Harness-1: Reinforcement Learning for Search Agents with State-Externalizing Harnesses
Pith reviewed 2026-06-28 14:23 UTC · model grok-4.3
The pith
Externalizing bookkeeping to an environment harness lets a 20B RL policy focus only on semantic search decisions and reach 0.730 average recall.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
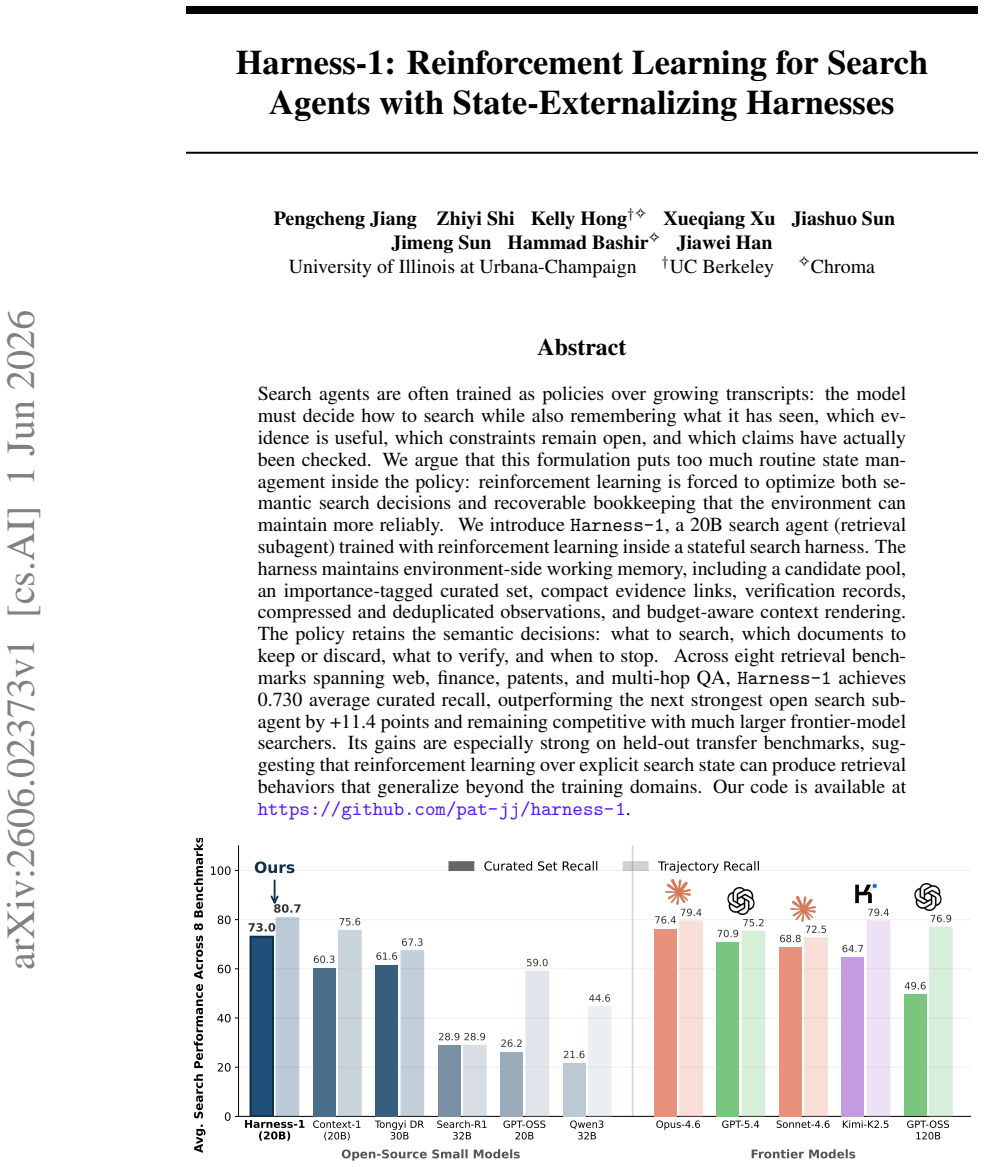
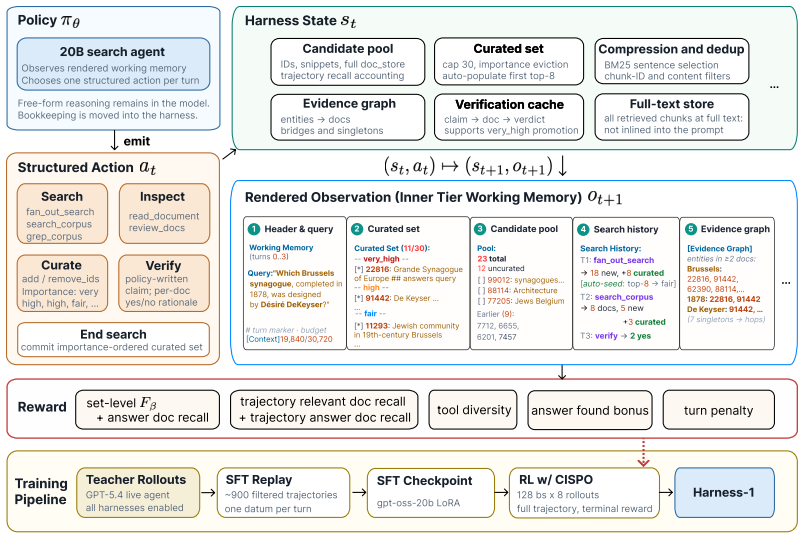
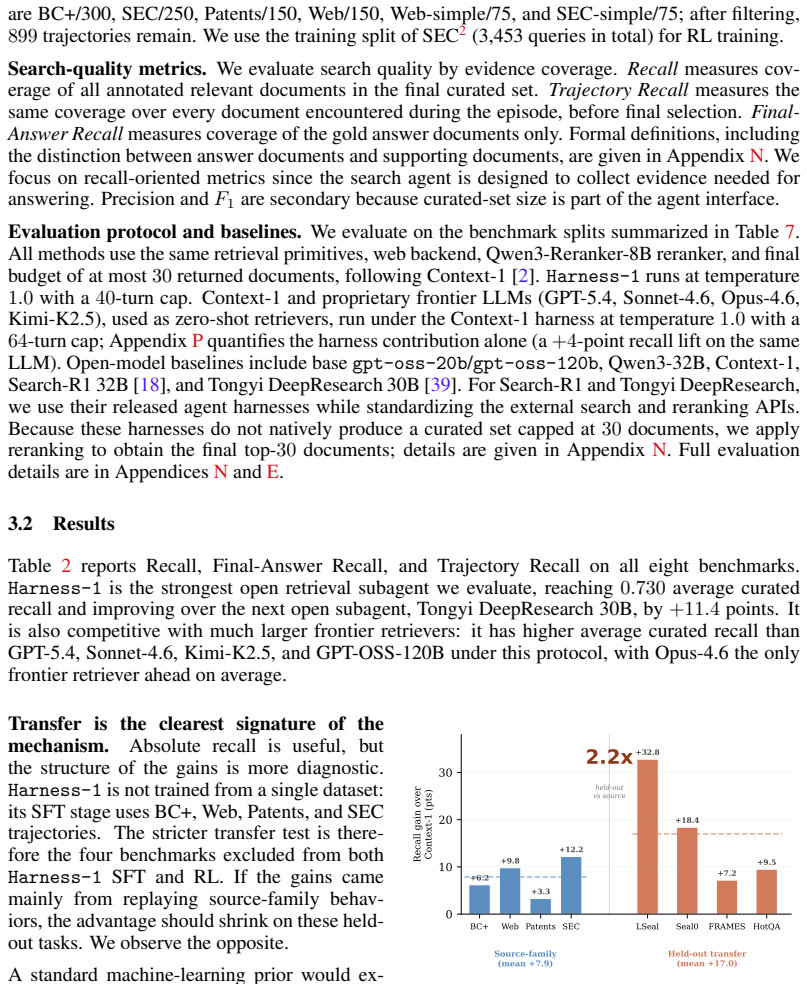
