Pixel Cube: Diffusion-based Portrait Video Relighting Through Realistic Lighting Reproduction
Pith reviewed 2026-06-28 14:48 UTC · model grok-4.3
The pith
A diffusion model relights dynamic portrait videos to match new environments while preserving identity and motion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By training a video diffusion model on a hybrid dataset of real-captured and rendered dynamic portrait videos with known lighting, and conditioning generation on per-frame HDR environment maps together with a synthesized background, the method produces relit videos that remain realistic and harmonious under the new lighting while faithfully preserving the subject's expression, skin tone, wrinkles, facial hair, and overall motion.
What carries the argument
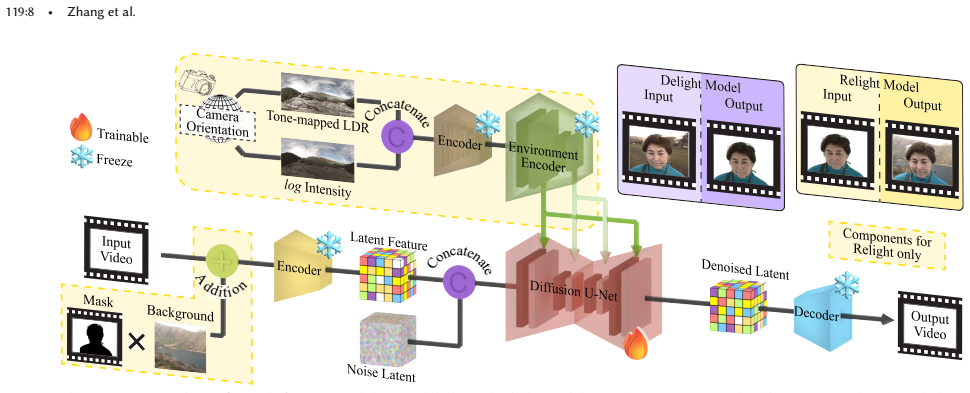
A conditional video diffusion model that takes per-frame HDR environment maps and a synthesized background image as lighting and exposure controls, initialized from pre-trained video diffusion priors.
If this is right
- Relit videos can be produced for subjects, motions, and lighting conditions absent from the training set.
- The same model supports practical portrait-photography workflows by swapping environment maps without new shoots.
- Temporal consistency holds across the full sequence when the input motion is preserved.
- Photorealism and lighting harmony reach levels reported as state-of-the-art on the authors' test set.
Where Pith is reading between the lines
- The background-synthesis trick for exposure control could be replaced by an explicit exposure parameter if the model were retrained.
- The same conditioning scheme might transfer to full-body or scene videos once suitable hybrid datasets exist.
- Because the model already separates lighting from identity, it could be combined with existing face-tracking tools for interactive lighting edits.
Load-bearing premise
The hybrid real-plus-rendered training set with accurate lighting labels is large and diverse enough for the diffusion model to learn relighting that works on arbitrary unseen videos.
What would settle it
Run the model on an in-the-wild video under a measured target environment map and compare the output frame-by-frame against a physical re-capture of the same subject under that same map; any systematic mismatch in skin-tone gradients or visible flicker across frames would falsify the claim.
Figures














read the original abstract
We present a diffusion-based method for relighting dynamic portrait videos with photorealism and temporal consistency. Our method is fueled by a hybrid training dataset that consists of real-captured and rendered dynamic portrait videos with diverse subject appearances, facial motions, head poses, and known lighting conditions. Specifically, we construct an LED-based lighting system for realistic lighting emulation and high-speed video relighting data acquisition. By leveraging the image priors embedded in pre-trained video diffusion models, and using per-frame high dynamic range (HDR) environment map as lighting control, we train a high-performance generative model for realistic and identity-preserving dynamic portrait video relighting. In addition to the environment map control, our model uses a synthesized background image to enable control on the camera's exposure level and color tone. Our model can produce temporally consistent relit portrait video that looks realistic and harmonious under a provided new environment and faithfully preserve the subject's expression and fine facial features, including skin tone, wrinkles, and facial hair. Our model generalizes well to unseen data, in terms of the subject appearance, motion, and lighting condition. We perform extensive experiments on relighting in-the-wild videos with various environment maps and demonstrate practical applications on portrait photography. Results show that our method achieves state-of-the-art performance in photorealism, lighting harmony, and temporal consistency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Pixel Cube, a diffusion-based method for relighting dynamic portrait videos. It constructs a hybrid training dataset of real-captured and rendered videos using an LED-based lighting rig for known lighting conditions, fine-tunes pre-trained video diffusion models with per-frame HDR environment map control and synthesized background images for exposure and color tone, and claims to achieve photorealistic, temporally consistent results that preserve identity, expression, and fine details while generalizing to unseen subjects, motions, and lighting; extensive experiments on in-the-wild videos are said to demonstrate state-of-the-art performance in photorealism, lighting harmony, and temporal consistency, with applications to portrait photography.
