ReLoRA: Knowledge-Reusing Adaptation for Fast Rollout of Evolving LLM Services
Pith reviewed 2026-06-30 15:02 UTC · model grok-4.3
The pith
ReLoRA restores task LoRA adapters after base LLM updates by fusing prior adapter knowledge into a Bayesian-optimized starting point and then applying scheduled regularization during fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
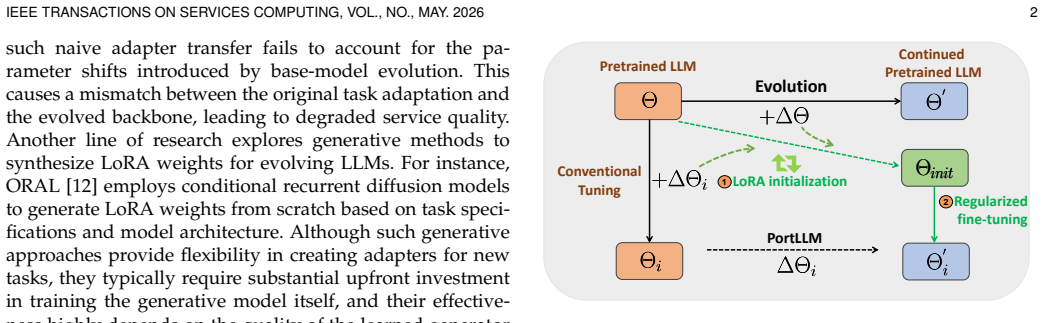
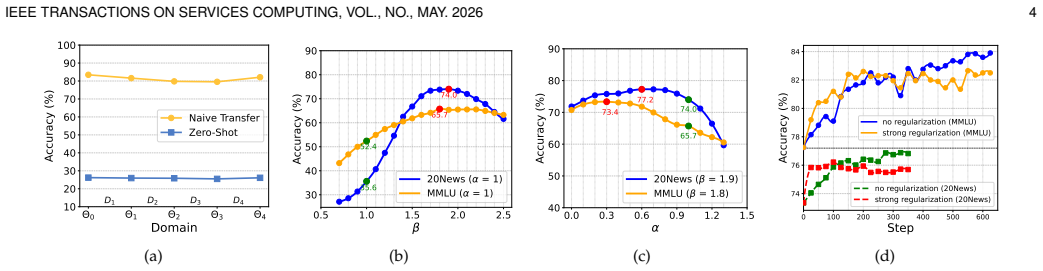
ReLoRA comprises two key optimization steps: Adaptive LoRA initialization leverages Bayesian optimization to construct a compatibility-aware starting point by fusing information from both the previously deployed task adapter and the base model's evolution; Fine-tuning with scheduled regularization first rapidly steers the adapter to a high-quality region via strong regularization, followed by relaxed regularization for task-specific refinement. This design enables rapid service-quality recovery with reduced re-adaptation overhead.
What carries the argument
The adaptive initialization step that uses Bayesian optimization to fuse the old task adapter with base-model evolution information, together with the subsequent scheduled-regularization fine-tuning phase.