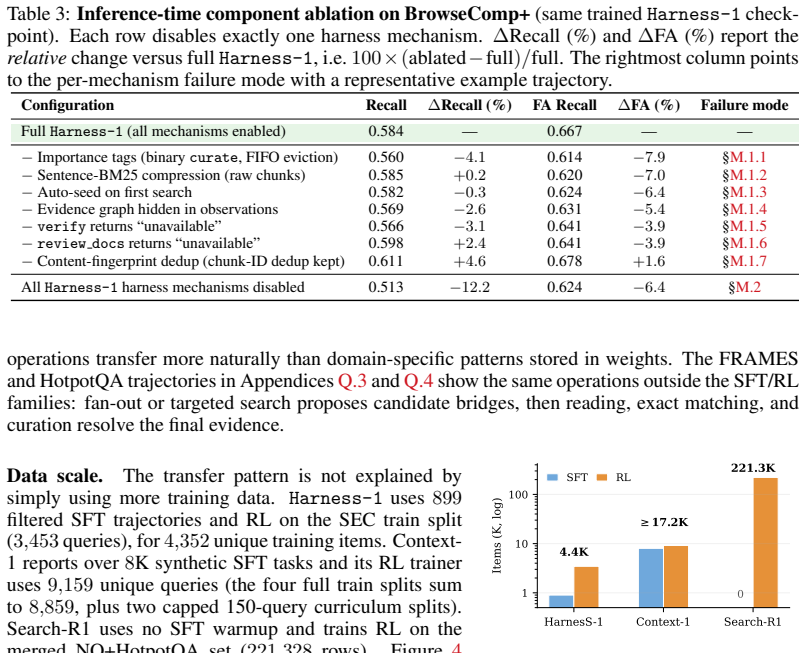
By placing working memory, importance-tagged curated sets, compact evidence links, verification records, and budget-aware rendering in the harness, reinforcement learning optimizes only the semantic decisions of search, keep-or-discard, verification, and stopping; the 20B policy trained this way attains 0.730 average curated recall across eight retrieval benchmarks and shows stronger transfer than transcript-based agents.