Significance. If the experimental validation holds, the work would advance portrait video relighting by showing how realistic capture rigs combined with diffusion priors and explicit lighting control can deliver practical, generalizable results for dynamic content, potentially impacting applications in film, photography, and AR/VR.
major comments (2)
- [Abstract] Abstract: the central claim of state-of-the-art performance in photorealism, lighting harmony, and temporal consistency is asserted without any quantitative metrics, baseline comparisons, ablation studies, or dataset details; this prevents verification that the hybrid dataset plus diffusion priors plus HDR control actually supports the generalization and superiority claims.
- [Abstract] The manuscript states that experiments were performed on in-the-wild videos with various environment maps, but no evaluation protocol, test set composition, or comparison tables are referenced; without these, the SOTA assertion cannot be assessed as load-bearing evidence for the method's effectiveness.
minor comments (1)
- The term 'Pixel Cube' is introduced in the title but not defined or motivated in the abstract; a brief explanation of the name or core technical contribution it represents would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. The comments correctly note that the abstract summarizes claims without inline quantitative support or protocol references. The full manuscript contains these details in the experiments section, but we agree the abstract should be strengthened for clarity. We will revise the abstract accordingly and address each point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of state-of-the-art performance in photorealism, lighting harmony, and temporal consistency is asserted without any quantitative metrics, baseline comparisons, ablation studies, or dataset details; this prevents verification that the hybrid dataset plus diffusion priors plus HDR control actually supports the generalization and superiority claims.
Authors: The abstract is intentionally concise, but the referee is correct that it does not reference the supporting evidence. The full paper includes quantitative metrics (e.g., PSNR, SSIM, LPIPS, user studies), baseline comparisons against prior relighting methods, ablation studies on the hybrid dataset and HDR control, and dataset details in Sections 3 and 4. To address this, we will revise the abstract to include a brief sentence referencing these quantitative results and the generalization experiments. revision: yes
-
Referee: [Abstract] The manuscript states that experiments were performed on in-the-wild videos with various environment maps, but no evaluation protocol, test set composition, or comparison tables are referenced; without these, the SOTA assertion cannot be assessed as load-bearing evidence for the method's effectiveness.
Authors: We agree the abstract lacks explicit references to the evaluation details. The manuscript describes the in-the-wild test videos, environment maps, evaluation protocol (including metrics and user studies), test set composition, and comparison tables in Section 4. We will revise the abstract to reference the experimental protocol and results sections, ensuring the SOTA claims are better supported at a high level. revision: yes
Circularity Check
No significant circularity identified
full rationale
The manuscript describes construction of an LED capture rig and hybrid real+rendered dataset with known lighting, followed by fine-tuning of a pre-trained video diffusion model conditioned on per-frame HDR environment maps plus synthesized backgrounds. No equations, uniqueness theorems, or self-citations are invoked to derive the central performance claims; the result is presented as the empirical outcome of standard supervised training on externally acquired data. The derivation chain therefore remains self-contained and does not reduce any prediction to a fitted input or self-referential definition by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
1899 Wraps Innovative Virtual Production , author=
-
[2]
2022 , booktitle =
LeGendre, Chloe and Lepicovsky, Lukas and Debevec, Paul , title =. 2022 , booktitle =
2022
-
[3]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Cai, Ziqi and Jiang, Kaiwen and Chen, Shu-Yu and Lai, Yu-Kun and Fu, Hongbo and Shi, Boxin and Gao, Lin , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[4]
Tero Karras and Miika Aittala and Timo Aila and Samuli Laine , title =. Proc. NeurIPS , year =
-
[5]
and Malik, Jitendra , title =
Debevec, Paul E. and Malik, Jitendra , title =. 1997 , booktitle =
1997
-
[6]
Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR) , year=
Comprehensive Relighting: Generalizable and Consistent Monocular Human Relighting and Harmonization , author=. Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR) , year=
-
[7]
2025 , booktitle =
Nadav Magar and Amir Hertz and Eric Tabellion and Yael Pritch and Alex Rav-Acha and Ariel Shamir and Yedid Hoshen , Title =. 2025 , booktitle =
2025
-
[8]
Annual Conference on Neural Information Processing Systems , year=
