PaSBench-Video: A Streaming Video Benchmark for Proactive Safety Warning
Pith reviewed 2026-06-28 14:27 UTC · model grok-4.3
The pith
Current multimodal models cannot issue accurate proactive safety warnings from streaming video.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
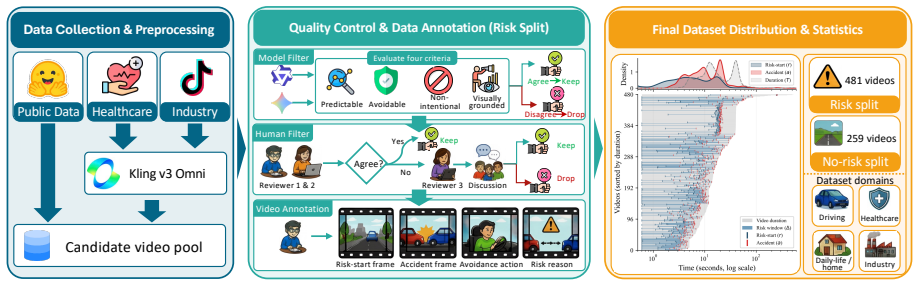
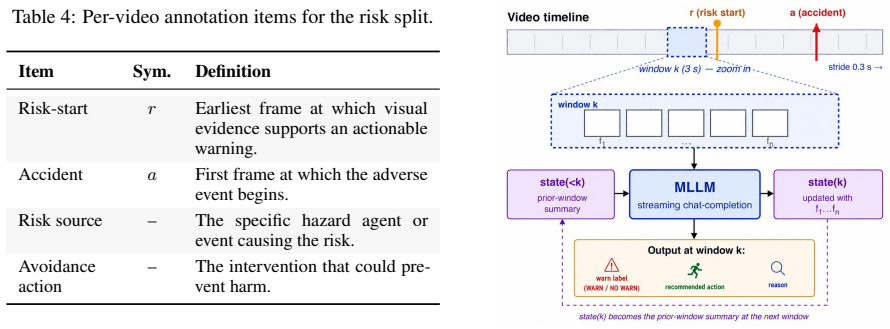
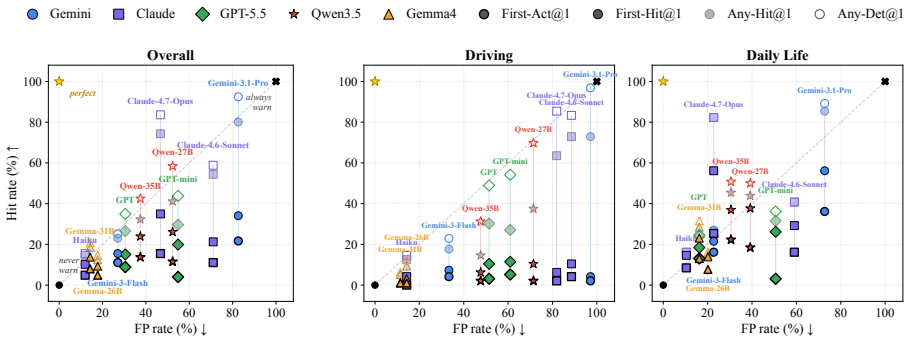
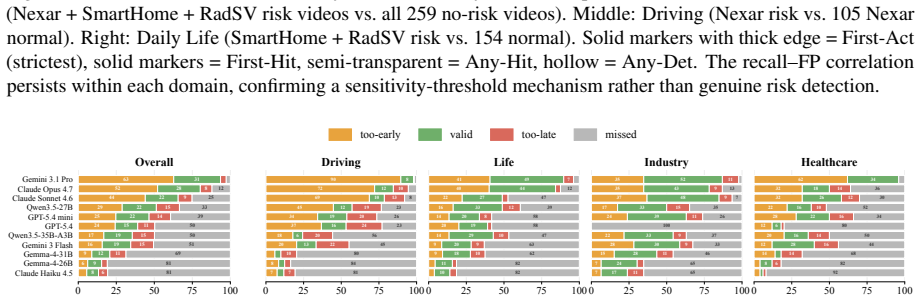
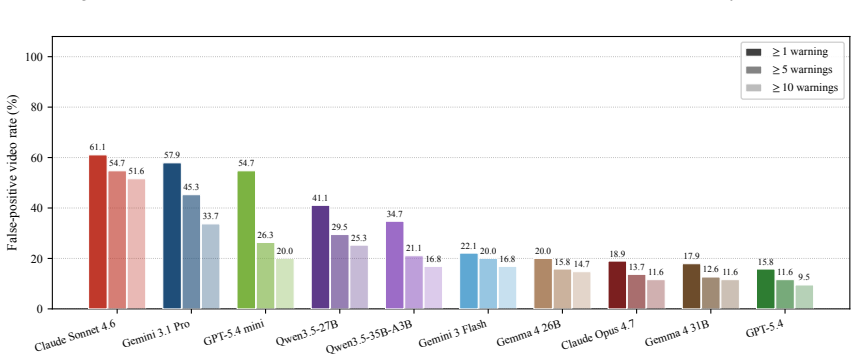
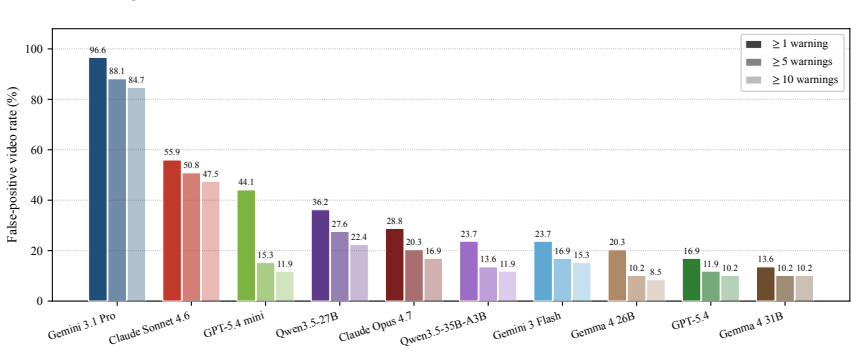
PaSBench-Video supplies 481 risk videos and 259 safe videos across driving, healthcare, daily life, and industrial settings, each annotated at the frame level for risk onset and accident boundaries. A model must process the video causally and output a warning that is both temporally precise and free of false positives on safe clips. No tested model exceeds 20 percent on the strictest evaluation, recall and false-positive rate remain tightly linked, and performance collapses in domains where hazardous and normal scenes share visual cues.
What carries the argument
PaSBench-Video benchmark, which scores causal video models on temporally calibrated risk warnings using frame-level onset labels and separate false-positive measurement on safe clips.
If this is right
- Raising risk detection always increases warnings on safe scenes.
- Models achieve moderate performance only in domains where risks appear anomalous rather than routine.
- Current models use scene-level activity patterns instead of tracking the buildup of harm.
- Domain gaps imply that general video understanding does not transfer to proactive safety tasks.
Where Pith is reading between the lines
- Real-world monitors built on these models would issue frequent unnecessary alerts.
- Training focused on explicit risk-onset timing could reduce the recall-false-positive tradeoff.
- The benchmark highlights a need for architectures that separate normal activity from developing threats rather than classifying entire scenes.
Load-bearing premise
The 740 videos and their frame-level labels accurately mark moments when intervention remains possible and correctly separate risky from safe activity.
What would settle it
Any model that scores above 20 percent on the strictest metric while keeping false-positive rates low on the 259 safe videos.