What carries the argument
The state-externalizing harness, which maintains environment-side working memory including candidate pools, curated evidence, verification records, and compressed observations so the policy handles only semantic choices.
If this is right
- The policy no longer expends capacity on recoverable bookkeeping and can allocate more parameters to semantic search.
- Retrieval behavior transfers better to unseen domains because state is explicit and consistent rather than reconstructed from transcripts.
- The same harness can pair with different policy sizes without retraining the state machinery.
- Verification records and importance tags become directly inspectable, allowing external auditing of the agent's reasoning trace.
Where Pith is reading between the lines
- The separation may reduce state-related errors that currently appear as hallucinations in transcript-only agents.
- Similar harness designs could be tested on non-retrieval agent tasks such as tool-use planning or multi-step reasoning where bookkeeping also competes with core decisions.
- Standardizing harness interfaces might let multiple research groups swap policies while keeping the same state infrastructure.
Load-bearing premise
The harness maintains working memory, candidate pools, evidence links, and verification records more reliably than the policy can inside its transcript.
What would settle it
Train the identical 20B policy without the harness on the same eight benchmarks and measure whether average curated recall falls below 0.730 or loses its advantage on held-out domains.
Figures
read the original abstract
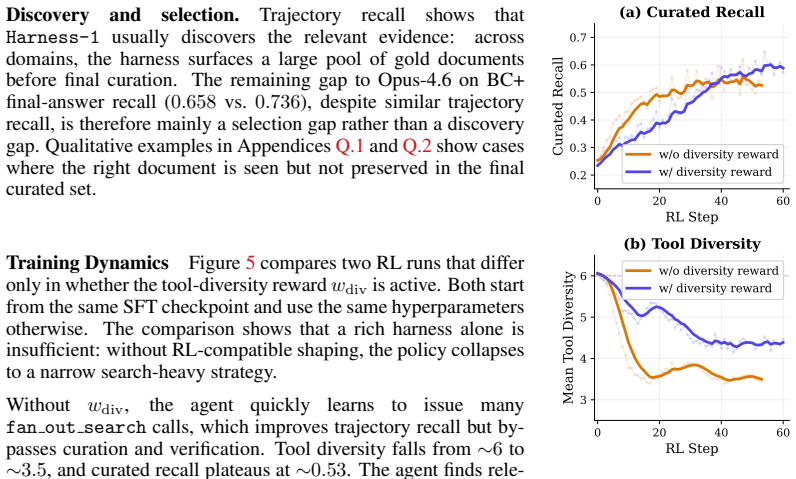
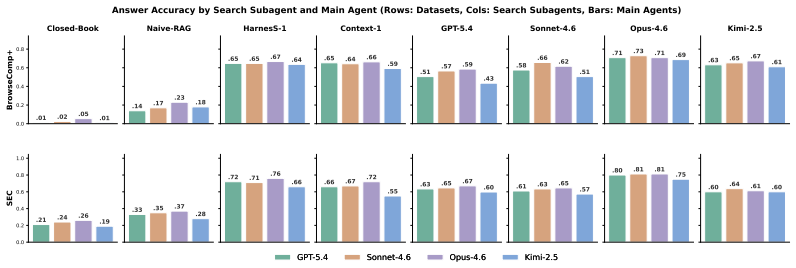
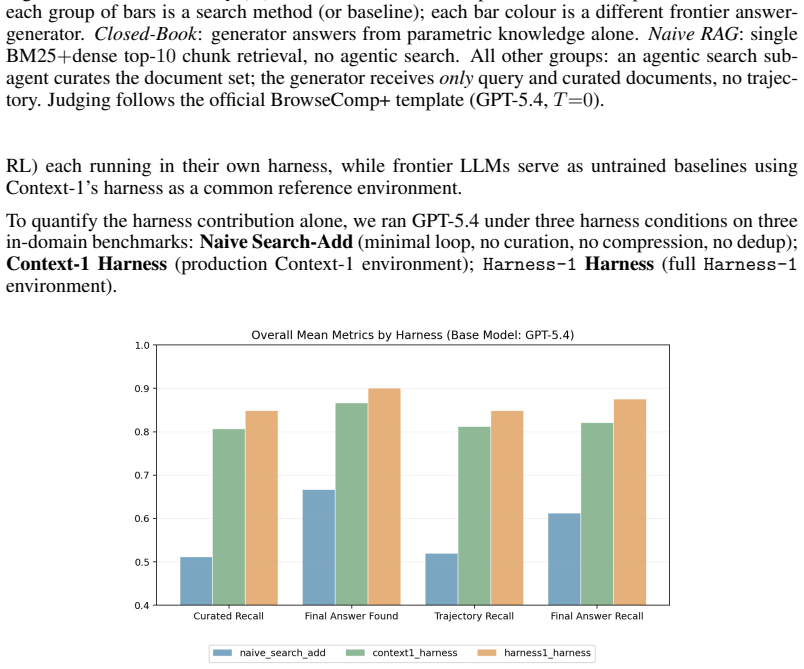
Search agents are often trained as policies over growing transcripts: the model must decide how to search while also remembering what it has seen, which evidence is useful, which constraints remain open, and which claims have actually been checked. We argue that this formulation puts too much routine state management inside the policy: reinforcement learning is forced to optimize both semantic search decisions and recoverable bookkeeping that the environment can maintain more reliably. We introduce Harness-1, a 20B search agent (retrieval subagent) trained with reinforcement learning inside a stateful search harness. The harness maintains environment-side working memory, including a candidate pool, an importance-tagged curated set, compact evidence links, verification records, compressed and deduplicated observations, and budget-aware context rendering. The policy retains the semantic decisions: what to search, which documents to keep or discard, what to verify, and when to stop. Across eight retrieval benchmarks spanning web, finance, patents, and multi-hop QA, Harness-1 achieves 0.730 average curated recall, outperforming the next strongest open search subagent by +11.4 points and remaining competitive with much larger frontier-model searchers. Its gains are especially strong on held-out transfer benchmarks, suggesting that reinforcement learning over explicit search state can produce retrieval behaviors that generalize beyond the training domains. Our code is available at https://github.com/pat-jj/harness-1.