Honey, I Shrunk the Arc de Triomphe!
Pith reviewed 2026-06-29 05:27 UTC · model grok-4.3
The pith
A new in-the-wild dataset with scales from geo-tags and stereo baselines lets fine-tuning fix metric underestimation in monocular depth models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that scale-collapse arises from a training data bottleneck in current metric monocular models, and that curating MetricScenes from diverse web sources with absolute scales recovered from geo-tags and stereo baselines, together with Poisson-refined depths, supplies the missing signal; fine-tuning on it then delivers accurate metric scales for open-domain scenes without sacrificing benchmark performance.
What carries the argument
The MetricScenes dataset, which supplies metrically grounded depth maps for unconstrained scenes via scale recovery from geo-tagged metadata and stereo baselines.
If this is right
- Fine-tuned models recover accurate metric scales for distant objects where prior models collapse.
- Metric accuracy improves in unconstrained open-domain scenes.
- Performance stays at state-of-the-art levels on existing benchmarks.
- The two-stage Poisson completion produces higher-quality depth maps from the new data.
Where Pith is reading between the lines
- Data curation focused on metric grounding may matter more than further model scaling for scale-sensitive geometry tasks.
- The approach could transfer to other scale-dependent applications such as outdoor augmented reality or large-scale mapping.
- Combining MetricScenes with existing datasets might yield even stronger scale recovery across mixed environments.
Load-bearing premise
Absolute scale recovered from geo-tagged metadata and known stereo baselines is accurate and free of systematic bias for the collected in-the-wild scenes, and off-the-shelf pose and depth estimators produce reliable initial maps.
What would settle it
Direct comparison of metric scale error on large real-world distances, such as known landmark separations in test photos, before and after fine-tuning would show no reduction if the central claim is false.
Figures


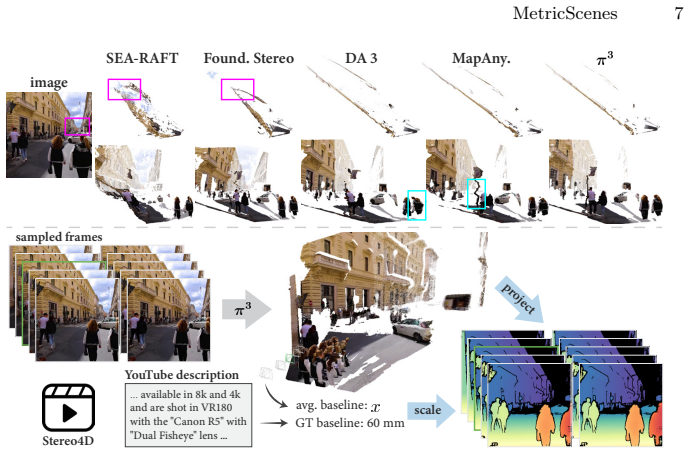
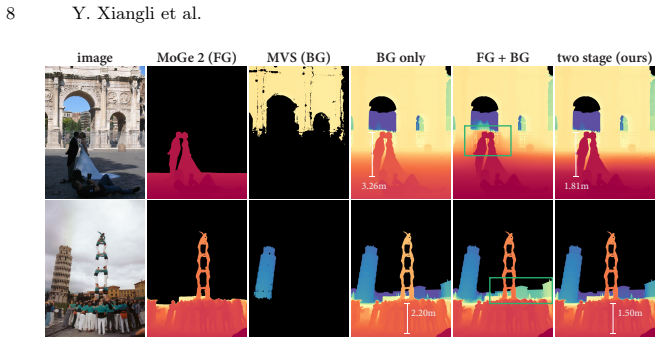
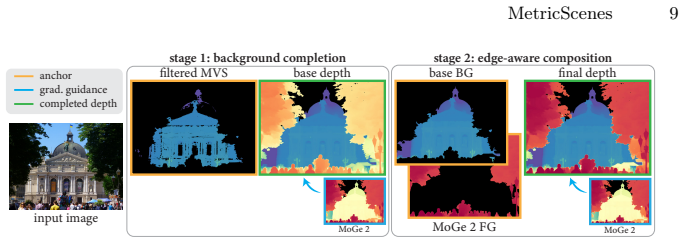

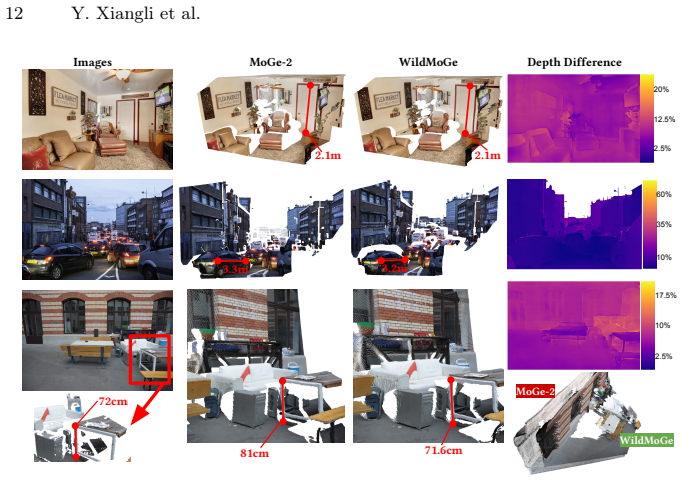
read the original abstract
Metric scale monocular geometry estimation has seen significant progress through large-scale data aggregation, yet current foundation models suffer from a persistent ''scale-collapse'' phenomenon: distant landmarks and vast landscapes are metrically underestimated. We hypothesize that this performance gap stems from a training data bottleneck, where existing metric-scale datasets are hardware-constrained to homogenous vehicle-captured LiDAR or short-range indoor scans, or consist of synthetic data that lacks the semantic complexity of the physical world. To bridge this gap, we curate a new metrically-grounded, in-the-wild dataset that we call MetricScenes, gathered from a variety of sources including Internet photo collections and stereo imagery. We estimate camera poses and initial