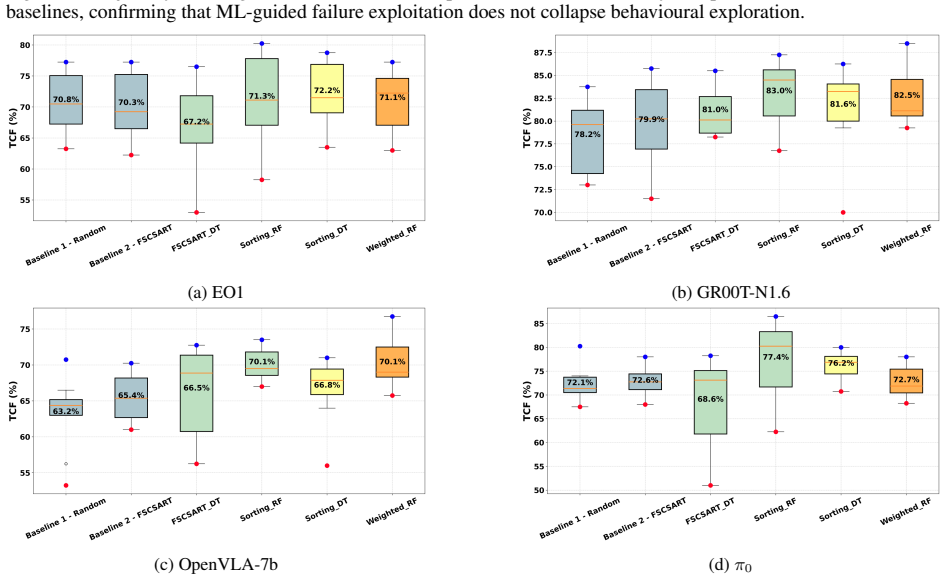
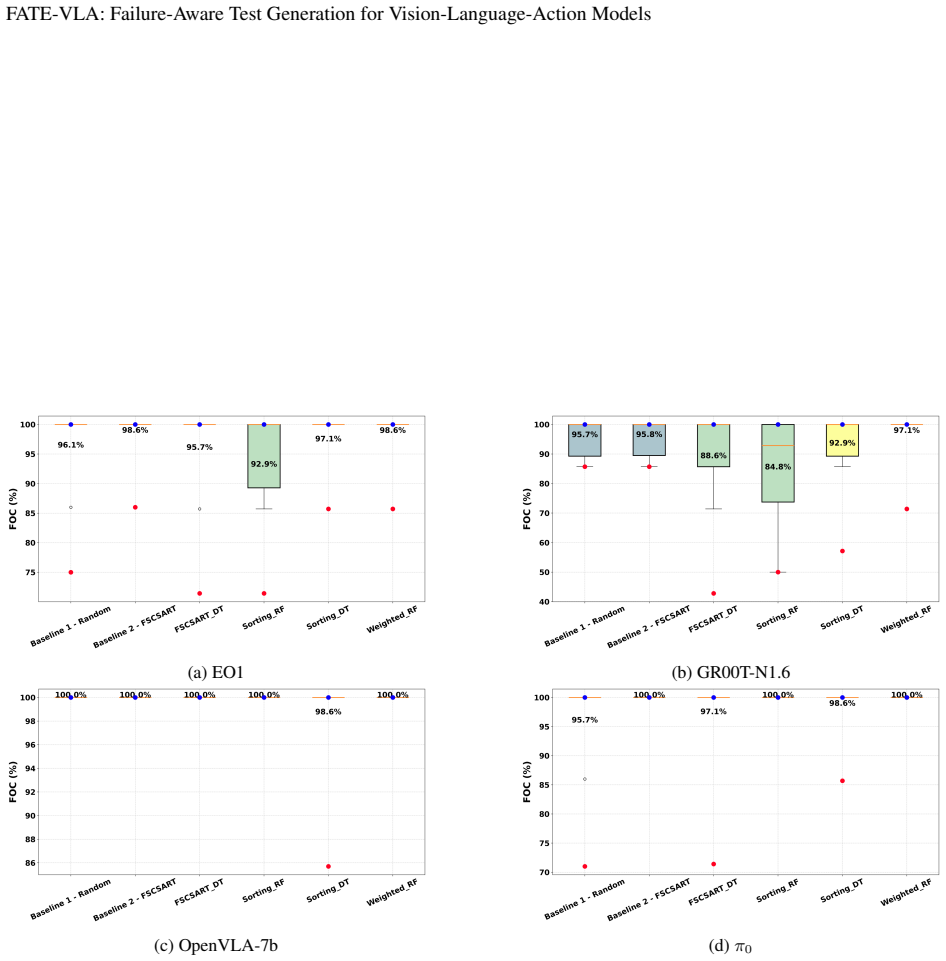
Pablo Valle, Chengjie Lu, Shaukat Ali, and Aitor Arrieta. Evaluating uncertainty and quality of visual language action-enabled robots.arXiv preprint arXiv:2507.17049, 2025. 9 FATE-VLA: Failure-Aware Test Generation for Vision-Language-Action Models A RQ1: Performance Against Both Baselines RQ1 serves as a sanity check for both our proposed ML-guided algor...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.