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Harness-1, a 20B-parameter retrieval subagent trained via reinforcement learning inside a stateful search harness. The harness externalizes working memory, candidate pools, evidence links, verification records, and budget-aware rendering, while the policy is restricted to semantic actions (search, keep/discard, verify, stop). Across eight benchmarks (web, finance, patents, multi-hop QA), it reports 0.730 average curated recall, +11.4 points above the next strongest open subagent, competitive with larger frontier models, and strong transfer to held-out domains. Code is stated to be released.
Significance. If the empirical claims hold after full evaluation details are supplied, the work would provide concrete evidence that environment-side state externalization can improve sample efficiency and generalization in RL for search agents by freeing the policy from bookkeeping. The public code release would be a notable strength, allowing direct testing of the central hypothesis.
major comments (2)
- [Abstract] Abstract: the central performance claim (0.730 curated recall, +11.4 over next open subagent) is presented without any description of training procedure, reward formulation, baseline implementations, number of runs, or statistical tests, rendering the result impossible to evaluate from the supplied text.
- [Abstract] Abstract and §3 (implied methods): no definition or computation details are given for 'curated recall' or how the harness's importance-tagged set is constructed and scored, which is load-bearing for the reported metric and the transfer claim.
minor comments (1)
- [Abstract] The abstract states code availability but provides no link or repository details beyond the GitHub URL; this should be expanded with commit hash or exact reproduction instructions in the final version.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. The comments highlight opportunities to strengthen the abstract's self-containment. We address each point below and will revise the abstract accordingly while preserving its length constraints.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claim (0.730 curated recall, +11.4 over next open subagent) is presented without any description of training procedure, reward formulation, baseline implementations, number of runs, or statistical tests, rendering the result impossible to evaluate from the supplied text.
Authors: We agree the abstract is currently too terse on these points. The full manuscript details the RL training (PPO on semantic actions only), reward as a combination of curated-recall improvement and budget penalty, baselines (including the next open subagent), and evaluation over 5 seeds with reported standard deviations. In revision we will insert a single sentence in the abstract summarizing the training regime, reward, and evaluation protocol without exceeding length limits. revision: yes
-
Referee: [Abstract] Abstract and §3 (implied methods): no definition or computation details are given for 'curated recall' or how the harness's importance-tagged set is constructed and scored, which is load-bearing for the reported metric and the transfer claim.