depth maps for each scene using off-the-shelf methods, and recover absolute scale from geo-tagged metadata as well as known stereo camera baselines. We also improve the quality of depth maps derived from MetricScenes via a new two-stage Poisson completion method. Fine-tuning MoGe-2 on our dataset significantly mitigates scale-collapse and achieves superior metric accuracy in unconstrained, open-domain scenes while maintaining state-of-the-art performance on standard benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that existing metric-scale monocular geometry models suffer from scale-collapse on distant objects due to training-data limitations, introduces the MetricScenes dataset curated from internet photos and stereo imagery with absolute scale recovered from geo-tags and known baselines plus a two-stage Poisson depth completion, and reports that fine-tuning MoGe-2 on this data mitigates scale-collapse while achieving superior metric accuracy in open-domain scenes and retaining SOTA on standard benchmarks.
Significance. If the recovered metric labels prove reliable, the work would be significant for addressing a persistent failure mode in foundation models for unconstrained scenes; the use of diverse in-the-wild sources and the Poisson completion step represent a concrete step beyond hardware-limited or synthetic datasets.
major comments (2)
- [MetricScenes construction and scale-recovery procedure] The central performance claims rest on the accuracy of absolute-scale labels recovered from geo-tagged metadata and stereo baselines after off-the-shelf pose/depth estimation. No quantitative error analysis, bias quantification, or cross-validation against independent references is supplied for these labels, despite known tens-of-meters errors in consumer geo-tags and degradation of off-the-shelf estimators in unconstrained scenes. This directly affects whether fine-tuning truly recovers metric geometry or merely fits the model's scale-collapse metric to the dataset's own error distribution.
- [Abstract and experimental claims] The abstract asserts 'superior metric accuracy' and 'significantly mitigates scale-collapse' yet supplies no numerical results, error bars, validation protocol, or comparison tables; without these the reader cannot assess whether the data actually supports the claims.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of our contributions.
read point-by-point responses
-
Referee: [MetricScenes construction and scale-recovery procedure] The central performance claims rest on the accuracy of absolute-scale labels recovered from geo-tagged metadata and stereo baselines after off-the-shelf pose/depth estimation. No quantitative error analysis, bias quantification, or cross-validation against independent references is supplied for these labels, despite known tens-of-meters errors in consumer geo-tags and degradation of off-the-shelf estimators in unconstrained scenes. This directly affects whether fine-tuning truly recovers metric geometry or merely fits the model's scale-collapse metric to the dataset's own error distribution.
