Forget Attention: Importance-Aware Attention Is All You Need
Pith reviewed 2026-06-28 14:36 UTC · model grok-4.3
The pith
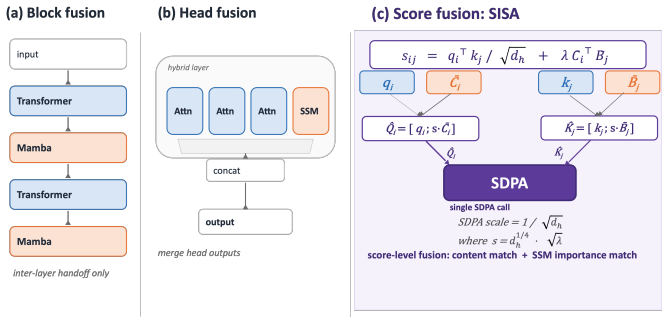
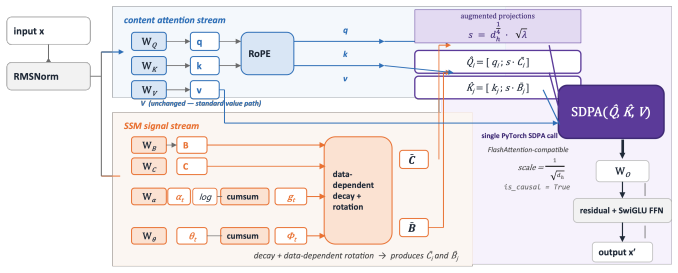
SISA adds an SSM-derived importance term inside attention scores and computes the full operation as one standard SDPA call on augmented query and key vectors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
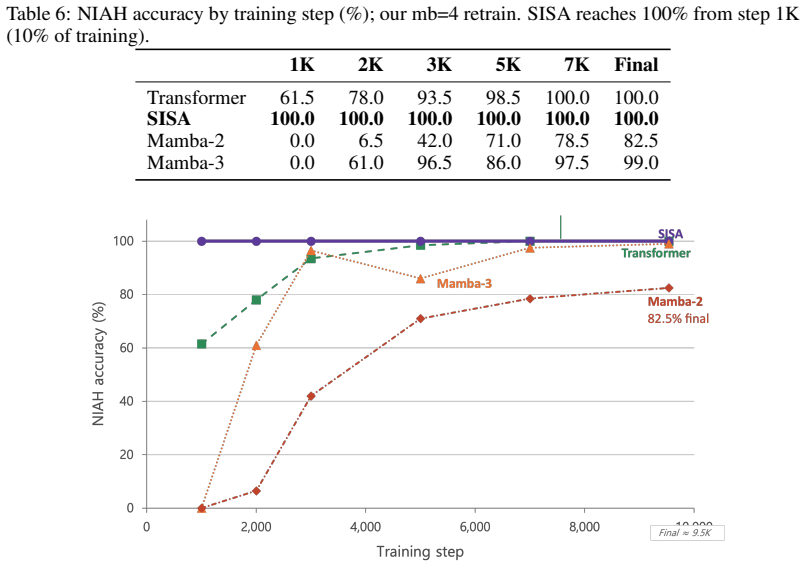
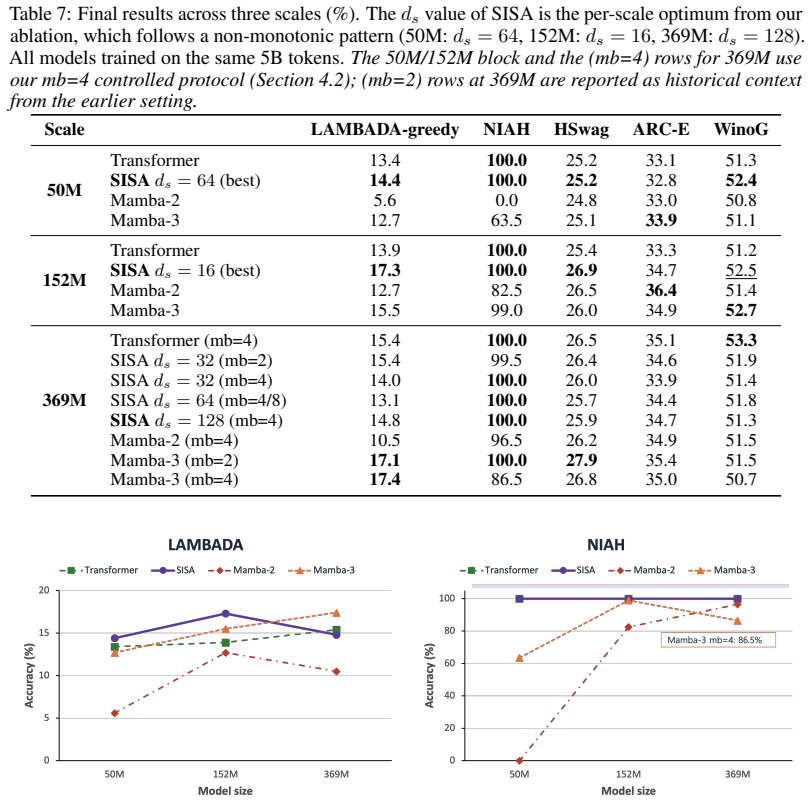
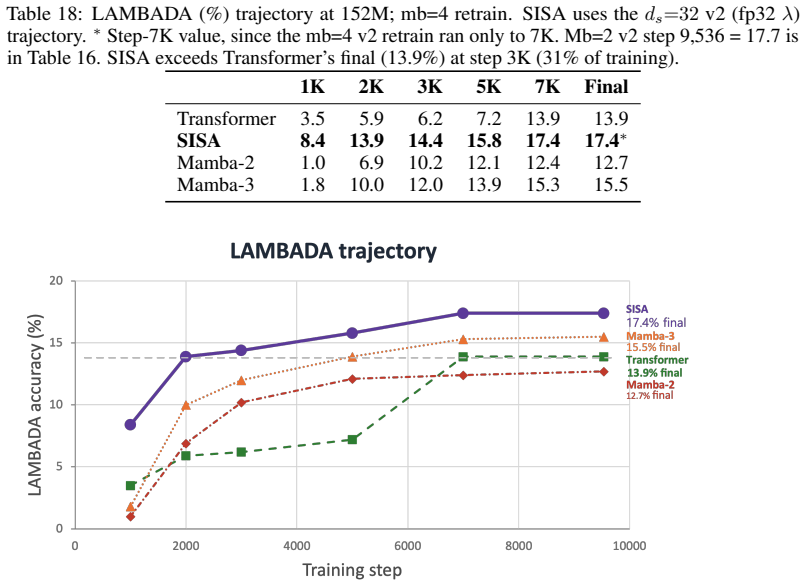
SISA integrates an importance term derived from state space models directly into the softmax attention computation by augmenting the query and key vectors, allowing the entire operation to be performed as a single scaled dot-product attention call without recurrent states or custom kernels. This score-level fusion enables the model to prioritize important tokens while maintaining global retrieval capability. At 152M parameters trained on 5B tokens, SISA reaches 17.3% on LAMBADA-greedy versus 13.9% for a Transformer and 15.5% for Mamba-3, while attaining 100% needle-in-a-haystack accuracy from step 1K, seven times faster than the Transformer baseline.
What carries the argument
SISA, the direct insertion of an SSM-derived importance term into attention scores via augmentation of query and key vectors before a single SDPA operation.
If this is right
- At the tested scales, SISA produces higher LAMBADA-greedy accuracy than both a standard Transformer and a Mamba-3 baseline.
- SISA reaches perfect needle-in-a-haystack retrieval from the first thousand steps, converging seven times faster than a Transformer.
- At 369M parameters, SISA keeps perfect needle-in-a-haystack performance while remaining compatible with stock SDPA execution.
- The method requires no recurrent state and no custom kernel, preserving the execution path of ordinary scaled dot-product attention.
Where Pith is reading between the lines
- Score-level fusion could be tested by deriving the importance term from sources other than SSMs to see whether the performance pattern generalizes.
- The single-call property might allow direct substitution into existing Transformer training pipelines without kernel modifications.