Authors: The manuscript defines curated recall in §3.2 as the fraction of query-relevant facts recovered in the harness-maintained importance-tagged set, where importance is computed from verification records and semantic overlap with the query. The set is populated by the keep/discard and verify actions and scored via an external judge. We acknowledge the abstract omits even a brief gloss; the revision will add one clause defining the metric and noting that the harness (not the policy) maintains the tagged set. revision: yes
Circularity Check
No significant circularity
full rationale
The manuscript describes an empirical RL system for retrieval subagents in which a stateful harness externalizes bookkeeping (candidate pools, evidence links, verification records) while the policy optimizes only semantic actions. No equations, fitted parameters, or derivation steps are presented that reduce by construction to the inputs; results are reported as direct benchmark outcomes (0.730 average curated recall across eight domains) with code release. No self-citation chains or ansatzes are invoked as load-bearing premises. The central distinction between harness and policy is stated directly and remains independently testable.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Retrieval-augmented generation for knowledge-intensive NLP tasks , year =
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K\". Retrieval-augmented generation for knowledge-intensive NLP tasks , year =. Proceedings of the 34th International Conference on Neural Information Processing Systems , articleno =
-
[2]
2026 , eprint=
Steer2Adapt: Dynamically Composing Steering Vectors Elicits Efficient Adaptation of LLMs , author=. 2026 , eprint=
2026
-
[3]
2023 , eprint=
Measuring Faithfulness in Chain-of-Thought Reasoning , author=. 2023 , eprint=
2023
-
[4]
, title =
Turpin, Miles and Michael, Julian and Perez, Ethan and Bowman, Samuel R. , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 , publisher =
2023
-
[5]
2025 , eprint=
The Personality Illusion: Revealing Dissociation Between Self-Reports & Behavior in LLMs , author=. 2025 , eprint=
2025
-
[7]
2025 , eprint=
Atom-Searcher: Enhancing Agentic Deep Research via Fine-Grained Atomic Thought Reward , author=. 2025 , eprint=
2025
-
[8]
2025 , eprint=
REINFORCE++: Stabilizing Critic-Free Policy Optimization with Global Advantage Normalization , author=. 2025 , eprint=
2025
-
[9]
2025 , eprint=
MEM1: Learning to Synergize Memory and Reasoning for Efficient Long-Horizon Agents , author=. 2025 , eprint=
2025
-
[10]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
DecoupleSearch: Decouple Planning and Search via Hierarchical Reward Modeling , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[11]
2026 , eprint=
APEX-Searcher: Augmenting LLMs' Search Capabilities through Agentic Planning and Execution , author=. 2026 , eprint=
2026
-
[12]
2025 , eprint=
WebSailor: Navigating Super-human Reasoning for Web Agent , author=. 2025 , eprint=
2025
-
[13]
2025 , eprint=
WebDancer: Towards Autonomous Information Seeking Agency , author=. 2025 , eprint=
2025
-
[14]
2025 , eprint=
From Web Search towards Agentic Deep Research: Incentivizing Search with Reasoning Agents , author=. 2025 , eprint=
2025
-
[15]
Proceedings of the ACM on Software Engineering , volume=
Demystifying llm-based software engineering agents , author=. Proceedings of the ACM on Software Engineering , volume=. 2025 , publisher=
2025
-
[16]
2023 , eprint=
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs , author=. 2023 , eprint=
2023
-
[17]
2025 , eprint=
DAPO: An Open-Source LLM Reinforcement Learning System at Scale , author=. 2025 , eprint=
2025
-
[18]
Zheng, Yuxiang and Fu, Dayuan and Hu, Xiangkun and Cai, Xiaojie and Ye, Lyumanshan and Lu, Pengrui and Liu, Pengfei. D eep R esearcher: Scaling Deep Research via Reinforcement Learning in Real-world Environments. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.22
-
[19]
ToolRL: Reward is All Tool Learning Needs
Toolrl: Reward is all tool learning needs , author=. arXiv preprint arXiv:2504.13958 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Zhang, Ruoyu and Ma, Shirong and Bi, Xiao and Zhang, Xiaokang and Yu, Xingkai and Wu, Yu and Wu, Z. F. and Gou, Zhibin and Shao, Zhihong and Li, Zhuoshu and Gao, Ziyi and Liu, Aixin and Xue, Bing and Wang, Bingxuan and Wu, Bochao and Feng, Bei ...