BecomingLit: Relightable Gaussian Avatars with Hybrid Neural Shading , author=. Annual Conference on Neural Information Processing Systems , year=
-
[9]
Proceedings of the SIGGRAPH Asia 2025 Conference Papers , pages=
3DPR: Single Image 3D Portrait Relighting with Generative Priors , author=. Proceedings of the SIGGRAPH Asia 2025 Conference Papers , pages=
2025
-
[10]
arXiv preprint arXiv:2504.16081 , year=
Survey of Video Diffusion Models: Foundations, Implementations, and Applications , author=. arXiv preprint arXiv:2504.16081 , year=
-
[11]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Smartbrush: Text and shape guided object inpainting with diffusion model , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[12]
Video diffusion models , author=. arXiv:2204.03458 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
2021 , journal=
High-Resolution Image Synthesis with Latent Diffusion Models , author=. 2021 , journal=
2021
-
[14]
Retrieval-Augmented Diffusion Models , year =
Blattmann, Andreas and Rombach, Robin and Oktay, Kaan and Ommer, Bj\". Retrieval-Augmented Diffusion Models , year =
-
[15]
Nature Machine Intelligence , volume=
Estimation of continuous valence and arousal levels from faces in naturalistic conditions , author=. Nature Machine Intelligence , volume=
-
[16]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Lux Post Facto: Learning Portrait Performance Relighting with Conditional Video Diffusion and a Hybrid Dataset , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[17]
A practical appearance model for dynamic facial color , year =
Jimenez, Jorge and Scully, Timothy and Barbosa, Nuno and Donner, Craig and Alvarez, Xenxo and Vieira, Teresa and Matts, Paul and Orvalho, Ver\'. A practical appearance model for dynamic facial color , year =
-
[18]
DifFRelight: Diffusion-Based Facial Performance Relighting , year =
He, Mingming and Clausen, Pascal and Ta. DifFRelight: Diffusion-Based Facial Performance Relighting , year =
-
[19]
ACM Trans
Wenger, Andreas and Gardner, Andrew and Tchou, Chris and Unger, Jonas and Hawkins, Tim and Debevec, Paul , title =. ACM Trans. Graph. , year =
-
[20]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Stable video diffusion: Scaling latent video diffusion models to large datasets , author=. arXiv preprint arXiv:2311.15127 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
European Conference on Computer Vision (ECCV) , year=
Emo: Emote portrait alive generating expressive portrait videos with audio2video diffusion model under weak conditions , author=. European Conference on Computer Vision (ECCV) , year=
-
[22]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
StableAnimator: High-Quality Identity-Preserving Human Image Animation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[23]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Animate anyone: Consistent and controllable image-to-video synthesis for character animation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[24]
, title =
Mei, Yiqun and Zeng, Yu and Zhang, He and Shu, Zhixin and Zhang, Xuaner and Bi, Sai and Zhang, Jianming and Jung, HyunJoon and Patel, Vishal M. , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[25]
Proceedings of Advances in Neural Information Processing Systems , year =
Neural Gaffer: Relighting Any Object via Diffusion , author =. Proceedings of Advances in Neural Information Processing Systems , year =
-
[26]
Proceedings of International Conference on Learning Representations , year=
Scaling In-the-Wild Training for Diffusion-based Illumination Harmonization and Editing by Imposing Consistent Light Transport , author=. Proceedings of International Conference on Learning Representations , year=
-
[27]
2025 , journal=
RelightVid: Temporal-Consistent Diffusion Model for Video Relighting , author=. 2025 , journal=
2025
-
[28]
Proceedings of ACM SIGGRAPH , year =
DiLightNet: Fine-grained Lighting Control for Diffusion-based Image Generation , author =. Proceedings of ACM SIGGRAPH , year =
-
[29]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Ruofan Liang and Zan Gojcic and Huan Ling and Jacob Munkberg and Jon Hasselgren and Zhi-Hao Lin and Jun Gao and Alexander Keller and Nandita Vijaykumar and Sanja Fidler and Zian Wang , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[30]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year=
DiFaReli: Diffusion Face Relighting , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year=
-
[31]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
SynthLight: Portrait Relighting with Diffusion Model by Learning to Re-render Synthetic Faces , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[32]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Repurposing Diffusion-Based Image Generators for Monocular Depth Estimation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[33]
2025 , journal=
Marigold: Affordable Adaptation of Diffusion-Based Image Generators for Image Analysis , author=. 2025 , journal=
2025
-
[34]
DreamFusion: Text-to-3D using 2D Diffusion