- If the importance term scales with model size, the approach could reduce reliance on block-level or head-level hybrid designs in larger models.
Load-bearing premise
An SSM-derived importance signal can be pre-computed or jointly computed so that it improves attention scores without new hyperparameters, extra passes, or changes that affect numerical stability or scaling behavior.
What would settle it
Zero out the importance term in the augmented vectors and measure whether LAMBADA and needle-in-a-haystack performance fall back to the levels of an unmodified Transformer at the same scale and training budget.
Figures
read the original abstract
Combining attention's global retrieval with the sequential importance signal of state space models (SSMs) is the open challenge of hybrid language modeling. Transformers see everywhere but cannot prioritize; SSMs know what matters but cannot revisit. Existing hybrids -- Jamba (block level) and Hymba (head level) -- place the two in separate compartments, so neither informs the other during the attention computation itself. We propose SISA (SSM-Informed Softmax Attention), which adds an SSM-derived importance term directly inside the attention score and realizes the full operation as a single SDPA call on augmented query/key vectors -- no recurrent state, no custom kernel. At 152M / 5B tokens, SISA reaches LAMBADA-greedy 17.3% (vs. Transformer 13.9 and Mamba-3 15.5) and attains NIAH 100% from step 1K, 7x faster than Transformer's retrieval convergence; at 369M, Mamba-3 leads LAMBADA while SISA preserves perfect NIAH and stock-SDPA execution. SISA thus defines a third design axis for SSM-attention hybrids -- score-level fusion -- beyond the block-level and head-level paradigms that have dominated the field.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SISA (SSM-Informed Softmax Attention) as a score-level fusion method for SSM-attention hybrids. It augments query and key vectors with an SSM-derived importance term so that the full attention operation executes as a single standard SDPA call, without recurrent state or custom kernels. At 152M parameters trained on 5B tokens, SISA reports LAMBADA-greedy accuracy of 17.3% (vs. 13.9% Transformer, 15.5% Mamba-3) and perfect NIAH retrieval from step 1K (7x faster convergence than Transformer); at 369M it preserves perfect NIAH while Mamba-3 leads on LAMBADA. The work positions this as a third design axis beyond existing block-level and head-level hybrids.
Significance. If the reported gains are reproducible, the contribution would be meaningful: it supplies a lightweight, kernel-free mechanism for injecting sequential importance directly into attention scores. This could simplify hybrid architecture design and improve retrieval without sacrificing the global access of attention. The absence of any training protocol, baseline code, or statistical controls, however, prevents assessment of whether the numerical improvements are robust or merely artifacts of a single run.
major comments (2)
- [Abstract] Abstract: the central performance claims (LAMBADA 17.3%, NIAH 100% from step 1K, 7x faster convergence) rest on benchmark numbers supplied without any description of training hyperparameters, optimizer settings, baseline re-implementations, number of random seeds, or statistical tests. These omissions are load-bearing for the empirical superiority argument.
- [Method] Method description: the assertion that an SSM-derived importance signal can be obtained and injected via simple Q/K augmentation while preserving exact SDPA semantics, scaling, and numerical stability is stated without an explicit algorithm, pseudocode, or verification that no additional passes or hyper-parameters are introduced. This detail is required to substantiate the “stock-SDPA execution” claim.
minor comments (1)
- [Abstract] Abstract: the parenthetical comparison omits the percent sign after the Transformer and Mamba-3 numbers; consistent formatting would improve readability.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater transparency in both the experimental protocol and the method description. We will revise the manuscript to incorporate the requested details, which will strengthen the reproducibility of the work.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claims (LAMBADA 17.3%, NIAH 100% from step 1K, 7x faster convergence) rest on benchmark numbers supplied without any description of training hyperparameters, optimizer settings, baseline re-implementations, number of random seeds, or statistical tests. These omissions are load-bearing for the empirical superiority argument.