-
[21]
and Finn, Chelsea , title =
Rafailov, Rafael and Sharma, Archit and Mitchell, Eric and Ermon, Stefano and Manning, Christopher D. and Finn, Chelsea , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 , publisher =
2023
-
[22]
2017 , eprint=
Proximal Policy Optimization Algorithms , author=. 2017 , eprint=
2017
-
[23]
2025 , eprint=
Beyond Ten Turns: Unlocking Long-Horizon Agentic Search with Large-Scale Asynchronous RL , author=. 2025 , eprint=
2025
-
[26]
2025 , eprint=
ReSearch: Learning to Reason with Search for LLMs via Reinforcement Learning , author=. 2025 , eprint=
2025
-
[28]
Li, Xiaoxi and Dong, Guanting and Jin, Jiajie and Zhang, Yuyao and Zhou, Yujia and Zhu, Yutao and Zhang, Peitian and Dou, Zhicheng. Search-o1: Agentic Search-Enhanced Large Reasoning Models. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.276
-
[29]
2026 , eprint=
AutoHarness: improving LLM agents by automatically synthesizing a code harness , author=. 2026 , eprint=
2026
-
[32]
2025 , eprint=
ToolOrchestra: Elevating Intelligence via Efficient Model and Tool Orchestration , author=. 2025 , eprint=
2025
-
[33]
2026 , publisher=
Harness Engineering for Language Agents: The Harness Layer as Control, Agency, and Runtime , author=. 2026 , publisher=
2026
-
[35]
2026 , month = apr, howpublished =
Scaling Managed Agents: Decoupling the Brain from the Hands , author =. 2026 , month = apr, howpublished =
2026
-
[36]
OpenAI engineering note , year=
Harness engineering: leveraging codex in an agent-first world , author=. OpenAI engineering note , year=
-
[38]
Prabha, D., Aswini, J., Maheswari, B., Subramanian, R
Press, Ofir and Zhang, Muru and Min, Sewon and Schmidt, Ludwig and Smith, Noah and Lewis, Mike. Measuring and Narrowing the Compositionality Gap in Language Models. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.378
-
[39]
Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions , author=. Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
-
[40]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
Active retrieval augmented generation , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
2023
-
[42]
s3: You Don ' t Need That Much Data to Train a Search Agent via RL
Jiang, Pengcheng and Xu, Xueqiang and Lin, Jiacheng and Xiao, Jinfeng and Wang, Zifeng and Sun, Jimeng and Han, Jiawei. s3: You Don ' t Need That Much Data to Train a Search Agent via RL. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1095
-
[43]
2025 , eprint=
WebExplorer: Explore and Evolve for Training Long-Horizon Web Agents , author=. 2025 , eprint=
2025
-
[44]
Cognition AI , title =
-
[45]
2026 , month =
Chroma Context-1: Training a Self-Editing Search Agent , author =. 2026 , month =
2026
-
[47]
2025 , eprint=
The Art of Scaling Reinforcement Learning Compute for LLMs , author=. 2025 , eprint=
2025
-
[48]
2024 , eprint=
MemGPT: Towards LLMs as Operating Systems , author=. 2024 , eprint=
2024
-
[49]
2026 , eprint=
ReSum: Unlocking Long-Horizon Search Intelligence via Context Summarization , author=. 2026 , eprint=
2026
-
[50]
Recursive language models , author=. arXiv preprint arXiv:2512.24601 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
Transactions of the association for computational linguistics , volume=
Lost in the middle: How language models use long contexts , author=. Transactions of the association for computational linguistics , volume=
-
[52]
2025 , month =
Context Rot: How Increasing Input Tokens Impacts LLM Performance , author =. 2025 , month =
2025
-
[53]
Advances in neural information processing systems , volume=
Toolformer: Language models can teach themselves to use tools , author=. Advances in neural information processing systems , volume=
-
[55]
2025 , eprint=
gpt-oss-120b & gpt-oss-20b Model Card , author=. 2025 , eprint=
2025
-
[56]
Advances in Neural Information Processing Systems , volume=
Swe-agent: Agent-computer interfaces enable automated software engineering , author=. Advances in Neural Information Processing Systems , volume=
-
[57]
BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents
Browsecomp: A simple yet challenging benchmark for browsing agents , author=. arXiv preprint arXiv:2504.12516 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[58]
2025 , eprint=
BrowseComp-Plus: A More Fair and Transparent Evaluation Benchmark of Deep-Research Agent , author=. 2025 , eprint=
2025
-
[60]
Fact, fetch, and reason: A unified evaluation of retrieval-augmented generation , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[61]
Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
HotpotQA: A dataset for diverse, explainable multi-hop question answering , author=. Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
2018
-
[62]
Humanity's last exam , author=. arXiv preprint arXiv:2501.14249 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[63]