If this is right
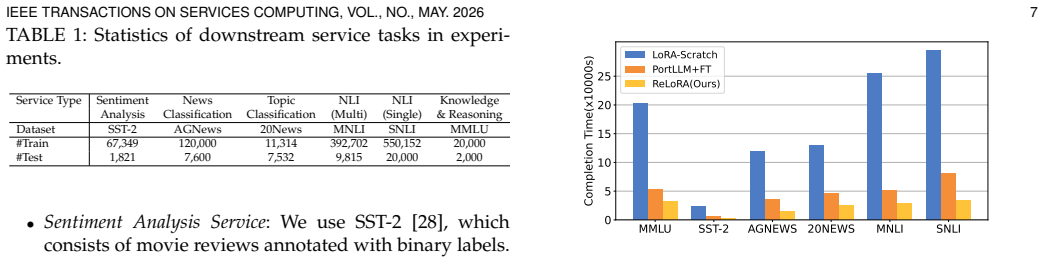
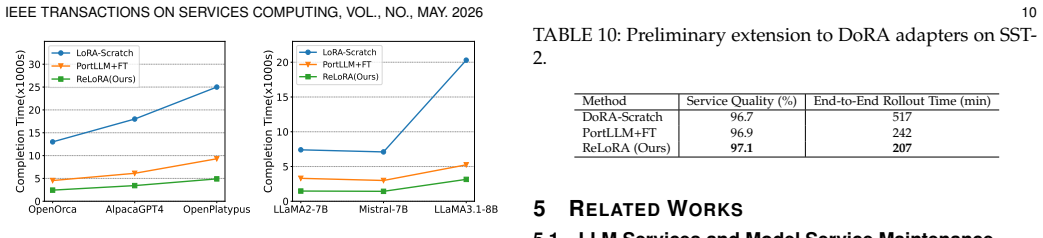
- ReLoRA reduces time-to-readiness by up to 8.9 times compared with training each adapter from scratch after a base-model update.
- Task accuracy improves by up to 4.6 percent over standard baselines while the adapter reaches service quality.
- Service providers managing many downstream LoRA services incur substantially lower re-adaptation compute when base models evolve.
- Task performance is preserved or improved rather than degraded by simple reuse of an incompatible old adapter.
Where Pith is reading between the lines
- The same initialization-plus-scheduling pattern might transfer to other parameter-efficient methods that must track base-model changes.
- Frequent base-model releases could become practical in production pipelines if the overhead of adapter refresh drops this sharply.
- The approach still requires the service provider to retain the previous adapter weights, which may not hold in every deployment scenario.
Load-bearing premise
Bayesian optimization can reliably produce a useful starting adapter by combining the old task adapter with information about how the base model has changed.
What would settle it
An experiment in which the Bayesian-optimization initialization is replaced by a naive copy of the old adapter and the time to reach target accuracy exceeds the claimed reduction relative to training from scratch would falsify the central claim.
Figures
read the original abstract
Large Language Models (LLMs) are increasingly deployed as continuously evolving services, where frequent base-model updates may invalidate previously deployed task-specific Low-Rank Adaptation (LoRA) adapters. For service providers managing numerous downstream model services, retraining each LoRA adapter from scratch for every updated base model is computationally prohibitive and delays service rollout. Meanwhile, the simpler alternative, i.e., naively applying the original LoRA adapter to the updated base model, often leads to degraded service quality due to adapter-backbone incompatibility. To address this problem, we propose ReLoRA, a knowledge-reusing re-adaptation framework that efficiently restores service-ready LoRA adapters for evolving LLM services while preserving or improving task performance. Specifically, ReLoRA comprises two key optimization steps: 1) Adaptive LoRA initialization leverages Bayesian optimization to construct a compatibility-aware starting point by fusing information from both the previously deployed task adapter and the base model's evolution; 2) Fine-tuning with scheduled regularization first rapidly steers the adapter to a high-quality region via strong regularization, followed by relaxed regularization for task-specific refinement. This design enables rapid service-quality recovery with reduced re-adaptation overhead. Extensive experiments demonstrate that ReLoRA reduces time-to-readiness by up to 8.9$\times$ and improves accuracy by up to 4.6\% compared to baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ReLoRA, a re-adaptation framework for LoRA adapters when base LLMs are updated in deployed services. It consists of (1) Adaptive LoRA initialization via Bayesian optimization to fuse the prior task adapter with base-model evolution information into a compatibility-aware starting point, and (2) fine-tuning under scheduled regularization (strong then relaxed) for rapid steering to high-quality regions. The central empirical claim is that this yields up to 8.9× reduction in time-to-readiness and up to 4.6% accuracy gains versus baselines for evolving LLM services.