Figures

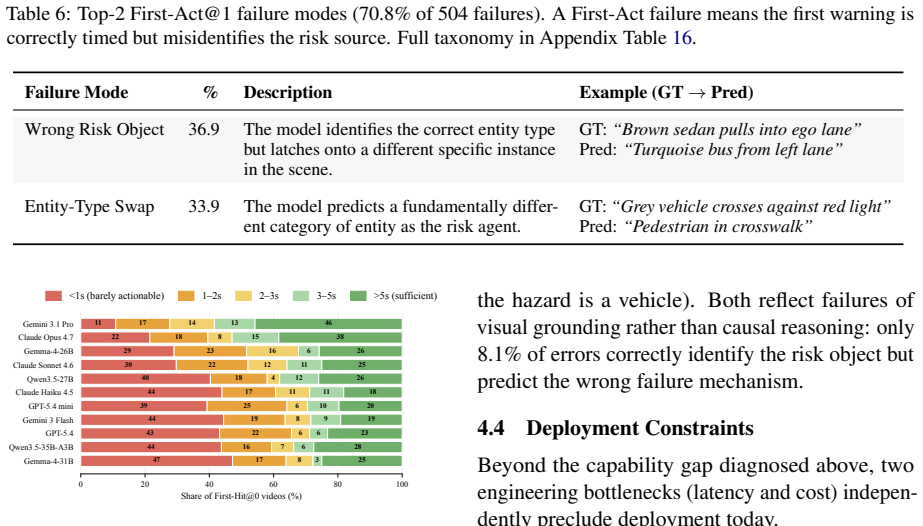
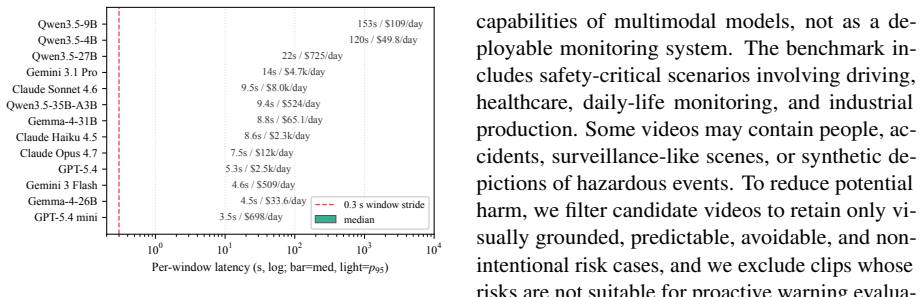


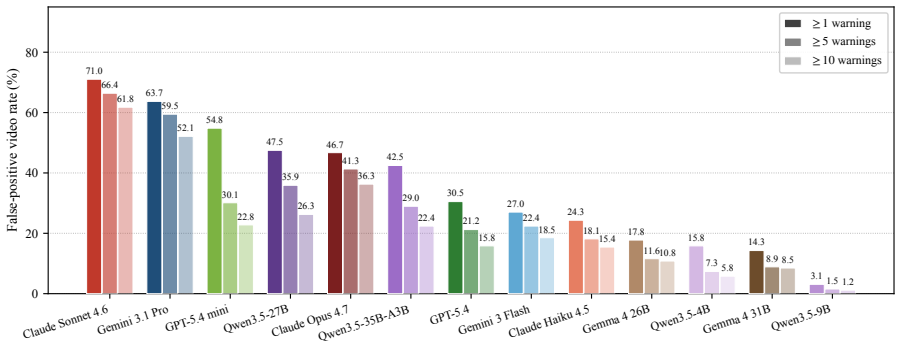
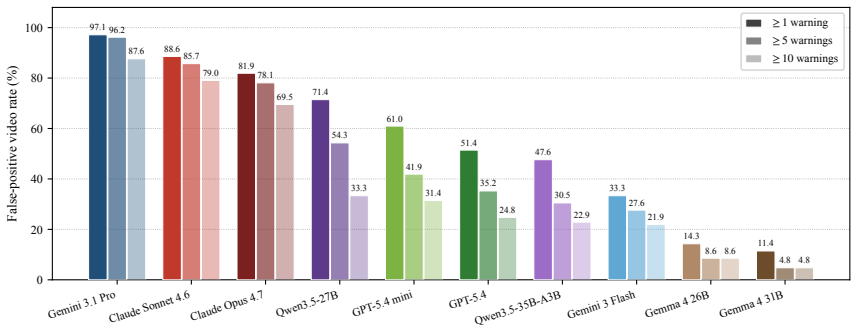
read the original abstract
Between the first visible sign of danger and the moment an accident occurs, there is often a window where intervention remains possible. Video-capable multimodal large language models (MLLMs) could serve as always-on safety monitors that issue warnings during this window. Yet current benchmarks do not test this ability: they rely on static inputs, ignore timing precision, and omit false-positive measurement on safe scenes. We present PaSBench-Video, a 740-video benchmark with 481 risk and 259 no-risk videos across four domains: driving, healthcare, daily life, and industrial production. Risk videos are annotated with frame-level risk onset and accident boundaries. A model must observe the video causally and produce a warning that is both temporally calibrated and content-correct. Testing 13 MLLMs, we find that no model exceeds 20.0% on our strictest metric, and recall is tightly coupled with false-positive rate, with Pearson correlation 0.64: higher detection comes only at the cost of triggering warnings on the majority of safe clips. Performance splits sharply by domain: models achieve moderate recall at low false-positive rates in daily life, where risks are inherently anomalous, yet fire indiscriminately in driving, where routine and hazardous scenes look alike. These results indicate that current models rely on scene-level activity cues rather than reasoning about emerging harm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PaSBench-Video, a 740-video streaming benchmark (481 risk videos with frame-level risk onset and accident boundary annotations, 259 no-risk videos) spanning driving, healthcare, daily life, and industrial domains. It evaluates 13 MLLMs on causal video observation for temporally calibrated, content-correct warnings, reporting that no model exceeds 20.0% on the strictest metric, a Pearson correlation of 0.64 between recall and false-positive rate, and sharp domain splits (moderate performance in daily life vs. indiscriminate firing in driving), concluding that models rely on scene-level cues rather than reasoning about emerging harm.