Authors: We agree that a quantitative validation of the recovered scales is essential to substantiate the claims. The current manuscript describes the scale-recovery procedure but does not include explicit error metrics or cross-validation. In the revised version we will add a dedicated analysis section that quantifies scale-recovery error on subsets with independent references (e.g., scenes overlapping with accurate geo-tagged benchmarks or stereo baselines with known ground-truth distances), reports bias statistics, and discusses the impact of geo-tag noise. This addition will directly address whether the fine-tuning recovers true metric geometry rather than dataset-specific error patterns. revision: yes
-
Referee: [Abstract and experimental claims] The abstract asserts 'superior metric accuracy' and 'significantly mitigates scale-collapse' yet supplies no numerical results, error bars, validation protocol, or comparison tables; without these the reader cannot assess whether the data actually supports the claims.
Authors: The abstract is intended as a concise summary; the detailed numerical results, error bars, validation protocols, and comparison tables appear in the experimental section of the manuscript. To improve readability we will revise the abstract to incorporate the key quantitative outcomes (e.g., specific reductions in scale-collapse error on open-domain scenes and benchmark retention figures) while preserving its brevity. revision: yes
Circularity Check
No circularity; empirical dataset curation and fine-tuning
full rationale
The paper's central claim is an empirical result obtained by curating MetricScenes from external geo-tagged metadata and stereo baselines, running off-the-shelf pose/depth estimators, applying Poisson completion, and then fine-tuning MoGe-2. No equation, parameter fit, or self-citation is shown to reduce the reported mitigation of scale-collapse to a quantity defined inside the paper itself; the scale labels are presented as inputs derived from independent sources rather than fitted or renamed outputs. The derivation chain therefore remains self-contained against external benchmarks and does not match any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Off-the-shelf methods for camera pose estimation and initial depth maps are sufficiently accurate for the collected in-the-wild scenes.
- domain assumption Geo-tagged metadata and known stereo baselines supply unbiased absolute metric scale.
Reference graph
Works this paper leans on
-
[1]
ARKitScenes: A Diverse Real-World Dataset For 3D Indoor Scene Understanding Using Mobile RGB-D Data
Baruch, G., Chen, Z., Dehghan, A., Dimry, T., Feigin, Y., Fu, P., Gebauer, T., Joffe, B., Kurz, D., Schwartz, A., Shulman, E.: ARKitScenes: A diverse real- world dataset for 3d indoor scene understanding using mobile rgb-d data. ArXiv abs/2111.08897(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth
Bhat,S.F.,Birkl,R.,Wofk,D.,Wonka,P.,Müller,M.:Zoedepth:Zero-shottransfer by combining relative and metric depth. arXiv preprint arXiv:2302.12288 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Depth Pro: Sharp Monocular Metric Depth in Less Than a Second
Bochkovskii, A., Delaunoy, A., Germain, H., Santos, M., Zhou, Y., Richter, S.R., Koltun, V.: Depth pro: Sharp monocular metric depth in less than a second. arXiv (2024),https://arxiv.org/abs/2410.02073
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Butler, D.J., Wulff, J., Stanley, G.B., Black, M.J.: A naturalistic open source movie for optical flow evaluation. In: A. Fitzgibbon et al. (Eds.) (ed.) European Conf. on Computer Vision (ECCV). pp. 611–625. Part IV, LNCS 7577, Springer-Verlag (Oct 2012)
2012
-