Significance. If the reported speedups and accuracy improvements hold under rigorous controls, the work addresses a practically important engineering problem for providers managing many downstream LoRA services on frequently updated base models. The combination of knowledge reuse via BO initialization and scheduled regularization could reduce re-training overhead in production settings, provided the method generalizes beyond the evaluated cases.
major comments (2)
- [Adaptive LoRA initialization (method description)] The central claim of 8.9× time-to-readiness reduction rests on the Adaptive LoRA initialization step producing a superior starting point via Bayesian optimization. However, neither the abstract nor the method description supplies the compatibility objective, the search space over LoRA parameters, the acquisition function, or the number of BO evaluations performed. Without these, it is impossible to determine whether the step is low-overhead and reliable or merely adds compute that offsets later savings.
- [Experiments / results] Table or experimental results section: quantitative claims of 8.9× speedup and 4.6% accuracy improvement are presented without accompanying details on experimental setup, baseline implementations (including how naive transfer and from-scratch training were realized), statistical significance tests, number of runs, or data exclusion criteria. This absence prevents verification that the data support the cross-method comparison.
minor comments (1)
- [Abstract] The abstract states gains 'compared to baselines' but does not name the baselines; this should be clarified in the abstract for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for greater methodological and experimental transparency. We will revise the manuscript to incorporate the requested details, which will strengthen the verifiability of our claims without altering the core contributions.
read point-by-point responses
-
Referee: [Adaptive LoRA initialization (method description)] The central claim of 8.9× time-to-readiness reduction rests on the Adaptive LoRA initialization step producing a superior starting point via Bayesian optimization. However, neither the abstract nor the method description supplies the compatibility objective, the search space over LoRA parameters, the acquisition function, or the number of BO evaluations performed. Without these, it is impossible to determine whether the step is low-overhead and reliable or merely adds compute that offsets later savings.
Authors: We agree that the method section currently lacks explicit specification of the Bayesian optimization components. In the revised manuscript we will add a dedicated subsection detailing the compatibility objective (a weighted combination of task performance on held-out data and parameter-space distance to the prior adapter), the search space (low-rank updates constrained to the delta between old and new base-model weights), the acquisition function (Expected Improvement), and the evaluation budget (30 iterations per task). These additions will confirm that the initialization overhead remains negligible relative to the reported fine-tuning savings. revision: yes
-
Referee: [Experiments / results] Table or experimental results section: quantitative claims of 8.9× speedup and 4.6% accuracy improvement are presented without accompanying details on experimental setup, baseline implementations (including how naive transfer and from-scratch training were realized), statistical significance tests, number of runs, or data exclusion criteria. This absence prevents verification that the data support the cross-method comparison.
Authors: We concur that the experimental reporting is insufficiently detailed. The revision will include an expanded experimental setup subsection specifying: (i) baseline implementations (naive transfer applies the original adapter directly; from-scratch uses standard LoRA training with identical hyperparameters), (ii) five independent random seeds per configuration, (iii) paired t-tests for significance (p < 0.05 reported), and (iv) no data exclusion. Updated tables will reference these controls. revision: yes