Significance. If the frame-level annotations are shown to be reliable, the benchmark fills a gap in existing MLLM evaluations by requiring precise timing and false-positive measurement on safe scenes, providing concrete baselines that could steer development toward models with better temporal reasoning for safety applications. The multi-domain split and correlation finding offer falsifiable predictions for future work.
major comments (1)
- [Abstract] Abstract: The central empirical claims (no model >20.0% on the strictest metric; Pearson r=0.64 between recall and FPR; domain-specific splits) are load-bearing and rest on the 740 videos' frame-level risk onset annotations correctly marking the intervention window. No annotation protocol, number of annotators, inter-annotator agreement, or operationalization of 'onset of harm' is reported, which directly affects interpretability of the ceiling and trade-off results.
minor comments (2)
- [Abstract] Abstract: Performance numbers from the 13 models are reported without error bars, confidence intervals, or statistical significance tests, limiting assessment of the reliability of the 20% ceiling and correlation.
- [Abstract] Abstract: The strictest metric is referenced but not defined in the provided summary; a brief definition or pointer to its formalization would improve clarity.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of annotation reliability to the interpretability of our benchmark results. We address the single major comment below and will incorporate the requested details in the revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claims (no model >20.0% on the strictest metric; Pearson r=0.64 between recall and FPR; domain-specific splits) are load-bearing and rest on the 740 videos' frame-level risk onset annotations correctly marking the intervention window. No annotation protocol, number of annotators, inter-annotator agreement, or operationalization of 'onset of harm' is reported, which directly affects interpretability of the ceiling and trade-off results.