Authors: We agree that the reported performance numbers require supporting experimental details to allow proper evaluation. In the revised manuscript we will add a dedicated Experimental Setup section that specifies all training hyperparameters (learning rate schedule, batch size, sequence length, optimizer), the exact re-implementations of the Transformer and Mamba-3 baselines, the number of random seeds, and any statistical tests or variance reporting used. This addition will directly address the concern that the current claims rest on insufficiently documented runs. revision: yes
-
Referee: [Method] Method description: the assertion that an SSM-derived importance signal can be obtained and injected via simple Q/K augmentation while preserving exact SDPA semantics, scaling, and numerical stability is stated without an explicit algorithm, pseudocode, or verification that no additional passes or hyper-parameters are introduced. This detail is required to substantiate the “stock-SDPA execution” claim.
Authors: We accept that an explicit algorithmic description is necessary to substantiate the claim of stock-SDPA execution. The revised manuscript will include a new Algorithm box (or pseudocode listing) that details (1) how the SSM importance term is computed from the input sequence, (2) the precise concatenation/augmentation of the query and key vectors, and (3) confirmation that the resulting operation remains a single call to standard scaled-dot-product attention with no extra forward passes or introduced hyperparameters. This will make the “kernel-free” and “exact SDPA semantics” properties verifiable. revision: yes
Circularity Check
No significant circularity; proposal is an empirical architectural change
full rationale
The paper presents SISA as a direct implementation: an SSM-derived importance term is added inside attention scores and realized via augmented Q/K vectors in one standard SDPA call. The abstract and description contain no equations, fitted parameters renamed as predictions, self-citations used as load-bearing uniqueness theorems, or ansatzes smuggled from prior author work. No derivation chain reduces the claimed improvement (LAMBADA/NIAH gains) to a self-referential definition or statistical forcing. The construction is presented as a vector-level fusion choice that preserves existing SDPA semantics, making the central claim self-contained against external benchmarks rather than circular by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Vaswani, A., et al. (2017). Attention is all you need.NeurIPS
2017
-
[2]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Gu, A. & Dao, T. (2023). Mamba: Linear-time sequence modeling with selective state spaces. arXiv:2312.00752
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Dao, T. & Gu, A. (2024). Transformers are SSMs.ICML. arXiv:2405.21060. 9
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Y ., Chen, B., Wang, C., Bick, A., Kolter, J
Lahoti, A., Li, K. Y ., Chen, B., Wang, C., Bick, A., Kolter, J. Z., Dao, T., & Gu, A. (2026). Mamba-3: Improved Sequence Modeling using State Space Principles.ICLR. arXiv:2603.15569
-
[5]
Lieber, O., et al. (2024). Jamba. arXiv:2403.19887
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [6]
- [7]
- [8]
-
[9]
Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models
De, S., Smith, S. L., Fernando, A., et al. (2024). Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models. arXiv:2402.19427
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation
Press, O., Smith, N. A., & Lewis, M. (2022). Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation.ICLR. arXiv:2108.12409
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y ., Li, W., & Liu, P. J. (2020). Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. JMLR, 21(140), 1–67
2020
- [12]
-
[13]
Lin, Z., Nikishin, E., He, X. O., & Courville, A. (2025). Forgetting Transformer: Softmax Attention with a Forget Gate.ICLR. arXiv:2503.02130
- [14]
-
[15]
R., Hestness, J., & Dey, N
Soboleva, D., Al-Khateeb, F., Myers, R., Steeves, J. R., Hestness, J., & Dey, N. (2023). SlimPajama: A 627B token cleaned and deduplicated version of RedPajama.Cerebras Systems
2023
-
[16]
Hoffmann, J., et al. (2022). Training compute-optimal large language models. arXiv:2203.15556
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[17]
N., Bernardi, R., Pezzelle, S., Baroni, M., Boleda, G., & Fernández, R
Paperno, D., Kruszewski, G., Lazaridou, A., Pham, Q. N., Bernardi, R., Pezzelle, S., Baroni, M., Boleda, G., & Fernández, R. (2016). The LAMBADA Dataset: Word Prediction Requiring a Broad Discourse Context.ACL
2016
-
[18]
Zellers, R., Holtzman, A., Bisk, Y ., Farhadi, A., & Choi, Y . (2019). HellaSwag: Can a Machine Really Finish Your Sentence?ACL
2019
-
[19]
Clark, P., Cowhey, I., Etzioni, O., Khot, T., Sabharwal, A., Schoenick, C., & Tafjord, O. (2018). Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge. arXiv:1803.05457
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[20]
Sakaguchi, K., Le Bras, R., Bhagavatula, C., & Choi, Y . (2020). WinoGrande: An Adversarial Winograd Schema Challenge at Scale.AAAI
2020
- [21]
- [22]
- [23]
- [24]
-
[25]
Waleffe, R., Byeon, W., Riach, D., Norick, B., Korthikanti, V ., et al. (2024). An Empirical Study of Mamba-based Language Models. arXiv:2406.07887
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
IBM, Princeton, CMU, & UIUC. (2024). Bamba: Inference-Efficient Hybrid Mamba2 Model. Hugging Face release, December 18, 2024.https://huggingface.co/blog/bamba. A Per-Layer Parameter Budget Table 9: Per-layer parameter comparison at 152M. Component Transformer SISA WQ +W K +W V +W O 2,359,296 2,359,296 SSM projections (WB,W C ,w α,W θ, λ) 0 746,508 SwiGLU ...