Circularity Check
No significant circularity; empirical method is self-contained
full rationale
The paper proposes ReLoRA as an applied engineering technique with two optimization steps (Bayesian optimization for adaptive initialization and scheduled regularization for fine-tuning), validated through experiments showing time and accuracy gains. No equations, derivations, or self-citations are shown that reduce the claimed results to fitted inputs or prior author work by construction. The contribution is framed as empirical rather than a closed-form prediction, leaving the derivation chain independent of the patterns that would indicate circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A brief overview of chatgpt: The history, status quo and potential future development,
T. Wu, S. He, J. Liu, S. Sun, K. Liu, Q.-L. Han, and Y. Tang, “A brief overview of chatgpt: The history, status quo and potential future development,”IEEE/CAA Journal of Automatica Sinica, vol. 10, no. 5, pp. 1122–1136, 2023. IEEE TRANSACTIONS ON SERVICES COMPUTING, VOL., NO., MAY . 2026 12
2023
-
[2]
Llama 2: Open Foundation and Fine-Tuned Chat Models
H. Touvron, L. Martin, K. Stone, P . Albert, A. Almahairi, Y. Babaei, N. Bashlykov, S. Batra, P . Bhargava, S. Bhosaleet al., “Llama 2: Open foundation and fine-tuned chat models,”arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Y. Cao, S. Li, Y. Liu, Z. Yan, Y. Dai, P . S. Yu, and L. Sun, “A comprehensive survey of ai-generated content (aigc): A history of generative ai from gan to chatgpt,”arXiv preprint arXiv:2303.04226, 2023
-
[4]
LoRA: Low-Rank Adaptation of Large Language Models
E. J. Hu, Y. Shen, P . Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen, “Lora: Low-rank adaptation of large language models,”arXiv preprint arXiv:2106.09685, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Gemini: A Family of Highly Capable Multimodal Models
G. Team, R. Anil, S. Borgeaud, J.-B. Alayrac, J. Yu, R. Soricut, J. Schalkwyk, A. M. Dai, A. Hauth, K. Millicanet al., “Gemini: a family of highly capable multimodal models,”arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Amazon sagemaker,
AWS, “Amazon sagemaker,” https://aws.amazon.com/cn/ sagemaker/
-
[7]
Together AI,
“Together AI,” https://www.together.ai, 2023, accessed: 2023-10- 15
2023
-
[8]
Qlora: Efficient finetuning of quantized llms,
T. Dettmers, A. Pagnoni, A. Holtzman, and L. Zettlemoyer, “Qlora: Efficient finetuning of quantized llms,”Advances in neural informa- tion processing systems, vol. 36, pp. 10 088–10 115, 2023
2023
-
[9]
{Cost-Efficient}large language model serving for multi-turn conversations with{CachedAttention},
B. Gao, Z. He, P . Sharma, Q. Kang, D. Jevdjic, J. Deng, X. Yang, Z. Yu, and P . Zuo, “{Cost-Efficient}large language model serving for multi-turn conversations with{CachedAttention},” in2024 USENIX Annual Technical Conference (USENIX ATC 24), 2024, pp. 111–126
2024
-
[10]
Amazon ec2 pricing,
AWS, “Amazon ec2 pricing,” https://aws.amazon.com/ec2/ pricing/
-
[11]
Portllm: Personalizing evolving large language models with training-free and portable model patches,
R. M. S. Khan, P . Li, S. Yun, Z. Wang, S. Nirjon, C.-W. Wong, and T. Chen, “Portllm: Personalizing evolving large language models with training-free and portable model patches,”arXiv preprint arXiv:2410.10870, 2024
-
[12]
Oral: Prompting your large-scale loras via conditional recurrent diffu- sion,
R. M. S. Khan, D. Tang, P . Li, K. Wang, and T. Chen, “Oral: Prompting your large-scale loras via conditional recurrent diffu- sion,”arXiv preprint arXiv:2503.24354, 2025
-
[13]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al- Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughanet al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Recyclable tuning for continual pre-training,