Dreamfusion: Text-to-3d using 2d diffusion , author=. arXiv preprint arXiv:2209.14988 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year=
Diffir: Efficient diffusion model for image restoration , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year=
-
[36]
ACM Trans
Learning to Relight Portrait Images via a Virtual Light Stage and Synthetic-to-Real Adaptation , author=. ACM Trans. Graph. , year=
-
[37]
Proceedings of ACM SIGGRAPH , year =
Debevec, Paul and Hawkins, Tim and Tchou, Chris and Duiker, Haarm-Pieter and Sarokin, Westley and Sagar, Mark , title =. Proceedings of ACM SIGGRAPH , year =
-
[38]
Institute for Creative Technologies Technical Report No
Postproduction re-illumination of live action using time-multiplexed lighting , author=. Institute for Creative Technologies Technical Report No. ICT TR , volume=
-
[39]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Relightful harmonization: Lighting-aware portrait background replacement , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[40]
Proceedings of SIGGRAPH Asia , year=
Uravatar: Universal relightable gaussian codec avatars , author=. Proceedings of SIGGRAPH Asia , year=
-
[41]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Shunsuke Saito and Gabriel Schwartz and Tomas Simon and Junxuan Li and Giljoo Nam , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[42]
Proceedings of SIGGRAPH Asia , year=
VRMM: A volumetric relightable morphable head model , author=. Proceedings of SIGGRAPH Asia , year=
-
[43]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
SwitchLight: Co-design of Physics-driven Architecture and Pre-training Framework for Human Portrait Relighting , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[44]
, author=
Total relighting: learning to relight portraits for background replacement. , author=. ACM Trans. Graph. , volume=
-
[45]
ACM Transactions on Graphics (TOG) , volume=
Free-viewpoint indoor neural relighting from multi-view stereo , author=. ACM Transactions on Graphics (TOG) , volume=
-
[46]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Ranjan, Anurag and Yi, Kwang Moo and Chang, Jen-Hao Rick and Tuzel, Oncel , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2023 , pages =
2023
-
[47]
Proceedings of ACM SIGGRAPH , year=
Volux-GAN: A Generative Model for 3D Face Synthesis with HDRI Relighting , author=. Proceedings of ACM SIGGRAPH , year=
-
[48]
Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition (CVPR) , year=
Face relighting with geometrically consistent shadows , author=. Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[49]
European Conference on Computer Vision (ECCV) , year=
Intrinsic face image decomposition with human face priors , author=. European Conference on Computer Vision (ECCV) , year=
-
[50]
ACM Transactions on Graphics (TOG) , volume=
Portrait lighting transfer using a mass transport approach , author=. ACM Transactions on Graphics (TOG) , volume=. 2017 , publisher=
2017
-
[51]
2014 , booktitle=
Style transfer for headshot portraits , author=. 2014 , booktitle=
2014
-
[52]
Animatable facial reflectance fields , year =
Hawkins, Tim and Wenger, Andreas and Tchou, Chris and Gardner, Andrew and G\". Animatable facial reflectance fields , year =
-
[53]
2002 , volume =
Debevec, Paul and Wenger, Andreas and Tchou, Chris and Gardner, Andrew and Waese, Jamie and Hawkins, Tim , title =. 2002 , volume =
2002
-
[54]
Deep relightable textures: volumetric performance capture with neural rendering , year =
Meka, Abhimitra and Pandey, Rohit and H\". Deep relightable textures: volumetric performance capture with neural rendering , year =
-
[55]
and Ramamoorthi, Ravi , title =
Sun, Tiancheng and Xu, Zexiang and Zhang, Xiuming and Fanello, Sean and Rhemann, Christoph and Debevec, Paul and Tsai, Yun-Ta and Barron, Jonathan T. and Ramamoorthi, Ravi , title =. 2020 , volume =
2020
-
[56]
Rendering Techniques , volume=
A Dual Light Stage , author=. Rendering Techniques , volume=
-
[57]
Virtual Cinematography: Relighting through Computation , year=
Debevec, Paul , journal=. Virtual Cinematography: Relighting through Computation , year=
-
[58]
Proceedings of ACM SIGGRAPH Asia , year=
Circularly polarized spherical illumination reflectometry , author=. Proceedings of ACM SIGGRAPH Asia , year=
-
[59]
Proceedings of ACM SIGGRAPH Asia , year=
Multiview face capture using polarized spherical gradient illumination , author=. Proceedings of ACM SIGGRAPH Asia , year=
-
[60]
ACM Trans
Acquiring reflectance and shape from continuous spherical harmonic illumination , author=. ACM Trans. Graph. , volume=
-
[61]
ACM Trans
Driving high-resolution facial scans with video performance capture , author=. ACM Trans. Graph. , volume=
-
[62]
ACM Trans
Estimating surface reflectance properties of a complex scene under captured natural illumination , author=. ACM Trans. Graph. , year=
-
[63]
International Journal of Computer Vision , volume=
Free-view face relighting using a hybrid parametric neural model on a small-olat dataset , author=. International Journal of Computer Vision , volume=. 2023 , publisher=
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.