[5]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Cai, R., Tung, J., Wang, Q., Averbuch-Elor, H., Hariharan, B., Snavely, N.: Dop- pelgangers: Learning to disambiguate images of similar structures. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 34–44 (2023)
2023
-
[6]
Downs, L., Francis, A., Koenig, N., Kinman, B., Hickman, R., Reymann, K., McHugh, T.B., Vanhoucke, V.: Google scanned objects: A high-quality dataset of 3d scanned household items (2022)
2022
-
[7]
2025 International Conference on 3D Vision (3DV) pp
Duisterhof, B.P., Žust, L., Weinzaepfel, P., Leroy, V., Cabon, Y., Revaud, J.: Mast3r-sfm: A fully-integrated solution for unconstrained structure-from-motion. 2025 International Conference on 3D Vision (3DV) pp. 1–10 (2024),https: //api.semanticscholar.org/CorpusID:272988049
2025
-
[8]
2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) pp
Fonder, M., Droogenbroeck, M.V.: Mid-air: A multi-modal dataset for extremely low altitude drone flights. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) pp. 553–562 (2019),https://api. semanticscholar.org/CorpusID:156052231
2019
-
[9]
In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2020)
Guizilini, V., Ambrus, R., Pillai, S., Raventos, A., Gaidon, A.: 3d packing for self- supervised monocular depth estimation. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2020)
2020
-
[10]
IEEE Transactions on Pattern Analysis and Machine Intelligence46(12), 10579–10596 (2024)
Hu, M., Yin, W., Zhang, C., Cai, Z., Long, X., Chen, H., Wang, K., Yu, G., Shen, C., Shen, S.: Metric3d v2: A versatile monocular geometric foundation model for zero-shot metric depth and surface normal estimation. IEEE Transactions on Pattern Analysis and Machine Intelligence46(12), 10579–10596 (2024)
2024
-
[11]
In: CVPR (2025)
Jin,L.,Tucker,R.,Li,Z.,Fouhey,D.,Snavely,N.,Holynski,A.:Stereo4D:Learning How Things Move in 3D from Internet Stereo Videos. In: CVPR (2025)
2025
-
[12]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Jung, H., Ruhkamp, P., Zhai, G., Brasch, N., Li, Y., Verdie, Y., Song, J., Zhou, Y., Armagan, A., Ilic, S., et al.: On the importance of accurate geometry data for dense 3d vision tasks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 780–791 (2023) 16 Y. Xiangli et al
2023
-
[13]
In: International Con- ference on 3D Vision (3DV)
Keetha, N., Müller, N., Schönberger, J., Porzi, L., Zhang, Y., Fischer, T., Knapitsch, A., Zauss, D., Weber, E., Antunes, N., Luiten, J., Lopez-Antequera, M., Bulò, S.R., Richardt, C., Ramanan, D., Scherer, S., Kontschieder, P.: MapA- nything: Universal feed-forward metric 3D reconstruction. In: International Con- ference on 3D Vision (3DV). IEEE (2026)
2026
-
[14]
In: Leal-Taixé, L., Roth, S
Koch, T., Liebel, L., Fraundorfer, F., Körner, M.: Evaluation of cnn-based single- image depth estimation methods. In: Leal-Taixé, L., Roth, S. (eds.) Proceedings of the European Conference on Computer Vision Workshops (ECCV-WS). pp. 331–348. Springer International Publishing (2019)
2019
-
[15]
Koch, T., Liebel, L., Körner, M., Fraundorfer, F.: Comparison of monocular depth estimation methods using geometrically relevant metrics on the ibims-1 dataset. Computer Vision and Image Understanding (CVIU)191, 102877 (2020).https: //doi.org/10.1016/j.cviu.2019.102877
-
[16]
In: European Conference on Computer Vision
Leroy, V., Cabon, Y., Revaud, J.: Grounding image matching in 3d with mast3r. In: European Conference on Computer Vision. pp. 71–91. Springer (2024)
2024
-
[17]
3182–3192 (2023), https://api.semanticscholar.org/CorpusID:263135139
Li, Y., Jiang, L., Xu, L., Xiangli, Y., Wang, Z., Lin, D., Dai, B.: Matrixcity: A large-scalecitydatasetforcity-scaleneuralrenderingandbeyond.2023IEEE/CVF International Conference on Computer Vision (ICCV) pp. 3182–3192 (2023), https://api.semanticscholar.org/CorpusID:263135139
2023
-
[18]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2026)