Y. Qin, C. Qian, X. Han, Y. Lin, H. Wang, R. Xie, Z. Liu, M. Sun, and J. Zhou, “Recyclable tuning for continual pre-training,”arXiv preprint arXiv:2305.08702, 2023
-
[15]
Elle: Efficient lifelong pre-training for emerging data,
Y. Qin, J. Zhang, Y. Lin, Z. Liu, P . Li, M. Sun, and J. Zhou, “Elle: Efficient lifelong pre-training for emerging data,”arXiv preprint arXiv:2203.06311, 2022
-
[16]
S2orc: The semantic scholar open research corpus,
K. Lo, L. L. Wang, M. Neumann, R. Kinney, and D. S. Weld, “S2orc: The semantic scholar open research corpus,”arXiv preprint arXiv:1911.02782, 2019
-
[17]
Ups and downs: Modeling the visual evolution of fashion trends with one-class collaborative filtering,
R. He and J. McAuley, “Ups and downs: Modeling the visual evolution of fashion trends with one-class collaborative filtering,” inproceedings of the 25th international conference on world wide web, 2016, pp. 507–517
2016
-
[18]
Defending against neural fake news,
R. Zellers, A. Holtzman, H. Rashkin, Y. Bisk, A. Farhadi, F. Roes- ner, and Y. Choi, “Defending against neural fake news,”Advances in neural information processing systems, vol. 32, 2019
2019
-
[19]
Measuring Massive Multitask Language Understanding
D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt, “Measuring massive multitask language under- standing,”arXiv preprint arXiv:2009.03300, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[20]
Don’t stop pretraining: Adapt language models to domains and tasks,
S. Gururangan, A. Marasovi ´c, S. Swayamdipta, K. Lo, I. Belt- agy, D. Downey, and N. A. Smith, “Don’t stop pretraining: Adapt language models to domains and tasks,”arXiv preprint arXiv:2004.10964, 2020
-
[21]
A probabilistic analysis of the rocchio algorithm with tfidf for text categorization,
T. Joachimset al., “A probabilistic analysis of the rocchio algorithm with tfidf for text categorization,” inICML, vol. 97. Citeseer, 1997, pp. 143–151
1997
-
[22]
Teknium”, “Openorca: An open dataset of gpt augmented flan reasoning traces,
W. Lian, B. Goodson, E. Pentland, A. Cook, C. Vong, and “Teknium”, “Openorca: An open dataset of gpt augmented flan reasoning traces,” 2023
2023
-
[23]
A Tutorial on Bayesian Optimization
P . I. Frazier, “A tutorial on bayesian optimization,”arXiv preprint arXiv:1807.02811, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[24]
Checkpoint merging via bayesian optimization in llm pretraining,
D. Liu, Z. Wang, B. Wang, W. Chen, C. Li, Z. Tu, D. Chu, B. Li, and D. Sui, “Checkpoint merging via bayesian optimization in llm pretraining,”arXiv preprint arXiv:2403.19390, 2024
-
[25]
Gaussian processes for machine learning,
M. Seeger, “Gaussian processes for machine learning,”Interna- tional journal of neural systems, vol. 14, no. 02, pp. 69–106, 2004
2004
-
[26]
SGDR: Stochastic Gradient Descent with Warm Restarts
I. Loshchilov and F. Hutter, “Sgdr: Stochastic gradient descent with warm restarts,”arXiv preprint arXiv:1608.03983, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[27]
D. S. Chaplot, “Albert q. jiang, alexandre sablayrolles, arthur men- sch, chris bamford, devendra singh chaplot, diego de las casas, florian bressand, gianna lengyel, guillaume lample, lucile saulnier, l´elio renard lavaud, marie-anne lachaux, pierre stock, teven le scao, thibaut lavril, thomas wang, timoth ´ee lacroix, william el sayed,”arXiv preprint ar...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding
A. Wang, “Glue: A multi-task benchmark and analysis plat- form for natural language understanding,”arXiv preprint arXiv:1804.07461, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[29]
Character-level convolutional networks for text classification,
X. Zhang, J. Zhao, and Y. LeCun, “Character-level convolutional networks for text classification,”Advances in neural information processing systems, vol. 28, 2015