2024
-
[27]
SDPA scale.Even though the augmented Q/K have dimension dh +d s, the SDPA scale must be 1/√dh,not 1/√dh +d s. Using PyTorch F.scaled_dot_product_attention’s default 1/√dh +d s breaks the equivalence in the proposition of Section 3.3, and the SISA score is no longer computed correctly: ˆQ⊤ i ˆKj√dh = q⊤ i kj√dh +λ· ¯C⊤ i ¯Bj (correct), ˆQ⊤ i ˆKj√dh +d s ̸=...
-
[28]
The minimax offset c= (max t gt + mint gt)/2 usually keeps |g−c| small, but during early-warmup spikes of α it may grow temporarily
bf16 numerical stability.If egi−c exceeds the bf16 max (65,504), it produces NaN. The minimax offset c= (max t gt + mint gt)/2 usually keeps |g−c| small, but during early-warmup spikes of α it may grow temporarily. We clamp g−c to [−11,11] (e11 ≈59,874<65,504 ). The clamp does not activate in normal training and has no effect on optimization
-
[29]
λ in fp32. λraw must be kept in fp32 to train. In bf16, the smallest representable change near −1.0 is 0.0078, far larger than the ∼10 −5 AdamW updates, so λ never moves from its initialization. Quantitative impact is reported in Appendix M. 11 D Mamba-3 Implementation We use the official Mamba-3 implementation now included in the mamba-ssm package. Earli...
-
[30]
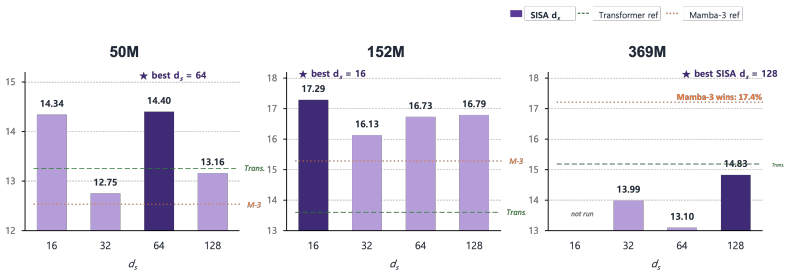
Intermediate values such as ds = 96 would refine the location of the 152M valley (currently ds = 16) and the 369M upward edge (currentlyd s = 128)
Intermediate ds values.The U-shape was observed for ds ∈ {16,32,64,128} . Intermediate values such as ds = 96 would refine the location of the 152M valley (currently ds = 16) and the 369M upward edge (currentlyd s = 128)
-
[31]
Scale-adaptive ds.Replacing the manual choice of ds with a learned mechanism (per-layer ds or sparse SSM channels)
-
[32]
Validation at1B+scale and ad s scaling law
-
[33]
Long-context training (with RoPE scaling). 19
-
[34]
Per-layer / per-head distribution ofλand task-specific patterns
-
[35]
SISA-2 (follow-up).Extending score-level fusion in two directions: (a) sigmoid-based SISA to address the softmax dilution observed in Section 6.2, and (b) deeper FFN–SSM integration toward a fully fused architecture without a separate block. 20
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.