2026 , eprint=
Adaptation of Agentic AI: A Survey of Post-Training, Memory, and Skills , author=. 2026 , eprint=
2026
-
[65]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Rearank: Reasoning re-ranking agent via reinforcement learning , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[66]
Introducing swe-grep and swe-grep-mini: Rl for multi-turn, fast context retrieval
Cognition AI. Introducing swe-grep and swe-grep-mini: Rl for multi-turn, fast context retrieval. Cognition technical report, 2025
2025
-
[67]
Chroma context-1: Training a self-editing search agent
Hammad Bashir, Kelly Hong, Patrick Jiang, and Zhiyi Shi. Chroma context-1: Training a self-editing search agent. Technical report, Chroma, March 2026
2026
-
[68]
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Aili Chen, Aonian Li, Bangwei Gong, Binyang Jiang, Bo Fei, Bo Yang, Boji Shan, Changqing Yu, Chao Wang, Cheng Zhu, et al. Minimax-m1: Scaling test-time compute efficiently with lightning attention. arXiv preprint arXiv:2506.13585 , 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[69]
Apex-searcher: Augmenting llms' search capabilities through agentic planning and execution, 2026
Kun Chen, Qingchao Kong, Zhao Feifei, and Wenji Mao. Apex-searcher: Augmenting llms' search capabilities through agentic planning and execution, 2026
2026
-
[70]
Pan, Wen Zhang, Huajun Chen, Fan Yang, Zenan Zhou, and Weipeng Chen
Mingyang Chen, Linzhuang Sun, Tianpeng Li, Haoze Sun, Yijie Zhou, Chenzheng Zhu, Haofen Wang, Jeff Z. Pan, Wen Zhang, Huajun Chen, Fan Yang, Zenan Zhou, and Weipeng Chen. Research: Learning to reason with search for llms via reinforcement learning, 2025
2025
-
[71]
Browsecomp-plus: A more fair and transparent evaluation benchmark of deep-research agent, 2025
Zijian Chen, Xueguang Ma, Shengyao Zhuang, Ping Nie, Kai Zou, Andrew Liu, Joshua Green, Kshama Patel, Ruoxi Meng, Mingyi Su, Sahel Sharifymoghaddam, Yanxi Li, Haoran Hong, Xinyu Shi, Xuye Liu, Nandan Thakur, Crystina Zhang, Luyu Gao, Wenhu Chen, and Jimmy Lin. Browsecomp-plus: A more fair and transparent evaluation benchmark of deep-research agent, 2025
2025
-
[72]
Atom-searcher: Enhancing agentic deep research via fine-grained atomic thought reward, 2025
Yong Deng, Guoqing Wang, Zhenzhe Ying, Xiaofeng Wu, Jinzhen Lin, Wenwen Xiong, Yuqin Dai, Shuo Yang, Zhanwei Zhang, Qiwen Wang, Yang Qin, Yuan Wang, Quanxing Zha, Sunhao Dai, and Changhua Meng. Atom-searcher: Enhancing agentic deep research via fine-grained atomic thought reward, 2025
2025
-
[73]
Beyond ten turns: Unlocking long-horizon agentic search with large-scale asynchronous rl, 2025
Jiaxuan Gao, Wei Fu, Minyang Xie, Shusheng Xu, Chuyi He, Zhiyu Mei, Banghua Zhu, and Yi Wu. Beyond ten turns: Unlocking long-horizon agentic search with large-scale asynchronous rl, 2025
2025
-
[74]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chong Ruan, Damai Dai, Deli Chen, Dongjie Ji, ...
2025
-
[75]
Michael Alvarez
Pengrui Han, Rafal Kocielnik, Peiyang Song, Ramit Debnath, Dean Mobbs, Anima Anandkumar, and R. Michael Alvarez. The personality illusion: Revealing dissociation between self-reports & behavior in llms, 2025
2025
-
[76]
Steer2adapt: Dynamically composing steering vectors elicits efficient adaptation of llms, 2026
Pengrui Han, Xueqiang Xu, Keyang Xuan, Peiyang Song, Siru Ouyang, Runchu Tian, Yuqing Jiang, Cheng Qian, Pengcheng Jiang, Jiashuo Sun, Junxia Cui, Ming Zhong, Ge Liu, Jiawei Han, and Jiaxuan You. Steer2adapt: Dynamically composing steering vectors elicits efficient adaptation of llms, 2026
2026
-
[77]
Context rot: How increasing input tokens impacts llm performance
Kelly Hong, Anton Troynikov, and Jeff Huber. Context rot: How increasing input tokens impacts llm performance. Technical report, Chroma, July 2025
2025
-
[78]
Reinforce++: Stabilizing critic-free policy optimization with global advantage normalization, 2025
Jian Hu, Jason Klein Liu, Haotian Xu, and Wei Shen. Reinforce++: Stabilizing critic-free policy optimization with global advantage normalization, 2025
2025
-
[79]
Pengcheng Jiang, Jiacheng Lin, Lang Cao, Runchu Tian, SeongKu Kang, Zifeng Wang, Jimeng Sun, and Jiawei Han. Deepretrieval: Hacking real search engines and retrievers with large language models via reinforcement learning. arXiv preprint arXiv:2503.00223 , 2025
-
[80]
Adaptation of agentic ai: A survey of post-training, memory, and skills, 2026
Pengcheng Jiang, Jiacheng Lin, Zhiyi Shi, Zifeng Wang, Luxi He, Yichen Wu, Ming Zhong, Peiyang Song, Qizheng Zhang, Heng Wang, Xueqiang Xu, Hanwen Xu, Pengrui Han, Dylan Zhang, Jiashuo Sun, Chaoqi Yang, Kun Qian, Tian Wang, Changran Hu, Manling Li, Quanzheng Li, Hao Peng, Sheng Wang, Jingbo Shang, Chao Zhang, Jiaxuan You, Liyuan Liu, Pan Lu, Yu Zhang, Hen...