2015
-
[30]
A large annotated corpus for learning natural language inference
S. R. Bowman, G. Angeli, C. Potts, and C. D. Manning, “A large annotated corpus for learning natural language inference,”arXiv preprint arXiv:1508.05326, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[31]
B. Peng, C. Li, P . He, M. Galley, and J. Gao, “Instruction tuning with gpt-4,”arXiv preprint arXiv:2304.03277, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Platypus: Quick, cheap, and powerful refinement of llms,
A. N. Lee, C. J. Hunter, and N. Ruiz, “Platypus: Quick, cheap, and powerful refinement of llms,”arXiv preprint arXiv:2308.07317, 2023
-
[33]
Fedpetuning: When federated learning meets the parameter- efficient tuning methods of pre-trained language models,
Z. Zhang, Y. Yang, Y. Dai, Q. Wang, Y. Yu, L. Qu, and Z. Xu, “Fedpetuning: When federated learning meets the parameter- efficient tuning methods of pre-trained language models,” in Annual Meeting of the Association of Computational Linguistics 2023. Association for Computational Linguistics (ACL), 2023, pp. 9963– 9977
2023
-
[34]
Ferrari: A personalized federated learning framework for heterogeneous edge clients,
Z. Yao, J. Liu, H. Xu, L. Wang, C. Qian, and Y. Liao, “Ferrari: A personalized federated learning framework for heterogeneous edge clients,”IEEE Transactions on Mobile Computing, 2024
2024
-
[35]
Dora: Weight-decomposed low-rank adaptation,
S.-Y. Liu, C.-Y. Wang, H. Yin, P . Molchanov, Y.-C. F. Wang, K.- T. Cheng, and M.-H. Chen, “Dora: Weight-decomposed low-rank adaptation,” inForty-first International Conference on Machine Learn- ing, 2024
2024
-
[36]
Scaling down to scale up: A guide to parameter-efficient fine-tuning,
V . Lialin, V . Deshpande, and A. Rumshisky, “Scaling down to scale up: A guide to parameter-efficient fine-tuning,”arXiv preprint arXiv:2303.15647, 2023
-
[37]
Parameter- efficient transfer learning for nlp,
N. Houlsby, A. Giurgiu, S. Jastrzebski, B. Morrone, Q. De Larous- silhe, A. Gesmundo, M. Attariyan, and S. Gelly, “Parameter- efficient transfer learning for nlp,” inInternational conference on machine learning. PMLR, 2019, pp. 2790–2799
2019
-
[38]
Conditional lora parameter generation,
X. Jin, K. Wang, D. Tang, W. Zhao, Y. Zhou, J. Tang, and Y. You, “Conditional lora parameter generation,”arXiv preprint arXiv:2408.01415, 2024
-
[39]
Model Merging in LLMs, MLLMs, and Beyond: Methods, Theories, Applications and Opportunities
E. Yang, L. Shen, G. Guo, X. Wang, X. Cao, J. Zhang, and D. Tao, “Model merging in llms, mllms, and beyond: Methods, theories, applications and opportunities,”arXiv preprint arXiv:2408.07666, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Editing Models with Task Arithmetic
G. Ilharco, M. T. Ribeiro, M. Wortsman, S. Gururangan, L. Schmidt, H. Hajishirzi, and A. Farhadi, “Editing models with task arith- metic,”arXiv preprint arXiv:2212.04089, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[41]
Merging models with fisher- weighted averaging,
M. S. Matena and C. A. Raffel, “Merging models with fisher- weighted averaging,”Advances in Neural Information Processing Systems, vol. 35, pp. 17 703–17 716, 2022
2022
-
[42]
Dataless knowl- edge fusion by merging weights of language models,
X. Jin, X. Ren, D. Preotiuc-Pietro, and P . Cheng, “Dataless knowl- edge fusion by merging weights of language models,”arXiv preprint arXiv:2212.09849, 2022
-
[43]
Adamerging: Adaptive model merging for multi-task learning.arXiv preprint arXiv:2310.02575,
E. Yang, Z. Wang, L. Shen, S. Liu, G. Guo, X. Wang, and D. Tao, “Adamerging: Adaptive model merging for multi-task learning,” arXiv preprint arXiv:2310.02575, 2023
-
[44]
Evolutionary op- timization of model merging recipes,
T. Akiba, M. Shing, Y. Tang, Q. Sun, and D. Ha, “Evolutionary op- timization of model merging recipes,”Nature Machine Intelligence, vol. 7, no. 2, pp. 195–204, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.