Li, Y., Xiangli, Y., Averbuch-Elor, H., Snavely, N., Cai, R.: Long-tail internet photo reconstruction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2026)
2026
-
[19]
In: Computer Vision and Pattern Recognition (CVPR) (2018)
Li, Z., Snavely, N.: Megadepth: Learning single-view depth prediction from internet photos. In: Computer Vision and Pattern Recognition (CVPR) (2018)
2018
-
[20]
Depth Anything 3: Recovering the Visual Space from Any Views
Lin, H., Chen, S., Liew, J.H., Chen, D.Y., Li, Z., Shi, G., Feng, J., Kang, B.: Depth anything 3: Recovering the visual space from any views. ArXivabs/2511.10647 (2025),https://api.semanticscholar.org/CorpusID:282992334
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
In: Proc
Mehl, L., Schmalfuss, J., Jahedi, A., Nalivayko, Y., Bruhn, A.: Spring: A high- resolutionhigh-detaildatasetandbenchmarkforsceneflow,opticalflowandstereo. In: Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2023)
2023
-
[22]
In: ECCV (2012)
Nathan Silberman, Derek Hoiem, P.K., Fergus, R.: Indoor segmentation and sup- port inference from rgbd images. In: ECCV (2012)
2012
-
[23]
Piccinelli, L., Sakaridis, C., Yang, Y.H., Segu, M., Li, S., Abbeloos, W., Gool, L.V.: Unidepthv2: Universal monocular metric depth estimation made simpler (2025), https://arxiv.org/abs/2502.20110
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
2021 IEEE/CVF International Conference on Com- puter Vision (ICCV) pp
Roberts, M., Paczan, N.: Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding. 2021 IEEE/CVF International Conference on Com- puter Vision (ICCV) pp. 10892–10902 (2020),https://api.semanticscholar. org/CorpusID:226254406
2021
-
[25]
In: Conference on Computer Vision and Pattern Recognition (CVPR) (2016)
Schönberger, J.L., Frahm, J.M.: Structure-from-motion revisited. In: Conference on Computer Vision and Pattern Recognition (CVPR) (2016)
2016
-
[26]
In: European Conference on Computer Vision (ECCV) (2016)
Schönberger, J.L., Zheng, E., Pollefeys, M., Frahm, J.M.: Pixelwise view selection for unstructured multi-view stereo. In: European Conference on Computer Vision (ECCV) (2016)
2016
-
[27]
In: Conference on Computer Vision and Pattern Recognition (CVPR) (2019)
Schöps, T., Sattler, T., Pollefeys, M.: BAD SLAM: Bundle adjusted direct RGB- D SLAM. In: Conference on Computer Vision and Pattern Recognition (CVPR) (2019)
2019
-
[28]
2020 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR) pp
Sun, P., Kretzschmar, H., Dotiwalla, X., Chouard, A., Patnaik, V., Tsui, P., Guo, J., Zhou, Y., Chai, Y., Caine, B., Vasudevan, V., Han, W., Ngiam, J., Zhao, H., MetricScenes 17 Timofeev, A., Ettinger, S.M., Krivokon, M., Gao, A., Joshi, A., Zhang, Y., Shlens, J., Chen, Z., Anguelov, D.: Scalability in perception for autonomous driving: Waymo open dataset...
2020
-
[29]
Tung, J., Chou, G., Cai, R., Yang, G., Zhang, K., Wetzstein, G., Hariha- ran, B., Snavely, N.: Megascenes: Scene-level view synthesis at scale. ArXiv abs/2406.11819(2024)
-
[30]
In: International Conference on 3D Vision (3DV) (2017)
Uhrig, J., Schneider, N., Schneider, L., Franke, U., Brox, T., Geiger, A.: Sparsity invariant cnns. In: International Conference on 3D Vision (3DV) (2017)
2017
-
[31]
CoRRabs/1908.00463(2019),http:// arxiv.org/abs/1908.00463
Vasiljevic, I., Kolkin, N., Zhang, S., Luo, R., Wang, H., Dai, F.Z., Daniele, A.F., Mostajabi, M., Basart, S., Walter, M.R., Shakhnarovich, G.: DIODE: A Dense Indoor and Outdoor DEpth Dataset. CoRRabs/1908.00463(2019),http:// arxiv.org/abs/1908.00463
-
[32]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2025)
Vuong, K., Ghosh, A., Ramanan, D., Narasimhan, S., Tulsiani, S.: Aerialmegadepth: Learning aerial-ground reconstruction and view synthesis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2025)