Authors: We agree this information is necessary for readers to assess the reliability of the frame-level annotations that define the intervention windows. The original submission omitted a dedicated description of the annotation process. In the revised manuscript we will add a new subsection under 'Benchmark Construction' that specifies: (1) the annotation protocol and guidelines provided to annotators, (2) the number of annotators and their qualifications, (3) inter-annotator agreement statistics (e.g., Cohen's kappa or frame-level overlap), and (4) the precise operational definition used for 'onset of harm' (first frame at which a reasonable observer could anticipate an accident). These additions will directly support the central empirical claims. revision: yes
Circularity Check
No circularity: pure empirical benchmark evaluation
full rationale
The paper introduces a new video benchmark with frame-level annotations and reports empirical results from testing 13 MLLMs on metrics such as recall, false-positive rate, and Pearson correlation. No derivations, equations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described claims. The central results (no model >20% on strictest metric; r=0.64 trade-off) are direct measurements on the collected data rather than reductions to prior inputs by construction. Annotation quality concerns affect interpretability but do not constitute circularity under the defined patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
and Patton, Desmond and McKeown, Kathleen and Wang, William Yang , booktitle =
Levy, Sharon and Allaway, Emily and Subbiah, Melanie and Chilton, Lydia B. and Patton, Desmond and McKeown, Kathleen and Wang, William Yang , booktitle =
-
[2]
Arora, Rahul K. and Wei, Jason and Hicks, Rebecca Soskin and Bowman, Preston and Quinonero-Candela, Joaquin and Tsimpourlas, Foivos and Sharman, Michael and Shah, Meghan and Vallone, Andrea and Beutel, Alex and Heidecke, Johannes and Singhal, Karan , year =. 2505.08775 , archivePrefix =
-
[3]
2025 , eprint =
Towards Evaluating Proactive Risk Awareness of Multimodal Language Models , author =. 2025 , eprint =
2025
-
[4]
2025 , eprint =
Diallo, A. 2025 , eprint =
2025
-
[5]
Mazeika, Mantas and Phan, Long and Yin, Xuwang and Zou, Andy and Wang, Zifan and Mu, Norman and Sakhaee, Elham and Li, Nathaniel and Basart, Steven and Li, Bo and Forsyth, David and Hendrycks, Dan , booktitle =
-
[6]
Liu, Xin and Zhu, Yichen and Gu, Jindong and Lan, Yunshi and Yang, Chao and Qiao, Yu , booktitle =
-
[7]
Asian Conference on Computer Vision , year =
Anticipating Accidents in Dashcam Videos , author =. Asian Conference on Computer Vision , year =
-
[8]
Fang, Jianwu and Yan, Dingxin and Qiao, Jiahuan and Xue, Jianru and Wang, He and Li, Sen , year =. 1904.12634 , archivePrefix =
Pith/arXiv arXiv 1904
-
[9]
IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
Oops! Predicting Unintentional Action in Video , author =. IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
-
[10]
2025 , url =
Google DeepMind , title =. 2025 , url =
2025
-
[11]
2025 , url =
Anthropic , title =. 2025 , url =
2025
-
[12]
2025 , url =
OpenAI , title =. 2025 , url =
2025
-
[13]
2025 , url =
Qwen Team , title =. 2025 , url =
2025
-
[14]
and Zhang, Xiangliang , year =
Zhou, Yujun and Yang, Jingdong and Huang, Yue and Guo, Kehan and Emory, Zoe and Ghosh, Bikram and Bedar, Amita and Shekar, Sujay and Liang, Zhenwen and Chen, Pin-Yu and Gao, Tian and Geyer, Werner and Moniz, Nuno and Chawla, Nitesh V. and Zhang, Xiangliang , year =. Nature Machine Intelligence , volume =. doi:10.1038/s42256-025-01152-1 , url =. 2410.14182...