2026
-
[81]
s3: You don ' t need that much data to train a search agent via RL
Pengcheng Jiang, Xueqiang Xu, Jiacheng Lin, Jinfeng Xiao, Zifeng Wang, Jimeng Sun, and Jiawei Han. s3: You don ' t need that much data to train a search agent via RL . In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors, Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages 21...
2025
-
[82]
Active retrieval augmented generation
Zhengbao Jiang, Frank F Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. Active retrieval augmented generation. In Proceedings of the 2023 conference on empirical methods in natural language processing , pages 7969--7992, 2023
2023
-
[83]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning. arXiv preprint arXiv:2503.09516 , 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[84]
Dhillon, David Brandfonbrener, and Rishabh Agarwal
Devvrit Khatri, Lovish Madaan, Rishabh Tiwari, Rachit Bansal, Sai Surya Duvvuri, Manzil Zaheer, Inderjit S. Dhillon, David Brandfonbrener, and Rishabh Agarwal. The art of scaling reinforcement learning compute for llms, 2025
2025
-
[85]
Fact, fetch, and reason: A unified evaluation of retrieval-augmented generation
Satyapriya Krishna, Kalpesh Krishna, Anhad Mohananey, Steven Schwarcz, Adam Stambler, Shyam Upadhyay, and Manaal Faruqui. Fact, fetch, and reason: A unified evaluation of retrieval-augmented generation. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies...
2025
-
[86]
Bowman, and Ethan Perez
Tamera Lanham, Anna Chen, Ansh Radhakrishnan, Benoit Steiner, Carson Denison, Danny Hernandez, Dustin Li, Esin Durmus, Evan Hubinger, Jackson Kernion, Kamilė Lukošiūtė, Karina Nguyen, Newton Cheng, Nicholas Joseph, Nicholas Schiefer, Oliver Rausch, Robin Larson, Sam McCandlish, Sandipan Kundu, Saurav Kadavath, Shannon Yang, Thomas Henighan, Timothy Maxwel...
2023
-
[87]
Meta-Harness: End-to-End Optimization of Model Harnesses
Yoonho Lee, Roshen Nair, Qizheng Zhang, Kangwook Lee, Omar Khattab, and Chelsea Finn. Meta-harness: End-to-end optimization of model harnesses. arXiv preprint arXiv:2603.28052 , 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[88]
Websailor: Navigating super-human reasoning for web agent, 2025
Kuan Li, Zhongwang Zhang, Huifeng Yin, Liwen Zhang, Litu Ou, Jialong Wu, Wenbiao Yin, Baixuan Li, Zhengwei Tao, Xinyu Wang, Weizhou Shen, Junkai Zhang, Dingchu Zhang, Xixi Wu, Yong Jiang, Ming Yan, Pengjun Xie, Fei Huang, and Jingren Zhou. Websailor: Navigating super-human reasoning for web agent, 2025
2025
-
[89]
Search-o1: Agentic search-enhanced large reasoning models
Xiaoxi Li, Guanting Dong, Jiajie Jin, Yuyao Zhang, Yujia Zhou, Yutao Zhu, Peitian Zhang, and Zhicheng Dou. Search-o1: Agentic search-enhanced large reasoning models. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors, Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages 5420...
2025
-
[90]
Webexplorer: Explore and evolve for training long-horizon web agents, 2025
Junteng Liu, Yunji Li, Chi Zhang, Jingyang Li, Aili Chen, Ke Ji, Weiyu Cheng, Zijia Wu, Chengyu Du, Qidi Xu, Jiayuan Song, Zhengmao Zhu, Wenhu Chen, Pengyu Zhao, and Junxian He. Webexplorer: Explore and evolve for training long-horizon web agents, 2025
2025
-
[91]
Harness engineering: leveraging codex in an agent-first world, 2026
Ryan Lopopolo. Harness engineering: leveraging codex in an agent-first world, 2026
2026
-
[92]
Xinghua Lou, Miguel Lázaro-Gredilla, Antoine Dedieu, Carter Wendelken, Wolfgang Lehrach, and Kevin P. Murphy. Autoharness: improving llm agents by automatically synthesizing a code harness, 2026
2026
-
[93]
Scaling managed agents: Decoupling the brain from the hands
Lance Martin, Gabe Cemaj, and Michael Cohen. Scaling managed agents: Decoupling the brain from the hands. https://www.anthropic.com/engineering/managed-agents, April 2026. Anthropic Engineering Blog
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.