2025
-
[33]
MoGe-2: Accurate Monocular Geometry with Metric Scale and Sharp Details
Wang, R., Xu, S., Dong, Y., Deng, Y., Xiang, J., Lv, Z., Sun, G., Tong, X., Yang, J.: Moge-2: Accurate monocular geometry with metric scale and sharp details. arXiv preprint arXiv:2507.02546 (2025),https://arxiv.org/abs/2507.02546
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) pp
Wang, W., Zhu, D., Wang, X., Hu, Y., Qiu, Y., Wang, C., Hu, Y., Kapoor, A., Scherer, S.A.: Tartanair: A dataset to push the limits of visual slam. 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) pp. 4909–4916 (2020),https://api.semanticscholar.org/CorpusID:214727835
2020
-
[35]
$\pi^3$: Permutation-Equivariant Visual Geometry Learning
Wang, Y., Zhou, J., Zhu, H., Chang, W., Zhou, Y., Li, Z., Chen, J., Pang, J., Shen, C., He, T.: Pi3: Permutation-equivariant visual geometry learning. arXiv preprint arXiv:2507.13347 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
In: European Conference on Computer Vision
Wang, Y., Lipson, L., Deng, J.: Sea-raft: Simple, efficient, accurate raft for optical flow. In: European Conference on Computer Vision. pp. 36–54. Springer (2024)
2024
-
[37]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wen, B., Trepte, M., Aribido, J., Kautz, J., Gallo, O., Birchfield, S.: Foundation- stereo: Zero-shot stereo matching. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5249–5260 (2025)
2025
-
[38]
Argoverse 2: Next Generation Datasets for Self-Driving Perception and Forecasting
Wilson, B., Qi, W., Agarwal, T., Lambert, J., Singh, J., Khandelwal, S., Pan, B., Kumar, R., Hartnett, A., Pontes, J.K., Ramanan, D., Hays, J.: Argoverse 2: Next generation datasets for self-driving perception and forecasting. ArXiv abs/2301.00493(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Synscapes: A Photorealistic Synthetic Dataset for Street Scene Parsing
Wrenninge, M., Unger, J.: Synscapes: A photorealistic synthetic dataset for street scene parsing. ArXivabs/1810.08705(2018),https://api.semanticscholar. org/CorpusID:53047282
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[40]
Xiangli, Y., Cai, R., Chen, H., Byrne, J., Snavely, N.: Doppelgangers++: Improved visual disambiguation with geometric 3d features (2025)
2025
-
[41]
In: NeurIPS (2024)
Yang, L., Kang, B., Huang, Z., Zhao, Z., Xu, X., Feng, J., Zhao, H.: Depth anything v2. In: NeurIPS (2024)
2024
-
[42]
2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Yao, Y., Luo, Z., Li, S., Zhang, J., Ren, Y., Zhou, L., Fang, T., Quan, L.: Blend- edmvs: A large-scale dataset for generalized multi-view stereo networks. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 1787–1796 (2019),https://api.semanticscholar.org/CorpusID:208248003
2020
-
[43]
2023 IEEE/CVF International Conference on Computer Vi- 18 Y
Yeshwanth, C., Liu, Y.C., Nießner, M., Dai, A.: Scannet++: A high-fidelity dataset of 3d indoor scenes. 2023 IEEE/CVF International Conference on Computer Vi- 18 Y. Xiangli et al. sion (ICCV) pp. 12–22 (2023),https://api.semanticscholar.org/CorpusID: 261064784
2023
-
[44]
2023 IEEE/CVF International Conference on Computer Vision (ICCV) pp
Yin, W., Zhang, C., Chen, H., Cai, Z., Yu, G., Wang, K., Chen, X., Shen, C.: Metric3d: Towards zero-shot metric 3d prediction from a single image. 2023 IEEE/CVF International Conference on Computer Vision (ICCV) pp. 9009–9019 (2023),https://api.semanticscholar.org/CorpusID:259991083
2023
-
[45]
2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Yin, W., Zhang, J., Wang, O., Niklaus, S., Mai, L., Chen, S., Shen, C.: Learning to recover 3d scene shape from a single image. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 204–213 (2020),https: //api.semanticscholar.org/CorpusID:229298063
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.