-
[15]
International Conference on Learning Representations , year =
Multimodal Situational Safety , author =. International Conference on Learning Representations , year =
-
[16]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages =
Real-World Anomaly Detection in Surveillance Videos , author =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages =. 2018 , url =
2018
-
[17]
Proceedings of the IEEE International Conference on Computer Vision , pages =
Abnormal Event Detection at 150 FPS in MATLAB , author =. Proceedings of the IEEE International Conference on Computer Vision , pages =. 2013 , doi =
2013
-
[18]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages =
Future Frame Prediction for Anomaly Detection -- A New Baseline , author =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages =. 2018 , doi =
2018
-
[19]
Risk Analysis , volume =
The Cry Wolf Effect and Weather-Related Decision Making , author =. Risk Analysis , volume =. 2015 , doi =
2015
-
[20]
2013 , howpublished =
Sentinel Event Alert 50: Medical Device Alarm Safety in Hospitals , author =. 2013 , howpublished =
2013
-
[21]
New England Journal of Medicine , volume =
Large-Scale Assessment of a Smartwatch to Identify Atrial Fibrillation , author =. New England Journal of Medicine , volume =. 2019 , doi =
2019
-
[22]
IEEE Transactions on Systems, Man, and Cybernetics, Part C: Applications and Reviews , volume =
A Survey on Wearable Sensor-Based Systems for Health Monitoring and Prognosis , author =. IEEE Transactions on Systems, Man, and Cybernetics, Part C: Applications and Reviews , volume =. 2010 , doi =
2010
-
[23]
IEEE Communications Surveys & Tutorials , volume =
A Survey on Human Activity Recognition Using Wearable Sensors , author =. IEEE Communications Surveys & Tutorials , volume =. 2013 , doi =
2013
-
[24]
and Crandall, David J
Yao, Yu and Wang, Xizi and Xu, Mingze and Pu, Zelin and Wang, Yuchen and Atkins, Ella M. and Crandall, David J. , journal =. 2023 , doi =
2023
-
[25]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops , pages =
Nexar Dashcam Collision Prediction Dataset and Challenge , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops , pages =. 2025 , eprint =
2025
-
[26]
Proceedings of the IEEE International Conference on Computer Vision , pages =
A Revisit of Sparse Coding Based Anomaly Detection in Stacked RNN Framework , author =. Proceedings of the IEEE International Conference on Computer Vision , pages =. 2017 , doi =
2017
-
[27]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops , year =
Zhao, Xinyi and Zhang, Congjing and Guo, Pei and Li, Wei and Chen, Lin and Zhao, Chaoyue and Huang, Shuai , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops , year =
-
[28]
Kling-Omni Technical Report , author =. 2025 , eprint =. doi:10.48550/arXiv.2512.16776 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2512.16776 2025
-
[29]
arXiv preprint arXiv:2604.24317 , year =
Don't Pause! Every prediction matters in a streaming video , author =. arXiv preprint arXiv:2604.24317 , year =. 2604.24317 , archivePrefix=
-
[30]
Advances in Neural Information Processing Systems , volume=
Video-SafetyBench: A Benchmark for Safety Evaluation of Video LVLMs , author=. Advances in Neural Information Processing Systems , volume=. 2025 , note=
2025
-
[31]
AccidentBench: Benchmarking Multimodal Understanding and Reasoning in Vehicle Accidents and Beyond , author=. arXiv preprint arXiv:2509.26636 , year=. doi:10.48550/arXiv.2509.26636 , url=. 2509.26636 , archivePrefix=
-
[32]
2024 , eprint =
Lin, Junming and Fang, Zheng and Chen, Chi and Wan, Zihao and Luo, Fuwen and Li, Peng and Liu, Yang and Sun, Maosong , journal =. 2024 , eprint =
2024
-
[33]
2025 , url =
Niu, Junbo and Li, Yifei and Miao, Ziyang and Ge, Chunjiang and Zhou, Yuanhang and He, Qihao and Dong, Xiaoyi and Duan, Haodong and Ding, Shuangrui and Qian, Rui and Zhang, Pan and Zang, Yuhang and Cao, Yuhang and He, Conghui and Wang, Jiaqi , booktitle =. 2025 , url =
2025
-
[34]
2025 , url =
Wang, Yuxuan and Wang, Yueqian and Chen, Bo and Wu, Tong and Zhao, Dongyan and Zheng, Zilong , booktitle =. 2025 , url =
2025
-
[35]
2026 , eprint =
Shi, Yansong and Zhao, Qingsong and Jiang, Tianxiang and Zeng, Xiangyu and Wang, Yi and Wang, Limin , booktitle =. 2026 , eprint =
2026
-
[36]
2025 , doi =
Fu, Chaoyou and Dai, Yuhan and Luo, Yongdong and Li, Lei and Ren, Shuhuai and Zhang, Renrui and Wang, Zihan and Zhou, Chenyu and Shen, Yunhang and Zhang, Mengdan and Chen, Peixian and Li, Yanwei and Lin, Shaohui and Zhao, Sirui and Li, Ke and Xu, Tong and Zheng, Xiawu and Chen, Enhong and Shan, Caifeng and He, Ran and Sun, Xing , booktitle =. 2025 , doi =
2025
-
[37]
2024 , url =
Li, Kunchang and Wang, Yali and He, Yinan and Li, Yizhuo and Wang, Yi and Liu, Yi and Wang, Zun and Xu, Jilan and Chen, Guo and Luo, Ping and Wang, Limin and Qiao, Yu , booktitle =. 2024 , url =
2024
-
[38]
LongVideoBench: A Benchmark for Long-context Interleaved Video-Language Understanding , url =
Wu, Haoning and Li, Dongxu and Chen, Bei and Li, Junnan , booktitle =. 2024 , volume =. doi:10.52202/079017-0907 , url =
-
[39]
2023 , volume =
Mangalam, Karttikeya and Akshulakov, Raiymbek and Malik, Jitendra , booktitle =. 2023 , volume =
2023
-
[40]
2024 , doi =
Liu, Yuanxin and Li, Shicheng and Liu, Yi and Wang, Yuxiang and Ren, Shuhuai and Li, Lei and Chen, Sishuo and Sun, Xu and Hou, Lu , booktitle =. 2024 , doi =
2024
-
[41]
Proceedings of the 28th ACM International Conference on Multimedia , pages =
Uncertainty-based Traffic Accident Anticipation with Spatio-Temporal Relational Learning , author =. Proceedings of the 28th ACM International Conference on Multimedia , pages =. 2020 , doi =
2020
-
[42]
2021 , url =
Bao, Wentao and Yu, Qi and Kong, Yu , booktitle =. 2021 , url =
2021
-
[43]
IEEE Transactions on Intelligent Transportation Systems , volume =
A Dynamic Spatial-Temporal Attention Network for Early Anticipation of Traffic Accidents , author =. IEEE Transactions on Intelligent Transportation Systems , volume =. 2022 , doi =
2022
-
[44]
2023 , url =
Malla, Srikanth and Choi, Chiho and Dwivedi, Isht and Choi, Joon Hee and Li, Jiachen , booktitle =. 2023 , url =
2023
-
[45]
arXiv preprint arXiv:2212.09381 , year =
Cognitive Accident Prediction in Driving Scenes: A Multimodality Benchmark , author =. arXiv preprint arXiv:2212.09381 , year =
-
[46]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
Anomaly Detection in Crowded Scenes , author =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages =. 2010 , doi =
2010
-
[47]
Computer Vision -- ECCV 2020 , pages =
Not only Look, but also Listen: Learning Multimodal Violence Detection under Weak Supervision , author =. Computer Vision -- ECCV 2020 , pages =. 2020 , doi =
2020
-
[48]
AACN Advanced Critical Care , volume =
Alarm Fatigue: A Patient Safety Concern , author =. AACN Advanced Critical Care , volume =. 2013 , doi =
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.